
- 1Java中可变长参数的使用及注意事项_java可变参数坑
- 2【AutoDL】服务器配置、Xftp数据传输及PyCharm连接_/root/autodl-fs
- 3用麻雀算法优化BP神经网络预测模型
- 4android启动程序报java.lang.NullPointerException的原因_android报错java.lang.nullpointerexception
- 5npcap lookback adapter回环网卡是什么 它的作用是什么_npcap loopback adapter
- 6开发者核心能力和素质
- 7我把面试问烂了的⭐MySQL面试题⭐总结了一下(带答案,万字总结,精心打磨,建议收藏)
- 8本地部署Graphhopper实现离线地图路径规划功能(小白放心食用版)_graphhopper 离线地图导航
- 9Proxmox VE(PVE)添加硬盘详解_pve添加新硬盘
- 10【51单片机】DS18B20(江科大)
k8s实践(1)--k8s集群入门介绍和基础原理_k8s多集群实践思考和探索
赞
踩
我们学习安排:由浅入深
1、简单了解集群的工作原理和基础概念,名词解释。
2、安装etcd集群:etcd分布式键值存储系统,用于保持集群状态,比如Pod、Service等对象信息。
3、安装k8s集群,简单了解集群的如何工作。
4、搭建集群网络:基础网络搞好,后面才能顺利部署各种资源。
5、学习k8s的安全、Secrets,ssl认证。如果安全认证没有搞好,创建pod和service都会报各种错误。
6、然后我们深入学习pod和service。
7、深入学习集群工作原理分析,从基础到深度,才能学的扎实。
8、有了pod和service,就需要知道如果发现,学习coreDNS
9、开始部署一些有状态的服务
10、案例实践
一、Kubernetes简介
1.1 Kubernetes简介
Kubernetes是Google在2014年6月开源的一个容器集群管理系统,使用Go语言开发,Kubernetes也叫K8S
K8S是Google内部一个叫Borg的容器集群管理系统衍生出来的,Borg已经在Google大规模生产运行十年之久。
K8S是一个轻便的和可扩展的开源平台,用于管理容器化应用和服务。主要用于:自动化部署、扩展和管理容器应用,提供了资源调度、部署管理、服务发现、扩容缩容、监控等一整套功能。
Kubernetes目标是让部署容器化应用简单高效。
Kubernets官方网站:www.kubernetes.io,目前在github.com/GoogleCloudPlatform/kubernetes进行维护。
它既是一款容器编排工具,也是全新的基于容器技术的分布式架构领先方案。在Docker技术的基础上,为容器化的应用提供部署运行、资源调度、服务发现和动态伸缩等功能,提高了大规模容器集群管理的便捷性。
Kubernetes特点:
易学: 轻量级, 简单, 容易理解
便携: 支持公有云, 私有云, 混合云, 以及多种云平台
可拓展: 模块化, 可插拔, 支持钩子, 可任意组合
自修复: 自动重调度, 自动重启, 自动复制
1.2 Kubernetes 主要功能
数据卷
Pod中容器之间共享数据,可以使用数据卷。
应用程序健康检查
容器内服务可能进程堵塞无法处理请求,可以设置监控检查策略保证应用健壮性。
复制应用程序实例
控制器维护着Pod副本数量,保证一个Pod或一组同类的Pod数量始终可用。
