
- 1AI绘画工具Stable Diffusion神级插件InstantID,AI换脸完美版!_sd换脸插件lnstansid
- 2图解 MySQL 索引:B-树、B+树_mysql b+树
- 3centos7 部署harbor镜像仓库_centos7部署harbor
- 4【开篇】STM32F103C8T6 含义、命名规则、GPIO原理以及初始化(参考男神江科协,学习交流用)_stm32f103c8t6引脚图及功能
- 5数据结构之链式栈
- 6Ubuntu下E: Unable to fetch some archives, maybe run apt-get update or try with --fix-missing?_ubuntu e: unable to fetch some archives, maybe run
- 7使用 docker-compose 安装搭建 RabbitMQ 集群_docker-compose 安装 rabbitmq
- 8【嵌入式硬件】快衰减和慢衰减
- 9企业云的未来一年,就看这一天
- 10Kimi:最适合老师与科研使用的AI,完全免费!_kimi生成的参考文献 准确吗
2024年最新Stable Diffusion 新手入门教程,安装使用及模型下载_stable diffusion安装
赞
踩
一、安装要求:
① 操作系统:Windows10以后的系统
② CPU:不做强制性要求
③ 内存:推荐8G以上
④ 显卡:必须是Nvidia的独立显卡,显存最低4G,推荐20系以后;A卡、核显只能用CPU跑
⑤ 整合包推荐放在固态硬盘中,提升模型加载速度
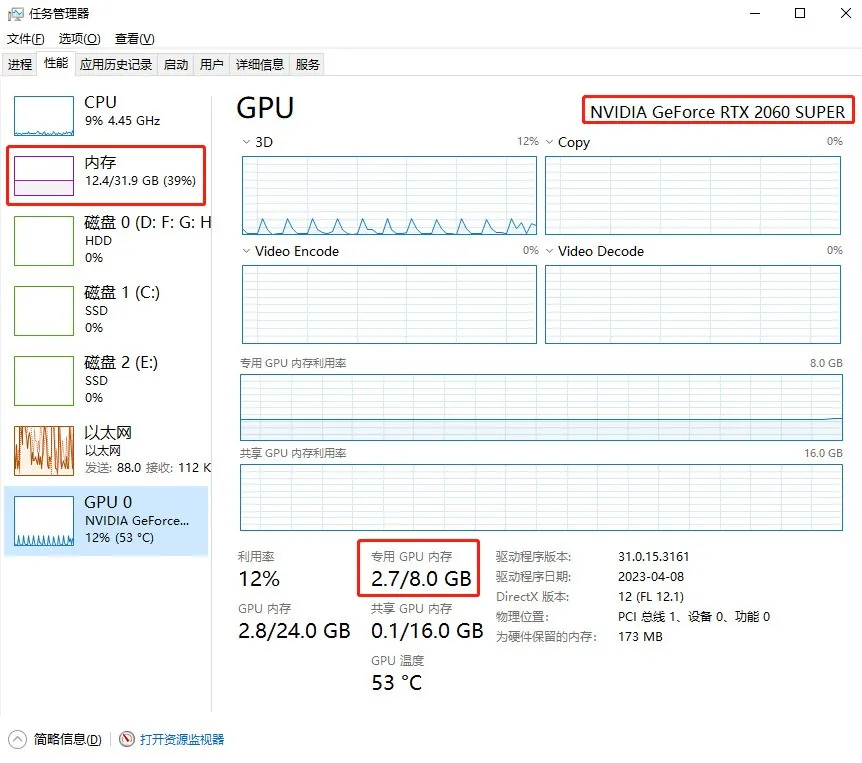
如何查看自己电脑性能:
同时按下 Ctrl+Alt+Delete 三个键(或鼠标右键底下的任务栏),选择任务管理器
二、下载安装
推荐下载b站秋葉大佬的整合包:文末会分享
安装启动器运行依赖,双击启动器运行依赖一步步安装即可。
解压整合包本体到空间比较大的分区,最好是固定硬盘中,不要安装到中文路径下
解压完后双击启动器就可以运行了,如果开着全局梯子请注意关闭
三、通过启动器进入web界面
启动器一览
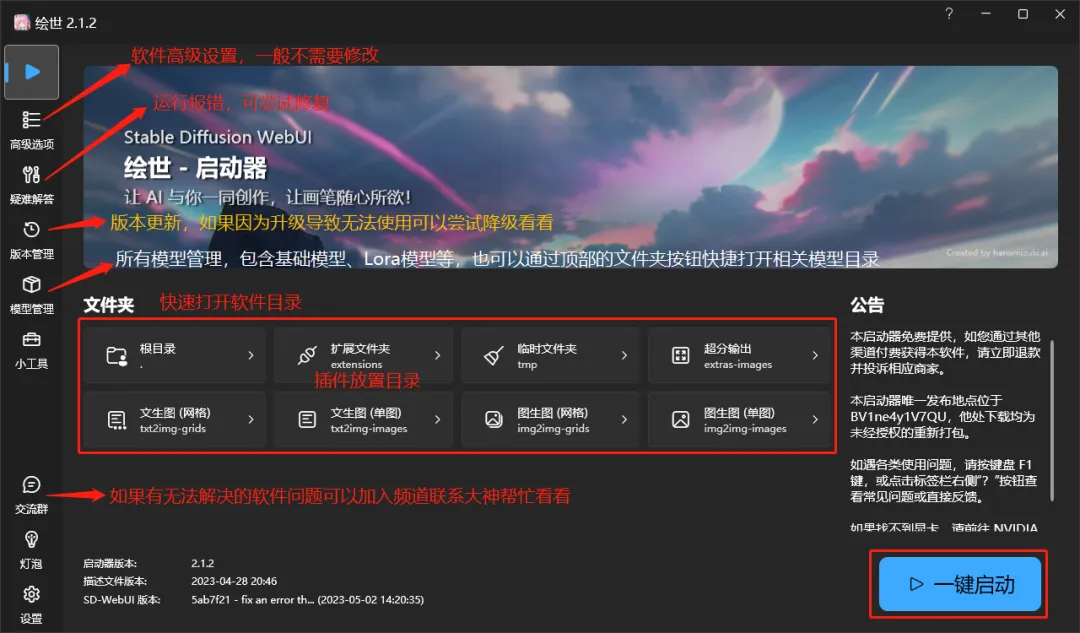
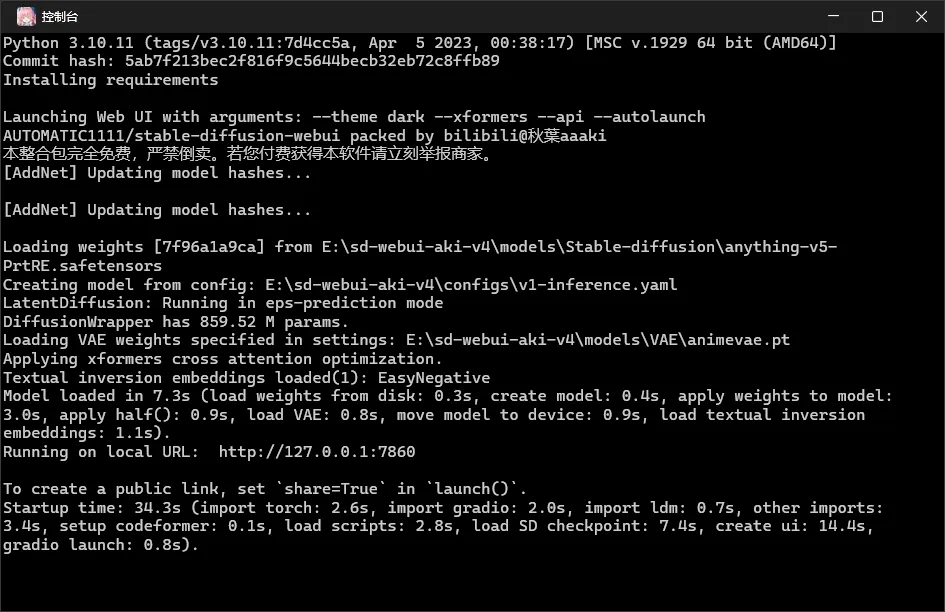
打开启动器,一键启动即可,留意随启动器一起打开的命令窗口,等待一会显示http://127.0.0.1:7860就成功启动了,若启动时有什么报错信息都可以在这个窗口看到,可以尝试用启动器的修复功能先修复看看,如果不行先百度下看看,实在解决不了可以进秋葉大佬的QQ频道咨询一下。
一般会自动打开网页进入绘图页面,文生图最基本的介绍看下图
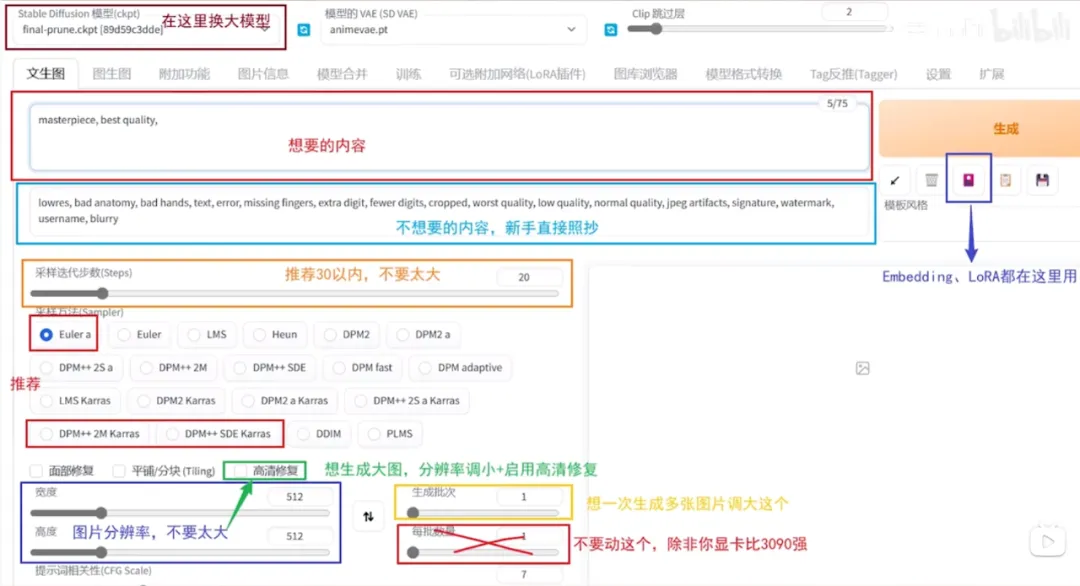
① Stable Diffusion 模型:切换大模型,出什么类型的图主要看这个
② 模型的VAE:VAE模型,主要作用就是滤镜和微调画面,常用的是840000
③ 跳过CLIP层数:数值越小其越贴近模型表现,通常为2不需要动
④ 正向提示词:想要生成的内容
⑤ 反向提示词:画面中不想要的内容
⑥ 迭代步数和采样方法是配套的,生成人物图建议使用DPM++ 2S a采样方法,迭代步数保持在25~30之间。过低过高都不会太好。
⑦ 宽高:一般方图512512即可,竖图和横图可以保持一边512另一边等比例计算即可,如512912
⑧ 高清修复:放大处理,想生成大图,分辨率调小+启用高清修复
⑨ 生成批次:一次想生成多少张图片
