
- 1linux 使用FIO测试磁盘iops_fio does not have enough space. current left space
- 2mac中JAVA环境变量配置步骤_mac配置java环境变量
- 3机器学习在教育领域的应用:个性化学习智能评测教育资源推荐_个性化学习与智能推荐
- 4Flink常见面试题总结_flank流面试题
- 5Python医疗数据分析与可视化_医疗大数据可视化分析
- 6Python闭包:深入解析与使用场景_python闭包的应用场景
- 7搭建Hive平台
- 8数据结构——顺序表(单链表)系列问题(c++)
- 9M1芯片苹果电脑关闭SIP详细教程_m1 芯片 关闭sip
- 10git clone项目_git clone signin
Are Emergent Abilities of Large Language Models a Mirage?
赞
踩
Paper name
Are Emergent Abilities of Large Language Models a Mirage?
Paper Reading Note
Paper URL: https://arxiv.org/pdf/2304.15004.pdf
Video URL: https://www.youtube.com/watch?v=hZspGdApDIo
TL;DR
- 2023 年斯坦福的研究,探索大语言模型表现出涌现能力的原因,初步结论是涌现能力主要是由研究人员选择一个非线性或不连续的评价指标导致的,另外探索了如何诱导涌现能力的出现,本文在视觉任务上通过对评价指标的修改复现了涌现现象。
Introduction
背景
- 最近的工作声称大型语言模型表现出涌现能力,也即只在大模型上有的现象,一般在小模型上不会出现
- 涌现能力最初是在 GPT3 上观察到的
- 最近一些工作认为 llm 应该要具备类似“突然的、特定的能力缩放”的涌现能力
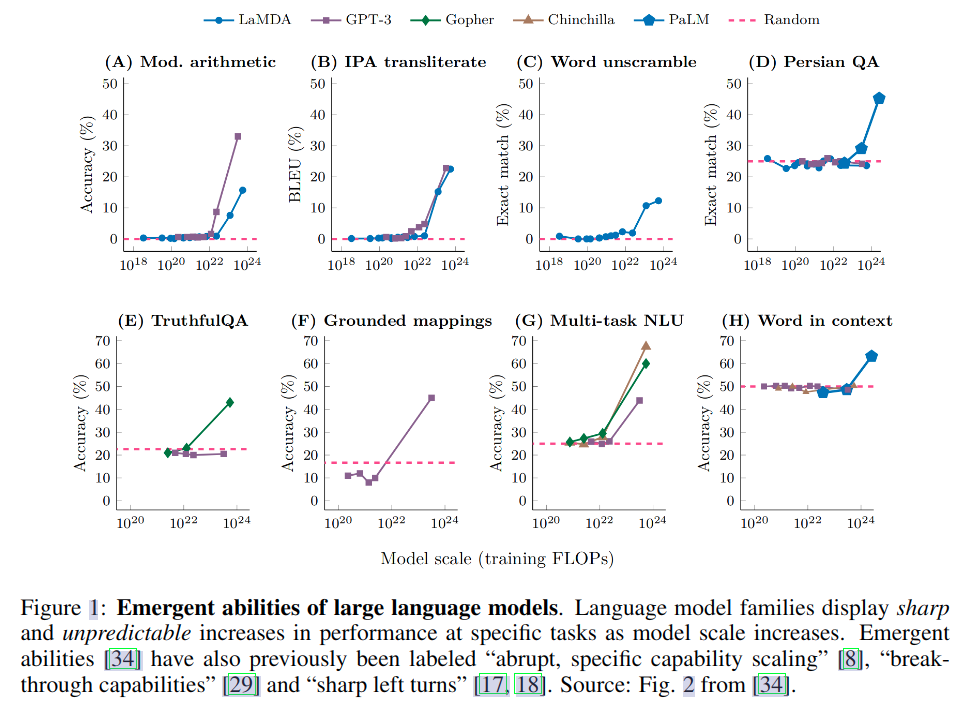
- 有两个原因让涌现能力变得有趣
- 突变:该现象从之前的不存在到现在的存在过渡似乎是瞬间发生
- 不可预测:在看似不可预见的模型尺度上过渡
- 神奇的涌现能力也不禁让我们产生一些思考:
- 什么控制了涌现能力的出现?
