
- 1使用Verilog实现CRC-8的串行计算_crc8 verilog
- 2大数据、人工智能、云计算、物联网、区块链序言【大数据导论】_大数据、云计算、物联网相关概念普及
- 3spring.HttpMessageNotReadableException: JSON parse error_spring json parse error
- 4springboot整合redisson实战(一)整合 redisson-spring-boot-starter
- 5设置了uni.chooseLocation,小程序中打不开_uni.chooselocation点击之后没反应
- 6头歌实验代码_表格样式头歌代码
- 7mysql的clob转字符串_Oracle中clob与varchar字段互转
- 8日常学习记录——使用Visio2019绘制思维导图_visio画大括号思维导图
- 9【数据结构】:冒泡排序(c++实现)_c++冒泡排序统计轮数
- 10chatgpt赋能python:Python选择界面的SEO介绍
一分钟原画变3D角色,清华VAST成果入选图形学顶会SIGGRAPH
赞
踩
CharacterGen团队 投稿
量子位 | 公众号 QbitAI
随便一张立绘都能生成游戏角色,任意IP快速三维化有新招了!
来自清华大学和VAST的研究人员联合推出了CharacterGen——
一种三维风格化人物生成框架。

具体而言,CharacterGen采用两阶段生成模式,可在1分钟内从单图生成高质量的标准姿态三维人体。
目前相关论文已入选计算机图形学顶会SIGGRAPH 2024,且在社区引发了热烈讨论。
CharacterGen开源后,已有玩家第一时间将其纳入了ComfyUI-3D工作流。
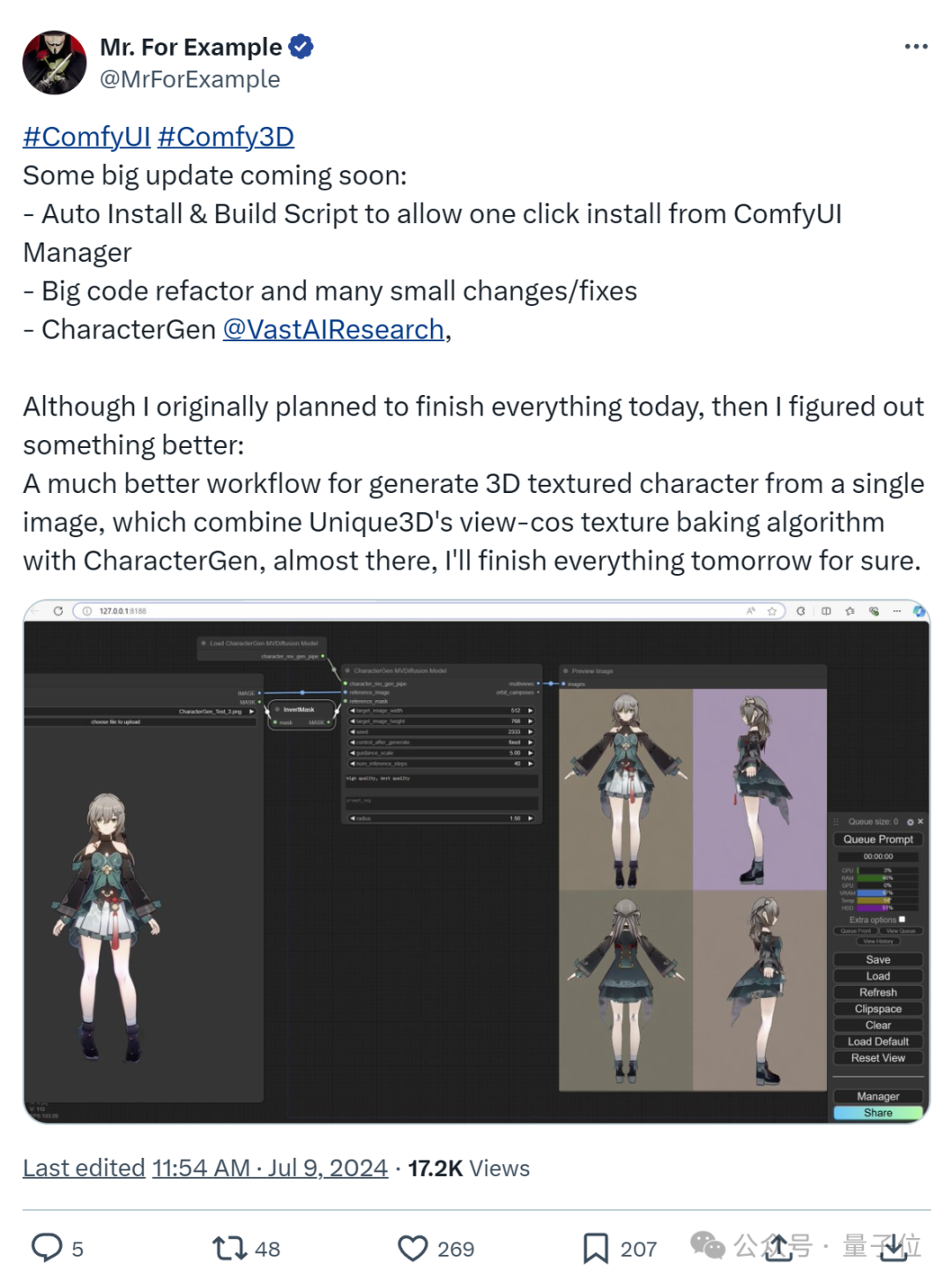
网友们搓手表示:
迫不及待看到构建3D角色工作流更简单!
更多详情接下来一起康康~
1分钟单图变3D角色
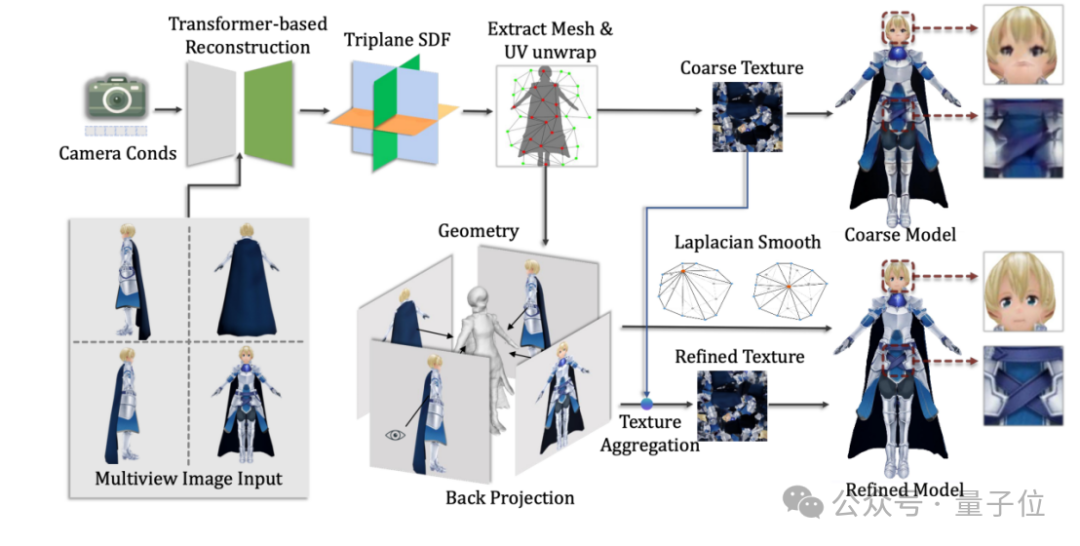
新框架CharacterGen想做的事儿,是将用户输入的复杂人物图像转换为标准Pose的三维人物网格。
总体而言,框架可分为如下两部分:
多视角人物图像生成器。以给定的带姿势人物图作为输入,通过Diffusion模型生成高度一致性的四视角图像。
三维重建模型。将生成的四视角图像重建,得到最终的三维人体以及对应的粗纹理。
最终,通过纹理投影策略,将多视角图像投影到重建的粗纹理之中,得到最后的高质量三维人物模型。
整个流程可以在A800单卡上1分钟内完成。
并且由于A-pose(人物两脚并拢,双手自然下垂,身体直立)的设置,可以方便地运用于下游的各种任务。
