
- 1大脑与反向传播
- 2adb工具下载及安装_adb下载
- 3Flutter零基础入门学习资料集合_mk甄选-2024年flutter零基础极速入门到进阶实战[同步更新中]
- 4消息队列基础篇_消息队列cnds
- 5全国青少年信息素养大赛图形化编程复赛·模拟一卷,含答案解析_图形画编程 竞赛
- 6大数据再出发-06Hadoop(优化&特性&HA)_hadoop的数据压缩和编码技术可以帮助减少存储空间和提高数据传输效率。以下哪个选
- 7了解AIGC:让AI创造内容,改变未来
- 8自然语言处理(NLP)原理、用法、案例、注意事项_nlp如何使用
- 9资深老鸟,自动化测试分层模型与落地总结,“我“该如何提升?_性能测试分层模型是什么
- 10ElasticSearch的Update By Query的坑(使用注意事项及其方案)_updatebyquery的坑
【云岚到家】-day04-1-数据同步方案-Canal-MQ
赞
踩
【云岚到家】-day04-1-数据同步方案-Canal-MQ
1 服务搜索
1.1 服务搜索技术方案
1.1.1 需求分析
服务搜索的入口有两处:
1.在门户最上端的搜索入口对服务信息进行搜索。
如下图:
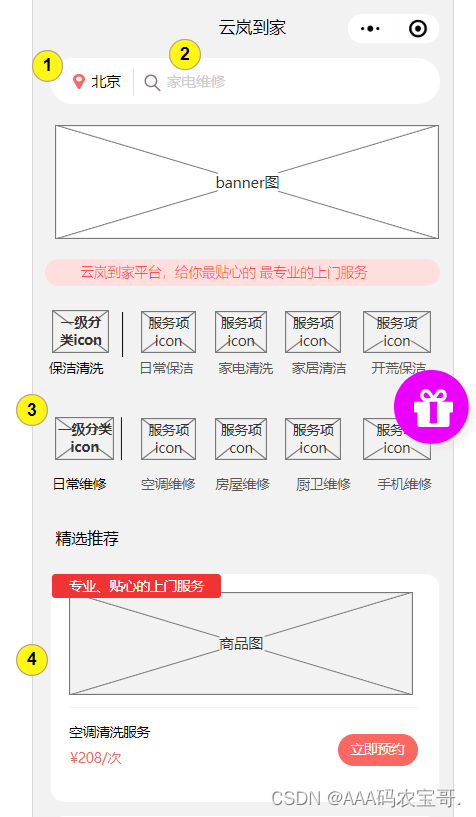
在第2部分触发搜索框进入搜索页面,输入关键字进行搜索,如下图:

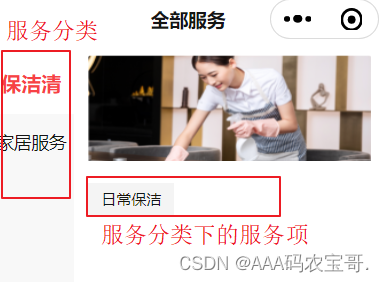
2.在门户最下方点击“全部服务”进入全部服务界面。
如下图:
点击服务分类查询分类下的服务。
1.1.2 技术方案
1.1.2.1 使用Elasticsearch进行全文检索
要实现服务搜索使用什么技术呢?
根据需求分析,对服务进行搜索除了根据服务类型查询其下的服务以外还需要根据关键字去搜索与关键字匹配的服务。
通过关键字去匹配服务的哪些信息呢?比如:输入关键字“家庭保洁”,它会去匹配服务相关的信息,比如:服务类型的名称、服务项的名称,甚至根据需要也可能去匹配服务介绍的信息,只要与“家庭保洁”相关的服务都会展示出来。如下效果:
要实现服务搜索使用什么技术呢?
根据需求分析,对服务进行搜索除了根据服务类型查询其下的服务以外还需要根据关键字去搜索与关键字匹配的服务。
通过关键字去匹配服务的哪些信息呢?比如:输入关键字“家庭保洁”,它会去匹配服务相关的信息,比如:服务类型的名称、服务项的名称,甚至根据需要也可能去匹配服务介绍的信息,只要与“家庭保洁”相关的服务都会展示出来。如下效果:

这里最关键的是根据关键字去匹配,使用数据库的like搜索能否实现呢?
上图的搜索效果是一种全文检索方式,在搜索“家庭保洁”关键字时会对关键字先分词,分为“家庭”和“保洁”,再根据分好的词去匹配索引库中的服务类型的名称、服务项的名称、服务项的描述等字段。Like搜索不具有分词功能,它不是一种全文检索的方式。
虽然MySQL也支持全文检索,但是考虑搜索接口具有高性能需求,并且它面向的是C端用户,如果C端用户直接访问数据库在高并发时就会对数据库造成很大的压力,影响接口的性能,同时也会对其它业务使用数据库造成影响,所以一般C端用户的高性能接口不会直接访问数据库。
如果要实现全文检索且对接口性能有一定的要求,最常用的是Elasticsearch,本项目使用ES完成服务搜索功能的开发。
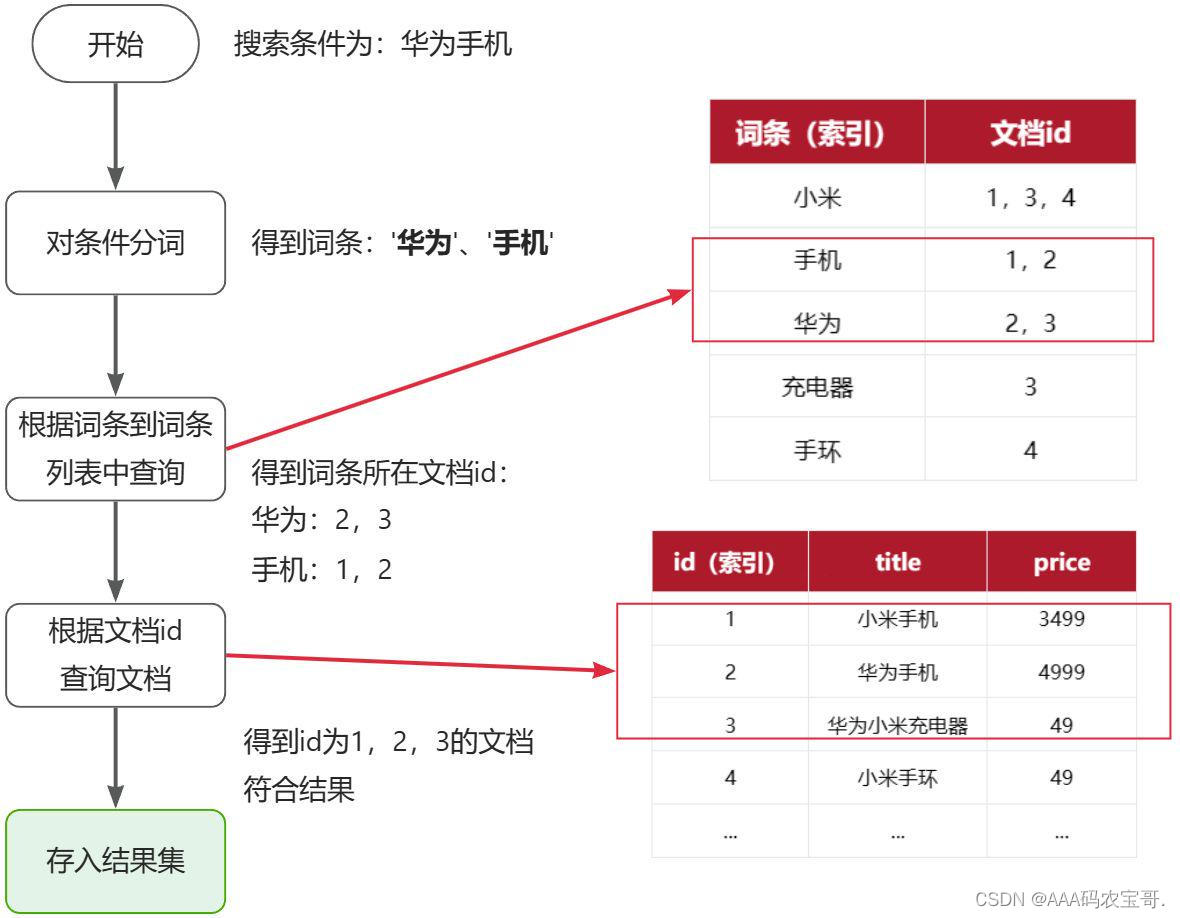
Elasticsearch是基于倒排索引的原理,正排索引是从文章中找词,倒排索引是根据词去找文章,原理如下:
1.1.2.2 索引同步方案
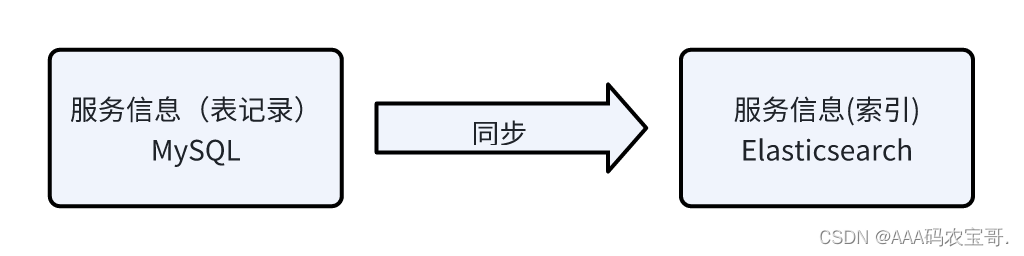
如果要使用ES去搜索服务信息需要提前对服务信息在ES中创建索引,运营端在管理服务时是将服务信息保存在数据库,如何对数据库中的服务信息去创建索引,保证数据库中的信息与ES的索引信息同步呢,本节对索引同步的方案进行分析与确定。
方案1: 添加服务信息维护索引
在服务项的增删改查Service方法中添加维护ES索引的代码。
在区域服务的增删改查Service方法中添加维护ES索引的代码。
例如下边的代码:
public Serve onSale(Long id){
//操作serve表
//添加向ES创建索引的代码
}
- 1
- 2
- 3
- 4
首先上边的代码是在原有业务方式的基础上添加索引同步的代码,增加代码的复杂度不方便维护,扩展性差。
其次上边的代码存在分布式事务,操作serve表会访问数据库,添加索引会访问ES,使用数据库本地事务是无法控制整个方法的一致性的,比如:向ES写成功了由于网络问题抛出网络超时异常,最终数据库操作回滚了ES操作没有回滚,数据库的数据和ES中的索引不一致。
方案1通常在生产中不会使用。
方案2:使用Canal+MQ
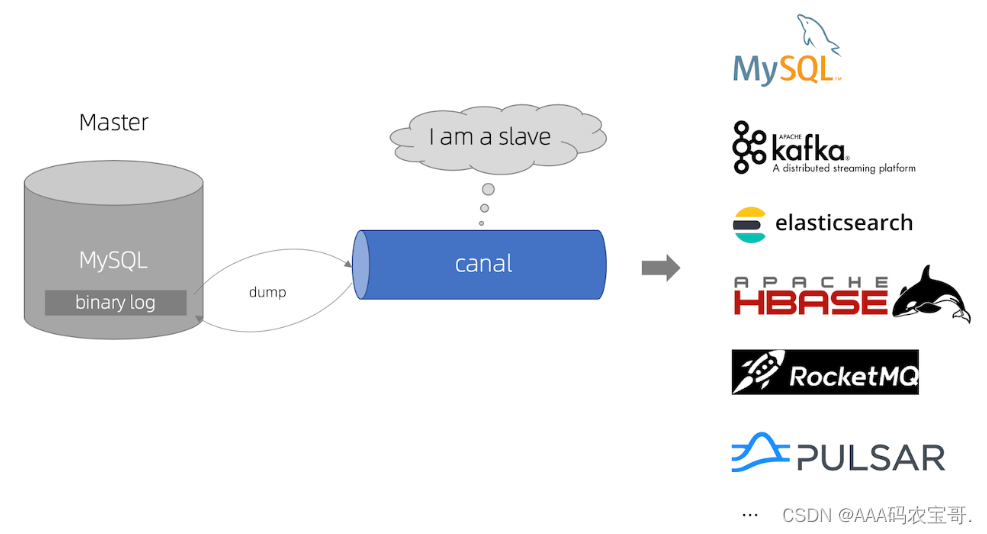
Canal是什么?
