
- 1TypeError: argument of type ‘type‘ is not iterable 解决办法python_argument of type 'type' is not iterable
- 2基于51单片机的万年历设计_51单片机万年历设计
- 3赛博活佛再出手,PaintsUndo一键生成绘画全过程视频!
- 4国产化区块链平台-FISCO BCOS 区块链
- 5微信小程序源码-160套微信小程序毕业设计的项目实战(源码+论文+演示视频)
- 6《Docker极简教程》--Docker容器--Docker容器的创建和使用_docker创建容器
- 7鸿蒙4.2小版本推出,鸿蒙5.0已经不远了_鸿蒙4.2不如4.0
- 8Springboot —— 根据docx填充生成word文件,并导出pdf_xwpftemplate
- 9MySQL运维实战(2.4) SSL认证在MySQL中的应用_ssl mysql通信
- 10sqlalchemy定期保持mysql连接活跃
(2022,Diffusion & 语义混合)MagicMix:使用扩散模型进行语义混合_magicmix模型
赞
踩
MagicMix: Semantic Mixing with Diffusion Models
公众号:EDPJ(添加 VX:CV_EDPJ 进群)
目录
0. 摘要
你有没有想象过像柯基犬一样的咖啡机或像老虎一样的兔子会是什么样子? 在这项工作中,我们试图通过探索一项称为语义混合的新任务来回答这些问题,旨在混合两种不同的语义以创建一个新概念(例如,柯基犬+咖啡机 → 类似柯基犬的咖啡机)。 与根据参考风格对图像进行风格化而不改变图像内容的风格迁移不同,语义混合以语义方式混合两个不同的概念,以合成新的概念,同时保留空间布局和几何形状。 为此,我们提出了 MagicMix,这是一种基于预训练的文本条件扩散模型的简单而有效的解决方案。 受扩散模型的渐进生成特性的启发,其中布局 / 形状出现在早期去噪步骤中,而语义上有意义的细节出现在去噪过程中的后续步骤中,我们的方法首先获得粗略布局(给定文本提示,通过破坏图像或从纯高斯去噪获得),然后注入条件提示以进行语义混合。 我们的方法不需要任何空间掩模或重新训练,但能够合成高保真度的新物体。 为了提高混合质量,我们进一步设计了两种简单的策略,以对合成内容提供更好的控制和灵活性。 通过我们的方法,我们在不同的下游应用中展示了我们的结果,包括语义样式迁移、新颖的对象合成、品种混合和概念删除,证明了我们方法的灵活性。 更多结果可以在项目页面 https://magicmix.github.io/ 上找到。

1. 简介
您有没有想象过类似柯基犬的咖啡机会是什么样子? 兔子长得像老虎怎么办? 由于现实世界中不存在此类物体,渲染此类想象场景极具挑战性。 在这项工作中,我们有兴趣研究一个称为语义混合的新问题,其目标是以语义方式混合两种不同的语义(例如“柯基犬”和“咖啡机”)以创建一个新概念(例如,像柯基犬的咖啡机),同时具有照片般的真实感。
最近开发的大规模文本条件图像生成模型,如 DALL-E2 (Ramesh et al., 2022)、Imagen (Saharia et al., 2022)、Parti (Yu et al., 2022) 等,已经展示了仅给出文本描述即可生成令人惊叹的高质量图像的能力。 由于从大量图像标题对中学到了强语义先验,此类模型甚至可以生成新颖的构图(例如,骑马的宇航员)。 尽管组合新颖,但每个对象实例(例如“宇航员”、“马”)都是已知的。 此外,与组合生成(例如,一只柯基犬坐在咖啡机旁边)不同,我们感兴趣的是通过在语义上混合两个不同的概念来合成一个新颖的概念(例如,类似柯基犬的咖啡机,反之亦然)。 然而,这样的问题具有挑战性,因为即使是人类用户也可能不知道它应该是什么样子。
为了解决这个问题,我们提出了一种称为 MagicMix 的新方法,它建立在现有的基于文本条件图像扩散的生成模型之上。 我们的方法非常简单,既不需要重新训练,也不需要用户提供掩模。 我们的方法受到基于扩散的模型的渐进特性的启发,其中布局/形状/颜色首先出现在早期去噪步骤中,而语义上有意义的内容在去噪过程中出现得更晚。 鉴于此,我们将语义混合任务分解为两个阶段:(1)布局(例如形状和颜色)语义和(2)内容语义(例如语义类别)生成。 具体来说,考虑混合“柯基犬”和“咖啡机”的例子,我们的 MagicMix 首先通过破坏给定的柯基犬真实照片或在给定文本提示“柯基犬的照片”的情况下从纯高斯噪声中去噪来获得粗略的布局语义。 然后,它注入一个新概念(在本例中为“咖啡机”)并继续去噪过程,直到我们获得最终的合成结果。 一般来说,这种简单的方法效果出奇地好。 为了改进混合,我们进一步设计了两种简单的策略,以对生成的内容提供更好的控制和灵活性。

