
- 1经典面试题:TopK问题(一种思路,两种优化,最终优化到极致)_topk 优化
- 2Android模拟器识别检测技术_antifakerandroidchecker
- 3cvc-complex-type.2.4.a: 发现了以元素 ‘base-extension‘ 开头的无效内容。应以 ‘{layoutlib}‘ 之一开头_cvc-complex-type.2.4.a: 发现了以元素 'extension-level' 开
- 4Android 布局视图生成图片_android视图树生成图片
- 5线程切换的开销
- 6ssm基于安卓的健身appcgua5【独家源码】计算机毕业设计问题的解决方案与方法_基于ssm个性化健身助手平台选题背景
- 7一个安全圈跑龙套的自白-上
- 8wpf chartcontrol 绑定数据_WPF界面开发:你真知道如何将数据绑定到Chart3D中吗?
- 9微带线的ABCD矩阵的推导、转换与级联-Matlab计算实例_s参数db转换成abcd矩阵
- 10keras之模拟线性回归(一)_# 用训练好的模型预测测试集 y_pred = classifier.predict(x_test)
Java的前世今生_java: -source 1.5 中不支持 lambda 表达式 (请使用 -source 8 或
赞
踩

搞Java 6年了,一直想对Java有一个系统的认识,今天终于做了这件事。
转载请注明出处:
http://blog.csdn.net/gane_cheng/article/details/74361498
http://www.ganecheng.tech/blog/74361498.html (浏览效果更好)
Java不仅仅是一门编程语言,还是一个由一系列计算机软件和规范形成的技术体系,这个技术体系提供了完整的用于软件开发和跨平台部署的支持环境,并广泛应用于嵌入式系统、移动终端、企业服务器、大型机等各种场合。时至今日,Java技术体系已经吸引了900多万软件开发者,这是全球最大的软件开发团队。使用Java的设备多达几十亿台,其中包括11亿多台个人计算机、30亿部移动电话及其他手持设备、数量众多的智能卡,以及大量机顶盒、导航系统和其他设备。

Java能获得如此广泛的认可,除了它拥有一门结构严谨、面向对象的编程语言之外,还有许多不可忽视的优点:它摆脱了硬件平台的束缚,实现了“一次编写,到处运行”的理想;它提供了一个相对安全的内存管理和访问机制,避免了绝大部分的内存泄露和指针越界问题;它实现了热点代码检测和运行时编译及优化,这使得Java应用能随着运行时间的增加而获得更高的性能;它有一套完善的应用程序接口,还有无数来自商业机构和开源社区的第三方类库来帮助它实现各种各样的功能……Java所带来的这些好处使程序的开发效率得到了很大的提升。
什么是Java
Java是一种咖啡
Sun公司开发了一种称为Oak的面向对象语言。但是在申请注册商标时,发现Oak已经被人使用了,当时他们正在咖啡馆喝着Java咖啡,有一个人灵机一动说就叫Java怎样,这个提议得到了其他人的赞同。最终Oak语言改名为Java。

Java是一门编程语言
Java是一门面向对象编程语言,不仅吸收了C++语言的各种优点,还摒弃了C++里难以理解的多继承、指针等概念,因此Java语言具有功能强大和简单易用两个特征。Java语言作为静态面向对象编程语言的代表,极好地实现了面向对象理论,允许程序员以优雅的思维方式进行复杂的编程 。
Java具有简单性、面向对象、分布式、健壮性、安全性、平台独立与可移植性、多线程、动态性等特点。Java可以编写桌面应用程序、Web应用程序、分布式系统和嵌入式系统应用程序等。
20世纪90年代,硬件领域出现了单片式计算机系统,这种价格低廉的系统一出现就立即引起了自动控制领域人员的注意,因为使用它可以大幅度提升消费类电子产品(如电视机顶盒、面包烤箱、移动电话等)的智能化程度。Sun公司为了抢占市场先机,在1991年成立了一个称为Green的项目小组,帕特里克、詹姆斯·高斯林、麦克·舍林丹和其他几个工程师一起组成的工作小组在加利福尼亚州门洛帕克市沙丘路的一个小工作室里面研究开发新技术,专攻计算机在家电产品上的嵌入式应用。
由于C++所具有的优势,该项目组的研究人员首先考虑采用C++来编写程序。但对于硬件资源极其匮乏的单片式系统来说,C++程序过于复杂和庞大。另外由于消费电子产品所采用的嵌入式处理器芯片的种类繁杂,如何让编写的程序跨平台运行也是个难题。为了解决困难,他们首先着眼于语言的开发,假设了一种结构简单、符合嵌入式应用需要的硬件平台体系结构并为其制定了相应的规范,其中就定义了这种硬件平台的二进制机器码指令系统(即后来成为“字节码”的指令系统),以待语言开发成功后,能有半导体芯片生产商开发和生产这种硬件平台。对于新语言的设计,Sun公司研发人员并没有开发一种全新的语言,而是根据嵌入式软件的要求,对C++进行了改造,去除了留在C++的一些不太实用及影响安全的成分,并结合嵌入式系统的实时性要求,开发了一种称为Oak的面向对象语言。
由于在开发Oak语言时,尚且不存在运行字节码的硬件平台,所以为了在开发时可以对这种语言进行实验研究,他们就在已有的硬件和软件平台基础上,按照自己所指定的规范,用软件建设了一个运行平台,整个系统除了比C++更加简单之外,没有什么大的区别。1992年的夏天,当Oak语言开发成功后,研究者们向硬件生产商进行演示了Green操作系统、Oak的程序设计语言、类库和其硬件,以说服他们使用Oak语言生产硬件芯片,但是,硬件生产商并未对此产生极大的热情。因为他们认为,在所有人对Oak语言还一无所知的情况下,就生产硬件产品的风险实在太大了,所以Oak语言也就因为缺乏硬件的支持而无法进入市场,从而被搁置了下来。
1994年6、7月间,在经历了一场历时三天的讨论之后,团队决定再一次改变了努力的目标,这次他们决定将该技术应用于万维网。他们认为随着Mosaic浏览器的到来,因特网正在向同样的高度互动的远景演变,而这一远景正是他们在有线电视网中看到的。作为原型,帕特里克·诺顿写了一个小型万维网浏览器WebRunner。
1995年,互联网的蓬勃发展给了Oak机会。业界为了使死板、单调的静态网页能够“灵活”起来,急需一种软件技术来开发一种程序,这种程序可以通过网络传播并且能够跨平台运行。于是,世界各大IT企业为此纷纷投入了大量的人力、物力和财力。这个时候,Sun公司想起了那个被搁置起来很久的Oak,并且重新审视了那个用软件编写的试验平台,由于它是按照嵌入式系统硬件平台体系结构进行编写的,所以非常小,特别适用于网络上的传输系统,而Oak也是一种精简的语言,程序非常小,适合在网络上传输。Sun公司首先推出了可以嵌入网页并且可以随同网页在网络上传输的Applet(Applet是一种将小程序嵌入到网页中进行执行的技术),并将Oak更名为Java(在申请注册商标时,发现Oak已经被人使用了,再想了一系列名字之后,最终,使用了提议者在喝一杯Java咖啡时无意提到的Java词语)。5月23日,Sun公司在Sun world会议上正式发布Java和HotJava浏览器。IBM、Apple、DEC、Adobe、HP、Oracle、Netscape和微软等各大公司都纷纷停止了自己的相关开发项目,竞相购买了Java使用许可证,并为自己的产品开发了相应的Java平台。
Java是一套技术体系
从广义上讲,Clojure、JRuby、Groovy等运行于Java虚拟机上的语言及其相关的程序都属于Java技术体系中的一员。如果仅从传统意义上来看,Sun官方所定义的Java技术体系包括以下几个组成部分:
- Java程序设计语言
- 各种硬件平台上的Java虚拟机
- Class文件格式
- Java API类库
- 来自商业机构和开源社区的第三方Java类库
我们可以把Java程序设计语言、Java虚拟机、Java API类库这三部分统称为JDK(Java Development Kit),JDK是用于支持Java程序开发的最小环境,在后面的内容中,为了讲解方便,有一些地方会以JDK来代替整个Java技术体系。另外,可以把Java API类库中的Java SE API子集和Java虚拟机这两部分统称为JRE(Java Runtime Environment),JRE是支持Java程序运行的标准环境。下图展示了Java技术体系所包含的内容,以及JDK和JRE所涵盖的范围。
以上是根据各个组成部分的功能来进行划分的,如果按照技术所服务的领域来划分,或者说按照Java技术关注的重点业务领域来划分,Java技术体系可以分为4个平台,分别为:
- Java Card:支持一些Java小程序(Applets)运行在小内存设备(如智能卡)上的平台。
- Java ME(Java Platform, Micro Edition Embedded):支持Java程序运行在移动终端(手机、PDA)上的平台,对Java API有所精简,并加入了针对移动终端的支持,这个版本以前称为J2ME。
- Java SE(Java Platform, Standard Edition):支持面向桌面级应用(如Windows下的应用程序)的Java平台,提供了完整的Java核心API,这个版本以前称为J2SE。
- Java EE(Java Platform, Enterprise Edition):支持使用多层架构的企业应用(如ERP、CRM应用)的Java平台,除了提供Java SE API外,还对其做了大量的扩充并提供了相关的部署支持,这个版本以前称为J2EE。
其中,Java SE是标准版本,其他版本则是在此版本上进行了增强或精简。
还有Java TV(面向电视领域)、Java Embedded(面向物联网领域)等平台,但是没有什么影响力。后面将会按照业务领域来介绍。
Java发展史
1991年,Java语言前身Oak项目开始启动,1995年5月23日。Java 1.0版本正式在SunWorld大会上发布。Java语言第一次提出了“Write Once,Run Anywhere”的口号。
目前,JDK已经发展到了1.8版。这么多年还诞生了无数和Java相关的产品、技术和标准。现在让我们走入时间隧道,从孕育Java语言的时代开始,再来回顾一下Java的发展轨迹和历史变迁。
在Java的四个主要平台,Java SE是发展最好也是最迅速的。
1991年4月,由James Gosling博士领导的绿色计划(Green Project)开始启动,此计划的目的是开发一种能够在各种消费性电子产品(如机顶盒、冰箱、收音机等)上运行的程序架构。这个计划的产品就是Java语言的前身:Oak(橡树)。Oak当时在消费品市场上并不算成功,但随着1995年互联网潮流的兴起,Oak迅速找到了最适合自己发展的市场定位并蜕变成为Java语言。
1992年3月,由于Oak已被用作另一种已存在的编程语言名称,因此必须选一个新的名字——它就是Java,灵感来源于咖啡。
1993年2月,电视机顶盒,FirstPerson试图从时代华纳获得一个电视机顶盒交互系统的一揽子订单。在那时,由于绿色计划不是很成功,随即失去了时代华纳的订单。于是开发的重心从家庭消费电子产品转到了电视盒机顶盒的相关平台上。
1995年5月23日,Oak语言改名为Java,并且在SunWorld大会上正式发布Java 1.0版本。Java语言第一次提出了“Write Once,Run Anywhere”的口号。
1996年1月23日,JDK 1.0发布,Java语言有了第一个正式版本的运行环境。JDK 1.0提供了一个纯解释执行的Java虚拟机实现(Sun Classic VM)。JDK 1.0版本的代表技术包括:Java虚拟机、Applet、AWT等。
1996年4月,10个最主要的操作系统供应商申明将在其产品中嵌入Java技术。同年9月,已有大约8.3万个网页应用了Java技术来制作。在1996年5月底,Sun公司于美国旧金山举行了首届JavaOne大会,从此JavaOne成为全世界数百万Java语言开发者每年一度的技术盛会。
1997年2月19日,Sun公司发布了JDK 1.1,Java技术的一些最基础的支撑点(如JDBC等)都是在JDK 1.1版本中发布的,JDK 1.1版的技术代表有:JAR文件格式、JDBC、JavaBeans、RMI。Java语法也有了一定的发展,如内部类(Inner Class)和反射(Reflection)都是在这个时候出现的。
直到1999年4月8日,JDK 1.1一共发布了1.1.0~1.1.8九个版本。从1.1.4之后,每个JDK版本都有一个自己的名字(工程代号),分别为:JDK 1.1.4 - Sparkler(宝石)、JDK 1.1.5 - Pumpkin(南瓜)、JDK 1.1.6 - Abigail(阿比盖尔,女子名)、JDK 1.1.7 - Brutus(布鲁图,古罗马政治家和将军)和JDK 1.1.8 – Chelsea(切尔西,城市名)。
1998年12月4日,JDK迎来了一个里程碑式的版本JDK 1.2,工程代号为Playground(竞技场),Sun在这个版本中把Java技术体系拆分为3个方向,分别是面向桌面应用开发的J2SE(Java 2 Platform, Standard Edition)、面向企业级开发的J2EE(Java 2 Platform, Enterprise Edition)和面向手机等移动终端开发的J2ME(Java 2 Platform, Micro Edition)。在这个版本中出现的代表性技术非常多,如EJB、Java Plug-in、Java IDL、Swing等,并且这个版本中Java虚拟机第一次内置了JIT(Just In Time)编译器(JDK 1.2中曾并存过3个虚拟机,Classic VM、HotSpot VM和Exact VM,其中Exact VM只在Solaris平台出现过;后面两个虚拟机都是内置JIT编译器的,而之前版本所带的Classic VM只能以外挂的形式使用JIT编译器)。在语言和API级别上,Java添加了strictfp关键字与现在Java编码之中极为常用的一系列Collections集合类。
在1999年3月和7月,分别有JDK 1.2.1和JDK 1.2.2两个小版本发布。
1999年4月27日,HotSpot虚拟机发布,HotSpot最初由一家名为“Longview Technologies”的小公司开发,因为HotSpot的优异表现,这家公司在1997年被Sun公司收购了。HotSpot虚拟机发布时是作为JDK 1.2的附加程序提供的,后来它成为了JDK 1.3及之后所有版本的Sun JDK的默认虚拟机。
