
- 1Linux工具【1】(编辑器vim、编译器gcc与g++)_vim环境 g++环境
- 2cef在android中使用_Android程序中,内嵌ELF可执行文件-- Android开发C语言混合编程总结...
- 3Markdown语法_csdn 写文章时 markdown怎么显示#
- 4SpringBoot+Mybatis+MySQL的pom依赖_springboot + mybatis +mysql8 的pom文件依赖
- 5手把手带你用Python和文心一言搭建《AI看图写诗》网页项目(附上完整项目源码)_python怎么实现ai
- 6Shell脚本-全局变量、局部变量、环境变量_shell 全局变量
- 7边缘计算的端、边、云:分层分级的数据处理新模式_端边云
- 8kubesphere多集群管理,实现kubernetes多集群同时应用部署_kubesphere部署应用
- 9Ubuntu 下用 Eclipse 编译调试 Android NDK 工程_[discovery options] page in project properties ecl
- 10电源管理之pmu驱动分析
LangChain的函数,工具和代理(二):LangChain的表达式语言(LCEL)_chain.invoke
赞
踩
LangChain Expression Language (LCEL) 是 LangChain 工具包的重要补充,旨在提高文本处理任务的效率和灵活性。LCEL 允许用户采用声明式方法来组合链,便于进行流处理、批处理和异步任务。其模块化架构还允许轻松定制和修改链组件。LCEL 的优势之一是它使用户更容易个性化链的不同部分。链的声明性和模块化特性允许轻松地交换组件。此外,现在的提示更加明显,可以轻松地修改以适应特定的用例。在 LangChain 中,提示只是默认值,但是可以为生产应用程序进行更改。
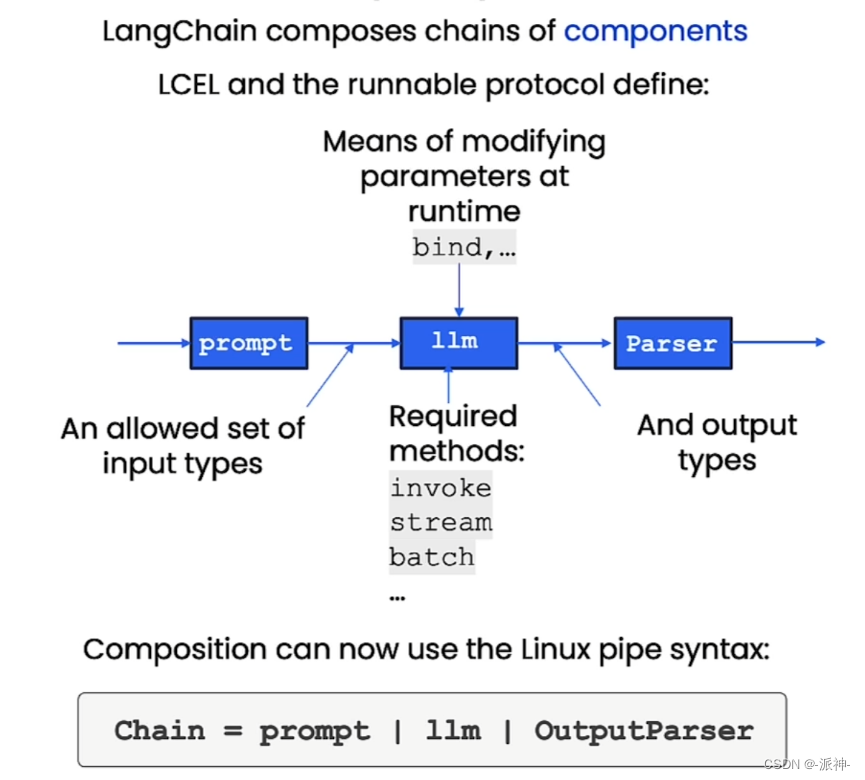
一,简单链(Simple Chain)
要实现一个链(chain),首先让我们做一些初始化的工作,如设置opai的api_key,这里我们需要说明一下,在我们项目的文件夹里会存放一个 .env的配置文件,我们将api_key放置在该文件中,我们在程序中会使用dotenv包来读取api_key,这样可以避免将api_key直接暴露在程序中:
- #pip install -U python-dotenv
-
- import os
- import openai
-
- from dotenv import load_dotenv, find_dotenv
- _ = load_dotenv(find_dotenv()) # read local .env file
- openai.api_key = os.environ['OPENAI_API_KEY']
接下来我们需要导入langchain相关的包,并且实现一个简单chain,然后我们查看一下chain的内容:
- from langchain.prompts import ChatPromptTemplate
- from langchain.chat_models import ChatOpenAI
- from langchain.schema.output_parser import StrOutputParser
-
- #通过prompt模板创建一个prompt
- prompt = ChatPromptTemplate.from_template(
- "请为我写一首关于 {topic}的诗。"
- )
- #定义opai的语言模型,默认使用gpt-3.5-turbo模型
- model = ChatOpenAI()
- output_parser = StrOutputParser()
-
- #创建一个简单链
- chain = prompt | model | output_parser
-
- chain

