
- 1fpga与lvds_基于fpga的lvds接收电路设计
- 2Unity中使用xLua基础
- 3binlog2sql的安装及使用_binlog2sql安装
- 4「栈」实现LIFO栈(先进后出栈|堆栈|stack)的功能 / 手撕数据结构(C++)
- 5鸿蒙模拟器(HarmonyOS Emulator)Beta申请审核流程_鸿蒙模拟器(harmonyos emulator)beta活动申请
- 6SpringBoot3:轻松使用Jasypt实现配置文件信息加密_springboot jasypt
- 7【记录】Apache DolphinScheduler在调度Flink1.12.2时的坑_apache dolphinscheduler flink
- 8failed (13: Permission denied) 解决Nginx由于权限导致大文件不能上传的问题
- 9【机器视觉】20个视觉应用项目展示,机器代替人眼来做测量和判断!
- 10Android 14 transtion 动画流程_ontransitionready
HDFS 读写数据流程_hdfs的数据读取流程图
赞
踩
优质博文:IT-BLOG-CN
一、HDFS 写数据流程
HDFS 文件写入流程图如下:三个模块(客户端、NameNode、DataNode)
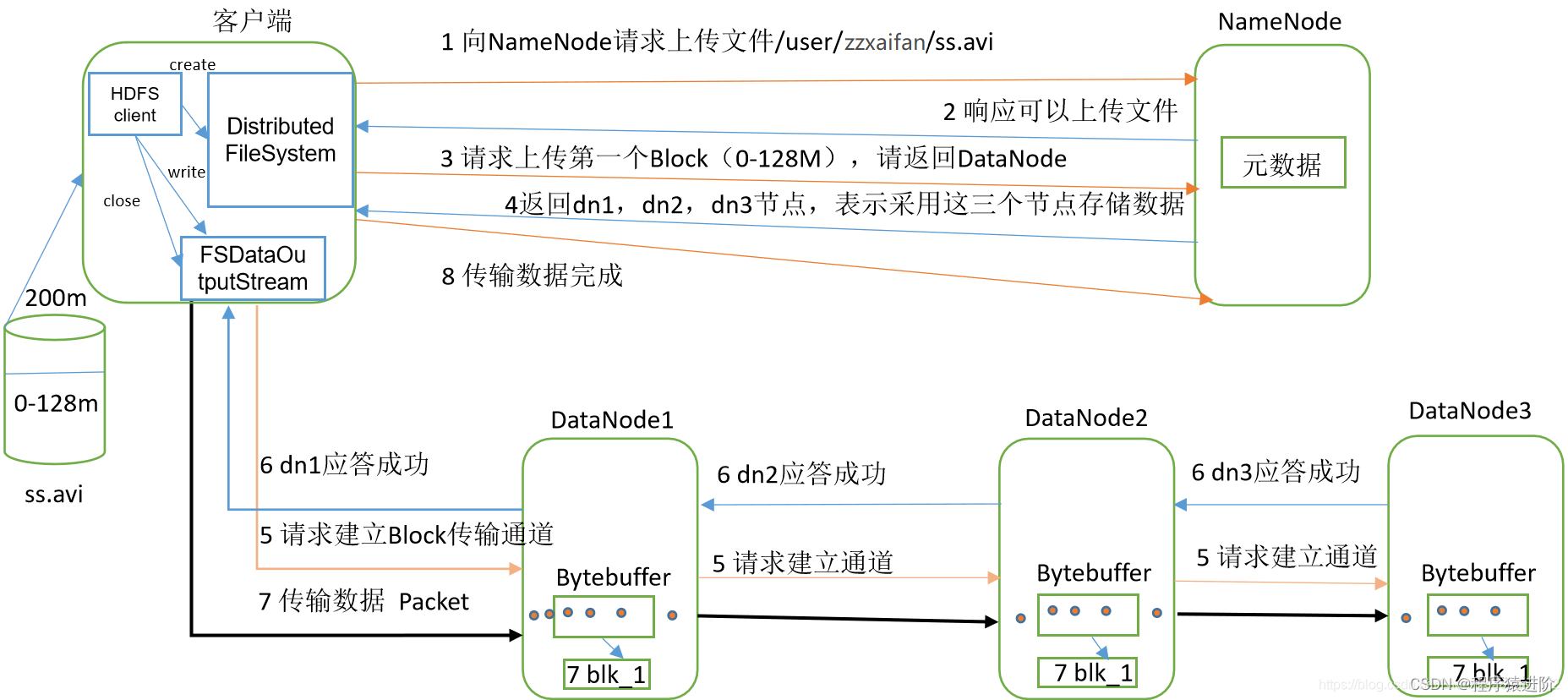
【1】校验: 客户端通过 DistributedFileSystem 模块向 NameNode 请求上传文件,NameNode 会检查目标文件是否已经存在,父目录是否存在。
【2】响应: NameNode 返回是否可以上传的信号。
【3】请求 NameNode: 客户端对上传的数据根据块进行切片,并请求第一块 Block 上传到哪几个 DataNode 服务器上。
【4】响应 DataNode节点信息: NameNode 根据副本数等信息返回可上传的DataNode节点,例如这里的 dn1,dn2,dn3。
【5】建立通道: 客户端通过 FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
【6】DataNode 响应 Client: dn1、dn2、dn3逐级应答客户端。