- 什么控制了何时出现涌现能力?
- 如何让涌现能力更快出现?
本文方案
- 本文发现涌现能力似乎仅在非线性或不连续地缩放模型的 token 错误率的指标下出现

- 这就提出了对 LLM 涌现能力来源的另一种解释: 研究人员选择测量指标可能会导致看似尖锐和不可预测的变化,即使模型的每个 token 错误率随着模型规模增加而平滑、连续和可预测地变化。也即涌现能力是由研究人员选择一个非线性或不连续的评价指标导致的,另外也有一部分测试数据较少的原因(导致小模型看起来完全无法执行任务)以及评估的大规模模型较少
- 在一个简单的数学模型上展示了本文的解释,然后以三种互补的方式对提出的解释进行验证:
- 利用 InstructGPT/GPT-3 模型系列验证了三个评价指标会导致的影响预测
- BIG-Bench 上分析关于度量选择的影响预测,在“任务-指标-模型”的三元组上,验证了只有一些特定的指标上出现了涌现能力。在固定模型输出的情况下,修改评价指标就会导致涌现能力消失
- 视觉任务上引入非线性或不连续的评价指标后也可以展现出涌现能力
- 在所有三个分析中,本文发现了强有力的支持证据,证明涌现能力可能不是缩放 AI 模型的基本属性
Dataset/Algorithm/Model/Experiment Detail
实现方式
涌现能力的解释
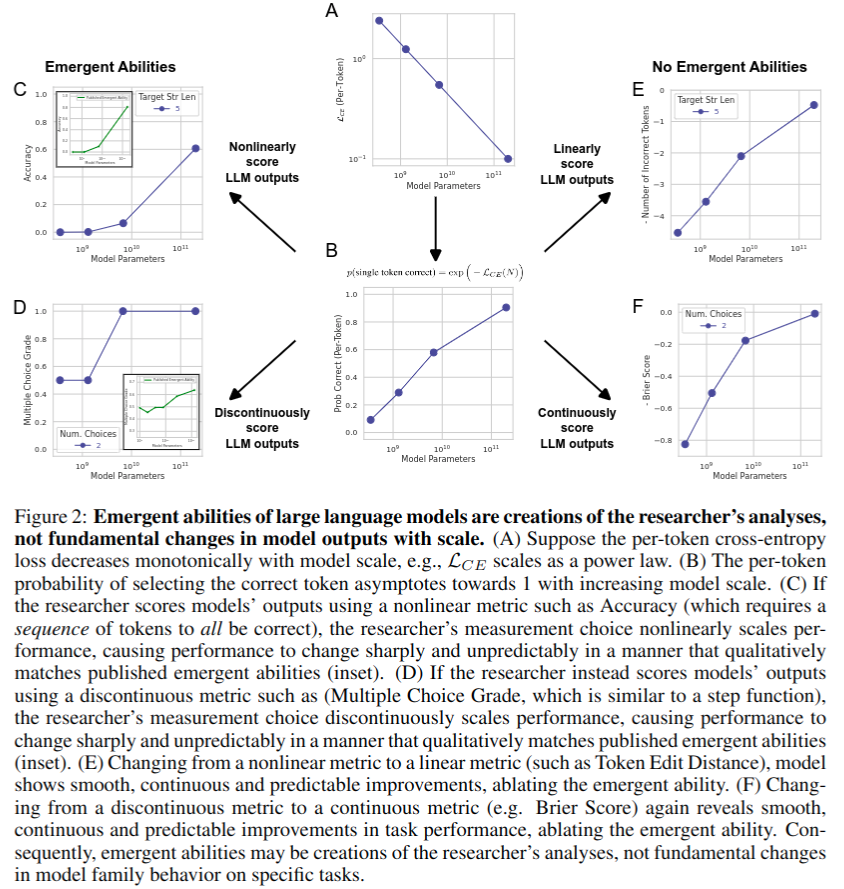
-
neural scaling laws:经验观察,深度网络在测试损失中表现出是训练数据集大小、参数数量(模型大小)或计算的幂律缩放函数
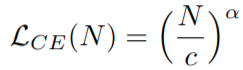
其中 N 是模型参数量,c>0, α < 0 \alpha<0 α<0 ,如上图 A 所示 -
写成 per-token 交叉熵的形式
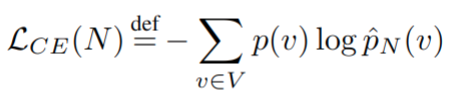
实际上替换了经验观察到的 token v * 的 one-hot 分布,将上式转换为
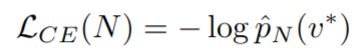
