
热门标签
热门文章
- 1IDE工具(47) 解决idea升级之后git密码记不住问题_idea git密码保存位置
- 2DialogFragment 不可取消和点击外部不消失_getdialog().setcanceledontouchoutside不起作用
- 3企业远程控制如何保障安全?向日葵“全流程安全远控闭环”解析
- 4「一本通 1.1 例 4」加工生产调度(典型例题,值得一看)_某工厂收到 n 个订单(ai,bi),
- 5git 代码提交错误,回滚到指定的远程版本_git 回滚远程节点
- 6K最近邻算法:简单高效的分类和回归方法_最近邻回归
- 7合合信息:TextIn文档解析技术与高精度文本向量化模型再加速_支持文本文档解析模型
- 8基于SpringBoot+Vue的社区助老志愿者服务平台的详细设计和实现(源码+lw+部署文档+讲解等)_基于springboot的社区助老志愿者服务平台
- 9基于AI的智能聊天机器人ChatTTS,自然语言处理和机器学习技术的完美结合!_基于tts的智能聊天机器人
- 10【大模型本地知识库搭建】ChatGLM3,M3E,FastGPT,One-API_m3e本地部署
当前位置: article > 正文
19 使用MapReduce编程统计超市1月商品被购买的次数_使用mapreduce编程统计某超市1月商品被购买的次数
作者:小桥流水78 | 2024-07-02 22:10:49
赞
踩
使用mapreduce编程统计某超市1月商品被购买的次数
首先将1月份的订单数据上传到HDFS上,订单数据格式 UserID, GoodName两个数据字段构成

将订单数据保存在order.txt中,(上传前记得启动集群)。

打开Idea创建项目

修改pom.xml,添加依赖
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.4</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>

指定打包方式:jar

打包时插件的配置:
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
</execution>
</executions>
</plugin>
</plugins>
</build>

在resources目录下新建log4j文件log4j.properties
log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n log4j.appender.logfile=org.apache.log4j.FileAppender log4j.appender.logfile.File=D:\\ordercount.log log4j.appender.logfile.layout=org.apache.log4j.PatternLayout log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n

在com.maidu.ordercount包中创建一个新类ShoppingOrderCount类,编写以下模块
1.Mapper模块的编写
在ShoppingOrderCount中定义一个内部类MyMapper
public static class MyMap extends Mapper<Object,Text, Text, IntWritable>{
@Override
public void map(Object key,Text value,Context context) throws IOException ,InterruptedException {
String line =value.toString();
String[] arr =line.split(" "); //3 水果 水果作为键 值 1(数量1 不是 3 表示用户编号)
if(arr.length==2){
context.write( new Text(arr[1]),new IntWritable(1) );
}
}
}

2.Reducer模块的编写
在ShoppingOrderCount中定义一个内部类MyReduce
public static class MyReduce extends Reducer<Text,IntWritable,Text,IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count =0;
for(IntWritable val:values){
count++;
}
context.write(key,new IntWritable(count));
}
}

3.Driver模块的编写
在ShoppingOrderCount类中编写主方法
public static void main(String[] args) throws Exception{
Configuration conf =new Configuration();
String []otherArgs =new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length<2){
System.out.println("必须输入读取文件路径和输出文件路径");
System.exit(2);
}
Job job = Job.getInstance(conf,"order count");
job.setJarByClass(ShoppingOrderCount.class);
job.setMapperClass(MyMap.class);
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//添加输入的路径
for(int i =0;i<otherArgs.length-1;i++){
FileInputFormat.addInputPath(job,new Path(otherArgs[i]));
}
//设置输出路径
FileOutputFormat.setOutputPath(job,new Path(otherArgs[otherArgs.length-1]));
//执行任务
System.exit( job.waitForCompletion(true)?0:1 );
}

4.使用Maven编译打包,将项目打包为jar

从上往下,四步走,最终target下会生产jar文件

5.将orderCount-1.0-SNAPSHOT.jar拷贝上传到master主机上。

6.执行Jar
[yt@master ~]$ hadoop jar orderCount-1.0-SNAPSHOT.jar com.maidu.ordercount.ShoppingOrderCount /bigdata/order.txt /output-2301-02/

7.执行后查看结果
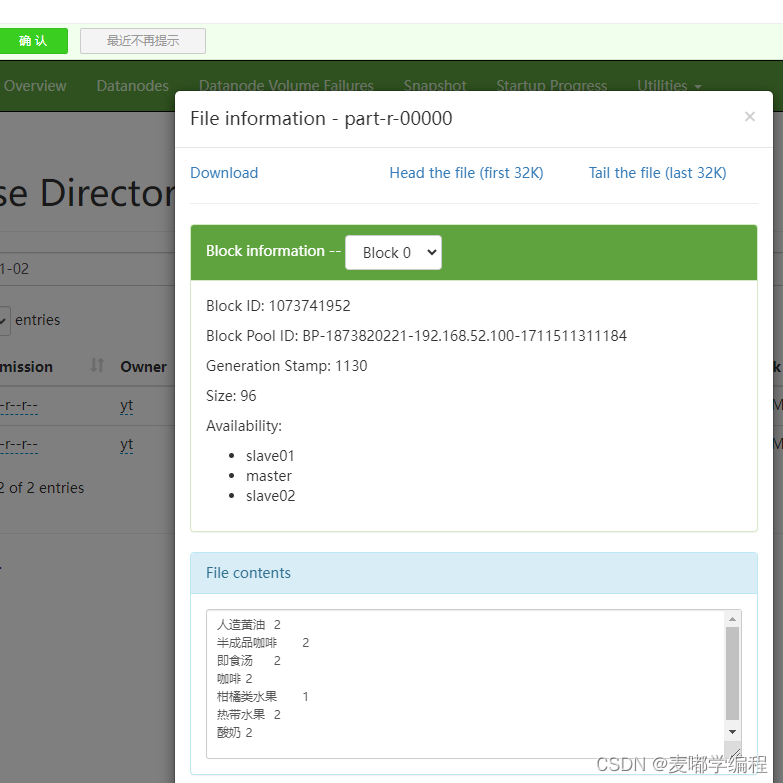
备注:如果运行出现虚拟内存不够,请参考:is running 261401088B beyond the ‘VIRTUAL‘ memory limit. Current usage: 171.0 MB of 1 GB physical-CSDN博客
推荐阅读
相关标签

