
- 1MySQL彻底卸载并且重新安装(配图文)_mysql卸载重装
- 2Github 2024-06-19 C开源项目日报 Top9
- 3设计模式-工厂模式
- 4解决命令行(cmd)使用 pip 安装了模块,但在 PyCharm 中导入时遇到“没有这个模块”的错误_cmd安装了模块 pycharm确提示找不到对应模块
- 5Unity 实现鼠标左键进行射击_unity 鼠标点击射击物体
- 6使用memtester工具对嵌入式Linux内存压力测试_memtester内存压力测试占用内存越来越多(1)_linux memtester
- 7全球IT界大佬权势排行:盖茨榜首马云第六_it界大佬简介
- 8云计算-无服务器计算与AWS Lambda (Serverless Computing with AWS Lambda)_aws无服务器计算
- 9编写了一个在线 Datasheet 曲线图取点工具_在线获取点数据
- 10《码农职场》(IT人求职就业手册)导读和理性书评_码农职场:it人求职就压手册
什么是LLM?了解AI大型语言模型_ai llm
赞
踩
随着人工智能(AI)领域的不断发展,大型语言模型(LLM)已成为推动技术创新的前沿力量。这些高度进阶的AI语言模型不仅重塑了我们与机器沟通的方式,更在众多行业中展现出其强大的应用潜质。但究竟什么是LLM,以及它们是如何运作的呢?本文将深入探讨LLM的核心概念、运作原理及其在当代科技中的关键作用。
LLM:AI语言模型的核心
LLM(大型语言模型)代表了人工智能语言模型的一个重要分支,它们是利用深度学习技术构建的先进模型,专门设计来理解和生成自然语言。这些模型的基本构架能够处理和分析庞大的文本数据集,从而学习到语言的深层结构和语义规则。
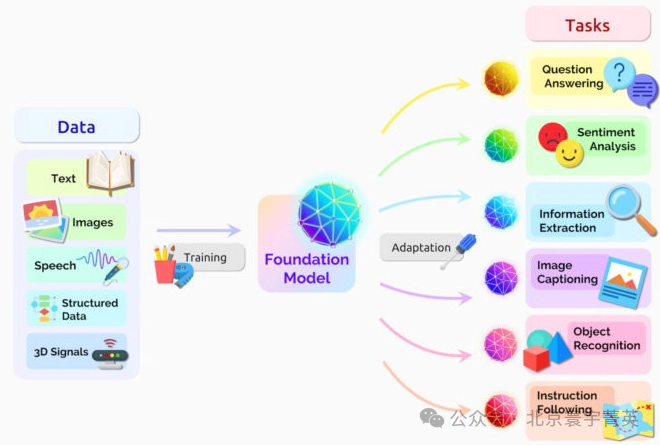
核心技术与学习机制
LLM的核心技术源自于深度学习中的神经网络,尤其是转换器(Transformer)构架,这使得LLM能够有效捕捉文本中的长距离依赖关系,进而更准确地理解语言的脉络和细节。通过对大规模文本数据的训练,LLM能学习到丰富的语言知识,包括词汇、语法、语境等各个层面。
转换器构架的优势
转换器构架不仅在自然语言处理任务中表现出色,其设计的灵活性和扩展性也为LLM提供了处理各种复杂语言任务的能力。无论是文本生成、机器翻译、文本摘要还是问答系统,转换器构架都能够提供卓越的性能。此外,转换器构架的高效率也使得LLM在训练和推理过程中,能够处理庞大的数据集和复杂的模型结构。
特点和优势
-
动态计算图:LLM的动态计算图机制赋予了模型高度的灵活性和直观性,使其能够在执行阶段调整计算流程,进而调节各种复杂的语言处理任务。
-
易于使用:LLM特别设计了友好的API,使得从概念到实际应用的转换过程更加简便,对Python开发者尤其友好。
-
