
- 1Vue项目中代码规范(Prettier + ESLint)_vue代码格式化插件
- 2Docker学习-04-容器管理工具 Docker架构及部署_docker管理器
- 31024与自己做爱做的事情
- 4计算机视觉方面的三大顶级会议:ICCV,CVPR,ECCV(统称ICE)
- 5Spring-Boot (二) application.properties配置文件内容_springboot中application配置内容
- 6贝塞尔曲线曲面原理及推导过程_贝塞尔曲面
- 7完美解决MSSQL安装问题“Polybase要求安装Oracle JRE 7更新51(64位)”方案
- 8CNN 模型所需的计算力(FLOPs)和参数(parameters)_3d-cnn作为预测模型需要确定那些模型参数
- 9解决安装Fiddler后无法上网的问题_安装fiddler后电脑无法上网
- 10【干货】requests的使用方法_requests.mount
AI大模型-关于推理、可解释性和 LLMs_ai 推理模型
赞
踩
引言:以下文章的主题我已经思考了很久,我希望能我的话能引起你的思考,并于一些更悲观的AI评论相均衡。推理和可解释性是充满细微差别的主题——我希望这篇文章能体现这一点。
去年 GPT-4 发布时,我注意到出现了一个特殊的议论:“可解释的人工智能”。 GPT-4 是第一个在推理领域显示出真正进步的人工智能模型。对于我们中的一些人来说,这是令人兴奋的,但它也威胁到了一些依靠更传统的决策技术谋生的人。可解释性一直被认为是采用 GPT-4 等模型的障碍。
在某些领域,例如医疗保健或金融服务,解释为什么做出特定决定尤其重要。因此,我们需要理解为什么人工智能会做出这些决定,因此需要可解释的人工智能。
在回答这个问题之前,值得花一些时间考虑一下LLM是如何工作的以及它是如何能够做出决策的。
LLM通过预测序列中最有可能出现的下一个标记来工作。因此,当我询问“谁是美国的总统?”时,模型不会执行某种形式的结构化推理和数据库查找来找到乔·拜登的名字。相反,它从训练数据中知道,拜登是一个在输入“谁是美国的总统?”后能够产生的统计上可能的标记序列。LLM已经阅读了非常大量的文本(这就是LLM中的第一个L),这意味着它能够对各种各样的输入进行这种预测。
对于LLM的批评者可能会在此打断,并指出这样的模型没有任何有意义的推理能力。他们还可能说它是不可“解释”的,因为其答案来自一个庞大的统计机器。要解释模型为什么给出了乔·拜登这个答案,就需要理解模型中数十亿个参数的情况——这显然对任何人来说是不切实际和不可能的。
然而,在这一点上结束讨论将是一个错误,也是对LLM实际代表的内容的故意忽视。
让我们稍微离题,进入科学的世界吧……
在科学世界中,对于如何研究和理解系统的属性有两种解释。第一种是还原论,通过检查复杂系统的组成部分来解释它。因此,还原论者认为世界只是原子、分子、化学反应和物理相互作用等构件行为的延伸。如果您了解基础知识,那么其他一切都只是其更大的版本。
还原论是我们大多数人思考大多数事情的方式——这是思考复杂系统的一种非常合乎逻辑的方式,也是人类思维的默认方式。
还原主义者对LLM的分析仅仅将其视为预测最有可能的下一个标记的能力。根据定义,LLM无法进行推理,任何表明它们可以推理的证据只是由于大规模训练集而带来的幻觉。这只是一种花俏的把戏。
然而,当我看待LLM时,我对还原主义的观点并不完全认同。对我来说,它不能完全解释我们所看到的一些现象。
然而,还原主义并不是分析复杂系统的唯一方法。事实上,还原主义无法解释科学的大部分内容以及我们对世界的实际体验。