弹性伸缩
根据设定的指标(CPU利用率)自动缩放Pod副本数。
服务发现
使用环境变量或DNS服务插件保证容器中程序发现Pod入口访问地址。
负载均衡
一组Pod副本分配一个私有的集群IP地址,负载均衡转发请求到后端容器。在集群内部其他Pod可通过这个ClusterIP访问应用。
滚动更新
更新服务不中断,一次更新一个Pod,而不是同时删除整个服务。
服务编排
通过文件描述部署服务,使得应用程序部署变得更高效。
资源监控
Node节点组件集成cAdvisor资源收集工具,可通过Heapster汇总整个集群节点资源数据,然后存储到InfluxDB时序数据库,再由Grafana展示。
提供认证和授权
支持角色访问控制(RBAC)认证授权等策略。
二、设计架构
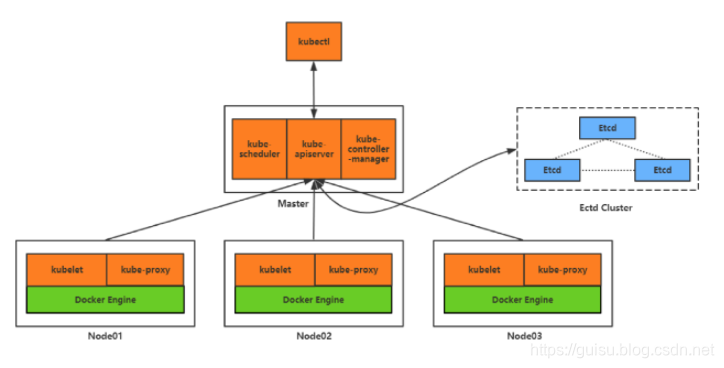
任何优秀的项目都离不开好的架构和设计蓝图,Kubernetes集群包含有节点代理kubelet和Master组件(APIs, scheduler, etc),一切都基于分布式的存储系统。下面这张图是Kubernetes的架构图。

2.1、功能组件
K8S集群中有管理节点Master 与工作节点Node两种类型。
1)、管理节点Master主要负责K8S集群管理,集群中各节点间的信息交互、任务调度,还负责容器、Pod、NameSpaces、PV等生命周期的管理。
2)、工作节点Node主要为容器和Pod提供计算资源,Pod及容器全部运行在工作节点上,工作节点通过kubelet服务与管理节点通信以管理容器的生命周期,并与集群其他节点进行通信。
1、Master 组件
K8S中的Master是集群控制节点,负责整个集群的管理和控制.
在Master上运行着以下关键进程:
kube-apiserver
Kubernetes API,资源操作的唯一入口,各组件协调者,以HTTP API提供接口服务,并提供认证、授权、访问控制、API注册和发现等机制;所有对象资源的增删改查和监听操作都交给APIServer处理后再提交给Etcd存储。
kube-controller-manager
处理集群中常规后台任务,一个资源对应一个控制器,而ControllerManager就是负责管理这些控制器的。负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;
kube-scheduler
负责资源的调度(Pod调度)的进程,通过API Server的Watch接口监听新建Pod副本信息, 按照预定的调度策略将Pod调度到相应的Node节点上;
2、Node组件
Node是K8S集群中的工作负载节点,每个Node都会被Master分配一些工作负载,当某个Node宕机时,其上的工作负载会被Master自动转移到其他节点上
在每个Node上都运行着以下关键进程:
kubelet
kubelet是Master在Node节点上的Agent,管理本机运行容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理;比如创建容器、Pod挂载数据卷、下载secret、获取容器和节点状态等工作。kubelet将每个Pod转换成一组容器。
kube-proxy
在Node节点上实现Pod/Serviced网络代理,提供cluster内部的服务发现和四层负载均衡工作;s是实现Kubernetes Service的通信与负载均衡机制的重要组件.
