
- 1区块链技术学习笔记(14) 以太坊账户
- 2【Numpy 版本 匹配 Tensorflow & Opencv version】_tensorflow和numpy对应版本
- 3Lattice PCIe IP核配置流程介绍_pcie ip核使用教程
- 4Elasticsearch集群搭建_elasticsearch 集群搭建
- 5Zookeeper实现分布式应用的(主节点HA)及客户端动态更新主节点状态
- 6整合Elasticsearch实现商品搜索_es 分词器 商品搜索
- 7Python:获取Prometheus接口数据并存入MySQL_prometheus 接口
- 8PC端 VUE 官网项目 前端开发 响应式布局(宽+高 等比例缩放)_vue项目pc端同比例放大缩小
- 9Hive最新数据操作详解(超级详细)_hive读写流程
- 10服务端渲染和客户端渲染的比较_web使用服务端渲染与客户端渲染哪种安全性高些
大家都在说的AI大模型微调到底是什么?最易懂的AI知识科普!为你解决对“微调”所有的疑问_ai 微调
赞
踩
当我们谈论AI,谈论人工智能领域时,经常会提到“模型微调”。这个词儿听起来可能有些专业,但它的的确确是解锁AI强大潜力,让AI更加精准地服务于我们的需求,推动人工智能落地的关键。
那么,究竟什么是模型微调?我们为什么需要对模型进行微调?它的作用表现在哪些方面?目前又有哪些主流的微调的方法呢?
今天,我们就用最白话的方式,带大家了解下这个“微调”,到底是在说什么?
什么是微调?
chatgpt说:模型微调(Model Fine-tuning)是指在已经训练好的模型基础上,针对特定任务或数据集进行调整,以获得更好的性能。通常情况下,模型微调是在预训练模型的基础上完成的,它可以提高模型在新任务或新数据集上的表现。
举个例子,如下图,一个与训练出来的什么都会的小羊驼(大语言模型),又通过FineTuning微调,学习了到专业的知识和背景(领域知识),于是它变成了一个领域专家(行业大语言模型)
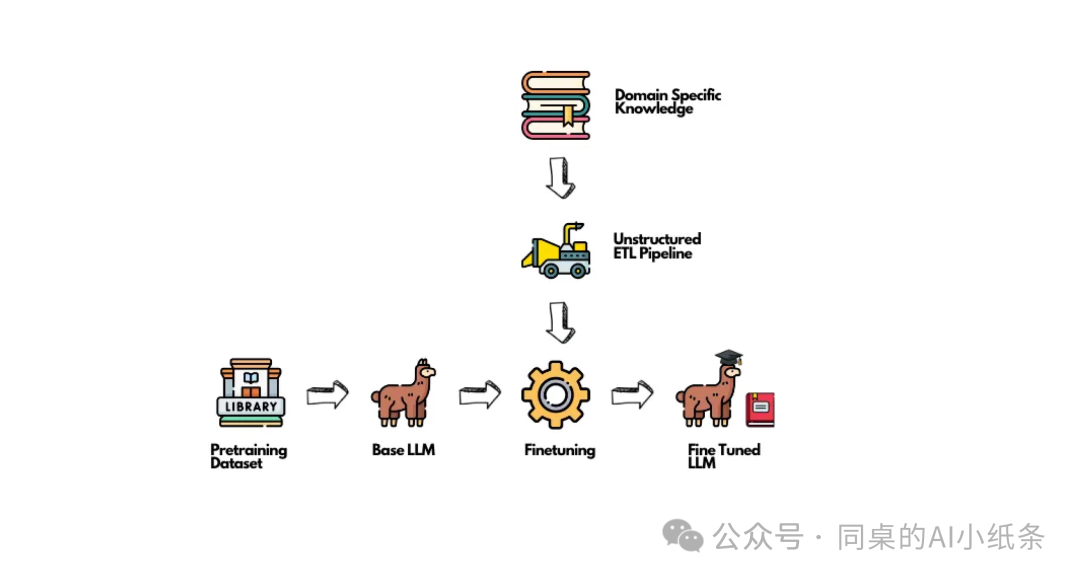
微调,翻译自Fine tuning,简称FT,也被很多人称为“精调”。
从字面意思理解,微调其实相当于在通用大模型的基础上,对超出范围或特定的领域,使用专门的数据集或方法对其进行相应的调整和优化,以提升其在特定领域或任务中的适用性和完成度。
虽然这种方式叫做“微”调,但在实际应用中,它仍然包含全量调整。但是如果从0开始做下游任务全模型的微调,不仅工作量大,成本高,遇上百万级乃至亿级参数的大模型,还可能导致过拟合。(过拟合是什么下面会说)
所以,现阶段人们常说的微调,以在预训练模型基础上针对特定任务或行业需求做局部调整居多。
在技术领域,微调被视为一种应用广泛的深度学习(Deep Learning)尤其是迁移学习(Transfer Learning)技术,一种常用的行业大模型构建方法。它提升着通用大模型在垂直领域的性能,也加速推动着大模型在各行业的落地。
为什么需要微调?