【7】上传数据到DataNode: 客户端开始往 dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以 Packet为单位,dn1收到一个 Packet就会传给 dn2,dn2传给 dn3;dn1每传一个 packet会放入一个应答队列等待应答。
【8】通知 NameNode上传完成: 当一个 Block传输完成之后,客户端再次请求 NameNode上传第二个 Block的服务器。
【9】关闭输入输出流。
二、网络拓扑-节点距离计算
在 HDFS写数据的过程中,NameNode会选择距离最近的 DataNode接收数据。那么这个最近距离怎么计算呢?
节点距离: 两个节点到达最近的共同祖先的距离总和。
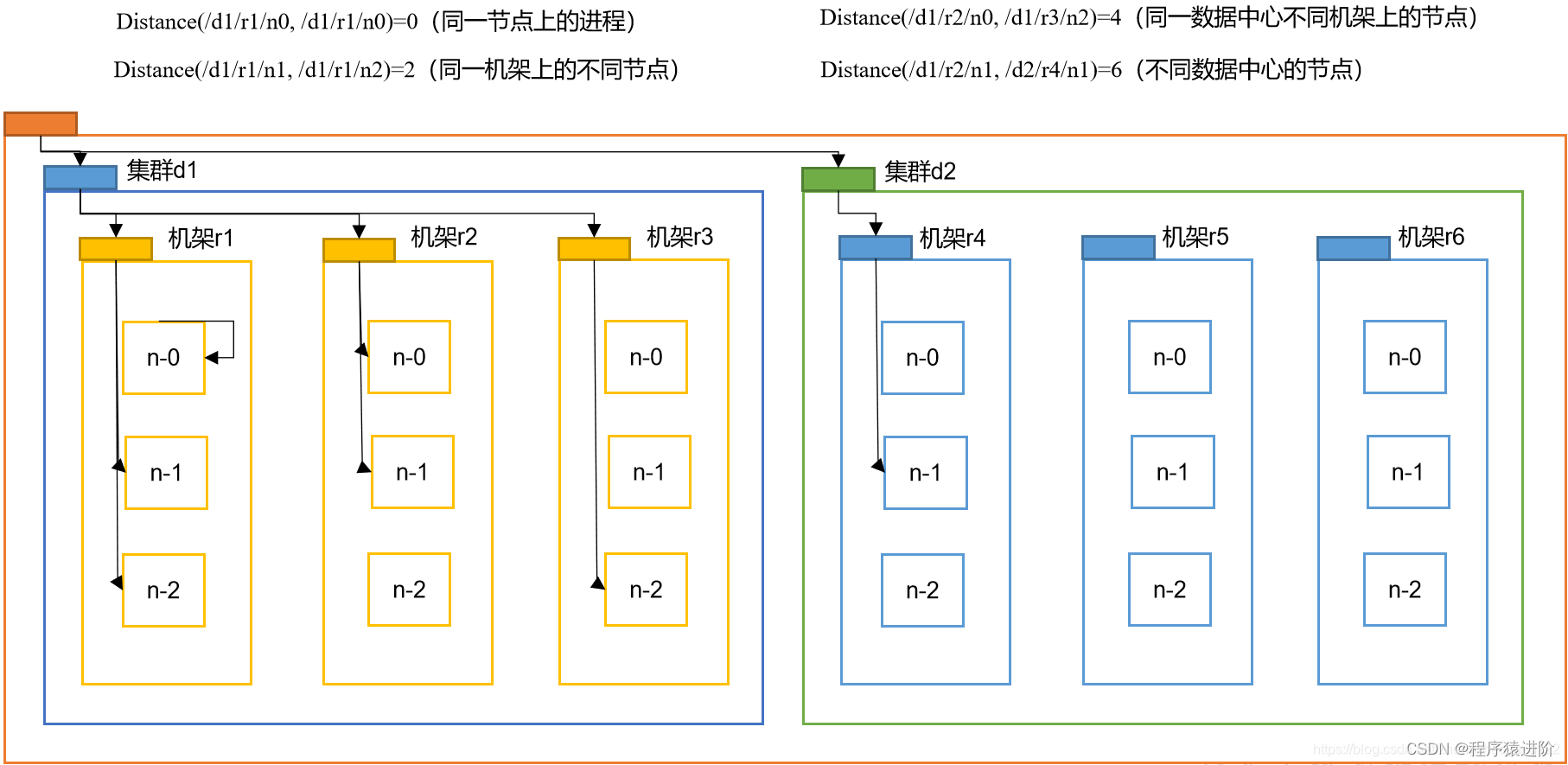
例如,假设有数据中心d1 机架r1 中的节点 n1。该节点可以表示为/d1/r1/n1。利用这种标记,这里给出四种距离描述,如上图所示:大家算一算每两个节点之间的距离:每一个线表示1,例如 11 到 4距离为3。so easy
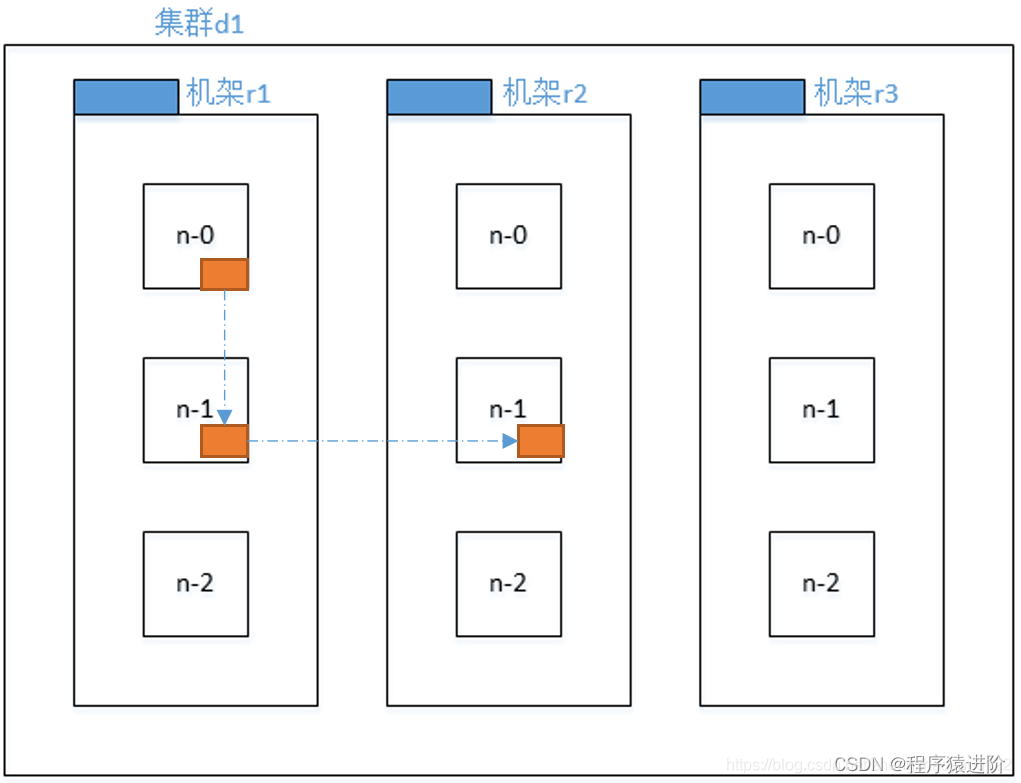
三、机架感知
【官方说明】:【链接】
