
- 1neo4j如何创建多个数据库_neo4j社区版建立两个库
- 2python毕业设计作品基于django框架 二手物品交易系统毕设成品(6)开题答辩PPT_二手交易网站答辩ppt
- 3高新面试系列 性格篇_我满脑子创业并有所行动心理测试
- 4点击劫持技术原理简述_点击劫持的原理及方法
- 5智慧校园平台建设中教育软件信创化的全面审视与战略部署
- 6Tomcat 8 性能优化_tomcat8 protocol=
- 7如何很好的理解机器学习模型,为什么大数据(Big data) 和大语言模型(Large Language Model, LLM)会变得那么火,会变得有效?_大语言模型与大数据
- 8鸿蒙一次开发,多端部署(七)响应式布局_鸿蒙breakpointsystem
- 9C++数据结构补充(双向链表)_c++ 双向链表
- 10倒计时2天!WAVE SUMMIT+ 2023将开启,五大亮点抢鲜看!
MySQL之视图,索引,存储过程,触发器--实操_索引 视图 触发器 存储过程的作用
赞
踩
一.视图
什么是视图?
- 视图是一个虚拟表,其内容由查询定义。
- 同真实的表一样,视图包含系列带有名称的列和行数据。
- 行和列数据来自定义视图的查询所引用的表,并且在引用视图时动态生成。
- 简单的来说视图是由select结果组成的表。
视图的出现其实优化了MySQL对用户权限的管理,我们在以前学的用户管理,在高级用户上也会对每个用户创建给予一些权限,
不知道有没有小伙伴注意到,在用户注册是给予的权限其实是一张张表的分发的,它的基本授予单位是表,也就是你可以对整个表进行增,删,改,查的任 一的权力
对于一般的表可能是够用了,但是对于重要的表是十分不妥的,比如 :用户登录表 对于运维人员来说,可能只用查看用户名和用户等级就差不多了,然后按特征分配服务
但是只要是个运维人员,都给select 权力给用户登录表,运维人员知道重要的用户密码有什么用呢?或者说每个运维人员知道所有用户的密码这妥当嘛
所以视图可以筛选其中的列,可以以最小分量的形式给开发团队授权,就比如运维人员,他们的权限只用知道 用户名和用户等级所在的列信息就可以了,没必要整个用户表都知道
1.视图的创建
命令格式:
Create or replace View (视图名称)
as 子查询语句(视图要显示的数据范围)
[with check option ];
视图名称后面可以跟要显示的数据列,但是必须和子查询中显示的列相等,不同则无法匹配
or replace :表示的是有相同的视图名就替换它
注意点:
- 视图是基于基本表数据的,对视图的更改,在成功的情况下,是对基本表的更改,视图只是用于隐藏一些不可见的列,并不是一个新的表实例,最后的操作都是基本表
- 一旦视图创建完成,对视图的操作关键字和对表操作的关键字都是一样的(select,insert ,update ,delete )

2.视图的增删改查
视图的插入(insert 语句):

视图的更改(update语句):

视图的查询(select语句):
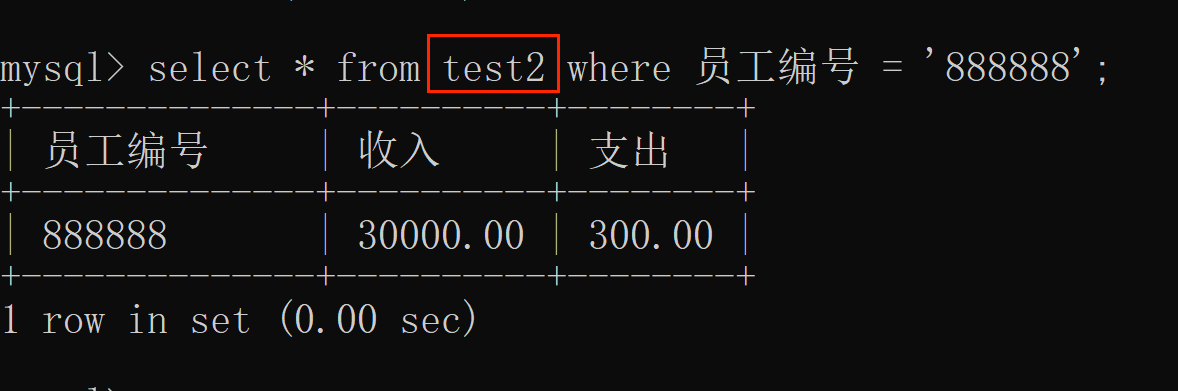
视图的删除(delete语句):

视图的操作成功了都是在基本表的操作!!!
视图不可操作的情况:
- 含有聚合函数
- distinct 关键字修饰
- group by 修饰
- order by 修饰
- having 修饰
- union运算符(联合查询)
- from子句含有多个表
3.视图的with check option检查选项
视图的检查选项一共有两种:Cascade 和 Local
它们两种关键字是一定要在基于视图建立起来的视图,才需要,如果是基于表建立起来的视图 只需要加上 with check option
加上检查选项以后,我们要对视图操作必须要满足创建该视图子查询的 where 条件,否则不能更改

