
- 1基于深度学习模型在移动端(安卓)实现的毕业设计(附完整项目代码)_android 深度学习模型
- 2Linux-- 查看SUSE 版本_linux服务器suse11 sp2 或 suse12
- 3Linux下的常用基本指令_在当前根目录下显示其他目录的文件
- 4华为OD 面试手撕代码真题【合法的括号】_华为od手撕代码题目
- 5北大视频大模型新SOTA,搞笑抖音视频AI秒懂笑点|开源
- 6鲍鱼数据案例(岭回归 、LASSO回归)_length diameter height whole shucked viscera shell
- 7在银河麒麟V10 SP2服务器上搭建本地私有yum源_麒麟yum源
- 8Folx Pro苹果BT磁力多线程下载工具
- 9【MySQL】事务四大特性以及实现原理
- 10做自媒体视频剪辑怎么赚钱呢?
大模型的涌现能力 (Emergent Abilities of LLM)
赞
踩

本文约1000字,建议阅读5分钟今天一起来研究下LLM中的emergent abilities现象。大家好,这里是NewBeeNLP。

论文名称:Emergent Abilities of Large Language Models
论文链接:
https://arxiv.org/pdf/2206.07682.pdf
论文来源:Google&Deepmind
1. Emergent Abilities Definition
本文中对LLM的emergent abilities的定义为:
在较小的模型中不出现,而在较大的模型中出现的能力,则可以称之为emergent.(An ability is emergent if it is not present in smaller models but is present in larger models.)
本文的目的不是去谈论是否存在一个scale就可以观察到emerge abilities,而是去讨论之前的工作中出现的emergent现象。
2. Few-Shot Prompted Tasks
本部分主要讨论在prompting范式下的emergent abilities, 该范式如下图所示:
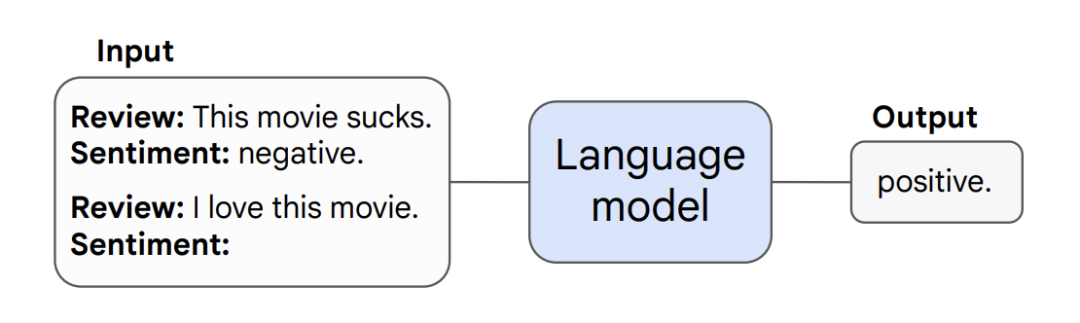
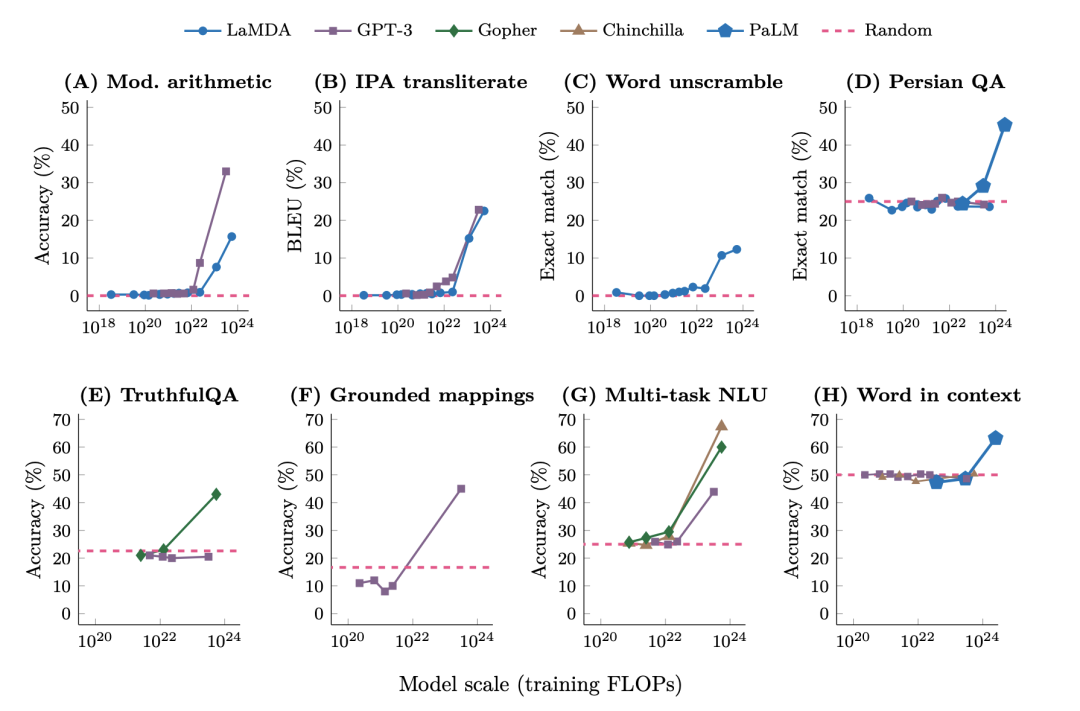
few-shot prompting的emergent主要体现为模型在没有达到一定规模前,得到的表现较为随机,在突破规模的临界点后,表现大幅度提升。如下图所示,在BIG-Bench上,GPT-3和LaMDA在未达到临界点时,模型的表现都是接近于零。而在GPT-3的规模突破2·10^22 training FLOPs (13B参数),LaMDA的规模突破10^23 training FLOPs (68B参数),模型的表现开始快速上升。
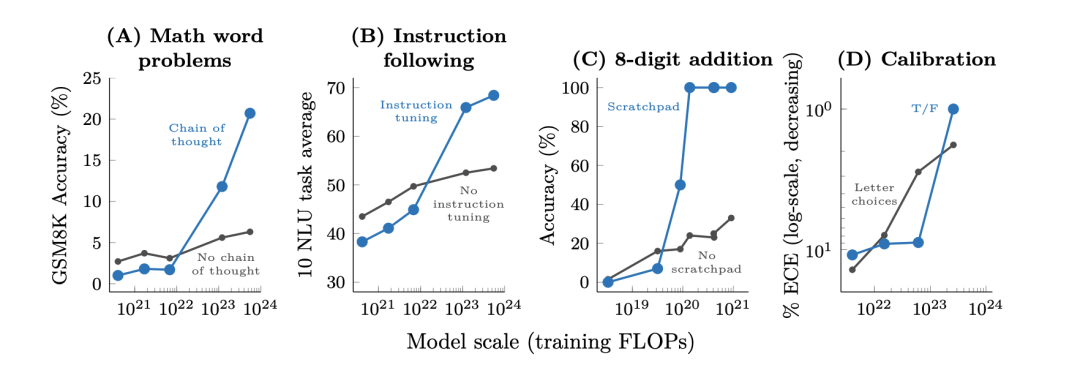
3. Augmented Prompting Strategies
除了few-shot prompting可以反映emergent abilities, 作者认为如果在某个任务上的某个手段,模型达到一定规模以前,使用该手段,相比于基线没有提升或者是有害的,那么可以将该手段看成emergent ability。
作者在Multi-step reasoning(chain-of-thought prompting); Instruction following(使用instructions描述任务,不使用few-shot exemplars); Program execution;Model calibration(calibration需要模型去评估自己是否能正确回答某个问题)
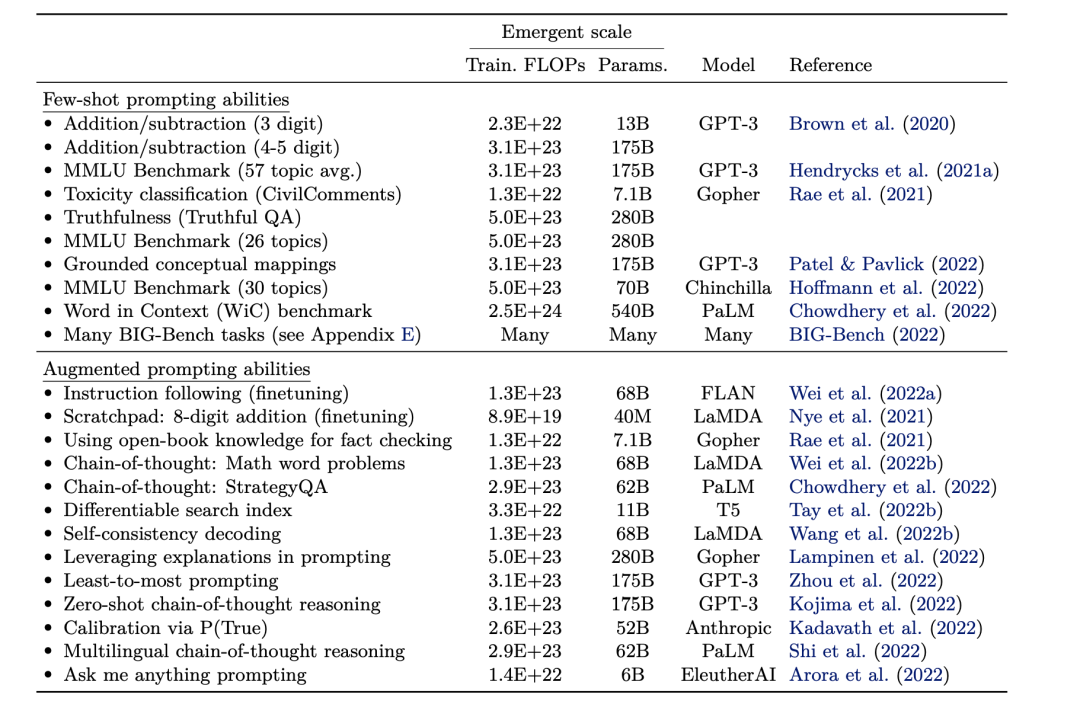
下表给出了大模型出现emergent ablities的规模统计
4. Discussion
4.1 Potential explanations of emergence