语义混合在概念上不同于其他图像编辑和生成任务,例如风格转移或组合生成。 风格迁移根据给定的风格(例如梵高的《星空》)对内容图像进行风格化,同时保留图像内容。 另一方面,组合生成将多个单独的组件组合起来以生成复杂的场景(例如,组合“骆驼”和“丛林”会产生骆驼站在丛林中的图像)。 虽然组合本身可能是新颖的,但每个单独的成分都是已知的(即骆驼是什么样子)。 不同的是,语义混合旨在将多种语义融合到一个新颖的对象/概念中(例如,“柯基犬”+“咖啡机” → 一台类似柯基犬的咖啡机)。 这些任务之间的差异如图 2 所示。
得益于生成新颖概念的强大能力,我们的 MagicMix 支持各种各样的创意应用,包括语义风格迁移(例如,给定参考符号布局和某些所需内容生成新符号)、新颖的对象合成(例如,生成看起来像西瓜片的灯)、品种混合(例如,通过混合“兔子”和“老虎”生成新物种)和概念去除(例如,合成看起来像橙子的非橙子物体)。 尽管该解决方案很简单,但却为计算图形领域开辟了新的方向,并为娱乐、电影摄影和CG效果等广泛领域的艺术家提供了人工智能辅助设计的新可能性。
总之,我们在这项工作中的贡献是:
- 一个新问题:语义混合。 目标是通过混合两种不同的语义来合成一个新颖的概念,同时保持照片般的真实感。
- 新技术:MagicMix。 它建立在大规模预训练的基于文本到图像扩散的生成模型之上,并将语义混合任务分解为布局和内容生成阶段。
- 我们展示了 MagicMix 的几种创意应用,包括语义风格转换、新颖的对象合成、品种混合和概念删除。
2. 相关工作
2.1 扩散概率模型
扩散概率模型(DPM)家族在无条件和条件生成建模任务中都取得了巨大的成功(Ho et al., 2020; Song et al., 2022; Ho et al., 2022; Song et al., 2021), 包括图像/视频生成(Ho et al., 2022;Nichol & Dhariwal, 2021)、分子生成(Xu et al., 2022)和时间序列建模(Rasul et al., 2021)。 它们不仅能够生成感知上高质量的样本,而且还可以产生出色的对数似然分数。 然而,由于迭代采样过程,基于扩散的模型的计算成本非常高(Song et al., 2022; Lu et al., 2022; Liu et al., 2022a)。 为了改善这个问题,人们提出了先进的采样器和新颖的建模框架。 例如,宋等人 (2021) 提出了概率流 ODE 采样策略,该策略激发了 DDIM (Song et al., 2022) 和 DPM 求解器 (Lu et al., 2022) 的发展。Rombach 等人(2022)和 Vahdat 等人(2021)同时提出将数据映射到低维潜在空间并使用扩散模型来拟合潜在编码的分布。 在图像生成的应用中,Ho 等人 (2020) 证明 DDPM 以渐进的方式合成图像,即中间噪声中的布局信息(例如形状和颜色)首先出现,而细节随后增强。 这种现象有利于潜在噪声空间中的图像编辑,例如图像插值和修复。 我们的工作还利用渐进生成特性来实现潜在噪声空间中的语义混合。
2.2 可控图像生成
生成模型可用于合成以某些控制信号为条件的图像(Kingma & Welling,2014;Goodfellow 等,2020;Oord 等,2016;Kobyzev 等,2021),例如类标签、文本描述(Saharia 等人,2022;Yu 等人,2022;Ramesh 等人,2022),以及退化图像(Kawar 等人,2022a)。 许多方法都是基于自回归模型、变分自动编码器(VAE)、生成对抗网络(GAN)和基于扩散/评分的模型而开发的。 例如,对于文本到图像的生成,Yu 等人 (2022) 提出以自回归方式对以文本标记为条件的图像标记的概率密度进行建模;Saharia 等人 (2022) 使用扩散模型直接近似 RGB 空间中图像的条件概率密度。 为了降低基于扩散的生成的计算成本,Rombach 等人 (2022) 提出了一种潜在扩散模型,将图像压缩为低维编码并对潜在编码的条件分布进行建模。
2.3 图像编辑
语义混合与多种图像编辑任务相关。 第一个是掩蔽图像修复,旨在用合理的内容填充掩蔽区域(Lugmayr et al., 2021;Saharia et al., 2021;Peng et al., 2021;Zhao et al., 2020)。 如果没有关于空白区域的语义指导,生成模型倾向于合成内容,使得整个图像位于高密度区域。 用户无法交互式地控制合成的内容以使其感兴趣(Lugmayr 等人,2021)。 即使给出了一定的语义指导,生成的内容可能看起来与原始图像的其他部分不协调。