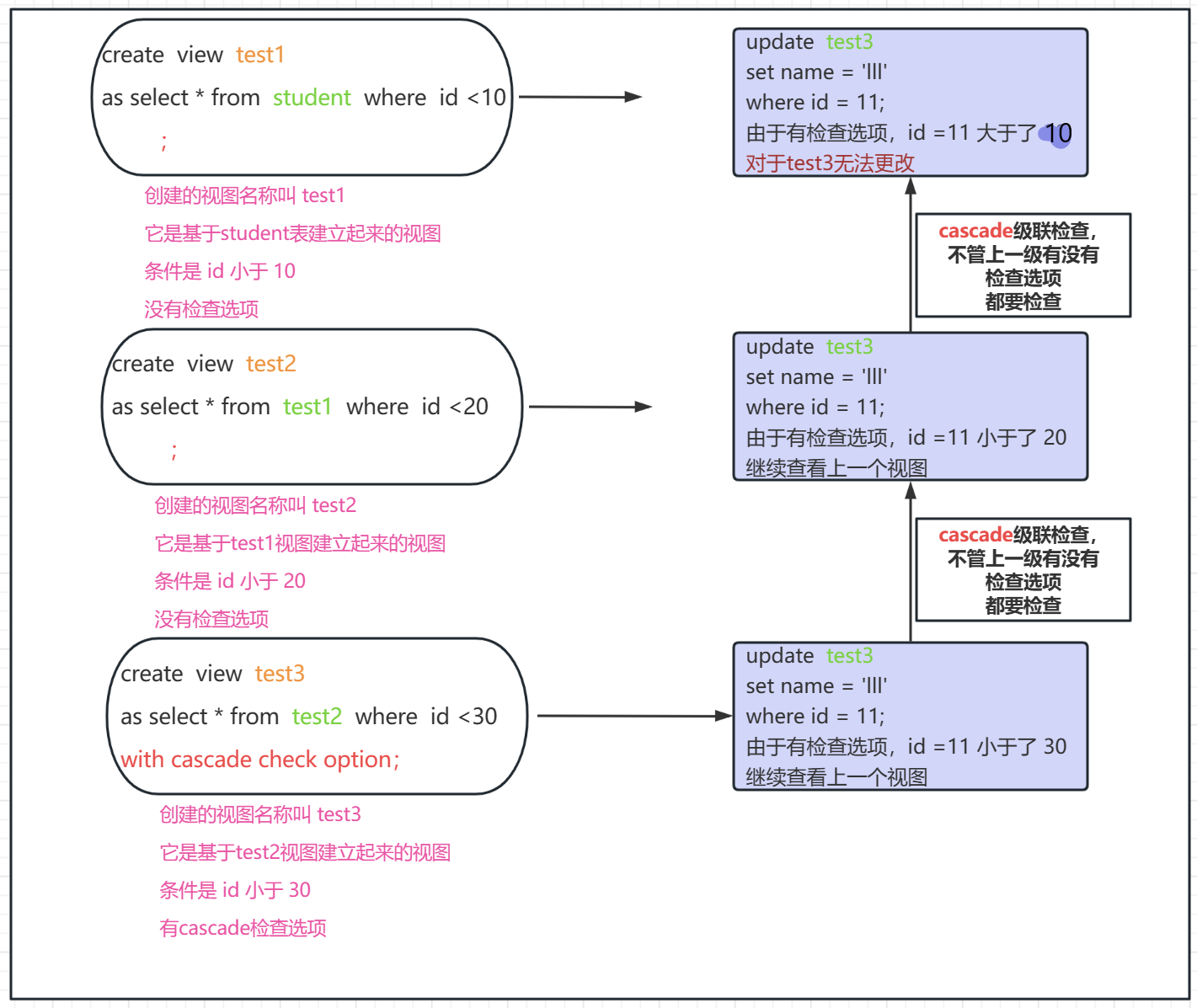
Cascade:
被cascade修饰的视图,它的检查范围是相互关联的,是一级一级的检查的,也叫做级联,当某个视图被此关键字修饰,不仅要检查自己视图的范围,还要对子查询中的视图进行检查,看看范围是否合乎要求
只要自己被标记,从自己开始一直往下检查where 子句的条件,一个不满足就不能更改
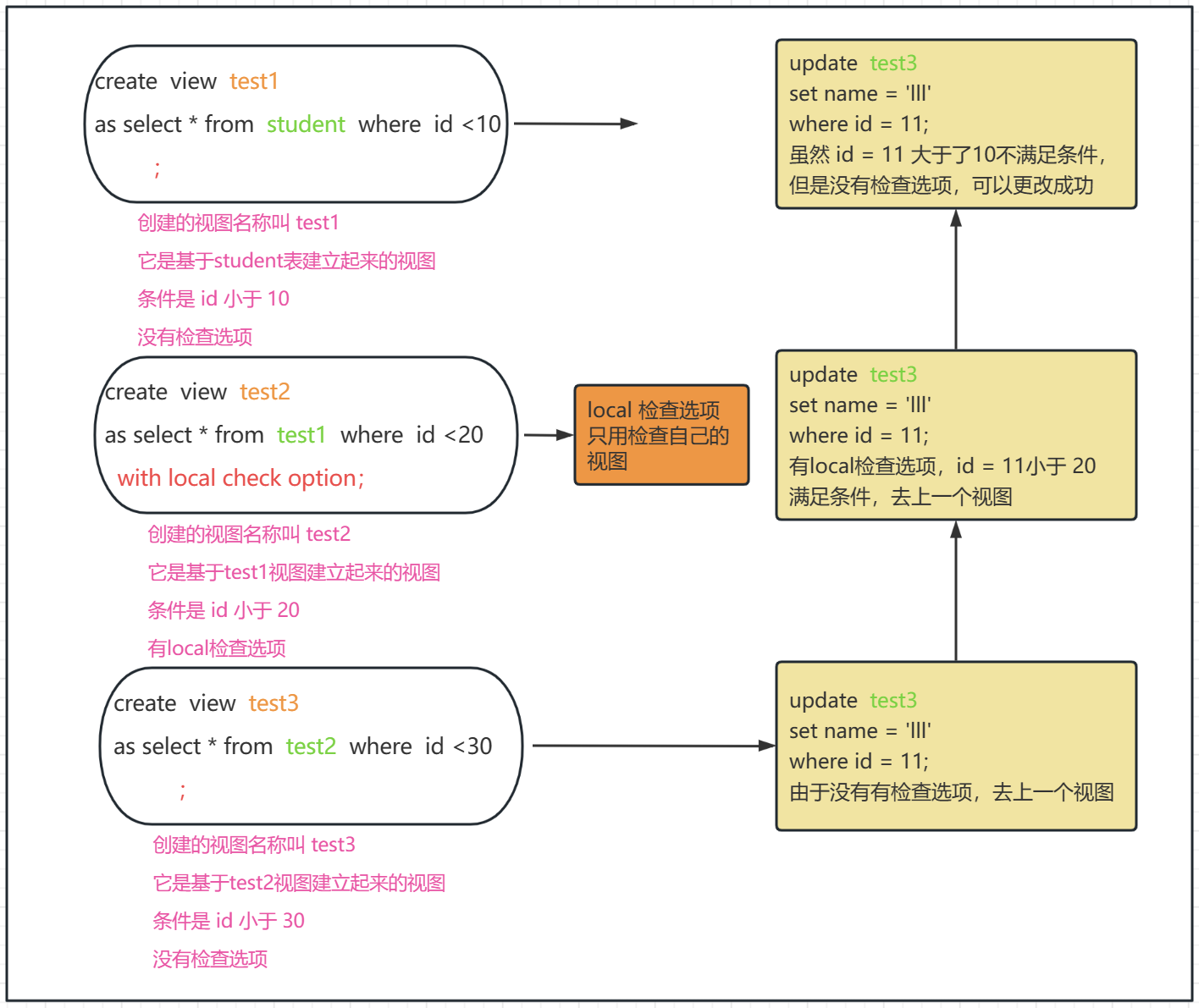
Local:
local关键字只会检查被标识的视图,对于未标识检查选项的视图不会检查,
但是他会一直去查看所构成自己所用到的视图有没有检查选项,这一步是有无检查选项都要经历的,万一上一级视图有检查选项呢?
省流:检查带有local的视图
对于local检查选项和cascade,可以看的出cascade检查选项要麻烦很多,尤其是我们在实际开发中有很多视图的情况,更加会混淆,根本不知道那个视图不满足要求,所以尽量少用cascade,要使用就是用local可以很明显的知道是哪里没有满足条件
这也是为什么阿里巴巴明文禁止使用级联的原因,所以道理都是在实践中探索出来的。
二.索引
什么是索引?
索引 ------是一种提升查找速度的机制