简单来说,微调的最大价值在于让大模型更接地气、更具适用性。
举个例子,如下图,一个会说话的鹦鹉(大语言模型),又学习了专业的关于中国美食知识和背景(领域知识),于是它变成了可以播报美食的舌尖上的鹦鹉(行业大语言模型)
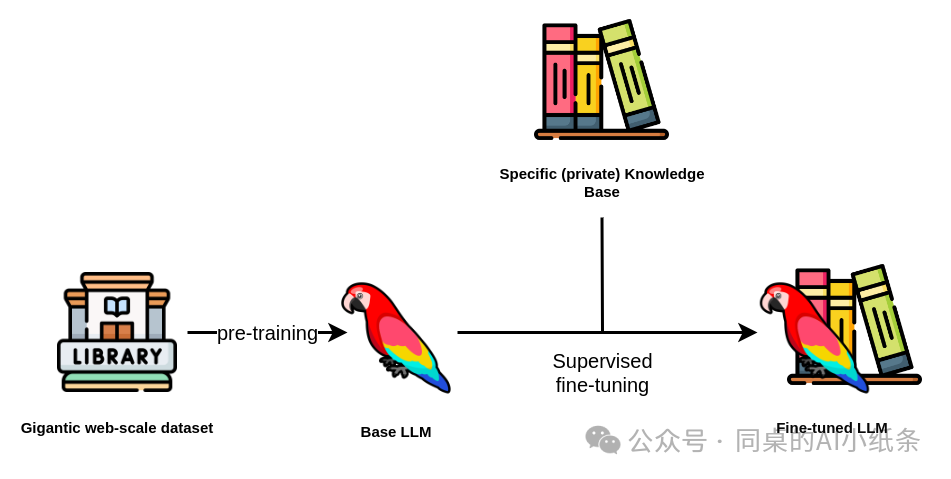
我们都知道,通用大模型是基于互联网公开的海量知识进行预训练,所以它具备很强的通识能力,但大模型在处理特定行业或私域的专业知识文档、专业术语、业务流程时,可能存在理解不足或胜任力有限的情况。一个是可能专业领域数据的不足,再一个也比较好理解,人家也没有花全部力气只学一科,没有对某一科设定很高的学习目标,主打什么都学点什么都会点,不对某一特定领域做专精的要求。
而微调恰好能根据实际需求,如果想要让它精通特定领域,就可以使用特定行业的数据集对它进行微调,这其中也可以包括企业内部的非公开行业数据,所以很多微调的教程第一步都是“准备数据集”,总之就是用更专业更垂直更行业精确的数据来让大模型学习,针对性的提升大模型与行业的和领域契合度,更好地为人们所用。
什么是微调中的过拟合?
