
- 1常用python代码大全-python使用csv模块进行CSV文件操作_csv文件读取的逐行处理
- 2华安泰2014摄影作品征集:盛夏里的青春_盛夏照片的命名
- 3Android屏幕适配 px,dp,dpi及density的关系与深入理解(转载)_android dpi
- 4Android黑白照片上色APP,黑白图片上色工具
- 5【AI从入门到入土系列教程】Ollama教程——进阶篇:【兼容OpenAI的API】高效利用兼容OpenAI的API进行AI项目开发_ollama openai
- 6dify-on-wechat中涉及企业微信几个函数解析_dify集成企业微信
- 7超详细的NLP实战案例解析——使用前馈神经网络进行姓氏分类_用nlp分析身份、
- 8现代IC/LSI工艺PCB封装大全
- 9一文学会Open5GS和UERANSIM安装及使用
- 10暑期大数据人工智能企业项目试岗实训班
机器学习之决策树(ID3算法)_决策树id3
赞
踩
一、决策树简介
决策树(Decision Tree)是一种常见的机器学习算法,用于分类和回归任务。它通过对数据集进行反复的二分划分,构建一棵树状结构,每个非叶节点代表一个特征属性上的决策,每个叶节点代表一个类别标签或回归值。
1.决策树的构建过程:
a. 选择划分特征:从所有特征中选择最佳的划分特征,通常是根据某种指标(例如信息增益)选择能够最好地将数据集分开的特征。
b. 划分数据集:根据选择的特征将数据集划分为若干个子集,每个子集包含具有相似特征的样本。
c. 递归构建子树:对每个子集递归地应用上述步骤,构建子树,直到满足停止条件,例如节点中的样本属于同一类别或达到树的最大深度。
d. 生成决策树:构建完所有子树后,将它们连接起来形成一棵完整的决策树。
2.决策树的应用场景:
- 分类问题:例如根据患者的一些特征来判断是否患有某种疾病。
- 回归问题:例如根据房屋的一些特征来预测房价。
- 特征选择:决策树可以用于特征选择,帮助识别对任务最有影响力的特征。
3.决策树的优点:
- 简单易于理解和解释,可视化效果好。
- 可以处理数值型数据和分类数据。
- 能够在相对较短的时间内对大型数据集进行训练。
4.决策树的缺点:
- 容易出现过拟合问题,特别是对于复杂的数据集。
- 对数据中的噪声非常敏感。
- 不稳定性,数据的小变化可能会导致完全不同的树结构。
决策树算法的改进版本包括随机森林(Random Forest)、梯度提升树(Gradient Boosting Tree)等,用于解决决策树的过拟合和不稳定性问题。
二、决策树原理
决策树的原理基于树形结构进行决策,每个非叶节点代表一个特征属性上的决策,每个叶节点代表一个类别标签或回归值。其主要原理包括特征选择、树的构建和剪枝。
1. 特征选择:
决策树的关键在于选择最优的特征来进行数据集的划分,常用的特征选择指标包括信息增益、信息增益比、基尼不纯度等。在每个节点,决策树算法会计算每个特征的指标,选择能够最好地划分数据集的特征作为该节点的划分特征。
2. 树的构建:
决策树的构建是一个递归的过程,通过选择最优特征将数据集划分为不同的子集,然后对每个子集递归地应用同样的划分过程,直到满足停止条件,例如节点中的样本属于同一类别或达到树的最大深度。在构建过程中,决策树算法会生成一棵完整的树状结构,其中每个节点代表一个特征属性上的决策,每个叶节点代表一个类别标签或回归值。
3. 剪枝:
为了防止过拟合,决策树算法通常会采用剪枝策略,即在构建完整的决策树后,通过剪去一些节点或子树来简化模型。剪枝过程可以分为预剪枝和后剪枝两种方式。预剪枝是在构建决策树的过程中,根据一些条件提前停止树的生长;后剪枝则是在构建完整的树后,通过一定的剪枝策略来修剪树的结构。
4. 分类与回归:
决策树可用于分类和回归任务。在分类任务中,每个叶节点代表一个类别标签,通过决策路径可以确定样本的类别;在回归任务中,每个叶节点代表一个回归值,通过决策路径可以预测样本的回归值。
5. 预测过程:
当新样本到来时,决策树会根据其特征属性逐步向下遍历树的节点,最终到达叶节点,然后根据叶节点的类别标签或回归值进行预测。
决策树通过选择最优特征进行数据集的划分,构建树状结构来进行分类或回归预测。其简单直观的原理使得决策树在实际应用中具有较高的可解释性和易用性。
三、生成算法
生成算法指的是决策树如何根据训练数据生成一棵决策树模型的过程。常见的生成算法包括ID3、C4.5和CART。
1. ID3(Iterative Dichotomiser 3)信息增益算法:
ID3是最早的决策树生成算法之一,其基本思想是通过选择能够最大程度地减少不确定性(或熵)的特征来进行划分。具体步骤如下:
- 选择最优划分特征:计算每个特征的信息增益,选择信息增益最大的特征作为当前节点的划分特征。
- 根据划分特征划分数据集:将数据集按照选定的特征值进行划分,生成相应的子集。
- 递归生成子树:对每个子集递归地应用上述步骤,生成子树。
ID3算法存在的问题是对取值较多的特征容易偏向,可能导致生成的树过于复杂,容易过拟合。
2. C4.5(信息增益率)算法:
C4.5算法是ID3算法的改进版本,主要改进了两点:处理连续特征和剪枝。具体步骤如下:
- 选择最优划分特征:计算每个特征的信息增益比,选择信息增益比最大的特征作为当前节点的划分特征。
- 处理连续特征:C4.5能够处理连续特征,它将连续特征离散化,通过尝试不同的划分点来找到最优划分。
- 剪枝:C4.5在生成完整的决策树后,采用后剪枝策略来减小树的复杂度,防止过拟合。
C4.5算法相对于ID3算法更加健壮,可以处理连续特征并且采用剪枝策略,减少了生成的树的复杂度。
3. CART(Classification and Regression Trees)基尼指数算法:
CART算法是一种同时适用于分类和回归问题的决策树算法。与ID3和C4.5不同,CART算法是一种二叉决策树,每个非叶节点只有两个子节点。具体步骤如下:
- 选择最优划分特征和划分点:对每个特征,选择能够最大程度减少基尼不纯度的划分点,使得基尼指数最小。
- 根据划分特征和划分点划分数据集:将数据集按照选定的特征值和划分点进行划分,生成两个子集。
- 递归生成子树:对每个子集递归地应用上述步骤,生成子树。
CART算法通过最小化基尼不纯度来构建树,既可以用于分类也可以用于回归,且生成的树结构较为简单,易于理解和解释。
四、ID3算法
ID3算法利用信息增益进行特征的选择进行树的构建。信息熵的取值范围为0~1,值越大,越不纯,相反值越小,代表集合纯度越高。信息增益反映的是给定条件后不确定性减少的程度。每一次对决策树进行分叉选取属性的时候,我们会选取信息增益最高的属性来作为分裂属性,只有这样,决策树的不纯度才会降低的越快。
1.信息增益
信息增益是用于决策树算法中特征选择的一个重要指标,它衡量了在给定特征的条件下,对目标变量的不确定性减少程度。
在使用决策树构建模型时,我们希望找到最佳的特征来作为节点进行数据集的划分,以便在每个子节点中尽可能地减少不确定性。信息增益就是衡量这种减少不确定性的度量。
1.1 具体计算方法:
a. 计算数据集的初始不确定性:通常使用熵(Entropy)或基尼不纯度(Gini Impurity)来度量数据集的不确定性。熵和基尼不纯度都是表示数据的混乱程度的指标,值越高表示数据越不确定。
b. 对每个特征计算条件熵或条件基尼不纯度:对于每个特征,根据该特征的取值将数据集划分为若干子集,然后计算每个子集的熵或基尼不纯度。这个值表示在该特征条件下,数据集的不确定性。
c. 计算信息增益:信息增益即初始不确定性减去条件不确定性的平均值,用来衡量特征对数据集的分类所带来的纯度提升。具体计算公式为:
信息增益 = 初始不确定性 - 条件不确定性的加权平均值
d. 选择信息增益最大的特征作为划分特征:选择具有最大信息增益的特征作为当前节点的划分特征。
1.2. 意义:
信息增益的大小反映了特征对分类的重要性,信息增益越大,表示使用该特征进行划分后,数据集的不确定性减少程度越大,对分类的贡献也越大。因此,信息增益可用于选择最佳的特征来构建决策树。