“A-pose”是动画和3D建模中的一个基准点,它提供了一个简单、统一的起点来进行后续的建模和动画工作。

为了进一步提高扩散模型理解3D角色的能力,团队准备了包含13,746个风格化角色主题的Anime3D数据集。
而且为了让多视角人物图像生成器能学到足够的先验,完成对风格化人物的多视角生成和人物的姿势转换,团队渲染并筛选了组数据。
每一组数据都包含了多组同一个人物在一个非标准姿势和标准姿势下的四视角渲染图像。
多视角人物图像生成器
团队采用了Dual-pass的多视角人物图像生成器。
它不仅能生成四视图的人物图像,还能在生成过程中完成姿势的标准化。
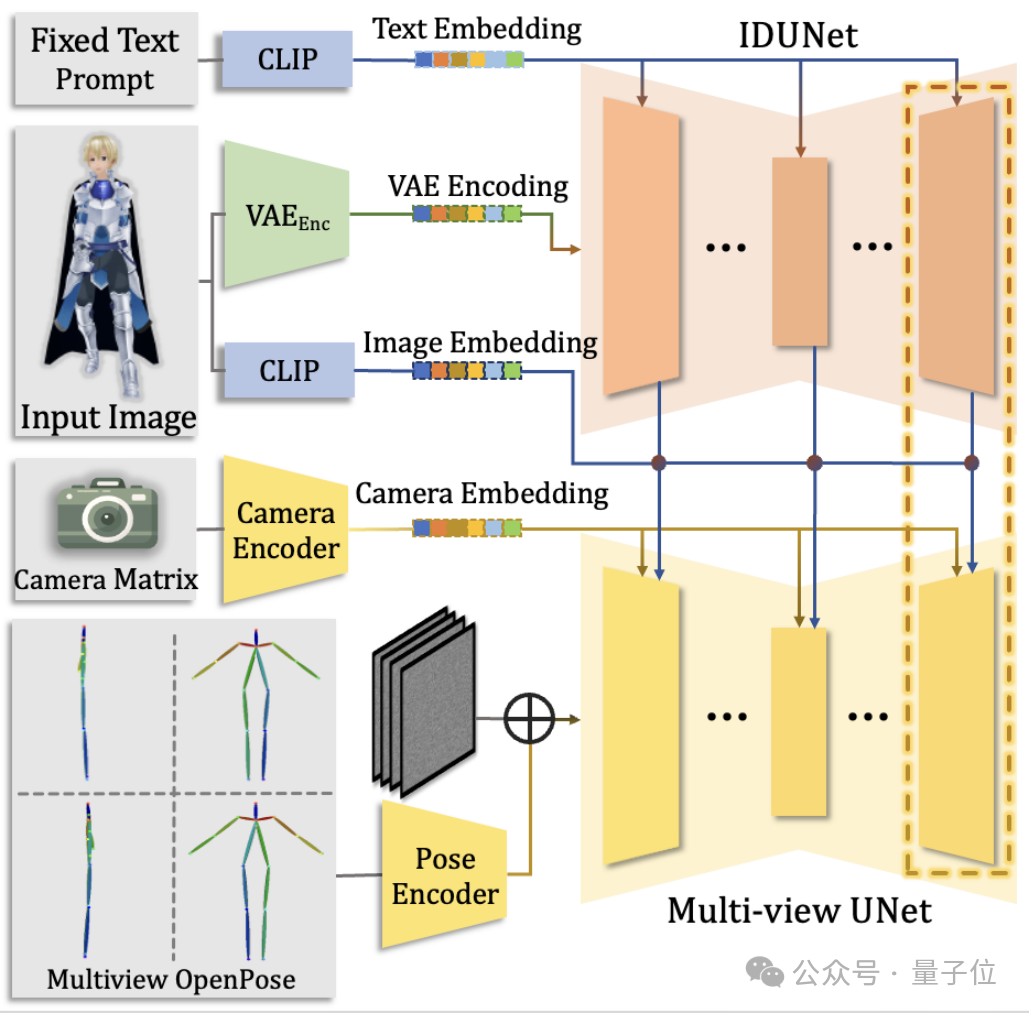
此外,团队在基本的多视角diffusion模型之外,添加了一个同样结构的IDUNet来提取输入人物图片的特征。
IDUNet逐层提取未加噪的图像的外表特征,通过Cross-Attention机制和Base-Diffusion模型中的多视角图像进行Patch-level的交互,使得最终生成的多视角人物具有极高的一致性。
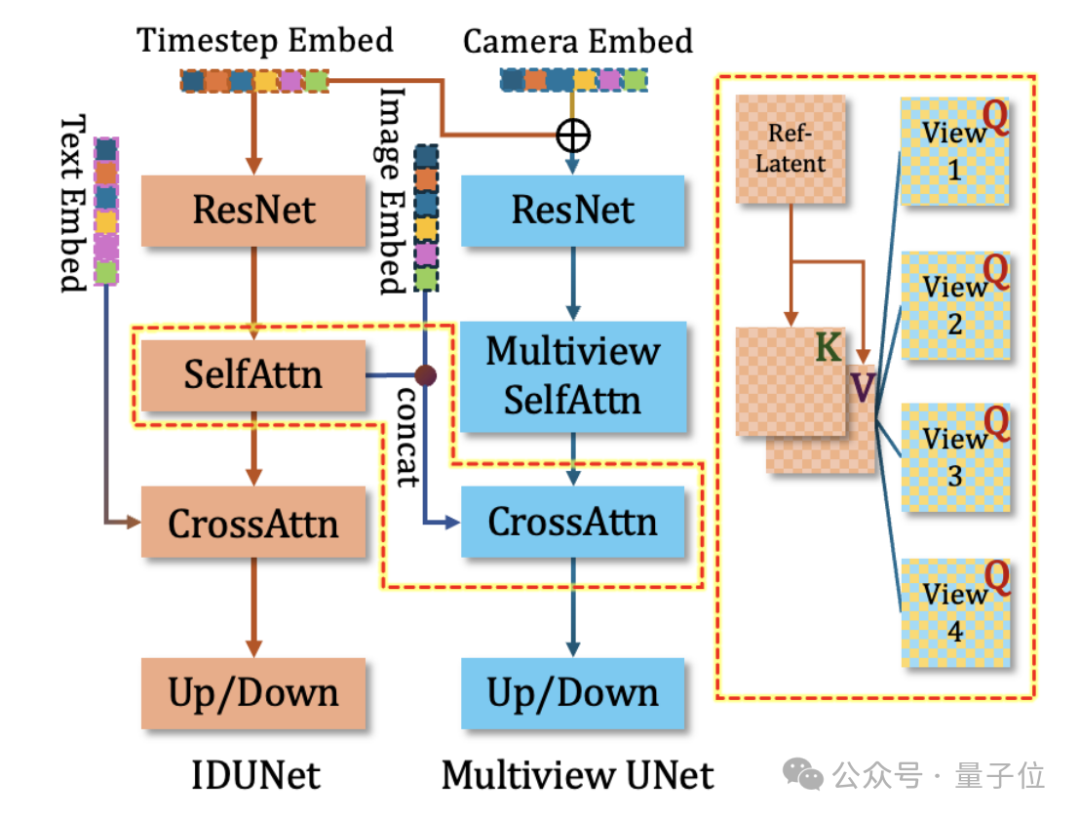
最后,生成器也包含一个布局姿势指导器Pose Guider,进一步为人物的姿势提供先验,并且使得生成人物的布局能够位于图片正中。