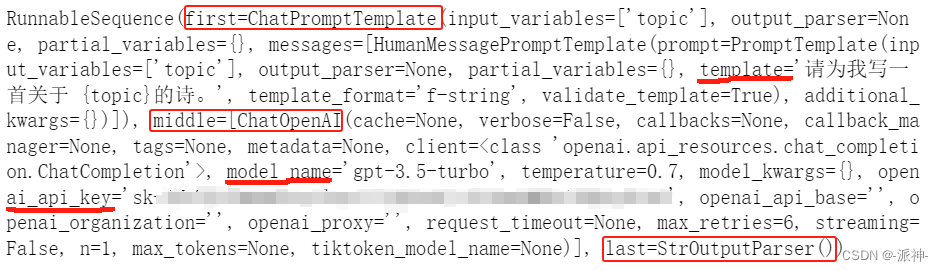 这里我们看到chain中包含了3部分信息,其中first部分是关于prompt模板的信息,middel部分是关于语言模型的信息,这里我们使用的是openai的gpt-3.5-turbo模型,last部分是关于输出解析器的信息。简单的链接就包含这些内容,下面我们使用invoke方法来调用这个chain:
这里我们看到chain中包含了3部分信息,其中first部分是关于prompt模板的信息,middel部分是关于语言模型的信息,这里我们使用的是openai的gpt-3.5-turbo模型,last部分是关于输出解析器的信息。简单的链接就包含这些内容,下面我们使用invoke方法来调用这个chain:
- response = chain.invoke({"topic": "大海"})
- print(response)