以盐为例,我们都知道它是钠和氯原子 (NaCl) 的组合。钠是一种与水发生爆炸反应的金属,而氯化物是一种有毒气体。然而,当我们将它们结合起来时,我们得到了具有独特味道的可食用晶体结构。据我所知,盐在遇到水时并不具有爆炸性,而且盐的毒性也不是特别大。还原主义无法解释为什么盐在性质上与其组成部分为何如此不同。研究钠或氯化物的性质并不能告诉我们有关盐的任何信息。
为了理解盐,我们需要一种不同的思维方式。这种不同的方式被称为" Emergence"(涌现)。
随着复杂系统变得越来越复杂,它们经常具有我们无法通过观察其组成部分来预测的属性和行为,这正是Emergence 预测。正如维基百科上关于这个主题的文章中解释的那样:
“在哲学、系统论、科学和艺术中,当一个复杂实体具有其组成部分本身没有的属性或行为,并且这些属性或行为只有在更广泛的整体中相互作用时才出现时,就发生了 Emergence。 Emergence 在整合等级理论和复杂系统理论中扮演着核心角色。例如,在生物学中研究的生命现象是化学和量子物理的 emergent 特性。“
在我看来,最后一句话很重要。 “生命现象……是化学和量子物理学的一个emergent 特性。”确实如此。如果我们只研究人体的化学成分,我们很难预测到智慧生命的存在。
“Emergence(涌现)”的概念源于诺贝尔物理学奖获得者菲利普·安德森(与我无关)1972年发表的一篇题为“[More Is Different](更多即不同)”的论文。
“事实证明,大型和复杂的基本粒子聚集物的行为不能通过简单推断少数粒子的性质来理解。相反,在每个复杂级别上,都会出现全新的属性……”
最近《新科学家》杂志的一篇文章《Emergence(涌现):掌握意识钥匙的神秘概念》就是一个很好的例子。
“下次你被大雨淋湿时,不要只考虑自己有多湿,而是考虑你为什么变湿。毕竟,雨水只是由氢和氧原子组成的分子,而这些原子本身并没有什么湿的特性。甚至一个单独的水分子也没有湿的特性。但将它们放在适当条件下大量结合,你就会感到湿润。水的湿润是"emergent"属性的一个例子:这种现象无法用某种东西的基本属性来解释,只有当这些部分非常多时才会显现。”
如果我们将Emergence (涌现)应用于LLMs,模型进行推理的能力就变得不那么令人惊讶了。这只是一种Emergence (涌现)能力,我们无法仅仅通过思考下一个标记的预测来预测它。
当我读到研究论文“大型语言模型的Emergence 能力”时,我第一次注意到LLMs中的Emergence (涌现)概念。
“本文……讨论了一种不可预测的现象,我们称之为大型语言模型的Emergence (涌现)能力。如果一种能力不存在于较小的模型中但存在于较大的模型中,则我们认为该能力是Emergence (涌现)的。因此,Emergence 能力不能简单地通过推断较小模型的性能来预测。”
该文章介绍了作者们发现的四种 emergent 能力:多步推理、遵循指令、程序执行和模型校准。
让我们以其中一种emergent能力为例:多步推理。
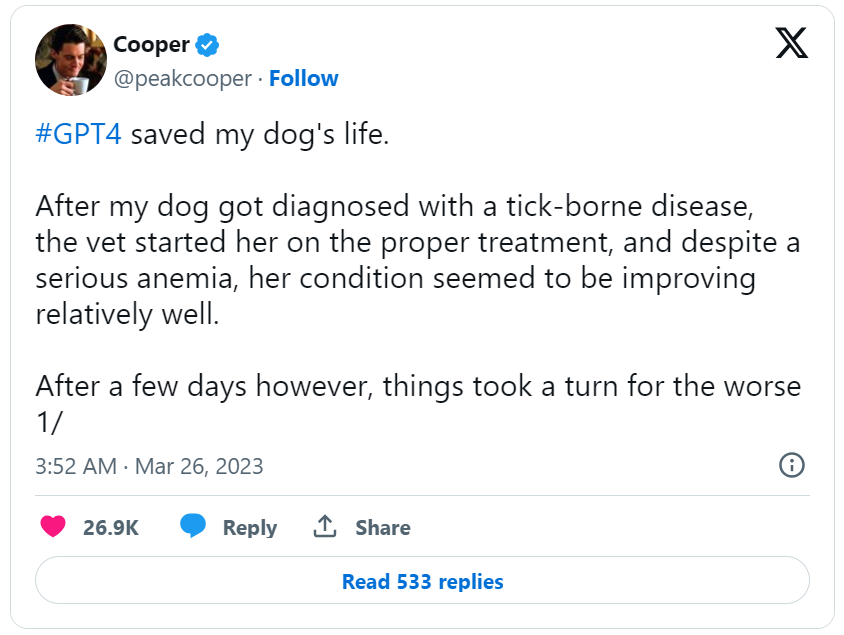
这位 GPT-4 用户将狗的症状和血液检测结果输入 GPT-4,并询问 “我家狗得了什么病?”。LLM 不仅能够预测下一个可能的标记,还可以通过多步推理来分析症状和血液测试结果,并提供一个潜在的诊断。然后 GPT-4 正确识别了狗的疾病,这是兽医无法做到的。
这种能力是 emergent 的,因为在较小的模型中,LLM 可能无法进行这种复杂的推理,但在更大的模型中,它出现了。
这些 emergent 能力的存在表明,LLM 在某种程度上展示了一些形式的推理和理解的迹象。虽然我们不能完全理解它是如何达到这些能力的,但 Emergence 理论告诉我们,有时候我们不必详细了解系统的每个组成部分,以便理解其整体行为。
