
- 1RabbitMQ(五)死信队列、延迟队列_死信队列和延时队列的区别
- 2使用GPU跑包工具
- 330岁程序员的转型思考_算法工程师30岁以后
- 4Android 面试问题 2024 版(其一)_安卓开发面试
- 5【学习笔记】爬虫(Ⅰ)—— Selenium和Pytest_pytest框架和selenium一样吗
- 6灰狼优化算法(GWO)与长短期记忆网络(LSTM)结合的预测模型(GWO-LSTM)及其Python和MATLAB实现
- 7十大经典排序算法-计数排序算法详解
- 8java实现lda模型_lda模型 java
- 9Python 微信自动化工具开发系列03_自动向微信好友发送信息和文件(2024年2月可用 支持3.9最新微信)_python使用wxauto实现多人微信自动发消息或文件
- 10Spring Boot 3 整合 Hutool 验证码实战_springboot3 整合hutool
下一代 RAG 技术来了!微软正式开源 GraphRAG_微软 graphrag
赞
踩
省流总结
优点:检索准确度高
缺点:单个19w字构建用时4分30s、gpt4 token花费12美元
概述
7 月 2 日,微软开源了 GraphRAG,一种基于图的检索增强生成 (RAG) 方法,可以对私有或以前未见过的数据集进行问答。在 GitHub 上推出后,该项目快速获得了 2700 颗 star!
开源地址:https://github.com/microsoft/graphrag
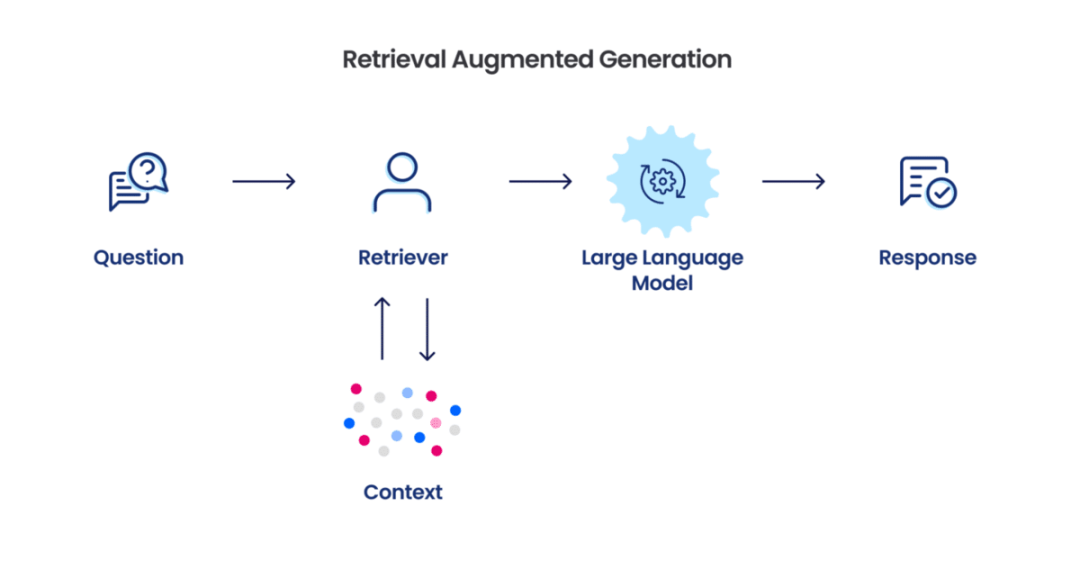
通过 LLM 构建知识图谱结合图机器学习,GraphRAG 极大增强 LLM 在处理私有数据时的性能,同时具备连点成线的跨大型数据集的复杂语义问题推理能力。普通 RAG 技术在私有数据,如企业的专有研究、商业文档表现非常差,而 GraphRAG 则基于前置的知识图谱、社区分层和语义总结以及图机器学习技术可以大幅度提供此类场景的性能。
微软在其博客上介绍说,他们在大规模播客以及新闻数据集上进行了测试,在全面性、多样性、赋权性方面,结果显示 GraphRAG 都优于朴素 RAG(70~80% 获胜率)。
与我们传统的 RAG 不同,GraphRAG 方法可以归结为:利用大型语言模型 (LLMs) 从您的来源中提取知识图谱;将此图谱聚类成不同粒度级别的相关实体社区;对于 RAG 操作,遍历所有社区以创建“社区答案”,并进行缩减以创建最终答案。
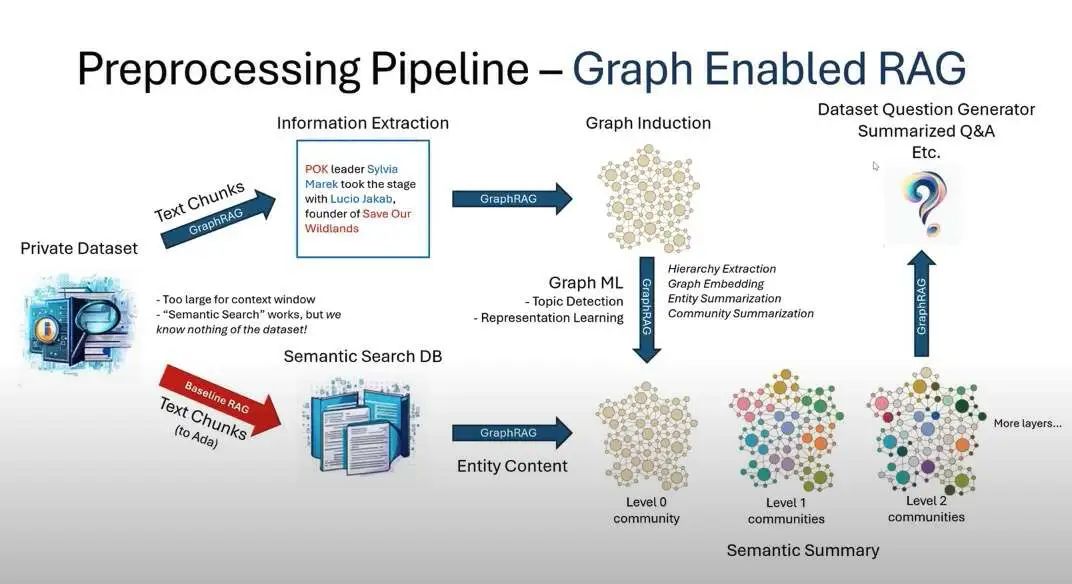
这个方法用微软高大上的说法是:

微软研究院于 4 月首次宣布推出 GraphRAG ,仅看到论文就让很多人有点等不及上手一试了,如今这项成果终于开源了,开发者们对此表现得超级兴奋:

太棒了,微软开源了 GraphRAG!看完演示视频后,我的脑海里充满了 GraphRAG 带来的各种可能性。我打算在 MacBook 上尝试使用 GraphRAG + Llama3,因为它有 96GB 的统一内存 (VRAM)。我认为这个工具绝对会带来颠覆性的改变。

从看了论文后,我就一直期待着能玩玩它。我曾想过根据论文自己实现它,不过我想官方的代码应该只会晚几周发布,事实证明我的耐心确实得到了回报
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

