
热门标签
热门文章
- 1寒武纪面试——数字IC,数字逻辑岗_寒武纪数字后端面试
- 2查询kafka信息,并设置Kafka的偏移量Offset_kafka 查下当下各分区offset
- 3【AI学习指南】轻量级模型-用 Ollama 轻松玩转本地大模型
- 4如何在 Spring Boot 中开发一个操作日志系统
- 5JAVA小白学习日记Day2
- 6Scrapy 框架采集亚马逊商品top数据_scrapy爬取亚马逊商品数据
- 7【实干!干货】Pycharm安装通义灵码ai智能编码助手
- 8昇思25天学习打卡营第三十天|快速入门
- 9PyQt5结合Yolo框架打包python为exe文件完整流程_用pyinstaller打包yolov5
- 10DataFrame 遍历访问方法_dataframe如何访问
当前位置: article > 正文
Hive select查询 简单函数(最常用的hive函数 看这一篇就够了)
作者:小舞很执着 | 2024-07-31 16:20:34
赞
踩
hive select
Hive函数
一、select查询
1、hive其他排序操作
知识点:
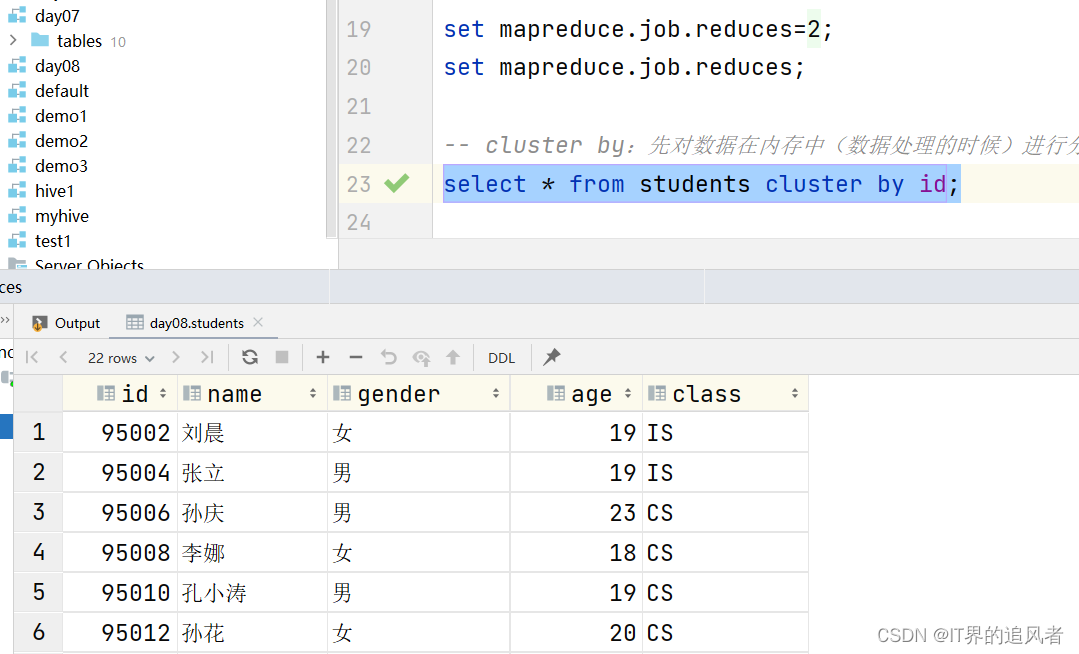
cluster by: 先对数据在处理的时候进行分桶,分完桶以后,再对桶内的数据进行局部排序。分桶和排序的字段是同一个
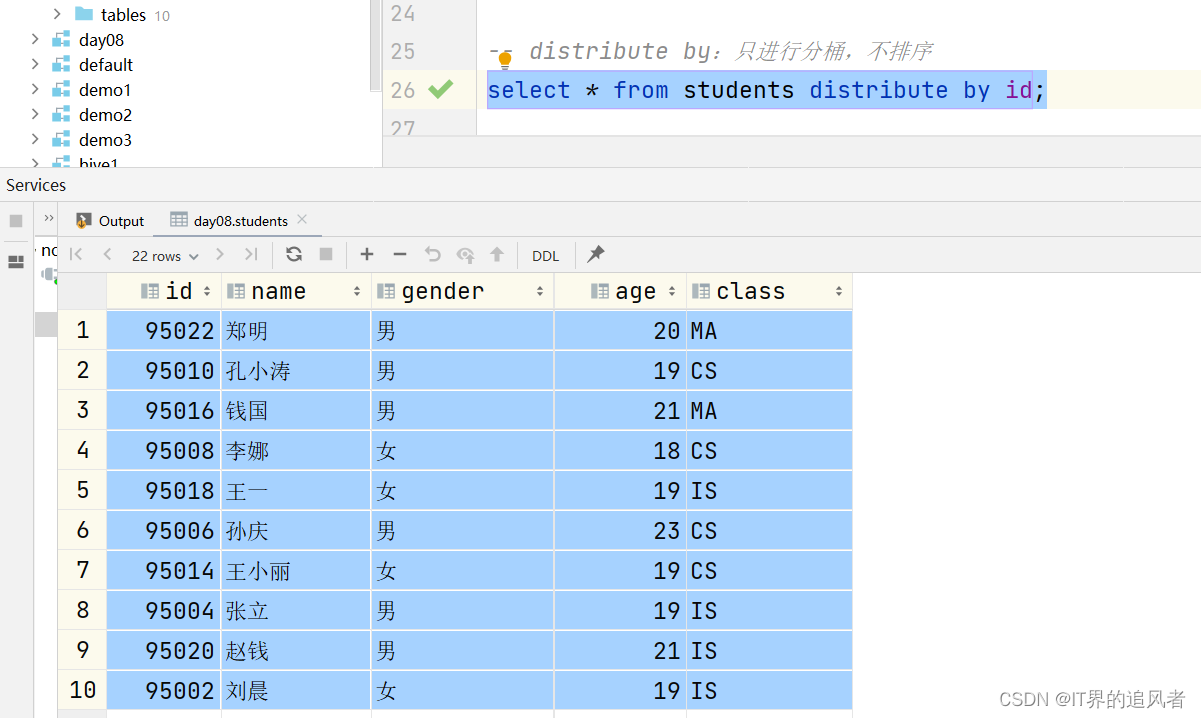
distribute by: 只对数据在处理的时候进行分桶,不排序
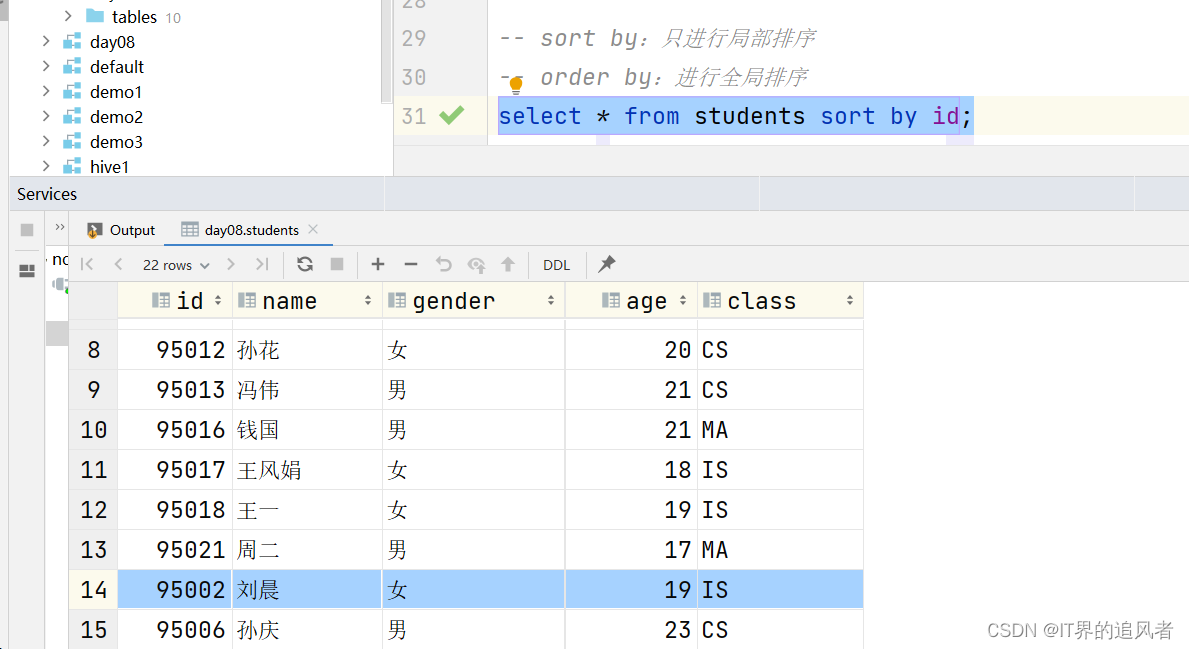
sort by: 只对数据进行局部的排序
order by: 对数据进行全局排序
distribute by + sort by: 先对数据在处理的时候进行分桶,分完桶以后,再对桶内的数据进行局部排序。分桶和排序的字段可以单独指定
- 1
- 2
- 3
- 4
- 5
示例:
create database day08 comment "第8天的数据库"; use day08; create table students ( id int, name string, gender string, age int, class string ) row format delimited fields terminated by ','; load data inpath '/dir/students.txt' into table students; -- 通过Hive参数设置桶的个数 set mapreduce.job.reduces=2; set mapreduce.job.reduces; -- cluster by:先对数据在内存中(数据处理的时候)进行分桶,再对桶内的数据进行排序 select * from students cluster by id; -- distribute by:只进行分桶,不排序 select * from students distribute by id; -- sort by:只进行局部排序 -- order by:进行全局排序 select * from students sort by id; select * from students order by id; -- distribute by 配合sort by:可以实现先分桶,再对桶内的数据进行排序。 -- 相对cluster by的好处是,可以指定不同的字段。 -- 字符串的排序规则,依据ASCII码表进行排序。https://www.runoob.com/w3cnote/ascii.html select * from students distribute by id sort by gender desc;

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
2、正则模糊查询
知识点:
模糊查询:
1- %: 匹配0到多个
2- _: 匹配仅且一个
正则查询:(今天先了解)
1- 使用正则的时候,需要将like改成rlike
2- 正则查询中不支持对数值的查询。需要使用cast进行数据类型转换
- 1
- 2
- 3
- 4
- 5
- 6
- 7
示例:
use day07; select * from orders; select * from orders where useraddress like 's%'; -- .*是正则的写法,匹配任意的内容。如果用的是正则,需要改成rlike,regex select * from orders where useraddress rlike 's.*'; select * from orders where userid like '_'; -- ..表示匹配2个字符。rlike中只支持字符串类型,不支持数值类型 select * from orders where cast(userid as string) rlike '..'; -- 正则表达式复杂用法 -- ^1\\d{6}$:匹配字符串中以1开头,并且后面跟上6个其他任意的数值。\d表示的是匹配数值。\\d表示转义 -- ^:匹配开头,必须要以1开头 -- $:匹配结尾,必须以数值结尾 select * from orders where orderno rlike '^1\\d{6}$';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
