
- 1最强开源模型来了!一文详解 Stable Diffusion 3 Medium 特点及用法
- 2免费AI网站,AI人工智能写作+在线AI绘画midjourney_免费网页ai
- 3零信任架构的实施规划——针对联邦系统管理员的规划指南_是nist标准《零信任架构》白皮书中列举的技术方案
- 4西门子S7_1200与E6C2_CWZ6C编码器设置_s7-1200与旋转编码器接线图
- 5LVDS硬件设计
- 6使用shedlock实现分布式互斥执行
- 7Git之Idea操作git_idea 登录git
- 82024HVV蓝队初级面试合集(非常详细)零基础入门到精通,收藏这一篇就够了_2024hvv面试题目
- 9毕业设计:基于java的企业员工信息管理系统设计与实现_员工信息查询功能的设计与实现
- 10视频服务器(4) webrtc-streamer(windows下卡住了)
一文彻底搞定 RAG、知识库、 Llama-3!!
赞
踩
▼最近直播超级多,预约保你有收获

—1—
使用 Llama-3 搞定 RAG
检索增强生成(Retrieval Augmented Generation,RAG)是一种强大的工具,它通过将企业外部知识整合到生成过程中,增强了大语言模型(LLM)的性能。
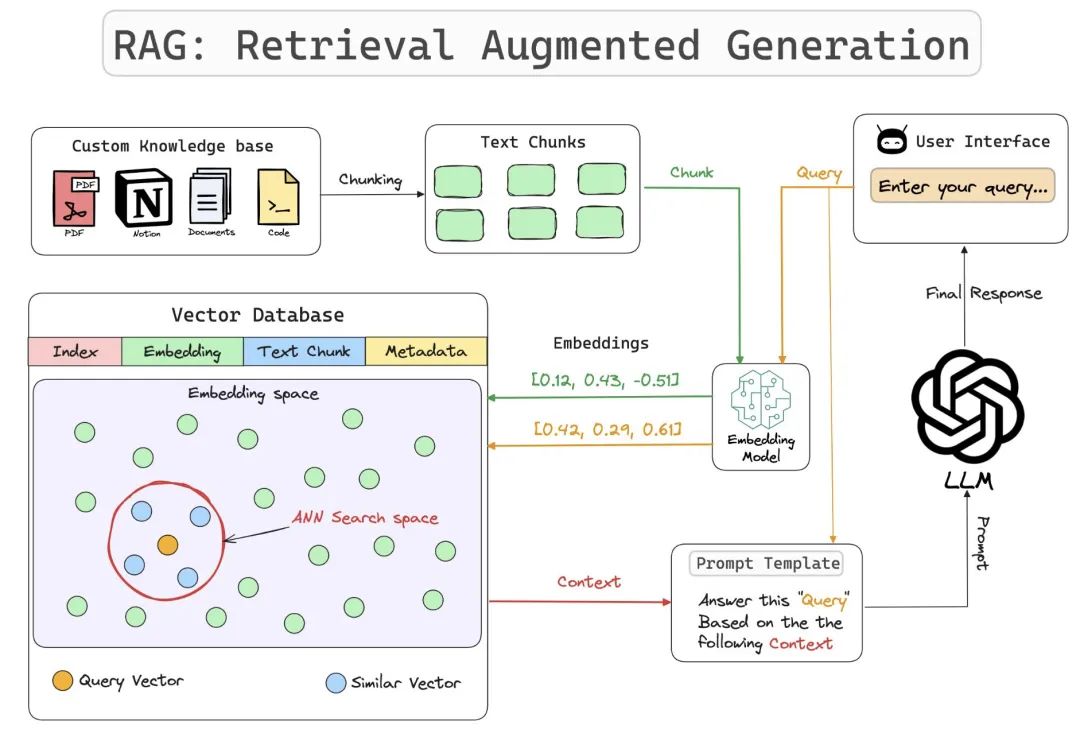
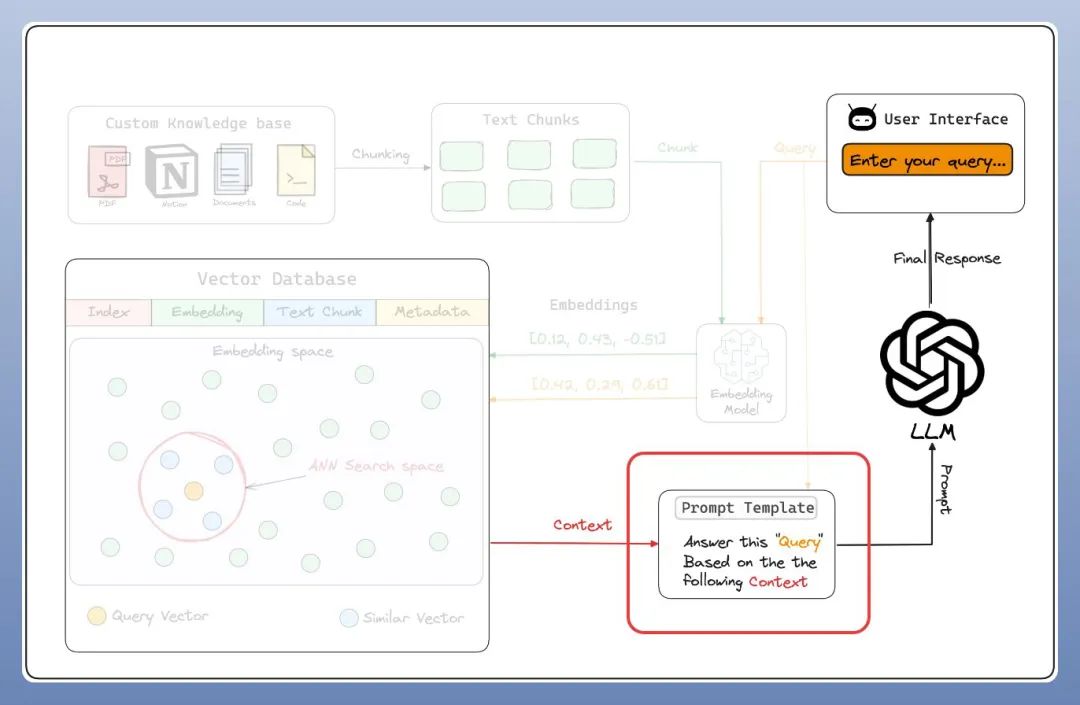
让我们探索 RAG 的关键7大组成部分。
第一、自定义知识库(Custom Knowledge)