Docker Engine:Docker引擎,负责本机的容器创建和管理工作
3、docker
运行容器,Container runtime负责镜像管理以及Pod和容器的真正运行(CRI)
4、etcd集群
分布式键值存储系统。用于保持集群状态,比如Pod、Service等对象信息。
5、Add-ons组件
除了核心组件,还有一些推荐的Add-ons:
- kube-dns/CoreDNS负责为整个集群提供DNS服务
- Ingress Controller为服务提供外网入口
- Heapster提供资源监控
- Dashboard提供GUI
- Federation提供跨可用区的集群
- Fluentd-elasticsearch提供集群日志采集、存储与查询
基本工作原理:
在默认情况下Kubelet会向Master注册自己,一旦Node被纳入集群管理范围,kubelet进程就会定时向Master汇报自身的信息(例如机器的CPU和内存情况以及有哪些Pod在运行等),这样Master就可以获知每个Node的资源使用情况,并实现高效均衡的资源调度策略。而某个Node在超过指定时间不上报信息时,会被Master判定为失败,Node的状态被标记为不可用,随后Master会触发工作负载转移的自动流程。
2.2、分层架构
Kubernetes及容器生态系统

Kubernetes设计理念和功能其实就是一个类似Linux的分层架构,如下图所示
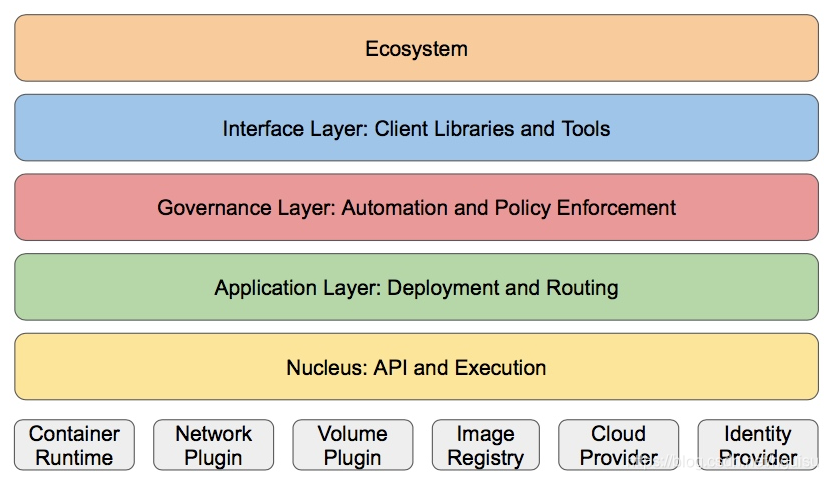
- 核心层:Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件式应用执行环境
- 应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解析等)
- 管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态Provision等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy等)
- 接口层:kubectl命令行工具、客户端SDK以及集群联邦
- 生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴
- Kubernetes外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS应用、ChatOps等
- Kubernetes内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等
三、基本抽象概念
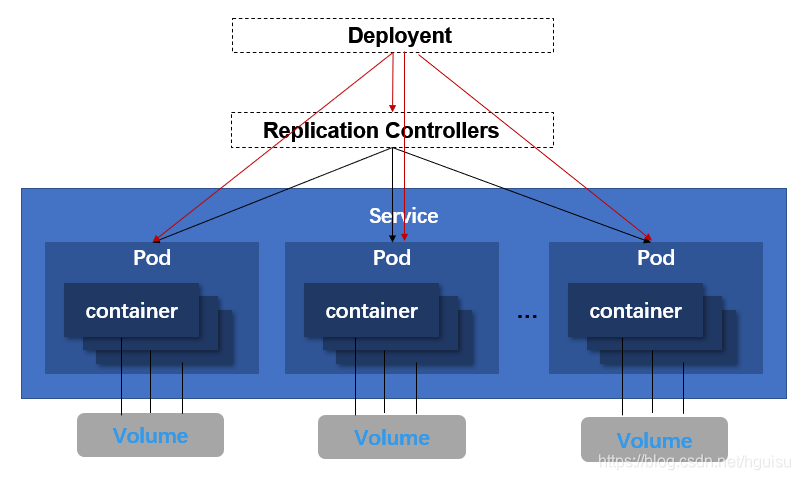

3.1 Pod
在Kubernetes中,最小的管理元素不是一个个独立的容器,而是Pod,Pod是最小的,管理,创建,计划的最小单元.