第二个相关任务是风格迁移,试图将一个源图像的艺术风格迁移到另一个目标图像(Gatys et al., 2015; Karras et al., 2019; Luan et al., 2017; Ulyanov et al., 2016) ; Zhu et al., 2020),通过全局方式修改目标图像的颜色、形状和纹理。 然而,风格迁移不能改变目标图像的语义内容。 另一方面,语义混合旨在将另一个对象的内容语义注入到布局语义中; 它会自动检测布局对象的哪一部分要修改(例如,当图 1 中的骆驼符号与“哈士奇”混合时,只有骆驼被哈士奇替换,而整体布局保持不变)。 生成的图像整体和局部看起来都很自然。
第三个相关任务是基于扩散生成模型的文本驱动图像编辑。 近期工作(Hertz 等人,2022;Gal 等人,2022;Couairon 等人,2022;Kawar 等人,2022b;Wu 和 De la Torre,2022;Chandramouli 和 Gandikota,2022;Kwon 和 Ye,2022 )探索使用扩散生成模型进行文本驱动的图像编辑,例如对象替换、样式或颜色更改、对象添加等。但是,与我们的语义混合不同,这种编辑不会导致新的未知对象/概念的合成,这是本文工作的主要焦点。 另一方面,组合生成将多个单独的组件组合起来生成复杂的场景。 例如,刘等人 (2022b) 将基于多个提示的扩散模型分解为分别基于每个提示的扩散模型的乘积。 因此,它可以将多个提示中描述的场景组合成一张图像。 与这些任务不同,语义混合旨在将多种语义融合到一个对象中,而不是在一张图像中组合多个对象。

另一个相关任务是提示插值,其中两个不同的文本提示在用于内容生成之前被插值在文本潜在空间中。 然而,这种方法仅适用于具有相似语义的提示(例如,两种狗品种或两张脸)。 在两个概念极其不同的情况下(例如“柯基犬”和“咖啡机”),生成的内容通常以其中一个概念为主(图 3)。 相反,我们的语义混合可以成功地混合两种高度不同的语义。
3. 方法
在本节中,我们首先介绍去噪扩散概率模型(DDPM)的背景。 然后,我们提出了语义混合的新问题,旨在结合两种不同的语义来创建新的概念,并提出一种有效的基于扩散的框架来实现这一目标。 此外,我们讨论了所提出框架的两个应用实例并阐明了实现细节。
3.1 扩散模型的预备知识
深度生成建模旨在通过深度神经网络近似一组数据的概率密度。 深度神经网络经过优化以模仿训练数据采样的分布(Ho et al., 2020;Kingma & Welling, 2014;Goodfellow et al., 2020;Song et al., 2021)。 去噪扩散概率模型(DDPM)是一系列潜在生成模型,通过马尔可夫高斯扩散过程的逆过程来近似训练数据的概率密度(Sohl-Dickstein et al., 2015;Ho et al., 2020)。
给定一组从某些数据分布 q(·) 中采样训练数据
![]()
DDPM 将概率密度 q(x) 建模为 x 和一系列潜在变量 x_1:T 之间的联合分布的边际,
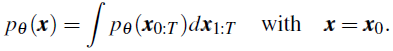
联合分布被定义为,具有从标准正态分布 N ( · ; 0, I) 开始学到的高斯转移的马尔可夫链,即
![]()
因此
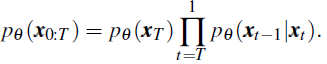
为执行参数化边际 p_θ (·) 的似然最大化,DDPM 使用固定马尔可夫高斯扩散过程 q(x_1:T | x_0) 来近似后验 p_θ (x_1:T | x_0)。 具体来说,定义了两个系列
![]()
![]()
对于任何 t > s ≥ 0,
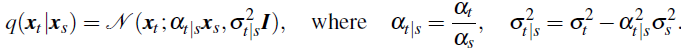
因此,
![]()
DDPM 的参数化逆过程 p_θ 通过最大化相关证据下界 (ELBO) 进行优化:
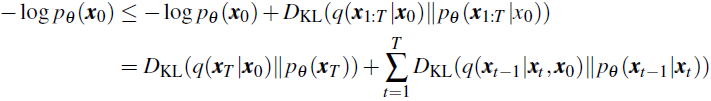
给定训练有素的 DDPM p_θ (·),我们可以通过各种类型的采样器生成新数据,包括 Langevin ancestral 采样和概率流 ODE 求解器(Song 等人,2021)。 在逆过程(采样过程)中,具有随机高斯噪声的信号将逐渐转换为位于训练数据流形上的数据点。 在图像生成的情况下,具有纯噪声的图像将逐渐演化为语义上有意义且感知上高质量的图像。 在每个阶段,我们都可以从相应的噪声中估计出真正的干净图像,并且重建从粗到细发展(Ho et al., 2020)。 更具体地说,已经表明 DDPM 的采样过程首先制作最终输出图像的布局或轮廓,然后合成细节,例如人脸或花的纹理。 考虑某个中间步骤,其中噪声已经包含布局信息,Ho 等人(2020)证明,如果我们修复噪声并从这一步开始运行多个采样操作,所得图像将共享通用布局。 受这种现象(渐进生成)的启发,我们将探索如何使用基于扩散的模型进行语义混合,即给定一定的语义布局,我们是否可以将其与我们感兴趣的任意内容混合?