使用正则查询遇到的问题:
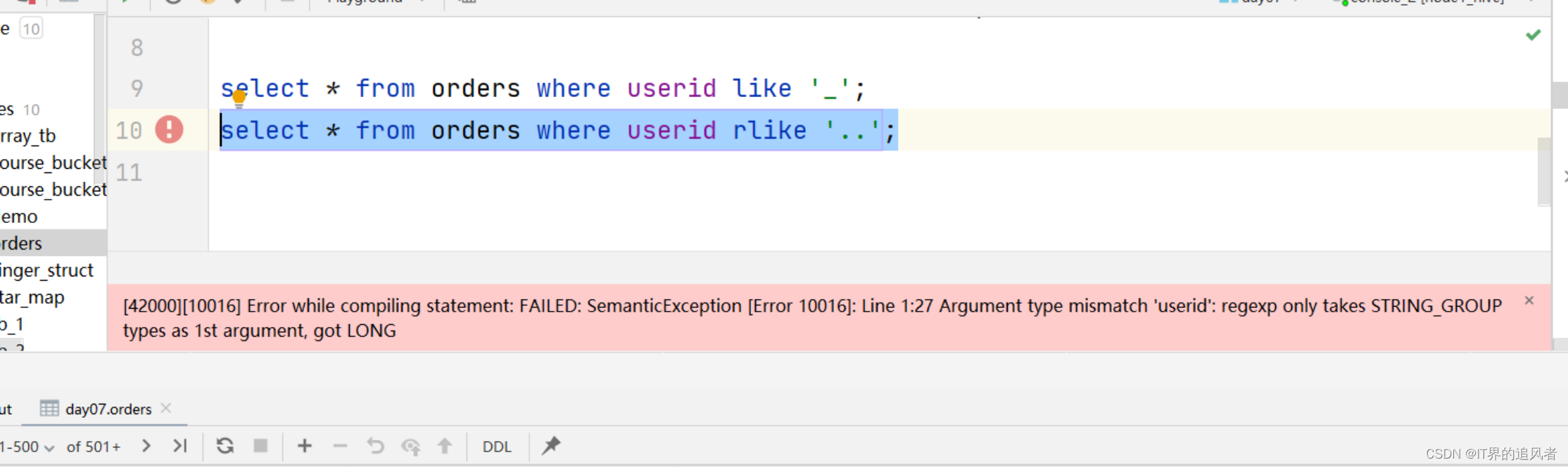
原因: rlike中只支持字符串类型,不支持数值类型
解决办法: 进行类型转换
- 1
- 2
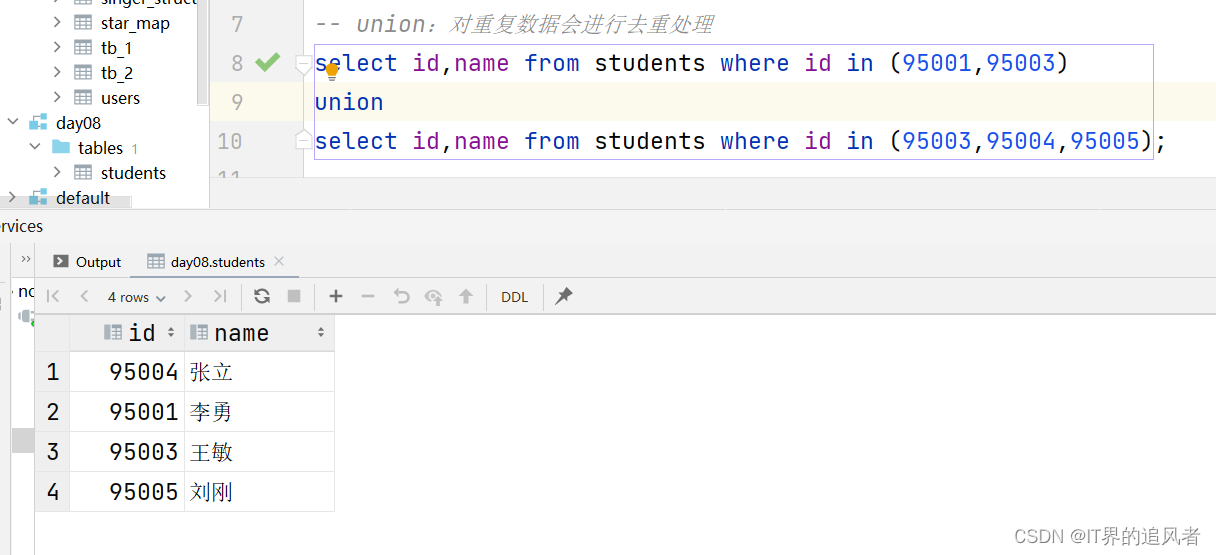
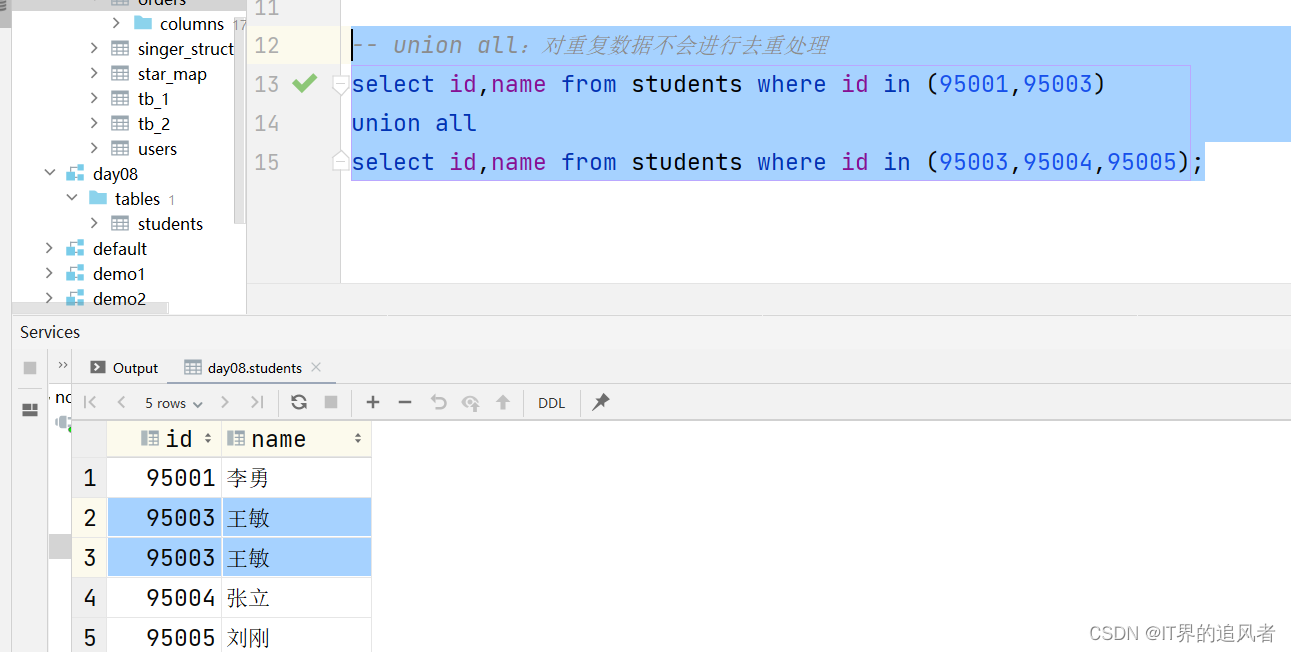
3、union联合查询
知识点:
union: 对重复数据会去重
union all: 对重复数据不会去重
注意:union和union all中两边的字段(类型、顺序)要对应上
- 1
- 2
- 3
- 4
示例:
use day08; select * from students; select id,name from students where id in (95001,95003); select id,name from students where id=95001 or id=95003; -- union:对重复数据会进行去重处理 select id,name from students where id in (95001,95003) union select id,name from students where id in (95003,95004,95005); -- union all:对重复数据不会进行去重处理 select id,name from students where id in (95001,95003) union all select id,name from students where id in (95003,95004,95005); -- 注意:union和union all中两边的字段(名称、顺序)要对应上 select id,name from students where id in (95001,95003) union all select id,age from students where id in (95003,95004,95005); select id,name from students where id in (95001,95003) union all select name,id from students where id in (95003,95004,95005);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
可能遇到的问题:
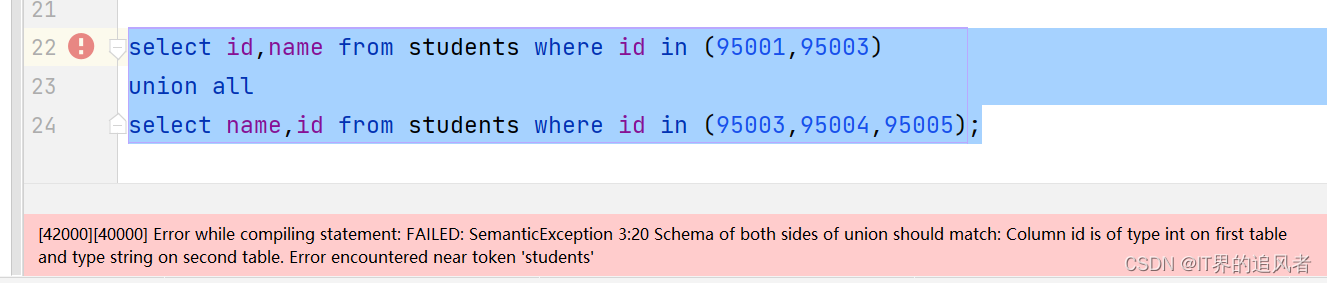
原因: union和union all中两边的字段(类型、顺序)要对应上
- 1
4、with as子查询
知识点:
with 临时表的名称1 as (
数据查询语句
) select语句;
with 临时表的名称1 as (
数据查询语句
),
临时表的名称2 as (
数据查询语句
)select语句;
注意:
1- 临时表的名称要保持唯一
2- with只能写在最前面,而且只有一个
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
示例:
-- with as子查询 -- 子查询:普通写法 select * from ( select id, name from students where id in (95001, 95003) )tmp where id=95001; -- 子查询:with as写法 with tmp_1 as ( select id, name from students where id in (95001, 95003) ) select * from tmp_1 where id=95001; with tmp_1 as ( select id, name from students where id in (95001, 95003) ), tmp_2 as ( select id, name from students where id in (95004, 95005) ) select * from tmp_1,tmp_2; -- 这里是cross join的简写
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
5、抽样查询
知识点:
语法:
tablesample (bucket 抽样桶的个数 out of 桶的总数 on [字段名称 | rand()])
抽样查询的用途: 当Hive表中的数据非常多的时候,我们想快速的对数据整体情况有一个大概的了解
