
- 1阿里大数据之路:数据模型篇大总结(收藏)
- 2PostgreSQL - 查询表结构和索引信息_postgres 查询表的索引字段信息
- 3Android Studio的Gradle错误解决方法_android studio 错误 丢失的gradle项目信息。请检查ide是否成功地将其状态与gr
- 4FPGA原理和结构- 理解FPGA的基础知识_fpga原理和结构天野英晴pdf
- 5一文读懂:区块链的原理、技术、应用领域_区块链技术应用总结
- 6记录一下一些收藏的网页
- 7【开源物联网平台】FastBee使用EMQX5.0接入步骤_java 开源的物联网项目
- 8大数据相关招聘岗位可视化分析-毕业设计_基于大数据的招聘岗位可视化分析与展示
- 9【深度学习论文翻译】基于LSTM深度神经网络的时间序列预测(Time Series Prediction Using LSTM Deep Neural Networks)_epochs = configs['training']['epochs'],
- 10ecc加解密算法 c++_ECC相关算法解析
2.2DFS的多种模型(算法提高课)_dfs常见模型
赞
踩
目录
一,连通性模型
之前用bfs实现的连通性模型,这里用dfs实现连通性模型
1,迷宫
题目链接:https://vjudge.net/problem/OpenJ_Bailian-2790
代码如下:
- #include<iostream>
- #include<algorithm>
- #include<cstring>
- using namespace std;
-
- const int N=110;
-
- int n;
- int xa,xb,ya,yb;
- char a[N][N];
- bool st[N][N];
-
- int dx[4]={-1,0,1,0};
- int dy[4]={0,1,0,-1};
-
- bool dfs(int x,int y)
- {
- if(a[x][y]=='#')return false;
- if(x==ya&&y==yb)return true;
- st[x][y]=true;
- for(int i=0;i<4;i++)
- {
- int fx=x+dx[i],fy=y+dy[i];
- if(fx<0||fx>=n||fy<0||fy>=n)continue;
- if(st[fx][fy])continue;
- if(dfs(fx,fy))
- return true;
- }
- return false;
- }
- int main()
- {
- int t;
- cin>>t;
- while(t--)
- {
- memset(st,false,sizeof st);
- cin>>n;
- for(int i=0;i<n;i++)cin>>a[i];
- cin>>xa>>xb>>ya>>yb;
- if(dfs(xa,xb))
- puts("YES");
- else
- puts("NO");
- }
- return 0;
- }

2,红与黑
题目链接:https://www.acwing.com/problem/content/1115/
- #include<iostream>
- #include<algorithm>
- #include<cstring>
-
- using namespace std;
-
- const int N=25;
-
- int n,m;
- char a[N][N];
- bool st[N][N];
-
- int dx[4]={0,1,0,-1};
- int dy[4]={1,0,-1,0};
-
- int dfs(int sx,int sy)
- {
- int cnt=1;
- st[sx][sy]=true;
- for(int i=0;i<4;i++)
- {
- int x=sx+dx[i],y=sy+dy[i];
- if(x<0||x>=n||y<0||y>=m)continue;
- if(st[x][y])continue;
- if(a[x][y] != '.')continue;
-
- cnt+=dfs(x,y);
- }
- return cnt;
- }
- int main()
- {
- while(cin>>m>>n,n||m)
- {
- for(int i=0;i<n;i++)cin>>a[i];
- int sx,sy;
- for(int i=0;i<n;i++)
- for(int j=0;j<m;j++)
- if(a[i][j]=='@')
- sx=i,sy=j;
- memset(st,false,sizeof st);
- cout<<dfs(sx,sy)<<endl;
- }
- return 0;
- }
二,搜索顺序
1,马走日
题目链接:https://vjudge.net/problem/OpenJ_NOI-CH0205-8465
就是一个普通的dfs,记得恢复现场
代码如下:
- #include<iostream>
- #include<algorithm>
- #include<cstring>
-
- using namespace std;
-
- const int N=12;
-
- int n,m,sx,sy;
- bool st[N][N];
- int ans=0;
-
- int dx[8]={-2,-1,1,2,2,1,-1,-2};
- int dy[8]={1,2,2,1,-1,-2,-2,-1};
-
- void dfs(int sx,int sy,int cnt)
- {
- if(cnt==n*m)
- {
- ans++;
- return;
- }
- st[sx][sy]=true;
- for(int i=0;i<8;i++)
- {
- int fx=sx+dx[i],fy=sy+dy[i];
- if(fx<0||fx>=n||fy<0||fy>=m)continue;
- if(st[fx][fy])continue;
- dfs(fx,fy,cnt+1);
- }
- st[sx][sy]=false;//当一个棋盘的所有状态都遍历完了,就恢复现场
- }
- int main()
- {
- int t;
- cin>>t;
- while(t--)
- {
- cin>>n>>m>>sx>>sy;
- ans=0;
- dfs(sx,sy,1);
- cout<<ans<<endl;
- }
- return 0;
- }
2,单词接龙
题目链接:https://vjudge.net/problem/OpenJ_NOI-CH0205-8783