关于索引的详细解释,在我MySQL之B+树中已经讲过了,这里我们主要看看索引的实操
索引的分类:
1.普通索引(index)
它是最基本的索引类型,它没有唯一性等要求,可以提升数据的检索效率,索引都会单独生成一个表文件
2.唯一性索引(unique)
其它的和基本索引差不多,但是唯一性索引的值都是唯一的或者为空
3.主键(primary key)
主键是表中唯一,且不为空,它在一个表中只能有一个
4.全文索引(Fulltext)
全文索引如其名一样,可以进行全文搜索,全文索引只能在varchar和text类型的文本上创建,并且引擎为MyISAM
创建索引:
命令格式:
Create [ unique | fulltext] index 索引名
on 表名(列名(长度)[ ASC | DESC ])
默认升序排序
create index :创建普通索引

create unique index :创建唯一索引

create fulltext index :创建全文索引
全文索引要在MyISAM引擎中创建,我们使用的都是InnoDB,所以就不演示了
create index不能创建主键索引
Alter Table 语句创建索引:
命令格式:
Alter Table 表名
add index 索引名(索引列) //普通索引
add primary key (索引列) // 主键索引
add unique index 索引名 (索引列)//唯一性索引
add fulltext index 索引名 (索引列)//全文索引
从上面的命令我们就可以看到其实我们是可以用alter table命令创建主键的,这是比create index高级一点的地方
并且alter table语句可连续创建,只要 add 命令写完整,并且使用英文逗号分割就可以了
alter table的 单行 命令创建:

alter table的 多行 命令创建:

索引的删除:
命令格式:
drop index 索引名 on 表名
除了主键外,删除索引统一使用index,不需要加上 unique,fulltext,但是此命令删除不了主键

使用alter table 删除索引
命令格式:
Alter Table 表名
drop primariy key // 删除主键
drop index 索引名 // 删除索引
删除命令和添加索引命令一样,只要drop命令写完整了,就可以连续删除了
alter table 的 单行 命令删除:

alter table的 多行 命令删除:

参照完整性约束:
参照完整性是广泛的存在关系型数据库当中的,在这种数据库中,两个或多个表它们之间其实是有联系的,可以通过这些关系一个表在另外的一个表中完成一些映射关系
它在数据库中指的是实体与另一个实体之间的联系
通常参数完整性我们使用外键来标识,参照的表叫子表,被参照的表叫父表
建立了外键,子表中的字段要么为父表中的分量,要么为null
一旦存在外键后两个表就绑定了联系,对于子表的插入,会受限制,当父表的主键没有的分量,子表是无法插入的,也叫此时没有参照关系
对于父表也是,对于父表的删除和更改也会受到限制,要么不能删除,要么和子表一起更改,要么给子表设置为null
外键设置命令格式:
Alter Table 表名
add Foreign ley (子表列名)
References 父表名(父表被参照字段(长度) [ ASC | DESC])
[ on delete { restrict | cascade | set NULL | no action }]
[ on update { restrict | cascade | set NULL | no action } ]
父表的字段名为父表的主键
on delete :父表分量删除时的选项
on update:父表分量更改时的选项
restrict | no action :父表的分量被参照时,要删除或更改时,不允许父表更改和删除
cascade :父表的分量被参照时,要删除或更改时,子表参照的分量和父表的分量进行同步更改
set NULL :父表的分量被参照时,要删除或更改时,子表的参照分量直接置为NULL

删除外键:
我们删除索引或者外键的时候都需要索引和外键名,但是一般我们并没有给外键命名,所以我们就需要使用:show create table 子表名 ,来查看建表时候的操作,也可以查看到外键名
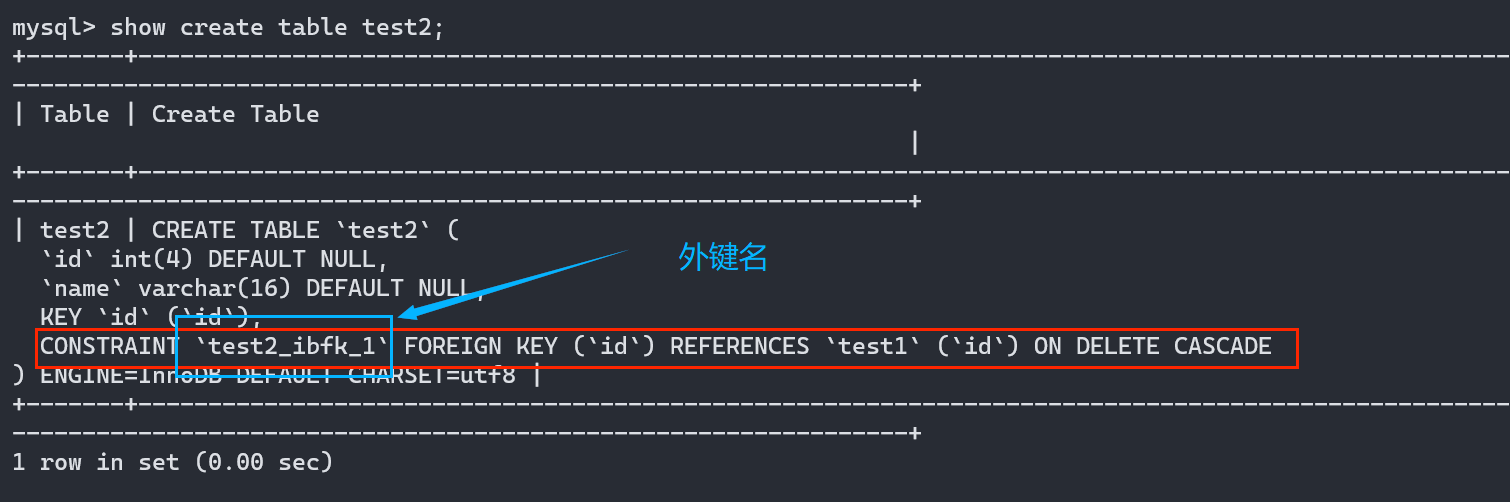
外键删除命令格式:
Alter table 表名
drop foreign key 外键名;
语法都是alter table 但是我们一定要知道外键名才能完成删除,不然是无法删除外键的