3.2 扩散模型的语义混合
新概念和对象的创建在多媒体制作中发挥着重要作用,例如创建拟人化动画角色。 概念创建的一种范例是混合多种事物的语义。 例如,许多经典动画角色都是将动物面孔与人体混合设计的,例如“孙悟空”和“穿靴子的猫”。 在本节中,我们介绍图像生成的一项新任务,即语义混合,其目的是修改给定对象的特定部分的内容,同时保留其布局语义。 新内容是根据另一个对象的内容语义合成的。 例如,给定从一个对象(例如,西瓜片)提取的形状和颜色布局语义,可以生成具有该形状和颜色的特定内容语义的对象(例如,一盏灯)。
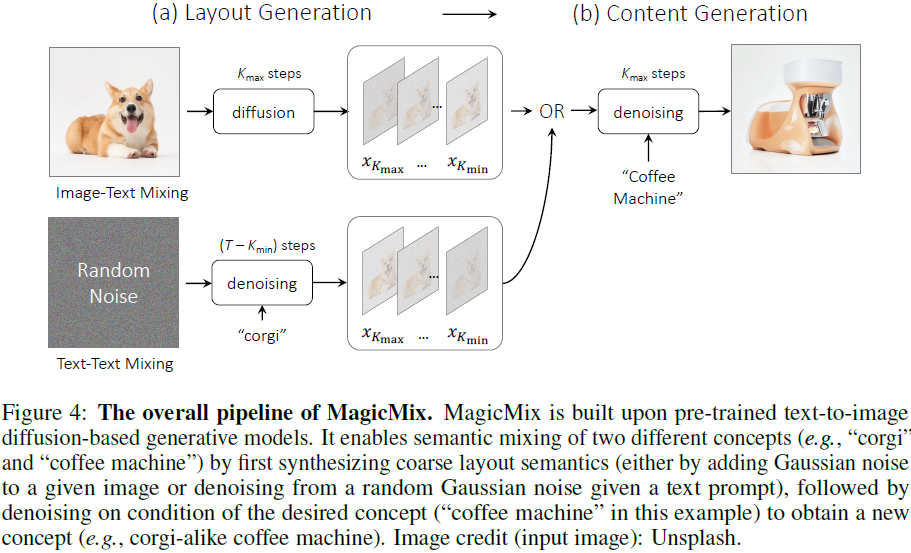
受基于扩散的模型的渐进生成特性的启发,我们提出了一种方法 MagicMix 来混合两个对象的语义。 MagicMix 利用预先训练的基于文本到图像扩散的生成模型 p_θ (x|y) 来提取和混合两种语义。 整体框架如图 4 所示。布局语义可以从给定图像或文本提示中提取,而内容语义则由条件文本提示确定。 我们可以通过使用条件内容提示对噪声布局图像进行去噪来生成混合语义的图像。 根据布局生成的输入类型,我们的 MagicMix 可以以两种不同的模式运行:(a) 图像-文本混合和 (b) 文本-文本混合。
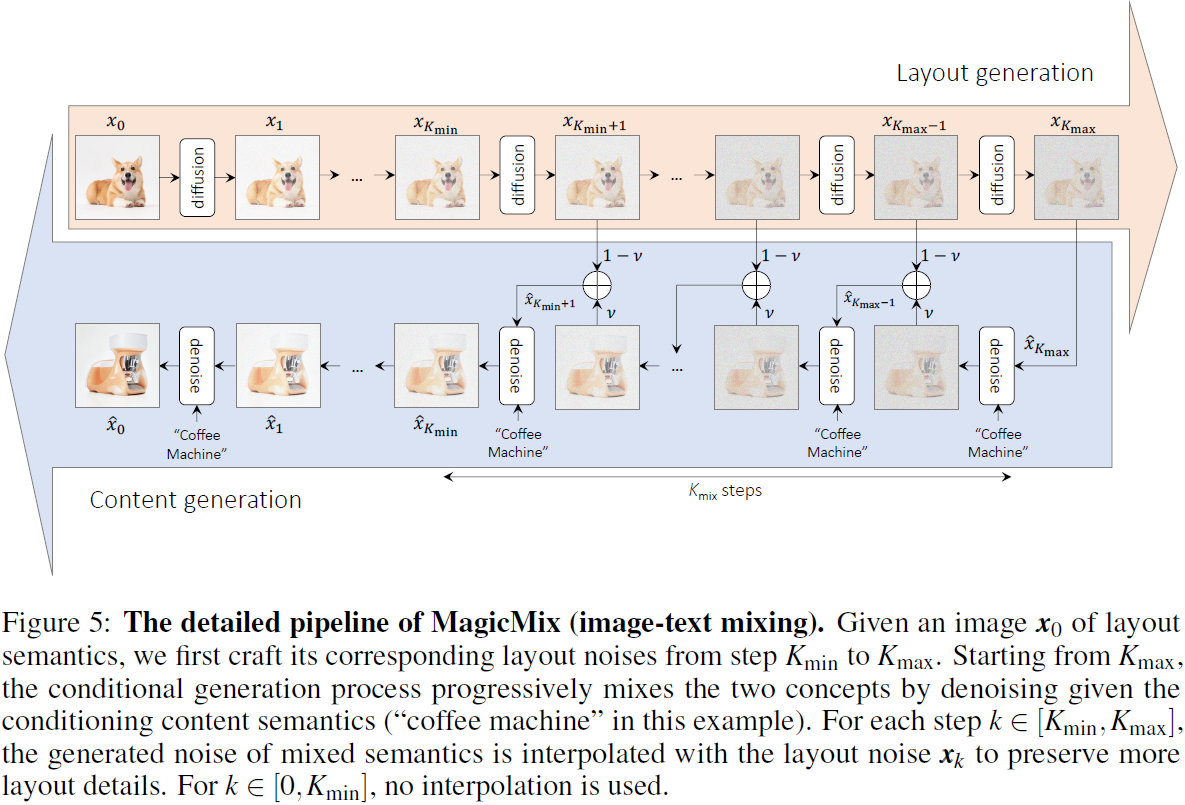
(a)图像-文本混合。 在布局语义由给定图像 x 指定的情况下,我们首先生成与从 Kmin 到 Kmax 的中间步骤相对应的噪声版本。 每个噪声图像
![]()
由给定图像 x 的布局和轮廓信息组成,具有从粗到细的布局。 然后,我们通过调节内容语义 y 的文本来执行去噪过程。 相反的过程从布局语义 ^x_Kmax = x_Kmax 的噪声开始。 对于从 Kmax 到 Kmin 的每个步骤 k,去噪过程利用来自生成模型
![]()
的信息以及来自布局噪声 x_(k-1) 的信息。 具体来说,我们首先从
![]()
中采样 ^x'_(k-1)。 然后,我们使用常数 v ∈ [0,1] 执行
![]()
的线性组合,以生成混合噪声
![]()
从步骤 Kmin 到 0,去噪过程仅依赖于条件生成模型,并且不应用线性插值。 图 5 展示了图文混合的详细过程。
(b) 文本-文本混合。 在布局语义由文本提示 y_layout 确定的另一种情况下,我们首先从分布
![]()
中采样布局噪声序列
![]()
然后,与图像文本混合的情况类似,我们迭代地对布局噪声进行去噪,以通过以 y_content 为条件的生成过程来合成混合语义的图像。 插值仍然仅适用于从 Kmax 到 Kmin 的步骤。
3.3 控制混合比
虽然能够合成具有混合语义的图像,但如何控制混合元素的数量仍不清楚,例如增加“咖啡机”的元素或保留更多“柯基犬”的元素。 接下来,我们将介绍一些技巧,以便对生成的内容提供更好的控制和灵活性。
