
- 1伺服系统的动态校正与控制:位置、转速、电流三环控制系统_伺服系统三环pid
- 2一文带你速通RAG、知识库和LLM!_知识库 rag
- 3sql update 特殊用法
- 4CosyVoice 实测,阿里开源语音合成模型,3s极速语音克隆,5分钟带你部署实战_cosyvoice 合成语音 速度慢
- 5LSSVM-ABKDE基于最小二乘支持向量机结合自适应带宽核函数密度估计的多变量回归预测(点预测+概率预测+核密度估计)_ls-svm 回归曲线
- 6百度api语音_function vol
- 7python中plot实现实时显示数据_python 一边显示图另一边显示数据
- 8Redis项目实战_redis 实战
- 9could not find implicit value for evidence parameter of type org.apache.flink.api.common.typeinfo.Ty
- 10树和二叉树
全网最新免费开源的ocr文字识别开源项目盘点整理,附项目开源地址,支持离线部署使用,支持多种语言识别和API调用以及第三方集成,支持各种证件、发票、通用模型识别,支持复杂文本、各种图片、文档、长文本等_开源ocr识别
赞
踩
全网最新免费开源的ocr文字识别开源项目盘点整理,附项目开源地址,支持离线部署使用,支持多种语言识别和API调用以及第三方集成,支持各种证件、发票、通用模型识别,支持复杂文本、各种图片、文档、长文本等。

OCR(Optical Character Recognition,光学字符识别)技术能够将图像中的文字转换为可编辑的文本格式,这一技术在多个领域有着广泛的应用。以下是OCR技术的一些主要应用场景以及几个流行的开源项目和它们的特点:
应用场景
- 证件识别:用于金融、银行、保险等行业,自动识别身份证、护照、驾驶证等证件信息。
- 银行卡识别:在移动支付绑卡等场景中,自动识别银行卡号,提升用户体验。
- 车牌识别:在移动警务、停车场管理等场景中,自动识别车牌号码和车辆特征信息。
- 名片识别:在CRM客户管理系统中,自动识别名片内容,便于信息管理。
- 营业执照识别:自动识别营业执照信息,如统一社会信用代码、公司名称等。
- 汽车VIN码识别:在汽车管理、二手车交易等领域,自动识别车架号。
- 票据类OCR识别:自动识别增值税发票等票据内容,用于财务管理等。
- 文档文字OCR识别:在图书馆、报社等机构,将纸质文档电子化。
开源项目及特点
-
Paddle OCR:
- 特点:轻量级模型,执行速度快;支持中英文识别;支持倾斜、竖排文字识别;可通过PaddleHub直接使用或训练自己的模型。
-
CnOCR:
- 特点:轻量级模型,执行速度快;支持简体中文、繁体中文、英文和数字识别;自带多个训练好的模型;支持训练自己的模型。
-
chinese_lite OCR:
- 特点:超轻量级中文OCR,支持竖排文字识别;模型大小仅4.7M,执行速度快。
-
EasyOCR:
- 特点:支持80多种语言的OCR;能够读取自然场景文本和文档中的密集文本。
-
Tesseract OCR:
- 特点:老牌开源OCR引擎,支持多种操作系统;支持补充训练,但安装使用较为困难。
-
chineseocr:
- 特点:基于YOLO3与CRNN实现中文自然场景文字检测及识别;支持多方向文字检测;适用于树莓派等设备。
-
ChineseOCR:
- 特点:专注于汉字识别,适用于复杂背景和手写字体;基于TensorFlow构建;提供预训练模型和数据增强技术。
-
腾讯云OCR:
- 特点:基于深度学习技术,支持多种文字识别;提供多种编程语言的SDK和API。
-
百度AI开放平台OCR:
- 特点:支持多种通用场景和20+种语言的高精度文字检测和识别;提供离线SDK和私有化部署选项。
-
阿里云OCR:
- 特点:支持通用文字识别、卡证识别、票据识别等;提供公有云服务、离线识别SDK和私有化部署。
