
热门标签
热门文章
- 1HTML2022年圣诞节专属你的圣诞树来了_好看的圣诞节html
- 2ROS 导航实现(A*,DWA)_ros配置文件dwa
- 3【ROS2】开发环境搭建——安装VSCode及插件_ros2 vscode
- 4美团面试都面不过?我又不是去送外卖的!美团Java面试经历总结【一面、二面、三面】_美团java社招多久通知二面
- 5【C#】制作TCP服务器_c# tcp服务器
- 6如何实现rviz中的机械臂和实际的机械臂同步----ROS机械臂学习笔记(三)_如何在rviz中通过订阅其他节点发布法话题让机械臂模型动起来
- 7【大数据技术之Flink】一文读懂Flink,流计算_flink 使用离线数据更正计算结果
- 8Spring Boot进阶(06):【超详细】Windows10搭建RabbitMQ Server服务端,让你轻松实现消息队列管理!_windows rabbitmq 管理平台
- 9ESP32 CAM+ VSCODE+ESP IDF环境搭建 python pip版本问题_espidf python -m pip
- 10解决Matplotlib运行时报错:AttributeError: module ‘backend_interagg’ has no attribute ‘FigureCanvas’的问题_matplotlib报错 attributeerror
当前位置: article > 正文
YoloV8改进策略:RepViT改进YoloV8,轻量级的Block助力YoloV8实现更好的移动性_repvit改进为repvb
作者:小舞很执着 | 2024-07-21 04:43:45
赞
踩
repvit改进为repvb
文章目录
- 摘要
- 论文:《RepViT:从ViT视角重新审视移动CNN》
- 1、简介
- 2、相关工作
- 3. 方法论
- 5、结论
- A. RepViTs架构
- 一些名词的理解
- Yolov8官方结果
- 改进一:构造全新的C2f_RepViTBlock模块,使用RepViTBlock替换Bottleneck,将C2f_RepViTBlock替换BackBone的C2f模块
- 改进二:构造全新的C2f_RepViTBlock模块,使用RepViTBlock替换Bottleneck,将C2f_RepViTBlock替换Head的C2f模块
- 改进三:构造全新的C2f_RepViTBlock模块,使用RepViTBlock替换Bottleneck,将C2f_RepViTBlock替换全部的C2f模块
- 总结
摘要
RepViT 是一种轻量级的深度学习模型,专为移动设备设计。它从ViT(Vision Transformer)的视角重新审视了移动设备上的CNN(Convolutional Neural Network)模型。
CNN通常在图像处理方面表现出色,但通常需要大量的计算资源,这使得它们不适合在资源受限的移动设备上运行。另一方面,ViT是一种基于自注意力机制的模型,适合处理长序列数据,但在图像处理方面不如CNN表现。
RepViT 通过将CNN和ViT结合,形成了一个既具备CNN局部感知能力,又具备ViT全局抽象能力的轻量级模型。这使得RepViT在保持较高性能的同时,又能够适应移动设备的计算和内存资源限制。
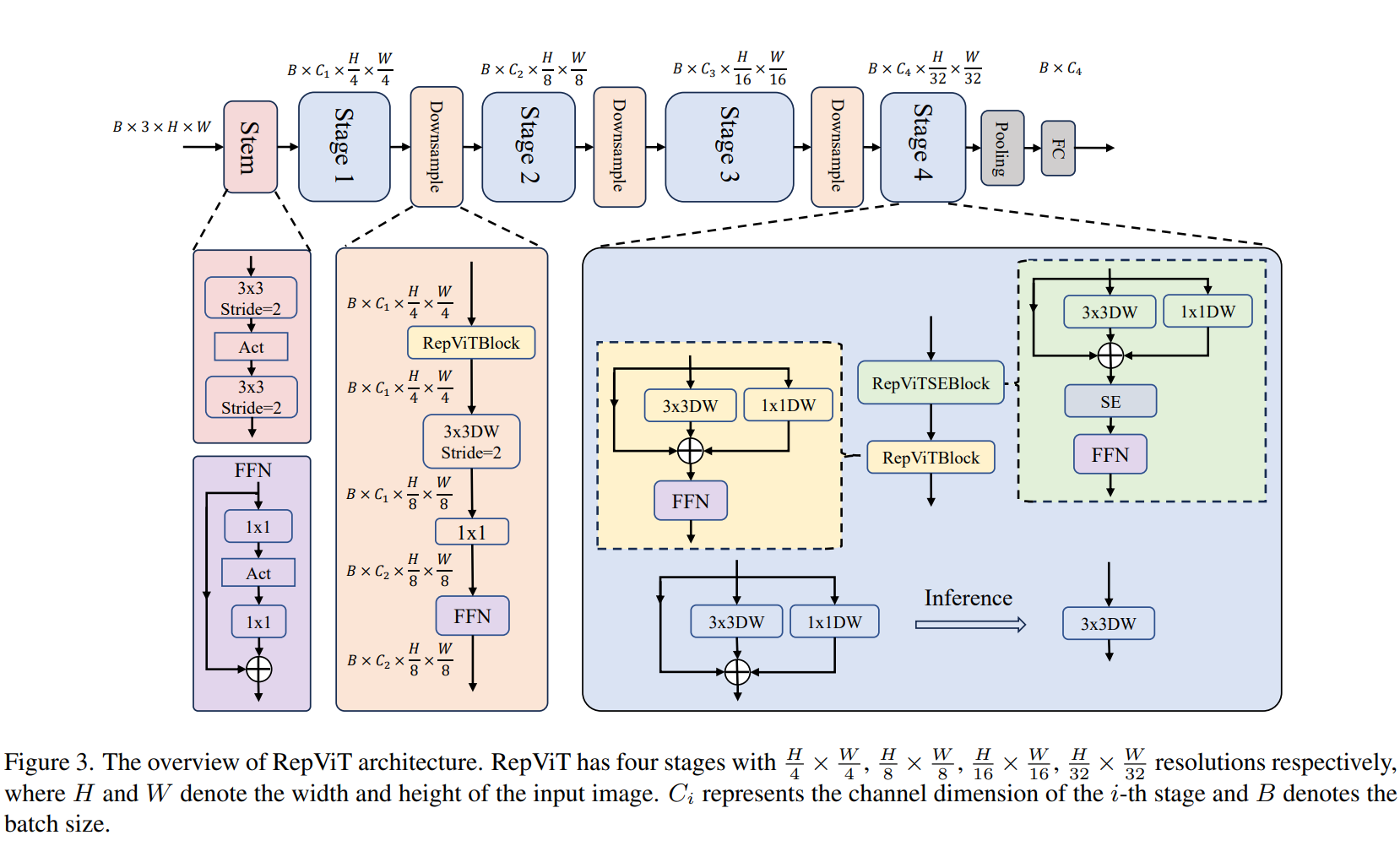
实现上,RepViT 采用了类似于CNN的卷积层结构,但在每一层的卷积之后,加入了类似于ViT的自注意力机制。此外,RepViT 还采用了类似于ViT的“位置嵌入”技术,将输入图像中的每个像素位置映射到一个向量空间中,从而更好地捕捉图像中的空间信息。
总的来说,RepViT 的主要优点是兼具CNN和ViT的优点,并且比两者更适合移动设备。
论文:《RepViT:从ViT视角重新审视移动CNN》
https://arxiv.org/pdf/2307.09283.pdf
近年来,与轻量级卷积神经网络(CNN)相比,轻量级视觉Transformers(ViTs)在资
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小舞很执着/article/detail/859671
推荐阅读
相关标签