3.3.1 注入内容提示的时间步长
如前所述,MagicMix 通过首先制作从步骤 Kmax 到 Kmin 的布局语义的噪声图像,然后注入条件提示,可以混合两个不同的概念。 我们选择 Kmin 使得噪声布局图像包含给定布局图像的丰富细节,并选择 Kmax 使得不相关的细节被破坏,只保留粗略的布局。 通过整合不同时间步长的噪声,生成过程可以将内容语义注入给定布局图像中的适当区域,并保留更多布局语义,例如形状和颜色。

内容注入的不同时间步长。 在图 6 中,令 K = Kmax = Kmin 且 v = 1,我们首先研究改变内容注入时间步长 K 的效果。 我们首先注意到,当 K 很小时,由于可用的去噪步骤数量有限,生成过程
![]()
只能修改一小部分图像内容。 因此,我们可以融合两个具有相似语义的概念(例如,柯基犬和哈士奇),但无法混合两个非常不同的对象(例如,柯基犬和咖啡机)。 例如,当 K = 0.4T 时,哈士奇的眼睛和纹理开始出现在柯基犬的脸上,但将“柯基犬”与“哈士奇”和“咖啡机”分别混合时,没有发现“咖啡机”的元素 。 另一方面,为了能够混合两个不同的对象,以 y_content 为条件的生成过程需要更大的 K 以确保足够的混合步骤。 如图 6 顶行所示,给定 K = 0.6T,条件生成过程成功合成了柯基犬形状的咖啡机。

保留更多布局细节。 为了保留给定布局对象的更多元素,我们从步骤 x_Kmax 开始执行去噪,并建议用先前从条件生成过程获得的合成噪声对原始布局噪声进行插值。 混合常数 v 控制布局和内容语义之间的比率。 我们再次在图 7 中展示了一个将“柯基犬”的布局与“咖啡机”的内容混合的示例。当 v = 1 时,条件生成过程从步骤 Kmax 开始,不使用噪声序列
![]()
中的信息。 我们可以合成一个与“柯基犬”图像颜色相似的“咖啡机”图像,但除了形状之外几乎不包含“柯基犬”的元素。 有趣的是,当 v 为 0.4 时,我们注意到由于“corgi”元素占主导地位,只合成了一个咖啡杯。 在此示例中,当我们设置 v = 0.5 或 0.6 时,我们可以获得类似柯基犬的咖啡机图像。 在实践中,我们固定 Kmax = 0.6T 和 Kmin = 0.3T,并且仅改变 n。
v 的最优值。我们还注意到,“最优”插值常数 v 是由两个概念之间的语义相似性决定的。 例如,当混合“柯基犬”和“哈士奇”时,扩散模型只需要修改眼睛和纹理。 因此,我们可以使用较小的 v 值(例如,0.1)。 相反,当混合“柯基犬”和“咖啡机”时,由于这两个概念极其不同,扩散模型需要更多的去噪步骤才能覆盖细节。 在这种情况下,我们可以使用较大的 v 值(例如,0.9)。
3.3.2 加权图文交叉注意力