这题需要先预处理出来,将一个单词接在其他单词后面的最小重合部分,这样才能保证我们接龙后得到的单词是最长的,对于合法的单词,我们进行暴搜,每次暴搜都记录单词的长度,所有情况暴搜完以后记录的长度就是我们想要的答案
代码如下:
- #include<iostream>
- #include<algorithm>
- #include<cstring>
-
- using namespace std;
-
- const int N=25;
-
- string word[N];
- char start;
- int used[N];
- int g[N][N];
- int ans,n;
-
- void dfs(string dragon,int last)//分别代表当前单词的状态和当前单词的末尾单词
- {
- ans=max((int)dragon.size(),ans);
-
- used[last]++;//用了的单词次数要加1
- for(int i=0;i<n;i++)
- if(g[last][i]&&used[i]<2)//找到符合条件的单词拼接在单词后面,进行深搜
- dfs(dragon+word[i].substr(g[last][i]),i);
- used[last]--;//恢复现场
- }
- int main()
- {
- cin>>n;
- for(int i=0;i<n;i++)
- cin>>word[i];
- for(int i=0;i<n;i++)
- {
- for(int j=0;j<n;j++)
- {
- string a=word[i],b=word[j];
- for(int k=1;k<min(a.size(),b.size());k++)//找到a跟b的最小公共部分,将b接在a后面的的最小重合部分
- {
- if(a.substr(a.size()-k,k)==b.substr(0,k))
- {
- g[i][j]=k;
- break;//一定要及时break,否则找到的公共部分可能不是最小的
- }
- }
- }
- }
- cin>>start;
- for(int i=0;i<n;i++)
- if(word[i][0]==start)//如果这个单词能接在给定的字母后面,就进行一个dfs
- dfs(word[i],i);
- cout<<ans;
- return 0;
- }
3,分成互质组
题目链接:https://vjudge.net/problem/OpenJ_NOI-CH0205-7834
这题我们如何用dfs来做呢,我们可以先开第一个组,将所有能加入到这个点的先加到这个组中去,如果没有点能加到当前组,就新开一个组
代码如下:
- #include<iostream>
- #include<algorithm>
-
- using namespace std;
-
- const int N=11;
-
- int group[N][N],a[N];
- int ans=N,n;//开始是要将分的组的数量置为最大,表示最坏情况
- bool st[N];
-
- int gcd(int a,int b)//返回两个值的最大公约数
- {
- return b?gcd(b,a%b):a;
- }
- bool check(int cnt,int gc,int x)//判断x能不能放进去这个数组中
- {
- bool flag=false;
- for(int i=0;i<gc;i++)
- {
- if(gcd(group[cnt][i],x)>1)//如果有组内元素与x不互质,就不能放进去
- return false;
- }
- return true;//如果x与组里所有元素都互质,说明可以放进去
- }
- void dfs(int cnt,int gc,int sum)//cnt表示第几个分组,gc表示当前分组的组内元素数量,sum表示已经分好了几个元素
- {
- if(cnt>=ans)return;//一个小优化,如果当前的分组方式分的组的数量比之前分组的数量多了,说明不是最优解,直接返回
- if(sum==n)//如果能跳过上一步,我们能找到的解一定是更优解
- {
- ans=cnt;
- return;
- }
- bool flag=false;//判断能不能将一个数放到现有的组中去
- for(int i=0;i<n;i++)
- {
- if(!st[i]&&check(cnt,gc,a[i]))//这个点一定是要还没分过组,并且这个组能把他放进去
- {
- st[i]=true;//表示已经给这个点分好组了
- group[cnt][gc]=a[i];//将这个点加入到这个组中
- dfs(cnt,gc+1,sum+1);//组内数量加一,安排好的点的数量总数加一
- st[i]=false;//恢复现场
-
- flag=true;//只要有一个数能放到现有组去,就继续搜索,暂时不用开新组
- }
- }
- if(!flag)//如果当前剩下的数都不能放进现有组,那么就要开一个新组
- dfs(cnt+1,0,sum);
- }
- int main()
- {
- cin>>n;
- for(int i=0;i<n;i++)cin>>a[i];
-
- dfs(1,0,0);//第一参数表示组的数量,第二个参数表示当前组的组内元素数量,第三个参数表示已经安排好的点的数量
-
- cout<<ans<<endl;
- return 0;
- }
三,dfs剪枝
dfs剪枝主要有以下几种
1)优化搜索顺序 2)排除等效冗余 3)可行性剪枝 4)最优性剪枝 5)记忆化
下面看几个例题来更好的理解这几中剪枝的方式
1,小猫爬山
题目链接:https://www.acwing.com/problem/content/167/
我们将小猫的重量从大到小排序,优先排重的小猫,这里可以看成是优化搜索顺序,因为有可能一只猫就可以把缆车占满,就不用先考虑把哪几只重量较轻的小猫放到一个缆车去。
接着,我们遍历到某种放小猫的方案需要的缆车数如果大于我们之前得到的方案数,那就可以及时返回,不用继续搜索了,这个可以看成是最优性剪枝,因为我们已经得到一个更优的方案,如果在当前方案继续搜索一定比我的更优方案要差
其次,对于一个小猫,我们先看能不能将他放到现有的缆车中,如果能放的话先把他放进去,这个可以看成是可行性剪枝,我们可以把这个问题放大来看来理解这一步操作,假设有十个小猫,如果没有这一步,我们可能回出现用十个缆车的情况,但是有了这一步,可能我们只需要五个缆车就能装下全部小猫了,这样在遍历到十个缆车的情况时,我们再结合最优性剪枝,就可以减少我们的搜索方案
代码如下:
- #include<iostream>
- #include<algorithm>
