- 1chatglm6b和闻达的功能扩展_chatglm 本地知识库
- 2scp命令——安全传输文件_scp 远程到本地
- 3解决Mac OS升级系统后git无法使用的问题_macos sonoma上使用git遇到的问题
- 4搭建个人服务器_自己搭建服务器
- 5动态路由 华三nat 静态路由_H3CNE学习---静态路由、动态路由协议
- 6Git:将本地仓库上传至GitHub的远程仓库_git提交到远程仓库命令
- 7使用RPA通过GPT大模型AI Agent自动执行业务流程任务企业级应用开发实战:如何选取符合业务需求的AI模型和技术_大模型应用流程
- 8一文读懂 MySQL 索引 B+树原理!_mysql索引b+树
- 9JS 创建表格_js表格
- 10如何保证同事的代码不会腐烂?一文带你了解 Alibaba COLA 架构_alibaba.cola.statemachine
CANN训练营_昇腾AI入门课第二章学习笔记_cann中提供的framwork adaptor可以让tensorflow、pytorch运行在异腾
赞
踩
第二章 TensorFlow模型迁移&训练
第一节:本章学习目标
-
了解异构计算架构CANN在神经网络训练中发挥的主要作用。
-
掌握如何基于CANN将TensorFlow模型迁移到昇腾AI处理器上。
-
掌握如何在昇腾AI处理器上进行模型训练,感受昇腾AI的极致性能。
-
掌握如何查看训练日志和训练结果,具备基本的问题定界、定位能力。
第二节:AI模型开发基础知识入门
第一单元:具备Python编程经验
1.应该具有的基础知识:(附上我的理解)
1.1使用位置和关键字参数定义和调用函数
#根据参数的位置调用参数
def function(a,b):
print(a,b)
#使用1代替参数a
function(1,"hello")
#对于具有默认参数值的函数,可以使用关键字来指定参数的值
def function(a=1,b="hello"):
print(a,b)
#a b 为函数的关键字,不会因为位置的改变而更改
function(b="hello",a=2)
在同一个函数中,可以两种方式都使用:
#position1,position2是位置参数,keyWord1,keyWord2是关键字参数 #position_or_keyWord既可以是位置参数也可以是关键字参数 def function(position1,position2,/,position_or_keyWord,*,keyWord1,keyWord2)
#举例
#只有位置
def pos_only_arg(arg,/):
print(arg)
#只有关键字
def kwd_only_arg(*,arg):
print(arg)
1.2字典、列表、集合(创建、访问和迭代)
1.2.1列表:
创建:
#两种方式创建空列表均可 list1=[] list2=list()
访问:
#追加元素
list1.append([1,2])
#追加列表
list2.extend(list1)
#删除
list1.remove(2)
#列表截取
list2=['hello','world','!']
print(list2[2])#!
print(list2[-1])#hello
print(list2[1:])#['world','!']
#打印
print("list1 = {}\n list2={}".format(list1,list2))
迭代
for i in list2: print(i)
补充:
list.append(obj):在列表末尾添加新的对象;
list.count(obj):统计某个元素在列表中出现的次数;
list.extend(seq):在列表末尾一次性追加另一个序列中的多个值(用新列表 扩展原来的列表);
list.index(obj):从列表中找出某个值第一个匹配项的索引位置;
list.insert(index, obj):将对象插入列表;
list.pop(obj=list[-1]):移除列表中的一个元素(默认最后一个元素),并且返回该元素的值;
list.remove(obj):移除列表中某个值的第一个匹配项;
list.reverse():反向列表中元素;
list.sort([func]):对原列表进行排序。
len(list):列表元素个数;
max(list):返回列表元素最大值;
min(list):返回列表元素最小值;
list(seq):将元组转换为列表。
1.2.2字典:
字典是一种可变容器模型,可以存储任意类型对象
创建:
d = {key1 : value1, key2 : value2 }
#其键必须是唯一的,但值则不必,值可以取任何数据类型,但键必须是不可变的,如字符串,数字或者元组。
directory ={'abc':'123','xyz':'456'}
访问:
#增加 directory['def']='789' #删除 del directory['def'] del directory #修改 directory['abc']='abc'
补充:
| 函数名 | 描述 |
|---|---|
| radiansdict.clear() | 删除字典内所有元素 |
| radiansdict.copy() | 返回一个字典的浅复制 |
| radiansdict.fromkeys() | 创建一个新字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值 |
| radiansdict.get(key, default=None) | 返回指定键的值,如果值不在字典中返回default值 |
| key in dict | 如果键在字典dict里返回true,否则返回false |
1.2.3集合:
创建:
parame= {value1,value2,...}
#创建一个空集合必须用set()而不是{ },因为{ }是用来创建一个空字典。
set(value1,value2,....)