- 1
- 2
- 3
- 4
示例:
use day07;
-- 分桶的时候按照字段进行分桶
select * from orders tablesample (bucket 1 out of 20 on orderId);
-- 分桶的时候进行随机分桶。内部会尽可能的做到均衡
select * from orders tablesample (bucket 1 out of 20 on rand());
- 1
- 2
- 3
- 4
- 5
- 6
6、内置虚拟列
知识点:
虚拟列是Hive内置的可以在查询语句中使用的特殊标记,可以查询数据本身的详细参数。
Hive目前可用3个虚拟列:
INPUT__FILE__NAME,显示数据行所在的具体文件
BLOCK__OFFSET__INSIDE__FILE,显示数据行所在文件的偏移量
ROW__OFFSET__INSIDE__BLOCK,显示数据所在HDFS块的偏移量
此虚拟列需要设置:SET hive.exec.rowoffset=true 才可使用
- 1
- 2
- 3
- 4
- 5
- 6
示例:
use day07;
-- 开启ROW__OFFSET__INSIDE__BLOCK使用
set hive.exec.rowoffset=true;
SELECT
*,
INPUT__FILE__NAME, -- 数据所在的文件位置
BLOCK__OFFSET__INSIDE__FILE, -- 数据所在的字节位置
ROW__OFFSET__INSIDE__BLOCK -- 数据文件所在的block块的偏移量
FROM course_bucket_tb_sort;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
二、hive函数
1、函数分类
知识点:
Hive函数对应的官方文档: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
原生分类标准: 内置函数(Hive官方写好的,咱们直接用即可) 和 用户自定义函数(UDF,UDAF,UDTF)
分类标准扩大化: 本来,UDF 、UDAF、UDTF这3个标准是针对用户自定义函数分类的; 但是,现在可以将这个分类标准扩大到hive中所有的函数,包括内置函数和自定义函数;
目前hive三大标准
UDF: 用户自定义函数user define function。特点:输入一条返回一条,也就是【一对一】的关系
UDAF: 用户自定义聚合函数user define aggregate function。特点:输入多条返回一条,也就是【多对一】的关系
UDTF: 用户自定义表数据生成函数user define table-generation function。特点:输入一条返回多条,也就是【一对多】的关系
查询所有hive函数名称: show functions;
查看某函数使用帮助文档: desc function [extended] 函数名;
注意: 加上extended关键字能查看详细信息示例
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
示例:
show tables;
show databases;
-- 查看Hive中有哪些函数列表
show functions;
-- 查看函数的具体说明
describe function extended count;
describe function extended avg;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2、复杂类型函数
知识点:
hive复杂类型: array struct map array类型: 又叫数组类型,存储同类型的单数据的集合 取值: 字段名[索引] 注意: 索引从0开始 获取长度的函数: size(字段名) 常用 判断是否包含某个数据的函数: array_contains(字段名,某数据) 常用 对数组进行排序的函数: sort_array(数组) struct类型: 又叫结构类型,可以存储不同类型单数据的集合 取值: 字段名.子字段名n map类型: 又叫映射类型,存储键值对数据的映射(根据key找value) 取值: 字段名[key] 获取长度的函数: size(字段名) 常用 获取所有key的函数: map_keys() 常用 获取所有value的函数: map_values() 常用
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
示例:
-- 演示集合函数
select array('binzi','666','888');
select size(array('binzi','666','888'));
select array_contains(array('binzi','666','888'),'binzi');
-- 复杂数据类型(补充sort_array)