这些开源项目和商业服务展示了OCR技术在不断进步和扩展应用范围,从简单的文本识别到复杂场景的多语言、多方向和多格式的识别,OCR技术正变得越来越强大和易于使用。
随着科技的发展,OCR场景随处可见,很多APP也集成如身份证识别,银行卡识别的功能,包括微信都支持截图文件中的文字提取。现在,各大厂商均有提供各种场景的OCR识别的API。但是,有时候我们也想自己来折腾一下。这时候,就可以借助一些主流开源框架来快速达到我们的目的。
OCR引擎
tesseract
Tesseract,一款由HP实验室开发由Google维护的开源OCR引擎,开源,免费,支持多语言,多平台;
https://github.com/tesseract-ocr/tesseract.git
tesseract.js
js版本的Tesseract OCR,支持一百多种语言,使用也是非常简单,可以用npm安装,也可以直接在页面引用js
https://github.com/naptha/tesseract.js.git
PaddleOCR
PaddleOCR是百度开源一套OCR,旨在打造一套丰富、领先、且实用的OCR工具库,助力开发者训练出更好的模型,并应用落地。
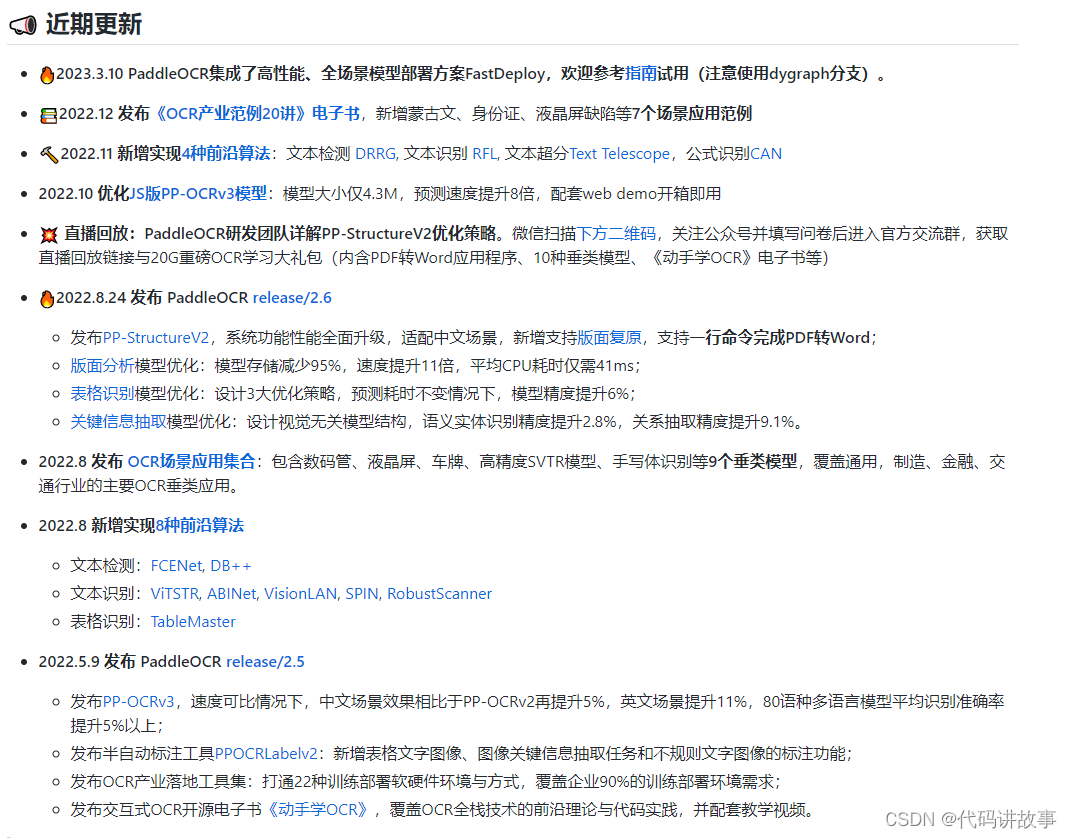
https://github.com/PaddlePaddle/PaddleOCR.git
EasyOCR
EasyOCR是用Python编写基于Tesseract的OCR识别库,用于图像识别输出文本,目前支持80多种语言。

https://github.com/JaidedAI/EasyOCR.git
mmocr
MMOCR 是基于 PyTorch 和 mmdetection 的开源工具箱,专注于文本检测,文本识别以及相应的下游任务,如关键信息提取。
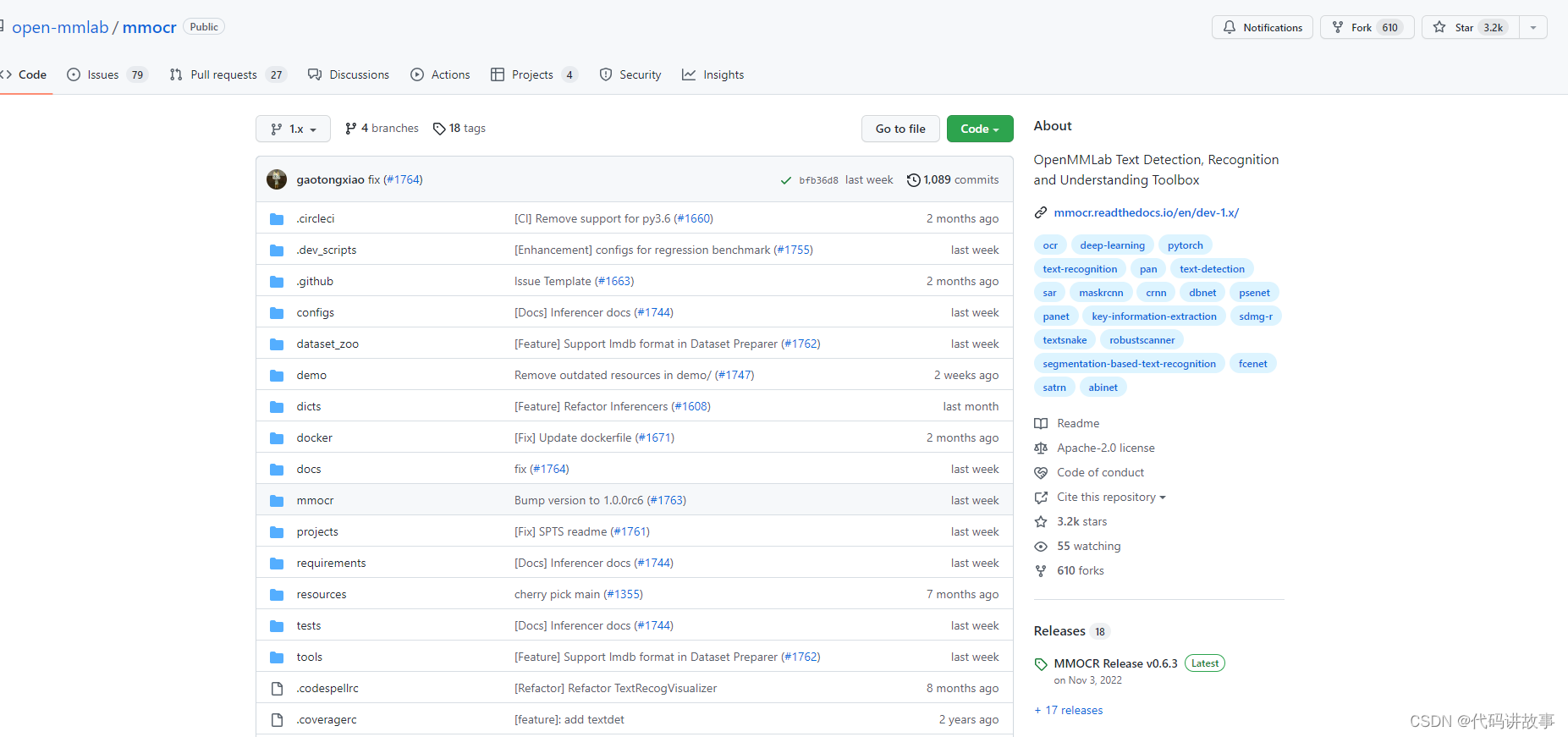
https://github.com/open-mmlab/mmocr.git
simple-ocr-opencv
基于opencv 和numpy开源的OCR识别引擎
https://github.com/goncalopp/simple-ocr-opencv.git
OCR工具
OCRmyPDF
OCRmyPDF是基于tesseract-ocr开发、训练的文字识别提取的开源项目

https://github.com/ocrmypdf/OCRmyPDF.git
Umi-OCR
基于 PaddleOCR 实现的一款开源的文字识别工具,

一般开源项目,识别率肯定没有商用的那么高,只有通过训练自己的字库来提高识别率。文字识别场景,有时候就会涉及到图片处理,这里又会关联到其它强大的图像处理开源项目,如:OpenCV。这些项目中,PaddleOCR相对来说会更符合我们常见的业务场景,也支持我们自己去训练。
OCR(光学字符识别)是一种将图像中的文字自动转换为可编辑文本的技术。现在,各大厂商均有提供各种场景的OCR识别的API。但是,也有一些开源的OCR框架和工具,可以支持自我定制和训练,使得开发人员能够更加灵活地应对不同场景下的OCR需求。
一、OCR开源工具的优点
使用OCR开源工具可以使文本识别更加自动化、高效化和准确化,从而为各种应用场景带来了便利性和实用性。相对于商业OCR软件,开源OCR工具有以下优势:
免费使用:没有商业软件的版权和授权限制,开源OCR工具提供的功能都可以免费使用。
开放源代码:源代码公开,可以根据需要对其进行修改和定制化。
灵活可扩展:可以根据实际需要选择不同的工具,并且这些工具在不同式样和领域都有应用实践,具有普遍性和可扩展性。
二、八大常见的OCR开源工具
1.Tesseract
Tesseract是一款由Google维护的开源OCR引擎,开源、免费、支持多语言、多平台。它可以处理很多类型的图像,并且还支持多种字体和文本布局。
2.Tesseract.js