受 Prompt-to-Prompt (Hertz et al., 2022) 的启发,我们还发现重新加权图像-文本交叉注意力以增加或减少概念的重要性是有效的。 考虑混合“兔子”和“老虎”的情况。 给定文本-图像交叉注意力图
![]()
其中 N_image 和 N_text 分别表示空间和文本标记的数量,以及条件提示 y =“老虎的照片”,我们缩放对应于参数为 s ∈ [-2,2] 的 “tiger” 标记的注意力图,同时保持其余注意力图不变。 如图8所示,“老虎”内容的程度可以使用不同的正尺度 s 值(例如老虎条纹的数量)来调整。

概念去除。 另一方面,我们观察到应用负 s 会导致一个有趣的行为:给定汉堡图像和条件提示 y =“汉堡包的照片”,使用负 s 相当于鼓励扩散模型生成布局类似于汉堡包但不是汉堡包的图像。 我们称这个为概念去除。 如图 8 的右子图所示,当消除“汉堡”概念时,扩散模型被迫想象最可能的非汉堡物体,例如飞艇或螃蟹。
3.4 实现细节
在实践中,我们使用潜在扩散模型(LDM)进行语义混合。 由于 LDM 中的自动编码器是通过 patch-wise 损失进行训练的,因此自动编码器保留了潜在空间和原始 RGB 空间之间的空间对应关系。 我们还观察了 LDM 采样过程中的渐进生成特性。 我们的实现是基于 Stable Diffusion (https://huggingface.co/CompVis/stable-diffusion)代码库开发的,它是 LDM 的开源实现。 人们可以使用稳定扩散来生成高质量的图像。 它还提供多种类型的采样器来平衡样本质量和计算效率之间的权衡。 我们在实验中使用 DDIM 采样器。
4. 应用
在本节中,我们将展示使用 MagicMix 的几个应用,包括 (a) 语义样式迁移(第 4.1 节)、(b) 新对象合成(第 4.2 节)、(c) 品种混合(第 4.3 节)和 (d) 概念删除 (第 4.4 节)。
4.1 语义风格迁移

我们首先通过合成具有不同语义的符号(例如,用人物替换双向符号中的箭头)来演示语义样式迁移应用。 与样式迁移基于参考样式图像对内容图像进行风格化而不更改图像内容不同,我们的 MagicMix 允许用户注入新的语义,同时保留空间布局和几何形状(例如,三角形符号)。 我们在图 9 中展示了一些示例。请注意,尽管内容发生了很大变化,背景仍保留完好。 此类应用程序可能用于通过向模板注入新概念来辅助新徽标/标志的设计。
4.2 新物体合成
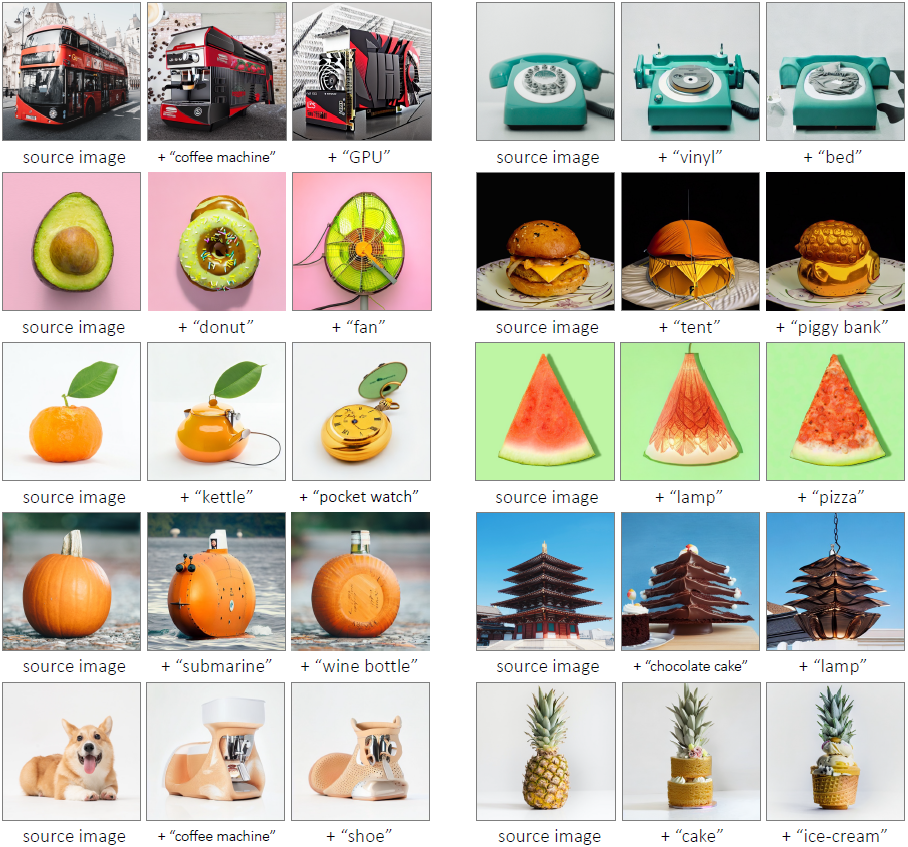
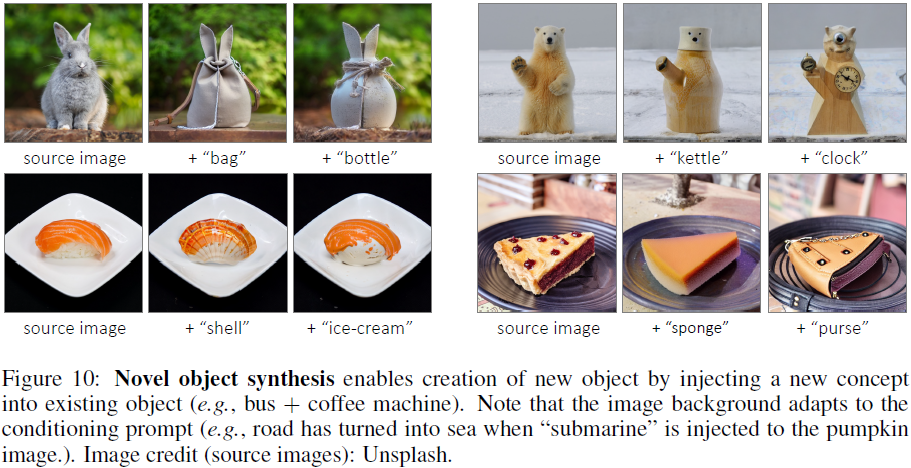
我们的 MagicMix 还允许通过将新概念(例如咖啡机)注入现有对象(例如公共汽车)来合成新颖的对象。 这对于在设计新的商业产品时激发创造力非常有用。 我们在图 10 中展示了一些示例。背景上下文根据条件提示进行相应的调整。 例如,当“潜艇”与南瓜图像混合时,道路就变成了大海。 同样,当一座宝塔与“巧克力蛋糕”混合在一起时,道路就变成了一张桌子,以更好地契合整个图像语境。 这表明这两个概念的混合发生在语义层面。
