
- 1Hive、SQL Server、MySQL 和 PostgreSQL 之间的对比区别_sql server和hive
- 2靠谱的副业推荐:适合上班摸鱼做的八种副业_上班摸鱼的副业
- 3git push origin HEAD:<name-of-remote-branch>报错_git push origin head:
- 4MySQL:数据类型&表的基础操作
- 5软考高级系统架构设计师系列之:快速掌握知识产权与标准化核心知识点_系统架构设计师知识产权
- 6ArcGIS制图技巧_arcgis制图经纬网
- 7数据库数据恢复—Sql Server数据库文件丢失如何恢复数据?_sqlserver数据库恢复
- 8[大数据汇总]--spark、hadoop未来发展趋势解读_spark与hadoop发展趋势对比折线图
- 9Android Recovery 的流程分析_recovery 动画界面加载流程
- 10蛋白组学资讯:百趣协助,非小细胞癌转移机制新解_整合非靶标和靶标代谢组研究芪玉三龙汤抑制非小细胞肺癌作用机理
Llama3.1系列模型正式开源,最大405B,闭源模型的统治时代将迎来结束?
赞
踩
Meta开源了Llama3.1系列模型,最大参数规模为405B,开源也是好起来了,榜单指标直逼GPT4-o。
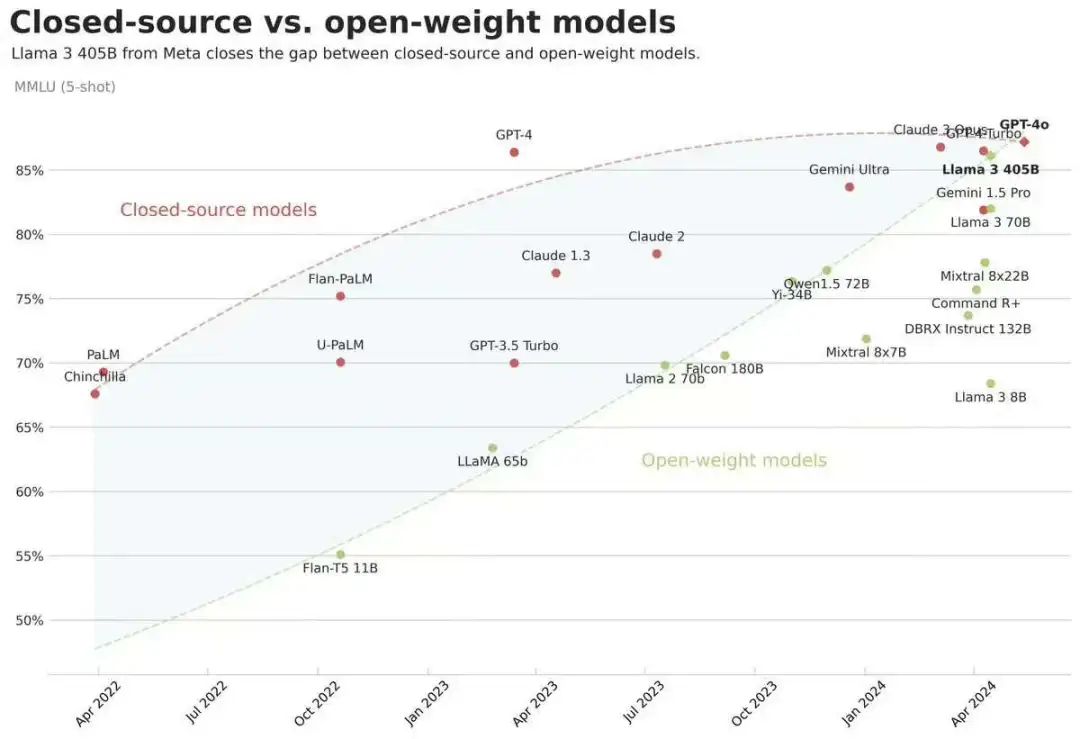
开源追上闭源模型不再是梦!Llama系列模型确实是开源界的头部,真金白银砸出来的就是不一样。
不过现在大家也都知道,榜单效果和真实使用效果也不是完全正比的,后面看看对lmsys战榜单,还有大家的实测效果吧!
