
- 1鸿蒙HarmonyOS开发实战—多媒体开发(音频开发 一)_鸿蒙播放声音 开发
- 2用UGUI制作HUD_unity hud ugui
- 3Gen-AI 的知识图和分析(无需图数据库)_gen ai
- 4用于三维点云语义分割的标注工具和城市数据集
- 5【Unity小技巧】可靠的相机抖动及如何同时处理多个震动(附项目源码)_cinemachine相机抖动
- 6QtCreator不识别安卓手机解决_qtscrcpy连不上手机
- 7Microsoft .NET框架糅合各种编程语言,开创Web新时代_.net语言合作
- 82023新年倒计时(付源码)_pycharm2023倒计时
- 9windows11内置微软copilot国内能用吗?一切来看下!_win 11 copilot登录不了
- 10caffe层解析之softmaxwithloss层_caffe softmaxwithloss
开源大模型FLM-101B:训练成本最低的超100B参数大模型
赞
踩

深度学习自然语言处理 原创
作者:Winnie
大语言模型(LLM)在诸多领域都取得了瞩目的成就,然而,也存在两个主要的挑战:
训练成本极高,通常只有少数几家大公司才能负担得起。
现行的评估基准主要依赖知识评估(如MMLU和C-Eval)以及NLP任务评估,但这种方式存在局限性,并且容易受到数据污染的影响。
近期,一支来自中国的研究团队正是针对这些问题提出了解决方案,他们推出了FLM-101B模型及其配套的训练策略。FLM-101B不仅大幅降低了训练成本,而且其性能表现仍然非常出色,它是目前训练成本最低的100B+ LLM。
下面我们就来深入探讨他们是如何实现这一目标的吧!

Paper: FLM-101B: An Open LLM and How to Train It with $100K Budgets
Link: https://arxiv.org/pdf/2309.03852.pdf
Model: https://huggingface.co/CofeAI/FLM-101B进NLP群—>加入NLP交流群
摘要
本篇研究的两大核心亮点为:
增长策略:该策略赋予了LLM一个独特的训练方式,它可以从较小规模动态增长到较大规模,而不仅仅是在一开始就确定其大小。这不仅能够保持在初期阶段已学到的知识,更重要的是,它大大降低了整体的计算成本。
IQ评估基准:该团队还提出了一个新的评估标准IQ benchmark,包含了符号映射、规则理解、模式挖掘和抗干扰能力这四个关键维度,从多方面对LLM的能力进行了全面深入的评估。
增长策略详解
与独立训练不同规模的模型的常规做法不同,在FLM-101B的训练过程中该项目团队按照16B、51B和101B参数的顺序连续训练了三个模型,每个模型都从其较小的前身那里继承了知识。
下图揭示了利用增长策略在三种典型场景中实施LLM训练的计算成本变化。在这里,我们依据一个基本原则:LLM的FLOPs与参数数量近似成正比,使我们可以通过观察模型参数变化曲线下的面积来估算训练的计算成本。
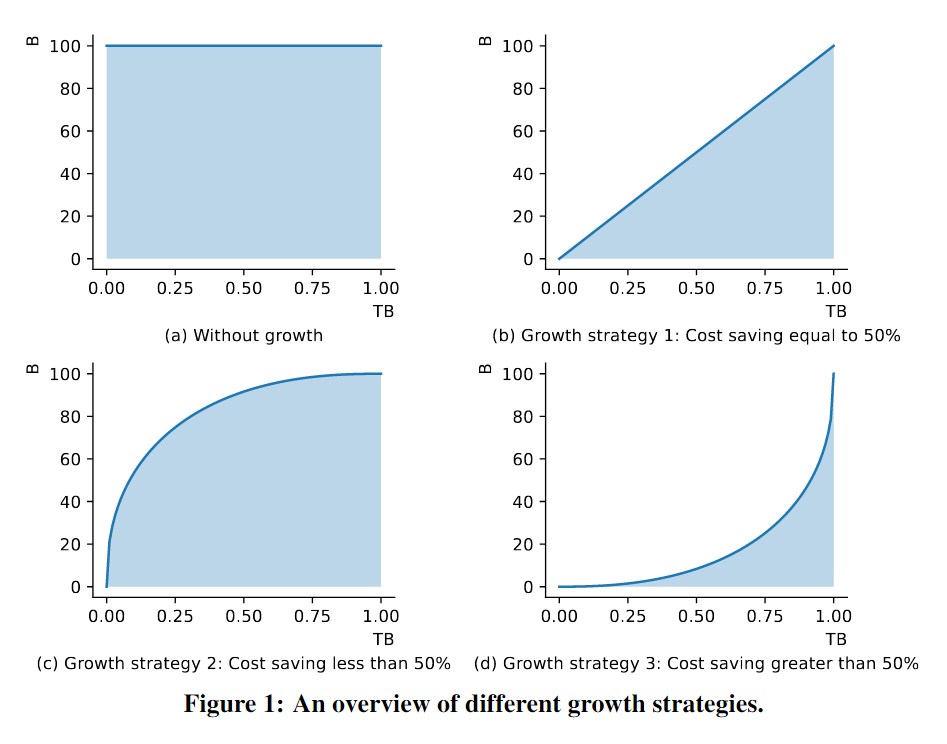
图(a) 一个标准的训练策略,其中没有实施模型的动态增长,从而导致训练计算成本相对较高。
图(b) 一个线性增长策略的应用,其结果是计算成本得以减少近50%。
图(c) 一个适度的增长策略,虽然它未能将成本降低到50%,但仍然实现了可观的成本节约。
图(d) 一种更为积极的增长策略,它成功地将计算成本降低了超过50%,揭示了这种策略在减少训练成本方面的巨大潜力。
