- 1nodejs下载历史版本_node.js历史版本下载
- 2Esxi 6.7部署配置Ubuntu-22.04-live-server_esxi ubuntu
- 3两大智能合约签名验证漏洞分析_25 - signature replay attacks
- 4python基础(八):函数yield生成器和iter迭代器_yield iter
- 5Unity物理效果-针对transform组件实现_unity 获得一个transition的宽
- 6前端echartsArray数据_echart data : proxy(array)
- 7vue3组件加载顺序踩坑记录_vue加载顺序坑
- 8session对象_session 撖寡情
- 9BeautifulSoup4基本使用
- 10人工神经网络有哪些主要的结构特征_人工神经网络结构 相似
第八篇 - 预测受众(Predictive audience)技术是如何赋能数字化营销生态的?- 我为什么要翻译介绍美国人工智能科技巨头IAB公司
赞
踩
IAB平台,使命和功能
IAB成立于1996年,总部位于纽约市。
作为美国的人工智能科技巨头社会媒体和营销专业平台公司,互动广告局(IAB- the Interactive Advertising Bureau)自1996年成立以来,先后为700多家媒体和营销会员企业赋能 - 为这些领先的媒体公司、品牌、代理商和负责销售、交付和优化数字广告营销活动公司和机构提供数字化营销平台服务和技术援助。IAB公司的使命是帮助平台上的企业快速高效转向数字化营销并建试图在行业之间推动数字化营销的标准并普及推广。
IAB使媒体和营销行业能够在数字经济中蓬勃发展。针对互联网数字世界营销广告眼花缭乱,鱼目混珠的现状,互动广告局带头进行了批判性研究,同时也对品牌、代理商和更广泛的商业界进行了数字营销重要性的教育。 IAB组建了人工智能标准工作组(the AI standards working group),2019年12月他们发布了第一份报告《人工智能与市场营销中的应用》。随即2020年,IAB联合IBM的WATSON广告和尼尔森公司(Nielsen)决定致力于研发与市场营销相关的人工智能技术、最佳行业实践、(推广)人工智能的案例和(规范)营销类人工智能技术条款术语来帮助营销负责人迅速转向数字化营销市场,拥抱人工智能和机器学习技术。 IAB与IAB技术实验室合作,制定技术标准和解决方案。IAB致力于专业发展,提升整个行业员工的知识、技能、专业知识和多样性。贸易协会通过其在华盛顿特区的公共政策办公室的工作,为其成员进行宣传,并向立法者和政策制定者宣传互动广告业的价值。
IAB全球网络汇集了包括三个区域组织在内的45个IAB组织,以分享挑战,开发全球解决方案,并推动全球数字广告业。IAB分布在北美、南美、非洲、亚洲、亚太和欧洲。每个协会都是独立拥有和运营的,根据符合当地市场需求的章程运作。

第八篇:对应场景下的人工智能和机器学习技术 – 预测受众(Predictive Audience)
一、原文作者及本文潜在受众

作者: Robert Redmond, Head of AI Ad Product Design, Design Principal, IBM Watson Advertising
首要受众:营销人员
次要受众:营销公司高管
二、与预测受众相关的人工智能技术

传统上,营销人员只有人口统计数据,这些数据很少是完美的,也限制了可以针对的细分市场数量。长相相似的观众的出现似乎很有价值,但他们并没有讲述整个故事。长相相似只会识别具有相似简单归因的人,如人口统计资料。事实上,长相相似的人并不总是表现得像对方。
预测方法可以利用人工智能,根据潜在受众的相似性更好地对他们进行细分,从而帮助减少媒体浪费。
三、人工智能如何帮助量测市场营销投入产出?