二、更复杂的链(More complex chain)
接下来我们将用户的问题和向量数据库检索结果结合起来,使用RunnableMap来组合一个更复杂的chain,不过我们首先需要定义一个基于内存的简单向量数据库,并在该向量数据库中存放两个简单的文档:
- from langchain.embeddings import OpenAIEmbeddings
- from langchain.vectorstores import DocArrayInMemorySearch
- from langchain.schema.runnable import RunnableMap
-
- #创建向量数据库
- vectorstore = DocArrayInMemorySearch.from_texts(
- ["人是由恐龙进化而来",
- "熊猫喜欢吃天鹅肉"],
- embedding=OpenAIEmbeddings()
- )
- retriever = vectorstore.as_retriever()
-
- #创建检索器
- retriever = vectorstore.as_retriever()
在上面的向量数据库中我们加入了两段文本:“人是由恐龙进化而来” 和 “熊猫喜欢吃天鹅肉”,加入这两句违反常识的文本是为了后面确认llm只从向量库中获取相关答案。
下面我们让检索器来检索相关文档:
retriever.get_relevant_documents("人从哪里来?")
检索器会返回和问题相关的问题,并且会根据文档的与问题的相似度对相关文档进行排序。
retriever.get_relevant_documents("熊猫喜欢吃什么?")
下面我们来创建一个比之前的simple chain更复杂的chain, 在这个chain中我们会加入RunnableMap,它用来提供和用户问题相关的文档集,最后我们查看一下chain中的内容:
- template = """Answer the question based only on the following context:
- {context}
- Question: {question}
- """
- prompt = ChatPromptTemplate.from_template(template)
-
- inputs = RunnableMap({
- "context": lambda x: retriever.get_relevant_documents(x["question"]),
- "question": lambda x: x["question"]
- })
-
- chain = inputs | prompt | model | output_parser
-
- chain
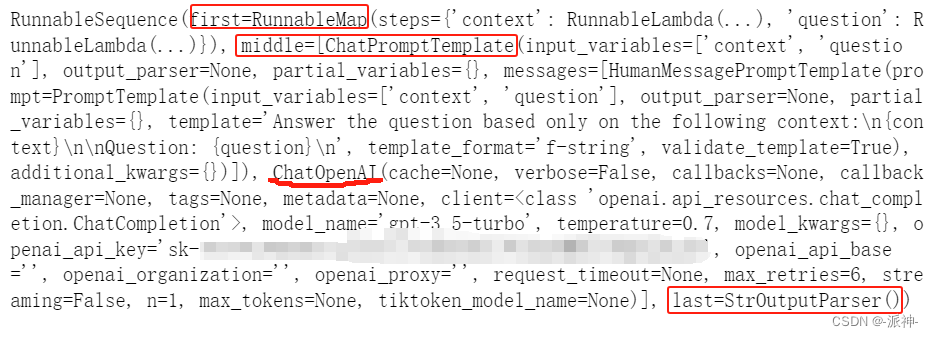
这里我们看到chain中的first部分为RunnableMap的相关信息,在middle中包含了两部分信息(prompt模板和llm模型),last部分仍然为输出解析器,下面我们还是使用invoke方法来调用该chain:
chain.invoke({"question": "人从哪里来?"})![]()
chain.invoke({"question": "熊猫喜欢吃什么?"})![]()
前面我们在prompt中设置了两个变量:“context”和 "question", 由于我们创建这个chain的时候将RunnableMap放置在prompt 前面,所以RunnableMap需要为prompt中的“context”和 "question"这两个变量提供数据,我们来看看RunnableMap所提供的数据:
inputs.invoke({"question": "人从哪里来?"}) 
这里我们看到 RunnableMap为context变量提供了和问题相关的两篇文档,为question变量提供了用户的问题,最终LLM会从相关问题中总结出最优的答案来返回给用户。
三、绑定(Bind)
在之前的OpenAI的函数调用这篇博客中我们讨论了openai的函数调用功能,openai的llm会根据用户提供的外部函数功能的描述信息,来判断在回答用户的问题时是否需要调用该外部函数,如何需要调用外部函数,则返回调用函数所需的参数(该参数从用户问题中提炼出来的)。下面我们用langchain来实现openai的函数调用功能,不过首先我们需要创建一个函数描述信息,这里我们仍然使用上一篇博客中的关于城市天气的查询函数get_current_weather:
- functions = [
- {
- "name": "get_current_weather",
- "description": "Get the current weather in a given location",
- "parameters": {
- "type": "object",
- "properties": {
- "location": {
- "type": "string",
- "description": "The city and state, e.g. San Francisco, CA",
- },
- "unit": {
- "type": "string",
- "enum": ["celsius", "fahrenheit"]},
- },
- "required": ["location"],
- },
- }
- ]
接下来我们使用.bind方法将外部函数描述信息绑定到llm上:
- #根据模板创建prompt
- prompt = ChatPromptTemplate.from_messages(
- [
- ("human", "{input}")
- ]
- )
- #创建openai模型并绑定函数描述信息
- model = ChatOpenAI(temperature=0).bind(functions=functions)
-
- runnable = prompt | model
-
- runnable

这里我们看到runnable的first部分为prompt模板,middel部分为空,last部分包含了openai的模型信息以及函数描述信息kwargs。下面我们来实现通过提交用户问题并返回函数参数的功能:
- response = runnable.invoke({"input": "上海的天气怎么样?"})
- response

这里我们看到了返回信息中包含了function_call和arguments,我们可以从arguments中提取所需的参数:
- arguments = response.additional_kwargs['function_call']['arguments']
- print(arguments)