Tesseract.js是一个JavaScript版本的Tesseract OCR,支持100多种语言,使用也非常简单,可以使用npm安装,也可以直接在页面中引用js。因为是基于JavaScript运行,因此无需进行任何额外的配置。
3.PaddleOCR
PaddleOCR是百度开源的一套OCR库,旨在打造一套丰富、领先、实用的OCR工具库,助力开发者训练出更好的模型,并应用落地。PaddleOCR包括文本检测模型和文本识别模型两个部分,支持多种语言和复杂情况下的文字识别。
4.EasyOCR
EasyOCR是基于Tesseract OCR引擎的OCR识别库,用于图像识别输出文本,目前支持80多种语言。此外,EasyOCR还具有更好的文本排列和字检测准确度,并且易于使用和快速部署。
5.MMOCR
MMOCR是基于PyTorch和MMDetection的开源工具箱,专注于文本检测、文本识别以及相应的下游任务,如关键信息提取。它在各种场景下都具有出色的性能,可以满足复杂场景下的OCR需求。
6.simple-ocr-opencv
simple-ocr-opencv是基于OpenCV和Numpy的OCR识别引擎。它提供了一种简单但可靠的方法来处理常见的OCR任务,可以轻松地集成到您的Python工程中。
7.OCRmyPDF
OCRmyPDF是基于Tesseract-OCR开发、训练的文字识别提取的开源项目。它可以将扫描或图像文件中的文本转换为可编辑的PDF文档。
8.Umi-OCR
Umi-OCR是基于PaddleOCR实现的一款开源的文字识别工具。它可以快速为您生成高质量的OCR模型,并提供简单易用的API,支持多种语言和文件格式。它特别适用于需要进行自定义训练的OCR应用程序。
三、八大OCR开源工具基本使用命令
1.Tesseract
官方地址:https://github.com/tesseract-ocr/tesseract
-
git clone https:
/
/github.com
/tesseract-ocr
/tesseract.git
-
cd tesseract
-
.
/autogen.sh
-
.
/configure
-
make
-
sudomake install
- 1
2.Tesseract.js
官方地址:https://github.com/naptha/tesseract.js
-
import
Tesseract
from
'tesseract.js';
-
Tesseract.
recognize(
'/path/to/image.png')
-
.
then(
function(
result){
-
console.
log(result.
text);
-
})
- 1
3.PaddleOCR
官方地址:https://github.com/PaddlePaddle/PaddleOCR
pip install paddleocr
使用示例:
-
import paddleocr
-
# 初始化识别器
-
ocr
= paddleocr.OCR()
-
# 读取图像文件
-
img_path
=
'/path/to/image.png'
-
img
= paddleocr.
read_image(img_path)
-
# 进行OCR识别
-
result
= ocr.ocr(img)
-
# 输出识别结果
-
for
line
in result:
-
print(
line)
- 1
4.EasyOCR
官方地址:https://github.com/JaidedAI/EasyOCR
pip install easyocr
使用示例:
-
import easyocr
-
#初始化OCR识别器
-
reader
= easyocr.Reader([
'en',
'ch'])
-
#读取图像文件
-
img_path
=
'/path/to/image.png'
-
img
= easyocr.imgproc.