它的工作原理
预测受众通过将多个连续的数据信号与第一方CRM数据和可信的第三方数据分层来识别最有可能或最不可能采取所需行动的用户。这远远超出了使用机器学习和预测分析从13000多个数据点中收集行为片段的人口统计数据的范围,这些数据点使用了数百个模型和数千种变体,从而快速确定最适合的数据。
这一切都是从组合广告商的第一方受众种子数据或通过种子像素获得的数据开始的。关于品牌属性,以收集独特的消费者见解。这些种子数据由内容参与度或与品牌的互动类型/计数等组成,由机器学习算法使用,并与13000个基于兴趣和行动的数据点进行对比,以分析各种消费者档案中的行为属性。然后,它构建数千个模型变体,测试并选择性能最好的变体,同时不断从性能中学习。这使得现场培训能够指导培训定期重建细分市场,以实现最高性能。
广告商对训练参数有完全的控制权,使他们能够确定哪些属性有价值,哪些属性可以忽略,哪些细分市场正在使用,以及允许排除的能力,对驱动模型性能的指标的所有权,以及控制输出的门。
其结果是根据您的个人活动KPI定制基于预测的独特行为相似细分市场,并将其分为以下细分市场:低-不太可能采取所需行动;中等——有可能采取所需行动;高–很可能会采取所需的行动。这让品牌有能力适当定位强有力的信息,与“志同道合”的观众产生共鸣
四、原文作者洞见
使用现有的第一方数据集或通过种子像素收集的数据,生成行为驱动的行为相似片段需要对当前消费者有深入的了解。
五、推荐一家客户数据分析大师 – 美国APPEN公司
推荐理由:
- 一家遍布中美两地的大型机器学习公司,在无锡和上海均有办事处。著名的美国ZEFR & GUMGUM也是他们的客户;
- 擅长数据标注,数据训练和学习,主要为客户提供深度学习服务,根据客户CRM数据库和其他数据库,能帮助客户深挖数据价值。
- 他们的文本注释、图像注释、音频注释和视频注释将使客户有信心大规模部署AI和ML模型。
- 拥有多种数据采集技术、数据自动结构化技术、音视频解析技术、数据自动化技术、数据库预标识技术、大语言模型技术
- 拥有一流科技人才,能提供机器学习全栈服务,为客户提供机器学习、数据采集、数据自动化和调优等全套软件及技术支持。
他们的口号:你的人工智能广告和你的数据一样好
他们认为:
如果使用得当,广告中的机器学习对每个人都有好处。客户可以获得与他们相关的广告,广告商也可以销售他们的产品。在使用机器学习和人工智能时,需要始终牢记一点:你的输出只会和你的数据一样好。
当你使用大量数据和新技术时,很容易让低质量的数据和偏见从裂缝中溜走。如果你要在广告计划中实施机器学习模型和预测性目标定位,你必须寻找高质量的培训数据集,以确保你的投资获得最大收益。
他们能提供什么帮助
他们的数据注释经验跨越了25年,为全球范围内的无数项目提供了培训数据的专业知识。通过将我们的人工辅助方法与最先进的技术平台相结合,我们为您提供所需的高质量训练数据。

