
- 1openai接口调用-如何接入openai获取 api key_获取 openai key
- 2嵌入式软件开发工程师就业发展前景怎么样?
- 3禁用el-tabs组件自带的键盘切换功能_element-plus 禁止键盘上下左右
- 4机器视觉三维点云分析系统3DPCAgent_3d点云数据测量系统架构
- 5ggplot 图像的保存_error in usemethod("grid.draw") : no applicable me
- 6120款超浪漫❤HTML5七夕情人节表白网页源码❤ HTML+CSS+JavaScript_浪漫网页
- 7Pytorch下查看各层名字及根据layers的name冻结层进行finetune训练;_model = net().cuda() for name, param in model.name
- 8《Python从入门到实践》外星人入侵学习笔记_python外星人入侵 求助 不按play键 一直处于活动状态
- 9Dump分析模式1: Multiple Exceptions(多线程异常)_multipe exceptions
- 10PyQtChart进行柱状图、饼图的基本设置_pyqt5 炫酷饼状图
yolov8实战第二天——yolov8训练过程、结果分析(保姆式解读)_yolov8跑出来的指标怎么看
赞
踩
yolov8实战第一天——yolov8部署并训练自己的数据集(保姆式教程)-CSDN博客
我们在上一篇文章训练了一个老鼠的yolov8检测模型,训练结果如下图,接下来我们就详细解析下面几张图。
 一、混淆矩阵
一、混淆矩阵
| 正确挑选(正确) | 错误没挑选(正确) |
| 错误挑选(误检) | 正确没挑选(漏检) |
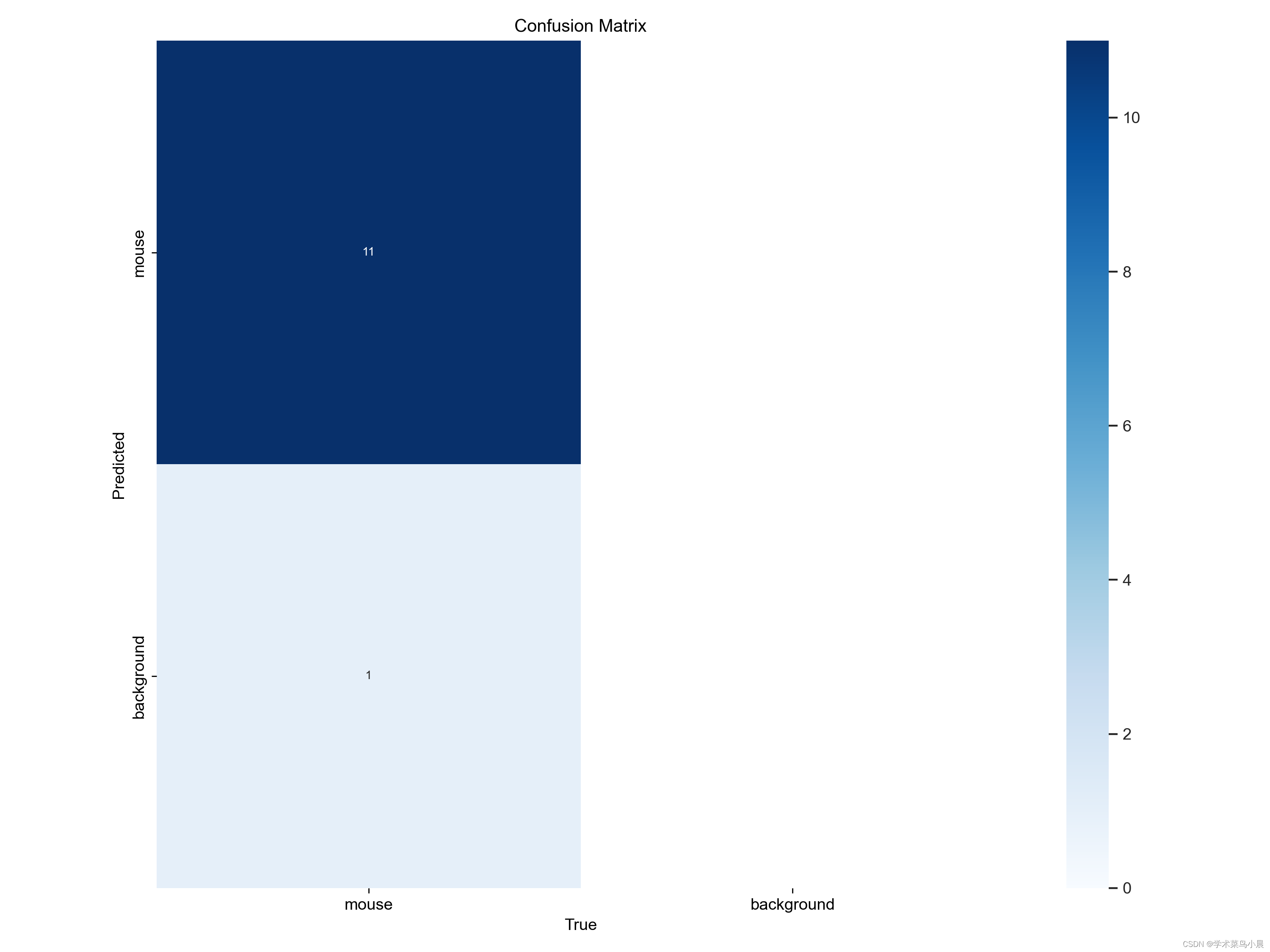

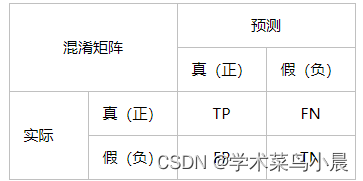
结合这张图看,验证集共11张图,共检测出11只老鼠,一张漏报,被认为是背景。