2000年5月8日,工程代号为Kestrel(美洲红隼)的JDK 1.3发布,JDK 1.3相对于JDK 1.2的改进主要表现在一些类库上(如数学运算和新的Timer API等),JNDI服务从JDK 1.3开始被作为一项平台级服务提供(以前JNDI仅仅是一项扩展),使用CORBA IIOP来实现RMI的通信协议,等等。这个版本还对Java 2D做了很多改进,提供了大量新的Java 2D API,并且新添加了JavaSound类库。JDK 1.3有1个修正版本JDK 1.3.1,工程代号为Ladybird(瓢虫),于2001年5月17日发布。
自从JDK 1.3开始,Sun维持了一个习惯:大约每隔两年发布一个JDK的主版本,以动物命名,期间发布的各个修正版本则以昆虫作为工程名称。
2002年2月13日,JDK 1.4发布,工程代号为Merlin(灰背隼)。JDK 1.4是Java真正走向成熟的一个版本,Compaq、Fujitsu、SAS、Symbian、IBM等著名公司都有参与甚至实现自己独立的JDK 1.4。哪怕是在十多年后的今天,仍然有许多主流应用(spring、hibernate、Struts等)能直接运行在JDK 1.4之上,或者继续发布能运行在JDK 1.4上的版本。JDK 1.4同样发布了很多新的技术特性,如正则表达式、异常链、NIO、日志类、XML解析器和XSLT转换器等。
JDK 1.4有两个后续修正版:
2002年9月16日发布的工程代号为Grasshopper(蚱蜢)的JDK 1.4.1
2003年6月26日发布的工程代号为Mantis(螳螂)的JDK 1.4.2。
2002年前后还发生了一件与Java没有直接关系,但事实上对Java的发展进程影响很大的事件,那就是微软公司的.NET Framework发布了。这个无论是技术实现上还是目标用户上都与Java有很多相近之处的技术平台给Java带来了很多讨论、比较和竞争,.NET平台和Java平台之间声势浩大的孰优孰劣的论战到目前为止都在继续。
2004年9月30日,JDK 1.5发布,工程代号Tiger(老虎)。从JDK 1.2以来,Java在语法层面上的变换一直很小,而JDK 1.5在Java语法易用性上做出了非常大的改进。例如,自动装箱、泛型、动态注解、枚举、可变长参数、遍历循环(foreach循环)等语法特性都是在JDK 1.5中加入的。在虚拟机和API层面上,这个版本改进了Java的内存模型(Java Memory Model,JMM)、提供了java.util.concurrent并发包等。另外,JDK 1.5是官方声明可以支持Windows 9x平台的最后一个JDK版本。
2006年12月11日,JDK 1.6发布,工程代号Mustang(野马)。在这个版本中,Sun终结了从JDK 1.2开始已经有8年历史的J2EE、J2SE、J2ME的命名方式,启用Java SE 6、Java EE 6、Java ME 6的命名方式。JDK 1.6的改进包括:提供动态语言支持(通过内置Mozilla Java Rhino引擎实现)、提供编译API和微型HTTP服务器API等。同时,这个版本对Java虚拟机内部做了大量改进,包括锁与同步、垃圾收集、类加载等方面的算法都有相当多的改动。
在2006年11月13日的JavaOne大会上,Sun公司宣布最终会将Java开源,并在随后的一年多时间内,陆续将JDK的各个部分在GPL v2(GNU General Public License v2)协议下公开了源码,并建立了OpenJDK组织对这些源码进行独立管理。除了极少量的产权代码(Encumbered Code,这部分代码大多是Sun本身也无权限进行开源处理的)外,OpenJDK几乎包括了Sun JDK的全部代码,OpenJDK的质量主管曾经表示,在JDK 1.7中,Sun JDK和OpenJDK除了代码文件头的版权注释之外,代码基本上完全一样,所以OpenJDK 7与Sun JDK 1.7本质上就是同一套代码库开发的产品。
JDK 1.6发布以后,由于代码复杂性的增加、JDK开源、开发JavaFX、经济危机及Sun收购案等原因,Sun在JDK发展以外的事情上耗费了很多资源,JDK的更新没有再维持两年发布一个主版本的发展速度。JDK 1.6到目前为止一共发布了37个Update版本,最新的版本为java se 6 Update 37,于2012年10月16日发布。
2009年2月19日,工程代号为Dolphin(海豚)的JDK 1.7完成了其第一个里程碑版本。根据JDK 1.7的功能规划,一共设置了10个里程碑。最后一个里程碑版本原计划于2010年9月9日结束,但由于各种原因,JDK 1.7最终无法按计划完成。
从JDK 1.7最开始的功能规划来看,它本应是一个包含许多重要改进的JDK版本,其中的Lambda项目(Lambda表达式、函数式编程)、Jigsaw项目(虚拟机模块化支持)、动态语言支持、GarbageFirst收集器和Coin项目(语言细节进化)等子项目对于Java业界都会产生深远的影响。在JDK 1.7开发期间,Sun公司由于相继在技术竞争和商业竞争中都陷入泥潭,公司的股票市值跌至仅有高峰时期的3%,已无力推动JDK 1.7的研发工作按正常计划进行。为了尽快结束JDK 1.7长期“跳票”的问题,Oracle公司收购Sun公司后不久便宣布将实行“B计划”,大幅裁剪了JDK 1.7预定目标,以便保证JDK 1.7的正式版能够于2011年7月28日准时发布。“B计划”把不能按时完成的Lambda项目、Jigsaw项目和Coin项目的部分改进延迟到JDK 1.8之中。最终,JDK 1.7的主要改进包括:提供新的G1收集器(G1在发布时依然处于Experimental状态,直至2012年4月的Update 4中才正式“转正”)、加强对非Java语言的调用支持(JSR-292,这项特性到目前为止依然没有完全实现定型)、升级类加载架构等。
到目前为止,JDK 1.7已经发布了9个Update版本,最新的Java SE 7 Update 9于2012年10月16日发布。从Java SE 7 Update 4起,oracle开始支持Mac OS X操作系统,并在Update 6中达到完全支持的程度,同时,在Update 6中还对ARM指令集架构提供了支持。至此,官方提供的JDK可以运行于Windows(不含Windows 9x)、Linux、Solaris和Mac OS平台上,支持ARM、x86、x64和Sparc指令集架构类型。
2009年4月20日,Oracle公司宣布正式以74亿美元的价格收购Sun公司,Java商标从此正式归Oracle所有(Java语言本身并不属于哪间公司所有,它由JCP组织进行管理,尽管JCP主要是由Sun公司或者说Oracle公司所领导的)。由于此前Oracle公司已经收购了另外一家大型的中间件企业BEA公司,在完成对Sun公司的收购之后,Oracle公司分别从BEA和Sun中取得了目前三大商业虚拟机的其中两个:JRockit和HotSpot,Oracle公司宣布在未来1~2年的时间内,将把这两个优秀的虚拟机互相取长补短,最终合二为一。可以预见在不久的将来,Java虚拟机技术将会产生相当巨大的变化。
2011年7月28日,Oracle公司发布Java SE 1.7
2014年3月18日,Oracle公司发表Java SE 1.8
Java语言有下面一些特点 :简单、面向对象、分布式、解释执行、鲁棒、安全、体系结构中立、可移植、高性能、多线程以及动态性。
| 版本 | 描述 |
|---|---|
| 1991年1月 | Sun公司成立了Green项目小组,专攻智能家电的嵌入式控制系统 |
| 1991年2月 | 放弃C++,开发新语言,命名为“Oak” |
| 1991年6月 | JamesGosling开发了Oak的解释器 |
| 1992年1月 | Green完成了Green操作系统、Oak语言、类库等开发 |
| 1992年11月 | Green计划转化成“FirstPerson”,一个Sun公司的全资母公司 |
| 1993年2月 | 获得时代华纳的电视机顶盒交互系统的订单,于是开发的重心从家庭消费电子产品转到了电视盒机顶盒的相关平台上。 |
| 1994年6月 | FirstPerson公司倒闭,员工都合并到Sun公司。Liveoak计划启动了,目标是使用Oak语言设计出一个操作系统。 |
| 1994年7月 | 第一个Java语言的Web浏览器WebRunner(后来改名为HotJava),Oak更名为Java。 |
| 1994年10月 | VanHoff编写的Java编译器用于Java语言 |
| 1995年3月 | 在SunWorld大会,Sun公司正式介绍了Java和HotJava。 |
| 1996年1月 | JDK1.0发布 |
| 1997年2月 | J2SE1.1发布 |
| 1998年12月 | J2SE1.2发布 |
| 1999年6月 | 发布Java的三个版本:J2SE、J2EE、J2ME |
| 2000年5月 | J2SE1.3发布 |
| 2001年9月 | J2EE1.3发布 |
| 2002年2月 | J2SE1.4发布 |
| 2004年9月 | J2SE1.5发布,将J2SE1.5改名JavaSE5.0 |
| 2005年6月 | JavaSE6.0发布,J2EE更名为JavaEE,J2SE更名为JavaSE,J2ME更名为JavaME |
| 2006年12月 | JRE6.0发布 |
| 2006年12月 | JavaSE6发布 |
| 2009年12月 | JavaEE6发布 |
| 2009年4月 | Oracle收购Sun |
| 2011年7月 | JavaSE7发布 |
| 2014年3月 | JavaSE8发布 |
JDK历史版本轨迹
大部分的JDK历史版本(JDK 1.1.6之后的版本),以及JDK所附带的各种工具的历史版本,都可以从Oracle公司的网站上下载到。
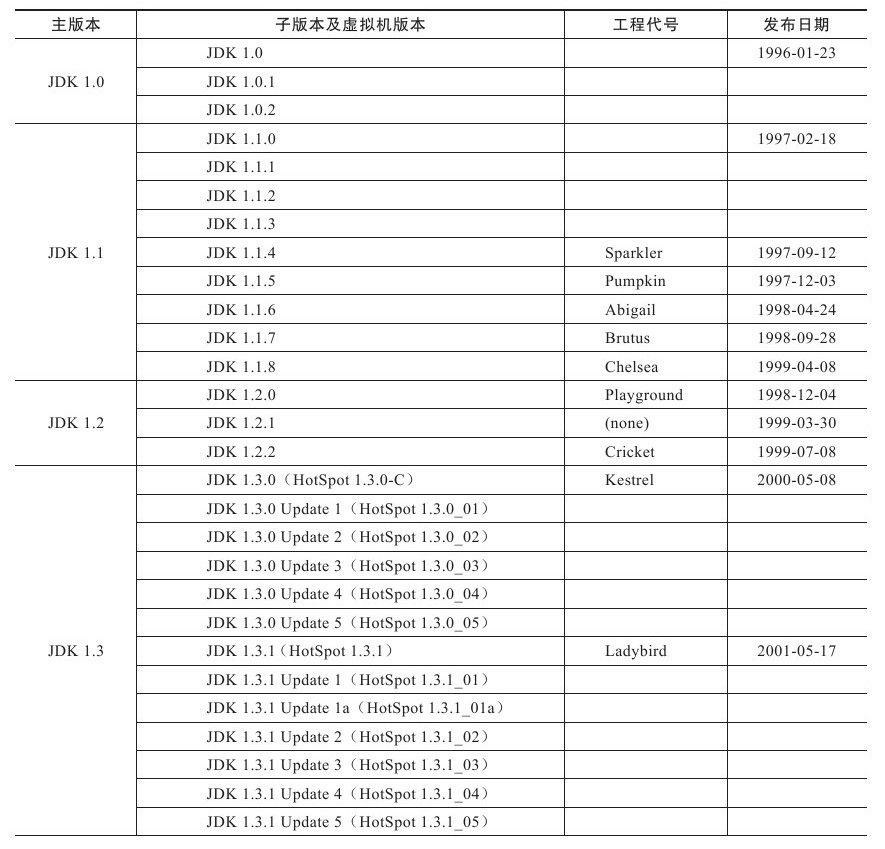

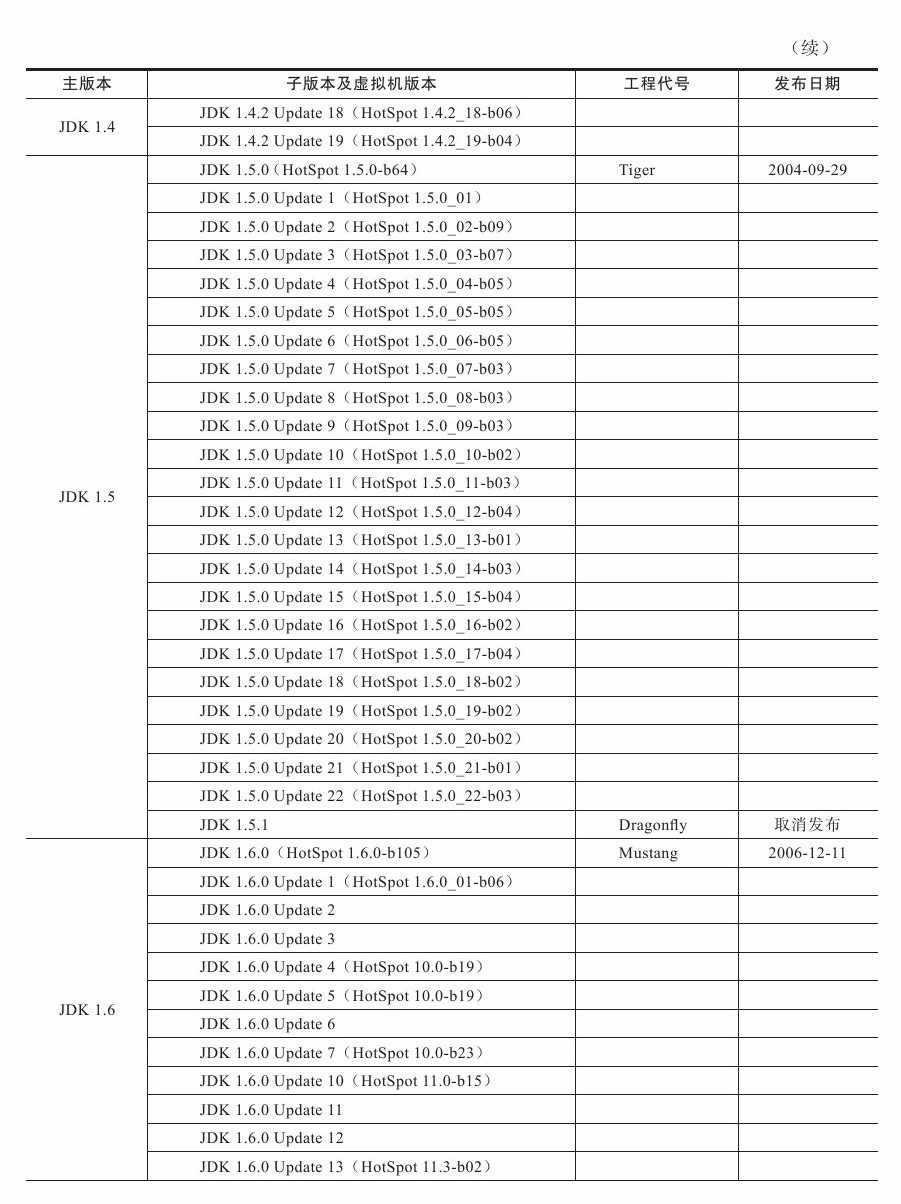
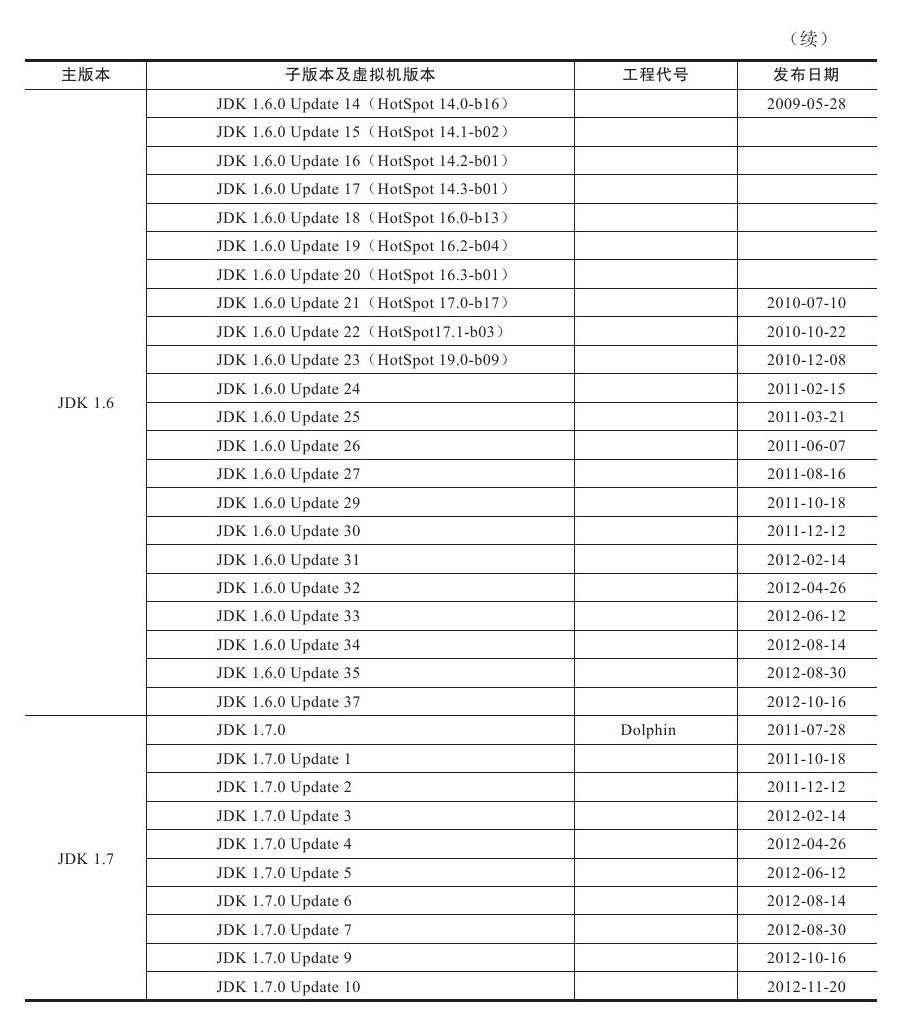
Java虚拟机发展史
Java虚拟机(Java Virtual Machine 简称JVM)是运行所有Java程序的抽象计算机,是Java语言的运行环境,它是Java 最具吸引力的特性之一。
Java语言的一个非常重要的特点就是与平台的无关性。而使用Java虚拟机是实现这一特点的关键。一般的高级语言如果要在不同的平台上运行,至少需要编译成不同的目标代码。而引入Java语言虚拟机后,Java语言在不同平台上运行时不需要重新编译。Java语言使用模式Java虚拟机屏蔽了与具体平台相关的信息,使得Java语言编译程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。Java虚拟机在执行字节码时,把字节码解释成具体平台上的机器指令执行。
Java虚拟机是Java语言底层实现的基础。这有助于理解Java语言的一些性质,也有助于使用Java语言。对于要在特定平台上实现Java虚拟机的软件人员,Java语言的编译器作者以及要用硬件芯片实现Java虚拟机的人来说,则必须深刻理解Java虚拟机的规范。另外,如果你想扩展Java语言,或是把其它语言编译成Java语言的字节码,你也需要深入地了解Java虚拟机。
从1996年初Sun公司发布的JDK 1.0中所包含的Sun Classic VM到今天,曾经涌现、湮灭过许多或经典或优秀或有特色的虚拟机实现,在这一节中,我们先暂且把代码与技术放下,一起来回顾一下Java虚拟机家族的发展轨迹和历史变迁。
Sun Classic/Exact VM
以今天的视角来看,Sun Classic VM的技术可能很原始,这款虚拟机的使命也早已终结。但仅凭它“世界上第一款商用Java虚拟机”的头衔,就足够有让历史记住它的理由。
1996年1月23日,Sun公司发布JDK 1.0,Java语言首次拥有了商用的正式运行环境,这个JDK中所带的虚拟机就是Classic VM。这款虚拟机只能使用纯解释器方式来执行Java代码,如果要使用JIT编译器,就必须进行外挂。但是假如外挂了JIT编译器,JIT编译器就完全接管了虚拟机的执行系统,解释器便不再工作了。用户在这款虚拟机上执行java-version命令,将会看到类似下面这行输出:
java version"1.2.2"
Classic VM(build JDK-1.2.2-001,green threads,sunwjit)- 1
- 2
其中的“sunwjit”就是Sun提供的外挂编译器,其他类似的外挂编译器还有Symantec JIT和shuJIT等。由于解释器和编译器不能配合工作,这就意味着如果要使用编译器执行,编译器就不得不对每一个方法、每一行代码都进行编译,而无论它们执行的频率是否具有编译的价值。基于程序响应时间的压力,这些编译器根本不敢应用编译耗时稍高的优化技术,因此这个阶段的虚拟机即使用了JIT编译器输出本地代码,执行效率也和传统的C/C++程序有很大差距,“Java语言很慢”的形象就是在这时候开始在用户心中树立起来的。
Sun的虚拟机团队努力去解决Classic VM所面临的各种问题,提升运行效率。在JDK 1.2时,曾在Solaris平台上发布过一款名为Exact VM的虚拟机,它的执行系统已经具备现代高性能虚拟机的雏形:如两级即时编译器、编译器与解释器混合工作模式等。Exact VM因它使用准确式内存管理(Exact Memory Management,也可以叫Non-Conservative/Accurate Memory Management)而得名,即虚拟机可以知道内存中某个位置的数据具体是什么类型。譬如内存中有一个32位的整数123456,它到底是一个reference类型指向123456的内存地址还是一个
值为123456的整数,虚拟机将有能力分辨出来,这样才能在GC(垃圾收集)的时候准确判断堆上的数据是否还可能被使用。由于使用了准确式内存管理,Exact VM可以抛弃以前Classic VM基于handler的对象查找方式(原因是进行GC后对象将可能会被移动位置,如果将地址为123456的对象移动到654321,在没有明确信息表明内存中哪些数据是reference的前提下,虚拟机是不敢把内存中所有为123456的值改成654321的,所以要使用句柄来保持reference值的稳定),这样每次定位对象都少了一次间接查找的开销,提升执行性能。
