
热门标签
热门文章
- 1基于FPGA的音频信号的FIR滤波(Matlab+Modelsim验证)
- 2Git 基本操作命令汇总_git基本操作命令
- 3SSH远程终端神器,你在用哪一款_ssh工具
- 4Python史上最全知识重点(超详细版)进阶篇_python 进阶 笔记
- 5Flutter 开发3:创建第一个Flutter应用_android studio安装flutter
- 6ARM处理器——I.MX6ULL学习总结_i.mx6ull有srio吗
- 7《强化学习周刊》第8期:强化学习应用之自然语言处理_far-ass: fact-aware reinforced abstractive sentenc
- 8spring使用@value注解读取properties文件失败或者@value值为注解值_读取properties配置文件失败
- 915年研发经验博士手把手教学:从零开始搭建智能客服_ai智能客服设计思路
- 10FPGA学习笔记——以太网_phy与fpga连接
当前位置: article > 正文
openchat-3.5-1210:迄今为止最优秀的开源7B模型,支持中文_openchat3.5
作者:小桥流水78 | 2024-08-03 08:01:44
赞
踩
openchat3.5
似乎潜力很大,只有很少的中文数据,但是ceval,cmmlu评测效果还挺高的

图片
| Model | # Params | Average | MT-Bench | HumanEval | BBH MC | AGIEval | TruthfulQA | MMLU | GSM8K | BBH CoT |
|---|---|---|---|---|---|---|---|---|---|---|
| OpenChat-3.5-1210 | 7B | 63.8 | 7.76 | 68.9 | 49.5 | 48.0 | 61.8 | 65.3 | 77.3 | 61.8 |
| OpenChat-3.5 | 7B | 61.6 | 7.81 | 55.5 | 47.6 | 47.4 | 59.1 | 64.3 | 77.3 | 63.5 |
| ChatGPT (March)* | ? | 61.5 | 7.94 | 48.1 | 47.6 | 47.1 | 57.7 | 67.3 | 74.9 | 70.1 |
| OpenHermes 2.5 | 7B | 59.3 | 7.54 | 48.2 | 49.4 | 46.5 | 57.5 | 63.8 | 73.5 | 59.9 |
| OpenOrca Mistral | 7B | 52.7 | 6.86 | 38.4 | 49.4 | 42.9 | 45.9 | 59.3 | 59.1 | 58.1 |
| Zephyr-β^ | 7B | 34.6 | 7.34 | 22.0 | 40.6 | 39.0 | 40.8 | 39.8 | 5.1 | 16.0 |
| Mistral | 7B | - | 6.84 | 30.5 | 39.0 | 38.0 | - | 60.1 | 52.2 | - |
请注意本模型没有针对性训练中文(中文数据占比小于0.1%)。ceval
| Model | Avg | STEM | Social Science | Humanities | Others |
|---|---|---|---|---|---|
| ChatGPT | 54.4 | 52.9 | 61.8 | 50.9 | 53.6 |
| OpenChat | 47.29 | 45.22 | 52.49 | 48.52 | 45.08 |
cmmlu-5shot
| Models | STEM | Humanities | SocialSciences | Other | ChinaSpecific | Avg |
|---|---|---|---|---|---|---|
| ChatGPT | 47.81 | 55.68 | 56.5 | 62.66 | 50.69 | 55.51 |
| OpenChat | 38.7 | 45.99 | 48.32 | 50.23 | 43.27 | 45.85 |
图片
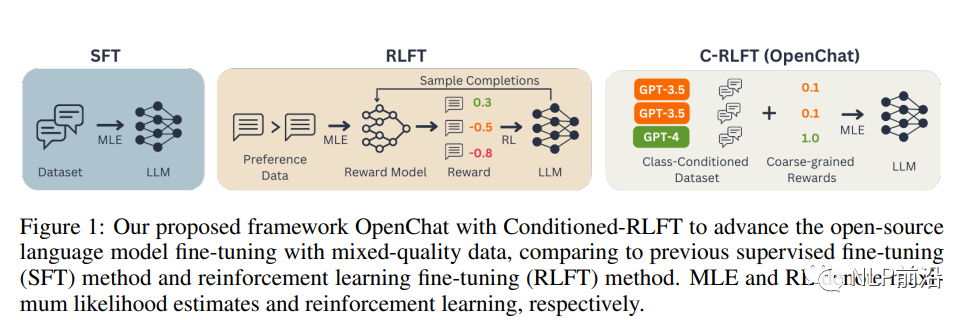
首先,我们需要了解两种常见的微调方法:监督式微调(SFT)和强化学习微调(RLFT)。SFT直接使用高质量的对话数据集对预训练的语言模型进行微调,而RLFT则根据人类偏好反馈或预定义的分类器建立奖励模型,并通过强化学习最大化估计奖励。然而,这两种方法都存在局限性。SFT要求训练数据具有很高的质量,而RLFT需要昂贵的人类专家注释来收集高质量的成对或排序偏好数据。
为了解决这些问题,OpenChat框架提出了C-RLFT方法。在这个方法中,我们考虑一个通用的非成对(或非排序)SFT训练数据,包括少量的专家数据和大量的次优数据。我们将不同数据来源视为粗粒度的奖励标签,并学习一个类条件策略来利用互补的数据质量信息。有趣的是,C-RLFT中的最优策略可以通过单阶段、无需强化学习的监督学习轻松解决,从而避免了昂贵的人类偏好标签收集。
OpenChat框架包括以下几个关键步骤:
类条件数据集和奖励:根据不同的数据来源(如GPT-4和GPT-3.5),为每个示例分配类标签,并构建类条件数据集Dc。然后,根据类标签为每个示例分配粗粒度奖励。
通过C-RLFT进行微调:我们将预训练的LLM视为类条件策略πθ(y|x, c),并使用类信息增强的参考策略πc而不是原始预训练的LLM π0对其进行正则化。这样,我们可以在KL正则化的强化学习框架下优化目标函数。
模型推理:在推理阶段,我们使用与GPT-4对话相同的特定提示,以便仅生成高质量响应。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小桥流水78/article/detail/922139?site
推荐阅读
相关标签