canal [kə’næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,对数据进行同步,如下图:
Canal可与很多数据源进行对接,将数据由MySQL同步到ES、MQ、DB等各个数据源。
Canal的意思是水道/管道/沟渠,它相当于一个数据管道,通过解析MySQL的binlog日志完成数据同步工作。
官方文档:https://github.com/alibaba/canal/wiki
1.1.3 Canal+MQ
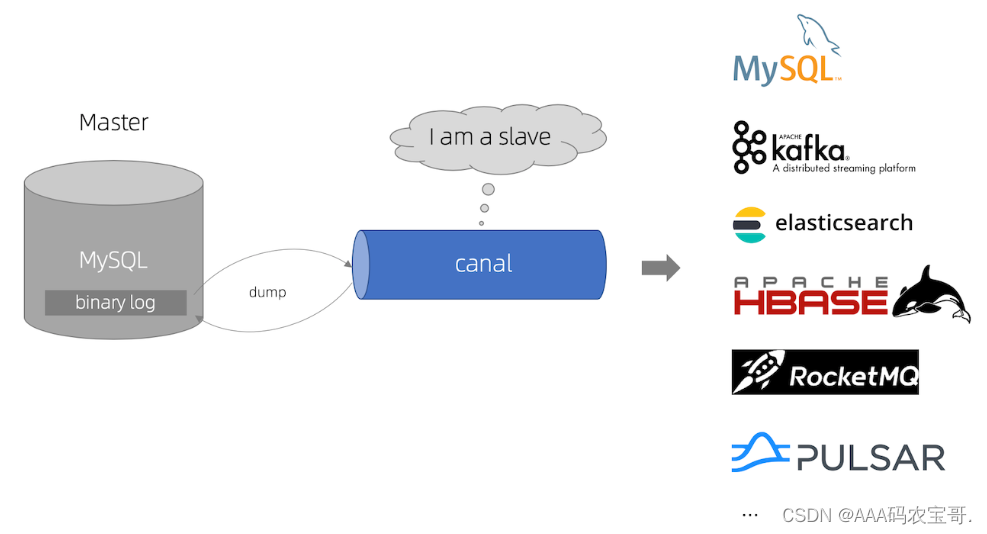
1.1.3.1 MySQL主从数据同步
要理解上图中Canal的工作原理需要首先要知道MySQL主从数据同步的原理,如下图:
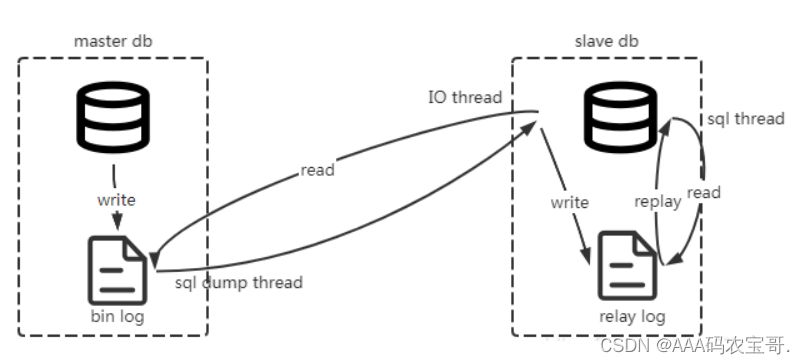
MySQL主从集群由MySQL主服务器(master)和MySQL从服务器(slave)组成,MySQL主从数据同步是一种数据库复制技术,进行写数据会先向主服务器写,写成功后将数据同步到从服务器,流程如下:
1、主服务器将所有写操作(INSERT、UPDATE、DELETE)以二进制日志(binlog)的形式记录下来。
2、从服务器连接到主服务器,发送dump 协议,请求获取主服务器上的binlog日志。MySQL的dump协议是MySQL复制协议中的一部分。
3、MySQL master 收到 dump 请求,开始推送 binary log 给 slave
4、从服务器解析日志,根据日志内容更新从服务器的数据库,完成从服务器的数据保持与主服务器同步。
1.1.3.2 Canal工作流程
理解了MySQL主从同步的原理,Canal在整个过程充当什么角色呢?
如下图:
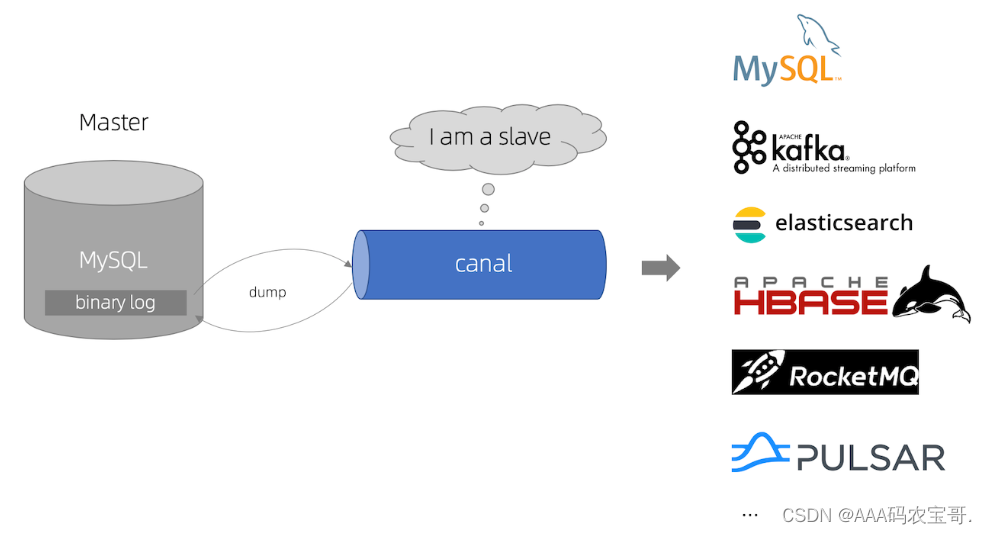
工作流程如下:
1、Canal模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议,MySQL的dump协议是MySQL复制协议中的一部分。
2、MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )。一旦连接建立成功,Canal会一直等待并监听来自MySQL主服务器的binlog事件流,当有新的数据库变更发生时MySQL master主服务器发送binlog事件流给Canal。
3、Canal会及时接收并解析这些变更事件并解析 binary log
通过以上流程可知Canal和MySQL master主服务器之间建立了长连接。
1.1.3.3 具体实现方案
本方案需要借助Canal和消息队列,具体实现方案如下:
通过上边的技术分析下边对本项目服务搜索方案进行总结。
本项目使用Elasticsearch实现服务的搜索功能,使用Canal+MQ完成服务信息与ES索引同步。
如下图:
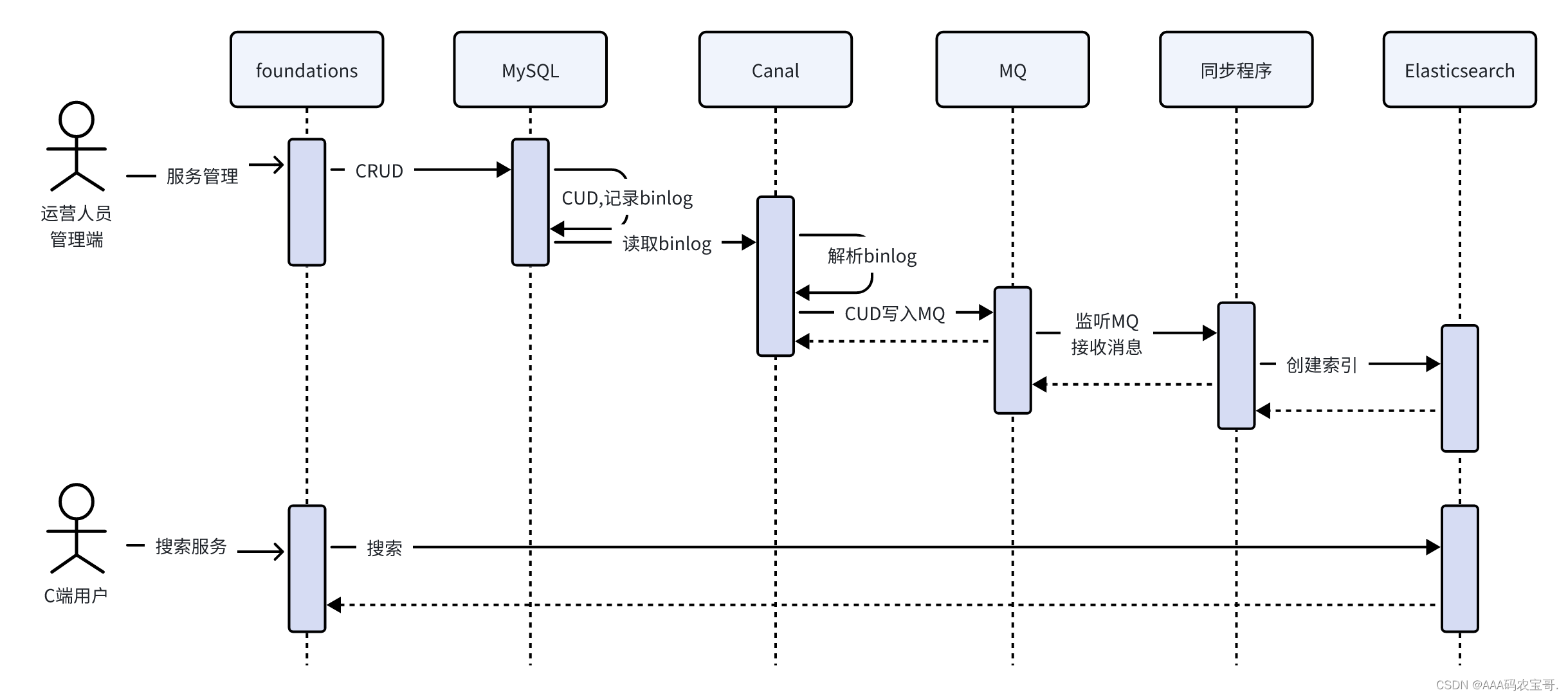
流程如下:
运营人员对服务信息进行增删改操作,MySQL记录binlog日志。
Canal定时读取binlog 解析出增加、修改、删除数据的记录。
Canal将修改记录发送到MQ。
同步程序监听MQ,收到增加、修改、删除数据的记录,请求ES创建、修改、删除索引。
C端用户请求服务搜索接口从ES中搜索服务信息。
1.2 MQ技术方案
1.2.1 保证生产消息可靠性
上述技术方案中有一个关键点,首先数据增删改的信息是保证写入binlog的,Canal解析出增删改的信息后写入MQ,同步程序从MQ去读取消息,如果MQ中的消息丢失了数据将无法进行同步。
如何保证MQ消息的可靠性?