-
- using namespace std;
-
- const int N=20;
-
- int n,m;
- int w[N],sum[N];
- int ans=N;
-
- void dfs(int u,int k)//u表示已经安排到了第几个小猫,k表示缆车的数量
- {
- if(k>=ans)return;//最优性剪枝
- if(u==n)
- {
- ans=k;
- return;
- }
- for(int i=0;i<k;i++)
- {
- if(sum[i]+w[u]<=m)//可行性剪枝
- {
- sum[i]+=w[u];
- dfs(u+1,k);
- sum[i]-=w[u];//恢复现场
- }
- }
- sum[k]=w[u];//将小猫放到新的缆车去
- dfs(u+1,k+1);
- sum[k]=0;//恢复现场
- }
- int main()
- {
- cin>>n>>m;
- for(int i=0;i<n;i++)cin>>w[i];
- sort(w,w+n,greater<int>());//将小猫从大到小排序,最优搜索顺序
-
- dfs(0,0);
- cout<<ans;
- return 0;
- }
2,数独
题目链接:https://www.acwing.com/problem/content/description/168/
这题是一个很经典的题目,可以反复多看看
这题的做法可以说是非常nb了,我们对于每一行每一列以及每个3*3的小矩阵都用一个九位二进制数来表示状态,如果这个二进制的哪个位置上对应是1,就表示我们能填数字,能填的数字就是这个1是在这个二进制数的第几位再加上1,例如一个9位二进制数100000101,那么能填的数字就是1,3,9.
我们把这个位置的行列以及小矩阵的三个二进制按位与之后就可以得到满足条件的能填的数,然后我们填数不能毫无章法,否则会增大我们的搜索量,按照常规思维,当我们人类在做数独问题时,肯定是优先填能填数字最少的空格,我们的搜索顺序同样如此,先找到能填数字最少的空格,再以这个分支往下递归搜索(这可以看成是优化搜索顺序),最终肯定能得到一个可行解,只要找到一个可行解,就可以直接停止搜索了
同时,对于每个二进制数中能填的数,我们可以用lowbit来优化
代码如下:
- #include<iostream>
- #include<algorithm>
-
- using namespace std;
-
- const int N=9,M=1<<N;
-
- int row[N],col[N],cell[3][3];//分别表示每一行列和每个3*3的小矩阵的状态,用二进制表示
- int mp[M],one[M];//mp表示一个二进制数对应的能填的数字,one表示一个二进制数中有几个1
- char str[100];
-
- int lowbit(int x)//返回一个二进制数的最后一个1以及后面的0,例如10100,返回100
- {
- return x&-x;
- }
- void init()//首先要预处理一些东西,方便后面计算
- {
- for(int i=0;i<N;i++)mp[1<<i]=i;//预处理出来一个二进制数是1的位置对应的我们能填哪个数字
- for(int i=0;i<M;i++)
- {
- int t=0;
- for(int j=i;j;j-=lowbit(j))//用lowbit可以加快运算,返回这个二进制数中1的个数
- t++;
- one[i]=t;//记录每个二进制数中1的个数,表示这个位置我们能填的个数有几个
- }
- for(int i=0;i<N;i++)
- row[i]=col[i]=(1<<N)-1;//将每一行列的每个位置都初始化为1,注意这里是二进制的1,不是十进制的1,表示所有位置都可以填数字
- for(int i=0;i<3;i++)
- for(int j=0;j<3;j++)
- cell[i][j]=(1<<N)-1;//将每个3*3的小矩阵都初始化为1,注意,这里是二进制的1,不是十进制的1
- }
-
- int get(int x,int y)//返回这个位置能填的数字,一个位置行列小矩阵都是1的时候才表示这个位置可以填数字
- { //具体可以填哪些数字就可以用我们预处理出来的mp得到
- return row[x]&col[y]&cell[x/3][y/3];
- }
- bool dfs(int cnt)//cnt表示还剩几个空位没填
- {
- if(!cnt)return true;//如果全部填完了返回true
-
- int minv=10,x,y;//先找到能填数字最少的空格,这里可以看成是优化搜索顺序
- for(int i=0;i<N;i++)
- {
- for(int j=0;j<N;j++)
- {
- if(str[i*9+j]=='.')//首先这个位置得是空格
- {
- int state=get(i,j);//返回这个位置能填的数字
- if(one[state]<minv)//找到这个位置能填的数字有几个,判断是否能更新
- {
- minv=one[state];
- x=i;
- y=j;
- }
- }
- }
- }
- int state=get(x,y);//能填数字最少的空格
- for(int i=state;i;i-=lowbit(i))//枚举这个空格能填的数字
- {
- int t=mp[lowbit(i)];//找到二进制数中1对应得能填得数字是几
- str[x*9+y]=t+'1';//这里要注意我们存的是0~8,但是要填得数字是1`9,所以要加1
-
- //这个空格填了数字以后要更新状态
- row[x]-=1<<t;
- col[y]-=1<<t;
- cell[x/3][y/3]-=1<<t;
-
- if(dfs(cnt-1))//继续向下搜索
- return true;//如果这个分支能找到一个可行解,就可以直接返回答案了
-
- //恢复现场
- str[x*9+y]='.';
- row[x]+=1<<t;
- col[y]+=1<<t;
- cell[x/3][y/3]+=1<<t;
- }
- return false;//表示当前分支不能找到一个可行解,就回溯然后继续搜索
- }
- int main()
- {
-
- while(cin>>str,str[0]!='e')
- {
- init();
- int cnt=0;//记录空格数
- for(int i=0,k=0;i<N;i++)//对于题目给出的已经填好的数字,要先更新一下状态
- {
- for(int j=0;j<N;j++,k++)
- {
- if(str[k]!='.')