HF: https://huggingface.co/collections/meta-llama/llama-31-669fc079a0c406a149a5738f
- 1
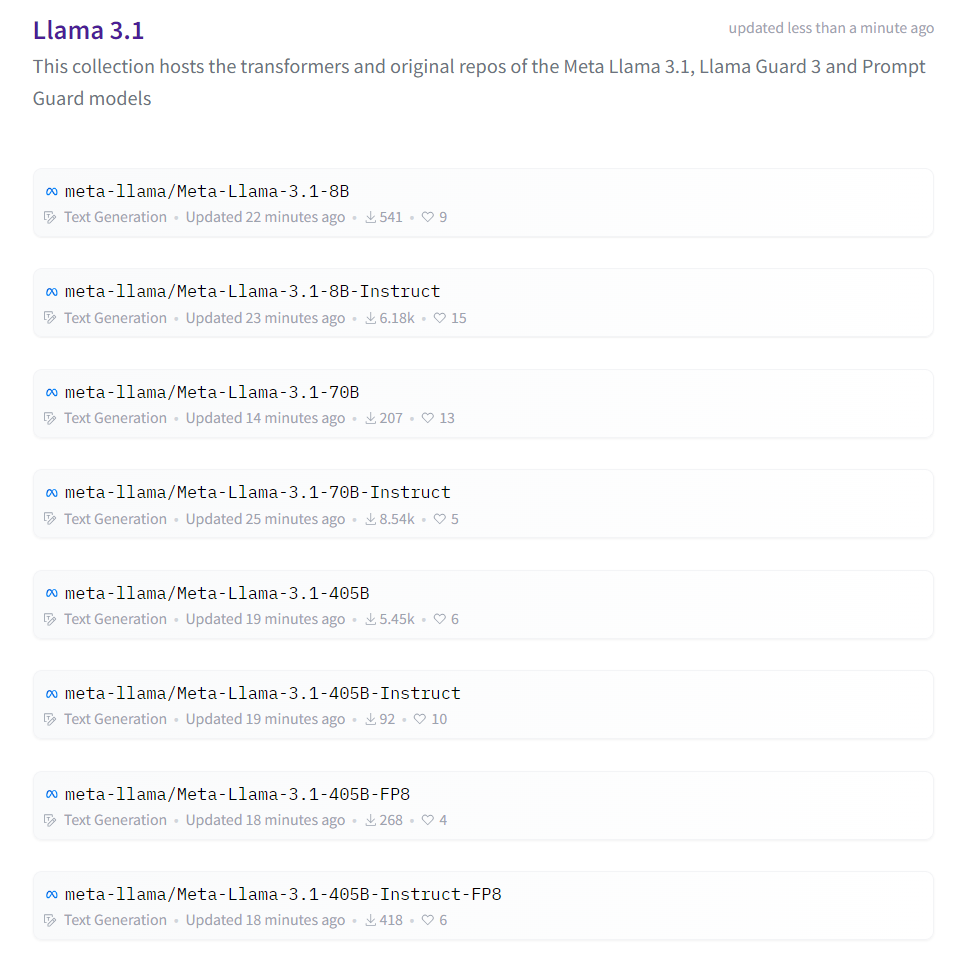
Llama3.1系列模型细节
- 15T Tokens预训练;占比知识50、数学25、代码17、语言8
- 8B、70B、405B的模型均采用GQA;
- 405B模型,有126层,词表大小128256,隐藏层维度16384;8B和70B模型与llama3一样就不介绍了;
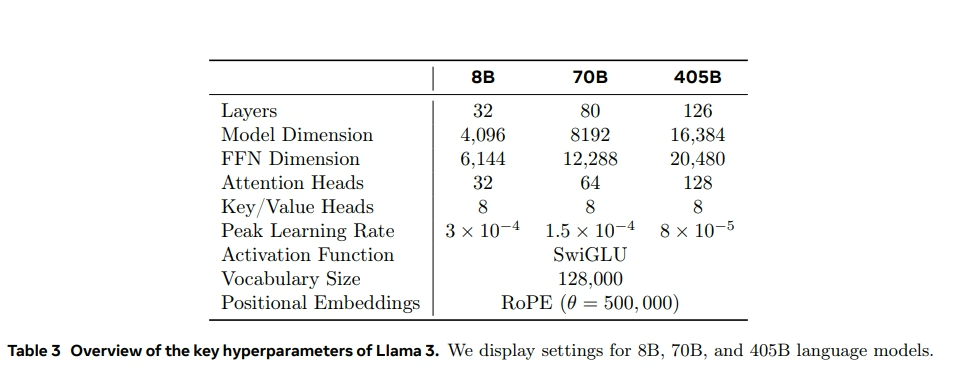
- 支持上下文长度128k;
- 支持多语言,包括英语、法语、德语、印地语、意大利语、葡萄牙语、西班牙语和泰语;当然其他语言也可以使用,只是没有针对性进行安全测试。