保证MQ消息的可靠性分两个方面:保证生产消息的可靠性、保证消费消息的可靠性。
保证生产消息的可靠性:
RabbitMQ提供生产者确认机制保证生产消息的可靠性,技术方案如下 :
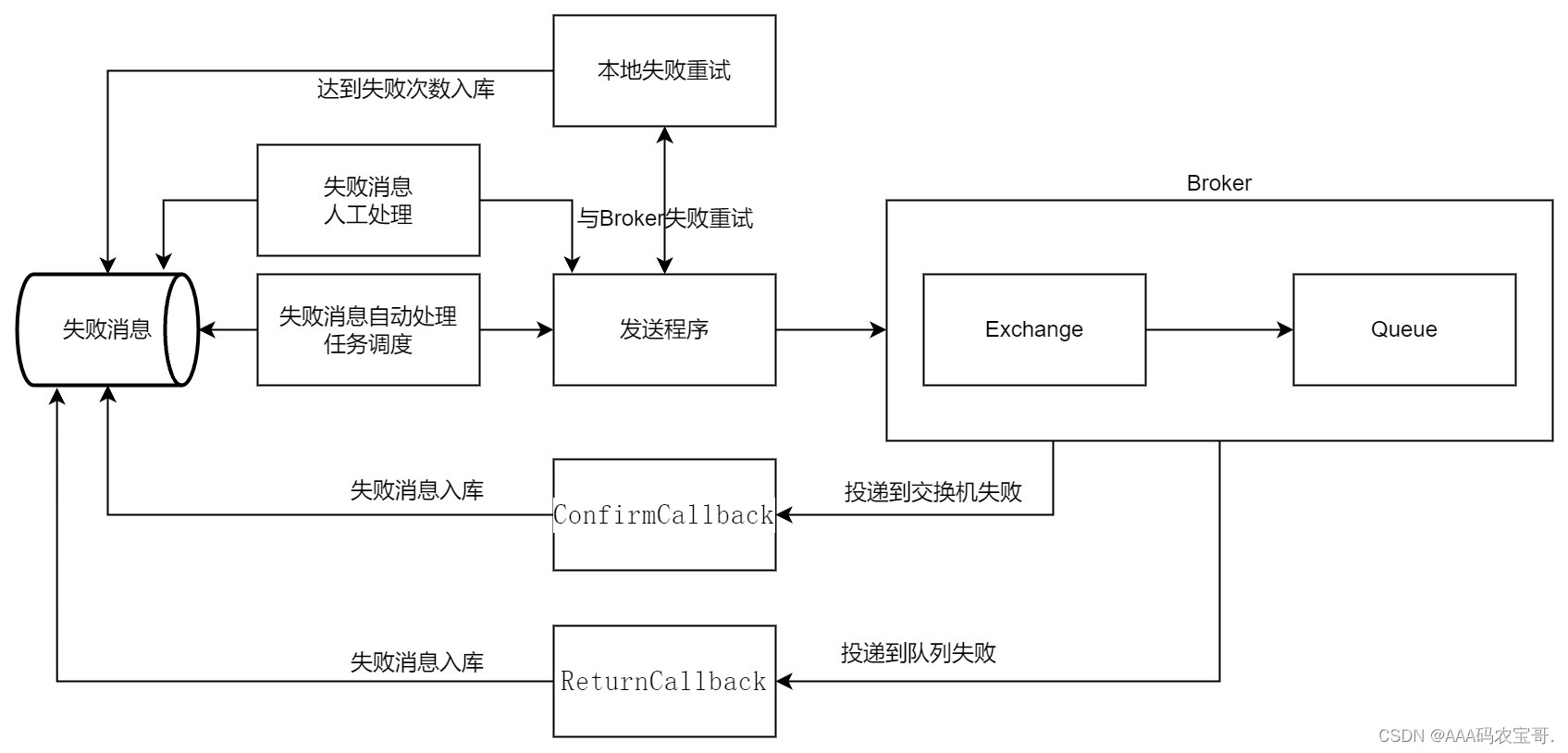
1.2.1.1 生产消息及重试方法
在com.jzo2o.rabbitmq.client.RabbitClient中,首先发送消息的方法如果执行失败会进行重试,重试次数耗尽记录失败消息,项目中抽取了发送消息的工具方法,代码 在jzo2o-rabbitmq中,如下图:
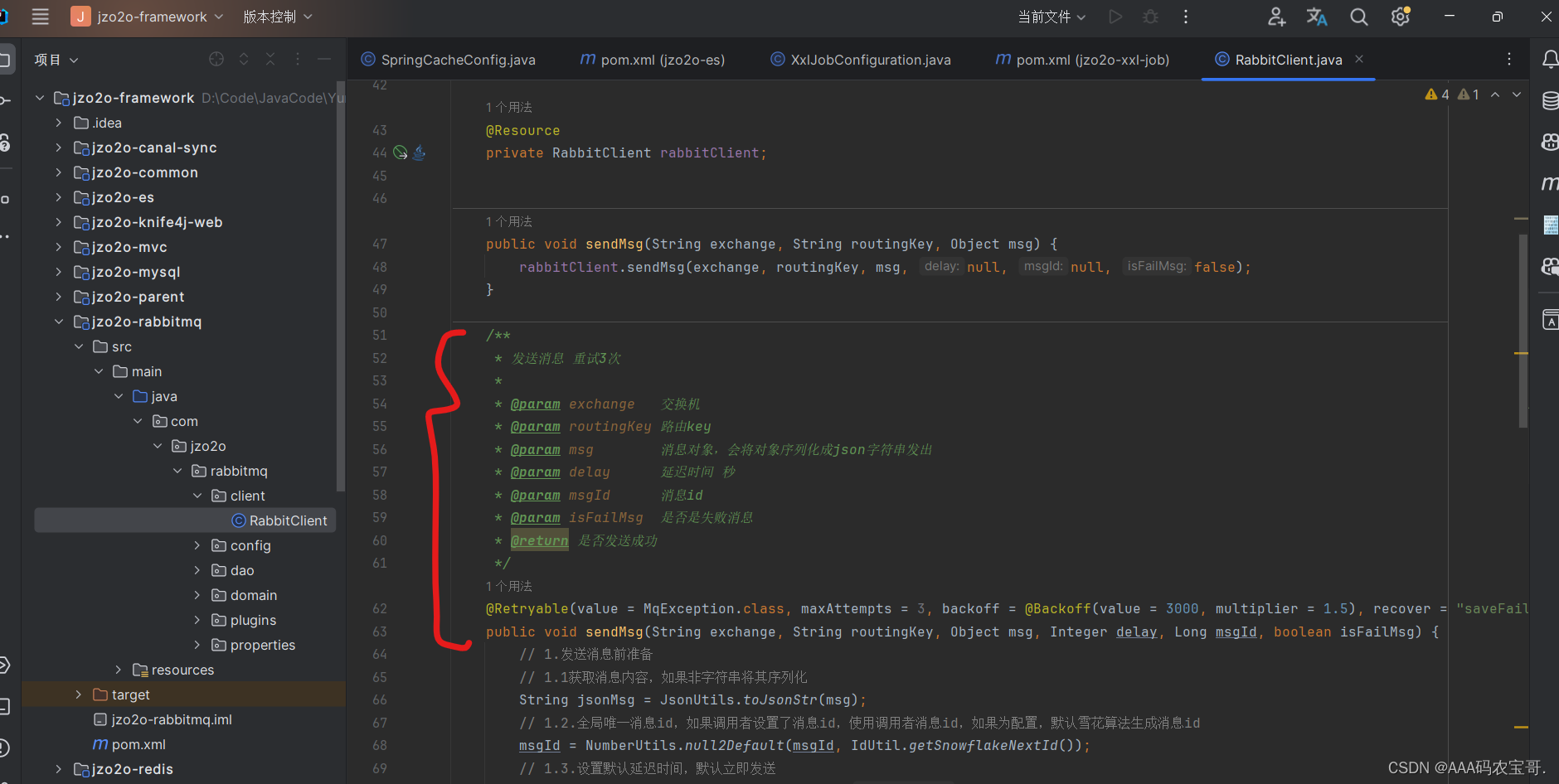
@Retryable注解可实现方法执行失败进行重试,如下:
@Retryable(value = MqException.class, maxAttempts = 3, backoff = @Backoff(value = 3000, multiplier = 1.5), recover = "saveFailMag")
- 1
说明如下:
value:抛出指定异常才会重试
include:和value一样,默认为空,当exclude也为空时,默认所有异常
exclude:指定不处理的异常
maxAttempts:最大重试次数,默认3次
backoff:重试等待策略,默认使用@Backoff,@Backoff的value默认为1000L,我们设置为3000L;表示第一次失败后等待3秒后重试,multiplier(指定延迟倍数)默认为0,如果把multiplier设置为1.5表示每次等待重试时间是上一次的1.5倍,则第一次重试为3秒,第二次为4.5秒,第三次为6.75秒。
Recover: 设置回调方法名,当重试耗尽时,通过recover属性设置回调的方法名。通过@Recover注解定义重试失败后的处理方法,在Recover方法中记录失败消息到数据库。
下边的方法表示将失败消息存储到失败表中
/**
* @param mqException mq异常消息
* @param exchange 交换机
* @param routingKey 路由key
* @param msg mq消息
* @param delay 延迟消息
* @param msgId 消息id
*/
@Recover
public void saveFailMag(MqException mqException, String exchange, String routingKey, Object msg, Integer delay, String msgId) {
//发送消息失败,需要将消息持久化到数据库,通过任务调度的方式处理失败的消息
failMsgDao.save(mqException.getMqId(), exchange, routingKey, JsonUtils.toJsonStr(msg), delay, DateUtils.getCurrentTime() + 10, ExceptionUtil.getMessage(mqException));
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
1.2.1.2 生产者确认机制
通过MQ的提供的生产者确认机制保证生产消息的可靠性,使用生产者确认机制需要给每个消息指定一个唯一ID,生产者确认机制通过异步回调的方式进行,包括ConfirmCallback和Return回调。
**ConfirmCallback:**消息发送到Broker会有一个结果返回给发送者表示消息是否处理成功:
1)消息成功投递到交换机,返回ack
2)消息未投递到交换机,返回nack
源代码如下:
在com.jzo2o.rabbitmq.client.RabbitClient#sendMsg(java.lang.String, java.lang.String, java.lang.Object, java.lang.Integer, java.lang.Long, boolean)中,在发送消息时指定回调对象
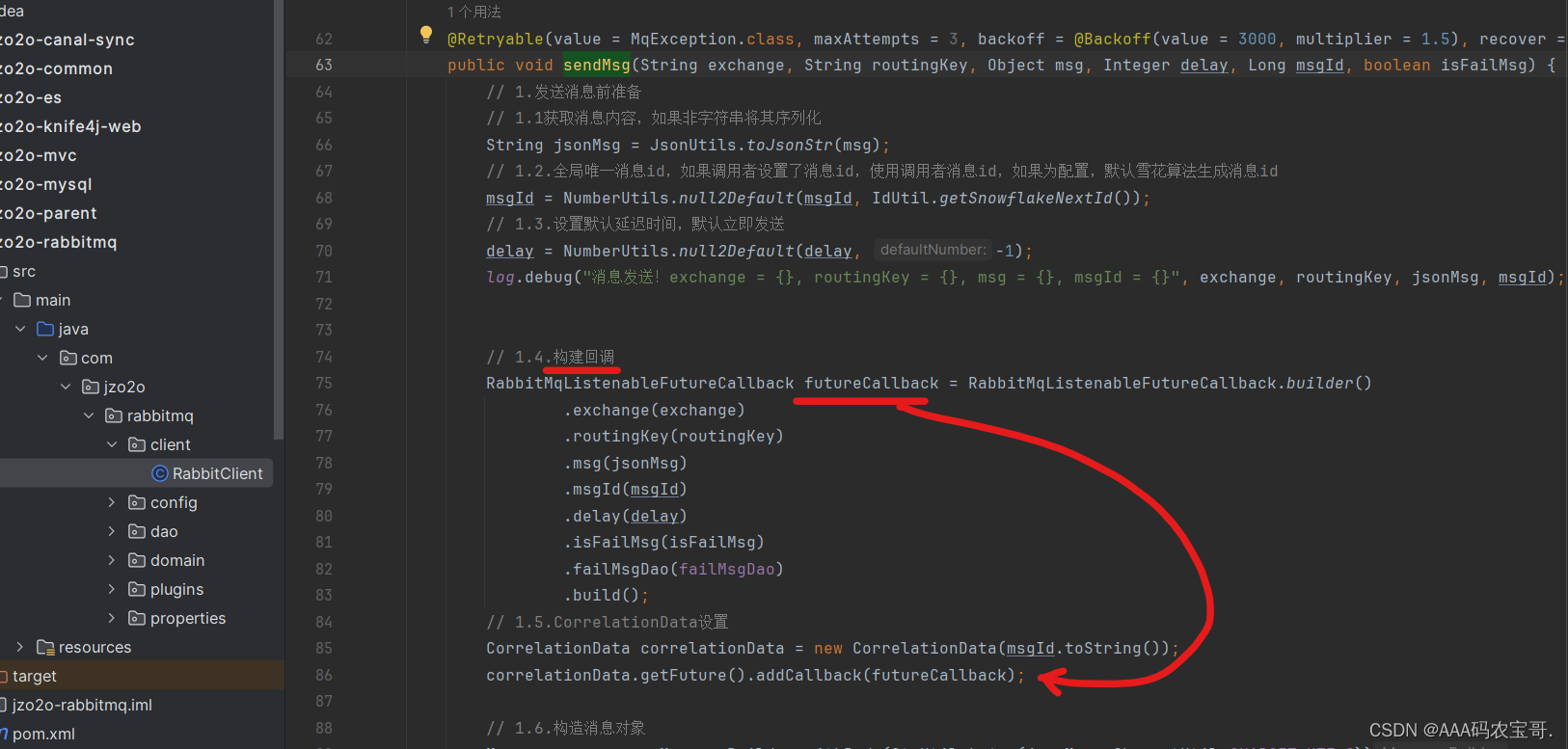
回调类中回调方法源代码:
如果没有返回ack则将消息记录到失败消息表,如果经过重试后返回了ack说明消息发送成功,此时将消息从失败消息表删除。
在com.jzo2o.rabbitmq.plugins.RabbitMqListenableFutureCallback中
@Override
public void onSuccess(CorrelationData.Confirm result) {
if(failMsgDao == null){
return;
}
if(!result.isAck()){
// 执行失败保存失败信息,如果已经存在保存信息,如果不在信息信息
failMsgDao.save(msgId, exchange, routingKey, msg, delay,DateUtils.getCurrentTime() + 10, "MQ回复nack");
}else if(isFailMsg && msgId != null){
// 如果发送的是失败消息,当收到ack需要从fail_msg删除该消息
failMsgDao.removeById(msgId);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