他们对机器学习产品逻辑介绍
营销人员需要人工智能技术来预测越来越多的个性化需求。
1. 机器学习如何改善广告
机器学习和人工智能最大的能力是可以处理大量数据进行预测。这可以用于广告和营销,以检测信号,并在正确的时间在正确的人面前获得正确的广告,即使不需要个人身份信息。在机器学习模型和人工智能技术的帮助和支持下,广告变得高度相关,可以实现营销人员对数字营销活动的投资回报率期望。
2. 预测目标和测试
预测目标是一种营销技术,使用人工智能和机器学习,根据行为模式和历史数据预测未来的客户决策。这些数据用于预测某个人采取行动的概率或可能性,例如进行购买、参与产品或以其他方式进行转换。预测性目标定位工具还可以帮助品牌创建更好的客户角色,帮助他们决定针对哪些活动,确保潜在客户获得尽可能最相关的广告。
3. 人工智能产品推荐与超相关性
在买家的旅程中,最好、最有效的方法之一是发布产品推荐广告。但是,这一切都取决于你的广告在任何特定时间对一个人的相关性。这就是人工智能推荐模型可以帮助消除过程中的猜测的地方。推荐模型通常建立在已知的客户属性和习惯之上。它允许模型根据模型了解的信息向新客户推荐产品。你会在Netflix和亚马逊上看到推荐模式在起作用,包括观看节目和购买产品,以及流行的搜索引擎和社交网络,这些网络的收入来源都依赖广告。
4. 高级推荐模型
在过去几年中,推荐模型的一个主要更新是,它们正在从使用显性反馈转向隐性反馈。最早的推荐模型使用了来自客户的明确反馈,即客户提供的信息,例如他们喜欢的产品类别。较新的模型使用更隐含的反馈来提出建议,寻找理解意图的行为信号。
高级推荐模型也变得更加精细和具体。他们现在不再仅仅使用产品类别来进行推荐,而是使用SKU编号,并将其作为单个产品进行具体化。
通过具体的推荐,广告的格局正在发生变化。这不再是关于产品和产品类别,而是关于客户和他们的购买途径。广告商现在甚至在顾客了解自己之前就开始猜测顾客想要买什么。
而且,推荐模型还不止于此。人工智能和机器学习广告模型的未来不仅将使用历史用户数据,还将结合用户对广告的反应。推荐将基本上实时更新。正如你所能想象的,处理如此庞大和多样的数据需要一个像Appen这样深刻理解挑战的数据合作伙伴。
5. 个性化广告定位
人们和组织总是在改变他们的偏好,对于广告商来说,能够实时检测和适应这些变化比以往任何时候都更重要。此外,如果广告是针对他们的旅程个性化的,人们更有可能购买,所以这意味着个性化广告不再是奢侈品,而是一种要求。广告可以通过多种不同的策略和镜头进行个性化设置,例如:
| 个性化设置 | |
|---|---|
| 序号 | 属性 |
| 1 | 季节性 |
| 2 | 天气 |
| 3 | 地区 |
| 4 | 个人特征 |
| 5 | 利益 |