下面我们将在functions变量中同时定义两个函数的描述信息,然后让llm来判断当用户提问时应该调用哪个函数,这两个函数中一个是之前的查询天气的函数:get_current_weather,另一个是商品信息查询函数:product_search。查询天气的函数get_current_weather接受的参数为location即所在城市的名称,商品信息查询函数product_search接受的参数为product_name即商品名称。
- functions = [
- {
- "name": "get_current_weather",
- "description": "Get the current weather in a given location",
- "parameters": {
- "type": "object",
- "properties": {
- "location": {
- "type": "string",
- "description": "The city and state, e.g. San Francisco, CA",
- },
- "unit": {
- "type": "string",
- "enum": ["celsius", "fahrenheit"]},
- },
- "required": ["location"],
- },
- },
-
- {
- "name": "product_search",
- "description": "Search for product information",
- "parameters": {
- "type": "object",
- "properties": {
- "product_name": {
- "type": "string",
- "description": "The product to search for"
- },
- },
- "required": ["product_name"]
- }
- }
- ]
下面我们来向llm询问有关手机的问题:
- model = model.bind(functions=functions)
-
- runnable = prompt | model
-
- response = runnable.invoke({"input": "请问iphone14 pro 现在卖什么价格?"})
- response

从上面的返回信息中我们可以看到当我们询问iphone14 pro 的价格时,llm知道此时需要调用外部函数了,并且返回了调用外部函数的名称为product_search及参数product_name为“iphone14 pro”,这样我们的应用程序就可以直接用product_name变量去调用外部的product_search函数了。同样我们也可以询问天气情况:
- response = runnable.invoke({"input": "上海的天气怎么样?"})
- arguments = response.additional_kwargs['function_call']['arguments']
- print(arguments)

四、后备措施(Fallbacks)
由于早期的openai的模型如"text-davinci-001",这些模型不支持格式化的输出结果即它们都是以字符串的形式输出结果,这会给我们的应用程序解析LLM的输出结果带来很大的麻烦,下面我们使用openai早期模型"text-davinci-001"来回答用户的问题,我们希望llm能以json格式输出结果:
- #导入langchain早期版本openai的llm包
- from langchain.llms import OpenAI
- from langchain.schema.output_parser import StrOutputParser
- import json
-
- #创建输出解析器
- output_parser = StrOutputParser()
-
- #创建llm
- simple_model = OpenAI(
- temperature=0,
- max_tokens=1000,
- model="text-davinci-001"
- )
- #创建一个简单chain
- simple_chain = simple_model |output_parser | json.loads
这里我们定义了一个早期版本的openai的llm:text-davinci-001 和一个simple_chain, 我们希望simple_chainn能以json格式输出结果,所以我们在创建simple_chain时在最后面组合了json.loads以便让simple_chain按json格式输出最终的结果,接下来我们先测试一下这个早期版本的simple_model,我们让simple_model写三首诗,并以josn格式输出,每首诗必须包含:标题,作者和诗的第一句:
- #让llm写三首诗,并以josn格式输出,每首诗必须包含:标题,作者和诗的第一句。
- challenge = "write three poems in a json blob, where each poem is a json blob of a title, author, and first line"
-
- response = simple_model.invoke(challenge)
- response

