
- 1Python sorted与lambda表达式结合的用法_sorted lamda
- 2双人贪吃蛇@botzone数据格式_botzone数据怎么用
- 3基于python下django框架 实现校园网站系统详细设计_基于django个设
- 4【无服务器数据库】如何创建一个非常便宜的无服务器数据库_谷歌 firebase与阿里
- 5Spark 数据读取保存_spark saveastextfile
- 6懂点人情世故,让你少吃亏。
- 7iOS 如何使用TestFlight进行测试_testfilght we require for you help
- 8mediasoup源码分析(三)channel创建及信令交互_channel request 信令
- 9【安卓】Android API 指南之数据存储(Data Storage)之存储选项(Storage Options)
- 10ROS入门21讲---常用可视化工具的使用及课程总结_ros可视化工具心得
信息熵、条件熵、信息增益
赞
踩
一、信息熵
其中:
:样本属于第i个类别的概率
:总样本数
:集合
中属于第
个类别的样本个数
二、条件熵
条件熵是在给定某个特征的情况下,对于分类结果的不确定性的度量。
- 条件熵越大,说明在给定该特征的情况下,样本的分类结果越不确定,即样本的混乱程度越高
- 条件熵较小,说明在给定该特征的情况下,样本的分类结果越趋向于一致,即样本的混乱程度越低
当一个特征的取值数目较多时,它可以将样本划分为更多的子集,这样可以更好地区分不同类别的样本,从而降低条件熵。
其中:
:属性
的取值个数
:选出属性
取值等于
的样本集合
三、信息增益
信息增益指的是在划分数据集前后,类别标签的混乱程度发生的减少的程度
- 信息增益越大,说明使用该属性进行划分可以获得更多的信息,可以更好地区分不同的类别。
- 信息增益越大,表示使用特征 A 来划分所获得的“纯度提升越大”
信息增益 = 信息熵 - 条件熵
四、示例
假设我们有一个关于动物的数据集,其中包含7个样本,每个样本有4个属性:是否有翅膀、是否有爪子、是否会游泳和是否有鳞片,以及一个类别标签,表示该动物属于哪一类别(例如,鱼类、鸟类、哺乳类等)。数据集如下:
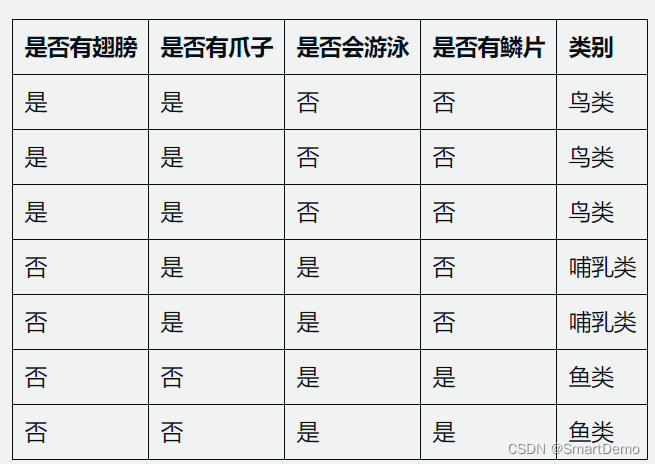
使用ID3算法来构建决策树。
1、计算整个数据集的信息熵,公式为:
2、其中,表示类别的个数,
表示样本属于第
个类别的概率。
在本例中
因此,整个数据集的信息熵为
3、接下来,计算每个属性的信息增益。以是否有翅膀为例,计算其信息增益的公式为:
其中:
表示属性
表示属性
的取值个数
表示选出属性
取值等于
的样本集合
在本例中,是否有翅膀有两个取值,即是和否,因此 。我们可以根据数据集中是否有翅膀的取值,将数据集划分为两个子集:
- 子集1:是否有翅膀=是。该子集有3个样本,其中2个属于鸟类,1个属于哺乳类。
- 子集2:是否有翅膀=否。该子集有4个样本,其中2个属于哺乳类,2个属于鱼类。
计算子集1和子集2的信息熵
因此,计算是否有翅膀的信息增益为:
同样的方式,可以计算其他属性的信息增益:
可以发现,是否有爪子的信息增益最大,因此选择该属性作为划分属性。将数据集按照是否有爪子的取值划分为两个子集:
- 子集1:是否有爪子=是。该子集有5个样本,其中3个属于鸟类,2个属于哺乳类。
- 子集2:是否有爪子=否。该子集有2个样本,其中2个属于鱼类
由于子集2中的样本已经属于同一类别,因此将该子集转换为叶子节点,并赋予该叶子节点对应的类别标签“鱼类”。
对于子集1,递归地执行上述步骤,选择最优的属性划分,直到所有子集都被转换为叶子节点。
最终得到的决策树如下:
- 是否有爪子=否:鱼类
- 是否有爪子=是:
- | 是否会游泳=是:哺乳类
- | 是否会游泳=否:鸟类
这棵决策树可以用于分类新的动物样本。例如,对于一个新的样本,如果它有爪子,不会游泳,则根据决策树可以得知它属于“鸟类”。
ID3算法缺点:
-
ID3 没有剪枝策略,容易过拟合;
-
信息增益准则对可取值数目较多的特征有所偏好,类似“编号”的特征其信息增益接近于 1;
-
只能用于处理离散分布的特征;
-
没有考虑缺失值。