Return回调:如果消息发送到交换机成功了但是并没有到达队列,此时会调用ReturnCallback回调方法,在回调方法中我们可以收到失败的消息存入失败消息表以便进行补偿。confirmcallback是针对发消息时的,而returncallback是针对全局。
要使用Return回调需要开启设置:
首先在shared-rabbitmq.yaml中配置rabbitMQ参数,如下:
spring:
rabbitmq:
publisher-confirm-type: correlated
publisher-returns: true
template:
mandatory: true
说明:
publish-confirm-type:开启publisher-confirm,这里支持两种类型:
simple:同步等待confirm结果,直到超时
correlated:异步回调,定义ConfirmCallback,MQ返回结果时会回调这个ConfirmCallback
publish-returns:开启publish-return功能,同样是基于callback机制,不过是定义ReturnCallback
template.mandatory:定义消息路由失败时的策略。true,则调用ReturnCallback;false:则直接丢弃消息
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
在com.jzo2o.rabbitmq.config.RabbitMqConfiguration#setApplicationContext中,阅读下边的代码理解写入失败消息表的逻辑。
@Override public void setApplicationContext(ApplicationContext applicationContext) throws BeansException { // 获取RabbitTemplate RabbitTemplate rabbitTemplate = applicationContext.getBean(RabbitTemplate.class); //定义returnCallback回调方法 rabbitTemplate.setReturnsCallback( new RabbitTemplate.ReturnsCallback() { @Override public void returnedMessage(ReturnedMessage returnedMessage) { byte[] body = returnedMessage.getMessage().getBody(); //消息id String messageId = returnedMessage.getMessage().getMessageProperties().getMessageId(); String content = new String(body, Charset.defaultCharset()); log.info("消息发送失败,应答码{},原因{},交换机{},路由键{},消息id{},消息内容{}", returnedMessage.getReplyCode(), returnedMessage.getReplyText(), returnedMessage.getExchange(), returnedMessage.getRoutingKey(), messageId, content); if (failMsgDao != null) { failMsgDao.save(NumberUtils.parseLong(messageId), returnedMessage.getExchange(), returnedMessage.getRoutingKey(), content, null, DateUtils.getCurrentTime(), "returnCallback"); } } } ); }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
1.2.2 保证消费消息可靠性
1.2.2.1 三种持久化及确认机制
首先设置消息持久化,保证消息发送到MQ消息不丢失。具体需要设置交换机和队列支持持久化,发送消息设置deliveryMode=2。
RabbitMQ是通过消费者回执来确认消费者是否成功处理消息的:消费者获取消息后,应该向RabbitMQ发送ACK回执,表明自己已经处理完成消息,RabbitMQ收到ACK后删除消息。
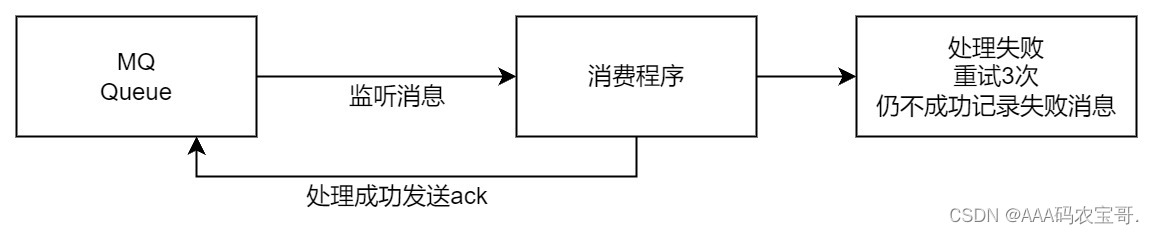
消费消息失败重试3次,仍失败则将消费失败的消息入库。
通过任务调度扫描失败消息表重新发送,达到一定的次数还未成功则由人工处理。
RabbitMQ提供三个确认模式:
-
manual:手动ack,需要在业务代码结束后,调用api发送ack。
-
auto:自动ack,由spring监测listener代码是否出现异常,没有异常则返回ack;抛出异常则返回nack
-
none:关闭ack,MQ假定消费者获取消息后会成功处理,因此消息投递后立即被删除
由此可知:
- none模式下,消息投递是不可靠的,可能丢失
- auto模式类似事务机制,出现异常时返回nack,消息回滚到mq;没有异常,返回ack
- manual:自己根据业务情况,判断什么时候该ack
一般,我们都是使用默认的auto即可。
在shared-rabbitmq.yaml中配置:
spring:
rabbitmq:
....