虽然Exact VM的技术相对Classic VM来说先进了许多,但是在商业应用上只存在了很短暂的时间就被更为优秀的HotSpot VM所取代,甚至还没有来得及发布Windows和Linux平台下的商用版本。而Classic VM的生命周期则相对长了许多,它在JDK 1.2之前是Sun JDK中唯一的虚拟机,在JDK 1.2时,它与HotSpot VM并存,但默认使用的是Classic VM(用户可用java-
hotspot参数切换至HotSpot VM),而在JDK 1.3时,HotSpot VM成为默认虚拟机,但Classic VM仍作为虚拟机的“备用选择”发布(使用java-classic参数切换),直到JDK 1.4的时候,Classic VM才完全退出商用虚拟机的历史舞台,与Exact VM一起进入了Sun Labs Research VM之中。
Sun HotSpot VM
提起HotSpot VM,相信所有Java程序员都知道,它是Sun JDK和OpenJDK中所带的虚拟机,也是目前使用范围最广的Java虚拟机。但不一定所有人都知道的是,这个目前看起来“血统纯正”的虚拟机在最初并非由Sun公司开发,而是由一家名为“Longview Technologies”的小公司设计的;甚至这个虚拟机最初并非是为Java语言而开发的,它来源于Strongtalk VM,而这款虚拟机中相当多的技术又是来源于一款支持Self语言实现“达到C语言50%以上的执行效率”的目标而设计的虚拟机,Sun公司注意到了这款虚拟机在JIT编译上有许多优秀的理念和实际效果,在1997年收购了Longview Technologies公司,从而获得了HotSpot VM。
HotSpot VM既继承了Sun之前两款商用虚拟机的优点(如前面提到的准确式内存管理),也有许多自己新的技术优势,如它名称中的HotSpot指的就是它的热点代码探测技术(其实两个VM基本上是同时期的独立产品,HotSpot还稍早一些,HotSpot一开始就是准确式GC,而Exact VM之中也有与HotSpot几乎一样的热点探测。为了Exact VM和HotSpot VM哪个成为Sun主要支持的VM产品,在Sun公司内部还有过争论,HotSpot打败Exact并不能算技术上的胜利),HotSpot VM的热点代码探测能力可以通过执行计数器找出最具有编译价值的代码,然后通知JIT编译器以方法为单位进行编译。如果一个方法被频繁调用,或方法中有效循环次数很多,将会分别触发标准编译和OSR(栈上替换)编译动作。通过编译器与解释器恰当地协同工作,可以在最优化的程序响应时间与最佳执行性能中取得平衡,而且无须等待本地代码输出才能执行程序,即时编译的时间压力也相对减小,这样有助于引入更多的代码优化技术,输出质量更高的本地代码。
在2006年的JavaOne大会上,Sun公司宣布最终会把Java开源,并在随后的一年,陆续将JDK的各个部分(其中当然也包括了HotSpot VM)在GPL协议下公开了源码,并在此基础上建立了OpenJDK。这样,HotSpot VM便成为了Sun JDK和OpenJDK两个实现极度接近的JDK项目的共同虚拟机。
在2008年和2009年,Oracle公司分别收购了BEA公司和Sun公司,这样Oracle就同时拥有了两款优秀的Java虚拟机:JRockit VM和HotSpot VM。Oracle公司宣布在不久的将来(大约应在发布JDK 8的时候)会完成这两款虚拟机的整合工作,使之优势互补。整合的方式大致上是在HotSpot的基础上,移植JRockit的优秀特性,譬如使用JRockit的垃圾回收器与MissionControl服务,使用HotSpot的JIT编译器与混合的运行时系统。
Sun Mobile-Embedded VM/Meta-Circular VM
Sun公司所研发的虚拟机可不仅有前面介绍的服务器、桌面领域的商用虚拟机,除此之外,Sun公司面对移动和嵌入式市场,也发布过虚拟机产品,另外还有一类虚拟机,在设计之初就没抱有商用的目的,仅仅是用于研究、验证某种技术和观点,又或者是作为一些规范的标准实现。这些虚拟机对于大部分不从事相关领域开发的Java程序员来说可能比较陌生。Sun公司发布的其他Java虚拟机有:
(1)KVM
KVM中的K是“Kilobyte”的意思,它强调简单、轻量、高度可移植,但是运行速度比较慢。在Android、iOS等智能手机操作系统出现前曾经在手机平台上得到非常广泛的应用。
(2)CDC/CLDC HotSpot Implementation
CDC/CLDC全称是Connected(Limited)Device Configuration,在JSR-139/JSR-218规范中进行定义,它希望在手机、电子书、PDA等设备上建立统一的Java编程接口,而CDC-HI VM和CLDC-HI VM则是它们的一组参考实现。CDC/CLDC是整个Java ME的重要支柱,但从目前Android和iOS二分天下的移动数字设备市场看来,在这个领域中,Sun的虚拟机所面临的局面远不如服务器和桌面领域乐观。
(3)Squawk VM
Squawk VM由Sun公司开发,运行于Sun SPOT(Sun Small Programmable Object
Technology,一种手持的WiFi设备),也曾经运用于Java Card。这是一个Java代码比重很高的嵌入式虚拟机实现,其中诸如类加载器、字节码验证器、垃圾收集器、解释器、编译器和线程调度都是Java语言本身完成的,仅仅靠C语言来编写设备I/O和必要的本地代码。
(4)JavaInJava
JavaInJava是Sun公司于1997年~1998年间研发的一个实验室性质的虚拟机,从名字就可以看出,它试图以Java语言来实现Java语言本身的运行环境,既所谓的“元循环”(Meta-Circular,是指使用语言自身来实现其运行环境)。它必须运行在另外一个宿主虚拟机之上,内部没有JIT编译器,代码只能以解释模式执行。在20世纪末主流Java虚拟机都未能很好解决性能问题的时代,开发这种项目,其执行速度可想而知。
(5)Maxine VM
Maxine VM和上面的JavaInJava非常相似,它也是一个几乎全部以Java代码实现(只有用于启动JVM的加载器使用C语言编写)的元循环Java虚拟机。这个项目于2005年开始,到现在仍然在发展之中,比起JavaInJava,Maxine VM就显得“靠谱”很多,它有先进的JIT编译器和垃圾收集器(但没有解释器),可在宿主模式或独立模式下执行,其执行效率已经接近了HotSpot Client VM的水平。
BEA JRockit/IBM J9 VM
前面介绍了Sun公司的各种虚拟机,除了Sun公司以外,其他组织、公司也研发过不少虚拟机实现,其中规模最大、最著名的就是BEA和IBM公司了。
JRockit VM曾经号称“世界上速度最快的Java虚拟机”(广告词,貌似J9 VM也这样说过),它是BEA公司在2002年从Appeal Virtual Machines公司收购的虚拟机。BEA公司将其展为一款专门为服务器硬件和服务器端应用场景高度优化的虚拟机,由于专注于服务器端应用,它可以不太关注程序启动速度,因此JRockit内部不包含解析器实现,全部代码都靠即时编译器编译后执行。除此之外,JRockit的垃圾收集器和MissionControl服务套件等部分的实现,在众多Java虚拟机中也一直处于领先水平。
IBM J9 VM并不是IBM公司唯一的Java虚拟机,不过是目前其主力发展的Java虚拟机。IBM J9 VM原本是内部开发代号,正式名称是“IBM Technology for Java Virtual Machine”,简称IT4J,只是这个名字太拗口了一点,普及程度不如J9。J9 VM最初是由IBM Ottawa实验室一个名为SmallTalk的虚拟机扩展而来的,当时这个虚拟机有一个bug是由8k值定义错误引起的,工程师花了很长时间终于发现并解决了这个错误,此后这个版本的虚拟机就称为K8了,后来扩展出支持Java的虚拟机就被称为J9了。与BEA JRockit专注于服务器端应用不同,IBMJ9的市场定位与Sun HotSpot比较接近,它是一款设计上从服务器端到桌面应用再到嵌入式都全面考虑的多用途虚拟机,J9的开发目的是作为IBM公司各种Java产品的执行平台,它的主要市场是和IBM产品(如IBM WebSphere等)搭配以及在IBM AIX和z/OS这些平台上部署Java应用。
Azul VM/BEA Liquid VM
我们平时所提及的“高性能Java虚拟机”一般是指HotSpot、JRockit、J9这类在通用平台上运行的商用虚拟机,但其实Azul VM和BEA Liquid VM这类特定硬件平台专有的虚拟机才是“高性能”的武器。
Azul VM是Azul Systems公司在HotSpot基础上进行大量改进,运行于Azul Systems公司的专有硬件Vega系统上的Java虚拟机,每个Azul VM实例都可以管理至少数十个CPU和数百GB内存的硬件资源,并提供在巨大内存范围内实现可控的GC时间的垃圾收集器、为专有硬件优化的线程调度等优秀特性。在2010年,Azul Systems公司开始从硬件转向软件,发布了自己的Zing JVM,可以在通用x86平台上提供接近于Vega系统的特性。
Liquid VM即是现在的JRockit VE(Virtual Edition),它是BEA公司开发的,可以直接运行在自家Hypervisor系统上的JRockit VM的虚拟化版本,Liquid VM不需要操作系统的支持,或者说它自己本身实现了一个专用操作系统的必要功能,如文件系统、网络支持等。由虚拟机越过通用操作系统直接控制硬件可以获得很多好处,如在线程调度时,不需要再进行内核态/用户态的切换等,这样可以最大限度地发挥硬件的能力,提升Java程序的执行性能。
Apache Harmony/Google Android Dalvik VM
这节介绍的Harmony VM和Dalvik VM只能称做“虚拟机”,而不能称做“Java虚拟机”,但是这两款虚拟机(以及所代表的技术体系)对最近几年的Java世界产生了非常大的影响和挑战,甚至有些悲观的评论家认为成熟的Java生态系统有崩溃的可能。
Apache Harmony是一个Apache软件基金会旗下以Apache License协议开源的实际兼容于JDK 1.5和JDK 1.6的Java程序运行平台,这个介绍相当拗口。它包含自己的虚拟机和Java库,用户可以在上面运行Eclipse、Tomcat、Maven等常见的Java程序,但是它没有通过TCK认证,所以我们不得不用那么一长串拗口的语言来介绍它,而不能用一句“Apache的JDK”来说明。如果一个公司要宣布自己的运行平台“兼容于Java语言”,那就必须要通过TCK(Technology Compatibility Kit)的兼容性测试。Apache基金会曾要求Sun公司提供TCK的使用授权,但是一直遭到拒绝,直到Oracle公司收购了Sun公司之后,双方关系越闹越僵,最终导致Apache愤然退出JCP(Java Community Process)组织,这是目前为止Java社区最严重的一次“分裂”。
在Sun将JDK开源形成OpenJDK之后,Apache Harmony开源的优势被极大地削弱,甚至连Harmony项目的最大参与者IBM公司也宣布辞去Harmony项目管理主席的职位,并参与OpenJDK项目的开发。虽然Harmony没有经过真正大规模的商业运用,但是它的许多代码(基本上是Java库部分的代码)被吸纳进IBM的JDK 7实现及Google Android SDK之中,尤其是对Android的发展起到了很大的推动作用。
说到Android,这个时下最热门的移动数码设备平台在最近几年间的发展过程中所取得的成果已经远远超越了Java ME在过去十多年所获得的成果,Android让Java语言真正走进了移动数码设备领域,只是走的并非Sun公司原本想象的那一条路。
Dalvik VM是Android平台的核心组成部分之一,它的名字来源于冰岛一个名为Dalvik的小渔村。Dalvik VM并不是一个Java虚拟机,它没有遵循Java虚拟机规范,不能直接执行Java的Class文件,使用的是寄存器架构而不是JVM中常见的栈架构。但是它与Java又有着千丝万缕的联系,它执行的dex(Dalvik Executable)文件可以通过Class文件转化而来,使用Java语法编写应用程序,可以直接使用大部分的Java API等。目前Dalvik VM随着Android一起处于迅猛发展阶段,在Android 2.2中已提供即时编译器实现,在执行性能上有了很大的提高。
Microsoft JVM及其他
在十几年的Java虚拟机发展过程中,除去上面介绍的那些被大规模商业应用过的Java虚拟机外,还有许多虚拟机是不为人知的或者曾经“绚丽”过但最终湮灭的。我们以其中微软公司的JVM为例来介绍一下。
也许Java程序员听起来可能会觉得惊讶,微软公司曾经是Java技术的铁杆支持者(也必须承认,与Sun公司争夺Java的控制权,令Java从跨平台技术变为绑定在Windows上的技术是微软公司的主要目的)。在Java语言诞生的初期(1996年~1998年,以JDK 1.2发布为分界),它的主要应用之一是在浏览器中运行Java Applets程序,微软公司为了在IE3中支持Java Applets应用而开发了自己的Java虚拟机,虽然这款虚拟机只有Windows平台的版本,却是当时Windows下性能最好的Java虚拟机,它在1997年和1998年连续两年获得了《PCMagazine》杂志的“编辑选择奖”。但好景不长,在1997年10月,Sun公司正式以侵犯商标、不正当竞争等罪名控告微软公司,在随后对微软公司的垄断调查之中,这款虚拟机也曾作为证据之一被呈送法庭。这场官司的结果是微软公司赔偿2000万美金给Sun公司(最终微软公司因垄断赔偿给Sun公司的总金额高达10亿美元),承诺终止其Java虚拟机的发展,并逐步在产品中移除Java虚拟机相关功能。具有讽刺意味的是,到最后在Windows XP SP3中Java虚拟机被完全抹去的时候,Sun公司却又到处登报希望微软公司不要这样做 [1] 。Windows XP高级产品经理Jim Cullinan称:“我们花费了3年的时间和Sun打官司,当时他们试图阻止我们在Windows中支持Java,现在我们这样做了,可他们又在抱怨,这太具有讽刺意味了。”
我们试想一下,如果当年Sun公司没有起诉微软公司,微软公司继续保持着对Java技术的热情,那Java的世界会变得怎么样呢?.NET技术是否会发展起来?但历史是没有假设的。其他在本节中没有介绍到的Java虚拟机还有:
JamVM.
cacaovm.