read(img_path)
-
#进行OCR识别
-
result
= reader.readtext(img)
-
#输出识别结果
-
for
line
in result:print(
line)
- 1
5.MMOCR
官方地址:https://github.com/open-mmlab/mmocr
pip install mmocr
使用示例:
-
import mmocr
-
# 初始化OCR识别器
-
pipeline
= mmocr.Pipeline(cnotallow
=
'configs/textrecog/detector/tp_det_mv3_db.yml')
-
# 读取图像文件
-
img_path
=
'/path/to/image.png'
-
img
= mmcv.imread(img_path)
-
# 进行OCR识别
-
result
= pipeline(img)
-
# 输出识别结果
-
for
line
in result:
-
print(
line[
'text'])
- 1
6.simple-ocr-opencv
官方地址:https://github.com/goncalopp/simple-ocr-opencv
pip install simple-ocr-opencv
使用示例:
-
import cv2
-
from simple_ocr
import OCR
-
# 初始化OCR识别器
-
ocr = OCR()
-
# 读取图像文件
-
img_path =
'/path/to/image.png'
-
img = cv2.imread(img_path)
-
# 进行OCR识别
-
result = ocr.ocr(img)
-
# 输出识别结果
-
print(result)
- 1
7.OCRmyPDF
官方地址:https://github.com/ocrmypdf/OCRmyPDF
pip install ocrmypdf
使用示例:
ocrmypdf /path/to/input.pdf /path/to/output.pdf
- 1
8.Umi-OCR
官方地址:https://github.com/umi-lib/UMI-OCR
pip install umi-ocr
使用示例:
-
import umi_ocr
-
# 初始化识别器
-
ocr = umi_ocr.OCR()
-
# 读取图像文件
-
img_path =
'/path/to/image.png'
-
img = umi_ocr.read_image(img_path)
-
# 进行OCR识别
-
result = ocr.ocr(img)
-
# 输出识别结果
-
print(result)
- 1
四、OCR实际应用场景
在本文中,我们介绍了八种常见的开源OCR框架和工具,包括Tesseract、Tesseract.js、PaddleOCR、EasyOCR、MMOCR、simple-ocr-opencv、OCRmyPDF和Umi-OCR。这些工具具有不同的特点和优势,可以根据实际需要进行选择。下面列出了这些工具的一些实际应用场景:
Tesseract:广泛应用于图像识别和文本转换领域,如扫描仪、数字化文档等。
Tesseract.js:用于网页端OCR识别,可实现将图像中的文字转为可编辑文本,适用于在线编辑器、智能表单、在线阅读器等应用场景。
PaddleOCR:适用于复杂文本场景下的OCR识别,比如身份证、银行卡、车牌等。
EasyOCR:适用于文本排列和字检测准确度要求较高的 OCR 应用场景,如名片识别、发票识别、商品标签识别等。
MMOCR:适用于中英文混合、竖排文字、非结构化场景下的OCR识别,如手写字、表格、小说等。
simple-ocr-opencv:适用于处理常见的OCR任务,如身份证、营业执照、车牌等。
OCRmyPDF:将扫描或图像文件中的文本转换为可编辑的PDF文档,适用于需要编辑PDF文档的场景。
Umi-OCR:可以帮助用户快速生成高质量的OCR模型,并支持多种语言和文件格式。适用于需要自定义训练的OCR应用程序。
五、OCR技术国内应用情况
OCR技术在信创领域中应用广泛,主要包括文字识别、表格识别、印刷体识别以及各种证件的识别。随着各种开源OCR工具的出现和不断完善,OCR技术得到了广泛应用,国内OCR技术也已相对成熟,并且得到广泛应用。常见的厂商有图鼎科技、中标信息、神州数码、讯飞OCR等,互联网公司如阿里云、腾讯云也推出了自己的OCR技术产品。
这些OCR技术可以应用于各个领域,例如:
- 电子商务:在订单处理、发票管理、商品识别等方面的应用,提高效率和准确性。
- 金融服务:在银行卡、身份证、证券账户等领域的识别,可以提高客户体验,降低工作量和出错率。
- 医疗健康:在病历管理、药品监管、个人隐私信息保护等方面的应用也十分重要。
除此之外,OCR技术还可以用于政务管理、教育、交通运输、安防等各个领域。应用范围广泛,具有广阔的市场前景。
