
热门标签
热门文章
- 1跟我学Python图像处理丨图像分类原理与案例_图像分类案例
- 2zabbix监控交换机_zabbix添加锐捷交换机
- 3双目项目实战---测距(获取三维坐标和深度信息)_双目相机求解三维坐标点
- 4微信小程序访问webservice(wsdl)+ axis2发布服务端(Java)
- 5chromedriver和selenium的下载以及安装教程(114/116/117.....121版本)_chromedriver 121
- 6Window系统命令行调用控制面板程序_programs|and|features
- 701-Node.js 简史_nodejs历史版本
- 8【STM32】FSMC—扩展外部 SRAM 初步使用 1_stm32 外接 ram
- 9python爬虫爬取淘宝商品并保存至mongodb数据库_tbsearch?refpid=mm_26632258_3504122_32554087
- 10OpenWrt 软路由IPv6 DDNS Socat 端口映射_openwrt socat
当前位置: article > 正文
yolov5 提速多GPU训练显存低的问题_yolov5在不同显卡下消耗的gpu有差异
作者:小蓝xlanll | 2024-02-18 00:21:30
赞
踩
yolov5在不同显卡下消耗的gpu有差异
yolov5多GPU训练显存低
修改前:
按照配置,在train.py配置如下:

运行 python train.py 后nvidia-smi 显示显存占用如下:
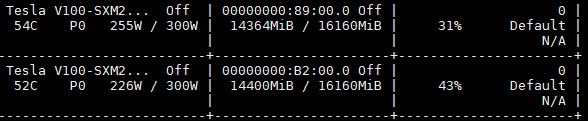
修改后
参考yolov5 官方中的issue中,有人提到的分布式多进程的方法:
在yolov5运行的虚拟环境下,找到torch的distributed 的环境:比如我的在conda3/envs/rcnn/lib/python3.6/site-packages/torch/distributed/;
在distributed文件下,新建多进程的脚本,命名为yolov5_launch.py:
import sys import subprocess import os from argparse import ArgumentParser, REMAINDER def parse_args(): """ Helper function parsing the command line options @retval ArgumentParser """ parser = ArgumentParser(description="PyTorch distributed training launch " "helper utility that will spawn up " "multiple distributed processes") # Optional arguments for the launch helper parser.add_argument("--nnodes", type=int, default=1, help="The number of nodes to use for distributed " "training") parser.add_argument("--node_rank", type=int, default=0, help="The rank of the node for multi-node distributed " "training") parser.add_argument("--nproc_per_node", type=int, default=2, help="The number of processes to launch on each node, " "for GPU training, this is recommended to be set " "to the number of GPUs in your system so that " "each process can be bound to a single GPU.")#修改成你对应GPU的个数 parser.add_argument("--master_addr", default="127.0.0.1", type=str, help="Master node (rank 0)'s address, should be either " "the IP address or the hostname of node 0, for " "single node multi-proc training, the " "--master_addr can simply be 127.0.0.1") parser.add_argument("--master_port", default=29528, type=int, help="Master node (rank 0)'s free port that needs to " "be used for communication during distributed " "training") parser.add_argument("--use_env", default=False, action="store_true", help="Use environment variable to pass " "'local rank'. For legacy reasons, the default value is False. " "If set to True, the script will not pass " "--local_rank as argument, and will instead set LOCAL_RANK.") parser.add_argument("-m", "--module", default=False, action="store_true", help="Changes each process to interpret the launch script " "as a python module, executing with the same behavior as" "'python -m'.") parser.add_argument("--no_python", default=False, action="store_true", help="Do not prepend the training script with \"python\" - just exec " "it directly. Useful when the script is not a Python script.") # # positional # parser.add_argument("training_script", type=str,default=r"train,py" # help="The full path to the single GPU training " # "program/script to be launched in parallel, " # "followed by all the arguments for the " # "training script") # # rest from the training program # parser.add_argument('training_script_args', nargs=REMAINDER) return parser.parse_args() def main(): args = parse_args() args.training_script = r"yolov5-master/train.py"#修改成你要训练的train.py的绝对路径 # world size in terms of number of processes dist_world_size = args.nproc_per_node * args.nnodes # set PyTorch distributed related environmental variables current_env = os.environ.copy() current_env["MASTER_ADDR"] = args.master_addr current_env["MASTER_PORT"] = str(args.master_port) current_env["WORLD_SIZE"] = str(dist_world_size) processes = [] if 'OMP_NUM_THREADS' not in os.environ and args.nproc_per_node > 1: current_env["OMP_NUM_THREADS"] = str(1) print("*****************************************\n" "Setting OMP_NUM_THREADS environment variable for each process " "to be {} in default, to avoid your system being overloaded, " "please further tune the variable for optimal performance in " "your application as needed. \n" "*****************************************".format(current_env["OMP_NUM_THREADS"])) for local_rank in range(0, args.nproc_per_node): # each process's rank dist_rank = args.nproc_per_node * args.node_rank + local_rank current_env["RANK"] = str(dist_rank) current_env["LOCAL_RANK"] = str(local_rank) # spawn the processes with_python = not args.no_python cmd = [] if with_python: cmd = [sys.executable, "-u"] if args.module: cmd.append("-m") else: if not args.use_env: raise ValueError("When using the '--no_python' flag, you must also set the '--use_env' flag.") if args.module: raise ValueError("Don't use both the '--no_python' flag and the '--module' flag at the same time.") cmd.append(args.training_script) if not args.use_env: cmd.append("--local_rank={}".format(local_rank)) # cmd.extend(args.training_script_args) process = subprocess.Popen(cmd, env=current_env) processes.append(process) for process in processes: process.wait() if process.returncode != 0: raise subprocess.CalledProcessError(returncode=process.returncode, cmd=cmd) if __name__ == "__main__": # import os # os.environ['CUDA_VISIBLE_DEVICES'] = "0,1" main()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
运行上述脚本: python yolov5_launch.py

显存占用超过80%,注意这里可以将train.py 配置里面的batch_size 调大;
另外一种方法
在网上看到另外一种方法,是不用在distributed文件夹下面新建文件这样麻烦,在
python -m torch.distributed.launch --nproc_per_node 2 train.py --batch-size 64 --data data/Allcls_one.yaml --weights weights/yolov5l.pt --cfg models/yolov5l_1cls.yaml --epochs 1 --device 0,1
- 1
训练时,在python后面加上-m torch.distributed.launch --nproc_per_node (修改成你的gpu的个数)再运行train.py 再后面加上各种配置文件
这个方法亲测可行,比第一种方法简单有效!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小蓝xlanll/article/detail/102735
推荐阅读
相关标签