- {
- int t=str[k]-'1';
- row[i]-=1<<t;
- col[j]-=1<<t;
- cell[i/3][j/3]-=1<<t;
- }
- else
- cnt++;
- }
- }
- dfs(cnt);
- cout<<str<<endl;
- }
- return 0;
- }
3,木棒
题目链接:https://www.acwing.com/problem/content/description/169/
这题的我们可以以正常思路,从小到大枚举长度,看在当前长度下是否能找到一个合法方案,如果能,第一次找到合法方案的长度一定就是最优解,每次先将一个木棒安排好放哪些木棍,安排好一根木棒以后才继续安排下一根木棒,这样暴力搜索一定是能不重不漏的得到一个解的
接着,我们看如何来剪枝优化,这题的剪枝非常经典
1)我们可以先记录所有木棍的长度总和,要想用等长的木棒安排好所有的木棍,那么木棍的长度一定要能整除长度的总和,这样我们就搜索很多长度是否能找到合法方案
2)优化搜索顺序 将木棍从大到小排序,类似于小猫爬山那题
3)排除等效冗余 我们可以按照组合的方式枚举,假设我们对于一根木棒,选择用第1,2,3根木棍来填充和选择用第1,3,2根木棍来填充的效果是一样的,因此我们只需要枚举其中之一的一种情况即可,所以我们记录下来当前木棒的最后一根木棍的下标,从最后一根木棍的下标开始枚举就可以满足上述要求,
4)对于当前木棒,记录最近一次尝试的木棍长度,如果分支搜索失败回溯,不再尝试向该木棒中插入其他相同长度的木棒(必定也会失败)
5)如果在当前木棒中插入第一根木棒得到的递归分支返回失败的话,就可以直接判定当前分支失败,立即回溯,用反证法可以证得,因为在没插入这根木棍之前,对于我们接下来要安排得木棒都是等效的(每个都是空的),如果将这根木棍插入到当前木棒中不能得到合法解,插入到其他木棒能得到合法解,那就矛盾了
6)如果将木棍插入到当前木棒中的最后一个位置得到的分支不能得到一个合法解,那么当前分支就可以回溯了,因为如果将当前木棍放到其他木棒中能得到合法解的话,也就是说当前木棍用了其他木棍来代替,其他木棍的长度和当前木棍的长度一定是相同的,那么一样可以用当前木棍替换回去,同样能得到合法解,这就矛盾了
至此,所有的剪枝就完成了
代码如下:
- #include<iostream>
- #include<algorithm>
- #include<cstring>
-
- using namespace std;
-
- const int N=70;
-
- int n,length,sum;
- int a[N];
- bool st[N];
-
- //u表示安排到了第根木棍,且前u-1个木棍都已经安排好了
- //num表示当前第u根木棍的长度
- //last表示当前第u根木棍的最后一根木棍,这里其实是一个剪枝,排除等效冗余
- //因为选第1,3,2,和选第1,2,3是一样的效果,所以同一种情况我们就枚举一次就够了,这里以下标的顺序枚举,就能做到这个条件
- bool dfs(int u,int num,int last)
- {
- if(u*length==sum)return true;//意味着找到了一个合法的方案
- if(num==length)return dfs(u+1,0,0);//如果当前第u根木棍已经安排好了,就去安排下一根木棍
-
- for(int i=last;i<n;i++)//枚举last后面的数
- {
- if(st[i])continue;//如果已经安排过的木棒就不能再安排了
- if(num+a[i]>length)continue;//如果这根木棒不符合条件也不能安排,这里可以看成是可行性剪枝
-
- st[i]=true;//标记已经安排了
- if(dfs(u,num+a[i],i+1))//如果以这个分支能找到合法方案,就可以返回true
- return true;
- st[i]=false;//恢复现场
-
- //这里有两个剪枝,如果将这个木棍放在第u根木棒的第一个位置得到的分支是失败的方案,就可以回溯了
- //如果将这个木棍放在第u根木棒的最后一个位置得到的分支是失败的方案,也可以回溯了,继续搜索得到的方案也一定不是合法方案
- if(!num||num+a[i]==length)return false;
-
- int j=i;//如果当前木棍索得到得方案不是一个合法得方案,那就根它等长得木棍搜索得到得方案也一定不是一个合法方案
- while(j<n&&a[i]==a[j])j++;
- i=j-1;
- }
- return false;//所有分支都尝试过,搜索失败
- }
- int main()
- {
- while(cin>>n,n)
- {
- sum=0;
- memset(st,false,sizeof st);//因为是多组测试数据,每次需要初始化
- for(int i=0;i<n;i++)
- {
- cin>>a[i];
- sum+=a[i];//计算木棍得总和,这样能分得组的长度一定是总和的约数
- }
- sort(a,a+n,greater<int>());//将木棍冲大到小排序,与小猫爬山那题类似,这里可以看成是优化搜索顺序
- length=1;//从小到大枚举长度,第一次得到的合法解一定是最优解
- while(1)
- {
- if(sum%length==0&&dfs(0,0,0))//长度必须能整除总和