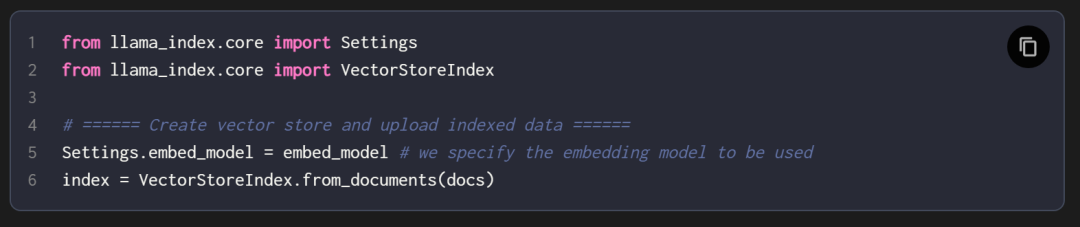
定制知识库是指一系列紧密关联且始终保持更新的知识集合,它构成了 RAG 的核心基础。这个知识库可以表现为一个结构化的数据库形态(比如:MySQL),也可以表现为一套非结构化的文档体系(比如:文件、图图片、音频、视频等),甚至可能是两者兼具的综合形式。

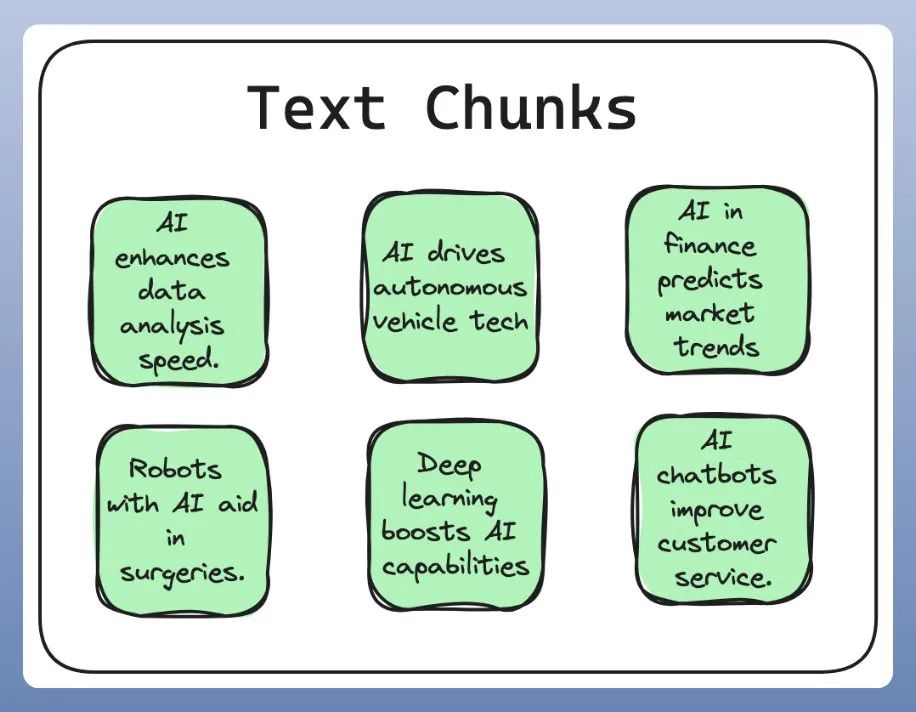
第二、分块处理(Chunking)
分块技术是指将大规模的输入文本有策略地拆解为若干个较小、更易管理的片段(Chunk)的过程。这一过程旨在确保所有文本内容均能适应嵌入模型所限定的输入尺寸,同时也有助于显著提升检索效率。