SableVM.
Kaffe.
Jelatine JVM.
NanoVM.
MRP.
Moxie JVM.
Jikes RVM.
Java相关组织
Sun:1980年代初期由斯坦福大学三位年轻学生创立的公司。Java的发明,使得Sun真正有机会在软件的历史天空中放射出太阳的光芒。Sun发明了Java,并且在长达十年的时间里始终走在Java大潮的最前端。Sun是Java的老家,是Java慈爱的母亲,这一切任何人都改变不了。虽然Sun似乎没能够从Java中获得应有的金钱回报,但这丝毫没有挫伤Sun对于Java的母爱,还有对于Java大潮的舍我其谁的领导气概。 所有人都迷恋富有的感觉,但是也迟早会意识到钱不是世上最宝贵的东西。这个世界并不缺少会赚钱的公司,但是能够靠着创新型技术推动整个世界进步的公司却是凤毛麟角。Sun应该感到骄傲,他们将因为Java而在历史的天空里发射出太阳的光芒。
IBM : Java经济的最大受益人 。Sun公司是Java的发明人,但IBM却是Java最大的受益者。
BEA : 用WebLogic Server证明了Java有着大型企业级应用的强悍功能。
Oracle:为Java提供数据库支持,并在后来收购了Sun公司。
Apache:开源软件的品牌保证。Apache这个名字在Java的世界中实在太出名了,以至于“Apache”这六个字母成为开源项目品质保证的代名词。
JBoss:职业开源软件组织。
JCP:Java世界的联合国。JCP(Java Community Process)在1998年由Sun发起成立,目标是通过一个开放、合作和鼓励参与的非盈利组织来发展和推进Java和相关的技术。正是由于JCP计划的推出可以让所有对Java感兴趣的软硬件厂商,个人和组织都能参与到技术规范的制定和发展过程中,协调各方的兴趣和利益、集思广益,才可以让Java在短短的几年内异军突起,成为可以和微软开发平台抗衡的一个主流开发语言。JCP计划既然是一个组织,自然也有一定的架构。JCP组织架构主要包括PMO(Program Management Office)、JCP成员、EC、EG。事实上,JCP的架构就好像一个Java世界的联合国。虽然也有不少人批评JCP成为各派利益的角力场,因而效率低下;但是,它毕竟为Java的顺利发展很好地掌握了方向。
JavaOne:Sun公司举办的Java开发者大会。
SpringOne:作为非常成熟的Java框架,Spring一直有拥有大规模的用户。Spring每年也会举办开发者大会。
Eclipse基金会:这个开源组织拥有众多项目,其中就包含了最为出名的Java IDE Eclipse。
Java SE介绍
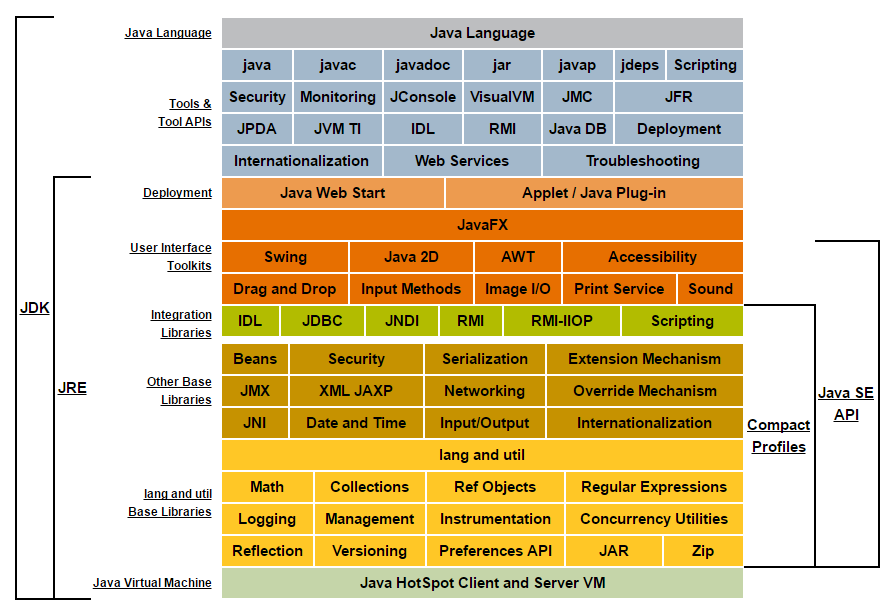
Java SE 是Java平台标准版的简称(Java Platform, Standard Edition),用于开发和部署桌面、服务器以及嵌入设备和实时环境中的Java应用程序。同时,Java SE为Java EE和Java ME提供了基础。
Oracle有两款产品可以用来实现Java SE 8:Java SE Development Kit (JDK) 8 和Java SE Runtime Environment (JRE) 8。
JDK 8是JRE 8的超集,包含JRE 8的一切,加上必要的用于开发程序的编译器和调试器。JRE 8提供库、Java虚拟机和运行Java程序需要的组件。注意,JRE包含不是由Java SE规格要求的组件,包括标准和非标准的Java 组件。
Java SE的概念图如下图所示。
Java Language
Tools & Tool APIs
java
javac
javadoc
jar
javap
JPDA
JConsole
Java VisualVM
Java DB
Security
Internationalization
RMI
IDL
Deploy
Monitoring
Troubleshoot
Scripting
JVM TI
Web Services
Deployment
Java Web Start
Applet / Java Plug-in
User Interface Toolkits
JavaFX
AWT
Swing
Java 2D
Accessibility
Drag and Drop
Input Methods
Image I/O
Print Service
Sound
Integration Libraries
IDL
JDBC
JNDI
RMI
RMI-IIOP
Scripting
Other Base Libraries
Beans
Int’l Support
Input/Output
JMX
JNI
Math
Networking
Override Mechanism
Security
Serialization
Extension Mechanism
XML JAXP
lang and util Base Libraries
lang and util
Collections
Concurrency Utilities
JAR
Logging
Management
Preferences API
Ref Objects
Reflection
Regular Expressions
Versioning
Zip
Instrumentation
Java Virtual Machine
Java Hotspot Client and Server VM
JDK包含上面所有的部分。
JRE包含以下的部分。
Deployment
User Interface Toolkits
Integration Libraries
Other Base Libraries
lang and util Base Libraries
Java Virtual Machine
Java SE API包含以下的部分。
User Interface Toolkits except JavaFX
Integration Libraries
Other Base Libraries
lang and util Base Libraries
紧凑型API包含以下部分。
Integration Libraries
Other Base Libraries
lang and util Base Libraries
下面依次介绍。
Java Language Java语言
Java语言的学习可以看《Think In Java》这本书。这本书介绍了Java的语法。在此书中将Java语言的学习分为了以下22个部分。
对象导论
一切都是对象
操作符
控制执行流程
初始化与清理
访问权限控制
复用类
多态
接口
内部类
持有对象
通过异常处理错误
字符串
类型信息
泛型
数组
容器深入研究
Java I/O系统
枚举类型
注解
并发
图形化用户界面
对象导论
万物皆为对象。
程序是对象的集合,它们通过发送消息来告知彼此所要做的。
每个对象都有自己的由其他对象所构成的存储。
每个对象都拥有其类型。
某一特定类型的所有对象都可以接收同样的消息。
一切都是对象
在Java中用引用操纵对象。
创建一个String对象的引用s。
String s;- 1
初始化引用s。
s=new String("abc");- 1
Java中的对象存储在”堆”里,但是基本类型需要特殊对待,直接存储基本类型的“值”到“堆栈”中。
Java要确定每种基本类型所占存储空间的大小。它们的大小并不像其他大多数语言那样随机器硬件架构的变化而变化。这种所占存储空间大小的不变性是Java程序比用其他大多数语言编写的程序更具有可移植性的原因之一。
| 基本类型 | 大小 | 最小值 | 最大值 | 包装器类型 | 默认值 |
|---|---|---|---|---|---|
| boolean | - | - | - | Boolean | false |
| char | 16-bit | Unicode 0 | Unicode 2^16-1 | Character | ‘\u0000’(null) |
| byte | 8 bits | -128 | +127 | Byte | (byte)0 |
| short | 16 bits | -2^15 | +2^15-1 | Short | (short)0 |
| int | 32 bits | -2^31 | +2^31-1 | Integer | 0 |
| long | 64 bits | -2^63 | +2^63-1 | Long | 0L |
| float | 32 bits | IEEE754 | IEEE754 | Float | 0.0f |
| double | 64 bits | IEEE754 | IEEE754 | Double | 0.0d |
| void | - | - | - | Void | - |
所有数值类型都有正负号,所以不要去寻找无符号的数值类型。
boolean类型所占存储空间的大小没有明确指定,仅定义为能够取字面值true或false。
基本类型具有的包装器类,使得可以在堆中创建一个非基本类型对象,用来表示对应的基本类型。
对于高精度计算,Java提供了两个用于高精度计算的类:BigInteger和BigDecimal。虽然它们大体上属于“包装器类”的范畴,但二者都没有对应的基本类型。
不过这两个类包含的方法,提供的操作与对基本类型所能执行的操作类似。也就是说,能作用于int或float的操作,也同样能作用于BigInteger或BigDecimal。只不过必须以方法调用方式取代运算符方式来实现。由于这么做复杂了许多,所以运算速度会比较慢。在这里,以速度换取了高精度。这两个类支持任意精度的数值进行数学计算,不会丢失任何信息。
如果类的某个成员是基本数据类型,即使没有进行初始化,Java也会确保它获得一个默认值。
当变量作为类的成员使用时,Java才确保给定其默认值,以确保那些是基本类型的成员变量得到初始化(C++没有此功能),防止产生程序错误。但是,这些初始值对你的程序来说,可能是不正确的,甚至是不合法的。所以最好明确地对变量进行初始化。
然而上述确保初始化的方法并不适用于“局部”变量(即并非某个类的字段)。因此,如果在某个方法定义中有:
int x;- 1
那么变量x得到的可能是任意值(与C和C++中一样),而不会被自动初始化为零。所以在使用x前,应先对其赋一个适当的值。如果忘记了这么做,Java会在编译时返回一个错误,告诉你此变量没有初始化。
操作符
在最底层,Java中的数据是通过使用操作符来操作的,和大多数编程语言一样。
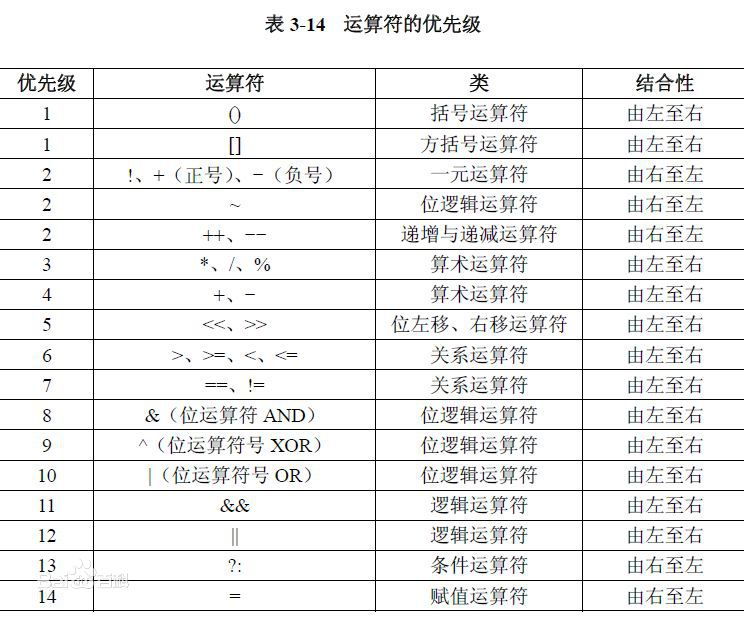
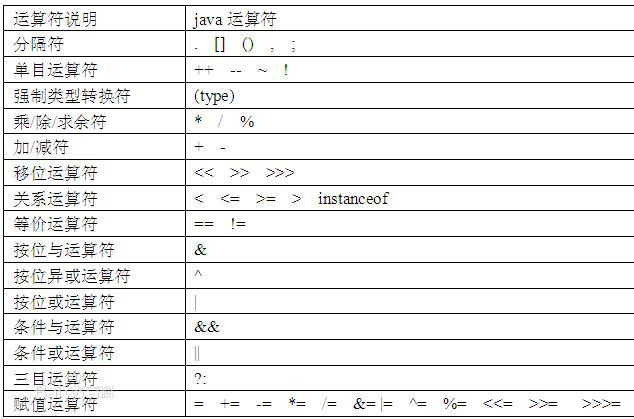
控制执行流程
就像有知觉的生物一样,程序必须在执行过程中控制它的世界,并做出选择。在Java中,你要使用执行控制语句来做出选择。所有条件语句都利用条件表达式的真或假来决定执行路径。
if-else
while、do-while、for、foreach
return、break、continue
switch
初始化与清理
随着计算机革命的发展,“不安全”的变成方式已逐渐成为编程代价高昂的主因之一。
Java中可以使用构造方法来对类中的成员变量进行初始化。清理则由Java虚拟机中的垃圾回收器在适当的时候回收不会再被使用到的对象,也有可能永远不会被清理到。
访问权限控制
| - | 类内部 | package内 | 子类 | 其他 |
|---|---|---|---|---|
| public | √ | √ | √ | √ |
| protected | √ | √ | √ | × |
| default | √ | √ | × | × |
| private | √ | × | × | × |
复用类
复用类有三种方式,继承,组合,代理。
多态
多态通过分离做什么和怎么做,从另一角度将接口和实现分离开来。多态不但能够改善代码的组织结构和可读性,还能够创建可扩展的程序。
使用向上转型和向下转型可以在基类和子类之间进行转换。
接口
在接口中的任何成员变量都自动是static和final的。在接口中的方法都是抽象方法。
内部类
可以将一个类的定义放在另一个类的定义内部,这就是内部类。
通过内部类提供闭包的功能是优良的解决方案,它比指针更灵活、更安全。
持有对象
Java提供了大量持有对象的方式,说人话,就是Java有很多集合类。