使用外键以后,表的删除和更改可见的麻烦,所以在实际开发中应该尽量少用外键,尤其是大量的外键关联,对于关系模型,其实两个表的主键就能联系起来了,没必要使用外键
这也是阿里巴巴明文规定不允许使用外键的原因
三.存储过程
什么是存储过程?
大多数 SQL 语句都是针对一个或多个表的单条语句。并非所有的操作都那么简单。经常会有一个完整的操作需要多条语句才能完成
存储过程简单来说,就是为以后的使用而保存的一条或多条 MySQL 语句的集合。可将其视为批处理文件。虽然他们的作用不仅限于批处理。
存储过程是为了减少服务器端和数据库端传输数据的优化,因为在大量的sql传输过程中其实有大量的语句重复,我们想,如果在数据库端有个模板供我们调用,每次传输只是参数的变动那不就万事大吉了嘛
这就是存储过程的思想:
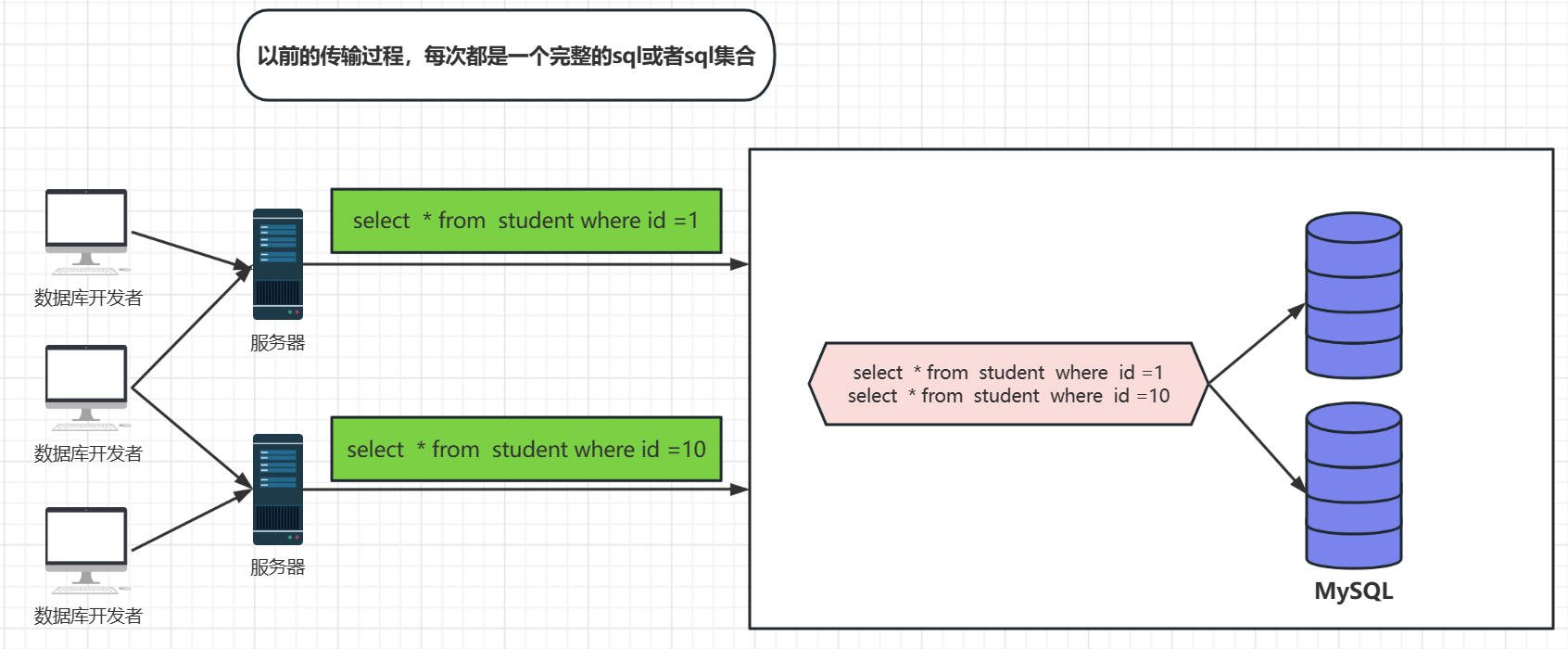
通过上面的图片我们在每次传输的过程都是一条完整的sql,更重要的是每次传输的sql都是一样的,只是参数在变化,这样是及其浪费资源的,所以我们要优化传输
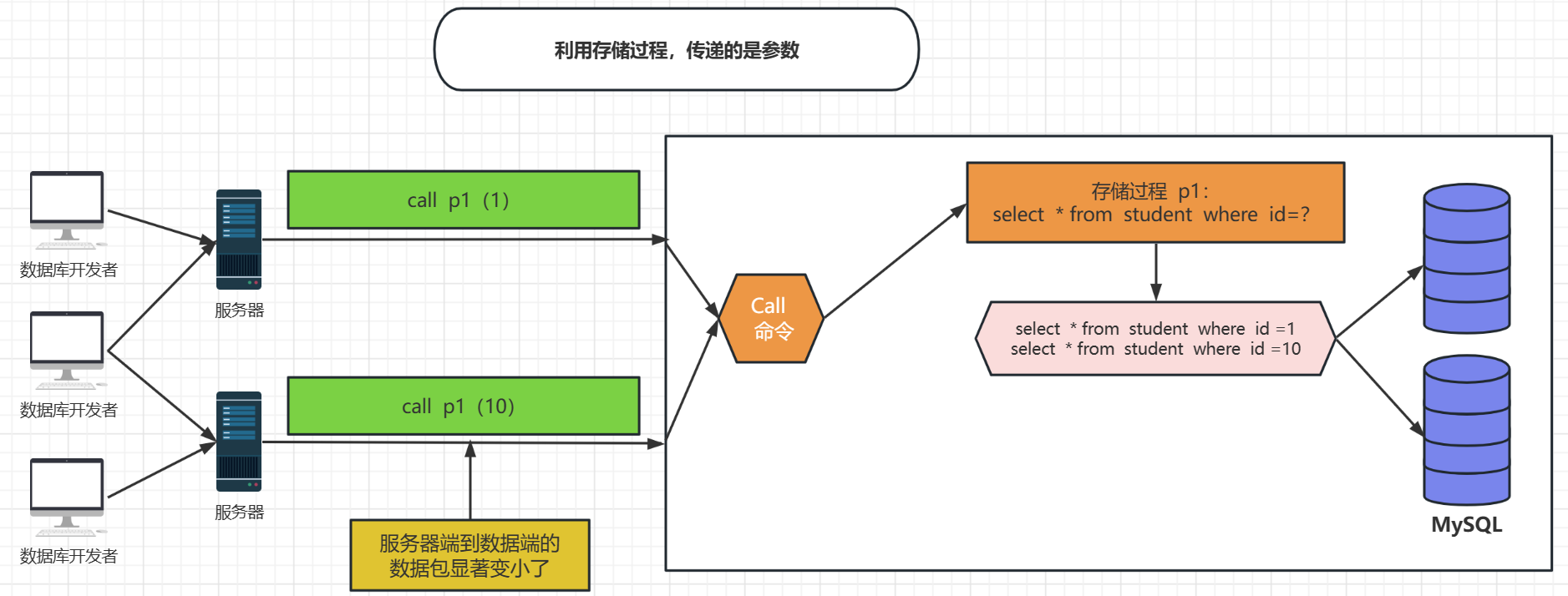
这就是存储过程的产生原因
存储过程的特点:封装,复用,可以接受参数,也可以返回数据,减少网络交互,效率提升
存储过程的基本语法:
命令格式:
Create Procedure 存储过程名称(参数名称)
Begin
sql 语句
End;
调用存储过程:
Call 存储过程名称(参数);