| 6 | 文化 |
| 7 | 以前的购买 |
6. 更好的品牌安全性和一致性
虽然广告个性化和预测定位的首要目标是在合适的客户面前获得合适的广告,但这并不是唯一的好处。使用人工智能和机器学习向客户推荐产品也可以帮助您的品牌建立更好的客户关系,并管理品牌安全和一致性。你的广告放在哪里反映了你的公司。如果你的广告出现在有偏见、负面或非事实的内容旁边,品牌信任度和好感度可能会下降。
围绕你的广告的背景是你的品牌标识和结盟的关键组成部分。你可以使用人工智能工具和机器学习算法来确保你的广告只出现在与你的品牌一致且安全的地方。
7. 做出更好的广告决策
人工智能和机器学习对广告的最大好处之一是能够做出更好的品牌和广告决策。有了人工智能,你的品牌就可以根据数据做出广告决策。而不是猜测谁会对哪些广告做出反应,以及何时有数据支持你。你还可以通过机器学习来决定在哪里投放广告,并确保你保持安全一致的品牌形象。我们身上都带着偏见,这些偏见会影响我们对特定情况的分析。好的机器学习模型不存在这个问题。你的决定将基于数据,而不是直觉。
机器学习和预测行动目标(成功客户案例)
现实生活中的公司是如何使用这些工具来解决问题和改善业务的。Zefr和Gumgum就是他们的两家客户。
Zefr ( WWW.zefr.com )
Zefr是一家平台公司,帮助其他公司将广告放置在上下文相关的环境中。Zefr帮助其他公司保持广告和品牌的安全。它们帮助公司将广告放置在与上下文相关的空间中,这也会让客户感到高兴。
挑战:
Zefr需要能够扩展他们的数据标签,但没有足够的内部资源。Appen使Zefr能够通过其众包解决方案准确高效地标记大量数据。起初,Zefr与Appen合作获取更多数据,以便帮助客户在品牌安全空间投放广告。但是,随着他们越来越多地可以访问大量数据,Zefr进行了扩展,使他们的客户能够在特定于客户的细微空间中投放广告。
在Appen数据注释平台的帮助和支持下,Zefr能够为客户提供关于广告投放位置的定量信息,并在不牺牲质量的情况下提供一致的体验。
GumGum ( www.gumgum.com )
GumGum是一家上下文优先的广告技术公司,它在不使用个人数据的情况下吸引人们的数字注意力。GumGum提供了一个平台,提供下一代上下文智能、行业领先的动态广告创意,以及衡量和优化广告活动的能力,以更好地了解消费者的心态,从而吸引注意力并推动行动和结果。
挑战:
GumGum的内部团队需要一种更快的方法来标记数据,对每个图像和文本进行分类。GumGum与Appen合作,以加快他们的贴标过程。通过与Appen合作,GumGum可以更有效地创建高质量的数据集并训练其机器学习算法。GumGum可以依靠Appen提供大量标记数据,不断改进现有模型,创建新的复杂模型,从而发展业务,为客户提供尽可能好的产品。