select array(4,2,3,5,1); -- 创建一个数组
select sort_array(array(4,2,3,5,1)); -- 只能升序排序
describe function extended sort_array;
select map('a',1,'b',2,'c',3);
select size(map('a',1,'b',2,'c',3));
select map_keys(map('a',1,'b',2,'c',3));-- ["a","b","c"]
select map_values(map('a',1,'b',2,'c',3));-- [1,2,3]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3、数学函数
知识点:
常用:
round: round(字段名称[,小数的位数]),对数据进行四舍五入
ceil: 得到大于字段值的最小整数
floor: 得到小于字段值的最大整数
不常用:
rand: 随机生成0-1的数据
pi: 生成Π的结果
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
示例:
select "hello world" as f; select 12123 as f; -- 复杂数据类型(补充sort_array) select array(4,2,3,5,1); -- 创建一个数组 select sort_array(array(4,2,3,5,1)); -- 只能升序排序 describe function extended sort_array; -- 数学函数 -- round(字段名称[,小数的位数]):对数据进行四舍五入 select round(3.1415926); select round(3.1415926,2); select round(3.140123,3); select age*1.2 from students; select round(age*id) from students; -- rand([seed]):随机生成0-1的数据。可以传递seed这个随机种子(了解) select rand(); select rand(10); describe function extended rand; -- ceil(字段):得到大于字段值的最小整数 select ceil(1.999999999); -- 2 select ceil(1.00000001); -- 2 -- floor(字段):得到小于字段值的最大整数 select floor(1.999999999); -- 1 select floor(0.999999999); -- 0 -- pi:生成Π的结果 select pi();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
4、类型转换函数
知识点:
类型转换: cast(字段名称 as 想要的数据类型)
- 1
示例:
-- 数据类型转换 -- string->int select cast("123" as int),"123"; -- string->float/double select cast("123.555" as float),"123.555"; -- int->float/double select cast(2 as float); -- float/double->int:只保留整数位 select cast(2.999 as int); -- 异常的 select cast("hello" as int); -- 返回null值 select cast("hello" as double);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
5、数据脱敏函数
知识点:
mask_hash: 返回数据的Hash
mask: 默认将大写字母变成X,小写字母变成x,数值变成n。自定义替换的内容。第一个是大写字母,第二个是小写字母,第三个是数值
mask_first_n: 对指定的前n个内容进行加密
mask_last_n: 对指定的后n个内容进行加密
mask_show_first_n: 除了指定的前n个内容不进行加密,其他内容全部加密
mask_show_last_n: 除了指定的后n个内容不进行加密,其他内容全部加密
- 1
- 2
- 3
- 4
- 5
- 6
- 7
示例:
-- mask_hash:返回数据的Hash select mask_hash("ABC123def"); -- mask:将大写字母变成X,小写字母变成x,数值变成n select mask("ABC123def"); -- XXXnnnxxx -- 自定义替换的内容。第一个是大写字母,第二个是小写字母,第三个是数值 select mask("ABC123def","#","*","$"); -- ###$$$*** select mask(cast(13545678912 as string),"#","$","*"); -- *********** -- mask_first_n:对指定的前n个内容进行加密 select mask_first_n("ABC123def",4); select mask_first_n("ABC123def",4,"#","*","$"); describe function extended mask_first_n; -- mask_last_n:对指定的后n个内容进行加密 select mask_last_n("ABC123def",4); select mask_last_n("ABC123def",4,"#","*","$"); -- mask_show_first_n:除了指定的前n个内容不进行加密,其他内容全部加密 select mask_show_first_n("ABC123def",4); select mask_show_first_n("ABC123def",4,"#","*","$"); -- mask_show_last_n:除了指定的后n个内容不进行加密,其他内容全部加密 select mask_show_last_n("ABC123def",4); select mask_show_last_n("ABC123def",4,"#","*","$");
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
6、字符串函数
知识点:
字符串常见的函数: concat: 将字符串拼接到一起,并且中间没有任何的拼接符号 concat_ws: 将字符串以指定的拼接符号拼接到一起 注意: concat_ws只支持对string或者array<string>进行拼接,不支持对数值类型进行拼接 length: 获取字符串的长度 注意: length不支持对数值类型获取长度 lower: 将字符串全部变成小写 upper: 将字符串全部变成大写 trim: 将字符串前后两端的空白字符去掉 注意: 去除前后的空白内容(例如:空格、制表符)。中间的去除不了 拓展字符串函数 substr: 截取字符串 replace: 替换字符串 regexp_replace: 正则方式替换字符串 parse_url: 解析网站URL get_json_object: 解析json字符串
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
示例:
-- concat:拼接任意类型的内容 select concat("hello","world") as new_str; -- helloworld select concat("hello",222) as new_str; select concat(1.99,222) as new_str; -- concat_ws(指定的符号,字段1,字段2...):以指定的符号对内容进行拼接 select concat_ws("_","hello","world","spark","hive") as new_str; -- hello_world_spark_hive select concat_ws("_","hello",222) as new_str; select concat_ws("_",1.99,222) as new_str; -- length:获取字符串长度 select length("hello"); -- 只能传递一个参数 select length("hello","world"); select length(123); -- lower:全部转小写 select lower("HELLO"); -- 只能传递一个参数 select lower("hello","world"); -- upper:全部转大写 select upper("hello"); -- trim:去除前后的空白内容(例如:空格、制表符)。中间的去除不了 select trim(" hello "); select concat("111"," hel lo ","2222"),concat("111",trim(" hel lo "),"2222"); /* substr(字段名称,截取开始的索引,[截取的长度]):字符串截取 截取开始的索引:有正数索引(从1开始)和负数索引(从-1开始) 截取的长度:可以不指定,默认截取到最后 */ select substr("abcdefg",2); -- bcdefg select substr("abcdefg",2,1); -- b select substr("abcdefg",-2); select substr("abcdefg",-5,2); select substr("2024-12-12 10:10:10",1,4); -- 获取当前日期 select current_date(); select substr(`current_date`(),1,4); -- replace(字段名称,被替换的内容,替换的内容):替换字符串 select