- instruct模型微调使用了公开可用的指令数据集,以及超过2500万的合成数据
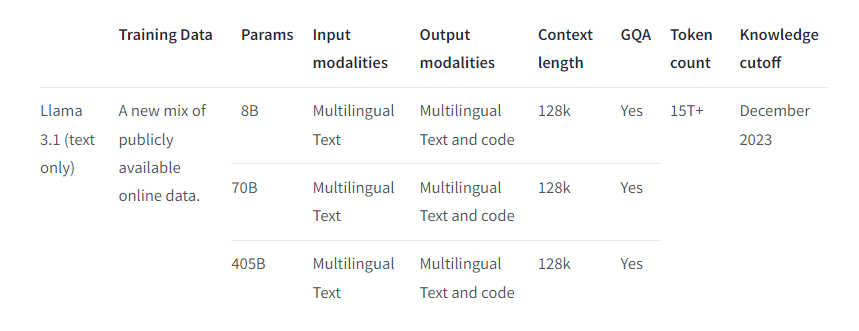
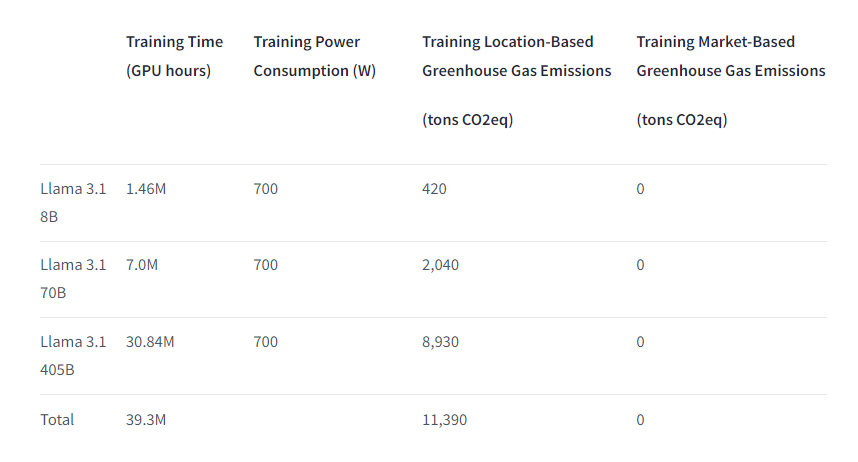
- 8B模型预训练用了146万 GPU小时,70B模型预训练用了700万 GPU小时,405B模型预训练用了3084万 GPU小时;
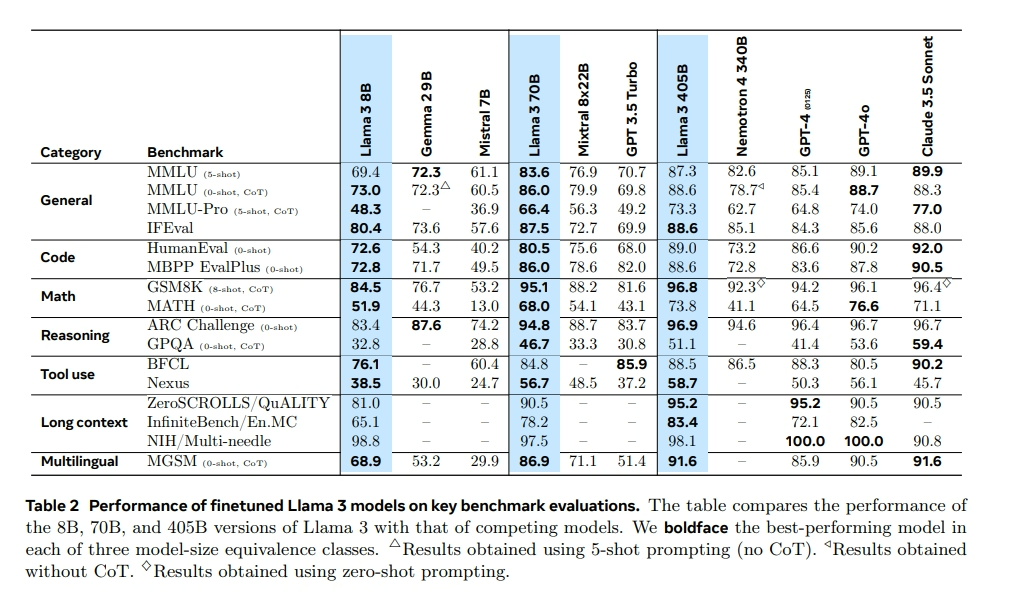
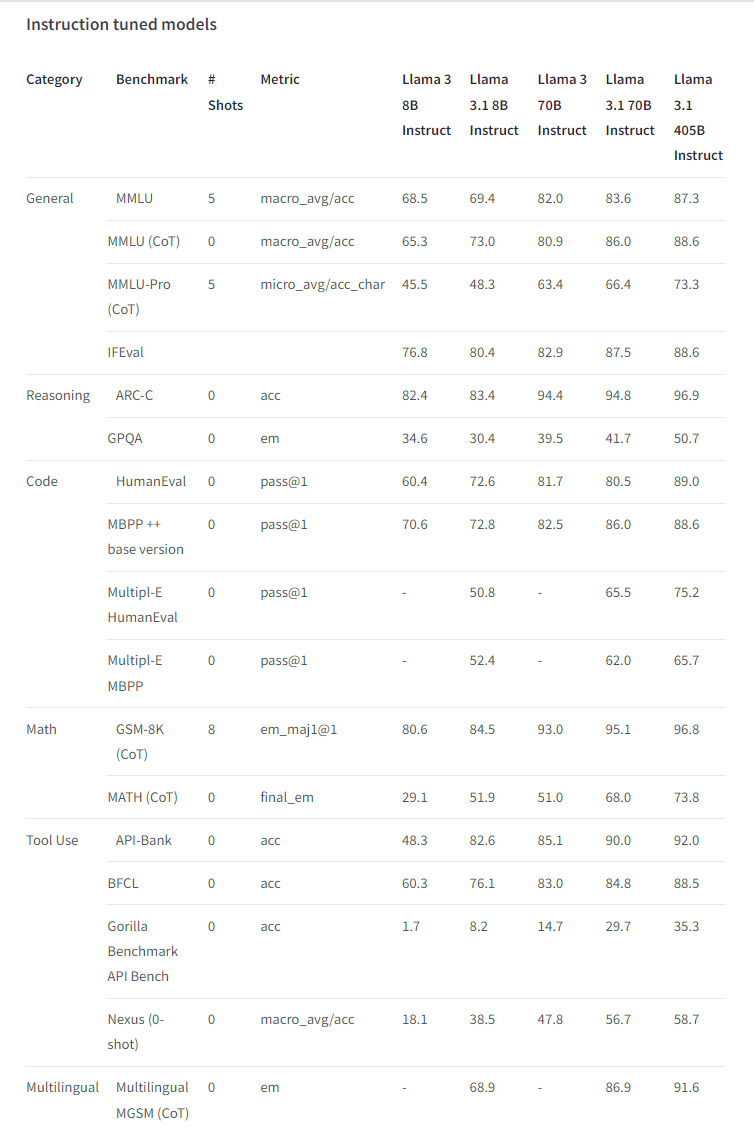
Llama3.1系列模型效果
Llama3.1系列的8B和70B模型的效果,普遍好于Llama3系列模型。尤其是Instruct模型提升较高,特别是通用、代码、数学和工具使用四个方面,大幅提高;额外添加的合成数据,应该是关键。
模型使用
Llama3-405B模型整体结构没有变化,所有直接transformers走起。

当然为了加速或者节省显存,也可以vllm、ollama、llamacpp等框架来加载量化模型,这里就不详细介绍了。
写在最后
不过405B模型太大了,部署成本太高了,即使效果很棒,但有多少企业有资格玩一把呢?
个人玩家就更不用说了,光模型大小就820G,别说有没有显卡,也许都没有820G磁盘空间下载都没资格,太难了!
不过后面各大平台(阿里、百度、SiliconFlow)应该会有调用API,到时候体验效果也不费事儿。
又有新工作可做了,应该很快会有Chinese-Llama-3.1工作出来,没资源的小伙伴,等就完事儿了。
如何学习AI大模型?
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