1.3. 注意事项:
- 信息增益通常用于处理分类问题,对于连续型特征,需要进行离散化处理。
- 信息增益存在一定的偏好,即倾向于选择取值较多的特征,可能导致过度拟合。
总的来说,信息增益是决策树算法中特征选择的重要指标,能够帮助我们找到最优的划分特征,构建出更好的决策树模型。
五、python应用
5.1使用Python中的scikit-learn库实现ID3决策树:
- from sklearn.datasets import load_iris
- from sklearn.tree import DecisionTreeClassifier, export_text
-
- # 加载鸢尾花数据集
- iris = load_iris()
- X = iris.data
- y = iris.target
-
- # 创建并拟合决策树模型
- model = DecisionTreeClassifier(criterion='entropy')
- model.fit(X, y)
-
- # 输出决策树规则
- tree_rules = export_text(model, feature_names=iris.feature_names)
- print(tree_rules)
这段代码首先加载了鸢尾花数据集,然后创建了一个ID3决策树模型,并将其拟合到数据上。最后,使用`export_text`函数输出了决策树的规则。
输出结果
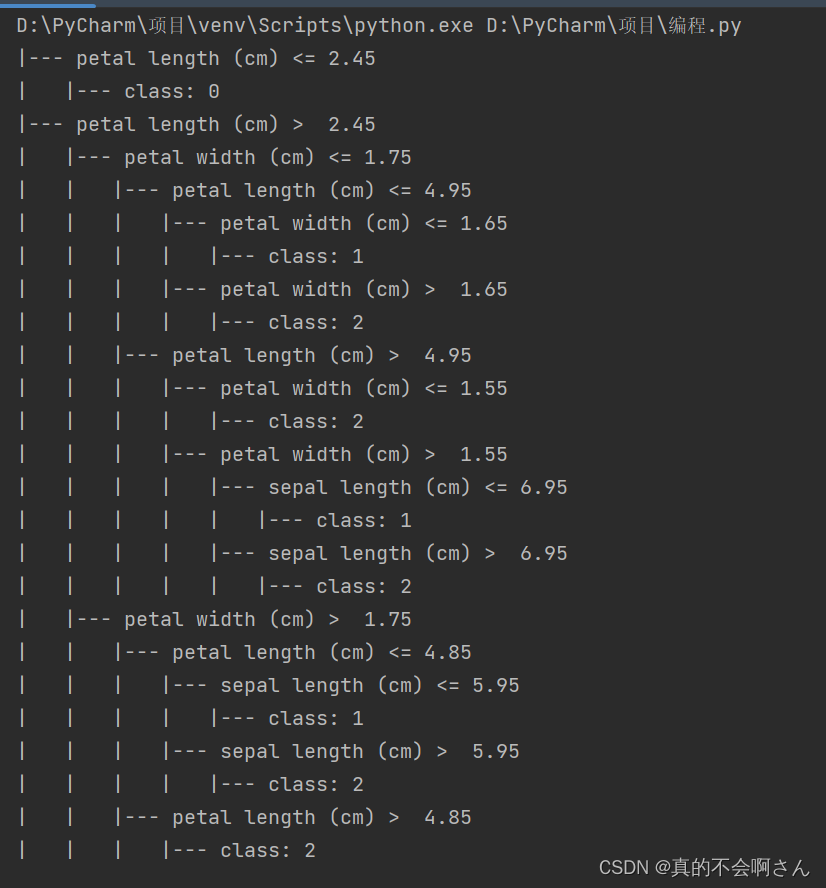
5.2在sklearn库中提供了DecisionTreeClassifier函数来实现决策树算法,其函数原型如下:
sklearn.tree.DecisionTreeClassifier(criterion='gini',max_deepth=None,random_state=None)
参数说明:
在python中决策数中默认的是gini系数,也可以选择信息增益的熵’entropy’
max_depth:树的深度大小
random_state:随机数种子
代码
- from sklearn.datasets import load_iris
- from sklearn.model_selection import train_test_split
- from sklearn.metrics import accuracy_score
- from sklearn import tree
-
- iris = load_iris() # 数据集导入
- features = iris.data # 属性特征
- labels = iris.target # 分类标签
- train_features, test_features, train_labels, test_labels = \
- train_test_split(features, labels, test_size=0.3, random_state=1) # 训练集,测试集分类
- clf = tree.DecisionTreeClassifier(criterion='entropy',max_depth=3)
- clf = clf.fit(train_features, train_labels) #X,Y分别是属性特征和分类label
- test_labels_predict = clf.predict(test_features) # 预测测试集的标签
- score = accuracy_score(test_labels, test_labels_predict) # 将预测后的结果与实际结果进行对比
- print("CART分类树的准确率 %.4lf" % score) # 输出结果
- dot_data = tree.export_graphviz(clf, out_file='iris_tree.dot') # 生成决策树可视化的dot文件

结果展示:
![]()