这样就很好理解混淆矩阵第一张图了。
| 预测到的老鼠11只 | 没有误检测背景为老鼠,空白 |
| 真实样本老鼠被误检测成背景1只 | 真实样本中没有背景图,空白 |
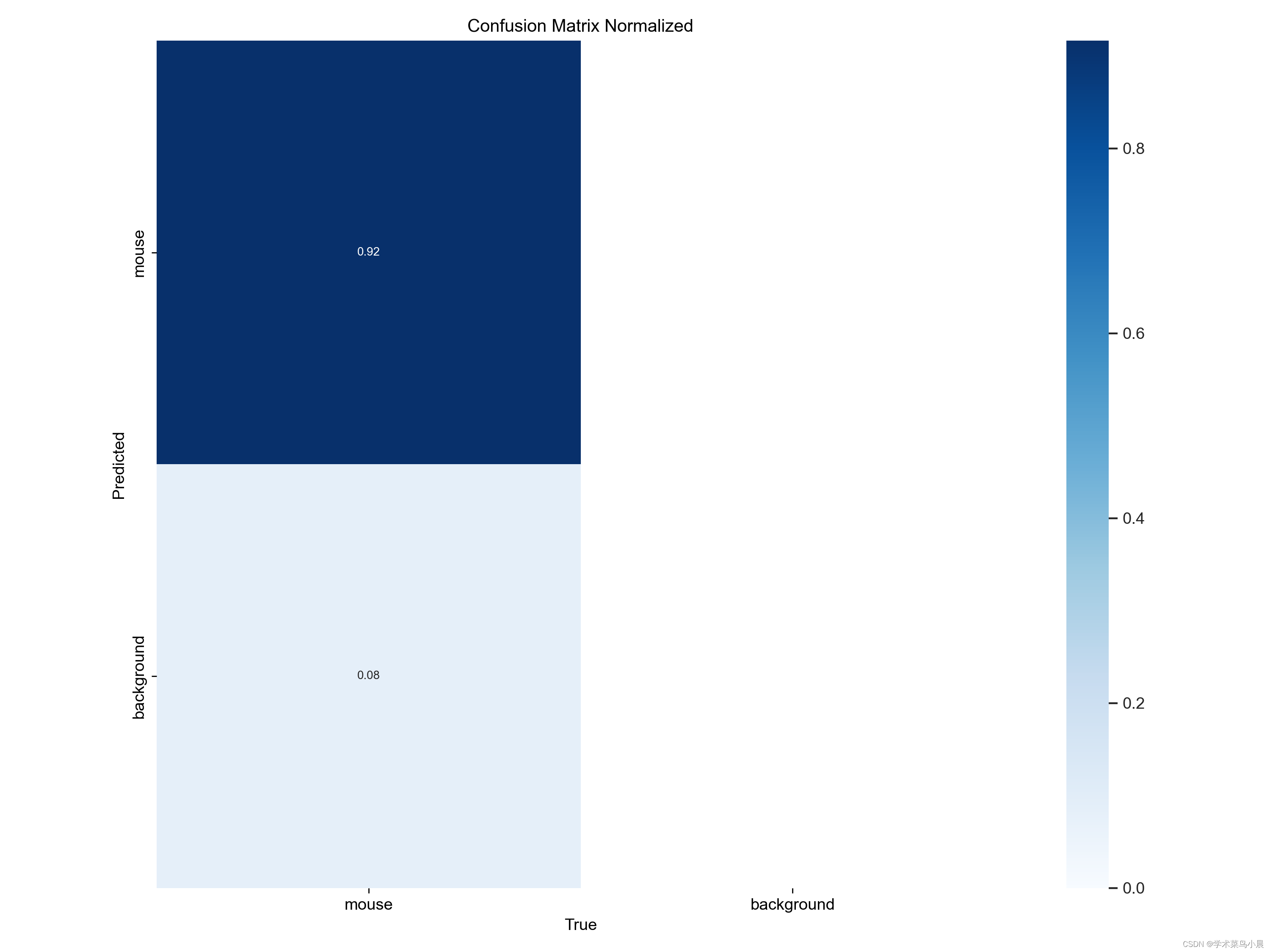
二、归一化混淆矩阵
三、F1置信度曲线
F1 Score(F1 分数)是一种用于评估二分类模型性能的指标,它综合考虑了准确率和召回率。F1 分数曲线显示了在不同阈值下 F1 分数的变化情况。
F1 分数定义为:

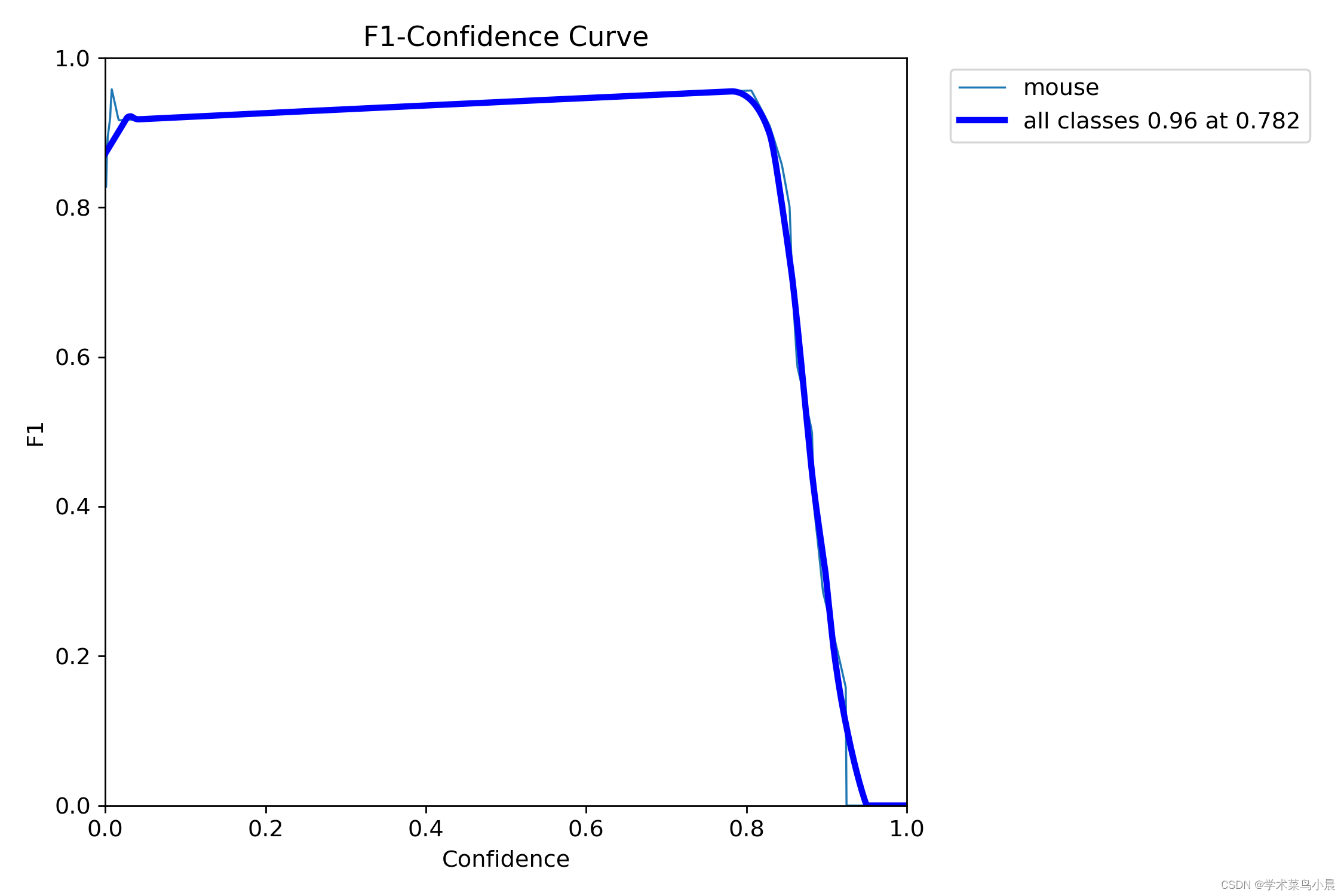
由图可知:置信度阈值在0.8时,效果最好 。
四、精度置信曲线
精确率指分类为正类别的样本中真正为正类别的比例,召回率指所有正类别样本中被正确识别为正类别的比例。这两者往往需要进行权衡。
precision=(TP)/(TP+FP) (挑选正确的占挑选的比例,说明从所有挑选出来的样本找正确挑选的比例)
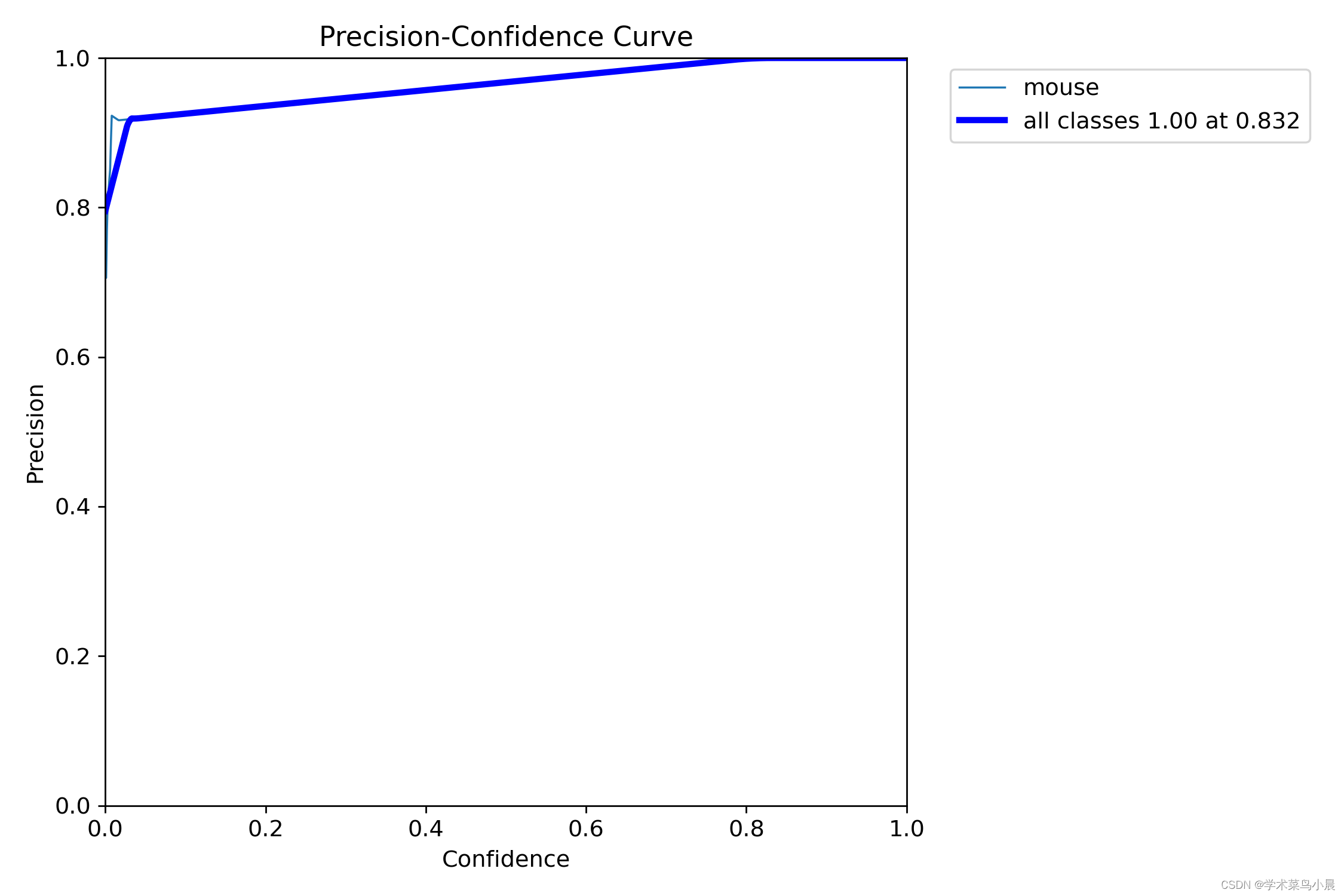