过拟合(Overfitting)是机器学习和统计学中的一个概念,指的是模型在训练数据上表现得过于复杂,以至于失去了泛化能力。换句话说,过拟合的模型在训练数据上可能表现得非常好,但在新的、未见过的数据上表现不佳。以下是一些关于过拟合的要点:
- 训练与测试误差:过拟合的模型通常在训练数据上的误差很小,但在测试数据上的误差很大。
- 复杂度过高:模型过于复杂,捕捉到了训练数据中的噪声和细节,而不仅仅是潜在的数据分布。
- 泛化能力差:由于模型过于依赖训练数据,它不能很好地泛化到新数据上。
- 原因:过拟合可能由多种因素引起,包括模型太复杂、训练数据太少或质量不高、训练时间过长等。
- 解决方法:为了避免过拟合,可以采取以下措施:
-
- 使用更简单的模型。
- 获取更多的训练数据。
- 使用数据增强技术。
- 应用正则化方法,如L1或L2正则化。
- 使用交叉验证来评估模型性能。
- 采用早停法(early stopping),在验证集上的性能不再提升时停止训练。
例子:想象一个学生在考试前夜努力学习,他们可能记住了所有的细节和例子,但在考试中遇到新的问题时却无法应用所学的知识,这就是一种过拟合的情况。
微调方法的分类
大家不需要为难自己非记住下面这些内容的细节,根据这些分类理解为什么会有这些技术的出现,就足够
按参数更新范围分类:
全量微调 FFT(Full Fine-Tuning):更新模型的所有参数。
参数高效微调 PEFT(Parameter-Efficient Fine-Tuning):只更新模型的一部分参数,如Prefix Tuning、Prompt Tuning、Adapter Tuning等。
因为FFT聚焦于对模型全量参数进行微调,因为参数更新力度大,计算成本高,且效果未必有保障,所以相比下面固定大部分预训练参数,只微调少数参数的PEFT方式会被更多的选择。
按学习策略分类:
监督学习微调(Supervised Fine-Tuning,SFT):使用标注数据进行微调。
无监督学习微调(Unsupervised Fine-Tuning):在没有标注数据的情况下进行微调,例如通过聚类或自编码器。
半监督学习微调(Semi-Supervised Fine-Tuning):结合使用标注和未标注数据进行微调。
强化学习微调(Reinforcement Learning Fine-Tuning,RLFT):通过奖励信号来引导模型行为的微调。
按任务类型分类:
任务特定微调(Task-Specific Fine-Tuning):针对特定任务进行微调,如文本分类、图像识别等。
多任务微调(Multi-Task Fine-Tuning):同时对模型进行多个任务的训练和微调。
按模型应用领域分类:
领域适应微调(Domain Adaptation Fine-Tuning,DAFT):使模型适应不同的数据领域。
跨模态微调(Cross-Modal Fine-Tuning,CMFT):将模型从一个模态迁移到另一个模态,如从文本到图像。
按微调过程的特点分类:
增量微调(Incremental Fine-Tuning,IFT):在已有微调基础上继续使用新数据进行微调。
微调后冻结(Fine-Tuning Followed by Freezing,FTFF):全量微调后,冻结大部分参数,只对特定部分进行进一步训练。
简单说说上面那些微调方法
全量微调 FFT(Full Fine-Tuning)
全量微调涉及对预训练模型的所有权重进行更新。这种方法适用于有大量标注数据和足够计算资源的情况,可以最大化模型对新任务的适应性。其中预训练模型的所有参数都会在微调过程中进行调整,以适应新的任务。
全量微调 FFT(Full Fine-Tuning)
在模型冻结中,我们固定预训练模型的一部分参数,只微调剩余的参数。这在底层特征足够通用,而高层特征需要针对特定任务进行调整时非常有用。例如,在图像识别任务中,除了顶层以外的所有层都可以被冻结,只微调顶层以适应新的类别。
参数高效微调 PEFT(Parameter-Efficient Fine-Tuning)
这类方法通过引入少量可学习参数来实现微调,适用于计算资源受限的情况。这种方法算力功耗比更高也是目前最常见的微调方法,比如OpenAI提供的在线微调方法就是基于PEFT,它包括一些不同的实现方法:
Prefix Tuning:在输入前添加可学习的virtual tokens作为Prefix,只更新Prefix参数。
Prompt Tuning:在输入层加入prompt tokens,简化版的Prefix Tuning。
P-Tuning:将Prompt转换为可学习的Embedding层,并用MLP+LSTM处理。
Adapter Tuning:设计Adapter结构并嵌入Transformer中,仅对新增的Adapter结构进行微调。
LoRA:在矩阵相乘模块中引入低秩矩阵来模拟全量微调。
后面我们会单独对以上几种主流的PEFT参数高效微调微调方法,进行大白话的原理解释!
