
- 1Android 面试问题 2024 版(其二)
- 2科技爱好者周刊(第 176 期):中国法院承认 GPL 吗?
- 3Linux(入门基础):21---查看已安装的软件与卸载yum、rpm_linux查看yum卸载
- 4Python 人工智能实战:图像分割_blurred = cv.medianblur(gray, 5) thresh = cv.adapt
- 5k8s的网络插件Flannel和Calico(the hard way)_k8s worker ip route add
- 6深度学习之基于Yolov5人体姿态摔倒识别分析报警系统(GUI界面)_yolov5激光雷达监测人
- 7最新版 mysql8.0.25 在window7 64位系统上编译和运行_mysqld: cannot load component from specified urn:
- 8【BUG记录】Windows server 2008虚拟机下载安装wireshark和npcap后,打开仍然显示没有接口_npcap是什么软件,可以卸载吗
- 9【2024】TCP、UDP和 HTTP 的区别是?
- 10unity 资料(API)_unityloader api
【探索AI】十一 深度学习之第1周:深度学习概述与基础
赞
踩
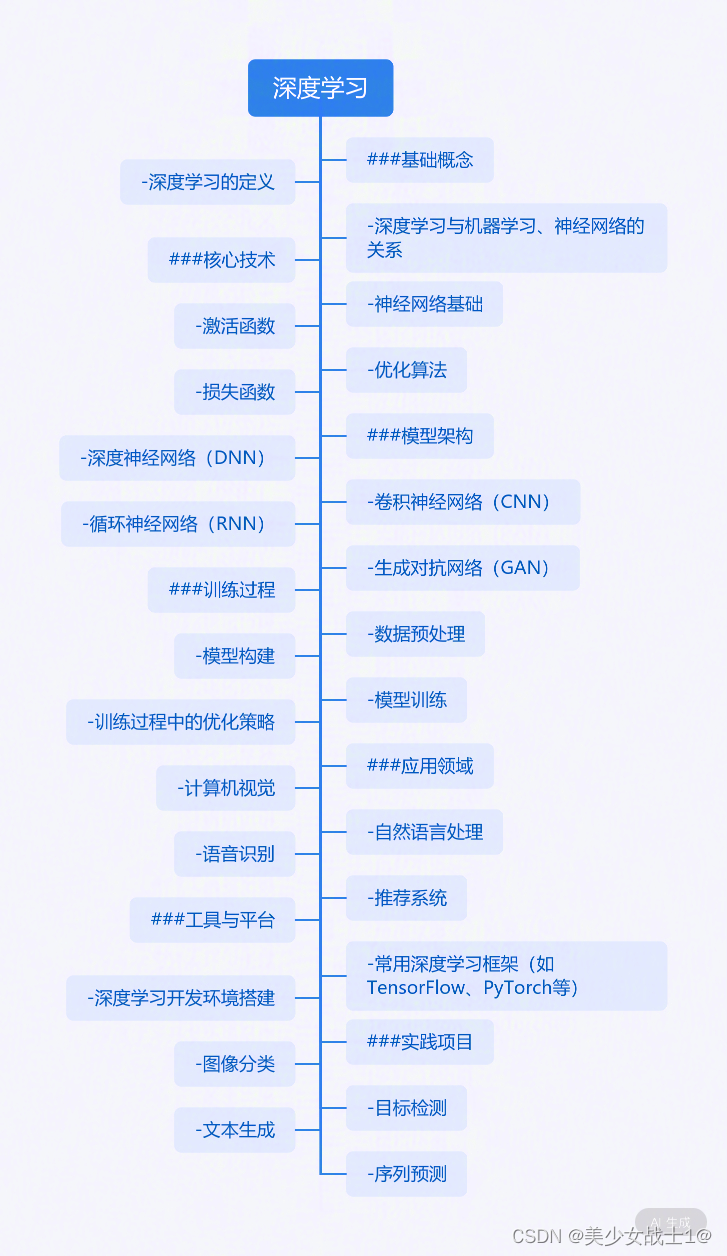
深度学习的发展历史与现状
深度学习的发展历史可以追溯到上世纪40年代,当时神经科学家Warren McCulloch和Walter Pitts提出了第一个神经网络模型,开启了人工神经网络的研究历程。随后,在1958年,计算机科学家Rosenblatt发明了感知器(Perceptron),这是一种单层神经网络,能够通过训练学习将输入数据分为两类。然而,感知器的功能非常有限,只能处理线性可分问题,对于非线性问题则无能为力。
直到上世纪80年代,深度学习才迎来了重要的突破。1986年,Rumelhart和Hinton等人提出了反向传播算法(Backpropagation),该算法可以有效地训练多层神经网络,从而解决了非线性问题的处理。随后,深度学习在各个领域得到了广泛的应用,包括语音识别、图像识别、自然语言处理等。
进入21世纪,随着大数据和计算机硬件的快速发展,深度学习得到了进一步的推动。2006年,Hinton等人提出了“深度学习”的概念,并指出了通过逐层预训练可以有效地训练深度神经网络。随后,深度学习在图像识别、语音识别、自然语言处理等领域取得了巨大的成功,成为了人工智能领域的重要分支。
目前,深度学习已经成为人工智能领域最热门的研究方向之一,各种深度学习模型和算法层出不穷。深度学习在各个领域都有着广泛的应用,如计算机视觉、自然语言处理、医疗影像分析、金融风控等。同时,深度学习也面临着一些挑战,如模型的可解释性、鲁棒性等问题,这些问题也是当前研究的热点和难点。
神经网络的基本原理
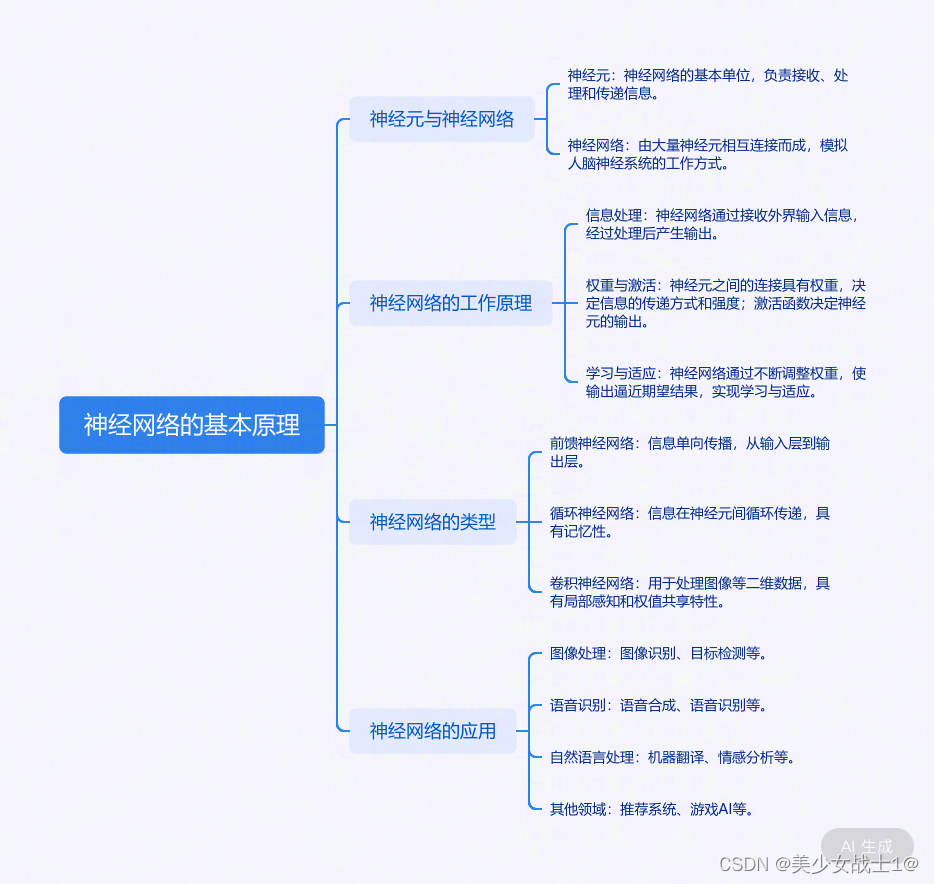