由图可知,置信度在0.8以上时,有较好的精确度。
五、精确召唤度曲线(有名的PR曲线)
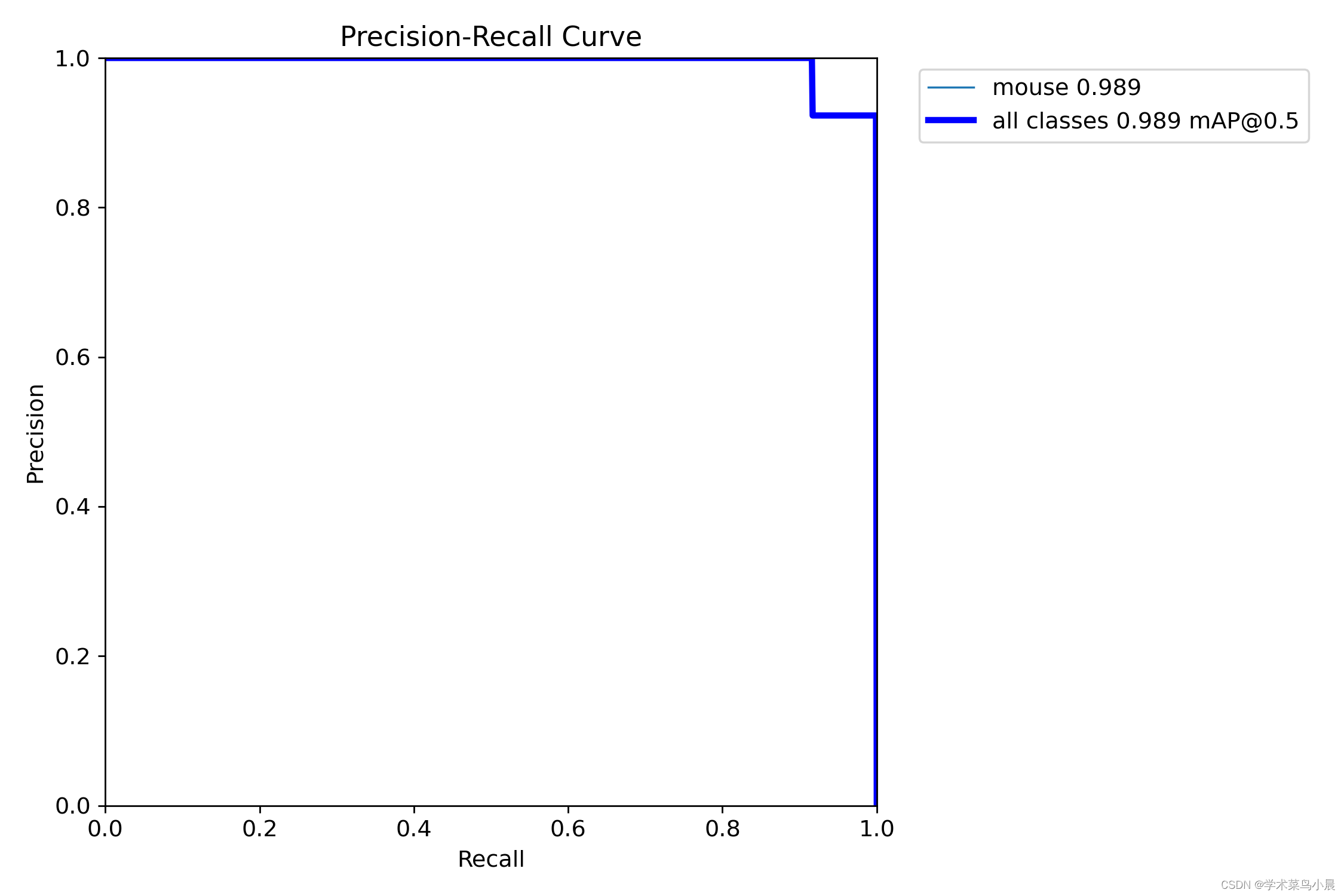
精准率和召回率的关系可以用一个 P-R 图来展示,以查准率 P 为纵轴、查全率 R 为横轴作图,就得到了查准率-查全率曲线,简称 P-R 曲线,PR 曲线下的面积定义为 AP:
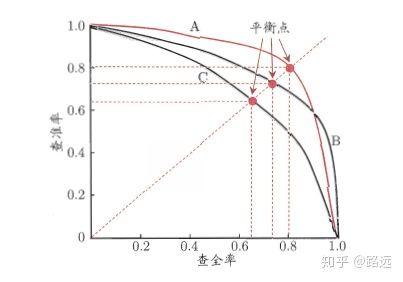
如何理解 P-R 曲线
可以从排序型模型或者分类模型理解。以逻辑回归举例,逻辑回归的输出是一个 0 到 1 之间的概率数字,因此,如果我们想要根据这个概率判断用户好坏的话,我们就必须定义一个阈值 。通常来讲,逻辑回归的概率越大说明越接近 1,也就可以说他是坏用户的可能性更大。比如,我们定义了阈值为 0.5,即概率小于 0.5 的我们都认为是好用户,而大于 0.5 都认为是坏用户。因此,对于阈值为 0.5 的情况下,我们可以得到相应的一对查准率和查全率。