然后具有 N 个参数的模型具有选择正确 token 的 per-token 概率,如上图 B 所示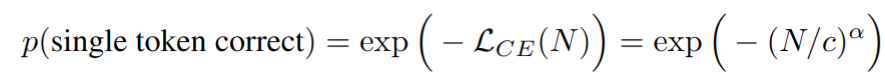 - 假设研究人员选择一个需要正确选择长度为 L 的 token 序列的评价指标(例如,我们的任务可能是 L 位整数加法,当且仅当所有 L 个输出数字与没有添加、删除或替换的所有目标数字完全匹配时,模型的输出才会被评为准确)。如果 token 正确的概率与其他预测 token 无关,则模型正确输出所有 L 个 token 的概率为
- 假设研究人员选择一个需要正确选择长度为 L 的 token 序列的评价指标(例如,我们的任务可能是 L 位整数加法,当且仅当所有 L 个输出数字与没有添加、删除或替换的所有目标数字完全匹配时,模型的输出才会被评为准确)。如果 token 正确的概率与其他预测 token 无关,则模型正确输出所有 L 个 token 的概率为
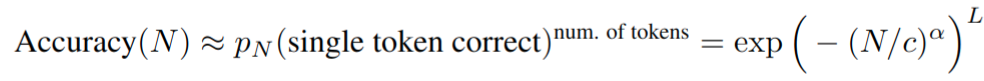
这种度量的选择随着 token 序列长度的增加而非线性缩放性能,在绘制线性对数图上较长序列的性能时,可以看到一个尖锐、不可预测的涌现能力,如上图 C 所示 -