实施一种明智且高效的分块策略,在优化知识处理流程方面具有关键作用,能够极大地增强您的 RAG 系统的性能与响应能力。
第三、嵌入模型(Embedding Model)
一种将多模态数据(文本、图片、音频等)表示为数值向量的技术,可以输入到机器学习模型中。

嵌入模型负责将多模态数据转换成这些向量。
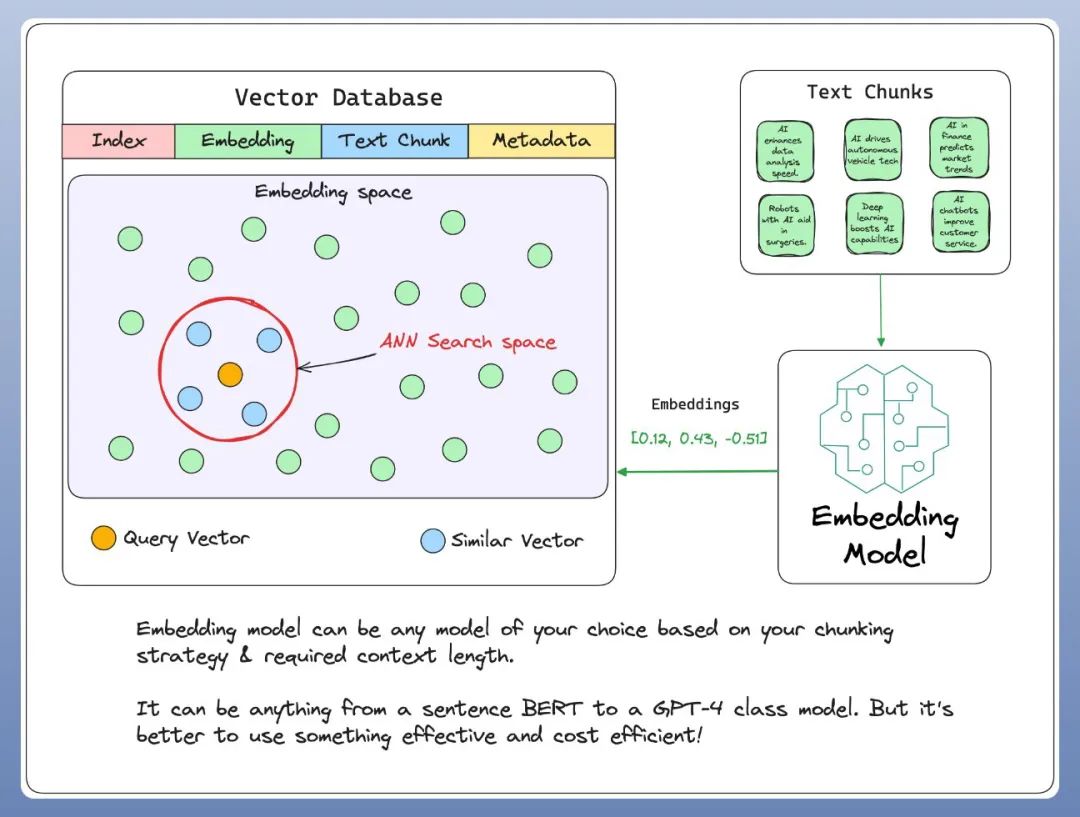
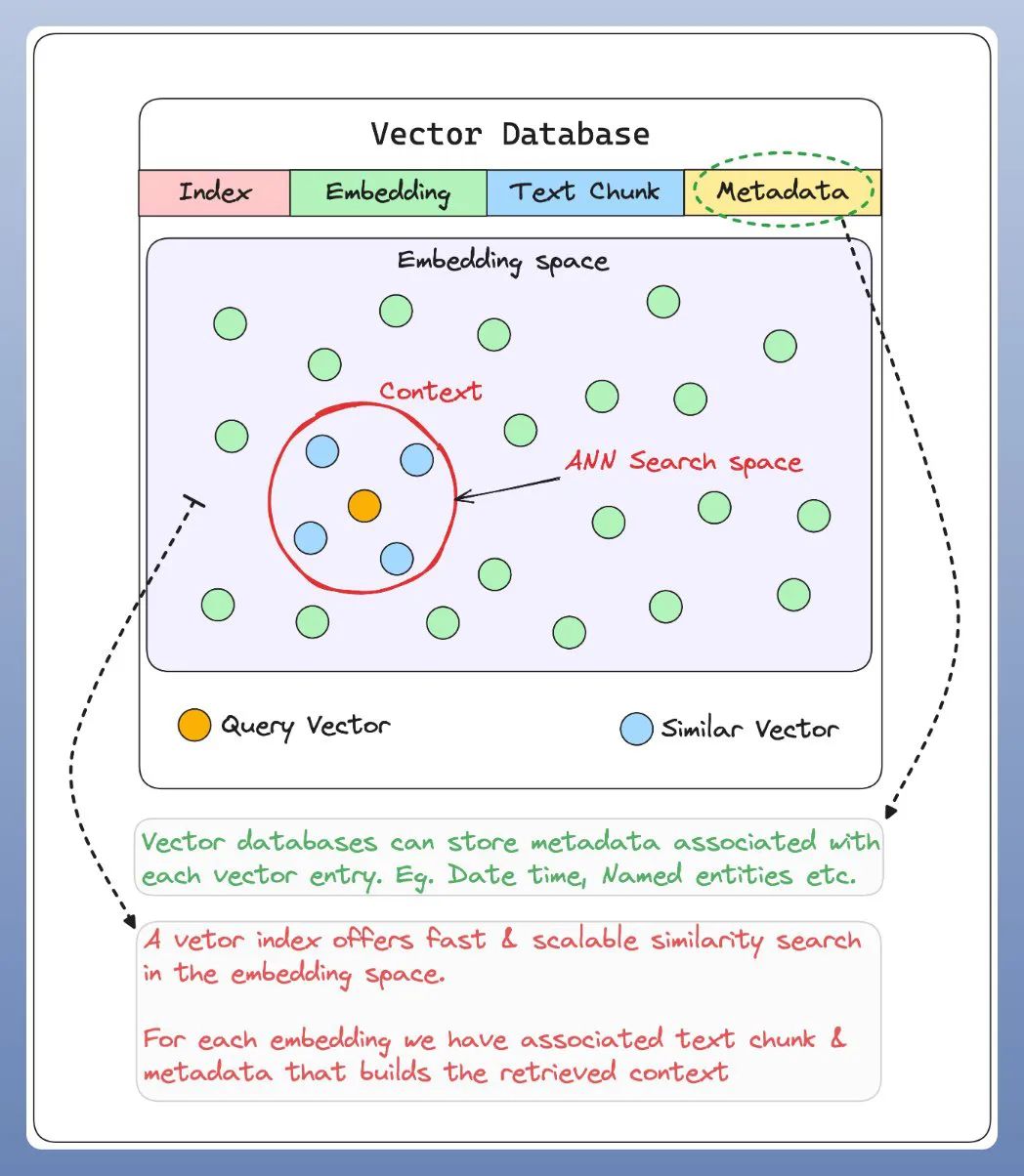
第四、向量数据库( Vector Databases)
一系列预先计算的文本数据向量表示,用于快速检索和相似性搜索,具有SQL CRUD 操作、元数据过滤和水平扩展等功能。
第五、用户聊天界面(User Chat Interface)