六、数字化营销工兵小结
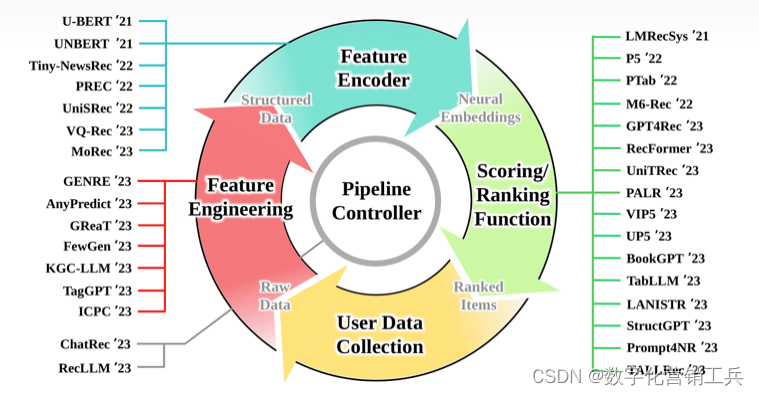
1、关于推荐算法,我推荐一篇文章,这是Cornell University师生共同发表的一篇文章。它的经典在于他们提出推荐系统中的广域和深度学习方法。具有非线性特征转换的广义线性模型被广泛用于具有稀疏输入的大规模回归和分类问题。通过一组广泛的跨产品特征转换来记忆特征交互是有效的和可解释的,而通用化需要更多的特征工程工作。在较少的特征工程的情况下,深度神经网络可以通过为稀疏特征学习的低维密集嵌入,将更好(better)推广到看不见的特征组合。然而,当用户-项目交互是稀疏的和高阶时,具有嵌入的深度神经网络可以过度泛化和推荐不太相关的项目。他们提出了广域和深度学习——联合训练广域线性模型和深度神经网络——以结合推荐系统的记忆和泛化的优势。他们在Google Play上对该系统进行了产品化和评估,Google Play是一家拥有超过10亿活跃用户和超过100万应用程序的商业移动应用商店。在线实验结果显示,与仅宽和仅深的模型相比,宽和深显著增加了应用程序的获取量。他们还在TensorFlow中开源实现。
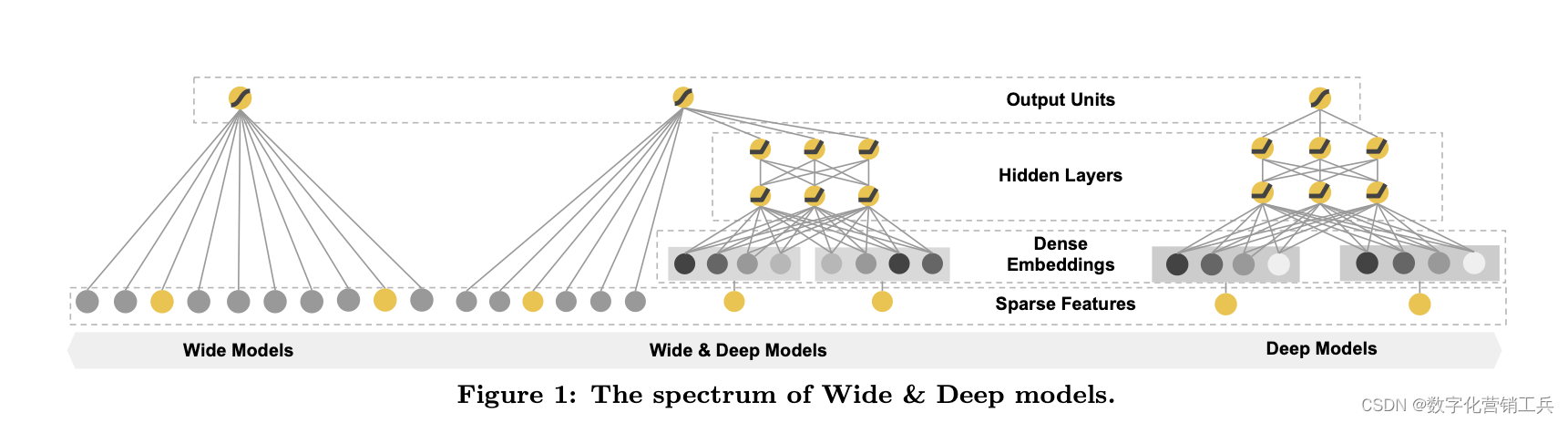
(模型谱系)
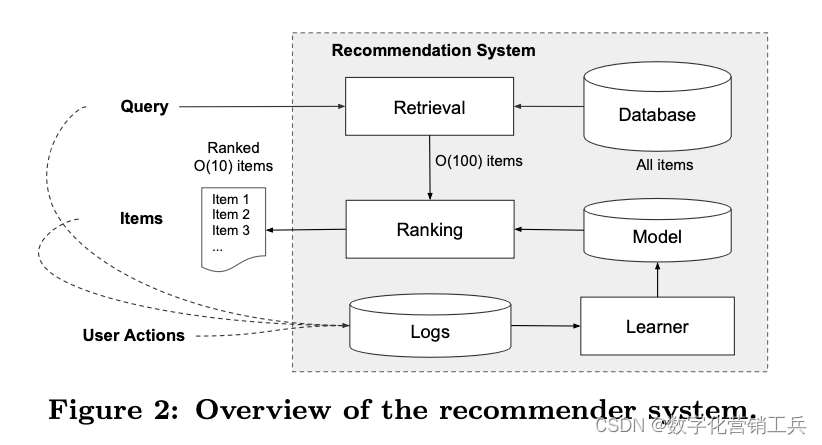
(推荐系统概览)
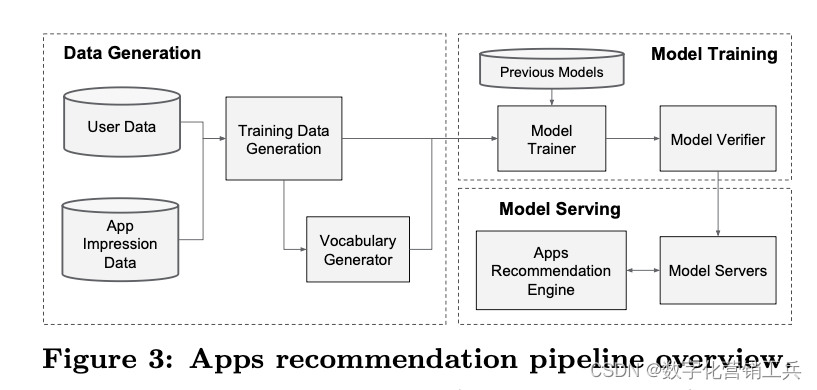
(APP推荐管道概览)
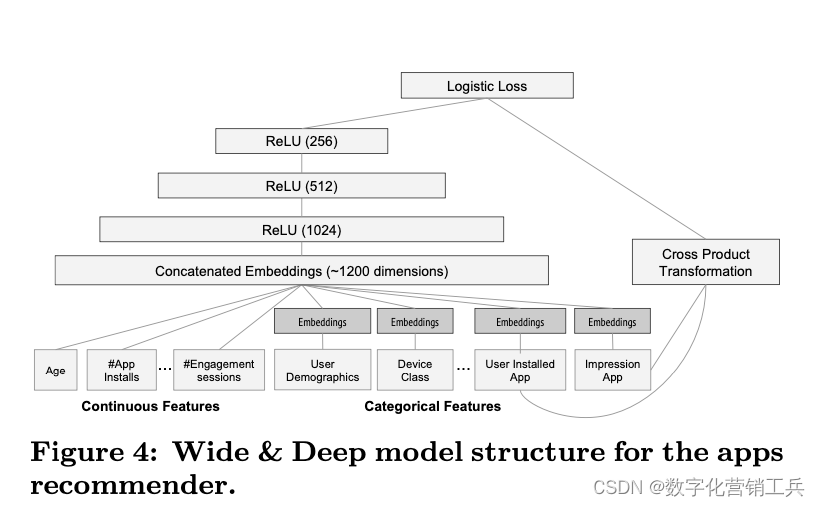
(App推荐模型结构)
有兴趣的朋友,还可以在知乎上找到一篇非常详细的介绍 (链接见文末)
2、除此之外,关于客户画像的算法和模型,无疑APPEN公司在数据采集,标识,分类,计算等智能自动化领域,具有较强的生命力。尤其是数据标注领域,个人觉得这种公司已经走在国内企业的前列。很多国内的公司对数据标注工作不够重视,有很多是外发出去给别人处理的。一个好的人工智能产品,一个决定因素是数据的质量,就好比今天我们用的尼龙66一样,杜邦的地位很难被人超越一样。能够立足把原始数据处理好的公司,我想,在将来很长的一段时间内,会变得越来越优秀。因为数据经过清洗和整理,会加速算法和模型的迭代以及他们的包容性。一套算法和模型如果能够处理各种数据格式的数据,才是最理想的。人工智能公司,如果忽略价值创造过程中的关键环节,光有算法和模型是远远不够的。