一个pod对应一个由相关容器和卷组成的容器组。相当于一个共享context的配置组,在同一个context下,应用可能还会有独立的cgroup隔离机制,一个Pod是一个容器环境下的“逻辑主机”,它可能包含一个或者多个紧密相连的应用,这些应用可能是在同一个物理主机或虚拟机上。
3.2 Replication Controllers 复本控制器
Replication Controller 保证了在所有时间内,都有特定数量的Pod副本正在运行,如果太多了,Replication Controller就杀死几个,如果太少了,Replication Controller会新建几个,和直接创建的pod不同的是,Replication Controller会替换掉那些删除的或者被终止的pod,不管删除的原因是什么(维护阿,更新啊,Replication Controller都不关心)。基于这个理由,我们建议即使是只创建一个pod,我们也要使用Replication Controller。Replication Controller 就像一个进程管理器,监管着不同node上的多个pod,而不是单单监控一个node上的pod,Replication Controller 会委派本地容器来启动一些节点上服务(Kubelet ,Docker)。
3.3 ReplicaSet
Replica Set是更高级的replication contorller 。确保任何给定时间指定的Pod副本数量,并提供声明式更新等功能。
RC(Replication Controllers)与RS唯一区别就是lable selector支持不同,RS支持基于等式的seletor。RC仅支持基于等式的标签。
replica set 主要功能:
确保Pod数量:它会确保Kubernetes中有指定数量的Pod在运行,如果少于指定数量的Pod,RC就会创建新的,反之这会删除多余的,保证Pod的副本数量不变。确保Pod健康:当Pod不健康,比如运行出错了,总之无法提供正常服务时,RC也会杀死不健康的Pod,重新创建新的。
弹性伸缩:在业务高峰或者低峰的时候,可以用过RC来动态的调整Pod数量来提供资源的利用率,当然我们也提到过如果使用HPA这种资源对象的话可以做到自动伸缩。
滚动升级:滚动升级是一种平滑的升级方式,通过逐步替换的策略,保证整体系统的稳定性。
3.4 Deployment
Deployment是一个更高层次的API对象概念,它管理ReplicaSets和Pod,并提供对pod的声明性更新以及许多其他的功能。
官方建议使用Deployment管理ReplicaSets,而不是直接使用ReplicaSets,这就意味着可能永远不需要直接操作ReplicaSet对象。除非您需要自定义更新编排或根本不需要更新。
Deployment是Kubernetes系统的一个核心概念,主要职责和RC一样的都是保证Pod的数量和健康,二者大部分功能都是完全一致的,我们可以看成是一个升级版的RC控制器。但那Deployment一些新特性:
Deployment特性
RC的全部功能:Deployment具备上面描述的RC的全部功能
事件和状态查看:可以查看Deployment的升级详细进度和状态
回滚:当升级Pod的时候如果出现问题,可以使用回滚操作回滚到之前的任一版本
版本记录:每一次对Deployment的操作,都能够保存下来,这也是保证可以回滚到任一版本的基础
暂停和启动:对于每一次升级都能够随时暂停和启动
3.5 Service
一个service定义了访问pod的方式,即定义了一组Pod的策略的抽象,我们也有时候叫做宏观服务。就像单个固定的IP地址和与其相对应的DNS名之间的关系。
Kubernetes Pod是平凡的,它门会被创建,也会死掉(生老病死),并且他们是不可复活的。 ReplicationControllers动态的创建和销毁Pods(比如规模扩大或者缩小,或者执行动态更新)。每个pod都由自己的ip,这些IP也随着时间的变化也不能持续依赖。这样就引发了一个问题:如果一些Pods(让我们叫它作后台,后端)提供了一些功能供其它的Pod使用(让我们叫作前台),在kubernete集群中是如何实现让这些前台能够持续的追踪到这些后台的?