图片就是存储过程的实现,我们来说几个注意点:
- 第一个红框是切换MySQL的sql语句结束符为$$
- 第二个红框存储过程中的sql语句必须是英文分号结尾,它是一句完整的sql,但是分号原来是sql的结束,要是不用delimiter切换结束符就会导致命令提前结束,创建不成功,所以这就是为什么一开始我就切换了的原因(如果不是命令行的操作可以不用切换)
- 第三个红框标识创建存储过程的命令完成了,我们该结束sql了,所以使用delimiter切换了的结束符
- 第四个红框就是调用存储过程
查看存储过程:
命令格式:
select * from information_schema.routines where routine_schema = 'XXX'; XXX为数据库名字
show create procedure 存储过程名;
删除存储过程:
命令格式:
drop procedure 存储过程名;
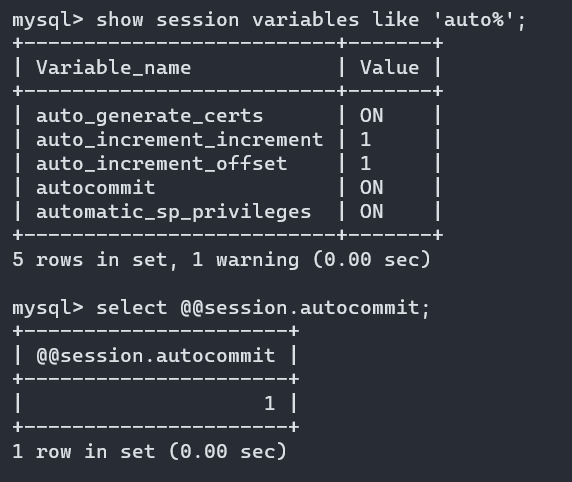
变量之系统变量:
系统变量一共有种:一种是全局变量(global),一种是会话变量(session)
全局变量是:全部用户都可以使用并被限制的
会话变量是:自己和数据库端使用的和被限制的
查看系统变量:
命令格式:
show [ global | session ] variables ; // 查看所有系统变量,默认查找session
show [ global | session ] variables like ' ... .' ;//模糊查找指定变量
select @@[ global | session ] 已知变量名 ; //查找已知的变量
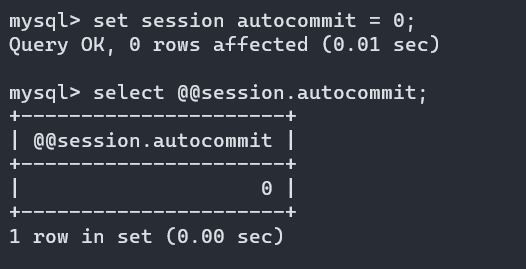
设置系统变量的值:
命令格式:
set [ global | session ] 系统变量名 = 值 ;
set @@[ global | session ] 系统变量名 = 值 ;
变量之用户自定义变量:
用户自定义变量指的是用户根据自己的需求定义的变量,用户变量不用提前声明,用的时候直接使用“@变量名”,作用域为会话级别session
用户自定义的变量是一个 @ ,而系统变量是两个@@
命令格式:
set @var_name = 值; // 普通赋值
set @var_name := 值;
select 字段名, into @var_name from 表名; // 对查询的结果字段映射到变量上
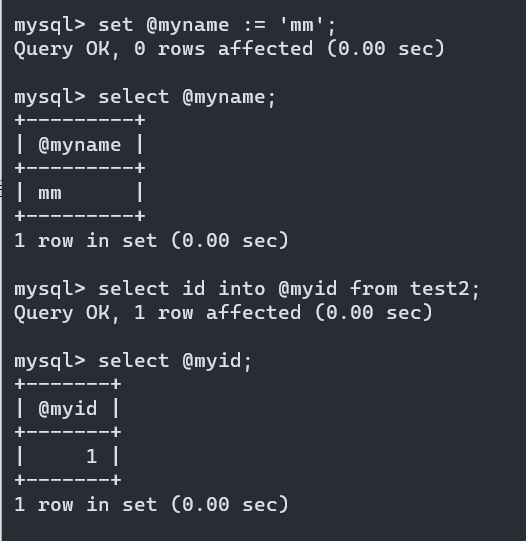
变量的使用:
命令格式:
select @var_name
变量既可以是直接使用,也可以嵌套select结果映射,还可以直接赋值使用
变量之局部变量:
局部变量是定义在局部生效的变量,在访问前必须用 declare 关键字声明为局部变量,可以用于存储过程的输入输出的参数变量
它的作用域只在 begin ...... end 之间
命令格式:
declare 变量名 变量类型 [ default ...] ;
局部变量必须使用declare关键字修饰,并且要有数据类型
赋值:
命令格式:
set 变量名 = 值; // 普通赋值
set 变量名:= 值;
select 字段名, into 变量名 from 表名; // 对查询的结果字段映射到变量上
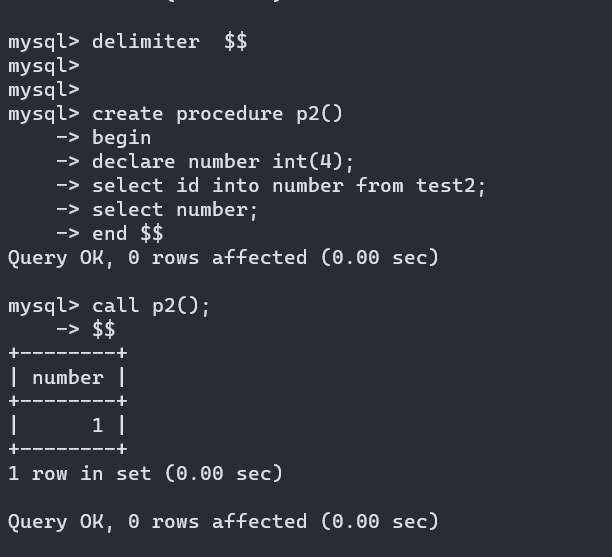
存储过程之存储的变量:
存储过程需要的传入的变量一共有三种类型:
- IN :表示的是输入变量,需要调用存储过程的人进行传入
- OUT:表示的是输出变量,需要调用者有一个变量来接受传回的值
- InOut:表示的是输入输出变量,它即可以作为输入参数进行计算,也可以作为输出参数来回带结果
这三种变量广泛用于存储过程, 用于标识参数的使用范围
MySQL存储过程编程:
存储过程之 IF 判断:
命令格式:
IF 条件 then ......;
elseif 条件 then .......;
else .........;
end if;
注意:elseif必须连写