访问:
#添加
s = {1,2,3}
s.add(4)
print(s)
#update
s.update({1,4})
#删除
s.discard(1)
补充:
| 方法 | 描述 |
|---|---|
| add() | 为集合添加元素 |
| clear() | 移除集合中的所有元素 |
| copy() | 拷贝一个集合 |
| difference() | 返回多个集合的差集 |
| difference_update() | 移除集合中的元素,该元素在指定的集合也存在。 |
| discard() | 删除集合中指定的元素 |
| intersection() | 返回集合的交集 |
| pop() | 随机移除元素 |
| remove() | 移除指定元素 |
| union() | 返回两个集合的并集 |
| update() | 给集合添加元素 |
| issubset() | 判断指定集合是否为该方法参数集合的子集。 |
| isdisjoint() | 判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。 |
1.3for循环,for具有 多个迭代器变量的循环(例如,fora, b in [(1,2), (3,4)])
迭代器模式,只与下标打交道
for k in {"x": 1, "y": 2}:
for i in ["houzi","daxiongmao","laohu","daxiang"]
print(i)
print(k)
1.4if/else条件块和条件表达式
学过c语言应该就没有太大问题,但是python是通过空格来判定层级的,所以要注意格式
#例子
height = float(input("输入身高(米):"))
weight = float(input("输入体重(千克):"))
bmi = weight / (height * height) #计算BMI指数
if bmi<18.5:
print("BMI指数为:"+str(bmi))
print("体重过轻")
elif bmi>=18.5 and bmi<24.9:
print("BMI指数为:"+str(bmi))
print("正常范围,注意保持")
elif bmi>=24.9 and bmi<29.9:
print("BMI指数为:"+str(bmi))
print("体重过重")
else:
print("BMI指数为:"+str(bmi))
print("肥胖")
1.5字符串格式(例如, '%.2f % 3.14)