replace("你TMD哦","TMD","***"); describe function extended replace; -- regexp_replace(字段名称,正则表达式,替换的内容):通过正则表达式找到目标,然后替换字符串 select regexp_replace("你TMD哦","TMD","***"); select regexp_replace("67869黑马234你好5687","\\d+","***"); describe function extended regexp_replace; -- parse_url(url,解析的内容):解析url地址 -- 注意:解析的内容中必须严格按照函数要求写对应的内容,不能随便写 select parse_url("https://www.baidu.com/s?ie=UTF-8&wd=asd","host"); -- 错误写法 select parse_url("https://www.baidu.com/s?ie=UTF-8&wd=asd","HOST"); -- 正确写法。www.baidu.com select parse_url("https://www.baidu.com/s?ie=UTF-8&wd=asd","PATH"); -- /s,是uri统一资源定位符 select parse_url("https://www.baidu.com/s?ie=UTF-8&wd=asd","QUERY"); -- ie=UTF-8&wd=asd select parse_url("https://www.baidu.com/s?ie=UTF-8&wd=asd","QUERY","wd"); -- 获取具体的查询内容 describe function extended parse_url; -- Parts: HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, USERINFO -- get_json_object /* { "name":"zhangshan", "age":18 } */ select get_json_object('{"name":"zhangshan","age":18}',"$.name"); select get_json_object('{"name":"zhangshan","age":18}',"$.age"); -- 嵌套json的解析 select get_json_object('{"name":"zhangshan","age":18,"addr":{"province":"广东省","city":"广州市"}}',"$.addr.province");
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
concat_ws可能出现的错误:
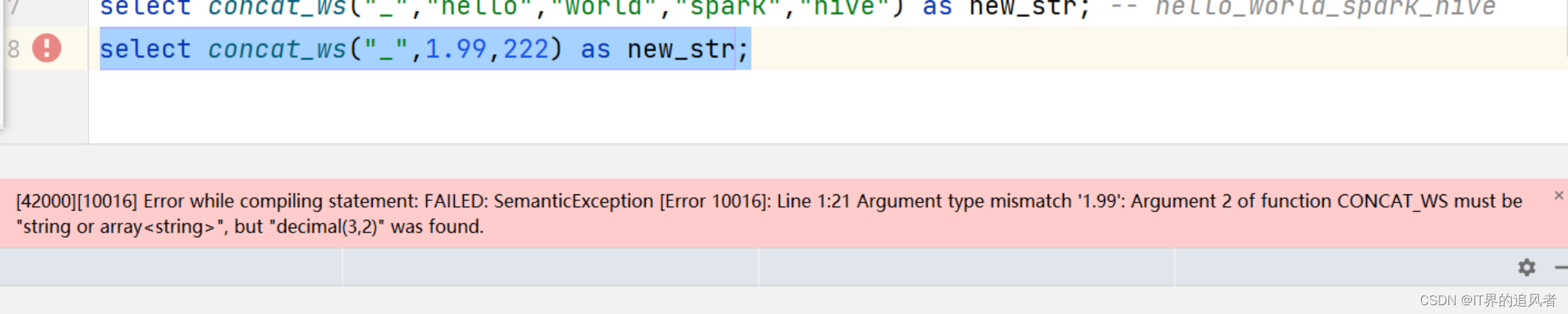
原因:concat_ws只支持对string或者array<string>进行拼接,不支持对数值类型进行拼接
- 1
length可能遇到的错误:
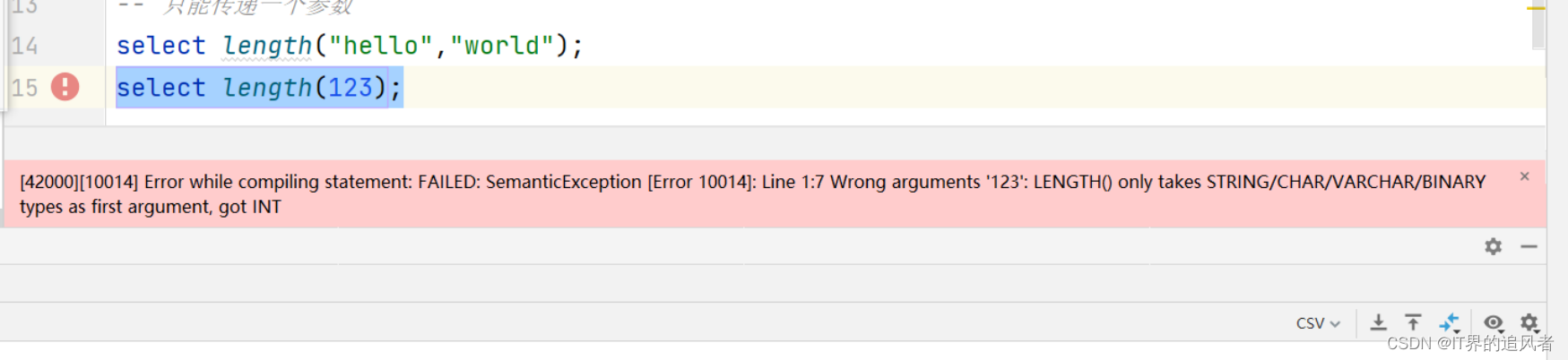
原因: length不支持对数值类型获取长度
- 1
substr中正数索引和负数索引的编号:
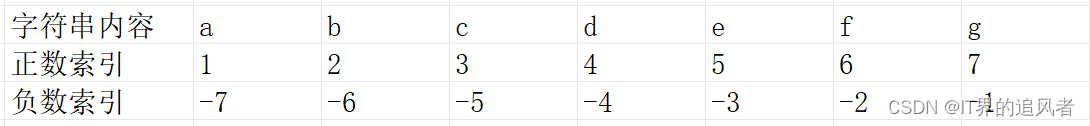
7、日期时间函数
Hive函数链接:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF
https://docs.oracle.com/javase/8/docs/api/java/text/SimpleDateFormat.html
知识点:
current_timestamp: 获取时间原点到现在的秒/毫秒,底层自动转换方便查看的日期格式 常用 to_date: 字符串格式时间戳转日期(年月日) current_date: 获取当前日期(年月日) 常用 year: 获取指定日期时间中的年 常用 month:获取指定日期时间中的月 常用 day:获取指定日期时间中的日 常用 hour:获取指定日期时间中的时 minute:获取指定日期时间中的分 second:获取指定日期时间中的秒 dayofmonth: 获取指定日期时间中的月中第几天 dayofweek:获取指定日期时间中的周中第几天 quarter:获取指定日期时间中的所属季度 weekofyear:获取指定日期时间中的年中第几周 datediff: 获取两个指定时间的差值 常用 date_add: 在指定日期时间上加几天 常用 date_sub: 在指定日期时间上减几天 unix_timestamp: 获取unix时间戳(时间原点到现在的秒/毫秒) 注意: 可以使用yyyyMMdd HH:mm:ss进行格式化转换 from_unixtime: 把unix时间戳转换为日期格式的时间 注意: 如果传入的参数是0,获取的是时间原点1970-01-01 00:00:00