所以,当我们谈论 LLM 时,我们应该意识到它不仅仅是一个预测机器,而是一个具有 emergent 能力的复杂系统。这给我们带来了探索和理解人工智能的新途径,也让我们反思和重新评估我们对智能和理解的定义。
这是prompt的一部分。


GPT-4能够理解这一点,并将血液检测结果与后续的结果进行比较,以确定可能存在的问题,这似乎不能仅仅通过“它只是输出最有可能的标记序列”来解释。感觉好像还有其他更复杂的情况发生了——一种emergent 的能力。
生病的狗只是众多实际客户情况中的一个例子。我有多个真实的客户案例,都使用LLM作为推理器。这感觉很奇怪,但令我感到欣慰的是,科学为我们提供了一个有助于解释它的参考点。也许它不应该让我们如此惊讶。
让我们来考虑和对比一下LLM是如何进行推理的,以及其他技术是如何进行推理的。
如果我想让一个基于规则的非人工智能系统来执行某种形式的推理,我必须定义一组硬编码规则来体现系统应该如何运行。如果情况很复杂,这些规则定义很快就会变得迷宫般,从而容易出现人为错误。换句话说,最终的系统有时可能会产生错误的答案,不是因为它本身容易出错,而是因为它的人类程序员很难用系统的“语言”来编码要遵循的规则。
相比之下,LLM并不需要任何形式的规则,而是通过自然语言训练材料和提示来指导其推理。推理的定义通常不太精确,因为它们是自然的人类语言,经常包含歧义。然而,我们完全可以以更正式的方式提示LLM - 例如,它们非常擅长理解计算机代码。
LLM以一种规则系统无法做到的方式对事物进行推理 - 它们能够理解并考虑到现实生活中的随机性。聊天机器人革命的第一个版本(V-1)受到了广泛批评,正是因为它们基于规则的定义无法适应必然出现的现实生活中独特的情况。“计算机说不行”并不符合人们对人工智能的期望。
如今,LLMs往往比我们想象的更容易犯错,但它们也更能够适应现实生活。当运行核电站时,这不是您想要的一组属性,但在很多其他情况下,这是非常有用的。
无论是人工智能还是基于规则的系统,它们都有可能出现错误,但原因不同。其中一个本质上是可错的,而另一个往往因为复杂性足够大,导致人类在构建时出现错误。为了提供一些背景,我朋友Chris Williams在Databricks最近写道:
“我们已经有了在业务流程中需要管理的不可预测因素,我们必须对其进行管理,它们就是人。”
LLM的推理能力感觉很奇怪,但也许它与我们的推理能力并没有那么遥远——两者都只能通过涌现来真正解释。
如今,LLMs不仅可以对相对简单的事物进行推理,而且多步骤的推理已经成为现实 - 我构建了一个宽带故障排除应用程序,它可以跨多个步骤按照自然语言的过程进行操作。如果用户偏离了预期流程,它也能保持对话,并温和地引导他们回到预期的流程中。
LLM技术正在以极快的速度改进,不久的将来,我们将会看到LLMs被用于更复杂的场景- 执行完整的业务流程并就诸如税务计算之类的复杂主题提供建议。当针对特定领域进行训练,比如医学,LLMs已经开始挑战人类准确性水平。最近的一篇论文显示,LLM 的表现超过了独立的临床医生。
另一篇论文对当今LLM在临床决策中的角色提出了惊人的结论。
“虽然没有真正的基准存在,但我们估计这种表现达到了刚从医学院毕业的水平,比如实习生或住院医师。这告诉我们,总体上,LLM有潜力成为医学实践的增强工具,并以令人印象深刻的准确性支持临床决策。”
当然,医学是一个特别敏感的话题,存在许多伦理困境以及各种不同的观点。尽管如此,LLMs 在其进化的早期就被认真考虑在临床中的潜在作用,这是值得注意的。
那么,如果LLM的推理能力成立,我们如何解决其可解释性问题或缺乏可解释性的情况?