⑩ 每批数量:一般保持1不要动,极消耗显存
⑪ 提示词引导系数:提示词与画面的相关程度,一般7-10
四、使用提示词生成自己的第一幅图
1、正向提示词的内容通常包含人物、场景、环境、视角以及画面品质和画风等基本元素组成



2、提示词的权重,想突出或减弱的画面内容可以使用提示词权重来控制,推荐直接使用小括号:数字的组合,高于1是增加权重,低于1是减少权重,如:
增加权重:(white flower:1.5) 会增加白色的花在画面中出现的概率和画面占比
减少权重:(white flower:0.5) 会减少白色的花在画面中出现的概率和画面占比

3、反向提示词:通常是放不希望出现在画面中的内容,好比描写下雨的场景AI总会把伞画进去,此时就可以把伞相关的词放入这里。反向提示词通常是可以直接抄作业的。如下面这个画人时通常使用的模板:
NSFW, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((grayscale)), skin spots, acnes, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), (tranny:1.331), mutated hands, (poorly drawn hands:1.5), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.61051), (too many fingers:1.61051), (unclear eyes:1.331), lowers, bad hands, missing fingers, extra digit,bad hands, missing fingers, (((extra arms and legs))),
4、如何来写提示词:因为SD对中文的识别不太友好,所以也是需要输入英文提示词来生成画面,这里提供3种方法供参考。
① 翻译大法:使用翻译软件把中文提示词翻译成英文,常用工具有DeepL、谷歌翻译、百度翻译等
② 提示词生成工具:用一些提示词生成工具可以依次选择需要的词,然后直接拷贝进去即可。常用的工具有:
③ 直接抄作业:很多网站提供了预览图和完整的提示词,可以直接拷贝过来用,当然要想出跟提示词相似的图片还要留意下使用的基础模型、Lora模型及采样步数等相关参数。相关网站有:
大名鼎鼎的C站:https://civitai.com/(现在这个网站需要梯子才能打开了,这也是主要的模型下载站,模型下面除了模型作者的演示图也会有网友创作的图,大多带有提示词可以参照)
Lexica:https://lexica.art/(虽然图库是他自家的模型,但是提示词一样很有参考价值)
5、生成第一张图吧
正向提示词我们就用:1girl, long hair, long skirt, indoors, morning, upper body, best quality, 8k
反向提示词就用上面给到的,分别填写到对应的输入框,生成自己的第一张图吧。其他参数也可以参考下图设置
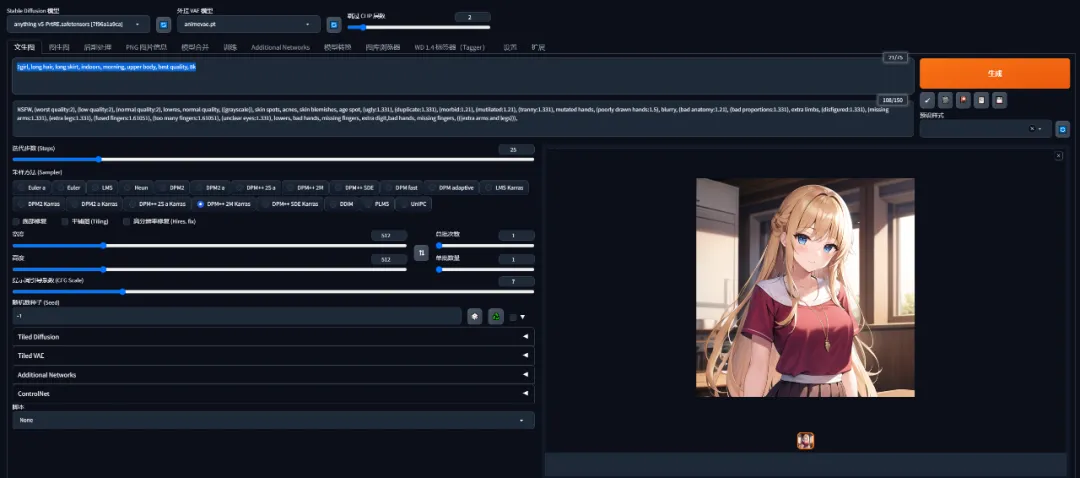
可以把总批次设置成4就可以一次生成4张图片了

好像还不错?但是为啥生成的都是动漫风格的呢?那是因为我们默认使用的是anyting这个大模型主要就是生成动漫风格的。而Stable Diffusion非常依赖模型来生成不同的风格。
这里直接将该软件分享出来给大家吧~

1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!