一个用户友好的界面,允许用户与 RAG 系统互动,提供输入查询并接收输出。
查询转换为嵌入向量,用于从向量数据库检索相关上下文知识!
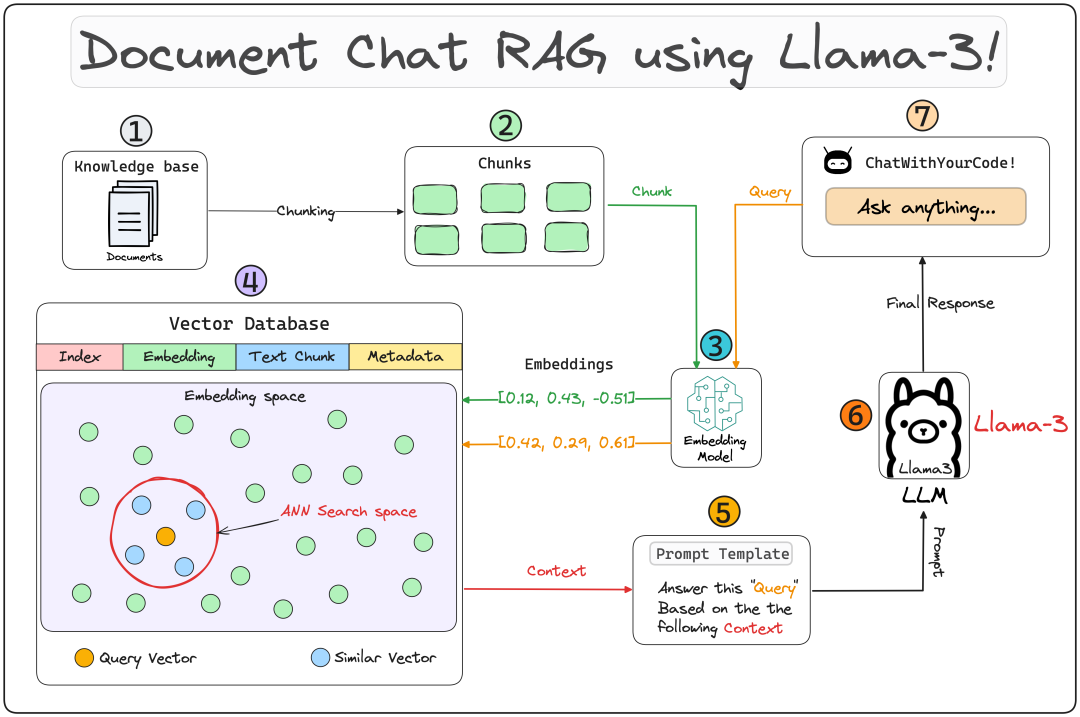
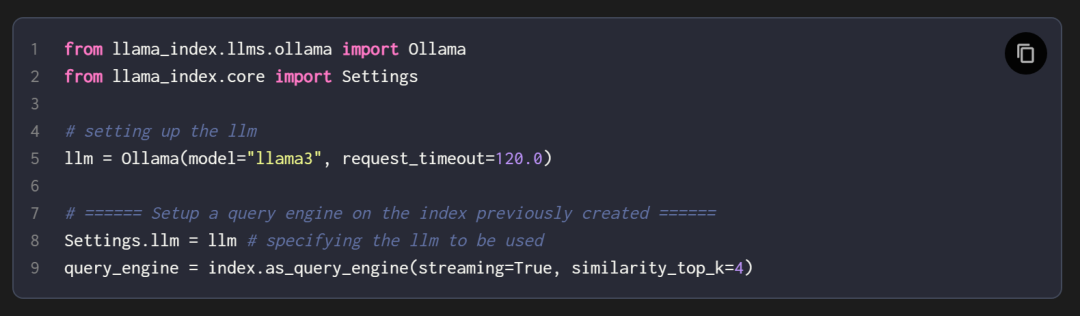
第六、查询引擎(Query Engine)
查询引擎获取查询字符串,使用它来获取相关上下文,然后将两者一起作为提示词发送给 LLM 以生成最终的自然语言响应。这里使用的 LLM 是Llama-3,它在本地运行,这要归功于 Ollama。最终响应将在用户界面上显示。
第七、提示词模板(Prompt Template)
为 RAG 系统生成合适提示词的过程,可以是用户查询和自定义知识库的组合。