- break;
- length++;
- }
- cout<<length<<endl;//输出答案
- }
- return 0;
- }
4,生日蛋糕
题目链接:https://www.acwing.com/problem/content/description/170/
这题可以说是非常非常难了,思路极其难想,同样很多剪枝,正常我们的dfs思路是先枚举每一层的半径,再枚举每一层的高度,知道所有层的安排完,找到一个可行解,但是这样会超时,接下来看是如何剪枝的
1)我们可以确定每一层的半径r和高度h可枚举的范围,第u层的半径和高度最小一定是u,最大不能超过下一层的高度和体积,因为要满足高度和半径从上往下严格递增,其次,我们还要考虑体积,我们从下往上安排蛋糕,原因与小猫那题一样,已经安排好的蛋糕的体积记为v,那么剩下的没有安排好的体积就是n-v,根据体积公式n-v==(R^2)*H(这题不用考虑pi),那么可以得到半径的最大值就是sqrt(n-v),所以r的范围就是【u,min(R[u+1]-1,sqrt(n-v)】,同理得h得范围就是【u,min(H[u+1]-1,(n-v)/r/r】
2)优化搜索顺序,使用倒叙枚举,并且从最底层开始安排
3)可行性剪枝,预处理出来前m层得最小体积和最小面积,如果已经安排好得体积加上还没安排得最小体积都比给定得体积大,就不用继续搜索了,如果已经安排得面积加上还没安排得最小面积比之前搜索到得答案要大,就不用继续搜索了
4)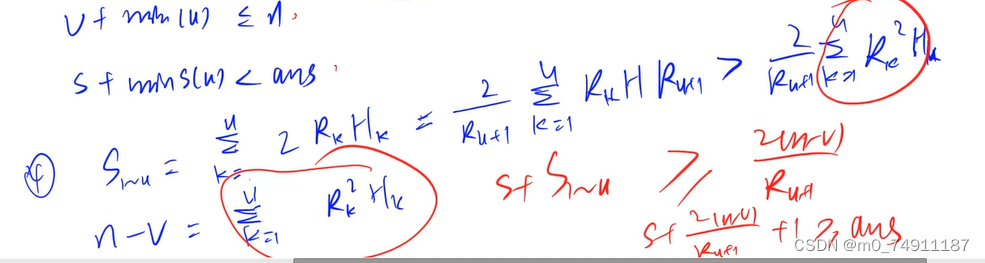
找到前u层得面积与体积得关系,可以帮助我们即时判断找到当前面积得情况能否继续搜索,这一点是最难想的,推导公式也很难想到
至此,所有剪枝就完成了
代码如下:
- #include<iostream>
- #include<algorithm>
- #include<cmath>
-
- using namespace std;
-
- const int N=30,INF=0x3f3f3f3f;
-
- int n,m;
- int R[N],H[N];//R表示每层的半径,r表示每层的高度
- int minv[N],mins[N];//minv表示前m层最小体积,mins表示前m层最小面积
- int ans=INF;//先将答案初始成最大值
-
- void dfs(int u,int v,int s)//u表示递归到第几层,v表示已经安排好的蛋糕的体积,s表示已经安排好的面积
- {
- //这个可以看成是可行性剪枝
- if(v+minv[u]>n)return;//如果当前已经安排好的面积加上没有安排的前u层的最小体积已经大于给定的体积了,就可以结束当前分支了
- //这两个可以看成是最优性剪枝
- if(s+mins[u]>=ans)return;//如果当前已经安排好的面积加上没有安排的前u层的最小面积大于之前找到的解,说明该方案一定不是最优解
- if(s+2*(n-v)/R[u+1]>=ans)return;//如果当前安排好的面积加上最已经安排好的面积的最小值还是比之前找到的解要大,就可以回溯了
-
- if(!u)//表示全部都层数都安排完了
- {
- if(v==n)//并且体积恰好等于给定的体积
- ans=s;//更新答案
- return;
- }
- for(int r=min(R[u+1]-1,(int)sqrt(n-v));r>=u;r--)//先枚举半径r,确定r的范围,从大到小枚举,优化搜索顺序
- {
- for(int h=min(H[u+1]-1,(n-v)/r/r);h>=u;h--)//枚举高度h,确定h的范围,从大到小枚举
- {
- int t=0;
- if(u==m)t=r*r;//最底下的那层蛋糕关系着蛋糕从上往下俯视的表面积
- R[u]=r,H[u]=h;//将当前层的半径和高度更新
- dfs(u-1,v+r*r*h,s+2*r*h+t); //继续向上一层安排
- }
- }
- }
- int main()
- {
- cin>>n>>m;
- for(int i=1;i<=m;i++)//预处理出来前m层的最小体积和侧面积,可行性剪枝
- {
- minv[i]=minv[i-1]+i*i*i;
- mins[i]=mins[i-1]+2*i*i;
- }
- R[m+1]=H[m+1]=INF;//防止边界问题,要在末尾加一个哨兵
- //从最后一层开始枚举,优化搜索顺序
- dfs(m,0,0);
- if(ans==INF)ans=0;//无解的情况
- cout<<ans;
- return 0;
- }
四,迭代加深
dfs搜索每次选定一个分支,不断深入,直至到达递归边界才回溯。这种策略带有一定的缺陷。试想以下情况:搜索树每个节点的分支数目非常多,并且问题的答案在某个较浅的节点上。如果深搜在一开始就选错 了分支,就很可能在不包含答案的深层子树上浪费许多时间。
所以我们可以从小到大限制搜索的深度,如果在当前深度的限制下搜索不到答案,就把深度限制增加,重新进行一次搜索,这就是迭代加深思想。所谓“迭代”,就是以上一次的结果为基础,重复执行以逼近答案的意思。
虽然该过程在深度限制为d时,会重复搜索第1~d-1层的节点,但是当搜索树节点分支数目较多时,随着层数的深入,每层节点数会呈指数级增长,这点重复搜索与深层子树的规模相比,实在是小巫见大巫了。
1,加成序列
题目链接:https://www.acwing.com/problem/content/172/