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
示例:
select `current_date`(), -- 获取当前的日期 `current_timestamp`(); -- 获取当前的日期时间 -- to_date:将字符串内容转成日期对象 select to_date("2024-04-25"); select to_date("2024-04-25 16:39:30"); -- 年月日时分秒分别获取 select year("2024-04-25 16:39:30") as my_year, month("2024-04-25 16:39:30") as my_month, day("2024-04-25 16:39:30") as my_day, dayofweek("2024-04-25 16:39:30") as dw1, -- 返回值是5。因为周日是1,周日 周一 周二 ... 周六 dayofweek("2024-04-28 16:39:30") as dw2, -- 返回值是1。因为周日是1,周日 周一 周二 ... 周六 hour("2024-04-25 16:39:30") as my_hour, minute("2024-04-25 16:39:30") as my_minute, second("2024-04-25 16:39:30") as my_second; -- 日期时间的加减 /* datediff(大的日期,小的日期):计算两个日期的天差值 */ select datediff("2024-04-24 16:39:30","2024-04-25 16:39:30") as `差值1`, -- 去公司里面不要用中文 datediff("2024-04-24 16:39:10","2024-04-25 16:39:30") as `差值2`, -- 去公司里面不要用中文 datediff("2024-03-25 16:39:10","2024-04-25 16:39:30") as `差值3`, -- 去公司里面不要用中文 datediff("2023-03-25 16:39:10","2024-04-25 16:39:30") as `差值4`, -- 去公司里面不要用中文 date_add("2024-04-25 16:39:30",1) as add1, date_add("2024-04-25 16:39:30",-1) as add2, date_sub("2024-04-25 16:39:30",1) as sub1, date_sub("2024-04-25 16:39:30",-1) as sub2; -- unix_timestamp:获取当前的时间戳 select unix_timestamp(),`current_timestamp`(); -- from_unixtime:将时间戳转成日期对象 select from_unixtime(1714035105) ,from_utc_timestamp(1714035105,"PRC"); -- (了解)需求:将这个时间日期4/25/2024 17:08:20变成中国喜欢用的。2024-04-25 17:08:20 -- 旧的日期时间 -> 时间戳 -> 新格式的日期时间 describe function extended unix_timestamp; describe function extended from_unixtime; select unix_timestamp("4/25/2024 17:08:20","M/dd/yyyy HH:mm:ss"),-- 旧的日期时间 -> 时间戳 from_unixtime(unix_timestamp("4/25/2024 17:08:20","M/dd/yyyy HH:mm:ss"),"yyyy-MM-dd HH:mm:ss") -- 时间戳 -> 新格式的日期时间
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
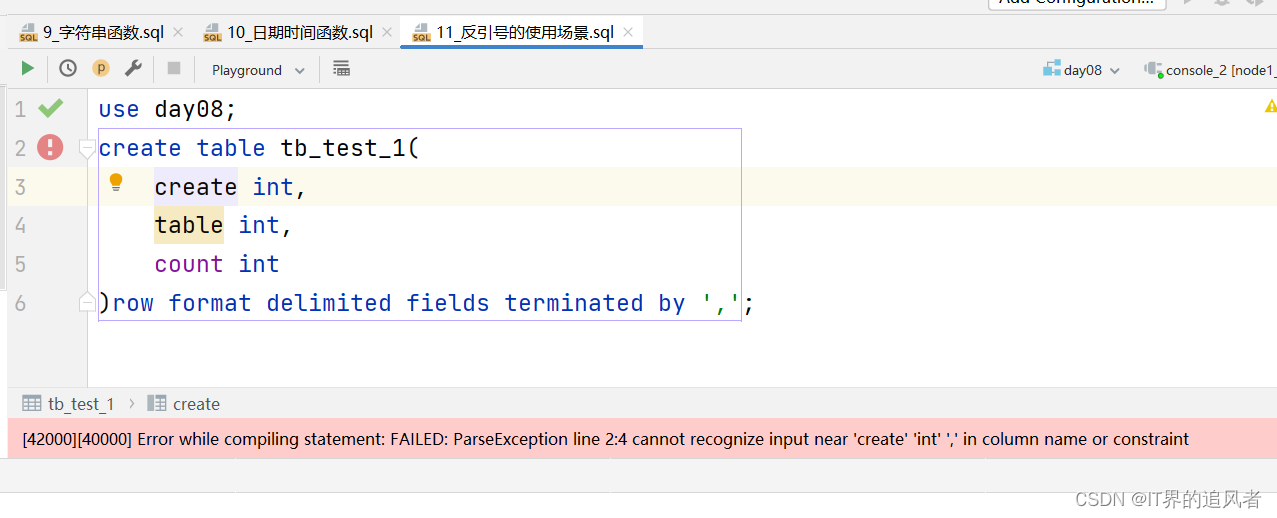
原因: 建表的时候,字段名称或者表名称最好不要和hive中的关键字(系统内部自己用的,例如:create、count、sum、max等)重名
解决办法:
1- 推荐取个不一样的名词
2- 加上反引号``
- 1
- 2
- 3
- 4
use day08;
create table tb_test_1(
`create` int,
`table` int,
count int
)row format delimited fields terminated by ',';
select count(count) from tb_test_1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
8、条件函数
知识点:
if(参数1,参数2,参数3): if(判断条件,条件成立(true)的时候执行,条件不成立(false)的时候执行)。if可以嵌套
case...when.then...end: 分条件判断
使用推荐: 如果判断比较简单推荐使用if,如果判断条件很多推荐使用case when
isnull(数据) : 判断是否为空。如果为空(null值)返回true;否则返回false。
注意: null才是空值。空字符串不是空值
isnotnull(数据): 判断是否不为空。如果为空(null值)返回false;否则返回true。
nvl(数据,参数2): 返回里面第一个不为空的值
coalesce(参数1,参数2...): 返回里面第一个不为空的值
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
示例:
-- if(判断条件,条件成立(true)的时候执行,条件不成立(false)的时候执行)。if可以嵌套 select if(20>18,"可以去上网","回家写作业"), if(10>18,"可以去上网","回家写作业"), if(10>18,null,"回家写作业"), if(10>18,"可以去上网",null), if(10>18,"可以去上网",if(10<15,"写小学作业","写初中作业")); -- if嵌套 -- isnull和isnotnull:返回true和false select isnull(null), isnull("hello"), isnull(123), isnotnull("hello"), isnotnull(null); -- nvl(字段名,默认值) select nvl("hello",123), nvl(null,"world"), nvl(19.99,123); -- coalesce(字段1,字段2,....):返回参数列表中第一个不为空null的值 select coalesce("hello","world",123,9.99), coalesce(null,"world",123,9.99), coalesce(null,null,123,9.99), coalesce(null,null,null,9.99), coalesce(null,"world",null,9.99); -- case when select 1 as today, case when 4==1 then "周一" when 4==2 then "周二" when 4==3 then "周三" else "休息" end, case 4 when 1 then "周一" when 2 then "周二" when 3 then "周三" else "休息" end;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
9、其他函数
-- hash:使用场景,用来对hive数据进行完整性校验。
select hash("world"); -- 113318802
-- md5
select md5("world"); -- 7d793037a0760186574b0282f2f435e7
select md5(concat_ws("_",cast(1 as string),"zhangshan",cast(18 as string),cast(50000 as string),"广州市"));
select current_user(),current_database(),version();
select sha2("allen",224);
select sha2("allen",512);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
10、堆内存错误
报错:
Error while processing statement: FAILED: Execution Error, return code -101 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. Java heap space
解决方案: 在node1上面操作即可
方式1: 找到/export/server/hive/conf/hive-env.sh,添加以下内容
export HADOOP_HEAPSIZE=2048
- 1
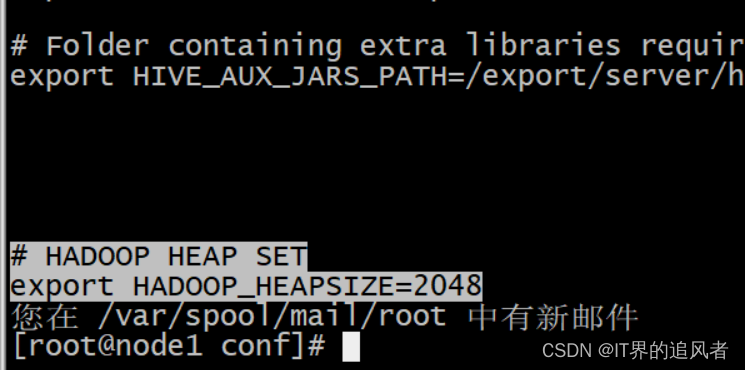
方式2: 找到hive-site.xml添加以下内容
<!-- hive堆内存-->
<property>
<name>hive.heapsize</name>
<value>2048</value>
</property>
- 1
- 2
- 3
- 4
- 5
修改完以后,先把Hadoop和Hive进程全部关掉。先启动Hadoop,再启动Hive。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小舞很执着/article/detail/909732
推荐阅读
相关标签