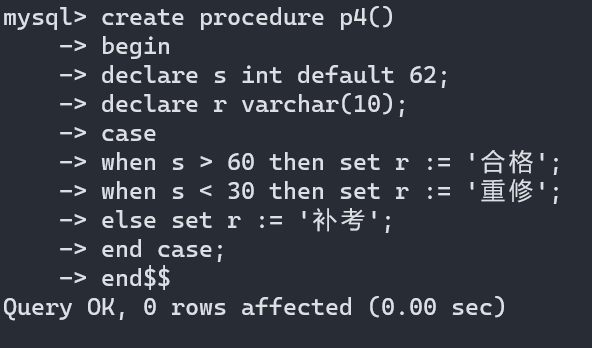
存储过程之case条件判断:
命令格式:
case
when 条件 then .....;
[ when 条件 then .....;]
else .....;
end case;
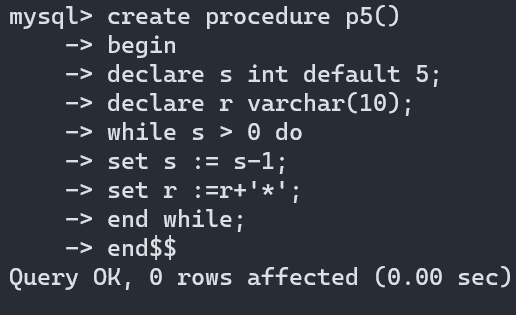
存储过程之while循环:
命令格式:
while 条件 do
sql 语句......
end while;
这里的while和编程语言中的一摸一样,会其一就会其二
存储过程之repeat循环:
命令格式:
repeat
sel 语句.......
until 条件
end repeat;
repaet循环的逻辑和一般的逻辑不一样,它是条件为真的时候退出,条件为假的时候执行,until 子句没有分号
repeat会先执行一次,看是否满足条件,满足就退出循环,不满足条件继续执行
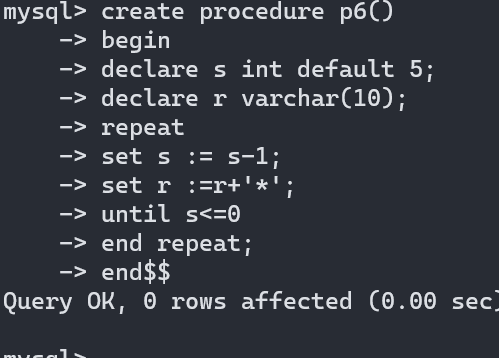
存储过程之loop循环:
命令格式:
[ begin_lable :] loop
sql 语句......
end loop lable;
leave lable; // 指定标记离开循环体
iterate lable; //直接进入下一次循环
特别注意的是 loop没有退出循环的条件,如果没有配置 leave lable将会是一个死循环,建议一定每次使用loop的时候加上 leave lable
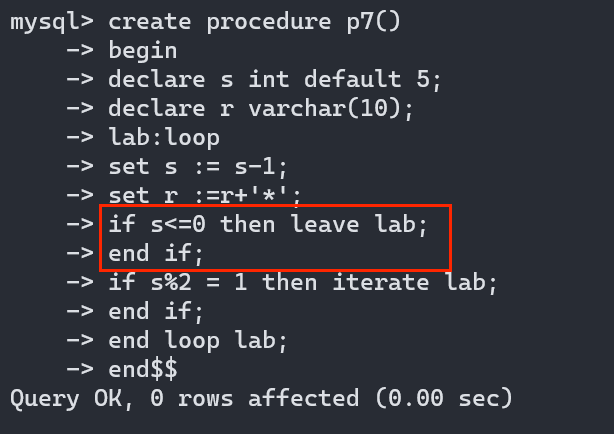
存储函数定义:
命令格式:
create function 函数名(参数【也需要用in/out/inout修饰】)
returns 数据类型 NO sql / deterministic / reads sql data // 必须写不然无法成功,一般选择deterministic
begin
sql语句.........
return 返回值;
end;
存储函数必须要有返回值,也就是调用者必须要要有变量来接受参数不然就会报错,根本执行不了
deterministic :相同的输入参数总是产生相同的结果
NO sql :不包括sql语句
reads sql data:包括读取数据的语句,但是不包括写入数据的语句
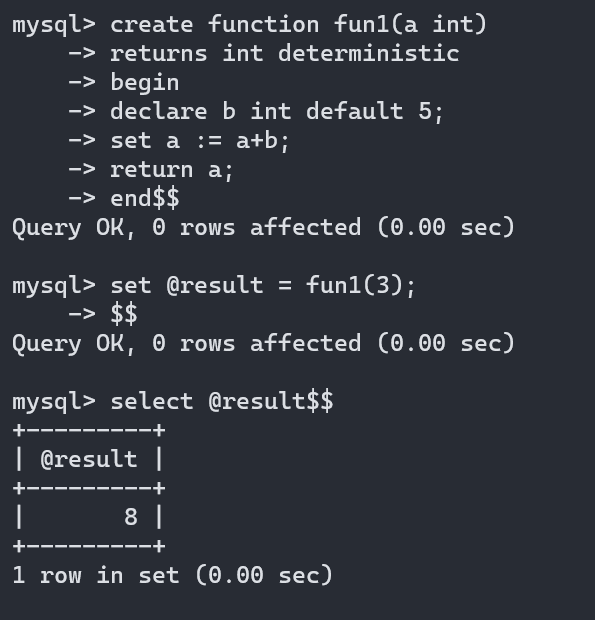
四.触发器
什么是触发器?
触发器是一种用来保障参照完整性的特殊的存储过程,它维护不同表中数据间关系的有关规则。当对指定的表进行某种特定操作(如:Insert,Delete或Update)时,触发器产生作用。触发器可以调用存储过程。
触发器就和它的名字一样触发,触发,什么才能触发呢?
一般是一个触发器绑定的表有增,删,改的时候,触发器就会有一个行为
什么行为?什么语句触发?什么时候触发?都是开发者自定义的
接下来我们看看触发器的创建命令
注意下面强调的NEW和OLD关键字单独使用没有任何意义,需要使用NEW.cloum_name,OLD.cloum_name,关键字加列名才能生效
查看触发器
命令格式:
show triggers;
触发器之insert型:
NEW关键字用于标识insert 语句将要或者已经更新的数据
命令格式:
create trigger trigger_name
before/after insert on table_name for each row
begin
sql语句......
trigger_stmt;
end;
关键词解释:
before/after :指的是触发器会在绑定表的sql执行前还是执行后插入
for each row :行级触发器,指的是每次只要是绑定表的一行增 / 删 / 改 都会触发
trigger_stmt :主要是指的 触发器的NEW和old关键字使用