强大的社群和生态系统:拥有活跃的开发者社群和丰富的预训练模型库,为LLM的学习和应用提供了强大支持。
-
适用于研究和生产:通过TorchScript等工具,LLM可以轻松转换为适用于生产环境的格式,满足商业和学术需求。
-
支持GPU加速:LLM与CUDA技术的整合使得模型训练和推理过程大幅加速,有效提高了数据处理效率。
LLM的运作原理
LLM(大型语言模型)的运作原理主要基于转换器(Transformer)构架,这是一种革命性的深度学习技术,于2017年被提出,迅速成为自然语言处理(NLP)领域的核心技术之一。转换器构架的关键创新之处在于自注意力(Self-Attention)机制,这使得模型能够在处理文本数据时,自动识别和赋予不同词语之间关系的不同权重,从而有效地捕捉到长距离依赖关系。
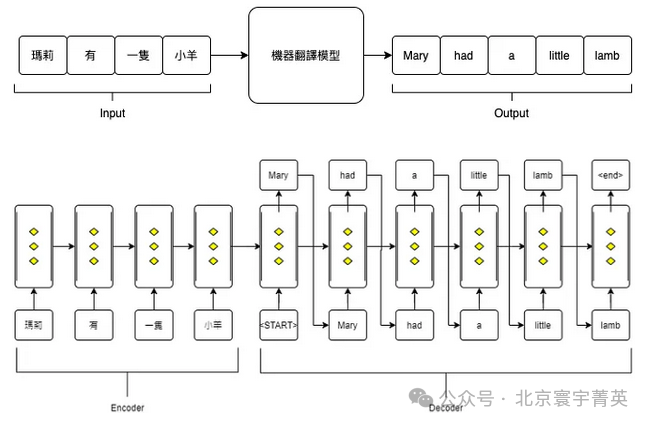
自注意力机制的作用
自注意力机制允许模型在分析每个词语时,考虑到整个文本序列中的所有词语,并计算它们之间的相互影响。这种机制使得LLM能够理解各个词语在特定上下文中的具体含义,进而深入理解整个文本的语义。例如,模型能够识别同一个词在不同语境中的多重含义,并根据上下文确定其正确意义。
面临的挑战和未来发展
尽管转换器以及自注意力构架带来了许多优势,LLM在实际应用中仍面临着一些挑战,如计算资源的大量需求、模型解释性的提升以及生成内容的准确性和偏见问题等。为了解决这些问题,研究人员正在不断优化转换器构架,开发更高效的训练方法,并探索新的模型构架和学习机制。
总之,LLM的运作原理及其基于转换器构架的设计,为理解和生成自然语言提供了强大的支撑,同时也为AI语言模型的未来发展奠定了坚实的基础。随着技术的不断进步,我们可以期待LLM在自然语言处理以及更广泛的人工智能领域中发挥更大的作用。
LLM在实际应用中的表现
从改进搜索引擎的准确性、提供个性化的聊天机器人服务,到支持创作高质量的文本内容,LLM的应用范围极为广泛。它们不仅在技术领域内发挥着重要作用,也正逐步影响着健康医疗、教育、娱乐等多个行业。
应用范围
LLM的应用范围极其广泛,它们能够执行包括文本生成、语言翻译、自然语言理解(NLU)、自然语言生成(NLG)和问答系统在内的多种任务。例如,LLM可以生成新闻文章、撰写程序码、创作诗歌或故事,甚至在法律和医疗领域提供专业建议。此外,LLM在对话系统和虚拟助手的开发中也发挥着关键作用,使得机器能够更自然地与人类进行交流。
结语及展望
随着大型语言模型(LLM)的兴起,我们正步入一个由AI驱动的沟通新时代。这些模型的进步不仅预示着技术创新的新浪潮,也为社会发展开辟了前所未有的道路。然而,随着LLM的能力日益增强,如何确保它们在负责任和伦理的框架内被运用,亦成为了我们必须面对的挑战。
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

