
- 1宝塔搭建站点(无域名版本、解决80端口占用)_宝塔没有域名直接做网站怎么弄
- 2大数据分析-用户画像详解_大数据画像隐患多
- 3新修订的《中华人民共和国保守国家秘密法》完善了定密授权制度,明确特殊情况下“()保密行政管理部门或者()保密行政管理部门可以授予机关、单位定密权限”。_特殊情况下保密行政部门或者
- 4华为OD机试C卷-- 最长子字符串的长度(二)(Java & JS & Python & C)
- 5axios拦截器和token_axios 拦截器 token
- 6Windows10下安装解压版MySQL8.0.12_win10解压mysql8.0
- 7python tkinter控件_Python TKinter布局管理Place()Grid Pack详解
- 8Ambari-2.7.5.0 + HDP-3.1.5.0网盘地址_hdp3.1.5 ubuntu ambari 2.7.5
- 9在linux中重启网络服务的命令,linux重启网络命令
- 10数据分析案例-基于亚马逊智能产品评论的探索性数据分析_08亚马逊评论数据集教程
【Spring】Spring的循环依赖以及解决方案_spring循环依赖
赞
踩
1. 什么是Spring循环依赖?
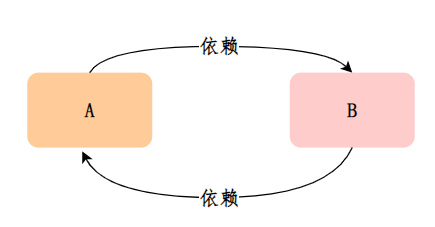
Spring循环依赖指的是两个或多个Bean之间相互依赖,形成一个环状依赖的情况。通俗的说,就是A依赖B,B依赖C,C依赖A,这样就形成了一个循环依赖的环。
Spring循环依赖通常会导致Bean无法正确地被实例化,从而导致应用程序无法正常启动或者出现异常。因此,Spring循环依赖是一种需要尽量避免的情况。
2. 常见形成原因
1. 构造函数循环依赖
在使用构造函数注入Bean时,如果两个Bean之间相互依赖,就可能会形成构造函数循环依赖,例如:
@Component
public class A {
private B b;
public A(B b) {
this.b = b;
}}
==============
@Component
public class B {
private A a;
public B(A a) {
this.a = a;
}}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
上述代码,A、B的构造函数分别需要创建对方,A依赖B,B依赖A,它们之间形成了一个循环依赖。
当Spring容器启动时,它会尝试先实例化A,但是在实例化A的时候需要先实例化B,而实例化B的时候需要先实例化A,这样就形成了一个循环依赖的死循环,从而导致应用程序无法正常启动。
2. 属性循环依赖
在使用属性注入Bean时,如果两个Bean之间相互依赖,就可能会形成属性循环依赖。例如:
@Component
public class A {
@Autowired
private B b;