这题是理解迭代加深很好的一个题目,我们以搜索层数为1时开始搜索,也就是相当于看序列长度为1是否能找到答案,不能就看序列长度为能否找到答案,直至找到答案为止。同时这题还有一个性质,那就是,要想序列最短,那每个数都必须是前一个数与序列的另一个数(包括前一个数)的和,如果不是的话,那么我们就可以把当前数的前一个数从序列中删除,同样可以得到我们的最优解
代码如下:
- #include<iostream>
- #include<algorithm>
- #include<cstring>
-
- using namespace std;
-
- const int N=110;
-
- int n;
- int path[N];
-
- bool dfs(int u,int depth)//u表示安排到第几位,depth表示可以搜索的深度
- {
- if(u>depth)return false;//如果安排的位置比可以搜索的深度还大,返回false,需要继续扩展搜索深度
- if(path[u-1]==n)return true;//说明找到了合法方案
-
-
- //当前这个位置的数一定是由上一个数与序列中的另一个数(包括上一个数)相加得到
- //可以用反正法证明,如果当前数不是由上一个数与序列的另一个数得到的话,那就可以将序列中的上一个数删掉,得到更短的合法序列
- for(int j=u-1;j>=0;j--)
- {
- int s=path[u-1]+path[j];
- if(s>n||s<path[u-1])continue;//判断这个数放在这个位置是否合法
-
- path[u]=s;//将这个数放到当前位置上
- if(dfs(u+1,depth))return true;//表示当前位置填这个数能得到一个合法方案
-
- }
- return false;//表示全部分支都不能得到一个合法方案
- }
- int main()
- {
- path[0]=1;
- while(cin>>n,n)
- {
- int depth=1;//迭代加深,看当前层数是否能找到答案
- while(!dfs(1,depth))depth++;//如果不能找到答案,就扩展搜索范围
- for(int i=0;i<depth;i++)
- cout<<path[i]<<" ";//输出答案
- cout<<endl;
- }
- return 0;
- }
五,双向DFS
1,送礼物
题目链接:https://www.acwing.com/problem/content/173/
这题初看很像背包问题,但看一下数据范围,就发现不能用背包来做,接着我们看物品的数量最多只有46个,因此我们可以用暴搜来做这个题,如果暴搜的话,我们的时间复杂度是O(2^N)N最大可以到46,所以是非常大的一个时间复杂度,因此我们要想一下怎么优化
我们可以用双向搜索的方式来优化,把礼物分成两半。首先,我们搜索出来从前半段中的礼物,重量总和在0~m的所有可能,存在一个数组A中,并对A去重排序。
然后我们进行第二次搜索,尝试从后一半礼物中选出一些。对于每个可能达到的重量t,在前半段中所有0~m的所有重量总和的可能中二分查找出来小于等于w-t的数值中最大的一个,用二者的和更新答案。
这个算法的时间复杂度就只有O(2^N+2^N*log(N/2))了。同时结合前面讲到的剪枝,我们可以优化搜索顺序,将所有的物品从大到小排序,先选择大的数,留给我们能选择的数就会比较少,分支就会比较少,因此搜索的效率会更高一点
代码如下:
- #include<iostream>
- #include<algorithm>
-
- using namespace std;
-
- typedef long long ll;//这题可能会爆int
- const int N=50;
-
- ll n,m,k;
- ll w[N],weight[1<<25];//weight中存储的数可能很多
- ll ans,cnt;
-
- void dfs(ll u,ll s)//先搜前半段的数
- {
- if(u==k)
- {
- weight[cnt++]=s;//表示前半段全部搜索完了,就把可以凑出来的和都放进一个数组中
- return;
- }
- dfs(u+1,s);//表示不选第u个数
- if(s+w[u]<=m)dfs(u+1,s+w[u]);//这里有一个可行性剪枝,如果这个数加了之后小于m,我们才加这个数,否则加了也没意义
- }
- void dfs1(ll u,ll s)//去后半段搜索,每搜到一个数就去前半段凑出来的数中,找一个数加上当前数是小于m的最大的那个数
- {
- if(u==n)
- {
- int l=0,r=cnt-1;
- while(l<r)//二分在前半段搜索
- {
- int mid=l+r+1>>1;
- if(weight[mid]<=m-s)l=mid;
- else r=mid-1;
- }
- ans=max(ans,weight[l]+s);//看是否能更新最大值
- return;
- }
- dfs1(u+1,s);//表示不选第u个数
- if(s+w[u]<=m)dfs1(u+1,s+w[u]);//这里也是一个可行性剪枝,跟上面一样
- }
- int main()
- {
- cin>>m>>n;
- for(int i=0;i<n;i++)cin>>w[i];
