
热门标签
热门文章
- 1金融质检新纪元:AI技术如何重塑服务体验
- 2求0~10000的水仙花数_0-10000水仙花
- 3基于SSM的“小型企业人事管理系统”的设计与实现(源码+数据库+文档+PPT)_ssm人力资源管理系统代码
- 4树莓派puttyl连接_putty连接树莓派
- 5包含libusb库文件报错:libusb-1.0/libusb.h: No such file or directory_libusb-1.0-0-dev
- 6深入解析SOME/IP协议在汽车行业的应用案例_汽车ip协议
- 7【粉丝投稿】上海某大厂的面试题,岗位是测开(25K*16)_大厂测开
- 8Kafka(三)生产者发送JSON消息+使用统一序列化器+提升吞吐量_kafka json序列化
- 9AI大模型探索之路-实战篇:智能化IT领域搜索引擎的构建与初步实践
- 10ireport中文手册3.7版(无图)_ireport中文版
当前位置: article > 正文
文本相似度计算_文本聚类判断两文本相似度
作者:小舞很执着 | 2024-07-07 02:21:18
赞
踩
文本聚类判断两文本相似度
一、简介
文本相似度是进行文本聚类的基础,和传统的结构化数值数据的聚类方法相似,文本聚类是通过计算文本之间的“距离”来表示文本之间的相似度,并产生聚类。文本相似度的常用计算反法有余弦定理。但是文本数据和普通的数据不同,它是一种半结构化的数据,在进行聚类之前必须要对文本数据源进行处理,如分词、向量化表示等,其目的就是使用向量化的数值来表达这些半结构化的文本数据。使其适用于文本分析。
二、TF-IDF算法
在一份给定的文件里,词频(term frequency,TF)指的是某一个给定的词语在该文本中出现的次数(该次数一般会归一化处理,以防止它偏向长文本)。
在给定的文件里,词频

其中,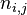 表示该词在文件
表示该词在文件
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小舞很执着/article/detail/794601
推荐阅读
相关标签