对于常见情况,当复制因子为3时,HDFS的放置策略是将一个副本放在本地机架中的一个节点上,另一个放在本地机架中的另一个节点上,最后一个放在不同机架中的另一个节点上。
【1】第一个副本在 Client所处的节点上。如果客户端在集群外,随机选一个。
【2】第二个副本和第一个副本位于相同机架,随机节点。
【3】第三个副本位于不同机架,随机节点。
四、HDFS 读数据流程
HDFS的读数据流程,如下图所示:
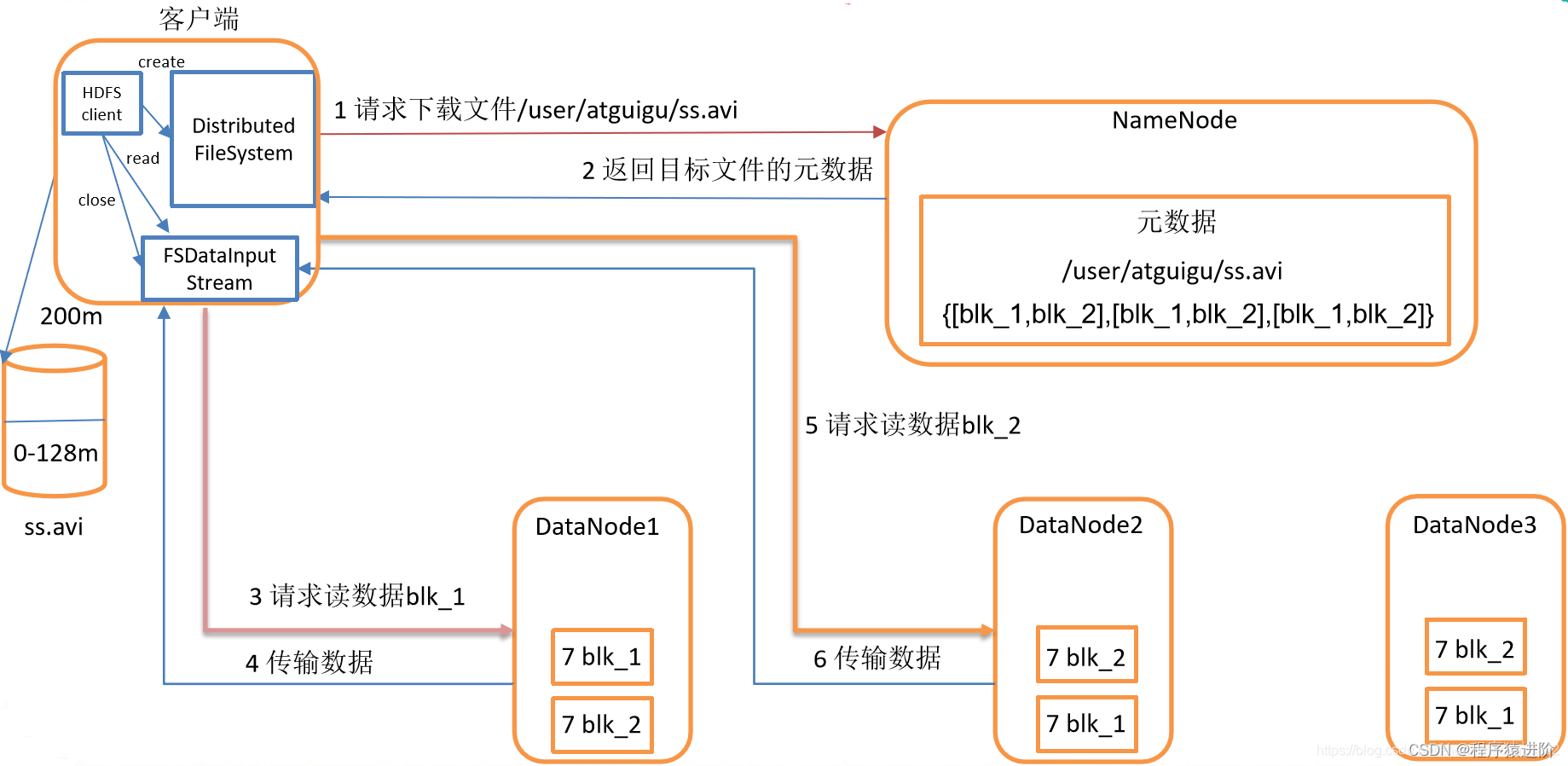
【1】客户端通过 Distributed FileSystem向 NameNode请求下载文件,NameNode通过查询元数据,找到文件块所在的DataNode地址进行返回。
【2】挑选一台 DataNode(就近原则,然后随机)服务器,请求读取数据。当第一次读取完成之后,才进行第二次块的读取。
【3】DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以 Packet为单位来做校验)。
【4】客户端以 Packet为单位接收,先在本地缓存,然后写入目标文件。