}
=============
@Component
public class B {
@Autowired
private A a;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
类似的,同样Spring在实例化A时会注入B,而注入B时又需要注入A,形成循环依赖
3. Spring如何解决循环依赖
要了解如何解决Spring的循环依赖,就必须要从Spring对Bean的创建过程入手,从原理上去理解,而不是单纯记忆
3.1 Spring 是如何创建Bean的?
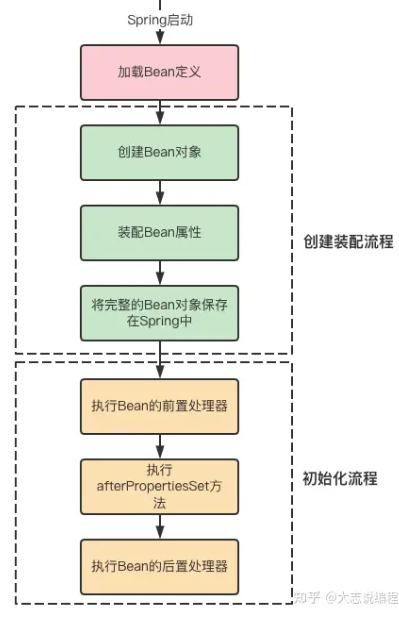
(1) 首先Spring容器启动之后,会根据使用不同类型的Application Context,通过不同的方式去加载Bean配置,如xml方式、注解方式,将这些Bean配置加载到容器中,作为Bean定义包装成BeanDefinition对象保存起来,为下一步创建Bean做准备。
(2) 根据加载的Bean定义信息,通过反射来创建Bean实例,如果是普通Bean,则直接创建Bean,如果是FactoryBean,说明真正要创建的对象为getObject()的返回值,调用getObject()将返回值作为Bean。
(3) 目前已经完成了Bean实例的创建,还需要对依赖的属性进行装配,例如,平时开发中Controller中,往往需要将Service Bean注入进来,循环依赖也是在这一步解决的,后面会详细说明,如果通过@Autowired注解注入的成员变量,则会通过AutowiredAnnotationBeanPostProcessor后置处理器进行注入,如果xml自动注入,则会根据按名字自动装配和按类型自动装配分别进行处理。
(4) 自动装配完成后,将完整的Bean对象保存到Spring 缓存中,接下来进入Bean的初始化流程,执行Bean的后置处理器的前置处理方法,如果Bean本身实现了InitializingBean接口,就去执行对应的afterPropertiesSet()方法,最后再执行Bean的后置处理器的后置处理方法。
3.2 Spring三级缓冲机制
1. Spring可以解决的依赖循环
回到上述的依赖循环案例,A、B相互依赖时,产生的循环依赖现象还需进一步细分:
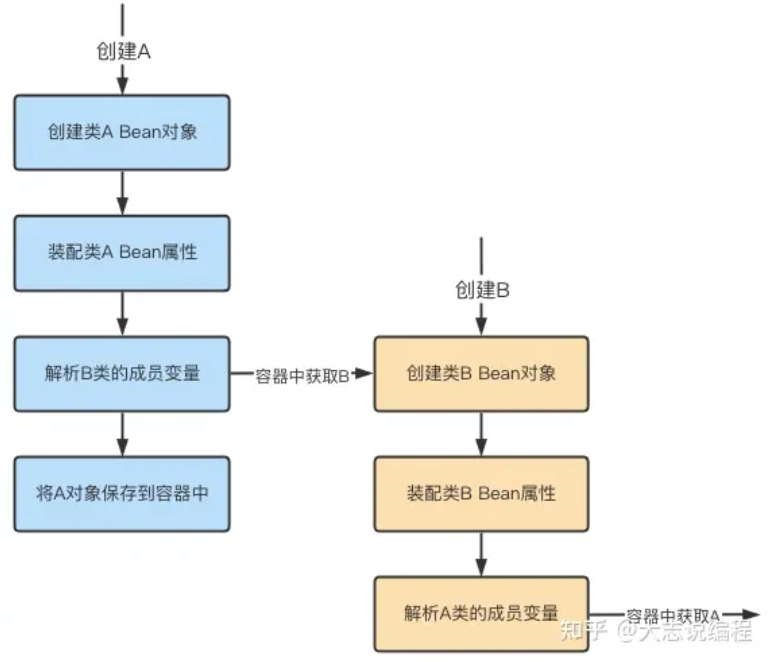
注意:只有单例的 Bean 存在循环依赖的情况,Spring才可以解决,原型(Prototype)情况下,Spring 会直接抛出异常。
Spring 不支持基于构造器注入的循环依赖。 但是假如 AB 循环依赖,如果一个是构造器注入,一个是 setter 注入呢?