如果换成 Token Edit Distance 这样的近似线性度量,per-token 错误率在目标长度上以准线性缩放,如上图 E
-
如果使用不连续的评估指标,比如 Multiple Choice Grade,也可以看到涌现能力,如上图 D。二如果换成类似 Brier Score 之类的连续评估指标,就不会有涌现现象,如上图 F
-
【总结】涌现现象的解释
- 非线性和不连续的评估指标放大了 per-token 误差率
- 大规模模型下的采样不充分,也即大模型下的实验一般比较少
- 小模型的评估细粒度不够,及如果训练数据量少的情况下细粒度为 1/test dataset size,所以应该尽量增加评估数据量
实验结果
InstructGPT/GPT-3 涌现能力分析
-
下图从左到右分别是
- 数学模型,2个两位整数乘法任务,2个四位整数加法任务
-
下图上面的是非线性的 accuracy 评价指标,有涌现现象,如果使用线性的 Token Edit Distance ,则随着模型参数增加性能是平滑可预测的提升
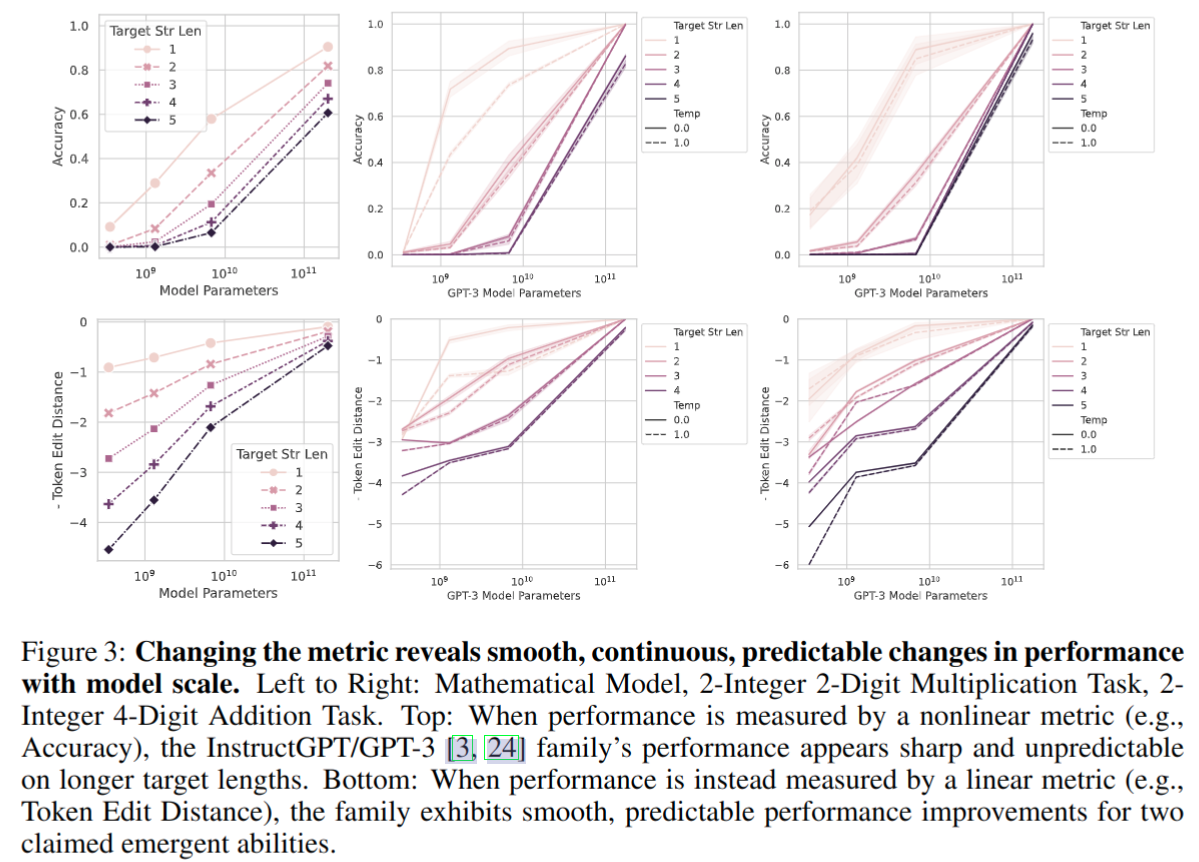
-
使用更多的评测数据使得性能变化是平滑、连续和可预测的。即便是在非线性的 accuracy 指标下,涌现现象也消失了
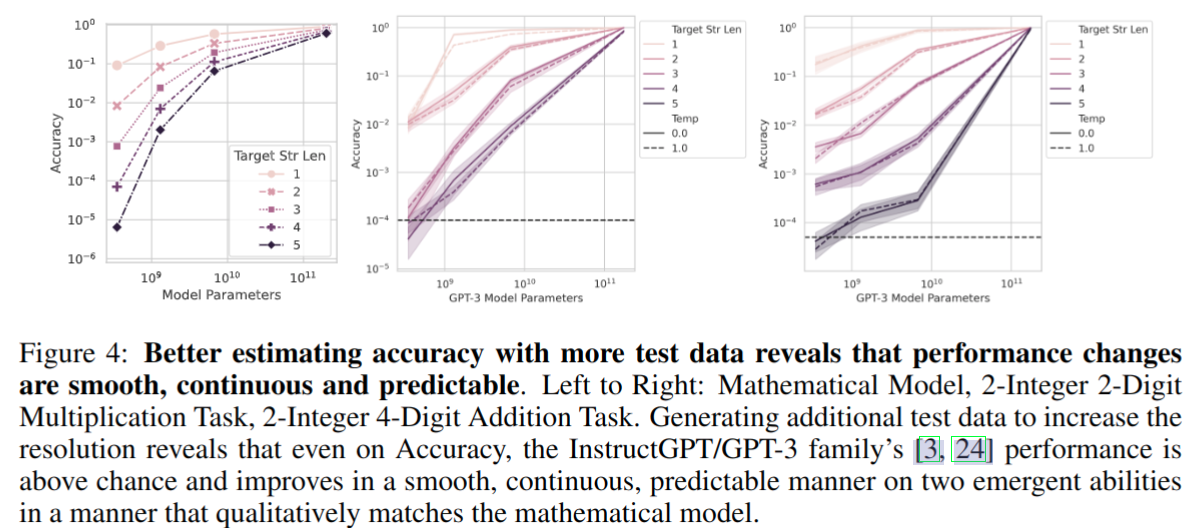
对声称涌现能力的分析
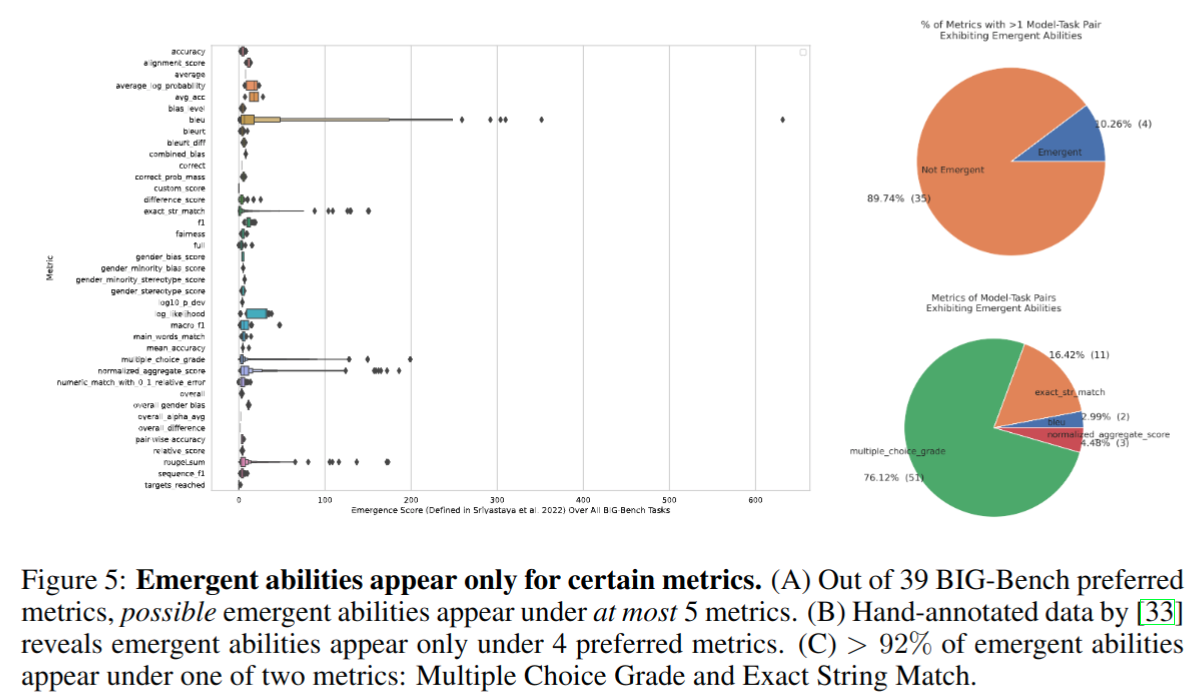
- 基于 BIG-Bench 这个大语言模型测试工具,39 个评价指标中,出现涌现能力的评价指标最多只有 5 个,大于 92% 的涌现能力来源于 Multiple Choice Grade 和 Exact String Match 这两个非线性或不连续指标
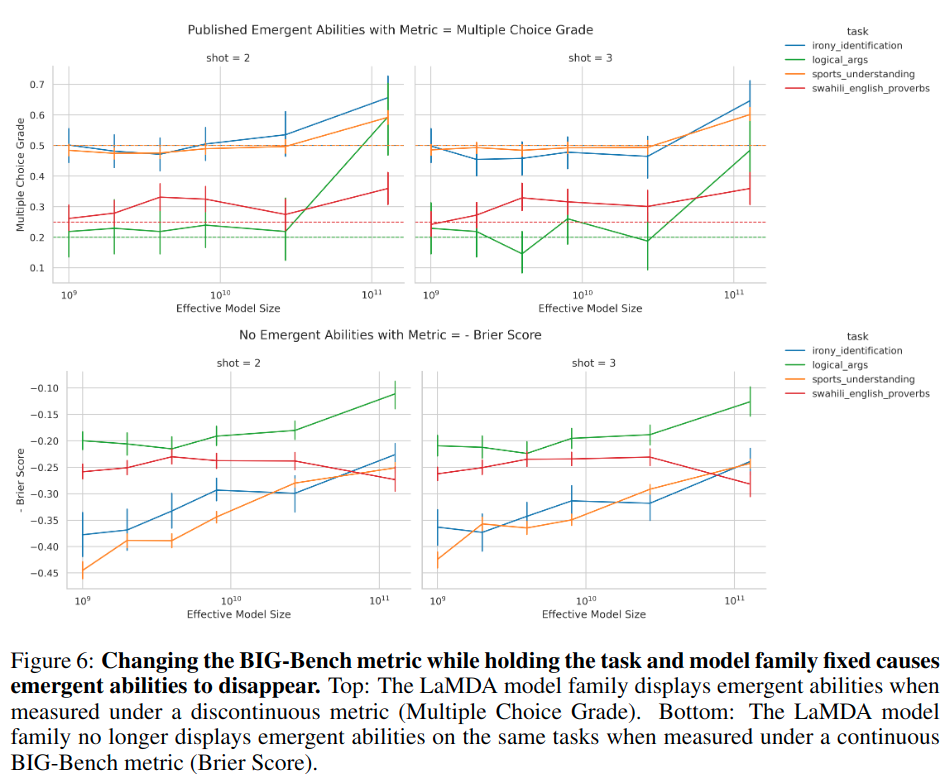
- 改变评价指标可以让涌现能力消失
诱导涌现能力的方式
-
在全连接网络、卷积网络、自注意网络上诱导涌现能力,主要关注视觉任务(之前视觉任务很少关注到涌现现象)
-