当然,OCR技术也存在一些缺陷。例如,一些手写文字识别的准确性尚待提高。在复杂环境下、格式多样化的文档处理中,OCR技术也可能出现误识别等问题。此外,OCR技术也需要不断地优化和改进,以适应新场景的需求并提高产品质量。
总体来说,OCR技术在信创领域中将会越来越重要,并且其应用也会不断扩展和深化。各家厂商可以通过技术创新、算法优化、运营推广等方面提高产品性能和竞争力,为用户带来更好的体验和服务。
综上所述,OCR技术作为一项重要的人工智能技术,已经得到了广泛的应用,并且将会越来越重要。通过使用开源的OCR框架和工具,开发者可以更灵活地构建高质量的OCR应用程序,实现更多实际的场景应用。
最后,推荐一款开源应用开发神器
关于目前低代码在技术领域很活跃!
低代码是什么?一组数字技术工具平台,能基于图形化拖拽、参数化配置等更为高效的方式,实现快速构建、数据编排、连接生态、中台服务等。通过少量代码或不用代码实现数字化转型中的场景应用创新。它能缓解甚至解决庞大的市场需求与传统的开发生产力引发的供需关系矛盾问题,是数字化转型过程中降本增效趋势下的产物。
这边介绍一款好用的低代码平台——JNPF快速开发平台。近年在市场表现和产品竞争力方面表现较为突出,采用的是最新主流前后分离框架(SpringBoot+Mybatis-plus+Ant-Design+Vue3)。代码生成器依赖性低,灵活的扩展能力,可灵活实现二次开发。
以JNPF为代表的企业级低代码平台为了支撑更高技术要求的应用开发,从数据库建模、Web API构建到页面设计,与传统软件开发几乎没有差异,只是通过低代码可视化模式,减少了构建“增删改查”功能的重复劳动,还没有了解过低代码的伙伴可以尝试了解一下。
应用体验入口:https://www.jnpfsoft.com/?csdn
有了它,开发人员在开发过程中就可以轻松上手,充分利用传统开发模式下积累的经验。所以低代码平台对于程序员来说,有着很大帮助。
十二款开源OCR开箱测评,文字识别哪家强
OCR(Optical Character Recognition,光学字符识别)作为信息爆炸时代的“炼金术士”,以其高效且相对精确的性能,在海量纸质文档、扫描件、图片的文字信息提取方面发挥着举足轻重的作用。其广泛应用于教育、医疗、交通等多个行业领域,其重要性不言而喻。然而,目前开源OCR工具种类繁多,不同场景图像的识别效果却参差不齐,这给开发人员的选型工作带来了不小的挑战。为了尽可能全面测试OCR工具的识别能力,本次测评精心挑选了12款开源OCR工具,在五类不同数据集上进行横向评比,以期为用户提供更为准确、客观的选型参考。
开源OCR介绍与评测系列共分为三篇,本文为文字识别能力篇,评测开源OCR基本的文字识别能力,包括印刷中文、印刷英文、手写中文等三类基本类型,以及复杂自然场景和变形字体两类附加测评;第二篇为结构信息能力篇,对表格、票证等结构化信息的OCR能力进行测评;第三篇为OCR Free评测篇,评测开源多模态大模型对图片信息的提取和分析能力。
本次开源OCR文字识别能力测评选取了12款OCR工具,其中,独立工具有:PaddleOCR、RapidOCR、读光(开源版)、ChineseOCR、EasyOCR、Tesseract、OcrLiteOnnx、Surya、docTR、JavaOCR;文档分析OCR组件:RagFlow、Unstructured。
备注:本次测评均使用OCR工具自身提供的预训练模型进行测试,测试均采用工具的示例中提供的参数设置。除开源工具以外,选取百度OCR云服务测试结果作为参照。
各OCR工具的测试版本如下:
PaddleOCR V2.7.5
读光OCR
DocTR V0.7.1
Tesseract V5.3.4
ChineseOCR
OcrLiteOnnx V1.6.1
RapidOCR V1.3.22
JavaOCR V1.0
EasyOCR V1.7.0
RAGflow V0.7.0
Unstructured V0.14.0
Surya V0.4.9
百度OCR V2.0
为了全面评测OCR工具各种场景下的识别和解析能力,本次测评收集整理了多种类型文字识别的图片数据,包括印刷中英文、自然场景、手写文字和验证码等方面数据集,具体文字识别数据集分类如下:
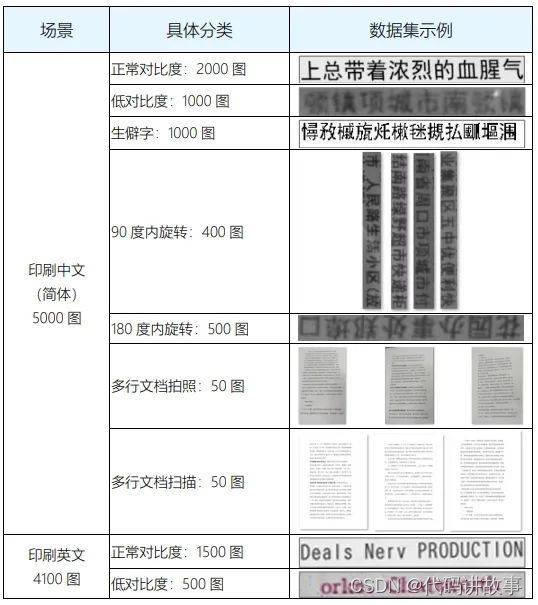

文字识别能力主要评测OCR工具对文字的检测和识别能力,包括支持识别的字符集规模(生僻字),字体形变(字体、艺术字),图像旋转、形变、干扰信息、明暗、模糊等外部因素影响。
备注:文字识别能力只考察是否正确识别出字符,不考察文字结构信息(即输出结果的文字顺序)。其中,中文统计粒度为字,英文为单词(区分大小写),中英文标点符号相互区别。
字符识别准确率(Precision):正确识别的字符数/识别输出总字符数
字符识别召回率(Recall):正确识别的字符数/验证集总字符数
字符识别综合评分(F-Score):2PrecisionRecall/(Precision+Recal)
平均响应时间:基准样本识别总时间/样本数量。