前向传播与反向传播算法
- 前向传播(Forward Propagation)
原理:
前向传播是神经网络中数据从输入层到输出层的传递过程。简单来说,就是根据当前网络的权重和偏置,计算每一层的输出,直到得到最终的输出。
步骤:
输入层:将原始数据输入到神经网络中。
隐藏层:每一层的神经元接收前一层神经元的输出作为输入,并使用激活函数进行转换。计算公式为:z = wx + b,其中z是加权输入,w是权重,x是输入,b是偏置。然后,通过激活函数f得到该层的输出:a = f(z)。
输出层:最后一层神经元的输出即为整个神经网络的输出。
应用:
前向传播在深度学习中的应用主要是用于预测或分类任务。给定输入数据,神经网络通过前向传播得到输出结果,与真实标签进行比较,从而评估模型的性能。
- 反向传播(Backpropagation)
原理:
反向传播是神经网络中用于更新权重和偏置的过程。它根据损失函数(如均方误差、交叉熵等)计算输出层的误差,然后将误差反向传播到每一层,根据误差调整权重和偏置,以减小模型在训练数据上的损失。
步骤:
计算输出层误差:根据损失函数计算输出层的误差,如均方误差或交叉熵误差。
反向传播误差:将误差反向传播到隐藏层,计算每一层神经元的误差。
更新权重和偏置:根据每一层神经元的误差和输入,计算权重和偏置的梯度,并使用优化算法(如梯度下降)更新权重和偏置。
应用:
反向传播在深度学习中的应用主要是用于训练模型。通过不断迭代前向传播和反向传播,神经网络能够学习到从输入到输出的映射关系,从而实现对新数据的预测或分类。
常见的激活函数与优化算法
常见的激活函数
Sigmoid
公式:σ(x) = 1 / (1 + e^(-x))
特点:将输入压缩到0和1之间,适合二分类问题的输出层。但存在梯度消失问题,当输入值非常大或非常小时,梯度接近于0,这可能导致在训练深层网络时,梯度无法有效回传。
ReLU (Rectified Linear Unit)
公式:f(x) = max(0, x)
特点:对于正输入,输出等于输入;对于负输入,输出为0。计算速度快,解决了梯度消失问题,但可能会导致神经元“坏死”。
Leaky ReLU
公式:f(x) = α * x for x < 0, f(x) = x for x ≥ 0
特点:为ReLU的负输入值添加了一个小的非零斜率α,避免神经元完全坏死。
Tanh
公式:tanh(x) = (e^x - e^(-x)) / (e^x + e^(-x))
特点:将输入压缩到-1和1之间,与Sigmoid类似,但输出范围更大。同样存在梯度消失问题。
Softmax
公式:σ(z)_j = e^(z_j) / Σ_k e^(z_k)
特点:常用于多分类问题的输出层,将输出转换为概率分布,所有输出值的和为1。
常见的优化算法
SGD (Stochastic Gradient Descent)
特点:每次迭代只使用一个样本来更新权重,更新速度快,但可能陷入局部最优解。
Mini-batch Gradient Descent