触发器之update型:
OLD关键字表示修改前的数据,NEW表示修改之后的数据
命令格式:
create trigger trigger_name
before/after update on table_name for each row
begin
sql语句......
trigger_stmt;
end;

触发器之delete型:
OLD关键字表示删除的数据
命令格式:
create trigger trigger_name
before/after delete on table_name for each row
begin
sql语句......
trigger_stmt;
end;
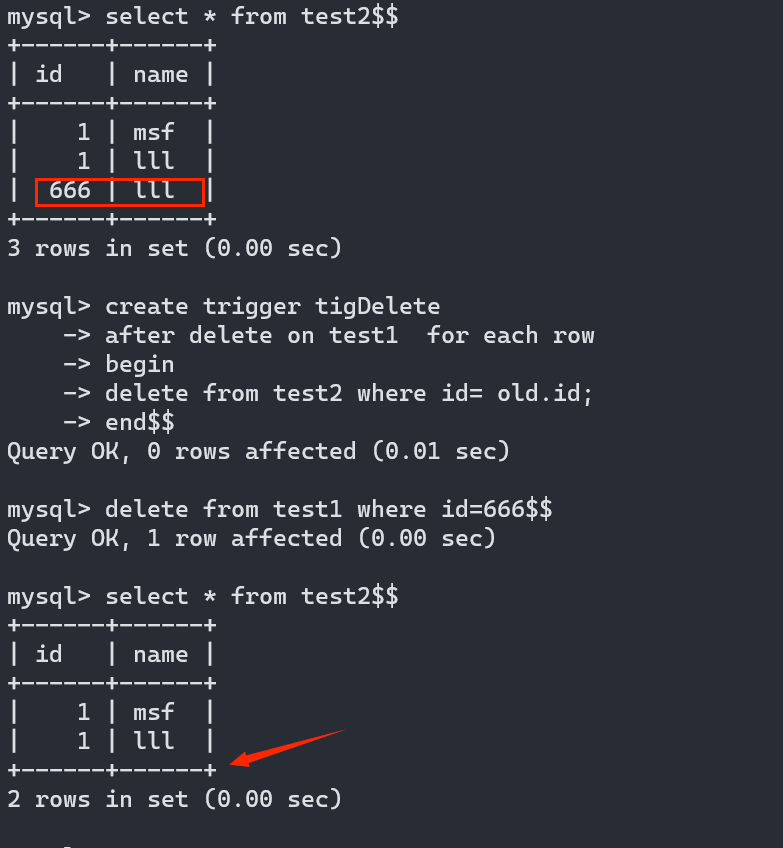
我的例子触发器触发的表都是test1,而触发器产生相应操作的表都是test2