改变评价指标可以在 MNIST 上复现涌现能力,实验模型是 LeNet,评价指标重新定义为 subset accuracy:K 个测试数据都需要预测正确才算对
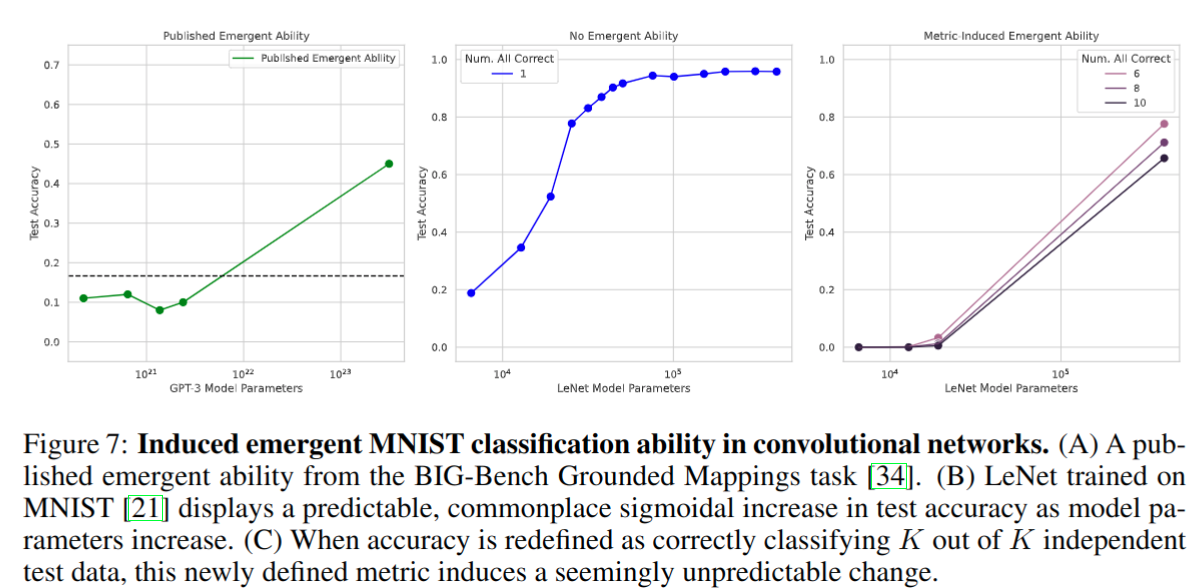
-
在非线性 autoencoders 上的实验,重建指标改为 R e c o n s t r u c t i o n c Reconstruction_{c} Reconstructionc 后有涌现现象
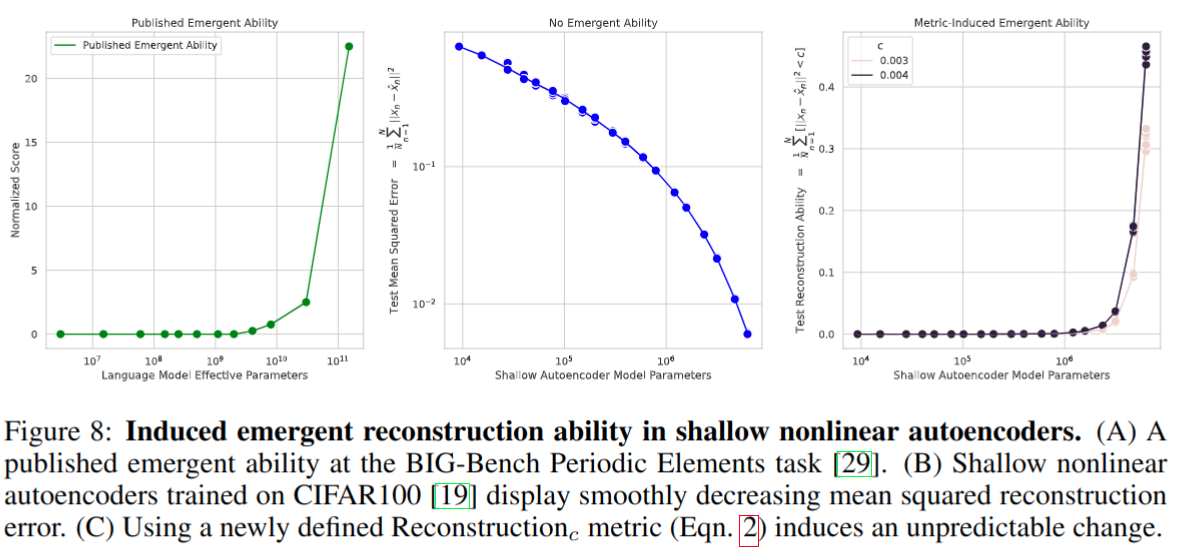
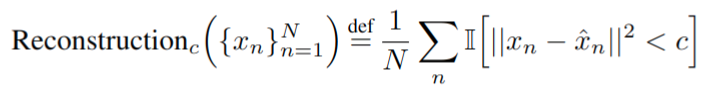
该指标卡了阈值造成了指标不连续,需要误差小于 c 才算正确 -
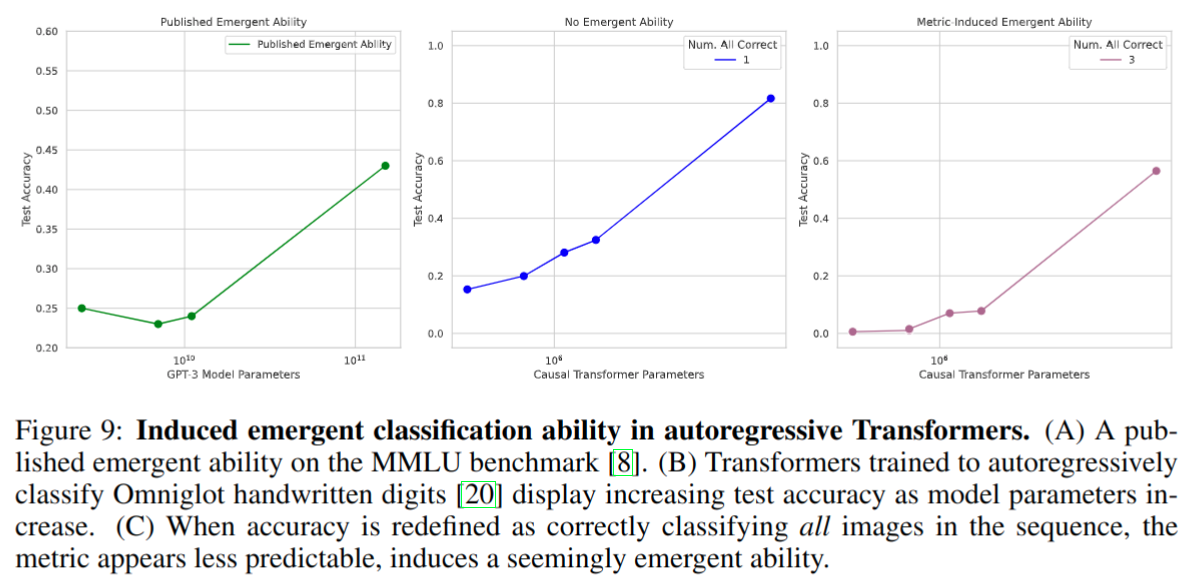
autoregressive transformers 上的诱导涌现能力实验,在 MMLU 数据集上做的,自回归分类 Omniglot 手写数字。指标重新定义为正确分类序列中的所有图像就会展现涌现能力
Thoughts
- 对涌现现象的一个看起来合理的解释,作者全篇的行文风格主要是在阐述该解释,并结合多个实验进行论证,并没有说该解释一定是确保正确,不排除未来有更合理的涌现现象解释
- 设置评价指标的时候需要考虑该指标对于 per-token 错误率的影响
- 比如如果选择 accuracy 作为评价指标,应该确保有足够的数据来准确测量模型性能;使用太少的数据意味着分辨率太低,这增加了得出无效科学结论的可能性
- 确定常用的 NLP 指标与人类偏好相关的程度应该是需要优先考虑的:
- 一些自动化的指标不一定靠谱,比如 BIG-Bench 上的 “Q: What is 4 plus 5?”,回答 “The sum of 4 and 5 is 9” 会被判别为错误,因为评价的方式是取回答中的第一个数字作为答案
- 不靠谱的 NLP 指标会导致模型在这些指标上过拟合,并不满足人类真正的需求
- 作者最后还批评了当前部分不公开模型或者 API 的问题会阻碍学术研究进展,推荐是至少要像 GPT3 这样公开 API 调用
- 基于本文的结果来看,因为人类现在主观也觉得大模型有涌现现象,人类主观评价可能也是非线性和不连续的