- sort(w,w+n,greater<int>());//优化搜索顺序,从大到小排序,从大到小搜索
-
- k=n/2;//分成两半搜索
- dfs(0,0);//先搜前半段
-
- sort(weight,weight+cnt);//前半段能凑出来的和从小到大排序,方便我们查找
- cnt=unique(weight,weight+cnt)-weight;//去重,减少搜索次数
-
- dfs1(k,0);//搜索后半段
- cout<<ans;
- return 0;
- }
六,IDA*
之前讲到的A*算法本质上是带有估价函数的优先队列BFS算法。故A*算法有一个显而易见的缺点,就是需要维护一个二叉堆来存储状态及其估价,耗费空间大,并且对堆进行一次操作也要花费O((logN)的时间。
IDA*算法与A*算法一样,都有估价函数,A*算法是估价函数与BFS算法结合,IDA*算法是估价函数与DFS结合。但是DFS也有一个缺点,就是一旦估价出现失误,容易向下递归深入一个不能产生最优解的分支,浪费许多时间。
综上,我们将估价函数与迭代加深的DFS算法相结合。我们设计一个估价函数,估算从每个状态到目标状态需要的步数。当然,与A*算法一样,估价函数需要遵守“估计值不大于未来实际步数”的准则。然后,以迭代加深DFS的搜索框架为基础,把原来简单的深度限制加强为:若当前深度+未来估计步数>深度限制,则立即从当前分支回溯、这就是IDA*算法
1,排书
题目链接:https://www.acwing.com/problem/content/182/
这题如果暴搜的话时间复杂度是很高的,我们先来估算一下每个状态的分支数量。在每个状态下,我们可以抽取连续的一段书,移动到另一个位置。对于任意整数i,当抽取长度为i时,有n-i+1种选择方式,有n-i个可插入的位置(减去了一个自身所在的位置)。另外,把一段书移动到更靠前的某个位置,等价于把“跳过”的那段书移动到靠后的某个位置,所以上面的计算方法把每种移动情况算了两遍,每个状态的分支数量约为(15*14+14*13+……+2*1)/2=560
根据题目要求,我们只要考虑在4次操作以内是否能实现目标,也就是我们只需要考虑搜索树的前4层,4层的搜索树的规模能够达到560^4,会超时。
所以这题我们可以用双向BFS或者IDA*。这里讲一下如何用IDA*来解,在目标状态下,第i本书后边应该是第i+1本书,我们称i+1是i的正确后继。对于任意状态,考虑整个排列中书的错误后继的总个数(记为tot),可以发现每次操作至多更改3本书的后继。即使在最理想的情况下,每次操作都把某3个错误后继全部改对,消除所有错误后继的操作次数也至少需要【tot/3】(其中【】表示上取整)次。
因此,我们把一个状态s的估价函数设计为f(s)=【tot/3】,其中tot表示在状态s下书的错误后继总数。同时结合迭代加深的方法求解
代码如下:
- #include<iostream>
- #include<algorithm>
- #include<cstring>
-
- using namespace std;
-
- const int N=15;
-
- int n,depth;
- int a[N];
-
- int f()//估价函数,计算这个序列的不合法后继有多少个
- {
- int tot=0;
- for(int i=0;i<n-1;i++)
- if(a[i+1]!=a[i]+1)
- tot++;
- return (tot+2)/3;//等价除3上取整
- }
- bool dfs(int depth,int max_depth)//当前深度与最大深度
- {
- if(depth+f()>max_depth)return false;//如果当前深度加上估计的深度比我们给定的最大深度要大,就可以直接回溯了
- if(f()==0)return true;//表示没有不合法的后继,已经排好序了
-
- for(int len=1;len<=n;len++)//枚举我们选择的子序列长度
- {
- for(int l=0;l+len-1<n;l++)//枚举起点
- {
- int r=l+len-1;//表示起点加长度的某位置
- for(int k=r+1;k<n;k++)//将这个子序列放到它的后面的某一个位置,不往前放是因为这个子序列往后放等价于与它交换的那莪序列往前放了
- {
- int w[N];//临时存储当前序列,因为每次要在序列上操作,后面要恢复现场
- memcpy(w,a,sizeof a);
- int y=l;//表示交换的位置
- for(int x=r+1;x<=k;x++,y++)a[y]=w[x];//先把要交换的那一段移到前面来
- for(int x=l;x<=r;x++,y++)a[y]=w[x];//再把交换的这段移到后面去
- if(dfs(depth+1,max_depth))return true;//继续搜索,如果当前分支能得到一个合法解,就返回true
- memcpy(a,w,sizeof w);//恢复现场
- }
- }
- }
- return false;//表示所有分支都不能得到一个合法解
- }
- int main()
- {
- int t;
- scanf("%d",&t);
- while(t--)
- {
- scanf("%d",&n);
- for(int i=0;i<n;i++)scanf("%d",&a[i]);
- depth=0;//迭代加深