三维重建模型
参考三维重建大模型(LRM),团队设计了针对四视角输入图像的三维重建模型。
团队首先仿照LRM,训练了基于NeRF的重建模型。
为了获得更好的表面几何,在训练第二阶段使用SDF表达作为输出,进一步精调重建模型。
最后,由于重建模型难以获得高清晰度的纹理,研究团队还引入了纹理投影机制。
具体而言,通过四视角本身预设的相机参数,将高质量的四视角生成图片投影到粗纹理图上,同时使用法向数值来筛出重叠和边缘的像素,得到最终的纹理贴图。
实验结果
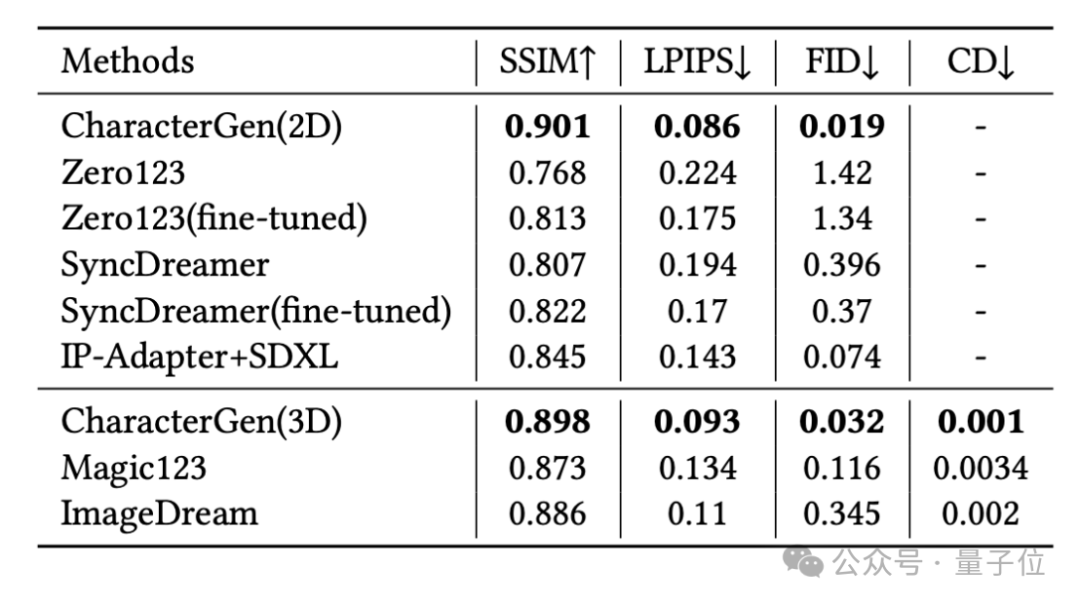
研究团队分别从二维多视角图片质量以及三维人物模型质量上对方法进行了评估。
在二维方法上,研究团队选取了Zero123和SyncDreamer作为Baseline进行比较。
结果显示,在生成人物图像的纹理质量和外表一致性上,CharacterGen取得了超越之前方法的效果。

在三维方法上,团队选取了Magic123和ImageDream作为泛用图像驱动生成的Baseline,选择TeCH作为图像驱动SMPL生成的Baseline。
实验表明,CharacterGen生成的标准A-pose姿势人体能够避免网格的黏贴问题,并且在纹理和几何上拥有更高的质量。

此外,团队也在Anime3D的验证集上,对CharacterGen和Baseline方法进行了定量的比较。
评估指标包括:
SSIM和LPIPS指标:衡量生成的对应视角图片与ground-truth图片的相似程度
FID指标:评价风格上的一致性
Chamfer-Distance指标:比较生成网格的几何质量
在这些指标上,CharacterGen都能获得更优的效果。
目前相关论文已公开,感兴趣可以进一步了解。
此外,研究团队还开源了基于Jittor框架JDiffusion库的CharacterGen实现(计图Jittor是清华大学计算机系图形学实验室于2020年3月20日发布并开源的深度学习框架)。
计图Jittor仓库链接:https://github.com/JittorRepos/JDiffusion/tree/master/examples/CharacterGen
项目主页:https://charactergen.github.io/
论文:https://arxiv.org/abs/2402.17214
Huggingface Gradio Demo: https://huggingface.co/spaces/VAST-AI/CharacterGen
GitHub:https://github.com/zjp-shadow/CharacterGen