listener:
simple:
acknowledge-mode: auto #,出现异常时返回nack,消息回滚到mq;没有异常,返回ack
retry:
enabled: true # 开启消费者失败重试
initial-interval: 1000 # 初识的失败等待时长为1秒
multiplier: 10 # 失败的等待时长倍数,下次等待时长 = multiplier * last-interval
max-attempts: 3 # 最大重试次数
stateless: true # true无状态;false有状态。如果业务中包含事务,这里改为false
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
本项目使用自动ack模式,当消费消息失败会重试,重试3次如果还失败会将消息投递到失败消息队列,由定时任务程序定时读取队列的消息,达到一定的次数还未成功则由人工处理。
1.2.3 保证消息的幂等性
消费者在消费消息时难免出现重复消费的情况,比如:消费者没有向MQ返回ack导致重复消费,所以消费者需要保证消费消息幂等性。
什么是幂等性?幂等性是指不论执行多少次其结果是一致的。
举例:
收到消息需要向数据新增一条记录,如果重复消费则会出现重复添加记录的问题。
下边根据场景分析解决方案:
1、查询操作
本身具有幂等性。
2、添加操作
如果主键是自增则可能重复添加记录。
保证幂等性可以设置数据库的唯一约束,比如:添加学生信息,将学号字段设置为唯一索引,即使重复添加相同的学生同一个学号只会添加一条记录。
3、更新操作
如果是更新一个固定的值,比如: update users set status =1 where id=?,本身具有幂等性。
如果只允许更新成功一次则可以使用token机制,发送消息前生成一个token写入redis,收到消息后解析出token从redis查询token如果成功则说明没有消费,此时更新成功将token从redis删除,当重复消费相同 的消息时由于token已经从redis删除不会再执行更新操作。
4、删除操作
与更新操作类似,如果是删除某个具体的记录,比如:delete from users where id=?,本身具有幂等性。
如果只允许删除成功一次可以采用更新操作相同的方法。
通过以上分析进行总结:
1、使用数据库的唯一约束去控制。
2、使用token机制,如下:
消息具有唯一的ID
发送消息时将消息ID写入Redis
消费时根据消息ID查询Redis判断是否已经消费,如果已经消费则不再消费。
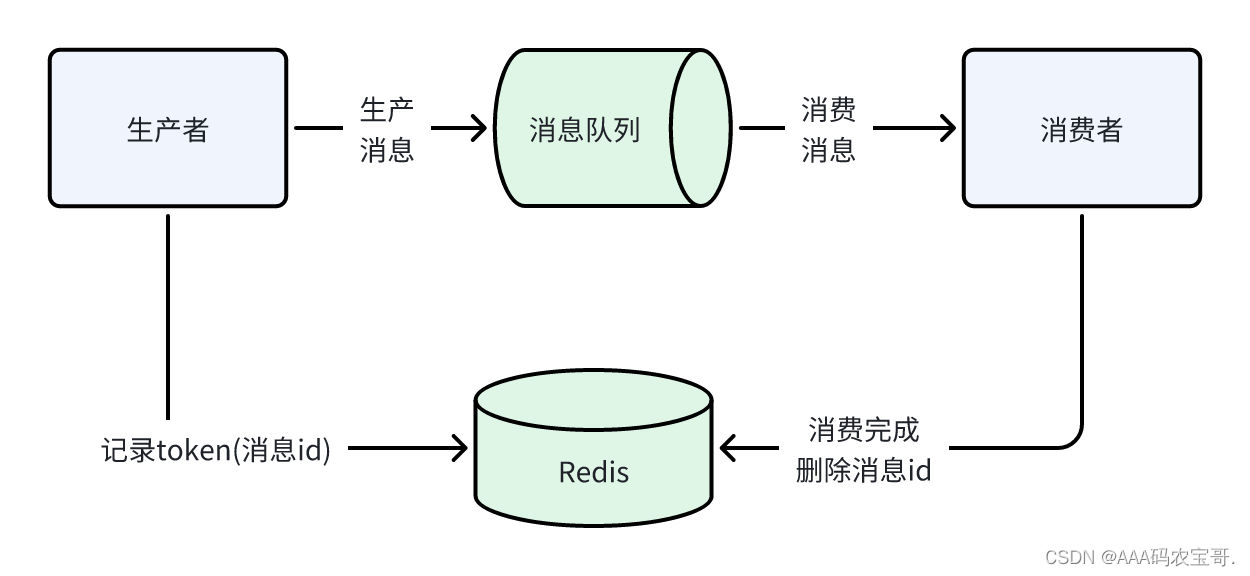
1.2.4 小结
可以百分百保证MQ的消息可靠性吗?
保证消息可靠性分两个方面:保证生产消息可靠性和保证消费消息可靠性。
保证生产消息可靠性:
生产消息可靠性是通过判断MQ是否发送ack回执,如果发nack表示发送消息失败,此时会进行重发或记录到失败消息表,通过定时任务进行补偿发送。如果Java程序并没有收到回执(如jvm进程异常结束了,或断电等因素),此时将无法保证生产消息的可靠性。
保证消费消息可靠性:
保证消费消息可靠性方案首先保证发送消息设置为持久化,其次通过MQ的消费确认机制保证消费者消费成功消息后再将消息删除。
虽然设置了消息持久化,消息进入MQ首先是在缓存存在,MQ会根据一定的规则进行刷盘,比如:每隔几毫秒进行刷盘,如果在消息还没有保存到磁盘时MQ进程终止,此时将会丢失消息。虽然可以使用镜像队列(用于在 RabbitMQ 集群中复制队列的消息,这样做的目的是提高队列的可用性和容错性,以防止在单个节点故障时导致消息的丢失。)但也不能百分百保证消息不丢失。
虽然我们加了很多保证可靠性的机制,这样也只是去提高消息的可靠性,不能百分百做的可靠,所以使用MQ的场景要考虑这种问题的存在,做好补偿处理任务。
1.3 配置数据同步环境
1.3.1 Canal+MQ同步流程