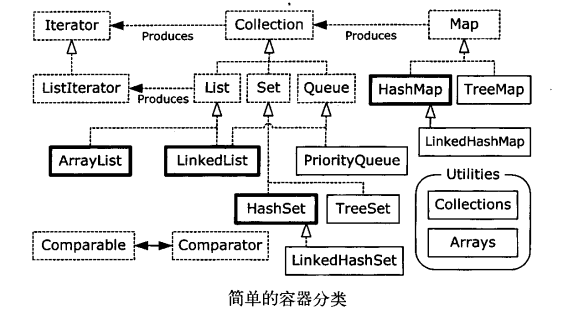
通过异常处理错误
Java的基本理念是“结构不佳的代码不能运行”。
发现错误的理想时机是在编译阶段,也就是在你试图运行程序之前。然而,编译期间并不能找出所有的错误,余下的问题必须在运行期间解决。Java中的异常处理的目的在于通过使用少于目前数量的代码来简化大型、可靠的程序的生成,并且通过这种方式可以使你更加自信:你的应用中没有未处理的错误。
throws
throw new Exception("");
try{}
catch(){}
finally{}- 1
- 2
- 3
- 4
- 5
- 6
- 7
字符串
字符串操作是计算机程序设计中最常见的行为。
String对象是不可变的。
正则表达式是一种强大而灵活的文本处理工具。可以构造复杂的文本模式来匹配字符串。
类型信息
运行时类型信息使得你可以在程序运行时发现和使用类型信息。
Java在运行时识别对象和类的信息有两种方式:一种是“传统的”RTTI,它假定我们在编译时已经知道了所有的类型;另一种是“反射”机制,它允许我们在运行时发现和使用类的信息。
==
equals()
instanceof
isInstance()- 1
- 2
- 3
- 4
Class类与java.lang.reflect类库一起对反射的概念进行了支持,该类库包含了Field、Method以及Constructor类。这样你就可以使用Constructor创建新的对象,用get()和set()方法读取和修改与Field对象关联的字段,用invoke()方法调用与Method对象关联的方法。另外,还可以调用getFields()、getMethods()和getConstructors()等很便利的方法,以返回表示字段、方法以及构造器的对象的数组。
泛型
泛型实现了参数化类型的概念,使代码可以应用于多种类型。为了更方便的创造容器类,Java中也出现了泛型。尽管是基于装箱拆箱实现的。
数组
优先使用容器而不是数组。只有当切换到数组对性能有所帮助时,才需要用数组。
容器深入研究
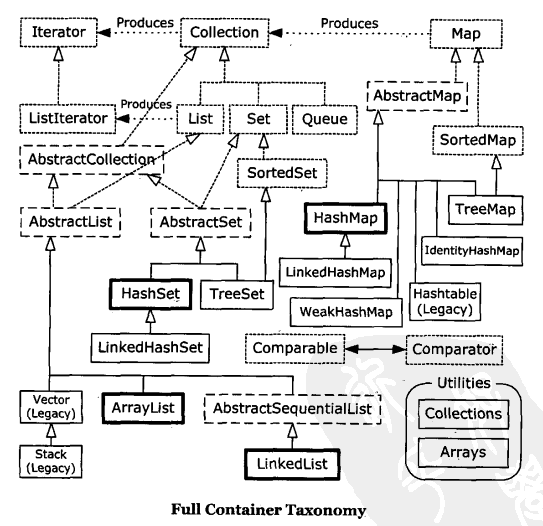
Java I/O系统
对程序语言的设计者来说,创建一个好的输入/输出(I/O)系统是一项艰难的任务。
不仅存在各种I/O源端和想要与之通信的接收端(文件、控制台、网络链接等),而且还需要以多种不同的方式与它们进行通信(顺序、随机存取、缓冲、二进制、按字符、按行、按字等)。
File-InputStream-Reader- 1
枚举类型
调用enum的values()方法,可以遍历enum实例。
注解
注解在一定程度上是在把元数据与源代码文件结合在一起,而不是保存在外部文档中这一大的趋势之下所催生的。通过使用注解,我们可以将这些元数据保存在Java源代码中,并利用annotation API为自己的注解构造处理工具,同时,注解的优点还包括:更加干净易读的代码以及编译期类型检查等。虽然Java SE预先定义了一些元数据,但一般来说,主要还是需要程序员自己添加新的注解,并且按自己的方式使用它们。
Java内置了三种标准注解和四种元注解。标准注解可以直接使用,元注解专职负责注解其他的注解。
三种标准注解。
@Override,表示当前的方法定义将覆盖超类中的方法。如果你不小心拼写错误,或者方法签名对不上被覆盖的方法,编译器就会发出错误提示。
@Deprecated,如果程序员为它的元素使用了注解,那么编译器会发出警告信息。
@SuppressWarnings,关闭不当的编译器警告信息。
四种元注解。

大多数时候,程序员主要是定义自己的注解,并编写自己的处理器来处理它们,就像SpringMVC那样。
并发
并发的实质是一个物理CPU(也可以多个物理CPU) 在若干道程序之间多路复用,并发性是对有限物理资源强制行使多用户共享以提高效率。
并行性指两个或两个以上事件或活动在同一时刻发生。在多道程序环境下,并行性使多个程序同一时刻可在不同CPU上同时执行。
并发,是在同一个cpu上同时(不是真正的同时,而是看来是同时,因为cpu要在多个程序间切换)运行多个程序。
并行,是每个cpu运行一个程序。
打个比方。并发,就像一个人(cpu)喂2个孩子(程序),轮换着每人喂一口,表面上两个孩子都在吃饭。并行,就是2个人喂2个孩子,两个孩子也同时在吃饭。
图形化用户界面
Java提供了AWT和Swing库来实现图形用户界面。
Tools & Tool APIs 工具及工具API
Java提供了一些帮助开发人员的工具。这些工具在JDK安装目录的bin目录下都可以找到。并且,在Java中也提供了相应的API直接调用,不用新开一个进程去处理。下面依次介绍。
java
java命令可以用来启动一个Java应用程序。
详细用法参考这里。
http://docs.oracle.com/javase/8/docs/technotes/tools/windows/java.html
javac
javac是Java语言的编译器,读入Java语言源码文件,编译成字节码文件。
详细用法参考这里。
http://docs.oracle.com/javase/8/docs/technotes/guides/javac/index.html
javadoc
Javadoc是一个转换工具,可以将源码中的声明信息,文档注释信息转换成HTML页面来描述类、接口、构造方法、方法和成员变量。
详细用法参考这里。
http://docs.oracle.com/javase/8/docs/technotes/guides/javadoc/index.html
jar
JAR(Java Archive)是一种将许多文件聚集成一个文件的与平台无关的文件格式。
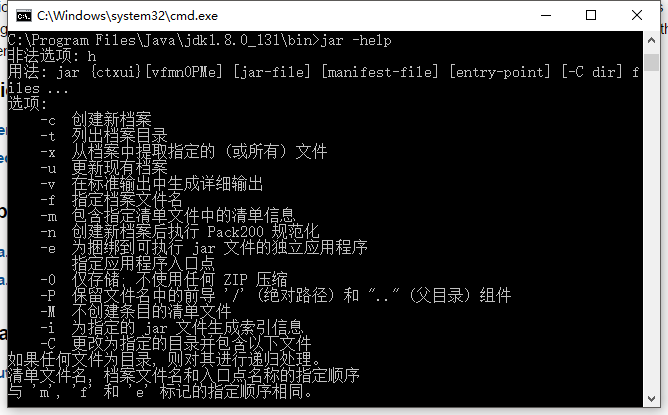
如何打包生成JAR文件的详细用法参考这里。
http://docs.oracle.com/javase/8/docs/technotes/guides/jar/index.html
javap
javap命令可以反编译类文件。将类文件反编译成容易阅读的代码。默认输出包,protected和public修饰的成员变量、方法。
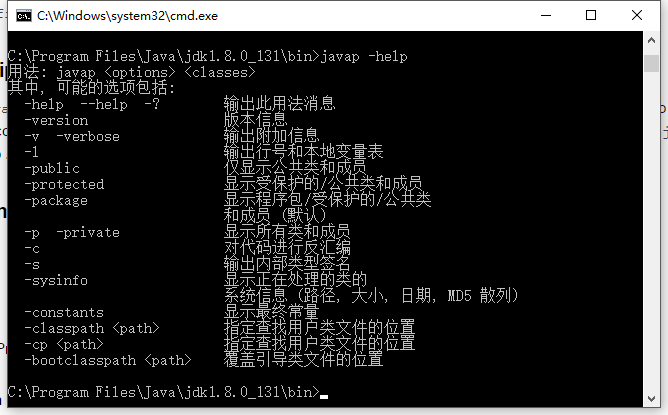
详细用法参考这里。
http://docs.oracle.com/javase/8/docs/technotes/tools/windows/javap.html
jdeps
Java类依赖分析器。
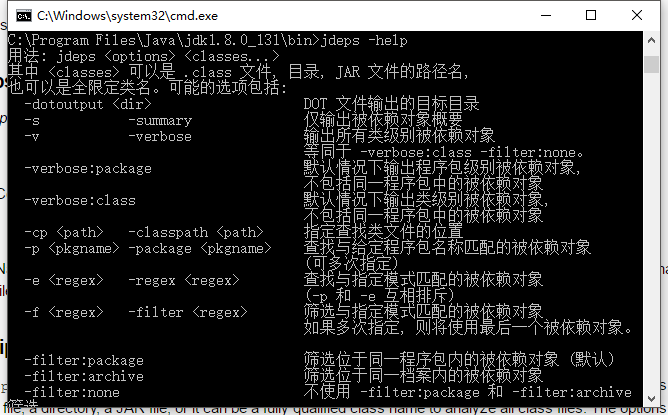
详细用法参考这里。
http://docs.oracle.com/javase/8/docs/technotes/tools/windows/jdeps.html
Scripting Tools
Java还提供了脚本工具方便Java代码与脚本代码之间交互。Java SE 8中提供了两个脚本工具jjs和jrunscript。
jjs被推荐使用,jjs运行时将调用Nashorn引擎。
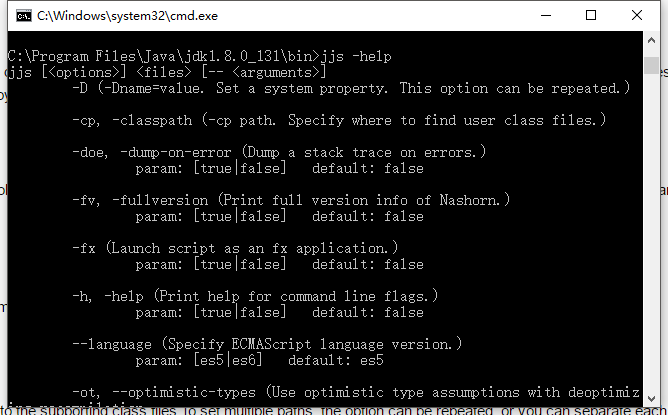
详细用法可以参考以下两个链接。
http://docs.oracle.com/javase/8/docs/technotes/tools/windows/jjs.html
http://www.infoq.com/cn/articles/nashorn
Security Tools
Java提供了一些安全工具,方便为程序设置安全策略。
keytool:可以生成密钥和证书。参考这里。
jarsigner:可以为JAR文件生成签名并验证。参考这里。
policytool:用于管理策略文件带界面的工具。参考这里。
kinit:用于获取Kerberos v5凭证的工具。参考这里。
klist:用于列出凭证缓存中的条目。参考这里。
ktab:用于帮助用户管理凭证键表中的条目。参考这里。
Monitoring Tools
Java提供了一些监控JVM性能统计数据的工具。
jps:JVM进程状态工具,列出运行中的HotSpot JVM进程。参考这里。
jstat:JVM统计监控工具。参考这里。
jstatd:jstat工具的守护工具,确保远程监控工具可以连接到JVM。参考这里。
jconsole
一个图形界面工具,可以监控和管理运行的Java程序。
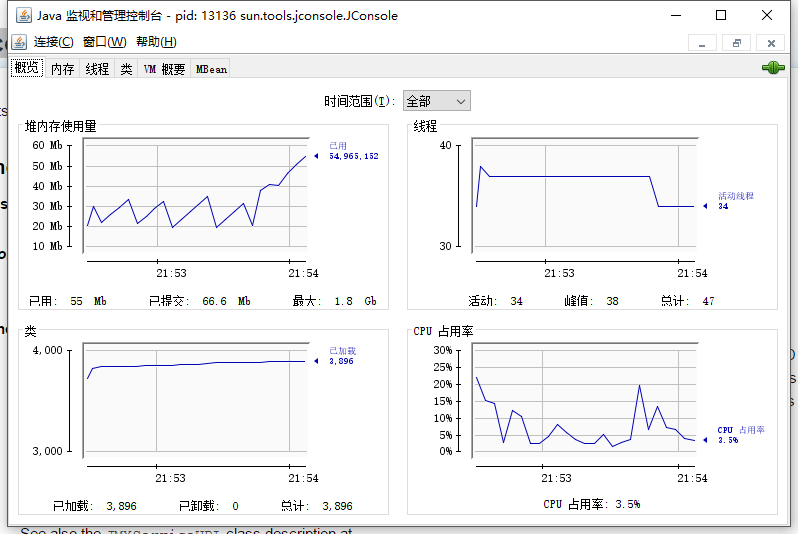
使用方法可以参考这里。
http://docs.oracle.com/javase/8/docs/technotes/guides/management/jconsole.html
Java VisualVM
Java VisualVM是一个工具,可以提供一个用户界面,监控运行在JVM上的Java程序的详细信息,帮助分析并排除程序中的问题。
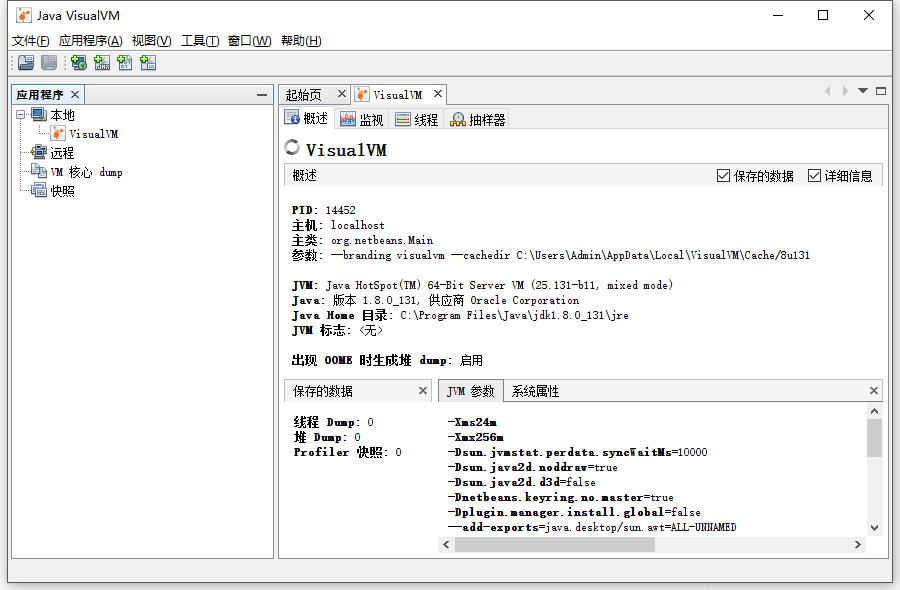
使用方法可以参考这里。
http://docs.oracle.com/javase/8/docs/technotes/guides/visualvm/index.html
Java Mission Control
Java Mission Control也是一个性能分析工具。
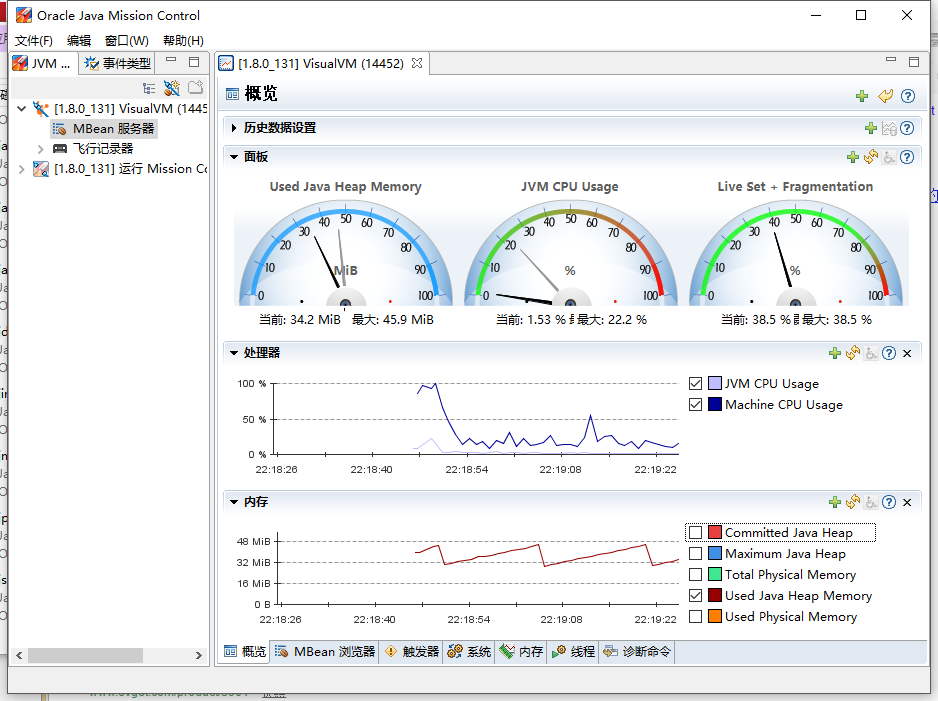
用法参考这里。
https://docs.oracle.com/javacomponents/jmc-5-5/jmc-user-guide/toc.htm
Java Flight Recorder
Java Flight Recorder集成在Java Mission Control工具中。也是用来监控Java程序运行状态的。
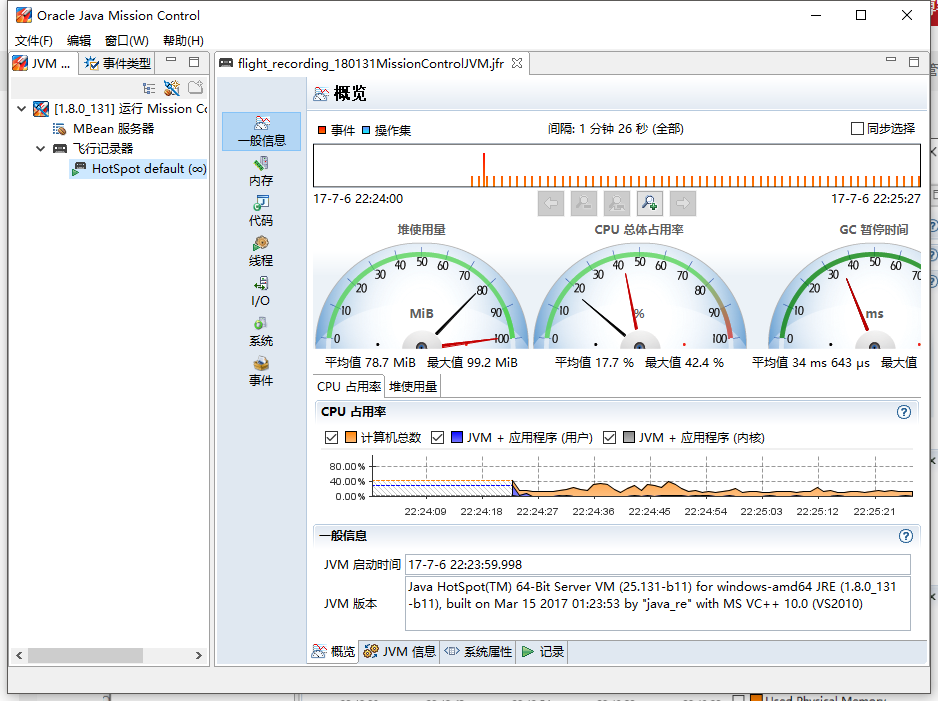
用法参考这里。
https://docs.oracle.com/javacomponents/jmc-5-5/jfr-runtime-guide/toc.htm
JPDA
JPDA(Java Platform Debugger Architecture)是Java平台调试体系结构的缩写。由3个规范组成,分别是JVM TI(JVM Tool Interface),JDWP(Java Debug Wire Protocol),JDI(Java Debug Interface) 。
既然是规范,当然就有实现。Sun公司自己在jdk中提供了一套实现,比如java调试工具jdb,就是sun公司提供的JDI实现 。
其他厂商也可以提供自己的实现。目前,大多数的JDI实现都是通过Java语言编写的。比如,eclipse IDE,它的两个插件org.eclipse.jdt.debug.ui和org.eclipse.jdt.debug与其强大的调试功能密切相关,其中前者是eclipse调试工具界面的实现,而后者则是JDI的一个完整实现 。
想要了解更多可以参考这里。
http://docs.oracle.com/javase/8/docs/technotes/guides/jpda/index.html
http://kyfxbl.iteye.com/blog/1697203
JVM TI
JVM Tool Interface (JVM TI)是一个给监控工具使用的编程接口。它可以控制正在JVM中运行的程序。
详细使用可以参考这里。
http://docs.oracle.com/javase/8/docs/platform/jvmti/jvmti.html
Java IDL and RMI-IIOP Tools
Java IDL(Interface Definition Language)可实现网络上不同平台上的对象相互之间的交互,该技术基于通用对象请求代理体系结构CORBA规范说明。IDL是不依赖于语言的接口定义语言,所有支持CORBA的语言都有IDL到该语言的映射。就像其名字所表示的那样,Java IDL支持到Java语言的映射。CORBA规范说明和IDL映射是由OMG(Object Management Group)定义的。OMG由700多个成员组成,Sun公司是其成员之一,它在定义IDL到Java映射的工作中起了主要作用。
包含四个工具tnameserv、idlj、orbd和servertool,已经超出我的认知范围了,想要了解更多,直接看这里。