但问题是:这个阈值是我们随便定义的,我们并不知道这个阈值是否符合我们的要求。 因此,为了找到一个最合适的阈值满足我们的要求,我们就必须遍历 0 到 1 之间所有的阈值,而每个阈值下都对应着一对查准率和查全率,从而我们就得到了 PR 曲线。
最后如何找到最好的阈值点呢? 首先,需要说明的是我们对于这两个指标的要求:我们希望查准率和查全率同时都非常高。 但实际上这两个指标是一对矛盾体,无法做到双高。图中明显看到,如果其中一个非常高,另一个肯定会非常低。选取合适的阈值点要根据实际需求,比如我们想要高的查全率,那么我们就会牺牲一些查准率,在保证查全率最高的情况下,查准率也不那么低。
结论:越靠近正方形的对角越好。
六、召回置信度曲线
正样本预测正确占实际正样本的比例。
精确率和召回率是用于衡量二分类模型性能的指标。精确率指分类为正类别的样本中真正为正类别的比例,召回率指所有正类别样本中被正确识别为正类别的比例。这两者往往需要进行权衡。
R=(TP)/(TP+FN) (挑选正确占挑选正确+没挑选错误(漏报),说明正确挑选的占实际正样本的比例)
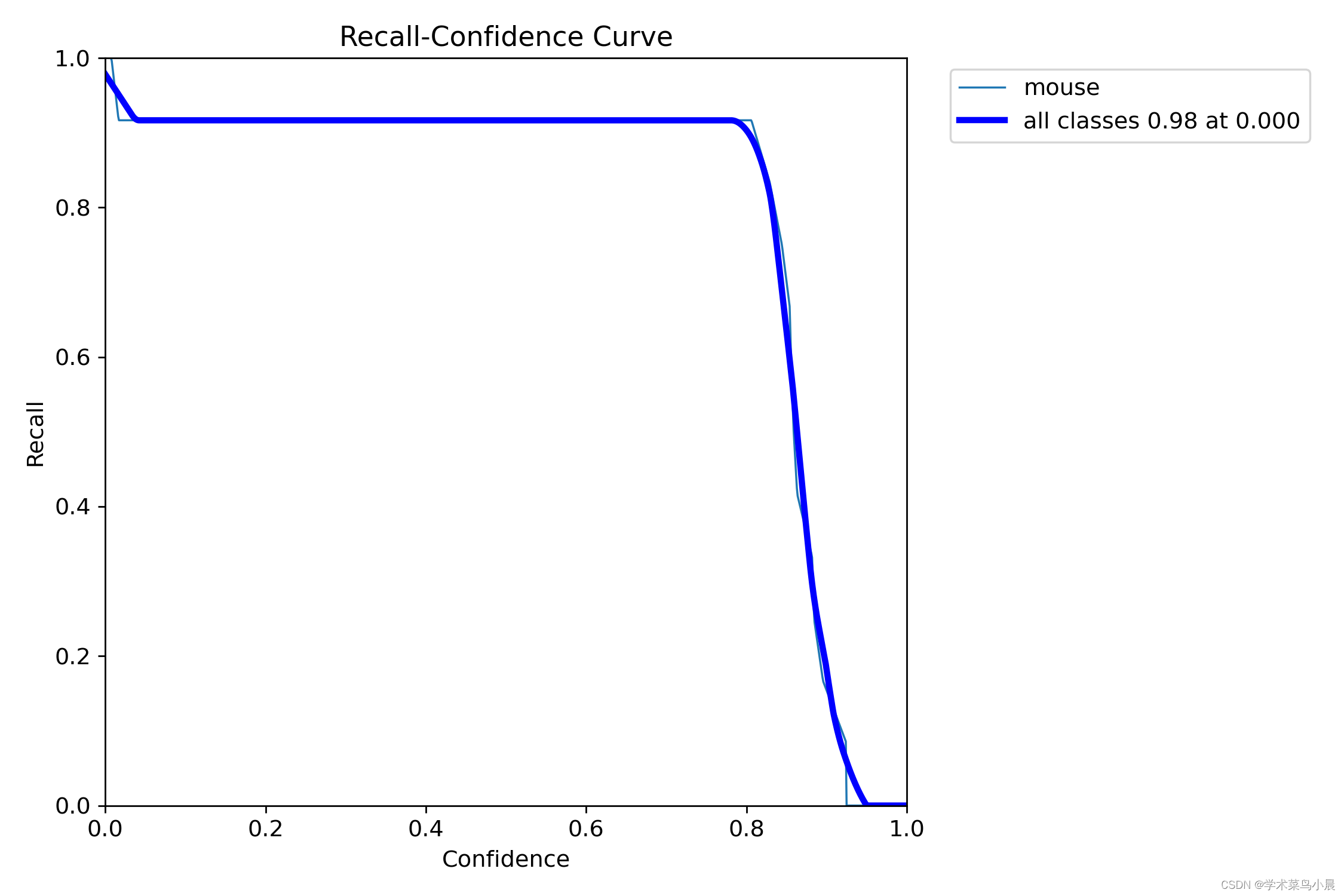
由图可知:置信度大于0.8后,召回率快速下降,说明漏报快速增加。
七、训练过程图
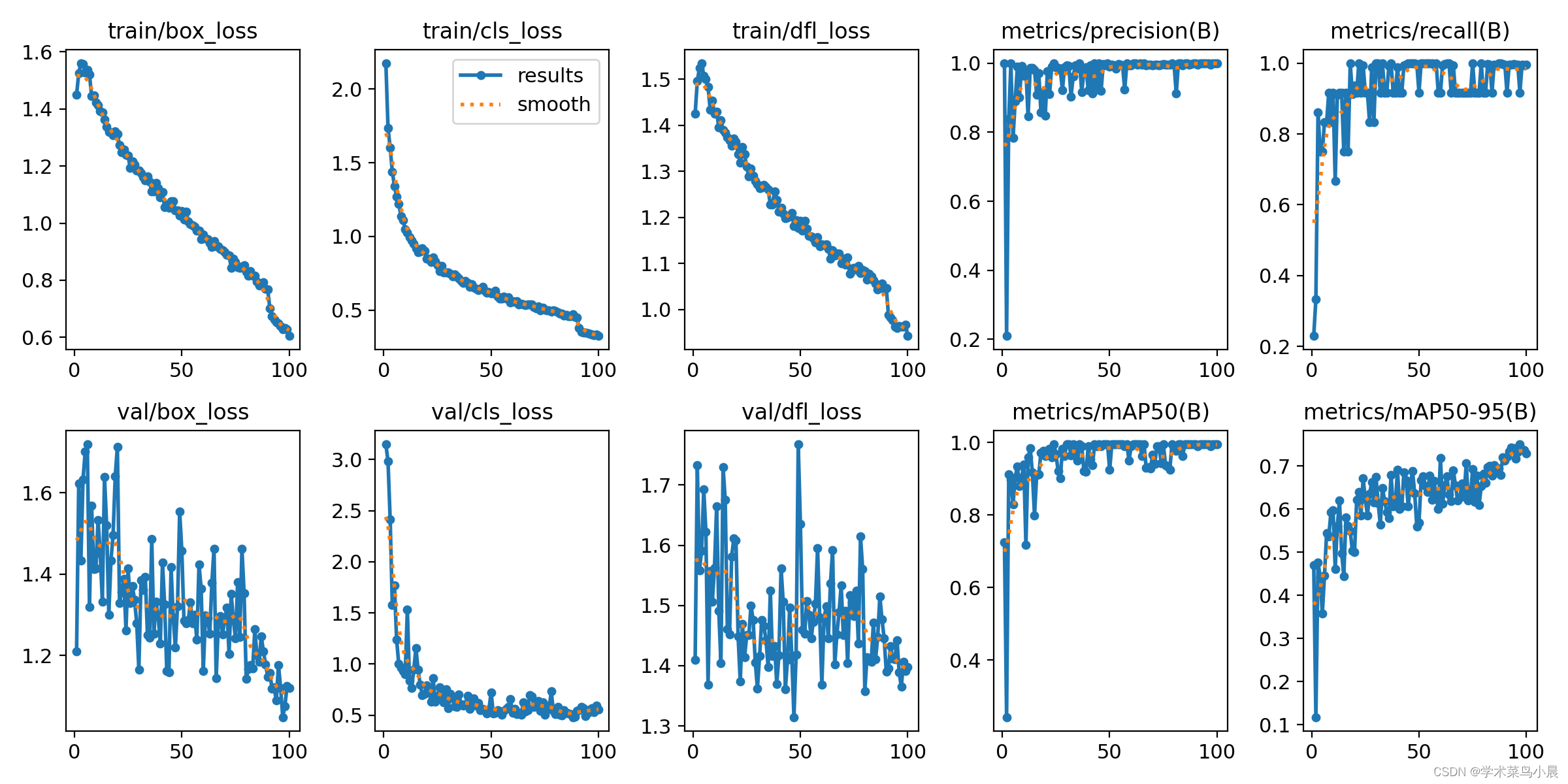
我训练了100轮。yolov8的三个损失,分别是:
-
box_loss(边界框损失):这个损失函数用于计算预测边界框与真实边界框之间的差异。YOLOv8使用IOU(Intersection over Union)作为度量,来衡量两个边界框之间的重叠程度。box_loss通过计算预测框与真实框之间的IOU,来衡量预测框的位置准确度,并将其转化为一个损失值。通过最小化box_loss,模型可以学习到更准确的边界框位置。 -