看看几种情形:

第四种可以而第五种不可以的原因是 Spring 在创建 Bean 时默认会根据自然排序进行创建,所以 A 会先于 B 进行创建。
简单总结,当循环依赖的实例都采用 setter 方法注入的时候,Spring 可以支持,都采用构造器注入的时候,不支持,构造器注入和 setter 注入同时存在的时候,看天。
2. 三层缓存机制
bean的创建流程:
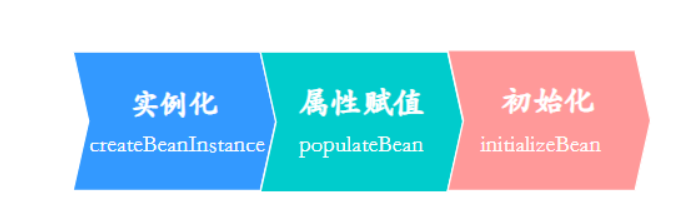
依赖注入就发生在第二步,属性赋值,结合这个过程,Spring 通过三级缓存解决了循环依赖:
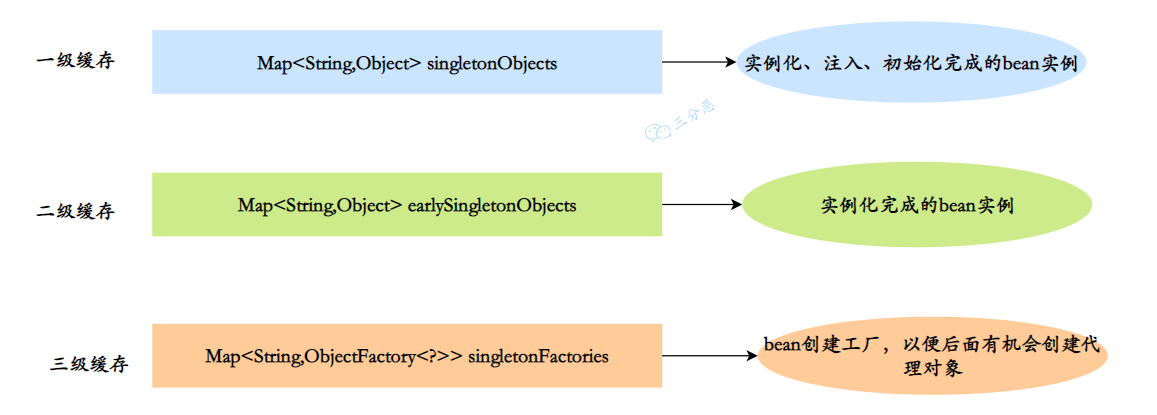
- 一级缓存 :
Map<String,Object>singletonObjects,单例池,用于保存实例化、属性赋值(注入)、初始化完成的 bean 实例 - 二级缓存 :
Map<String,Object>earlySingletonObjects,早期曝光对象,用于保存实例化完成的 bean 实例 - 三级缓存 :
Map<String,ObjectFactory<?>>singletonFactories,早期曝光对象工厂,用于保存 bean 创建工厂,以便于后面扩展有机会创建代理对象。
我们来看一下三级缓存解决循环依赖的过程:
当 A、B 两个类发生循环依赖时:
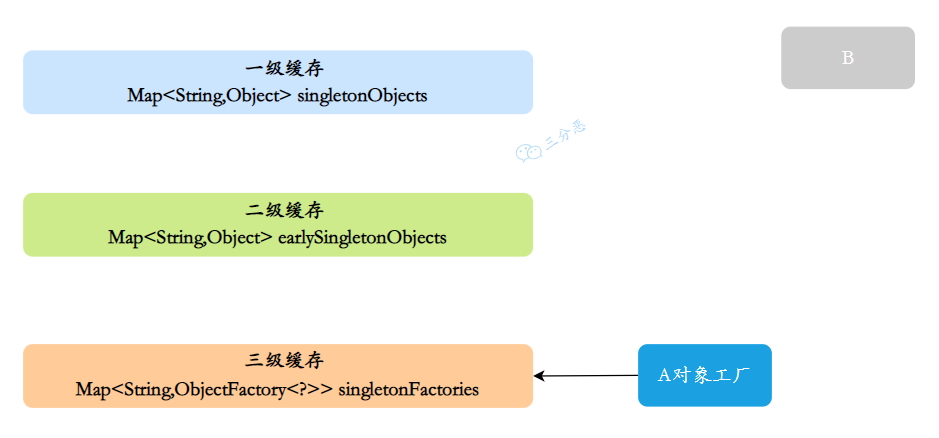
A 实例的初始化过程:
- 创建 A 实例,实例化的时候把 A 对象⼯⼚放⼊三级缓存,表示 A 开始实例化了,虽然我这个对象还不完整,但是先曝光出来让大家知道
 1
1
- A 注⼊属性时,发现依赖 B,此时 B 还没有被创建出来,所以去实例化 B
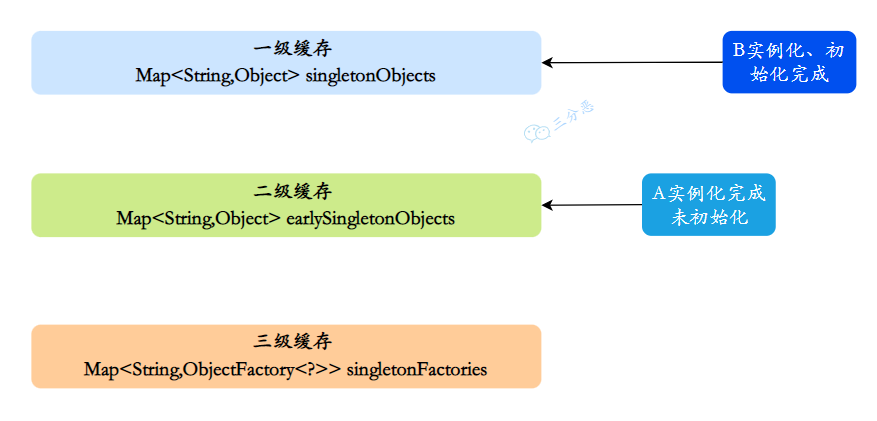
- 同样,B 注⼊属性时发现依赖 A,它就会从缓存里找 A 对象。依次从⼀级到三级缓存查询 A,从三级缓存通过对象⼯⼚拿到 A,发现 A 虽然不太完善,但是存在,把 A 放⼊⼆级缓存,同时删除三级缓存中的 A,此时,B 已经实例化并且初始化完成,把 B 放入⼀级缓存。
 2
2
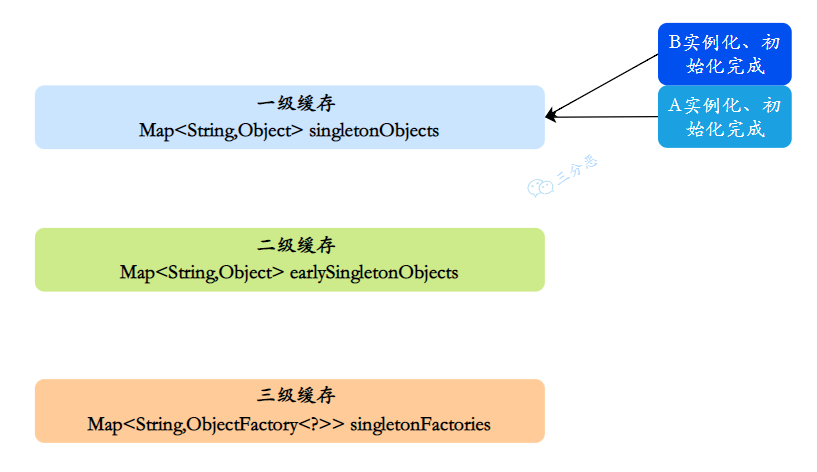
- 接着 A 继续属性赋值,顺利从⼀级缓存拿到实例化且初始化完成的 B 对象,A 对象创建也完成,删除⼆级缓存中的 A,同时把 A 放⼊⼀级缓存
- 最后,⼀级缓存中保存着实例化、初始化都完成的 A、B 对象
 5
5
所以,我们就知道为什么 Spring 能解决 setter 注入的循环依赖了,因为实例化和属性赋值是分开的,所以里面有操作的空间。如果都是构造器注入的化,那么都得在实例化这一步完成注入,所以自然是无法支持了。
所以,我们就知道为什么 Spring 能解决 setter 注入的循环依赖了,因为实例化和属性赋值是分开的,所以里面有操作的空间。如果都是构造器注入的化,那么都得在实例化这一步完成注入,所以自然是无法支持了。