在LLM增长前后,模型始终给出任意输入的一致输出。这个属性对于知识继承和训练稳定性都是有利的。为了适应多节点3D并行框架,团队通过离线扩展模型结构,并在下一个阶段开始时重新加载检查点来实现这一点。
增长策略具体设置
规划模型增长是一个需要权衡不同大小模型固有优缺点的过程:较小的模型在计算每个训练步骤时更快,能够更快地消耗训练数据来获取更广泛的常识知识;反之,较大的模型更擅长于减少每步的损失,显示出对细微的语言模式有更深的理解,该团队使用245.37B个令牌来训练16B模型,39.64B个令牌来训练51B模型,以及26.54B个令牌来训练101B模型。不同大小的每天数十亿令牌的使用情况详见下表。
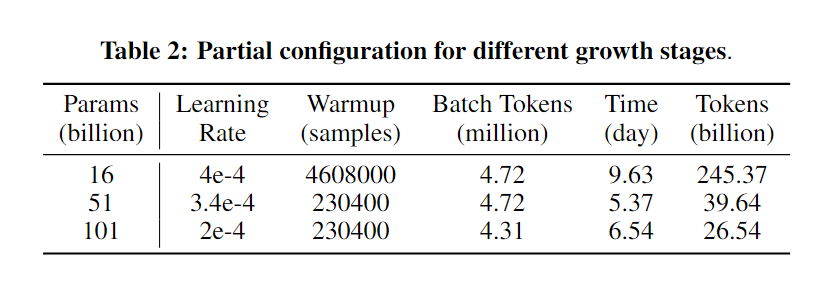
在这种增长时间表下,101B模型的总时间成本是21.54天,这比从头开始训练一个101B模型(需要47.64天)节省了54.8%的时间,相当于2.2倍的加速。
不同阶段的性能评估
研究成员对FLM在所有阶段(包括16B、51B和101B)的性能进行了评估。每个阶段的训练数据分别是0.246TB、0.04TB和0.026TB。下表呈现了各阶段FLM模型的表现。
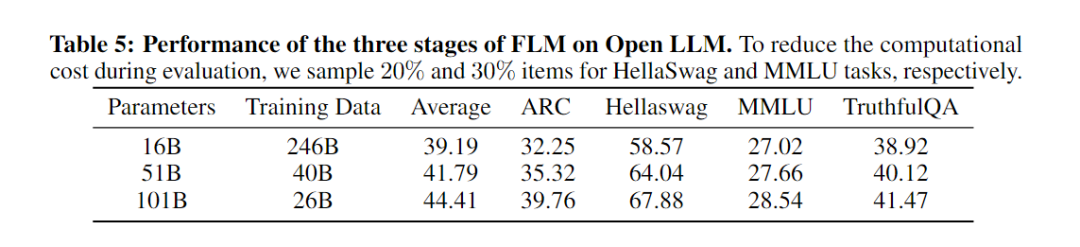
结果显示,FLM的性能确实随着模型大小的增加而提高,这符合预期。FLM-101B在几乎所有任务上都实现了最佳性能,这意味着模型能够在每次增长后从先前的阶段继承知识。他们还发现101B模型在使用较少样本的情况下比51B模型有更显著的性能提升。这表明模型在增长后的训练中成功地加入了新的权重,并在损失较低时利用了模型大小的优势。有趣的是,ARC和HellaSwag的表现也持续并显著增加。因此,可以预见,随着处理更多的训练数据,FLM-101B在开放LLM上的性能将大大提高,除了在MMLU上,因为它与特定的领域有关。
FLM主要结构和其他技术细节
Backbone
选择FreeLM作为基础架构主要是为了实现高效的长序列建模,此中采用了可外推的位置嵌入(xPos)来增强模型的长度外推能力。该技术受到了RoPE原理的启发,并在旋转矩阵中引入了指数衰减来实现目标。同时,模型保留了GPT和FreeLM的变换器块设计,并采用了来自GPT-4的分词器,以支持更大的词汇量。
预训练
FLM-101B延续了FreeLM的训练策略,结合了受语言信号指导的语言建模目标和受教师信号指导的二元分类目标。但是当模型规模扩大超过16B时,它开始展示出训练不稳定的问题。为了克服这一问题,研究团队采用了一个统一的目标,它通过使用一种掩码策略和两个专用令牌来同时处理教师和语言信号。这些令牌协助将二元分类目标转化为一个语言建模格式。
在大规模的无监督文本语料库中,该模型遵循GPT系列的训练目标,即最大化token预测的可能性。FLM-101B是一个英汉双语模型,它在语言建模中将英语和汉语语料库按约53.5:46.5的比例混合。在预训练阶段,作者整合了OIG和COIG多任务教育提示数据。
在命题判断任务中,原始的FreeLM教师目标旨在最小化二元分类的交叉熵。在FLM-101B的训练过程中,这一二元分类已转化为自回归语言模型形式。具体来说,它利用两个emoji 本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/小蓝xlanll/article/detail/131285
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