- while(depth<5&&!dfs(0,depth))depth++;//depth<5的这个条件要放到前面,先判断,否则会都搜索一次depth=5的情况
- if(depth<5)
- printf("%d\n",depth);
- else
- printf("5 or more\n");
- }
- return 0;
- }
2,回转游戏
题目链接:https://www.acwing.com/problem/content/description/183/
我们用IDA*来求解,首先从上到下,从左到右依次给棋盘上的每个格子编号,接着对于每个操作会影响到的格子记录下来,便于后续操作,同时有一个剪枝,我们记录下来上一次操作,如果当前操作等于上一次的逆操作,我们就没有必要进行当前操作,避免来回搜索。
接下来我们设计估价函数,我们发现,每一次操作最多改变中间八个格子的其中一个格子的状态,那么我们记录下来当前八个格子中出现次数最多的那个数,就可以知道最少需要几步能使得八个格子相同,我们以整个最小操作数作为估价函数,再结合迭代加深求解
代码如下:
- #include<iostream>
- #include<algorithm>
- #include<cstring>
-
- using namespace std;
-
- const int N=24;
-
- int q[N];
- int op[8][7]={//给棋盘上的个子从上到下,从左到右编号,记录每一个操作会影响到的编号
- {0, 2, 6, 11, 15, 20, 22},//A操作
- {1, 3, 8, 12, 17, 21, 23},//B操作
- {10, 9, 8, 7, 6, 5, 4},//C操作
- {19, 18, 17, 16, 15, 14, 13},//D操作
- {23, 21, 17, 12, 8, 3, 1},//E操作
- {22, 20, 15, 11, 6, 2, 0},//F操作
- {13, 14, 15, 16, 17, 18, 19},//G操作
- {4, 5, 6, 7, 8, 9, 10}//H操作
- };
- int center[8] = {6, 7, 8, 11, 12, 15, 16, 17};//记录中心八个格子的编号
- int opposite[8] = {5, 4, 7, 6, 1, 0, 3, 2};//记录每个操作的逆操作的编号,方便我们回溯,回溯时对于每个操作的逆操作操作一遍就可以了
- int path[100];
-
- int f()//设计估价函数,记录中间八个格子出现次数最多的数的数量,返回最少还需要几步操作能使得中间的八个格子的数字全部相同
- {
- int cnt=0,sum[4];//sun记录每个数出现的次数
- memset(sum,0,sizeof sum);
- for(int i=0;i<8;i++)sum[q[center[i]]]++;
- for(int i=1;i<=3;i++)cnt=max(cnt,sum[i]);
- return 8-cnt;//返回最少还需要几步操作能使得中间的八个格子的数字全部相同
- }
- void operation(int x)//每次进行的操作
- {
- int t=q[op[x][0]];
- for(int i=0;i<6;i++)q[op[x][i]]=q[op[x][i+1]];
- q[op[x][6]]=t;
- }
- bool dfs(int depth,int max_depth,int last)//depth表示当前深度,也可以说是我们的操作步数到第几步了,max_depth表示我们迭代加深的最大深度
- { //last记录上一次操作
- if(depth+f()>max_depth)return false;//如果当前操作步数加上预估最小步数还是比我们迭代加深的最大步数要大的话,就可以直接回溯了
- if(f()==0)return true;//表示八个格子的数字都一样了
-
- for(int i=0;i<8;i++)//八个操作
- {
- if(opposite[i]==last)continue;//如果我们接下里要进行的操作等于上一次操作的逆操作,就没有必要进行这一步操作
- operation(i);//操作
- path[depth]=i;//将当前操作记录下来
- if(dfs(depth+1,max_depth,i))return true;//如果当前分支能得到一个合法解,就返回答案
- operation(opposite[i]);//进行当前操作的逆操作,恢复现场
- }
- return false;//全部操作都不能得到一个合法解
- }
- int main()
- {
- while(cin>>q[0],q[0])
- {
- for(int i=1;i<N;i++)cin>>q[i];
- int depth=0;
- while(!dfs(0,depth,-1))depth++;//迭代加深
- if(!depth)
- cout<<"No moves needed"<<endl;
- else
- {
- for(int i=0;i<depth;i++)
- printf("%c",path[i]+'A');
- cout<<endl;
- }
- cout<<q[6]<<endl;
- }
- return 0;
- }