特点:每次迭代使用一小批样本来更新权重,平衡了计算速度和收敛稳定性。
Momentum
特点:引入动量项,加速SGD在相关方向上的收敛,并抑制振荡。
RMSprop
特点:自适应地调整每个参数的学习率,根据梯度的历史平均值来调整学习率。
Adam (Adaptive Moment Estimation)
特点:结合了Momentum和RMSprop的思想,使用梯度的一阶矩(平均值)和二阶矩(未中心化的方差)来动态调整每个参数的学习率。
Adagrad
特点:为每个参数维护一个累积梯度平方的缓存,并根据这个缓存来调整学习率,适合处理稀疏数据。
Adamax
特点:是Adam的一个变种,使用无穷范数来替代RMSprop中的平方范数。
以上就是一些常见的激活函数和优化算法的介绍。它们在不同的神经网络架构和任务中各有优劣,需要根据实际情况选择合适的激活函数和优化算法。
深度学习框架(如TensorFlow或PyTorch)进行基础操作
我们将展示如何在PyTorch中执行一些基础操作。首先,确保你已经安装了PyTorch:
import torch # 创建一个张量 tensor = torch.tensor([1, 2, 3, 4, 5]) print("Tensor:", tensor) # 执行计算 result = tensor + tensor print("Result of addition:", result) # 创建一个变量(在PyTorch中,变量通常是张量,并且具有`requires_grad`属性) variable = torch.tensor([1.0, 2.0], requires_grad=True) print("Initial value of variable:", variable) # 定义一个简单的损失函数和优化器 loss_fn = torch.nn.MSELoss() optimizer = torch.optim.SGD(variable, lr=0.1) # 进行梯度下降优化 for _ in range(10): optimizer.zero_grad() # 清空梯度 loss = loss_fn(variable, torch.tensor([3.0, 4.0])) # 计算损失 loss.backward() # 反向传播计算梯度 optimizer.step() # 更新变量 print("Updated value of variable:", variable.data)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
这些示例展示了如何在TensorFlow和PyTorch中创建张量、执行基本计算、定义变量和进行简单的优化。这些基础操作对于理解深度学习框架的基本用法非常重要。

均源自AI对话收集整理
仅用作学习笔记,持续…
- 相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

