
- 1spark为什么比mapreduce快?_下面哪些是spark比mapreduce计算快的原因(4分) a 基于内存的计算 b 基于dag的调
- 2Android 进阶——常用的Base64编码算法和MD5 信息摘要算法详解_android md5
- 3使用llama.cpp实现LLM大模型的格式转换、量化、推理、部署
- 4LLM 大模型实用指南 | The Practical Guides for Large Language Models_ret-llm: towards a general read-write memory for l
- 5activemq的优势_【消息队列】1-为什么使用消息队列?消息队列有什么优点和缺点?Kafka、ActiveMQ、RabbitMQ、RocketMQ 都有什么优点和缺点?...
- 6数据结构之B树
- 7智能新时代的天津故事
- 8谷歌插件市场
- 9请求限流算法有哪些?分别面向什么应用场景?_对用户请求限流
- 10华为OD机试C卷-- 贪吃的猴子(Java & JS & Python & C)
【机器学习小实验2】逻辑回归实例-乳腺癌肿瘤预测_天津大学机器学习逻辑回归实验
赞
踩
###实验所需的数据以及源码下载###
一、实验目的
1.熟悉逻辑回归原理掌握sklearn逻辑回归相关API。
2.掌握LogisticRegression函数和LogisticRegressionCV的调用和调参。
3.掌握交叉验证的使用。
二、代码及结果
1.查看数据集基本信息,去掉异常符号。
粘贴代码:
import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.linear_model import LogisticRegression from sklearn.linear_model import LogisticRegressionCV from sklearn.metrics import classification_report,accuracy_score from sklearn.model_selection import cross_val_score, KFold import matplotlib.pyplot as plt from sklearn.metrics import precision_recall_curve, auc from sklearn.metrics import roc_curve, auc column_names = ['Sample code number','Clump Thickness','Uniformity of Cell Size','Uniformity of Cell Shape','Marginal Adhesion','Single Epithelial Cell Size','Bare Nuclei','Bland Chromatin','Normal Nucleoli','Mitoses','Class'] dataFrame = pd.read_csv("./breast-cancer-wisconsin.data",names = column_names) dataFrame.head() dataFrame.info() # 将?替换成标准缺失值表示 dataFrame = dataFrame.replace('?',value = np.nan) # 丢弃带有缺失值的数据 dataFrame = dataFrame.dropna(how='any') dataFrame.shape

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
结果:

2.根据notebook提示实验,sklearn中与逻辑回归有关的函数LogisticRegression函数和LogisticRegressionCV函数的默认参数补全代码。
粘贴代码:
# 3.准备训练测试数据 # 数据中第一列到第九列为输入X X = dataFrame[column_names[1:10]] # 第十列为标签y y = dataFrame[column_names[10]] # 将目标变量转换为 {0, 1} y = np.where(y == 4, 1, 0) X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.25,random_state=42) # 4. 标准化数据 # 标准化数据,保证每个维度的特征数据方差为1,均值为0。