| 表达式 | 含义 |
|---|---|
| %s | 字符串 |
| %% | 文字 :%哈哈哈哈'' 嘿嘿嘿“% |
| %c | 字符 |
| %d | 十进制(整数) |
| %i | 整数 |
| %u | 无符号整数 |
| %o | 八进制整数 |
| %x | 十六进制整数 |
| %X | 十六进制整数大写 |
| %e | 浮点数格式1 |
| %E | 浮点数格式2 |
| %f | 浮点数格式3 |
| %g | 浮点数格式4 |
| %G | 浮点数格式5 |
1.6变量、赋值、基本数据类型( int, float, bool, str等)
1.6.1数据类型:
| 类型 | 说明 |
|---|---|
| int | 整数类型 |
| float | 浮点数类型,不精确 |
| str | '',"" |
| bool | true,false,可以转化为整数 1,0 |
1.6.2变量:
作用: 是用来存储数据,便于对数据进行操作
声明变量: 直接取名赋值
标识符命名规则:
a. 只能由字母、数字、下划线组成,不能以数字开头
b. 严格区分大小写 (a和A是两个不同的标识符)
c. 如果标识符是由多个单词组成,每个单词之间用下划线隔开(规范)
d. 命名要见名之义
e. 变量名所有字母小写
第2单元 了解深度学习和神经网络
2.1理解概念:
深度学习:一个由简单概念组成的多层连接网络来定义复杂对象,计算机通过对这个网络的迭代计算与训练后,可以掌握这个对象的特征,一般称这种方法为深度学习
2.2应用领域:
图像、语音、自然语言处理、大数据特征提取和广告点击率预估等方面
Link: deeplearning_ai的个人空间哔哩哔哩bilibili
第3单元 了解TensorFlow AI框架
内容较多,会在其他的博客中再完善,先附上官方学习链接
第4单元 了解基于CANN的模型开发流程
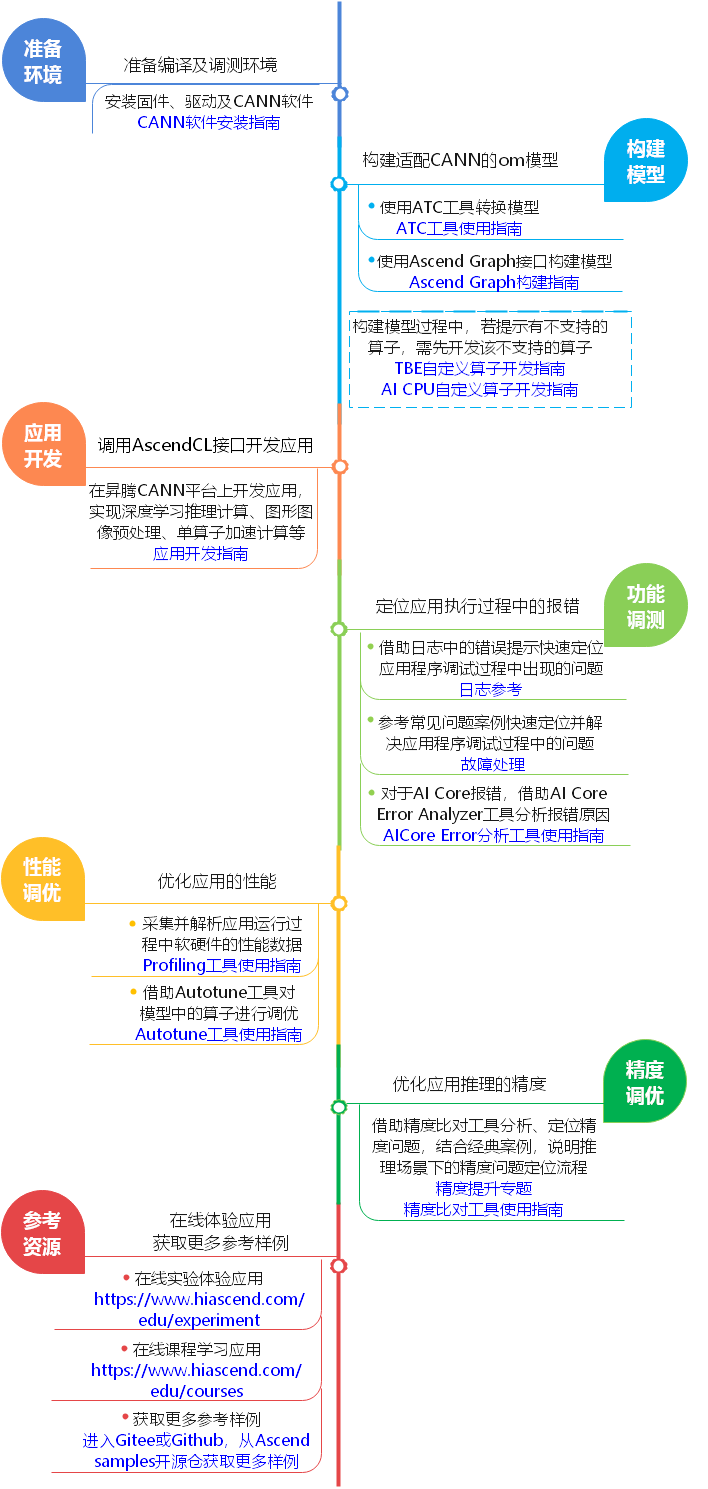
目前社区版本的文档打不开,下面是生态版的文档链接:
第5单元 了解遇到问题如何求助
有问题或者建议可以借助以下渠道:
-
在华为方集中组织培训的场景下,可求助培训或对应课程的接口人。
-
开发者自学的场景下:
a. 可在ModelZoo仓上提Issue,该仓的接口人会定期处理问题。
b. 可在昇腾社区论坛中查阅经验贴、或者发帖,论坛的接口人会定期处理问题。
第3节 TensorFlow AI模型迁移详解
第一单元 本节学习目标
-
了解为什么要做模型迁移
-
了解模型迁移的两种迁移方式