下边回顾Canal的工作原理,如下图:
1、Canal模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议,MySQL的dump协议是MySQL复制协议中的一部分。
2、MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )。一旦连接建立成功,Canal会一直等待并监听来自MySQL主服务器的binlog事件流,当有新的数据库变更发生时MySQL master主服务器发送binlog事件流给Canal。
3、Canal会及时接收并解析这些变更事件并解析 binary log
通过以上流程可知Canal和MySQL master主服务器之间建立了长连接。
基于Canal+MQ数据同步流程:
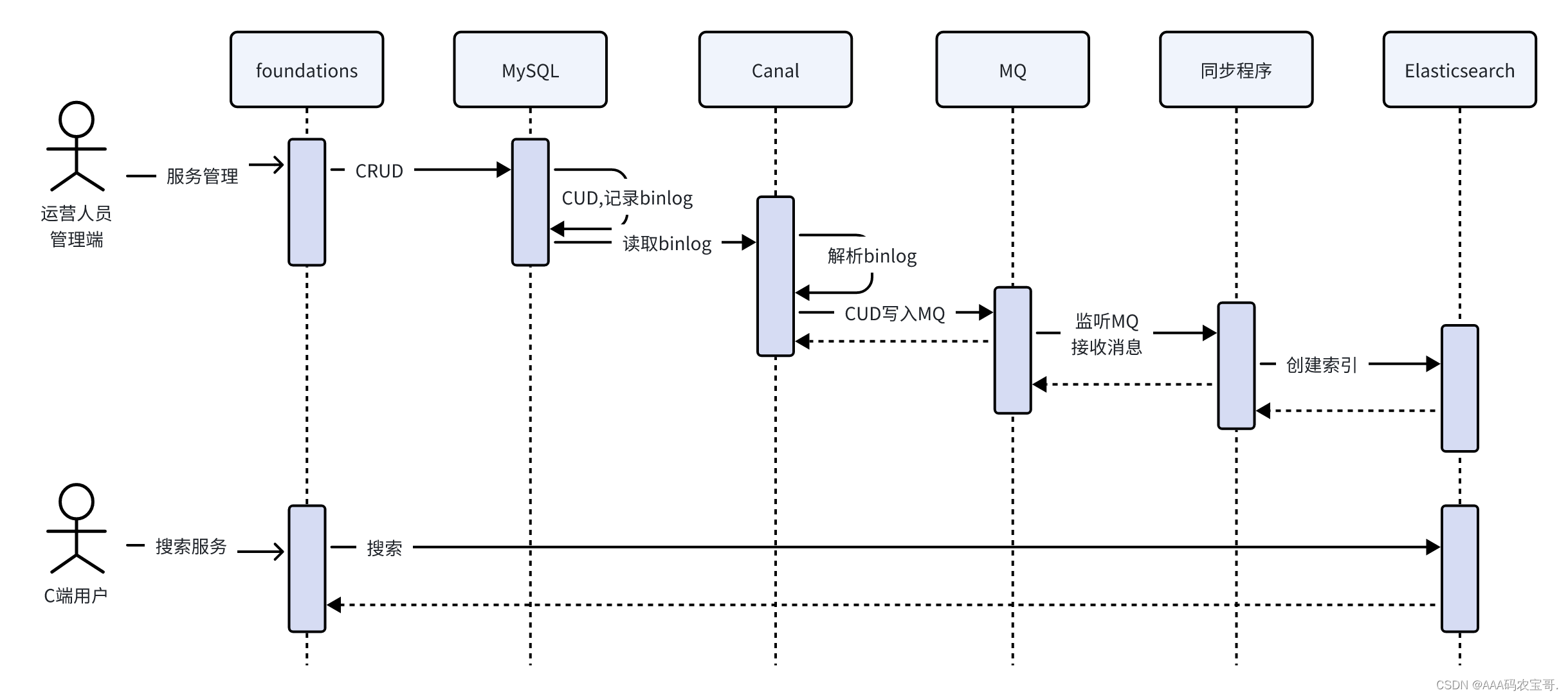
- 服务管理不仅向serve、serve_item、serve_type表写数据,同时也向serve_sync表写数据,serve_sync用于Canal同步数据使用。
- 向serve_sync写数据产生binlog
- Canal请求读取binlog,并解析出serve_sync表的数据更新日志,并发送至MQ的数据同步队列。
- 异步同步程序监听MQ的数据同步队列,收到消息后解析出serve_sync表的更新日志。
- 异步同步程序根据serve_sync表的更新日志请求Elasticsearch添加、更新、删除索引文档。
最终实现了将MySQL中的serve_sync表的数据同步至Elasticsearch
本节实现将MySQL的变更数据通过Canal写入MQ。
1.3.2 配置Canal+MQ数据同步环境
根据Canal+MQ同步流程,下边进行如下配置:
- 配置Mysql主从同步,开启MySQL主服务器的binlog
- 安装Canal并配置,保证Canal连接MySQL主服务器成功
- 安装RabbitMQ,并配置同步队列。
- 在Canal中配置RabbitMQ的连接信息,保证Canal收到binlog消息写入MQ
对于异步程序监听MQ通过Java程序中实现。
- 清理docker容器日志
cd /data/soft/
sh clean_docker_log.sh
- 1
- 2
- 启动canal和mq
docker restart rabbitmq canal
- 1
-
使用命令查看是否打开binlog模式:
-
SHOW VARIABLES LIKE 'log_bin'- 1
1.3.2.1 配置Canal+RabbitMQ
下边通过配置Canal与RabbitMQ,保证Canal收到binlog消息将数据发送至MQ。
最终我们要实现的是:
修改jzo2o-foundations数据库下的serve_sync表的数据后通过canal将修改信息发送到MQ。
1、在Canal中配置RabbitMQ的连接信息
修改/data/soft/canal/canal.properties
# tcp, kafka, rocketMQ, rabbitMQ
canal.serverMode = rabbitMQ
##################################################
######### RabbitMQ #############
##################################################
rabbitmq.host = 192.168.101.68
rabbitmq.virtual.host = /xzb
rabbitmq.exchange = exchange.canal-jzo2o
rabbitmq.username = xzb
rabbitmq.password = xzb