传统系统中的可解释性是因为我们可以回溯到编码的规则,按照一条路径进行推导,并确定为什么会得出特定的答案。这可能并不太有趣,但对于善于观察细节的人来说,这是完全可能的。这种能力提供了一定程度的信心,即“系统按照设计工作”。当然,设计可能是错误的,或者团队甚至可能没有正确理解设计的需求,但“按照设计工作”在商业领域是很熟悉的,适用于合同和法律责任。这是自计算机技术诞生以来IT领域一直采用的方式。
相比之下,LLMs中的可解释性非常不同。没有明确的规则可供追踪,并且构成LLM的巨大统计模型并不是人类可以打开来追踪特定答案是如何得出的。然而,这并不意味着可解释性不存在。事实上,它确实存在,但形式却截然不同。
这就是LLM中可解释性的工作方式:我只需要求机器做出决策并解释其推理过程。这正是我向人类提问时所做的。人类被认为是可解释的,因此我认为LLM也是可解释的。
以GPT-4为例,考虑以下交互过程:
问:1 公斤羽毛和 0.5 公斤钢哪个更重?请解释您的推理以及这与两种材料的性质有何关系。
答:1公斤羽毛的重量超过0.5公斤钢材。
原因很简单:物体的重量是作用在其上的重力的量度,而该力与物体的质量成正比。
由于 1 公斤的质量是 0.5 公斤的两倍,因此无论材料的性质如何,1 公斤的羽毛都会比 0.5 公斤的钢重。
然而,这两种材料之间的重量差异也凸显了它们性质的一个有趣的方面:密度。密度是每单位体积物质的质量。
钢比羽毛密度大得多,这意味着给定体积的钢比相同体积的羽毛重得多。因此,虽然 1 公斤的羽毛由于质量较大而重量更重,但它所占的体积却比 0.5 公斤的钢大得多。这种密度差异就是为什么钢材等材料因其强度和紧凑性而被用于建筑和机械,而羽毛则用于需要轻便和绝缘的应用。
GPT-4对其推理的解释详细且有条理。事实上,它比大多数人提供的解释更加详细、更有条理。比试图编码物理定律的复杂规则集相比,它也更容易理解。
在我们以还原主义思维模式思考时,LLM可能确实是“黑盒子”。然而,当我们接受 Emergence(涌现)时,它们却是我们迄今为止最容易解释的IT系统。
据传 OpenAI 有一个名为 Q* 的项目,据称该项目在教授语言模型如何做数学方面取得了突破。我们现在所说的是传闻和推测,请耐心等待…但无论OpenAI是否实现了所谓的突破,我认为这是一个重要的途径。
我们往往认为数学是完全基于理论的典型学科。很少有人会认为数学家除了通过扎实的基础知识之外,还可以通过其他任何方式获得技能,而其他一切都是建立在基础知识的基础上的。这是非常还原主义的观点。
逻辑上讲,要教机器做数学就需要它对数学原理有所理解。然而,我们大多数人通过反复背诵来学习乘法口诀表。我们知道7乘以6等于42,并不是通过其他方式,而是反复记忆7乘以6等于42,直到我们能够熟记于心。当我们在学校举手回答42时,并不是在脑子里进行计算,而是回忆我们的训练数据。
这听起来是不是有点熟悉?
最后的想法
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
-END-

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