http://docs.oracle.com/javase/8/docs/technotes/tools/index.html#idl
Remote Method Invocation (RMI) Tools
Java RMI 指的是远程方法调用 (Remote Method Invocation)。它是一种机制,能够让在某个 Java 虚拟机上的对象调用另一个 Java 虚拟机中的对象上的方法。可以用此方法调用的任何对象必须实现该远程接口。
Java RMI不是什么新技术(在Java1.1的时代都有了),但却是是非常重要的底层技术。大名鼎鼎的EJB都是建立在RMI基础之上的,现在还有一些开源的远程调用组件,其底层技术也是RMI。
RMI工具有四个,rmic、rmiregistry、rmid和serialver。想了解更多直接看这里。
http://docs.oracle.com/javase/8/docs/technotes/tools/index.html#rmi
Java DB
Java DB是一个基于Java语言和SQL的关系型数据库管理系统。Java DB是Apache Derby项目的Oracle版本。Java DB包含在JDK中。
了解更多参考这里。
http://docs.oracle.com/javadb/index.html
Java Deployment Tools
部署Java应用程序和applet相关的工具。提供了三个工具。
javapackager:执行打包应用程序和签名Java和JavaFx应用程序相关的工作。
pack200:使用Java的gzip压缩器将一个JAR文件转换为一个压缩的pack200文件。压缩之后的打包文件是高压缩率的JAR文件,可以直接被部署,节省宽带,减少下载时间。
unpack200:将一个用pack200打包的文件转为一个JAR文件
Internationalization Tools
这个工具帮助创建本地化程序。利用native2ascii工具可以将文本转为Unicode Latin-1编码。
Java Web Services Tools
提供与Web Service相关的工具。有四个,schemagen、wsgen、wsimport和xjc。不想多说Web Service,想了解更多的看这里。
http://docs.oracle.com/javase/8/docs/technotes/tools/index.html#webservices
Troubleshooting Tools
Java提供了一些故障排除的工具。
Jinfo:Java的配置信息。打印给定进程或者核心文件或者一个远程调试服务器的配置信息。
Jhat:堆栈转储浏览器。在堆栈转储文件上启动一个web服务器(例如,jmap -dump),允许堆栈被浏览。
Jmap:Java的内存映射。打印共享的对象内存映射或者给定进程、核心文件和远程调试服务器的堆栈内存细节。
Jsadebugd:Java的代理调试守护进程。附加到一个进程、核心文件或者作为一个调试服务器。
Jstack:Java堆栈跟踪。打印一个给定的进程中一个线程、核心文件或者远程调试服务器的堆栈。
Deployment 部署
使用部署工具可以轻松地发布自己编写的程序。里面包含Java Web Start,和Applet / Java Plug-in两个部分,为什么这东西还要放在JDK中。
一般都可以通过IDE导出可部署的程序,喜欢手动生成的直接看这里吧。
http://docs.oracle.com/javase/8/docs/technotes/guides/deploy/index.html
User Interface Toolkits 用户界面工具集
用户界面工具集提供了构建图形用户界面所需要的工具。提供了JavaFX、Swing、Java 2D、AWT、Accessibility、Drag and Drop、Input Methods、Image I/O、Print Service、Sound。
下面依次介绍。
JavaFX
JavaFX是用于构建富互联网应用程序的Java库。 使用此库编写的应用程序可以跨多个平台一致运行。使用JavaFX开发的应用程序可以在各种设备上运行,如台式计算机,手机,电视,平板电脑等。
要使用Java编程语言开发GUI应用程序,程序员依赖于诸如AWT和Swings之类的库。在JavaFX出现之后,这些Java程序开发就可以有效地利用丰富的类库来开发GUI应用程序。
这是继Applet之后Java又折腾出来的一个东西,用来和Adobe Flash、Microsoft Silverlight竞争RIA(Rich Internet Applications)市场。但是很明显,这些东西在HTML5的普及下不堪一击,都走进历史的尘埃中。
AWT
AWT(Abstract Window Toolkit):抽象窗口工具包,早期编写图形界面应用程序的包。
Swing
为解决 AWT 存在的问题而新开发的图形界面包。Swing是对AWT的改良和扩展。
Java 2D
Java 2D API可以创建和操作图形和图像。
Accessibility
方便残疾人使用Java应用程序的一组API。
Drag and Drop
拖放API方便程序内或程序间通过拖放传递数据。
Input Methods
用来和输入法交互的一组API。
Image I/O
Java提供了一些处理图像的API。
Print Service
Java提供的和打印机交互的一组API。
Sound
Java提供的和声音处理相关的API。
Integration Libraries 集成库
IDL
Java IDL(Interface Definition Language)可实现网络上不同平台上的对象相互之间的交互,该技术基于通用对象请求代理体系结构CORBA(Common Object Request Broker Architecture,公共对象请求代理体系结构)规范说明。
JDBC
Java JDBC API可以方便地在Java语言中操作各大数据库。
JNDI
JNDI(Java Naming and Directory Interface)是一个应用程序设计的API,为开发人员提供了查找和访问各种命名和目录服务的通用、统一的接口,类似JDBC都是构建在抽象层上。现在JNDI已经成为J2EE的标准之一,所有的J2EE容器都必须提供一个JNDI的服务。
RMI
Java Remote Method Invocation (Java RMI) ,Java远程方法调用API方便程序员创建分布式的Java程序,在不同Java虚拟机之间相互调用方法。
RMI-IIOP
RMI以Java为核心,可与采用本机方法与现有系统相连接。IIOP,Internet Inter-ORB Protocol(互联网内部对象请求代理协议),它是一个用于CORBA 2.0及兼容平台上的协议。通过支持IIOP协议,Java EE应用程序就可以使用RMI-IIOP来访问CORBA服务。
Scripting
方便Java语言与脚本语言交互的一组API。
Other Base Packages 其它基本包
I/O
用于程序输入输出。
Object Serialization
用于对象序列化和反序列化。
Networking
提供网络相关的功能。
Security
提供安全相关的功能。
Internationalization
提供国际化相关的功能。
JavaBeans Component API
JavaBeans是Java中一种特殊的类,可以将多个对象封装到一个对象中。特点是可序列化,提供无参构造器,提供getter方法和setter方法访问对象的属性。
Java Management Extensions (JMX)
The Java Management Extensions (JMX) API是一套API来管理和监控程序、设备、服务、虚拟机的资源。是为应用程序植入管理功能的框架。
XML (JAXP)
Java提供了XML处理的API。
Java Native Interface (JNI)
JNI是Java Native Interface的缩写,它提供了若干的API实现了Java和其他语言的通信(主要是C&C++)。从Java1.1开始,JNI标准成为java平台的一部分,它允许Java代码和其他语言写的代码进行交互。JNI一开始是为了本地已编译语言,尤其是C和C++而设计的,但是它并不妨碍你使用其他编程语言,只要调用约定受支持就可以了。使用java与本地已编译的代码交互,通常会丧失平台可移植性。但是,有些情况下这样做是可以接受的,甚至是必须的。例如,使用一些旧的库,与硬件、操作系统进行交互,或者为了提高程序的性能。JNI标准至少要保证本地代码能工作在任何Java 虚拟机环境。
Extension Mechanism
假设你将Google的Guava库作为Extension来扩展Java平台,那么你便可以像使用Java Collections Framework一样使用Google Guava Collections,看上去GGC就好像变成了Java平台的一部分。
此功能已被废弃,将来会移除。
Endorsed Standards Override Mechanism
Java标准覆盖机制。此功能已被废弃,将来会移除。
lang and util Base Libraries 语言和工具基本库
提供基本的语言和工具类。
Math
提供数学运算相关的API。
Monitoring and Management
综合监控管理平台包括监测和管理的Java API。
Package Version Identification
包版本功能可以实现包级别的版本控制,以便程序能在运行时识别一个特定的Java运行环境版本。
Reference Objects
引用对象支持与垃圾收集器的有限程度的交互。
Reflection
反射使Java代码可以获取加载类的成员变量、方法和构造方法。
Collections Framework
Java提供了大量的集合类方便处理数据。
Concurrency Utilities
Java提供了并发相关的API来构建更强大的程序。
Java Archive (JAR) Files
JAR是平台独立的打包格式。
Logging
Java也提供了日志API。
Preferences
Preferences API类似于Windows注册表,可以将一些偏好设置保存在本地。
Java Virtual Machine Java虚拟机
JDK提供了多个Java虚拟机的实现。当运行客户端程序时,JDK使用Java HotSpot Client VM,这个版本JVM会降低启动时间和内存占用。当在所有平台上运行程序时,JDK使用Java HotSpot Server VM,这个版本JVM会最大化程序执行速度。
Compact Profiles 紧凑型配置文件
JRE精简版,该特性定义了Java SE平台规范的一些子集,使Java应用程序不需要整个JRE平台即可部署和运行在小型设备上。开发人员可以基于目标硬件的可用资源选择一个合适的JRE运行环境。
好处
更小的Java环境需要更少的计算资源。
一个较小的运行时环境可以更好的优化性能和启动时间。
消除未使用的代码从安全的角度总是好的。
这些打包的应用程序可以下载速度更快。
紧凑的JRE分3种,分别是compact1、compact2、compact3,他们的关系是compact1
Java Card介绍
Java Card技术主要是让智慧卡或与智慧卡相近的装置上,以具有安全防护性的方式来执行小型的Java Applet,此技术也被广泛运用在SIM卡、提款卡上。
Java Card架构
智能卡就长这样。
Java Card也是一套技术规范,由三部分组成:
• Java Card 虚拟机规范,定义了用于智能卡的 Java 程序语言的一个子集和虚拟机。
• Java Card 运行时环境规范,进一步定义了用于基于 Java 的智能卡的运行期行为。
• Java Card 应用编程接口规范,定义了用于智能卡应用程序核心框架和扩展 Java 程序包和类。
Java Card运行原理图。
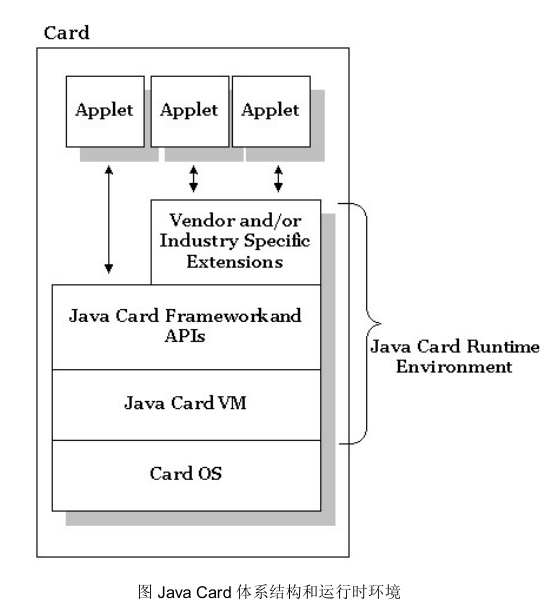
(1)最底层是硬件(芯片),然后会提供硬件的接口(底层驱动)。
(2)网上是卡片的操作系统,是定制的微型操作系统,不是你想的Linux。
(3)操作系统往上才是虚拟机,也就是说虚拟机必须依赖于操作系统!虚拟机不是操作系统!!