测评结果
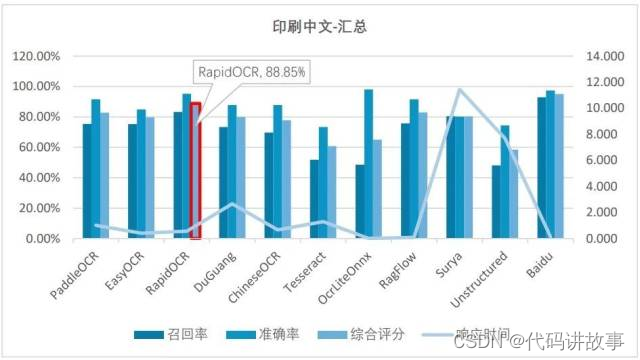
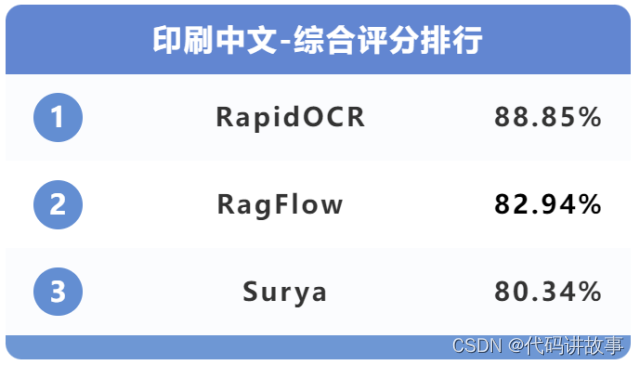
(1)印刷中文的综合测评结果为:
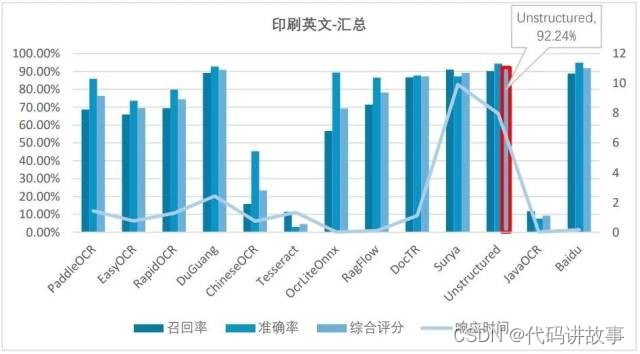
(2)印刷英文的综合测评结果为:
(3)变形字体的艺术字测评结果为:

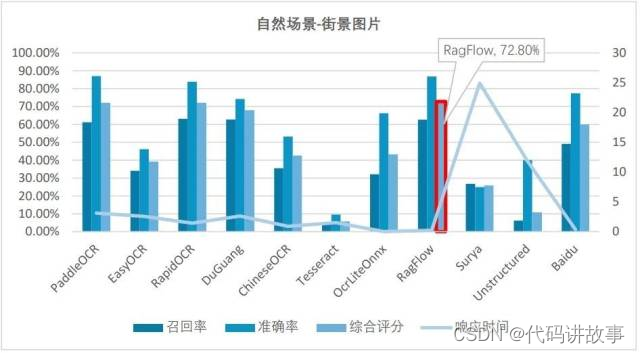
(4)自然场景的街景图片测评结果为:
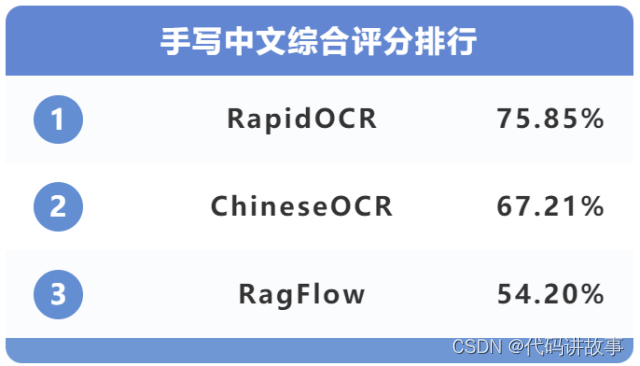
(5)手写中文的综合测评结果为:

印刷中文识别准确度测试中,综合前三分别是RapidOCR、RagFlow和Surya。
在印刷英文识别准确度测试环节,综合前三分别是Surya、Unstructured和读光OCR,还是国外开源软件领先。
在各种变形字体(艺术字、验证码等非标准字体)场景下,由于本次测评仅采用各OCR工具自身提供的预训练模型进行测试,识别准确度均较低,如需提高变形字体的准确率需要针对变形字体进行专项训练。

在复杂多行文字的街景场景中,前三名分别是RagFlow、RapidOCR和PaddleOCR,它们的综合评分相当接近,均略高于70%。

在手写中文识别场景下,综合前三分别是RapidOCR、ChineseOCR和RagFlow。
在响应时间方面,表现优异的有OcrLiteOnnx(0.01秒级)、RagFlow(0.1秒级),响应非常快。另外,ChineseOCR、EasyOCR和RapidOCR表现也不错,平均时间小于1秒。

随着大语言模型的快速发展和应用,我们对OCR识别的需求不再局限于字的识别,对于结构化信息抽取的需求越来越大。我们将在下一篇将对开源OCR工具的结构分析能力进行评测。同时,针对OCR Free类的大模型,如TextMoneky、DocPedia、UReader、Pix2struct、Donut,以及国内研究的InterVL等,我们计划开展一次OCR Free类评测,敬请期待。
最近百度飞桨团队推出了一款基于文心大模型的通用图像关键信息抽取工具PP-ChatOCR。它结合了OCR文字识别和文心一言大语言模型,可以在多种场景下提取图像中的关键信息,效果非常惊艳。而传统的OCR识别技术的准确率容易受到多种因素影响,例如图像质量、字符布局、字体样式等。但当我们将OCR技术与大语言模型相结合时,可以避免繁杂的规则后处理,提升泛化能力,从而能够更智能、准确地理解和利用文本信息。(官方说明)
这里以手机app截图为例,定制化提取其中的感兴趣信息。实现OCR模型提取文字信息,输入LLM分析其识别结果直接给出所关注的关键信息——这就是ChatOCR的核心思想。
技术方案
文字识别模型:PP-OCRv4;
LLM:百度“文心一言”
开发环境:Python 3.10 + PaddlePaddle深度学习框架
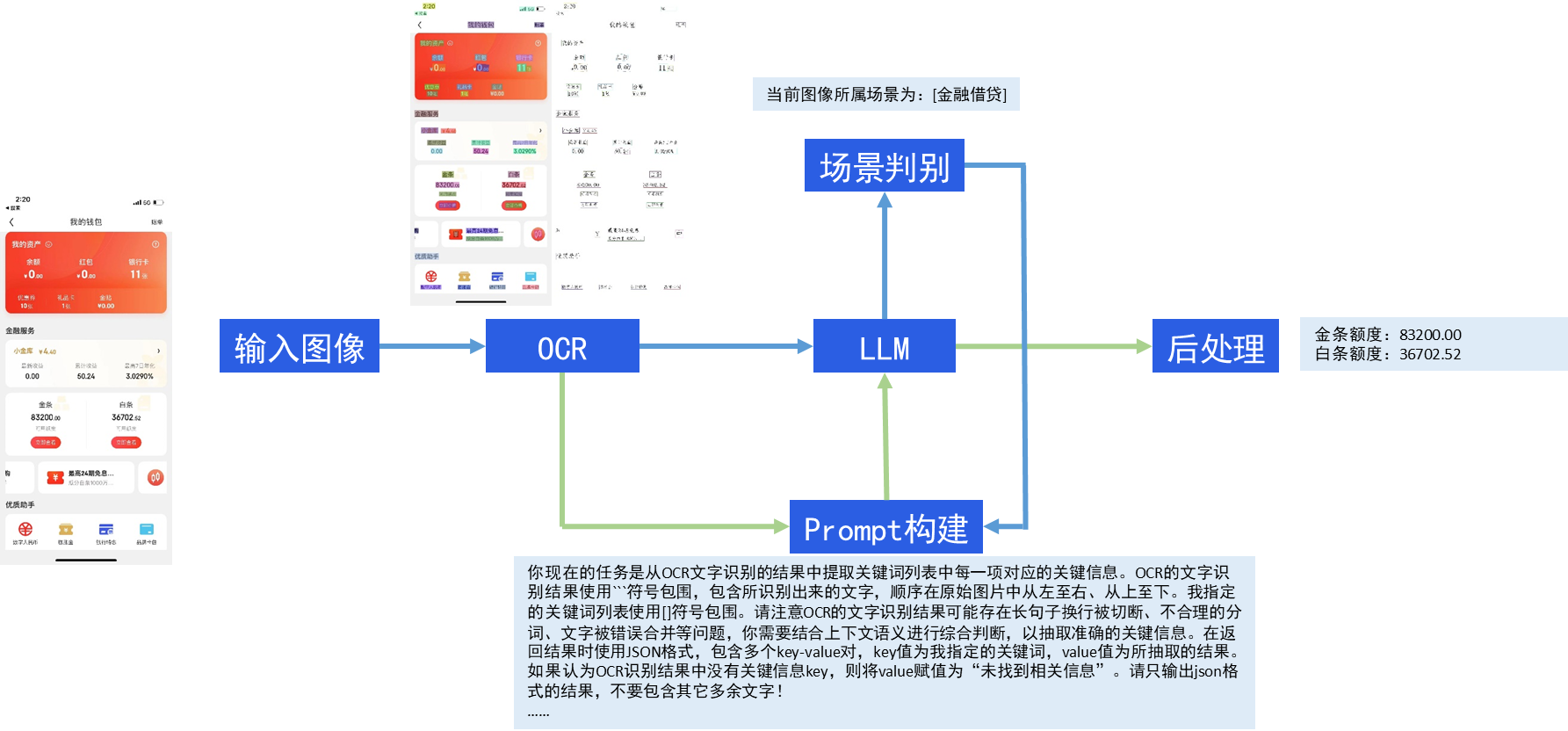
存在的问题及解决思路
LLM无法100%准确地判别图像所属的场景
使用官方给出的思路,即给出场景列表,让大模型识别OCR结果属于哪个场景,然后将其作为key去提前写好的few-shot例子中找到对应场景下的信息抽取结果来指导LLM,然后LLM再根据用户提供的关键信息项和OCR结果得到最终的结果。
而这种方式依赖于LLM能准确无误的将OCR结果对应到给定列表中的某一个场景,若OCR结果不属于给定场景列表中的任何一个,或者将其错误的归于其他场景,都会导致关键信息提取失败,前者会使程序报错,而后者可能导致不正确的信息提取结果。(实测非卡证场景识别不稳定)
解决思路:取消场景识别这一步骤,直接输入相关例子让LLM学习
大量场景例子无法一次性喂入LLM
LLM学习的例子太多,token数量的增加会导致成本的上升和推理时间的增加。 ———超过一次输入问题的2000字数限制
解决思路:构建多轮对话,逐次学习例子
LLM的记忆遗忘
多轮对话中bot的回应需要自己写,这个上下文信息会影响到后续的推理结果。对话轮数(例子)越多,LLM对前文的记忆越弱,导致忘记任务要求。
解决思路:in-context learning prompt工程

替换文心一言
参考链接:https://aistudio.baidu.com/projectdetail/6629280
LangChain
一个基于LLM来开发应用程序的框架,提供Chain接口来继承各种LLM相关模块。可以读取结构化或非结构化数据,然后用LLM来进行信息摘要或信息提取。高度集成化,支持众多模型和工具。
大型多模态模型(Large Multimodal Model, LMM)
直接使用目前的SOTA LMM来在业务场景下的OCR图片集上fine-tune,然后进行OCR-VQA或者关键信息提取。
论文:On the Hidden Mystery of OCR in Large Multimodal Models, Arxiv 2023.