目前PEFT框架已开源在Hugging Face的库中,主流的微调方法包括LoRA、 Prefix Tuning、P-Tuning、Promt Tuning、 AdaLoRA等都可以通过安装和调用Hugging Face的PEFT(高效微调)库,来进行使用。

增量学习(Incremental Learning)
增量学习允许模型逐步适应新数据,而不必每次都从头开始训练。这在数据持续更新的场景中非常有用,比如推荐系统中新用户数据的到来。
多任务学习(Multi-Task Learning)
这种方法允许模型同时学习多个任务,通常涉及到共享表示的参数,同时为每个任务学习特定的参数。这在任务之间存在相关性的情况下非常有用,比如同时进行情感分析和实体识别。
迁移学习(Transfer Learning)
这种方法侧重于利用预训练模型在源任务上学到的知识来提高目标任务的性能。例如,将一个在大规模数据集上预训练的图像识别模型应用到特定类型的图像分类任务上。
元学习(Meta-Learning)
这种方法专注于学习如何快速适应新任务,通常涉及到优化学习算法本身,以便在新任务上更快地收敛。例如,MAML算法可以优化模型,使其能够快速适应新任务,这在需要快速适应多种任务的场景中非常有用。
任务特定微调(Task-Specific Fine-Tuning)
任务特定微调只更新模型的特定部分,适用于当模型的大部分结构对新任务已经足够适用,只有小部分需要调整的情况。例如,在语音识别中,可以只微调模型的输出层,以识别特定口音或方言。
人类反馈强化学习 RLHF(Reinforcement Learning from Human Feedback)
人类反馈强化学习 RLHF(Reinforcement Learning from Human Feedback)不直接属于上述微调方法的任何一种,因为它是一种不同的学习和优化框架。然而,RLHF可以与上述的一些微调方法结合使用。
RLHF的核心思想是利用人类的反馈来指导模型的训练过程,它允许模型学习如何生成更符合人类价值观和偏好的输出。在这种框架下,模型的行为或输出会被人类评估,并根据评估结果给予模型奖励或惩罚。模型的目标是最大化长期累积的奖励。这种方法在生成任务中尤其有用,比如文本生成、对话系统等,其中模型需要生成符合人类偏好的输出。
以下是RLHF可以与上述微调方法的潜在结合方式的举例:
与全量微调结合:在使用全量微调进行初步训练后,可以应用RLHF进一步优化模型输出,使其更符合人类评估者的偏好。
与参数高效微调结合:RLHF可以用于微调那些通过参数高效微调方法(如Prefix Tuning或Adapter Tuning)调整过的模型,以提高生成内容的质量。
与多任务学习结合:在多任务学习框架下,RLHF可以为不同任务提供定制化的人类反馈,帮助模型更好地学习如何满足各种任务的需求。
与迁移学习结合:在迁移学习的上下文中,RLHF可以帮助模型更好地适应特定的目标任务,通过人类反馈来细化模型的行为。
RLHF通常涉及以下几个步骤:
- 模型生成输出或行为。
- 人类评估者提供反馈,通常是奖励或惩罚的形式。
- 模型使用强化学习算法(如策略梯度、Q学习等)来更新其参数,以最大化获得的奖励。
小结
综合考虑,上述各种微调策略各有千秋,适用于不同的应用场景。选择微调方案时,应充分考虑任务的具体需求、所选模型的特性、可用数据的规模以及计算资源的限制。
目前,为了满足特定行业或任务的需求,通过微调来提升大型模型的性能,进而增强小型模型(SLM)的能力,已成为一种日益普及的做法。这种现象可能也解释了为何众多业界领袖,包括周鸿祎在内,会提出以下观点:
今天的重点不在于反复做通用大模型,而在于找到细分场景,做出具体应用,并通过微调,落实商用价值。
在当今时代,我们不应仅仅聚焦于开发通用的大型模型。相反,关键在于识别并专注于特定的细分市场,开发出能够解决实际问题的应用,并通过精细的微调过程,实现其商业价值。
毕竟,加速模型在行业中的实际应用,可以为大型模型开拓更多的商业机会。而微调,作为优化特定领域模型的关键步骤,将在这一过程中发挥不可替代的作用。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。

