
- 1VMware Workstation Pro 17.5.2 配置 Ubuntu Server 24.04 LTS 教程,MobaXterm的配置,克隆虚拟机后的工作
- 2揭秘!国内10大低代码构建平台_国内低代码平台有哪些
- 3数据库加固措施 oracle,oracle如何加固你的数据库
- 4DuiLib编译_dui designer 不能保存gifanim
- 5Python 基于多环境的配置方式_python多环境配置
- 6TortoiseGit Svn 实现Github上项目版本控制_tortoisesvn可以直接git项目吗
- 7内置指令(Vue2版)
- 8博客摘录「 AI 正在取代工作岗位、ChatBot 进入厌倦期、向量数据库崛起,人工智能现状报告有这些重要发现!...」2024年7月11日_使用ai chatbots的趋势
- 9【数据结构】最小堆_最小堆 数据结构
- 10消息队列 面试题 整理_mqtt面试
机器翻译Machine Translation及其Tensorflow代码实现(含注意力attention)_机器翻译举例
赞
踩
机器翻译
翻译句子 x x x从一种语言(源语言)到句子 y y y另一种语言(目标语言)。下面这个例子就是从法语转换成为英文。

统计机器翻译
英文是Statistical Machine Translation (SMT)。核心思想是从数据中学习概率模型。
a r g m a x y P ( y ∣ x ) = a r g m a x y P ( x ∣ y ) P ( y ) argmax_y P(y|x) \\\\ = argmax_y P(x|y) P(y) argmaxyP(y∣x)=argmaxyP(x∣y)P(y)
公式前一部分 P ( x ∣ y ) P(x|y) P(x∣y)是翻译模型,负责翻译词和词组。后一部分 P ( y ) P(y) P(y)是语言模型,负责使译文更加流畅。
优点
- 思路容易理解,有可解释性
缺点
- 需要大量的特征工程,耗费人力
- 空间复杂度较高,需要存储额外资源,例如平行语句
对齐
为了训练出一个性能优秀的翻译模型,我们首先需要有很多的平行数据(从原文到译文)。这就需要引出对齐的概念。找到原文中的哪个短语对应到译文中的哪个短语。我们用 a a a代表对齐。因此,我们的翻译模型从最大化 P ( x ∣ y ) P(x|y) P(x∣y)变成了最大化 P ( x , a ∣ y ) P(x,a|y) P(x,a∣y)。对齐的难点就在于原文中可能存在词语没有对应的译文(counterpart)。我们还需要考虑单词在句子中不同位置导致对句意产生的不同的影响。
即便能够进行对应,对齐本身也十分复杂,有可能出现以下3种情况。
多对一
多个译文词组对应一个原文词组。
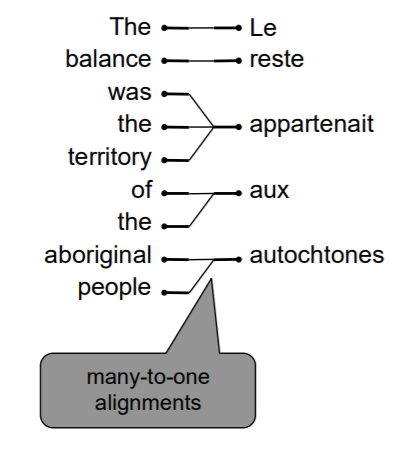
一对多
一个译文词组对应多个原文词组。类似的词被称为多产词(fertile word)。

多对多
多个译文词组对应多个原文词组。无法进行更细致的拆分。

解码
在对齐之后,我们需要进行翻译。如果使用暴力方法,即枚举所有可能的译文并计算其概率,显然不太现实,因为复杂度太高。更有效的方法是进行启发式搜索算法(heuristic search algorithm),放弃探索所有可能性较小的译文。
神经机器翻译
英文是Neural Machine Translation (NMT)。模型架构是序列到序列模型(sequence-to-sequence, seq2seq),详情请参见我的另一篇博客。
在NMT中,我们直接计算 P ( y ∣ x ) P(y|x) P(y∣x)而不是像SMT拆开计算。
P ( y ∣ x ) = P ( y 1 ∣ x ) P ( y 2 ∣ y 1 , x ) . . . P ( y T ∣ y 1 , . . . , y T − 1 , x ) P(y|x) = P(y_1|x) P(y_2|y_1,x) ... P(y_T|y_1,...,y_{T-1},x) P(y∣x)=P(y1∣x)P(y2∣y1,x)...P(yT∣y1,...,yT−1