(4)虚拟机往上是Java卡框架和API接口。
(5)最顶层就是Applet。
中间也可以有其他的一些层级,比如虚拟机和Applet之间还可以有个Applet组件。
下层为上层提供API接口(例如import的包里面的函数),上层调用下层的API接口进行编程,接口可以是C/C++的接口,也可以是java的接口。无论是C/C++,最终都是要转化成汇编/机器码执行的,所以只要编译器支持,java和C/C++混合着写都行。所以最高难度的就是在这,例如操作系统这块,虚拟机这块,都是开发难度极大的,所以估计一遍都是直接使用官方(如Sun)提供好的OS/虚拟机。
Java Card与Java SE不同,Java Card虚拟机(Java Card Virtual Machine,也可简称为Java Card VM或JCVM)它是原有Java 虚拟机的子集合,负责对Java Applet进行程式直译、执行及结果回应,也因此JCVM的空间占量不能太大,必须能小到放入智慧卡内。此外,Java Card的Java Applet也必须比一般Java Applet更小型,要求JCVM与Java Card Applet都更小化,对日后的进一步撰写开发与程式移植等有帮助。
既然有容量取向的要求,那也就必须对Java的功效机能进行部分权衡取舍,即便可以用多种方式让应用程式的体积占量突破容量限制,例如将应用程式的程式码划分到Package(Java程式语言中,用来将类以性质、用途等不同取向等而集中放置的地方,即称为Package)内,但是每个Package也被限制不能超过64KB的容量。
完整的 Java Card 应用程序
完整的 Java Card 应用程序由一个后端应用程序和系统、一个主机(卡外)应用程序、一个接口设备(读卡器)和卡上小应用程序、用户证书和支持软件组成。所有的这些元素共同组成一个安全的端到端应用程序:
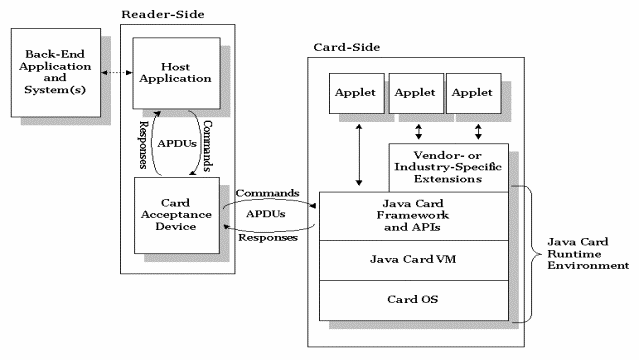
一个典型的 Java Card 应用程序不是孤立的,而是包含卡端、读取端和后端元素。让我们更详细的讲述一下每个元素。
后端应用程序和系统
后端应用程序提供了支持卡上 Java 小应用程序的服务。 例如,一个后端应用程序可以提供到安全系统和卡上的证书的连接,提供强大的安全性。在一个电子付款系统中,后端应用程序可以提供到信用卡及其他付款信息的访问。
读取端主应用程序
主应用程序存在于一个例如个人计算机这样的台式机或者终端、电子付款终端、手机或者一个安全子系统中。主应用程序处理用户、Java Card 小应用程序和供应商的后端应用程序之间的通讯。传统的读取端应用程序是使用 C 编写的。近来 Java ME 技术的广泛普及有望使用 Java 实现主应用程序;例如,它可以在一台支持 MIDP 和安全信赖服务应用编程接口(Security and Trust Services API)手机上运行。智能卡供应商一般不仅提供开发工具箱,而且提供支持读取端应用程序和Java Card小应用程序的应用程序编程接口。例如 OpenCard Framework,就是一个基于Java的应用程序编程接口集,隐藏了来自不同供应商的读取器的一些细节,并且提供了Java Card远程方法调用分布式对象模型和安全信任服务应用编程接口(SATSA)。
读取端卡片接受设备
卡片接受设备(CAD)是处于主应用程序和 Java Card 设备之间的接口设备。一个 CAD 为卡片提供电力,以及与之进行电子或者射频通信。一个 CAD 可能是一个使用串行端口附于台式计算机的读卡器,或者可能被整合到终端内,例如饭店或者加油站内的电子付款终端。接口设备从主应用程序到卡片转送应用程序协议数据单元( Application Protocol Data Unit,简称 APDU)命令(在后面讨论),并且从卡片向主应用程序转送响应。一些 CAD 有用于输入个人识别号码的键盘,有的可能还有显示屏。
卡片端小应用程序和环境
Java Card 平台是一个多应用程序环境。在图4中我们可以看到,卡片上可能存在一个或多个Java Card 小应用程序,还有支持软件–卡片的操作系统和 Java Card 运行时环境(JCRE)一起。JCRE 由 Java Card 虚拟机、Java Card Framework 和应用程序编程接口以及一些扩展应用程序编程接口组成。所有的 Java Card 小应用程序扩展 Applet 基本类,并且必须实现 install()和 process()方法;JCRE 在安装小应用程序的时候调用 install(),并且在每次有一个进入的用于小应用程序的APDU 的时候调用 process()。Java Card 小应用程序在被装载的时候实例化,并且在断电的时候保持运行。Java Card 小应用程序起一个服务器的作用,并且是无源的。在一张卡片被加电以后,每个小应用程序都保持非运行的状态直到它被选择,在此时可能会做初始化。小应用程序只有在一个 APDU 被发送给它以后才被激活。一个小应用程序如何激活(被选择)在”一个 Java Card 小应用程序的生命周期”一节中描述。
与 Java Card 小应用程序通讯(访问智能卡)
你可以使用两种模型中的任何一种来在一个主应用程序和一个 Java Card 小应用程序之间通信。第一个模型是基本消息传送模型,第二种是基于 Java Card 远程方法调用(JCRMI),这是J2SE RMI 分布式对象模型的一个子集。此外,SATSA 通过一个基于更加抽象的应用编程接口的普通连接框架(Generic Connection Framework,简称 GCF)应用编程接口,让你要么使用消息传递要么使用 JCRMI 来访问智能卡。
虚拟机
Java Card 虚拟机(JCVM)规范定义了 Java 程序设计语言的一个子集和一个用于智能卡的兼容Java 的虚拟机,包括二进制数据表示和文件格式,以及 JCVM 指令集。
用于 Java Card 平台的虚拟机是两部分实现,一部分在卡外,一部分运行在卡本身。卡上的Java Card 虚拟机解释字节码、管理类和对象等等。外部 Java 虚拟机部分是一个开发工具,一般称为 Java Card 转换工具,装载、检验和进一步地准备卡片小应用程序 Java 类,用于在卡上执行。转换工具输出的是一个 Converted Applet(CAP)文件,这是一个包含一个 Java 程序包中所有类的文件。转换程序检验类是否遵循 Java Card 规范。
JCVM 只支持 Java 程序设计语言的一个有限的子集,然而它保留了许多熟悉的特性,包括对象、继承、程序包、动态对象创建、虚拟方法、接口和异常。JCVM 规范放弃了对许多语言元素的支持,因为这些语言元素可能会用掉很多智能卡本来就很有限的内存。
JCVM 的生命周期与卡片本身的生命周期一致:在卡片制造并测试之后至发行到持卡人手中的一段时间内它就开始了生命周期,当卡片丢失或者毁坏的时候它的生命周期也就结束了。 卡片没有电力的时候 JCVM 也不会停止,因为它的状态被保存在卡片的非易失性存储器中。启动 JCVM 初始化 JCRE 并且创建所有的 JCRE 框架对象,这些在 JCVM 的整个生命周期都是运转着的。JCVM 启动之后,与卡片所有的相互作用原则上都是被卡片上的某个小应用程序控制。 当卡片没电的时候,保存在 RAM 中的任何数据都会丢失,但是保存在永久性存储器中的任何状态都被保留。当再次加电以后,虚拟机又再次激活,这时虚拟机和对象的状态被恢复,并且重新开始执行等待进一步地输入。
API
Java Card 应用编程接口规范定义了传统的 Java 程序设计语言应用编程接口的一个小的子集–甚至小于 J2ME 的 CLDC。不支持字符串也不支持多线程。没有象 Boolean 和 Integer 这样的包装类,也没有 Class 和 System 类。
除 Java 核心类的小子集以外,Java Card 框架还定义了它自己的特定支持 Java Card 应用程序的核心类。
Java Card与Java ME的区别
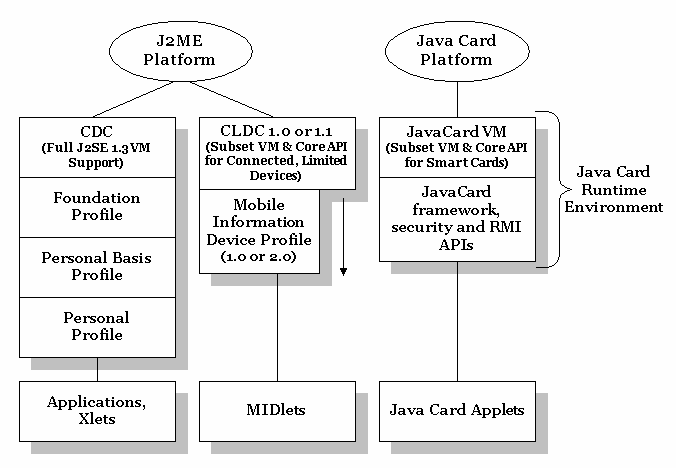
CDC 和 CLDC 配置以及它们相关的简表是 J2ME 平台的一部分,而 Java Card 是一个单独创
建来用于智能卡环境的平台。
Java Card开发流程
当创建一个 Java Card 应用程序的时候的典型的步骤是:
1、编写 Java 源代码。
2、编译你的源代码。
3、把类文件改变为一个 Converted Applet(CAP)文件。
4、检验这个 CAP 是否有效;这个步骤是可选的。
5、安装这个 CAP 文件。
当用 Java 程序设计语言开发传统的程序的时候,头两个步骤是相同的:编写.java 文件并且把它们编译成.class 文件。可是,一旦你已经创建 Java Card 类文件,过程会变化的。
Java Card 虚拟机(JCVM)被分成卡外虚拟机和卡内虚拟机。这个分解移除了昂贵的卡外操作,并且考虑到了在卡本身上的小的内存空间,但是它导致在开发 Java Card 应用程序的时候的额外步骤。
在 Java Card 类可以被导入一个 Java Card 设备之前,他们必须被转化成标准的 CAP 文件格
式,然后选择性地检验:
(1)转化必然伴有把每个 Java 程序包变换到一个 CAP 文件中,在一个程序包中包含类和接口的联合二进制表示法。转化是一个卡外操作。
(2)验证是一个可选择的过程,来确认 CAP 文件的结构、有效的字节码子集和程序包内依赖性。你可能想在你使用的第三方供应商程序包上进行验证,或者如果你的转换工具来自一个第三方供应商。验证一般来说是一个卡外操作,但是一些卡片产品可能包括一个机载的检验器。
一旦检验,CAP 文件就即将安装在 Java Card 设备上了。
想要对Java Card了解更多可以参考下面的博文。
http://blog.csdn.net/Lv_Victor/article/category/6161516
Java ME介绍
Java ME是Java微型版的简称(Java Platform, MicroEdition),是一个技术和规范的集合,它为移动设备(包括消费类产品、嵌入式设备、高级移动设备等)提供了基于Java环境的开发与应用平台。Java ME目前分为两类配置,一类是面向小型移动设备的CLDC(Connected Limited Device Profile ),一类是面型功能更强大的移动设备如智能手机和及顶盒,称为CDC(Connected Device Profile CDC)
Java ME的体系结构
Java ME由多种配置(Configuration)、简表(Profile)和可选包(Optional Package)组成。平台的实现者和应用程序的开发者可以从中选择并组合出一个完整的Java运行环境来满足特定范围内的设备需求,每种组合都应该使这一系列设备的内存、处理器和I/O能力达到最优化。Java ME专家组只所以采取这种灵活的设计结构,主要是为了满足市场上不同种类的嵌入式设备的需求,这些设备在软件和硬件特性上都存在巨大的差异,一种规范很难将它们统一起来。
Java ME的体系结构如下图所示。

配置由Java虚拟机和一系列的API集合组成,为某一范围内的嵌入式设备提供基本的功能,这些设备通常在硬件和软件上具有类似的特性。目前,Java ME主要包含两个配置:连接设备配置(Connected Device Configuration,CDC)和连接受限设备配置(Connected Limited Device Configuration,CLDC)。为了给目标设备提供完整的运行环境,配置必须和简表组合。
简表位于配置之上,为运行环境提供高层的API,例如,应用程序模型和图形用户界面等。目前,CLDC上采用最广泛的简表是移动信息设备简表(Mobile Information Device Profile,MIDP)。基于CLDC与MIDP的Java ME主要面对的目标设备是移动电话。
Java ME可以通过添加可选包(Optional Package)进行扩展,可选包是针对特殊技术的实现,因此它定位的是特定范围的设备,而不适合作为一项特性定义在MIDP中。比较常见的可选包有无线消息API(Wireless Messaging API,JSR120)、移动多媒体API(Mobile Media API,JSR 135)。随着移动终端设备内存的扩大和处理能力的提高,越来越多的可选包被添加到具体的Java ME上,这大大加强了Java ME的功能,第三方开发者可以使用这些可选API开发出功能更强大的应用程序。
Configuration 配置
目前,Java ME主要包括两个配置,即CLDC和CDC。
CLDC是两个配置中较小的一个,为具有间断性联网能力、较慢的处理器和有限内存的设备设计的。这些设备包括移动电话、双工呼叫器和入门级的PDA,它们通常具有16位或32位的CPU、128KB~512KB可用于Java平台实现和相关应用程序的内存。运行在这一配置上的程序称为MIDlet ,在KVM上进行解释。
CDC是为处理能力较强、内存空间更大、联网能力更出色的设备设计的。这些设备包括电视机顶盒、车载娱乐系统、高端PDA等。CDC包含一个具有完备特性的Java虚拟机,比CLDC更大的Java SE的子集。CDC的目标设备通常具有32位或者64位的处理器,2MB以上的可用于Java平台实现和相关应用程序的内存空间。运行在这一配置上的程序称为Java ME Application,在CVM上进行解释。
移动信息设备的硬件发展速度远远超过了Java ME规范制定者的预计。因此,现在很难依照上面的标准来区分现在的移动电话是属于CLDC还是CDC范畴。
随着智能手机的流行,Android和iOS系统二分天下,Java ME也要淡出主流移动领域,在特定的嵌入式设备上继续发光发亮或者苟延残喘吧。
在 J2ME 中有两类虚拟机:CVM (Compact Virtual Machine,C虚拟机)与 KVM (Kernel-based Virtual Machine,K虚拟机)。KVM 和 CVM均可被看作是一种 Java 虚拟机,是 JVM 的子集,在功能上都是 JVM 的缩减版。这两类虚拟机的适用范围并不相同,简单地说,CVM 的功能比KVM 功能更为强大。
| - | CDC | CLDC |
|---|---|---|
| 硬件设备参数 | 针对32位的处理器主频通常在75MHz以上,内存可能在1~4MB | CPU为16位、32位主频在 16MHz以上的处理器,设备的内存比较少,可能只有512KB,甚至更少。现在硬件的发展非常快,以前所定义的CLDC的设备目前的设备甚至远远超过原来的定义。不过请注意一下,J2ME 对CLDC设备配置的定义只是一个最低要求的定义。要分辨CLDC设备主要要从设备特点上进行区别 |
| 支持设备种类 | 数字电视、机顶盒、网络电话、车载计算设备等 | Nokia 7650,Nokia 3650, PDA设备、智能手机等 |
| 设备特点 | 有线连接 电源稳定 设备外设资源比较受限 | 无线连接 没有稳定的电源供应(通常使用电池) 设备外设资源极少 |
| API | CDC 是建立在 CLDC 顶部的 API,是整个 J2SE API 的一个更完整的子集。它还包含一个额外的软件包 – javax.microedition.io 软件包 – 包含 CLDC 中定义的所有相同的类和接口,及其它。 | CLDC API 实际上只是 J2SE 的一个子集,它包括 java.lang、java.io 和 java.util, javax.microedition。 |
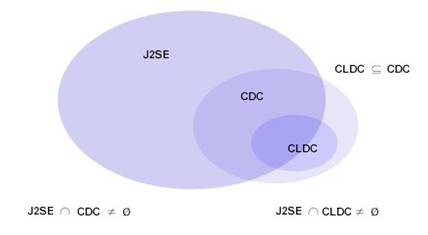
Profile 简表
简表用来描述特定的设备,是支持特定设备(某类功能的设备)的API的集合,以Java类的形式提供。所以它是建立在特定的配置(Configration)之上的。
常用简表
MIDP (Mobile Information Devices Profile,移动信息设备简表):定义了移动信息设备的类型和提供相关的API集合, MIDP 所定义的功能更加面向用户,而且比 CLDC 更高级。
IMP (Mobile Information Device Profile,信息模块简表):定义了提供网络连接,但是显示方式比较单一的设备简表,例如告警器。
Foundation Profile(基础简表):提供除了用户界面以外 Java SE 所能够提供的标准类库。
Personal Profile(个人简表):针对那些资源相对有限,但是对网络访问要求很高,基于AWT图形界面的设备,例如Web-TV、汽车导航系统等。
KJava 包含一个特定于 Sun 的、运行在 Palm 操作系统上的 API。这个 KJava API 和 Java SE 抽象视窗工具包 (AWT) 有很多地方都是相同。然而,由于它不是一个标准的 Java ME 软件包,它的主软件包是 com.sun.kjava。它不作为一种完整的、功能齐全的简表,而是作为一种示范,示范简表如何与 CLDC 一起工作。
配置与简表的搭配
CLDC – MIDP、Kjava
CDC – FP、PP、PFP
Optional Package 可选包