4.3 品种混合


接下来,我们展示了根据我们的方法混合两种不同品种的可能性。 如图 11 的前两行所示,我们的方法可以混合两种不同的动物品种(例如拉布拉多犬 Labrador 和斗牛犬 bulldog),并生成具有不同特征(拉布拉多犬的耳朵和斗牛犬的脸)的合理结果。 更有趣的是,我们的方法甚至可以混合两种不同的物种并生成新的未见过的动物物种,如第三行和第四行所示。 请注意,其中一些组合几乎没有共同点(例如,兔子和鸡、兔子和老虎),但我们仍然可以获得逼真的结果。 同样,在最后两行中,我们还演示了两种不同水果(例如菠萝和葡萄)或花朵(例如玫瑰和蒲公英)的混合。
4.4 概念去除

我们通过向现有语义注入新语义来呈现各种应用。 在这里,我们还感兴趣的是通过删除其原始语义来生成新图像,并让模型决定除了原始内容之外还生成什么。 这可以通过将图像-文本交叉注意力图乘以负权重来轻松实现(第 3.3.2 节)。 图 12 显示了一些示例。正如我们所看到的,生成的图像在很大程度上保留了整体布局,同时删除了原始语义。 例如,如最后一行所示,给定一篮子水果,通过删除“水果”概念,我们得到一篮子花。 另一方面,删除“篮子”的概念会导致生成顶部有水果的蛋糕。
4.5 文本-文本语义混合

在前面的部分中,我们已经演示了 MagicMix 使用图像文本混合的几种应用(布局语义是根据给定图像精心设计的)。 接下来,我们还提供了一些不需要图像的情况下使用文本-文本混合模式的 MagicMix 的结果。 如图 13 所示,我们的方法成功地混合了两种不同的语义并生成逼真的结果。 然而,文本-文本语义混合的一个限制是,由于没有提供图像用于布局生成,因此最终的合成结果是不可预测的。
5. 限制

我们确定了我们的方法的失败案例,其中如果两个概念没有任何形状相似性,则它们不能混合(例如,混合“货车”和“猫”或“厕纸”和“柯基犬”)。 在这种情况下,这两个概念将被简单地组合起来(例如,一只猫骑着一辆货车或在卫生纸卷上画了一幅柯基犬)。 图 14 中可以找到一些示例。我们将解决这些问题留待未来的工作。
6. 结论
在这项工作中,我们提出了一项称为语义混合的新颖任务,其目标是混合两种不同的语义以合成一个新的看不见的概念。 为此,我们提出了 MagicMix,这是一种基于预先训练的基于文本条件扩散的图像生成模型的简单解决方案。 我们的方法通过在去噪过程中注入新概念来利用基于扩散的生成模型的特性。 我们的方法不需要任何空间掩模或重新训练,同时保留布局和几何形状。 鉴于此,我们的 MagicMix 支持多种下游应用程序,包括语义样式转换、新对象合成、品种混合和概念删除。
7. 社会影响