文章在多个Text及OCR benchmark上测试了目前的LMMs的Zero-Shot迁移性能,给出了利用LMM提升OCR识别性能的思路。
开源大模型汇总
以下仅列出主要的、关键的、常用的大模型。
LLaMA —— Meta 大语言模型
LLaMA 语言模型全称为 “Large Language Model Meta AI”,是 Meta 的全新大型语言模型(LLM),这是一个模型系列,根据参数规模进行了划分(分为 70 亿、130 亿、330 亿和 650 亿参数不等)。
其中 LaMA-13B(130 亿参数的模型)尽管模型参数相比 OpenAI 的 GPT-3(1750 亿参数) 要少了十几倍,但在性能上反而可以超过 GPT-3 模型。更小的模型也意味着开发者可以在 PC 甚至是智能手机等设备上本地运行类 ChatGPT 这样的 AI 助手,无需依赖数据中心这样的大规模设施。
Stanford Alpaca —— 指令调优的 LLaMA 模型
Stanford Alpaca是一个指令调优的 LLaMA 模型,从 Meta 的大语言模型 LLaMA 7B 微调而来。
Stanford Alpaca 让 OpenAI 的 text-davinci-003 模型以 self-instruct 方式生成 52K 指令遵循(instruction-following)样本,以此作为 Alpaca 的训练数据。
在测试中,Alpaca 的很多行为表现都与 text-davinci-003 类似,且只有 7B 参数的轻量级模型 Alpaca 性能可与 GPT-3.5 这样的超大规模语言模型性能媲美。
Lit-LLaMA —— 基于 nanoGPT 的语言模型
Lit-LLaMA 是一个基于 nanoGPT 的 LLaMA 语言模型的实现,支持量化、LoRA 微调、预训练、flash attention、LLaMA-Adapter 微调、Int8 和 GPTQ 4bit 量化。
主要特点:单一文件实现,没有样板代码;在消费者硬件上或大规模运行;在数值上等同于原始模型。
Lit-LLaMA认为人工智能应该完全开源并成为集体知识的一部分。但原始的 LLaMA 代码采用 GPL 许可证,这意味着使用它的任何项目也必须在 GPL 下发布。这 “污染” 了其他代码,阻止了与生态系统的集成。Lit-LLaMA使用Apache 2.0协议,永久性地解决了这个问题。
GPT4All —— 基于 LLaMA 的大语言模型
GPT4All是基于 LLaMa 的~800k GPT-3.5-Turbo Generations 训练出来的助手式大型语言模型,这个模型接受了大量干净的助手数据的训练,包括代码、故事和对话,提供的模型性能接近text-davinci-003。
给出了多平台的桌面版应用,可以在本地的CPU上运行。同时提供Python的API,可以在本地自己调用下载好的模型完成问答。
Chinese-LLaMA
1、Chinese-LLaMA-Alpaca
在Apache-2.0协议下开源了中文LLaMA模型和指令精调的Alpaca大模型,以进一步促进大模型在中文NLP社区的开放研究。这些模型在原版LLaMA的基础上扩充了中文词表并使用了中文数据进行二次预训练,进一步提升了中文基础语义理解能力。同时,中文Alpaca模型进一步使用了中文指令数据进行精调,显著提升了模型对指令的理解和执行能力。文档全面,支持本地推理部署,还在持续更新。
2、Chinese-Vicuna —— 一个中文低资源的LLaMA+lora方案
A Chinese Instruction-following LLaMA-based Model。项目目的是希望基于LLaMA+instruction数据构建一个中文的羊驼模型,并帮助大家能快速学会使用引入自己的数据,并训练出属于自己的小羊驼(Vicuna)。
方案的优势是参数高效,显卡友好,部署简易:
在一张2080Ti(11G)上可以对Llama-7B进行指令微调 (7b-instruct)
在一张3090(24G)上可以对Llama-13B进行指令微调 (13b-instruct)
即使是长度为2048的对话,在3090上也可以完成Llama-7B的微调;使用5万条数据即可有不错效果 (chatv1)
领域微调的例子:医学问答 和 法律问答。(medical and legal)
支持qlora-4bit,使用4bit可以在2080Ti上完成13B的训练
可在2080Ti/3090上轻松部署,支持多卡同时推理,可进一步降低显存占用
项目包括
finetune模型的代码
推理的代码
仅使用CPU推理的代码 (使用C++)
下载/转换/量化Facebook llama.ckpt的工具
其他应用
详细文档
3、伶荔 (Linly) —— 大规模中文语言模型
深圳大学与腾讯AI Lab推出。相比已有的中文开源模型,伶荔模型具有以下优势:
在 32*A100 GPU 上训练了不同量级和功能的中文模型,对模型充分训练并提供强大的 baseline。据知,33B 的 Linly-Chinese-LLAMA 是目前最大的中文 LLaMA 模型。
