
 各位同学们,好久没写原创技术文章了,最近有些忙,所以进度很慢,给大家道个歉。
各位同学们,好久没写原创技术文章了,最近有些忙,所以进度很慢,给大家道个歉。
> 警告:本教程仅用作学习交流,请勿用作商业盈利,违者后果自负!如本文有侵犯任何组织集团公司的隐私或利益,请告知联系猪哥删除!!!
一、淘宝登录复习
前面我们已经介绍过了如何使用requests库登录淘宝,收到了很多同学的反馈和提问,猪哥感到很欣慰,同时对那些没有及时回复的同学说声抱歉!
顺便再提一下这个登录功能,代码是完全没有问题。如果你登录出现申请st码失败的错误时候,可以更换_verify_password方法中的所有请求参数。 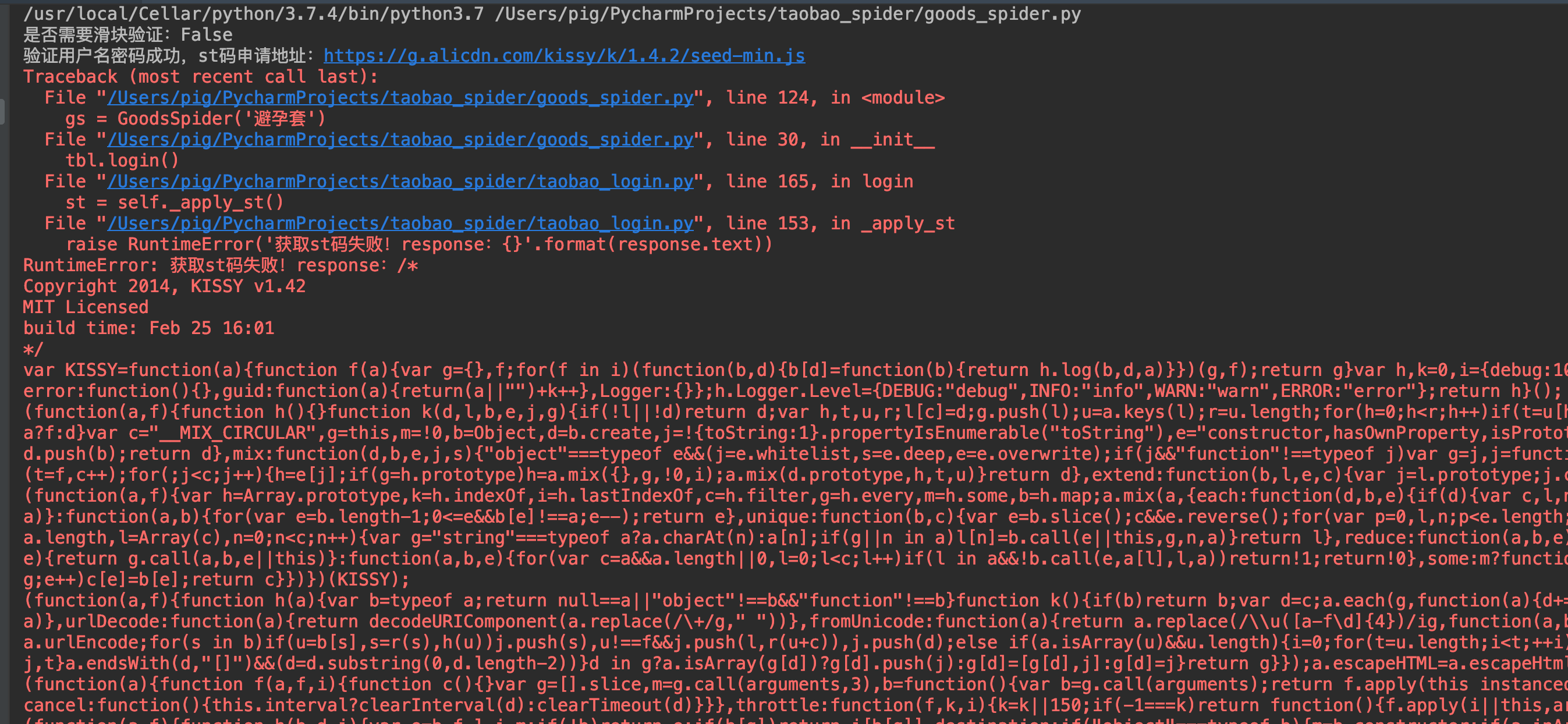
在淘宝登录2.0改进中我们增加了cookies序列化的功能,目的就是为了方便爬取淘宝数据,因为如果你同一个ip频繁登录淘宝的话可能就会触发淘宝的反扒机制!
关于淘宝登录的成功率,在猪哥实际的使用中基本都能成功,如果不成功就按上面的方法更换登录参数!
二、淘宝商品信息爬取
这篇文章主要是讲解如何爬取数据,数据的分析放在下一篇。之所以分开是因为爬取淘宝遇到的问题太多,而猪哥又打算详细再详细的为大家讲解如何爬取,所以考虑篇幅及同学吸收率方面就分两篇讲解吧!宗旨还会不变:让小白也能看得懂!
本次爬取是调用淘宝pc端搜索接口,对返回的数据进行提取、然后保存为excel文件!
看似一个简单的功能却包含了很多问题,我们来一点一点往下看吧!