对于模型突破某个规模的临界值后,出现emergent abilities的现象。作者给出直观上的猜想,某个multi-step reasoning任务需要l个step的计算,那么可能需要模型主要需要O(l)层的数目。同时也可以很自然猜想更多的参数和更多的训练有助于模型记忆更多的world knowledge. 比如在closed-book question-answering可能需要模型有更多的参数去记忆尝试知识。
衡量emergent abilities的evaluation metrics也值得探究。仅仅使用最终的指标如acc等并不一定很好反映emergence.
4.2 Beyond scaling
虽然本文主要探究模型超过一定规模后出现emergent ability, 但模型仍然有可能通过数据,算法的改进在更小规模出现emergence. 比如在BIG-Bench任务上,LaMDA在137B,GPT-3在175B上出现emergent ability,而PaLM在62B就可以出现。
4.3 Another view of emergence
虽然模型的规模与大模型的表现高度相关,但是但模型的规模不是观察到emergent abilities的唯一尺度。如下图所示,模型的emergent abilities可以看成一系列相关变量的函数。
4.4 Directions for future work
作者为未来研究大模型中的emergent abilitie提供了一些方向。
Further model scaling: 继续增加模型的规模探究模型的表现的提升。
Improved model architectures and training :从模型的结构和训练过程上提高模型的质量,从而使模型在较低的训练成本下就可以获得emergent abilities。
Data scaling: 增大数据集的规模。
Better techniques for and understanding of prompting:更好地发挥prompt在模型中的作用。
Frontier tasks: 仍然有些任务无法出现emerent abilities,这也是值得探究的。
Understanding emergence: 关于emergent abilities为什么会在语言模型中发生仍然是未知的。
编辑:王菁