公开所有训练数据、代码、参数细节以及实验结果,确保项目的可复现性,用户可以选择合适的资源直接用于自己的流程中。
项目具有高兼容性和易用性,提供可用于 CUDA 和 CPU 的量化推理框架,并支持 Huggingface 格式。
目前公开可用的模型有:
Linly-Chinese-LLaMA-2 (7B、13B) 模型:使用 LLaMA2 扩充中文词表,在混合语料上进行增量预训练,模型仍在迭代中,将定期更新模型权重。
Linly-Chinese-Falcon(7B): Chinese-Falcon 模型在 Falcon 基础上扩充中文词表,在中英文数据上增量预训练。模型以 Apache License 2.0 协议开源,支持商业用途。
Linly-Chinese-LLaMA:中文基础模型,基于 LLaMA 在高质量中文语料上增量训练强化中文语言能力,现已开放 7B、13B 和 33B 量级,65B 正在训练中。
Linly-ChatFlow:中文对话模型,在 400 万指令数据集合上对中文基础模型指令精调,现已开放 7B、13B 对话模型。
Linly-ChatFlow-int4 :ChatFlow 4-bit 量化版本,用于在 CPU 上部署模型推理。
GLM —— 用于自然语言理解和生成的通用预训练框架
GLM (General Language Model)是清华大学推出的一种使用自回归填空目标进行预训练的通用语言模型,可以针对各种自然语言理解和生成任务进行微调。
GLM 通过添加 2D 位置编码并允许以任意顺序预测跨度来改进空白填充预训练,从而在 NLU 任务上获得优于 BERT 和 T5 的性能。同时,GLM 可以通过改变空白的数量和长度对不同类型的任务进行预训练。在横跨 NLU、条件和无条件生成的广泛任务上,GLM 在给定相同的模型大小和数据的情况下优于 BERT、T5 和 GPT,并从单一的预训练模型中获得了 1.25 倍 BERT Large 参数的最佳性能,表明其对不同下游任务的通用性。
关于 GLM 的详细描述可参考论文 GLM: General Language Model Pretraining with Autoregressive Blank Infilling (ACL 2022)
ChatGLM-6B 就是在 GLM 框架的基础上为中文 QA 和对话进行了优化。
ChatGLM-6B —— 中英双语对话语言模型
ChatGLM-6B()是一个开源的、支持中英双语问答的对话语言模型,并针对中文进行了优化。该模型基于 General Language Model (GLM) 架构,具有62亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。
ChatGLM-6B 使用了GLM框架,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62亿参数的 ChatGLM-6B 虽然规模不及千亿模型,但大大降低了推理成本,提升了效率,并且已经能生成相当符合人类偏好的回答。
MLC LLM —— 本地大语言模型
MLC LLM是一种通用解决方案,它允许将任何语言模型本地部署在各种硬件后端和本地应用程序上。
此外,MLC LLM 还提供了一个高效的框架,供使用者根据需求进一步优化模型性能。MLC LLM 旨在让每个人都能在个人设备上本地开发、优化和部署 AI 模型,而无需服务器支持,并通过手机和笔记本电脑上的消费级 GPU 进行加速。
mPLUG-Owl —— 多模态大语言模型
阿里达摩院提出的多模态 GPT 的模型:mPLUG-Owl,基于 mPLUG 模块化的多模态大语言模型。它不仅能理解推理文本的内容,还可以理解视觉信息,并且具备优秀的跨模态对齐能力。
论文:https://arxiv.org/abs/2304.14178
DEMO:https://huggingface.co/spaces/MAGAer13/mPLUG-Owl
全网开源最优秀的 ocr 文字识别项目:
https://github.com/PaddlePaddle/PaddleOCR
https://github.com/Layout-Parser/layout-parser
https://github.com/Calamari-OCR/calamari
https://github.com/hiroi-sora/Umi-OCR
https://github.com/tesseract-ocr/tesseract
https://github.com/naptha/tesseract.js
https://github.com/ocropus
https://github.com/JaidedAI/EasyOCR
https://github.com/Ucas-HaoranWei/Vary
https://github.com/OpenBMB/MiniCPM-V