-
掌握如何进行模型迁移
-
第2单元 为什么要做模型迁移
必要性:
除了昇思MindSpore外,TensorFlow等其他深度学习框架下的模型并不能直接在昇腾910 AI处理器上训练,为了使其充分利用昇腾910 AI处理器的澎湃算力来提升训练性能,我们需要借助异构计算架构CANN的Plugin适配层转换,使转换后的模型能够高效运行在昇腾910 AI处理器上。
取得的成就和优势:值得庆幸的是,目前,CANN已经能够支持多种主流AI框架,包括昇思MindSpore、TensorFlow、PyTorch、飞浆、ONNX等,并且开发者只需要非常少的改动,即可快速搞定算法移植,大大减少切换平台的代价。
第3单元 了解两种模型迁移方式
将TensorFlow网络模型迁移到昇腾AI处理器执行训练,主要有两种方式:
-
一种是自动迁移方式。通过迁移工具对原始脚本进行AST语法树扫描,可自动分析原生的TensorFlow API在昇腾AI处理器上的支持度,并将原始的TensorFlow训练脚本自动迁移成昇腾AI处理器支持的脚本,对于无法自动迁移的API,可以参考工具输出的迁移报告,对训练脚本进行相应的适配修改。
-
一种是手工迁移方式。算法工程师需要人工分析TensorFlow训练脚本中的API支持度情况,并且参照文档逐一手工修改不支持的API,以便在昇腾AI处理器上训练,该种方式较为复杂,我们建议大家优先使用自动迁移方式。
第4单元 TensorFlow AI模型自动迁移详解
第5单元TensorFlow AI模型手工迁移详解
5.1课程目标及准备工作:
·学完本课程,应该能够:
1.了解如何将TensorFlow训练脚本迁移Ascend910训练
2.CANN平台的部分特性
· 为了达成上述目标,应该具备如下知识:
1.熟练的python语言编程能力
2.熟悉TensorFlow1.15的API
3.深度学习知识基础,熟悉训练网络的基本知识和流程
·迁移开始前,需要准备下面工作:
1.能够在GPU/CPU上跑通的TensorFlow1.15训练脚本
2.与脚本配套的数据集
5.2为什么要进行网络迁移
大多数训练脚本基于TensorFlow的Python API 开发,默认运行在CPU/GPU/TPU上,为了使其用上NPU的澎湃算力执行训练,我们需要完成这项工作。
当前Ascend910上支持TensorFlow的三种API开发训练脚本迁移:Estimator,Sess run,Kears.
5.3迁移流程:
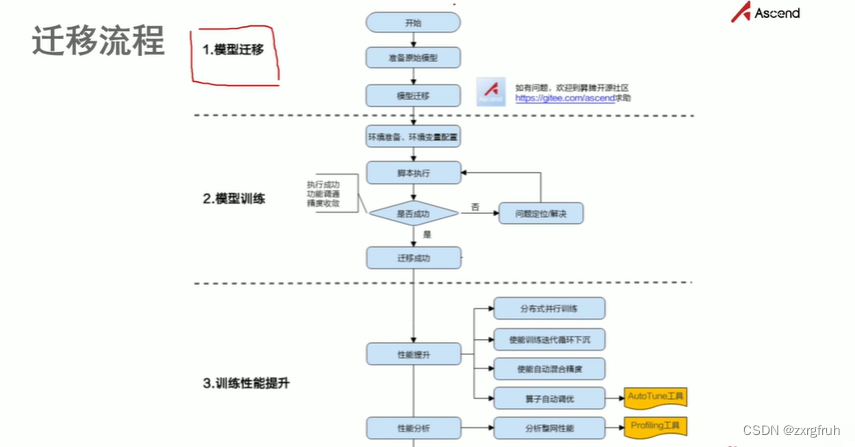