rabbitmq.deliveryMode = 2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
本项目用于数据同步的MQ交换机:exchange.canal-jzo2o
虚拟主机地址:/xzb
账号和密码:xzb/xzb
rabbitmq.deliveryMode = 2 设置消息持久化
2、设置需要监听的mysql库和表
修改/data/soft/canal/instance.properties
canal.instance.filter.regex需要监听的mysql库和表- 全库:
.*\\..* - 指定库下的所有表:
canal\\..* - 指定库下的指定表:
canal\\.canal,test\\.test库名\\.表名:转义需要用\,使用逗号分隔多个库
- 全库:
这里配置监听 jzo2o-foundations数据库下serve_sync表,如下:
canal.instance.filter.regex=jzo2o-foundations\\.serve_sync
- 1
3、在Canal配置MQ的topic
这里使用动态topic,格式为:topic:schema.table,topic:schema.table,topic:schema.table
配置如下:
canal.mq.dynamicTopic=canal-mq-jzo2o-foundations:jzo2o-foundations\\.serve_sync
- 1
上边的配置表示:对jzo2o-foundations数据库的serve_sync表的修改消息发到topic为canal-mq-jzo2o-foundations关联的队列,会将当前携带topic的消息转发至交换机exchange.canal-jzo2o
4、进入rabbitMQ配置交换机和队列
进入rabbitmq管理界面 http://192.168.101.68:15672/
账号:czri 密码:czri1234
查看交换机
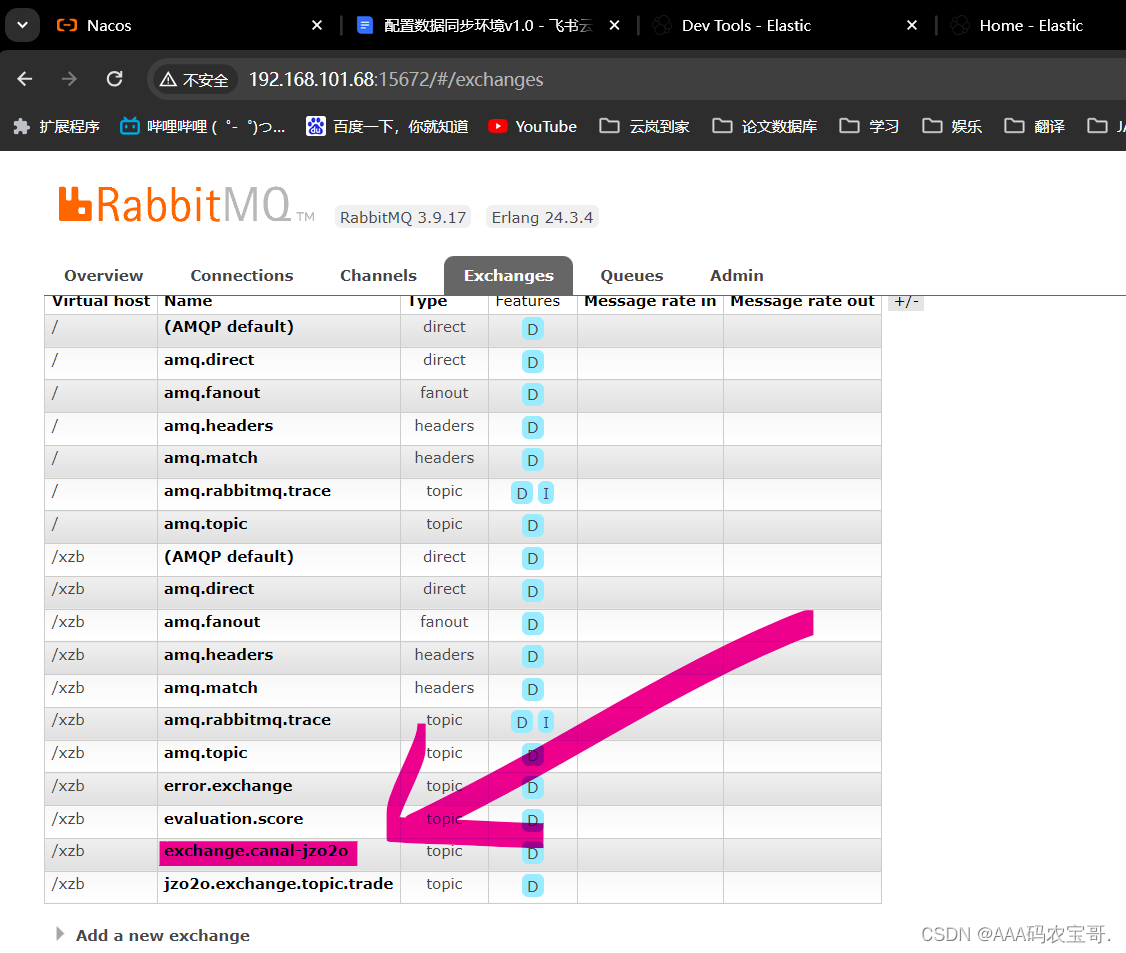
点击交换机,查看其绑定的队列
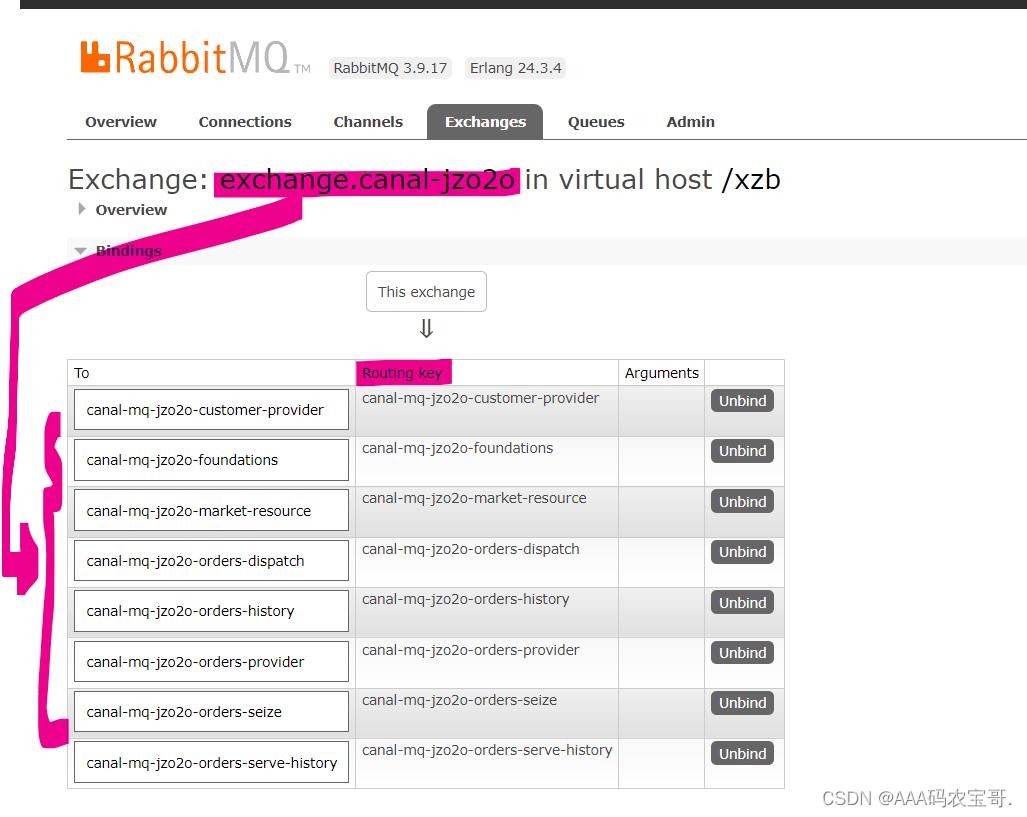
1.3.2.2 测试
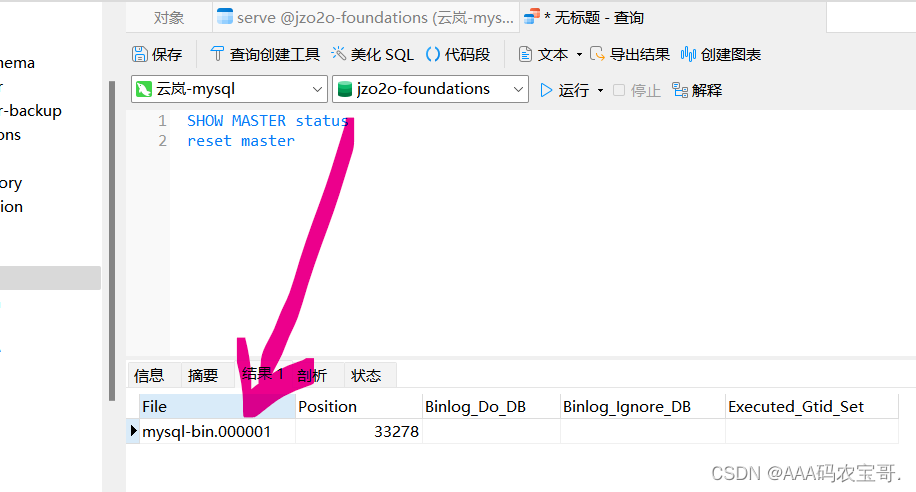
查看当前master的binlog和偏移量
SHOW MASTER status
- 1

复位
reset master
- 1
复位后查询
删除canal的同步日志,保证master和canal是同时开始同步的
cd /data/soft/canal/conf
rm meta.dat
- 1
- 2
重新启动canal,查看其日志
docker restart canal
cd /data/soft/canal/logs
tail -f xzb-canal.log
- 1
- 2
- 3
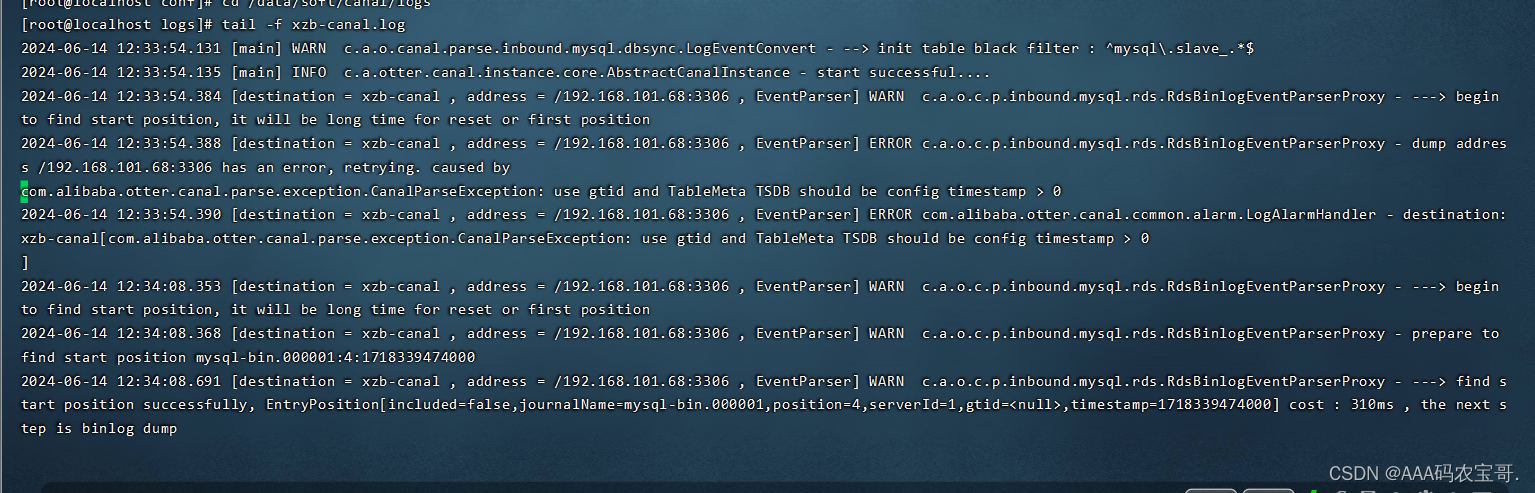
并无报错
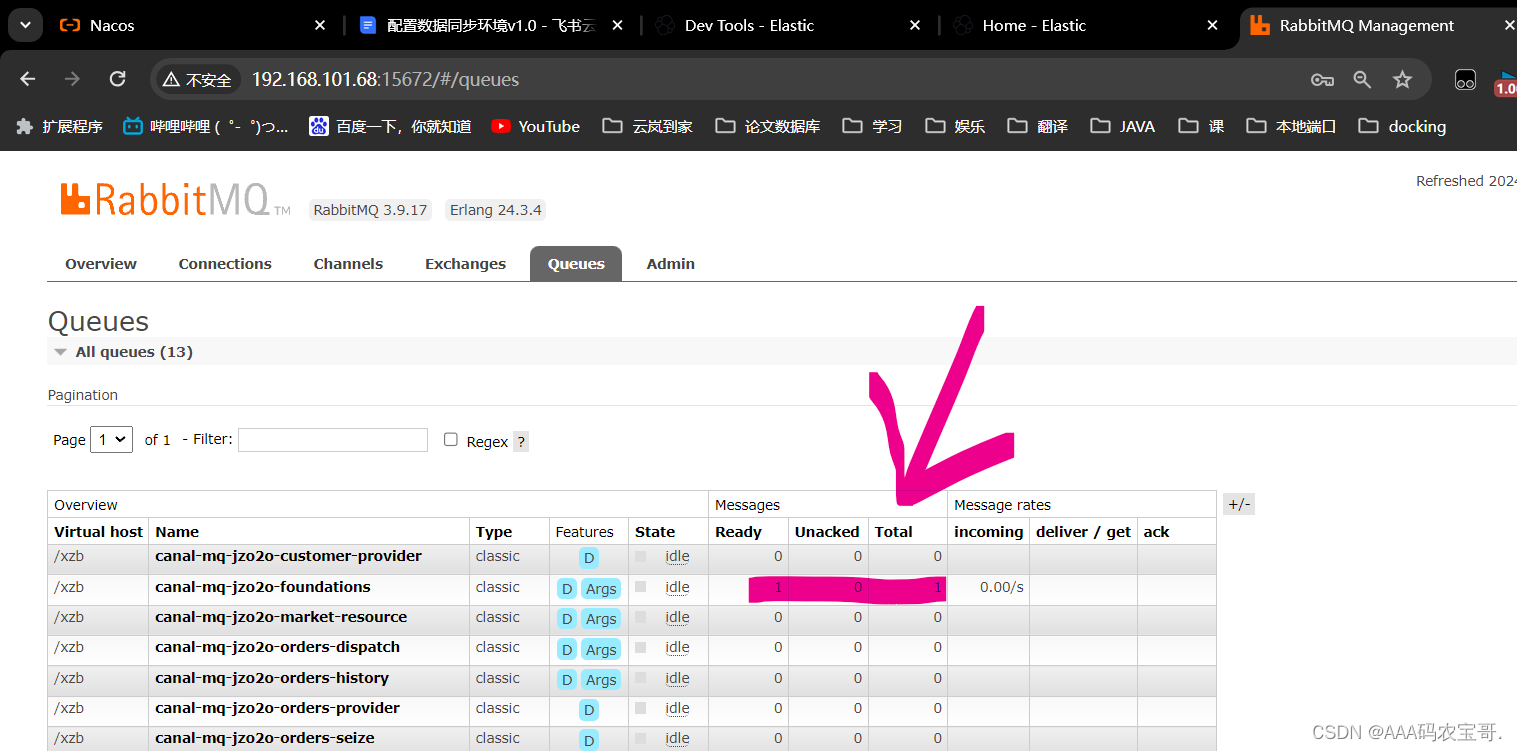
修改jzo2o-foundations数据库的serve_sync表的数据,稍等片刻查看canal-mq-jzo2o-foundations队列,如果队列中有的消息说明同步成功,如下图:
修改serve_sync数据
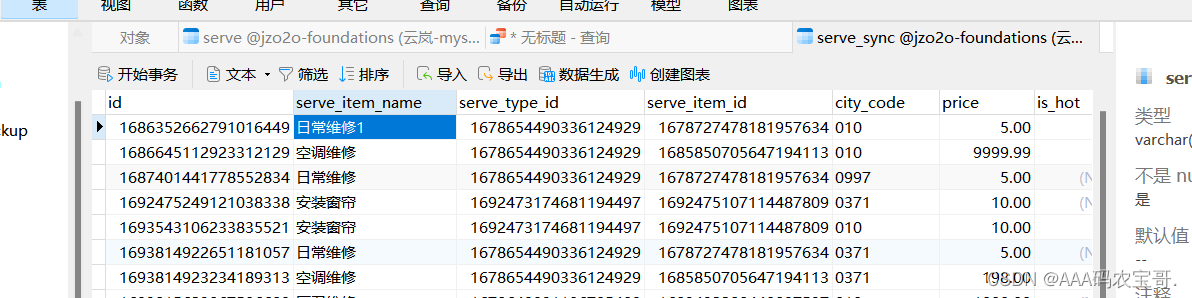
查看canal日志

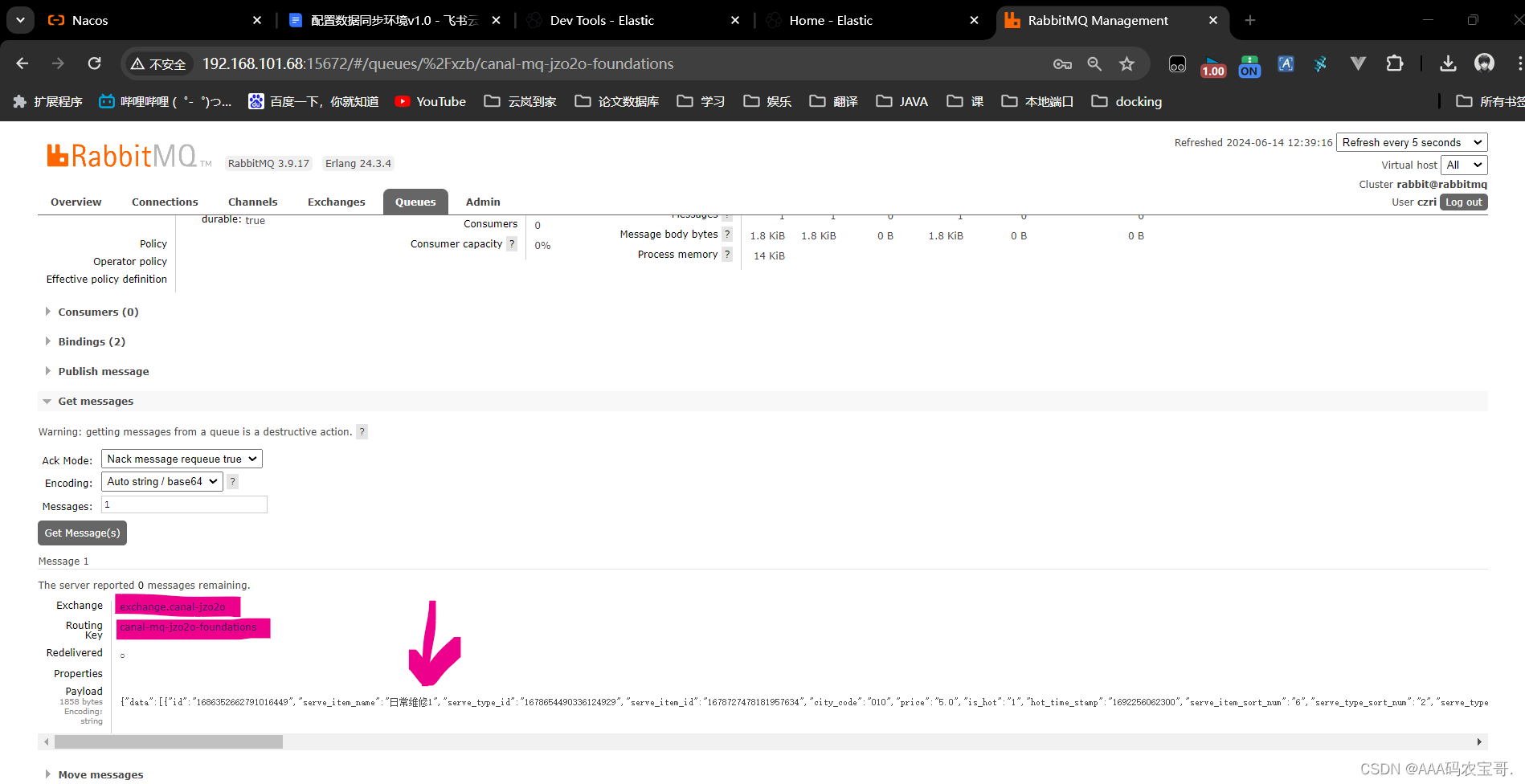
查看mq
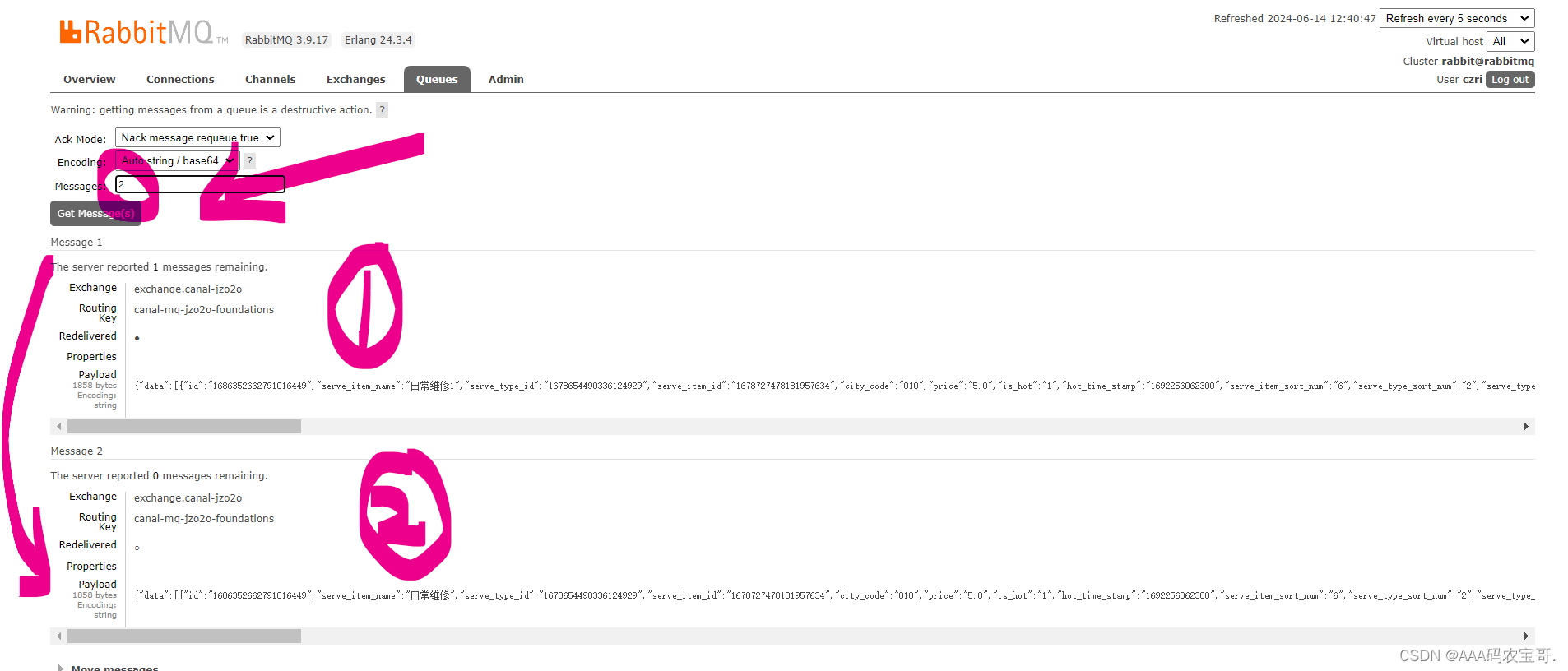
点开队列后Get Message
再改回来
1.3.2.3 数据不同步解决方法
如果停机后导致canal数据不同步解决方法:
当发现修改了数据库后修改的数据并没有发送到MQ,通过查看Canal的日志发现下边的错误。