我们工作的目标是合成一个混合概念的新颖对象。 与其他基于深度学习的图像合成和编辑算法类似,我们的方法根据应用和用途既有积极的也有消极的社会影响。 从积极的一面来看,MagicMix 可以激发新商业产品的创造(例如,类似柯基犬的咖啡机)。 不利的一面是,它可能被恶意方用来欺骗或误导人类。 另一个问题是,这项工作中使用的预训练模型 Stable Diffusion v1.4(Rombach 等人,2022)是在 LAION 数据集上进行训练的,已知该数据集存在社会和文化偏见。
参考
Liew J H, Yan H, Zhou D, et al. Magicmix: Semantic mixing with diffusion models[J]. arXiv preprint arXiv:2210.16056, 2022.
S.总结
S.1 主要思想
MagicMix 基于预训练的文本条件扩散模型进行语义混合。受扩散模型的渐进生成特性的启发,其中布局 / 形状出现在早期去噪步骤中,而语义上有意义的细节出现在去噪过程中的后续步骤中。
基于此,语义混合任务可分解为两个阶段:
- 布局语义(例如形状和颜色)生成:通过破坏给定的真实照片或在给定文本提示的情况下从纯高斯噪声中去噪来获得粗略的布局语义。
- 内容语义(例如语义类别)生成:为布局语义注入一个新概念并继续去噪过程,直到我们获得最终的合成结果。
语义混合在概念上不同于其他图像编辑和生成任务,例如风格转移或组合生成。
- 风格迁移根据给定的风格(例如梵高的《星空》)对内容图像进行风格化,同时保留图像内容。
- 组合生成将多个单独的组件组合起来以生成复杂的场景。
- 语义混合旨在将多种语义融合到一个新颖的对象/概念中。
S.2 应用
语义风格迁移:与样式迁移基于参考样式图像对内容图像进行风格化而不更改图像内容不同,MagicMix 允许用户注入新的语义,同时保留空间布局和几何形状。
新物体合成:通过将新概念注入现有对象来合成新颖的对象。此外,背景上下文根据条件提示进行相应的调整。例如,当一座宝塔与“巧克力蛋糕”混合在一起时,道路就变成了一张桌子,以更好地契合整个图像语境。
品种混合:混合两种不同的动物品种,并生成具有不同特征的合理结果。甚至可以混合两种不同的物种并生成新的未见过的动物物种,即使这些组合几乎没有共同点。
概念去除:通过将图像-文本交叉注意力图乘以负权重,使生成的图像在很大程度上保留了整体布局,同时删除了原始语义。例如,给定一篮子水果,删除“水果”概念得到一篮子花,删除“篮子”的概念得到顶部有水果的蛋糕。
文本-文本混合:在没有图像的情况下进行合成。然而,由于没有提供图像用于布局生成,因此最终的合成结果是不可预测的。
S.3 限制
如果两个概念没有任何形状相似性(例如,货车和猫),则它们不能混合,只能将两个概念简单地组合(例如,骑着货车的猫)。该问题留待未来解决。