使得预测结果不会被某些维度过大的特征值而主导 sc = StandardScaler() X_train = sc.fit_transform(X_train) X_test = sc.transform(X_test) # 调用linear_model.LogisticRegression模型进行建模 lr = LogisticRegression() # 调用fit函数训练模型,确定参数 lr.fit(X_train,y_train) # 调用predict函数进行预测,得到y_predict,并打印出y_predict y_predict = lr.predict(X_test) # 输出测试个数和预测正确的个数 print("测试个数:",len(y_test)) count = 0 for i in range(len(y_test)): if y_predict[i] == y_test[i]: count += 1 print("预测正确个数:",count) # 调用coef_得到预测模型的系数,应该有9个系数,并打印出来 print("预测模型的系数:",lr.coef_) print("测试集预测结果:",y_predict) # 使用score函数得到测试数据的准确率,并打印 #print("准确率:",accuracy_score(y_test,y_predict)) print("准确率:",lr.score(X_test,y_test)) # 调用metrics中的classification_report函数输入y_test和y_predict查看查准率和查重率 print("查准率与查全率:",classification_report(y_test,y_predict,labels = [0,1],target_names=["良性","恶性"]))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
3.运行上述默认参数代码即LogisticRegression()和LogisticRegressionCV()的默认参数,根据要求打印两种实验结果。
打印测试数据个数和预测正确个数,打印权重、准确率、预测结果和查准率与查重率:
粘贴代码:
# 调用linear_model.LogisticRegression模型进行建模 lr = LogisticRegression() # 调用fit函数训练模型,确定参数 lr.fit(X_train,y_train) # 调用predict函数进行预测,得到y_predict,并打印出y_predict y_predict = lr.predict(X_test) # 输出测试个数和预测正确的个数 print("测试个数:",len(y_test)) count = 0 for i in range(len(y_test)): if y_predict[i] == y_test[i]: count += 1 print("预测正确个数:",count) # 调用coef_得到预测模型的系数,应该有9个系数,并打印出来 print("预测模型的系数:",lr.coef_) print("测试集预测结果:",y_predict) # 使用score函数得到测试数据的准确率,并打印 #print("准确率:",accuracy_score(y_test,y_predict)) print("准确率:",lr.score(X_test,y_test)) # 调用metrics中的classification_report函数输入y_test和y_predict查看查准率和查重率 print("查准率与查全率:",classification_report(y_test,y_predict,labels = [0,1],target_names=["良性","恶性"])) lrcv = LogisticRegressionCV() lrcv.fit(X_train,y_train) y_predict_cv = lrcv.predict(X_test) # 输出测试个数和预测正确的个数 print("cv测试个数:",len(y_test)) count = 0 for i in range(len(y_test)): if y_predict_cv[i] == y_test[i]: count += 1 print("cv预测正确个数:",count) # 调用coef_得到预测模型的系数,应该有9个系数,并打印出来 print("cv预测模型的系数:",lrcv.coef_) print("cv测试集预测结果:",y_predict_cv) # 使用score函数得到测试数据的准确率,并打印 #print("cv准确率:",accuracy_score(y_test,y_predict_cv)) print("cv准确率:",lrcv.score(X_test,y_test)) # 调用metrics中的classification_report函数输入y_test和y_predict查看查准率和查重率 print("cv查准率与查全率:",classification_report(y_test,y_predict_cv,labels = [0,1],target_names=["良性","恶性"]))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
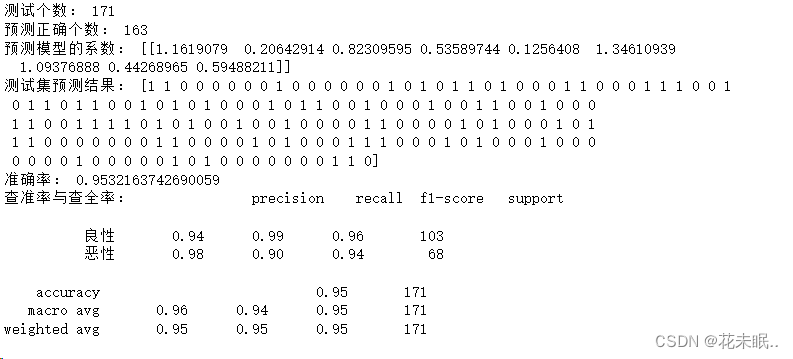
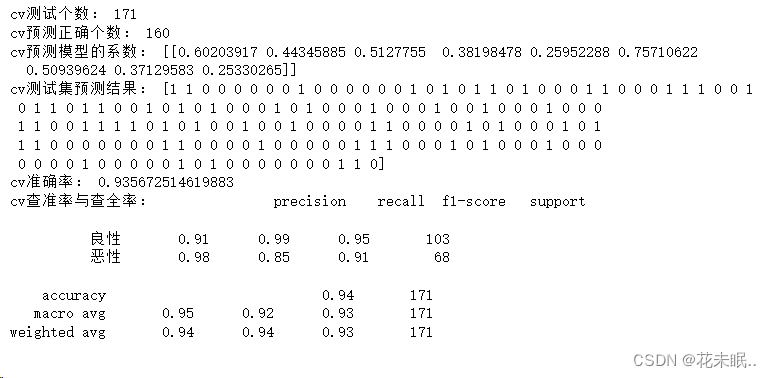
运行结果:
4.以2为例,使用不同参数C(正则化强度倒数)的LogisticRegression函数进行实验,设置C=0.1和0.01进行实验。实验结果按照上述要求打印两种实验结果。
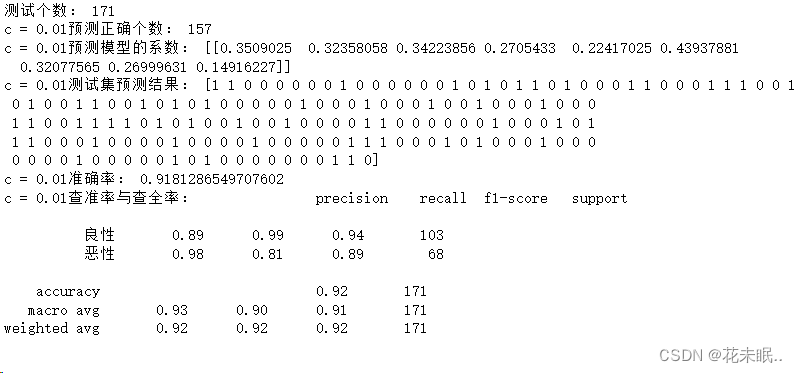
打印结果:

5.绘制ROC曲线:
粘贴代码:
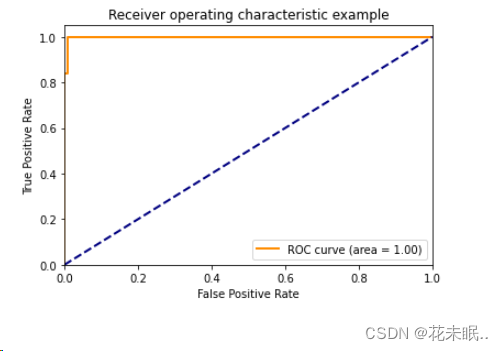
# 获取预测概率 y_scores = lr.predict_proba(X_test)[:, 1] fpr, tpr, thresholds = roc_curve(y_test, y_scores) auc =roc_auc_score(y_test, y_scores) plt.figure() lw = 2 plt.plot(fpr, tpr, color='darkorange', lw=lw, label='ROC curve (area = %0.2f)' % auc) plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--') plt.xlim([0.0, 1.0]) plt.ylim([0.0, 1.05]) plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.title('Receiver operating characteristic example') plt.legend(loc="lower right") plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
运行结果:
6.进行十折交叉验证。
粘贴代码:
#法一: score = 0 kfold = KFold(n_splits=10) for train_index, test_index in kfold.split(X,y): # train_index 就是分类的训练集的下标,test_index 就是分配的验证集的下标 train_x, test_x = X.iloc[train_index], X.iloc[test_index] train_y, test_y = y[train_index], y[test_index] # 训练本组的数据,并计算准确率 # 调用linear_model.LogisticRegression模型进行建模 lr = LogisticRegression() # 调用fit函数训练模型,确定参数 lr.fit(train_x,train_y) prediction = lr.predict(test_x) score += lr.score(test_x, test_y) print("模型的平均准确率为:",score/10) #法二: #进行十折交叉验证 kf = KFold(n_splits=10) lr = LogisticRegression() precision_scores = cross_val_score(lr, X, y, cv=kf, scoring='accuracy') precision_mean = np.mean(precision_scores) print(f'Average accuracy: {precision_mean:.6f}')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
运行结果:
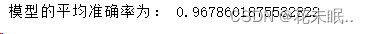
三、结果分析
1.LogisticRegression 和 LogisticRegressionCV 的对比:
LogisticRegression 的准确率为 0.9532,而 LogisticRegressionCV 的准确率为 0.9357。这两者的准确率相差不大,但 LogisticRegression 稍高。这可能表明在这个问题上,默认的 LogisticRegression 参数效果较好,不需要通过交叉验证选择正则化强度。
2.不同正则化参数 C 的实验:
对于 C=0.1,准确率为 0.9415,而对于 C=0.01,准确率为 0.9181。这表明在这个问题上,较小的正则化强度(C=0.01)可能导致一些过拟合,准确率较低。而 C=0.1 提供了一个较好的平衡,提高了模型的性能。
3.十折交叉验证的结果:
十折交叉验证模型的平均精确率为 0.9679,这是一个相对较高的值。这表明模型在不同的训练集和验证集上都表现得很好,具有较好的泛化能力。
四、实验总结
在这个乳腺癌肿瘤预测问题上,使用默认参数的 LogisticRegression 在测试集上表现较好。通过 LogisticRegressionCV 进行正则化参数选择,虽然准确率略低,但也能得到可接受的性能。通过调整正则化参数 C,发现在此问题上 C=1 的性能最好。
实验结果表明,逻辑回归在这个二分类问题上表现良好,具有较高的准确率。
十折交叉验证的结果强化了模型的鲁棒性和泛化能力。可能的改进方向有以下两个:一是进一步尝试不同的特征工程方法,或者考虑特征选择,以优化模型的输入。二是可以尝试其他分类算法,比较它们在这个问题上的性能,寻找更好的模型。