cls_loss(分类损失):这个损失函数用于计算预测类别与真实类别之间的差异。YOLOv8使用交叉熵损失(Cross Entropy Loss)来衡量分类准确度。cls_loss通过比较预测类别分布与真实类别标签之间的差异,来计算分类的损失值。通过最小化cls_loss,模型可以学习到更准确的类别分类。 -
dfl_loss(特征点损失):这个损失函数是YOLOv8中引入的自定义损失函数。YOLOv8使用了特征点来预测物体的方向和角度信息,dfl_loss用于计算预测特征点与真实特征点之间的差异。通过最小化dfl_loss,模型可以学习到更准确的物体方向和角度信息。
由图可知:
上面一排是训练的时候的三个损失和精确度,召回率。
下面一排是验证 的时候的三个损失和精确度,召回率。
八、val_batch0_label 和val_batch_pred


标签框和预测框,由图可知,漏报一个。
2023/12/26新增:
训练过程图分析:
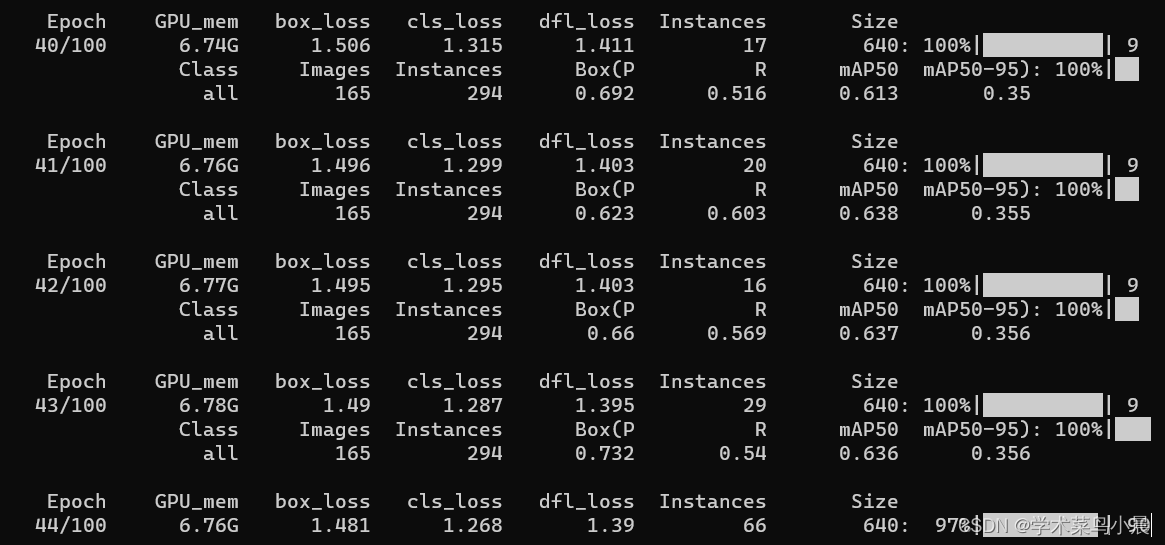
Epoch:迭代次数
Gpu_men:显卡显存占用,不超过最大显卡显存就好,如果超过可以调低batch。
box_loss: 边界框损失
cls_loss:分类损失
dfl_loss:特征点损失
Instances:实例个数,矩形框个数,这个数是在不断变化的
Size:640,训练时会将输入图像resize到640*640
Class:训练类
Images:后面少二个0,训练图像数量,我的是16500张
Instances:全部矩形框个数,我的是29400个
Box(P:精准率
R:召回率
由图可知,精准率在提高,召回率在下降,结合前面公式,说明漏检数量在提升。
map50:置信度阈值在0.5时,检测的map
map50-95:0.5 0.55 0.6 0.65 0.7 0.75 0.8 0.85 0.9 0.95,取得10个mAP值,然后对这十个值取平均。
由图可知,map50,map是0.6,map50-95:map是0.35,说明在高阈值时,检测效果并不好,由0.7,0.75对称可得:大部分检出框置信度在0.5~0.7之间。