3.6、Volumes
一个 volume 就是一个目录,可能包含一些数据,这些数据对pod中的所有容器都是可用的,这个目录怎么使用,什么类型,由什么组成都是由特殊的volume 类型决定的
3.7 StatefulSet
StatefulSet适合持久性的应用程序,有唯一的网络标识符(IP),持久存储,有序的部署、扩展、删除和滚动更新。
3.8 DaemonSet
DaemonSet确保所有(或一些)节点运行同一个Pod。当节点加入Kubernetes集群中,Pod会被调度到该节点上运行,当节点从集群中
移除时,DaemonSet的Pod会被删除。删除DaemonSet会清理它所有创建的Pod。
3.9 Job
一次性任务,运行完成后Pod销毁,不再重新启动新容器。还可以任务定时运行。
3.10 Ingress
通常情况下,service和pod的IP仅可在集群内部访问。集群外部的请求需要通过负载均衡转发到service在Node上暴露的NodePort上,然后再由kube-proxy将其转发给相关的Pod。而Ingress就是为进入集群的请求提供路由规则的集合
四、创建Pod流程
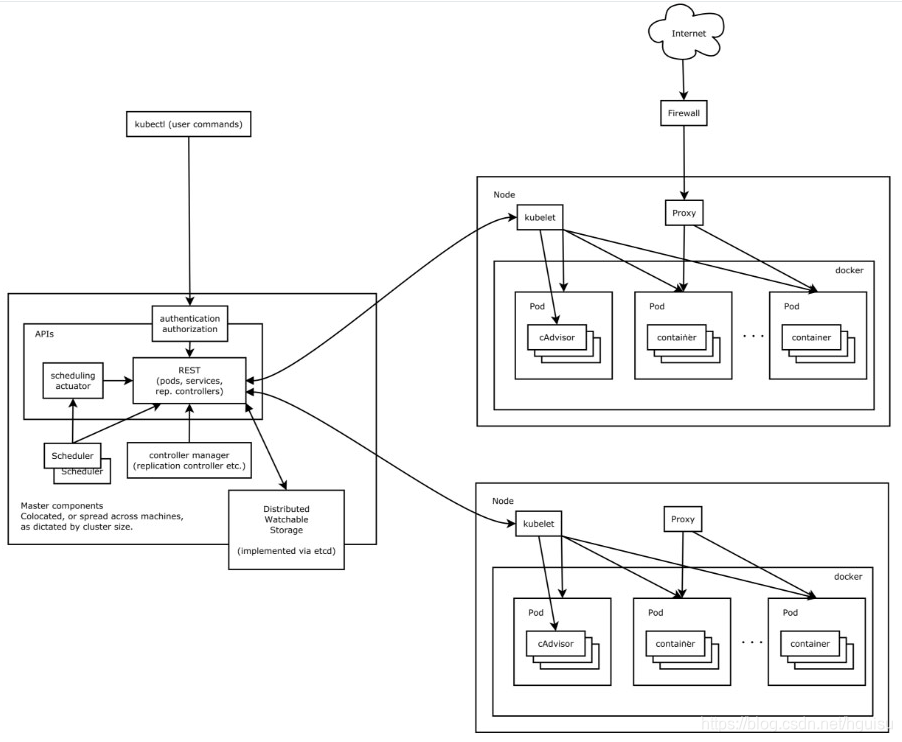
创建Pod的整个流程,时序图如下:

1. 用户提交pod请求:用户提交创建Pod的请求,可以通过API Server的REST API ,也可用Kubectl命令行工具,支持Json和Yaml两种格式;
2. API Server 处理请求:API Server 处理用户请求,存储Pod数据到Etcd;
3. Schedule调度pod:Schedule通过和 API Server的watch机制,查看到新的pod,按照预定的调度策略将Pod调度到相应的Node节点上;
1)过滤主机:调度器用一组规则过滤掉不符合要求的主机,比如Pod指定了所需要的资源,那么就要过滤掉资源不够的主机;
2)主机打分:对第一步筛选出的符合要求的主机进行打分,在主机打分阶段,调度器会考虑一些整体优化策略,比如把一个Replication Controller的副本分布到不同的主机上,使用最低负载的主机等;
3)选择主机:选择打分最高的主机,进行binding操作,结果存储到Etcd中;
4. kubelet创建pod: kubelet根据Schedule调度结果执行Pod创建操作: 调度成功后,会启动container, docker run, scheduler会调用API Server的API在etcd中创建一个bound pod对象,描述在一个工作节点上绑定运行的所有pod信息。运行在每个工作节点上的kubelet也会定期与etcd同步bound pod信息,一旦发现应该在该工作节点上运行的bound pod对象没有更新,则调用Docker API创建并启动pod内的容器。