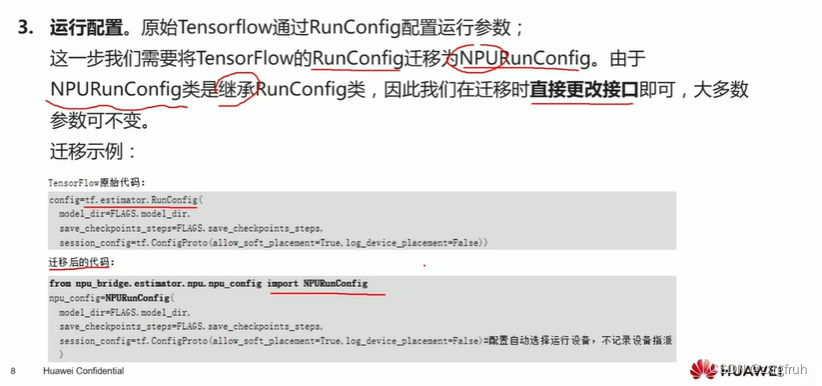
5.3.1Estimator迁移



第4节 TensorFlow AI模型训练详情
第一单元 本节学习目标
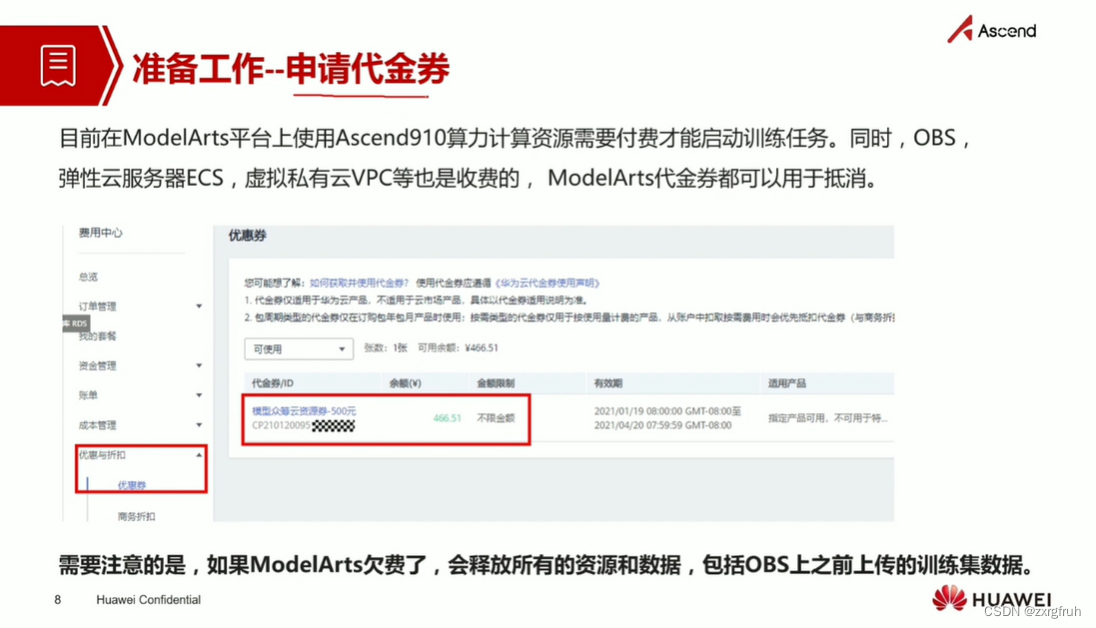
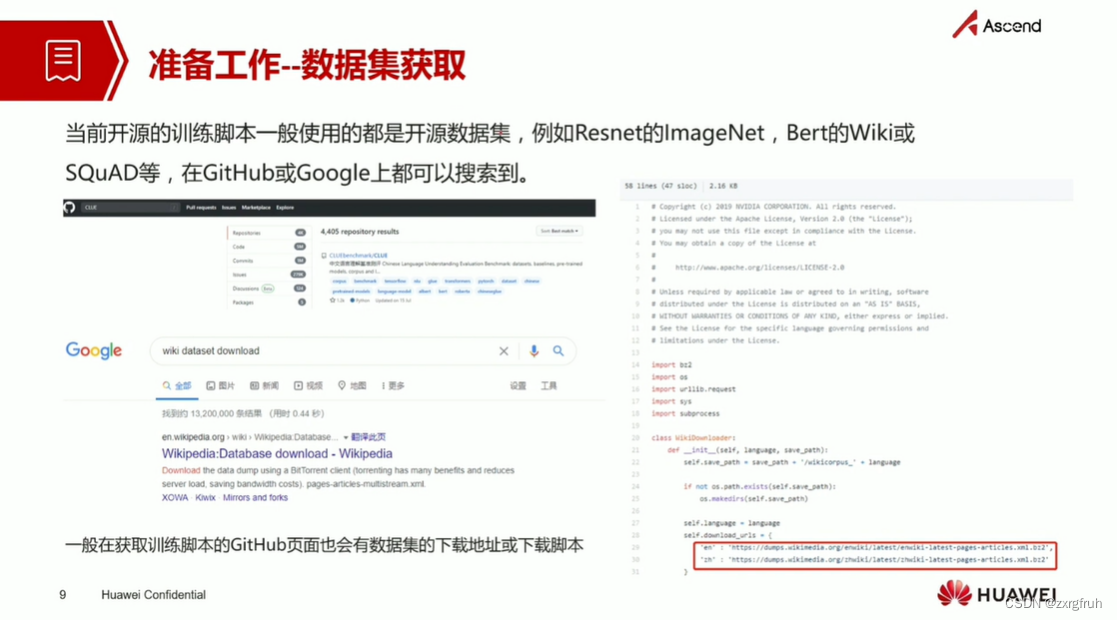
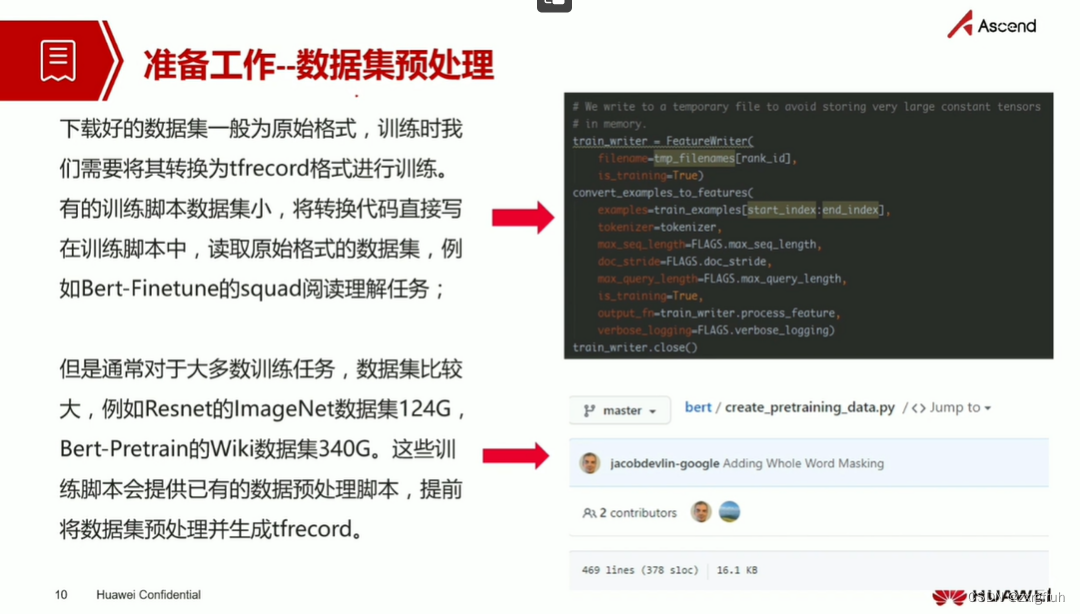
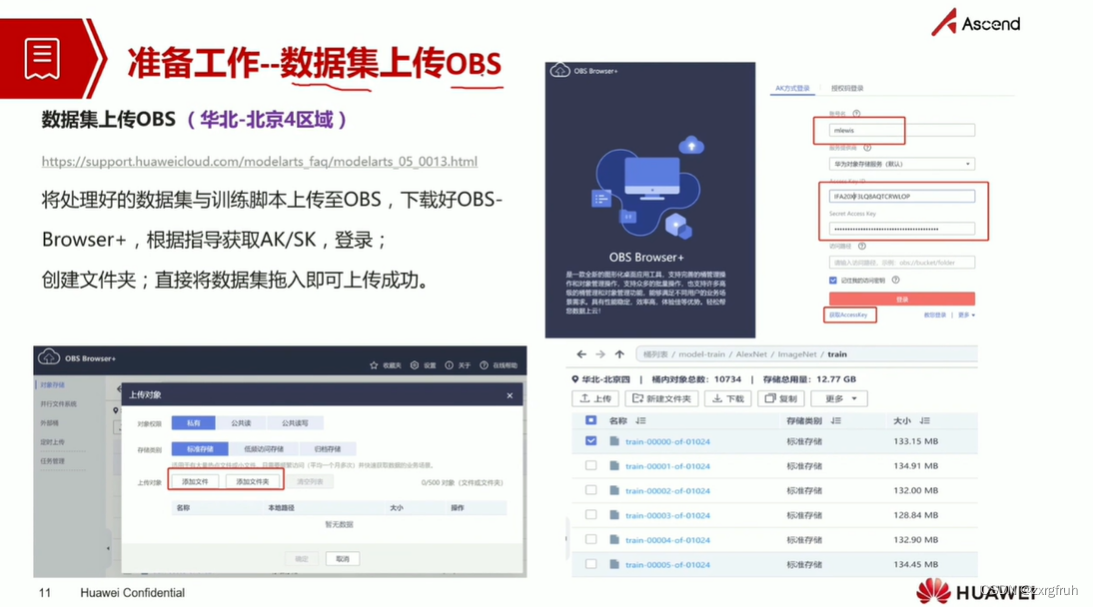
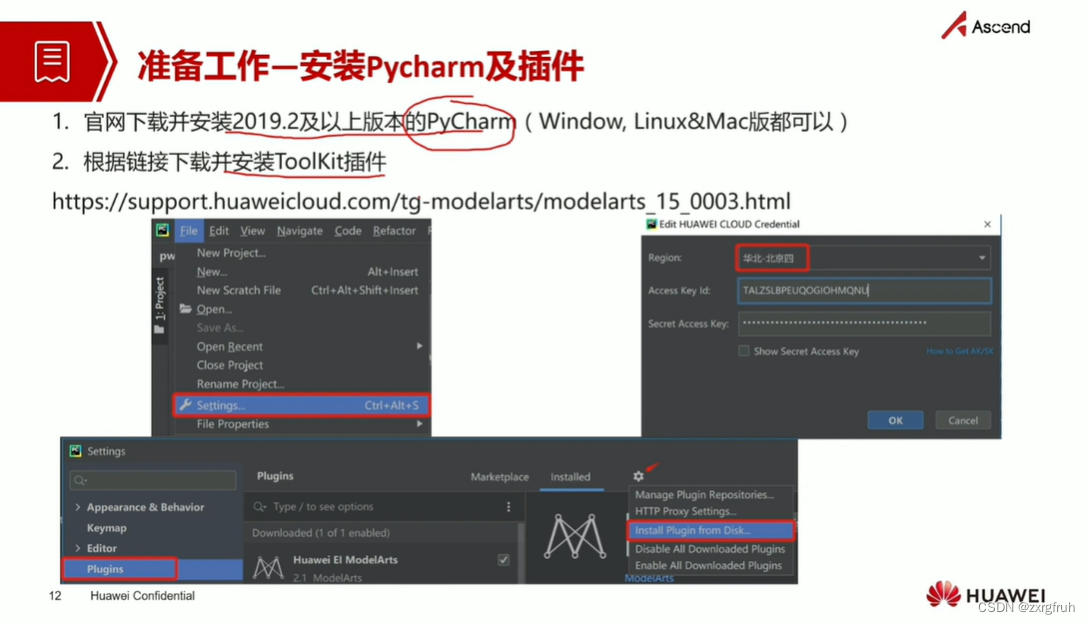
1.了解ModelArts训练之前各项准备工作
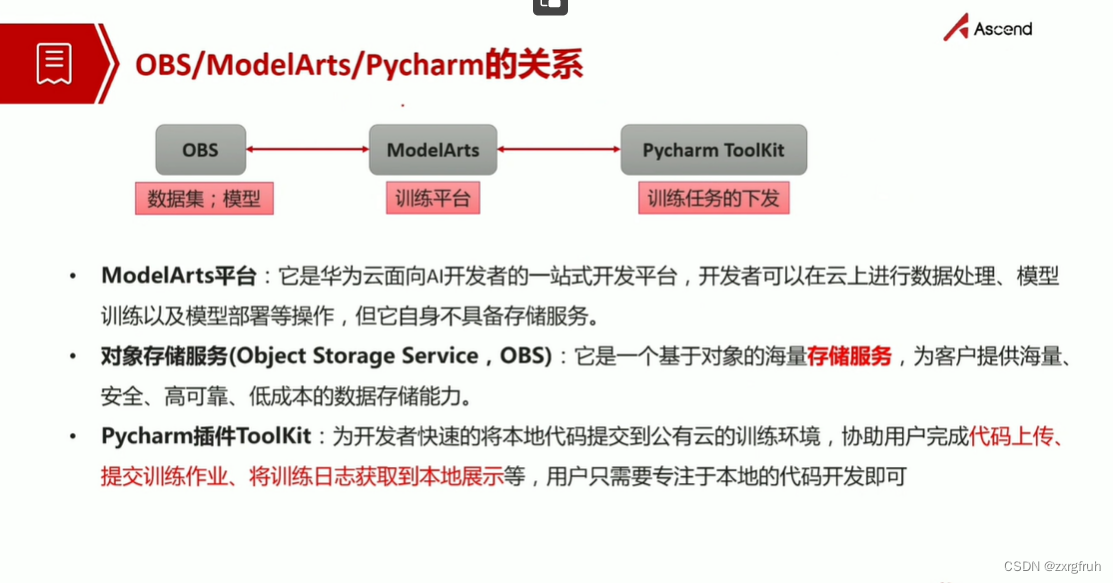
2.了解OBS、ModelArts以及Pycharm插件关系
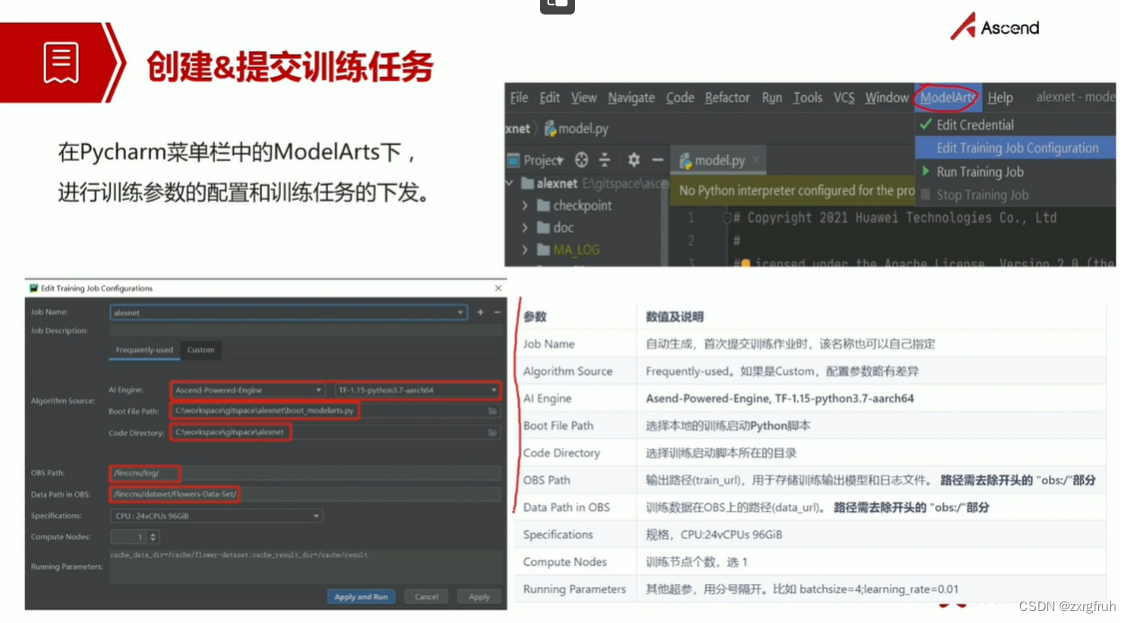
3.掌握如何使用ModelArts平台进行网络训练
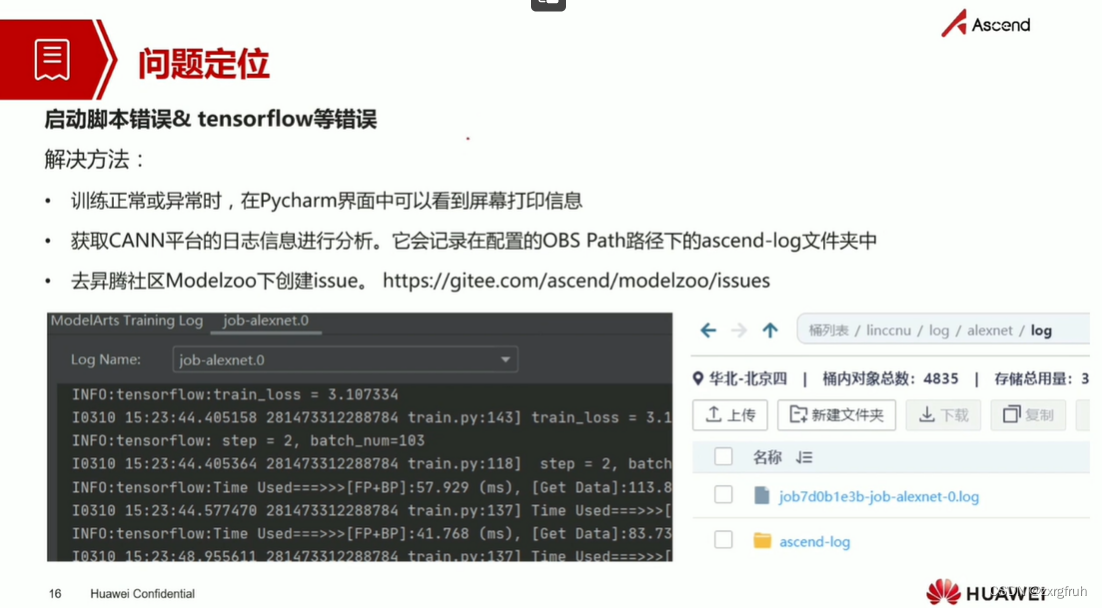
4.掌握如何查看训练日志和训练结果,具备基本的问题定界、定位能力。
第二单元 学习资源