这里我们看到早期版本的openai的llm无法输出指定格式的内容,它只能输出字符串内容,虽然这里的每首诗都是用"[ ]"隔开,但是它们仍然都在一个大的字符串内,这对于我们解析输出结果非常的不方便,下面我们使用simple_chain 来测试输出结果:
simple_chain.invoke(challenge)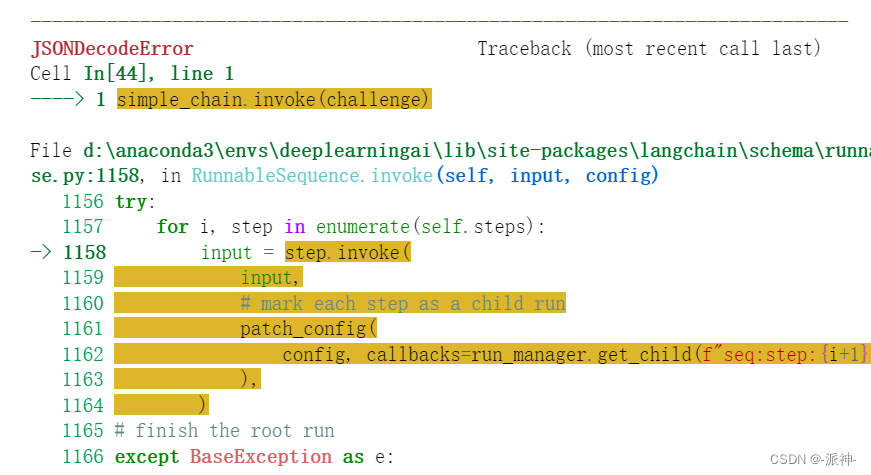
这里我们看到即便我们在创建 simple_chain的时候加了格式化输出项(json.loads),但它仍然无法实现格式化的输出,其中主要的原因还是由于早期版本的openai模型不支持格式的输出,所以即便我们在使用langchain创建chain时加上了格式化输出项(json.loads)也无济于事。下面我们使用较新的gpt-3.5-turbo模型:
- model = ChatOpenAI(temperature=0)
- chain = model | output_parser | json.loads
-
- chain.invoke(challenge)

这里我们看到当我们使用了gpt-3.5-turbo模型(ChatOpenAI默认使用gpt-3.5-turbo模型)时输出结果完全符合我们的要求即全部以json格式输出。如果你的项目用的时早期的“text-davinci-001”模型,在不大幅度修改源代码的情况下是否有办法让早期模型也能做到格式化输出呢?下面我们使用fallbacks的方式来让openai的早期模型也能做到格式化的输出:
- final_chain = simple_chain.with_fallbacks([chain])
- final_chain.invoke(challenge)

这里我们使用了fallbacks方法将早期模型的chain"嫁接"到新模型的chain上,这样就让早期模型的chain也同样可以做到格式化的输出了。
五、接口(Interface)
接口定义了自定义链,并启用了标准化调用。公开的标准接口包括:
- stream:将输出内容已流式返回
- invoke:在输入上调用chain
- batch:在输入列表上调用chain
这些也有相应的异步方法:
- astream:异步将输出内容已流式返回
- ainvoke:在输入上异步调用chain
- abatch:在输入列表上异步调用chain。

下面我们来测试以invoke,batch,stream的方式来调用chain,看看会得到怎样的结果:
- prompt = ChatPromptTemplate.from_template(
- "请给我讲一个关于 {topic}的笑话"
- )
- model = ChatOpenAI()
- output_parser = StrOutputParser()
-
- chain = prompt | model | output_parser
-
- chain.invoke({"topic": "老鼠"})

上面我们使用了常规的invoke调用,并且顺利得到了想要的结果,下面使用batch方法来调用chain即给chain提供一个输入列表,在列表中可以有多个问题,也就是说我们向让llm同时回答多个问题:
chain.batch([{"topic": "猫"}, {"topic": "狗"}])
这里我们看到当我们使用batch调用时,llm可以同时回答了多个问题 ,下面我们使用stream调用即让llm以流的形式返回结果:
- for t in chain.stream({"topic": "bears"}):
- print(t)

这里我们看到当我们使用stream调用时结果将会逐字输出,这可以应用在某些应用场合中,如在web页面中和chatbot交流时,在页面上逐字输出chatbot的回复内容这样会有一个比较好的用户体验,接下来我们使用ainvoke来实现异步调用:
- response = await chain.ainvoke({"topic": "青蛙"})
- response

六、总结
今天我们介绍了LangChain的表达式语言(LCEL)的基础知识,其中包括了简单链(Simple Chain),复杂链(More complex chain),绑定(Bind),后备措施(Fallbacks),接口(Interface)的应用,其中包括对invoke,batch,stream等方法的使用以及相应的异步方法的介绍,希望今天的内容对大家有所帮助。
七、参考资料
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