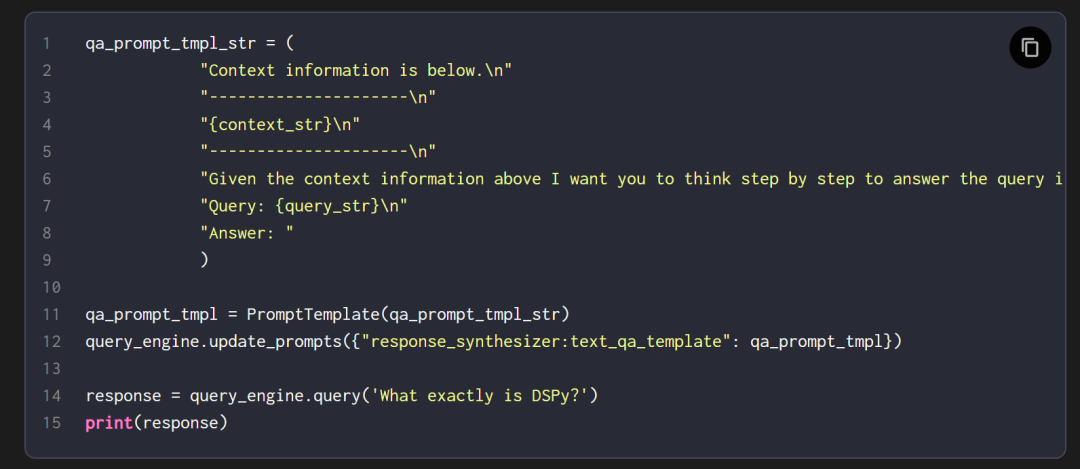
这作为输入给 LLM,生成最终的回复。
—2—
领取 AI 大模型学习资料
 不会吧,都2024年了,还有人在网盘、B站上爬学习资源?
不会吧,都2024年了,还有人在网盘、B站上爬学习资源?
 今天给大家搞到的是一份大厂内部在用的『AI大模型学习资源』:
今天给大家搞到的是一份大厂内部在用的『AI大模型学习资源』:
▶形式:直播公开课
▶费用:原价299,本号用户0元白嫖
▶内容:大模型原理、Agent、LangChain、Spring AI、RAG、向量数据库、知识库、私有大模型、算力评估...
扫码一键预约
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