进入Canal目录,查看日志:
cd /data/soft/canal/logs
tail -f logs/xzb-canal.log
- 1
- 2
Canal报错如下:
2023-09-22 08:34:40.802 [destination = xzb-canal , address = /192.168.101.68:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> find start position successfully, EntryPosition[included=false,journalName=mysql-bin.000055,position=486221,serverId=1,gtid=,timestamp=1695341830000] cost : 13ms , the next step is binlog dump
2023-09-22 08:34:40.811 [destination = xzb-canal , address = /192.168.101.68:3306 , EventParser] ERROR c.a.o.canal.parse.inbound.mysql.dbsync.DirectLogFetcher - I/O error while reading from client socket
java.io.IOException: Received error packet: errno = 1236, sqlstate = HY000 errmsg = Could not find first log file name in binary log index file
at com.alibaba.otter.canal.parse.inbound.mysql.dbsync.DirectLogFetcher.fetch(DirectLogFetcher.java:102) ~[canal.parse-1.1.5.jar:na]
at com.alibaba.otter.canal.parse.inbound.mysql.MysqlConnection.dump(MysqlConnection.java:238) [canal.parse-1.1.5.jar:na]
at com.alibaba.otter.canal.parse.inbound.AbstractEventParser$1.run(AbstractEventParser.java:262) [canal.parse-1.1.5.jar:na]
at java.lang.Thread.run(Thread.java:748) [na:1.8.0_181]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
找到关键的位置:Could not find first log file name in binary log index file
根据日志分析是Canal找不到mysql-bin.000055 的486221位置,原因是mysql-bin.000055文件不存在,这是由于为了节省磁盘空间将binlog日志清理了。
解决方法:
把canal复位从最开始开始同步的位置。
1)首先重置mysql的bin log:
连接mysql执行:
reset master
- 1
执行后所有的binlog删除,从000001号开始
通过
show master status
- 1
查看 ,结果显示 mysql-bin.000001
2)先停止canal
docker stop canal
- 1
3)删除meta.dat
rm -rf /data/soft/canal/conf/meta.dat
- 1
4)再启动canal
docker start canal
- 1