3、读完此文一个深刻的理解是,数据库的来源有两个,一个是自己内部的,一个外部可信度高的第三方数据库。无论是我们内部或者外部,在训练数据的时候,数据的来源,采集,标注方法,训练方法等过程中,有大量的软件工厂管理工作。作为甲方,如果把自己的需求讲清楚,对于乙方人工智能公司来说,他们或许可以提供更好的解决模型给我们。比如潜在客户画像的相关特征,我们要尽可能描述清楚,推动客户购买的哪些因素有哪些,这些因素之间是如何联系和相互影响的,甲方非常有必要和乙方供应商讲清楚。否则,由于难以避免的算法偏见,再加上由于乙方不懂甲方的行业知识和产品知识,供应商开发出来的模型大概率要打折。会想起之前上一篇文章第七篇中波士顿咨询公司一直强调公司要培养人才,建立公司的专家库。人工智能更是这样,一个公司如果缺乏灵魂人物,这个人要懂产品,懂客户,懂公司内部流程,还要有一定的人工智能基础知识,公司需要培养更多这样的优秀工程师和专家。
七、资料来源及推荐阅读
1、美国APPEN公司网站
Improves AI with Data - Powering AI Innovation | AppenSee how Appen provides data to improve AI, guide our customers to driving innovation, accelerating AI development, and staying ahead of the competition.![]() https://www.appen.com2、关于推荐算法大语言模型,知乎上有一篇文章外,其它的,大家也可以自行查看
https://www.appen.com2、关于推荐算法大语言模型,知乎上有一篇文章外,其它的,大家也可以自行查看
3. GITHUB专栏
https://github.com/CHIANGEL/Awesome-LLM-for-RecSys![]() https://link.zhihu.com/?target=https%3A//github.com/CHIANGEL/Awesome-LLM-for-RecSys
https://link.zhihu.com/?target=https%3A//github.com/CHIANGEL/Awesome-LLM-for-RecSys
4、Wide & Deep Learning for Recommender Systems
https://arxiv.org/abs/1606.07792![]() https://arxiv.org/abs/1606.07792
https://arxiv.org/abs/1606.07792
八、下一篇文章
第九篇:过程发现(Process Discovery)
为了便于读者后续深入学习数字化营销体系相关的这九种人工智能和机器学习技术,经过与多位同行讨论及前辈老师们的讨教,后续每一篇文章将尽可能按照以下原则,要求和框架进行编写。翻译和整理过程中,我力图自己先能理解,但是难免有很多错误,欢迎您不吝指教。如果您有任何想法,期待您的来信。我一定认真学习,坚持终身学习。