在标准的API中,很多都是接口,这些就要求厂商在手机中提供真实的实现,而且很多本地方法也要求手机厂商进行实现。
但是随着手机功能的增强,SUN公司为了满足手机厂商的要求,又推出了很多套API,因为这些API不要求手机厂商必须支持,所以叫做可选包(Option Package)。例如常见的可选包有:
MMA(Mobile Media API)——移动媒体API,实现对于多媒体编程更深入的支持
WMA(Wireless Message API)——无线信息API,实现对于短信息编程的支持
Location API——定位API,实现对于位置服务的支持
M3G(Mobile 3D Graphics)——移动3D图形API,实现对于手机3D编程的支持
当然,还有很多其他的实现,这里就不再累述了。
最后,由于可选包越来越多,而且支持可选包的手机越来越多,SUN公司想统一手机对于CLDC、MIDP和一部分可选包的支持,所以又推出了JTWI(Java Technology for the Wireless Industry)来规范手机对于各种API的支持。
想要对Java ME了解更多,可以参考下面的博文。
http://blog.csdn.net/dodream/article/category/638391
Java EE介绍
什么是Java EE
Java EE(Java Platform,Enterprise Edition)是一系列技术标准所组成的平台,具体由各个厂商来实现。
与Java SE不同,Java EE是一个企业级应用的架构体系,而不是一门编程语言。Java EE作为一个架构体系,它定义了企业级应用的层次结构,旨在简化和规范企业应用系统的开发和部署。
Java EE提供了一个基于标准开发Web和企业应用程序的平台。这些应用程序通常被设计作为多层应用程序,用一个前端层组成的网络架构,一个中间层提供安全和交易,以及后端层提供连接到数据库或遗留系统。这些应用程序应该是反应迅速的, 能够扩展以适应用户需求的增长。
Java EE平台的API为这多层应用的每一层定义不同的组件,并且还提供了一些额外的服务,如命名,注射,和资源管理。这些组件被部署在提供运行时支持的容器中。Java EE应用程序组件不会直接与其他Java EE应用程序组件互动 。他们使用的协议和方法实现容器相互之间以及与平台服务进行交互。可以透明地注入由组件所需要的服务,例如声明事务管理,安全检查,资源池和状态管理。
Java EE 7发布2013年6月,并提供了一个简单,易于使用,建立Web和企业应用程序的技术堆栈。
架构图如下。
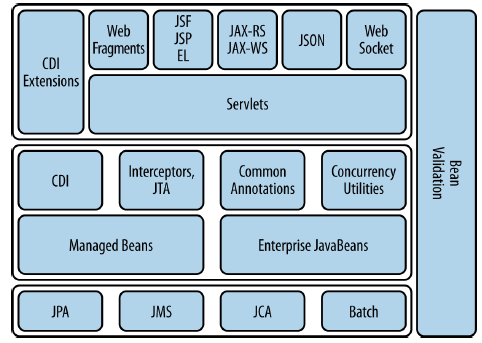
下面是完整的 14 个 JSRs 和 9 个 MRs (维护发行):
JSRs:
Java Platform, Enterprise Edition 7 (JSR 342)
Concurrency Utilities for Java EE 1.0 (JSR 236) (新加入)
Java Persistence 2.1 (JSR 338)
JAX-RS: The Java API for RESTful Web Services 2.0 (JSR 339)
Java Servlet 3.1 (JSR 340)
Expression Language 3.0 (JSR 341)
Java Message Service 2.0 (JSR 343)
JavaServer Faces 2.2 (JSR 344)
Enterprise JavaBeans 3.2 (JSR 345)
Contexts and Dependency Injection for Java EE 1.1 (JSR 346)
Bean Validation 1.1 (JSR 349)
Batch Applications for the Java Platform 1.0 (JSR 352) (新加入)
Java API for JSON Processing 1.0 (JSR 353) (新加入)
Java API for WebSocket 1.0 (JSR 356) (新加入)
MRs:
Web Services for Java EE 1.4 (JSR 109)
Java Authorization Service Provider Contract for Containers 1.5 (JACC 1.5) (JSR 115)
Java Authentication Service Provider Interface for Containers 1.1 (JASPIC 1.1) (JSR 196)
JavaServer Pages 2.3 (JSR 245)
Common Annotations for the Java Platform 1.2 (JSR 250)
Interceptors 1.2 (JSR 318)
Java EE Connector Architecture 1.7 (JSR 322)
Java Transaction API 1.2 (JSR 907)
JavaMail 1.5 (JSR 919)
Java EE设计思想
Java EE将企业级应用分为两部分:实现基础支撑功能的容器和实现特定业务逻辑的组件。
容器
容器提供的底层基础功能被称为服务。这些服务主要用来实现企业级应用的共性需求,如事务、安全、可扩展性和远程连接等。组件通过调用容器提供的标准服务来与外界交互。为满足企业级应用灵活部署,组件与容器之间必须既松散耦合,又能够强有力地交互。为实现这一点,组件和容器都要遵循一个标准规范,这个 标准规范就是Java EE。
容器由专门的厂商来生产,容器必须实现的基本接口和功能由 Java EE规范定义,但具体如何实现完全由容器厂商自己决定。常见的容器类型分为Web容器和EJB容器。
组件
组件一般由开发人员根据特定的业务需求编程实现。所有的 Java EE组件都是在容器的Java虚拟机中进行初始化的,组件通过调用容器提供的标准服务来与外界交互。容器提供的标准服务有:命名服务、数据库连接、持久化、Java消息服务、事务支持和安全服务等。因此在组件的开发过程中,完全可以不考虑复杂多变的企业应用运行环境,而专注于业务逻辑的实现,这样可大大提高组件开发的效率,降低开发企业级应用程序的难度。
容器与组件的交互
那么组件与容器之间是如何实现交互的呢?即容器如何知道要为组件提供何种服务、组件又是如何来获取容器提供的服务呢?Java EE采用部署描述文件来解决这一难题。每个发布到服务器上的应用除了要包含自身实现的代码文件外,还要包括一个XML文件,称为部署描述文件。部署描述文件中详细地描述了应用中的组件所要调用的容器服务的名称、参数等。部署描述文件就像组件与容器间达成的一个“契约”,容器根据部署描述文件的内容为组件提供服务,组件根据部署文件中的内容来调用容器提供的服务。
从上面的介绍中我们可以发现,部署描述文件的配置是 Java EE开发中的一项重要而又烦琐的工作。值得庆幸的是,在 Java EE规范中,提供了一种注解机制来取代配置复杂的部署描述文件。所谓注解其实就是一个以“@”开头的特殊注释文本,但它比注释的作用要大得多。代码中的注释是帮助开发人员阅读和理解代码内容,而注解则是帮助容器来阅读和理解组件内容。我们可以把注解看成是贴在组件身上的标签,在将组件部署到容器中时,根据这些标签,容器便知道该如何为组件提供服务。注解的出现大大简化了 Java EE应用程序的开发和部署,是 Java EE规范的一项重大进步。
更值得一提的是,在最新的 Java EE规范中,还引入了一种“惯例优于配置”,也称为“仅异常才配置”的思想。通俗一点讲,就是对于 Java EE组件的一些属性和行为,容器将按照一些约定俗成的惯例来自动进行配置,此时开发人员甚至连注解都可以省略。只有当组件的属性和行为不同于惯例时,才需要进行配置。这种编程方式大大降低了程序人员的工作量,也是需要开发人员逐渐熟悉和适应的一种编程技巧。
Java 技术架构
作为一个企业应用开发标准, Java EE最终由一系列的企业应用开发技术来实现。 Java EE技术框架可以分为四部分:组件技术、服务技术、通信技术和框架技术。整个 Java EE技术框架体系如下图所示。
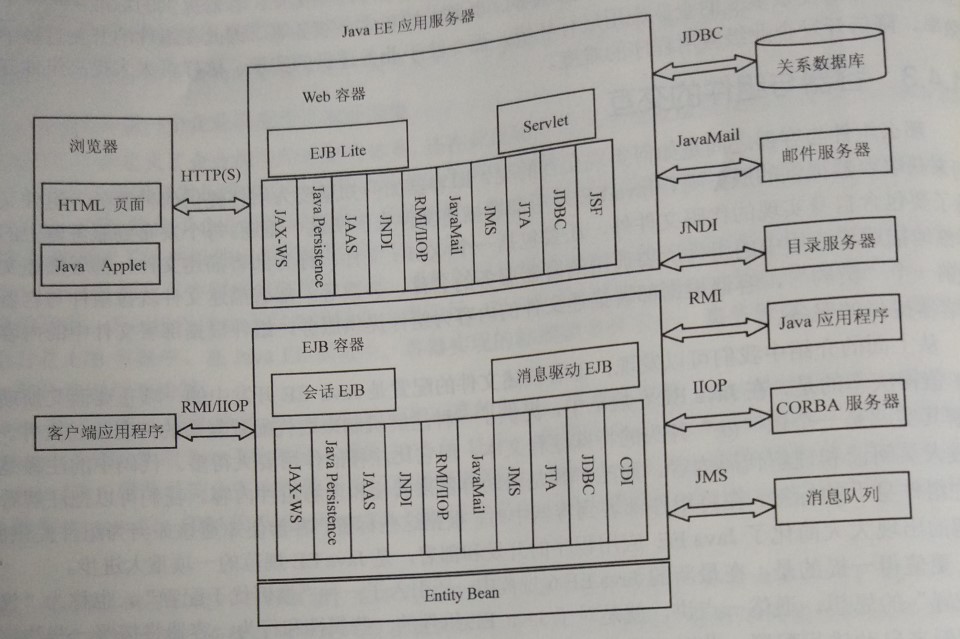
组件技术
组件是 Java EE应用的基本单元。 Java EE 6提供的组件主要包括三类:客户端组件、Web组件和业务组件。
1.客户端组件
用户通过客户端组件与企业应用进行交互。 Java EE客户端既可以是一个Web浏览器、一个Applet,也可以是一个应用程序。
(1)Web浏览器。
Web浏览器又称为瘦客户。它通常只进行简单的人机交互,不执行如查询数据库、业务逻辑计算等复杂操作。
(2) Applet。
Applet是一个用Java语言编写的小程序,运行在浏览器上的虚拟机里,通过HTTP等协议和服务器进行通信。
(3)应用程序客户端。
Java EE应用程序客户端运行在客户机上,它为用户处理任务提供了比标记语言丰富的接口。典型的 Java EE应用程序客户端拥有通过 Swing或 AWT API建立的图形用户界面。应用程序客户端直接访问在服务器EJB容器内的EJB组件。当然, Java EE客户应用程序也可以像 Applet客户那样通过HTTP连接与服务器的 Servlet通信。与 Applet不同的是,应用程序客户端一般需要在客户机进行安装,而Applet是通过Web下载,无需专门安装。
2.Web组件
Web组件对客户提交的Web请求进行动态响应。用户每次在浏览器上单击一个链接或图标,实际上是通过HTTP请求向服务器发出请求。Web容器负责将Web请求传递给Web组件。Web组件对这些请求进行处理后生成动态内容,再通过Web容器返回给客户端。
Java EE web组件包括 Servlet和JSF( Javaserver faces)组件。
Servlet是Web容器里的程序组件。 Servlet实质上是动态处理HTTP请求和生成网页的Java类。JSF组件是一种基于JSF框架的组件,它可以实现像桌面应用一样基于事件驱动Web应用。
3.业务组件
业务组件用来实现特定的业务逻辑操作,它们通常不直接与客户交互。业务组件包含EJB组件和Entity组件两大类。
EJB组件用于实现特定的业务逻辑,而不是像Web组件一样对客户端请求生成动态页面。EJB组件能够在容器的支持下完成诸如远程连接、消息驱动、分布式事务处理等复杂的业务逻辑,因此使用EJB组件编写的程序可大大降低开发难度,且具有良好的扩展性。 Java EE支持两种类型的EJB组件:Session Bean(会话Bean)和 Message-Driven Bean(消息驱动Bean)。
Entity组件主要用来完成应用数据的持久化操作。
服务技术
Java EE容器为组件提供了各种服务,这些服务是企业应用经常用到但开发人员难以实现的,例如服务、数据库连接、上下文和依赖注入、事务、安全和连接框架等。现在这些服务已经由容器实现,因此 Java EE组件只要调用这些服务就可以了。
1.命名服务
企业应用中通常包含大量的组件,为了完成功能需求,组件间通常要相互调用。JNDI( Java Naming and Directory Interface,Java命名和目录服务接口)简化了企业应用组件之间的查找调用。它提供了应用的命名环境( naming environment)。这就像一个公用电话簿,企业应用组件在命名环境注册登记,并且通过命名环境查找所需要的其他组件。
2.数据库连接服务
数据库访问几乎是任何企业应用都需要实现的。JDBC( Java DataBase Connectivity,Java数据库连接)API使 Java EE平台可以和各种关系数据库之间连接起来。JDBC技术提供Java程序和数据库服务器之间的连接服务,同时它能保证数据事务的正常进行。另外,JDBC提供了从Java程序内调用SQL数据检索语言的功能, Java EE 6平台使用JDBC 4.0 API以及JDBC 4.0拓展API,这些API提供了高级的数据连接功能。
3.Java事务服务
JTA( Java Transaction API,Java事务API)允许应用程序执行分布式事务处理——在两个或多个资源节点上访问并且更新数据。JTA用于保证数据读/写时不会出错。当程序进行数据库操作时,要么全部成功完成,要么一点也不改变数据库内容。最怕的是在数据更改过程中程序出错,那样整个系统的业务状态和业务逻辑就会陷入混乱。所以,数据事务有一个“不可分微粒”的概念,是指一次数据事务过程不能间断,JTA保证应用程序的数据读/写进程互不干扰。如果一个数据操作能整个完成,它就会被批准;否则,应用程序服务器就当什么都没做。应用程序开发者无需自己实现这些功能,这样数据操作就被简化了。数据事务技术使用JTA的API,它可以在EJB层或Web层实现。
4.安全服务
JAAS( Java Authentication Authorization Service,Java验证和授权服务)提供了灵活和可伸缩的机制来保证客户端或服务器端的Java程序。Java早期的安全框架强调的是通过验证代码的来源和作者,保护用户避免受到下载下来的代码的攻击JAS强调的是通过验证谁在运行代码以及他她的权限来保护系统免受用户的攻击。它使用户能够将一些标准的安全机制,例如 Solaris nis(网络信息服务)、Windows NT、LDAP(轻量目录存取协议)或 Kerberos等通过一种通用的可配置的方式集成到系统中。
5.Java连接框架
JCA( Java Connector Architecture,Java连接框架)是一组用于连接 Java EE平台到企业信息系统(EIS)的标准API。企业信息系统是一个广义的概念,它指企业处理和存储信息数据的程序系统,例如企业资源计划(ERP)、大型机数据事务处理以及数据库系统等。由于很多系统已经使用多年,这些现有的信息系统又称为遗产系统(Legacy system),它们不一定是标准的数据库或Java程序,例如非关系数据库等系统。JCA定义了一套扩展性强、安全的数据交互机制,解决了现有企业信息系统与EJB容器和组件的集成。这使 Java EE企业应用程序能够和其他类型的系统进行通话。
6.上下文和依赖注入
上下文和依赖注入( Contexts and Dependency Injection,CDI)使得容器以类型安全的低耦合方式为EJB等组件提供一种上下文服务。它将EB等受控组件的生命周期交由容器来管理,降低了组件之间的耦合度,大大提高了组件的重用性和可移植性。
通信技术
Java EE通信技术提供了客户和服务器之间及在服务器之间及在服务器上不同组件之间的通信机制.Java平台支持几种典型的通信技术: Internet协议、RMI( Remote Method Invocation,远程方法调用)、消息技术( Messaging)和 JavaMail等。
1.Internet协议
Java EE平台能够采用通用的 Internet协议实现客户服务器和组件之间的远程网际通信。
TCP/IP( Transport Control Protocol over Internet Protocol,互联协议之上的传输控制协议)是 Interne在传输层和Web层的核心通信协议。
HTTP1.1是在互联网上传送超文本文件的协议。HTTP消息包括从客户端到服务器的请求和从服到客户端的响应,HTTP和Web浏览器称为 Internet最普及和最常用的功能。大多数Web机器都提供HTTP端口和互联网进行通信,在HTTP之上的SOAP( Simple Object Access Protocol)成为受到广泛关注的Web服务基础协议。
SSL3.0( Secure Socket Layer)是Web的安全协议。它在TCP/IP之上对客户和服务器之间的Web通信信息进行加密而不被窃听,它可以和HTTP共同使用(即HTPS)。服务器可以通过SSL对客户进行验证。
2.RMI
RMI是Java的一组用于开发分布式应用程序的API。RMI使用Java语言接口定义了远程对象不同机器操作系统的程序对象),它结合了Java序列化( Java serialization)和Java远程方法协议(Java Remote Method Protocol)。简单地说,这样使原先的程序在同一操作系统的方法调用,变成了不同操作系统之间程序的方法调用。由于 Java EE是分布式程序平台,它以RMI机制实现程序组件在不同操作系统之间的通信。比如,一个EJB可以通过RMI调用Web上另一台机器上的EJB远程方法。
3.Java消息技术
AJMS( Java Message Service,Java消息服务)API允许 Java EE应用程序访问企业消息系统,例如IBM MQ系列产品和 JBOSS的 JBOSS MQ。
4.邮件技术
Java邮件( Java Mail)API提供能进行电子邮件通信的一套抽象类和接口。它们支持多种电子邮件格式和传递方式。Java应用可以通过这些类和接口收发电子邮件,也可以对其进行扩充。
框架技术
框架方面的贡献是 Java EE 6规范的一项重大进步。在之前的Java EE规范中,主要从微观的角度来规范企业应用的开发,关注的重点是在组件级别上上如何处理组件与客户端的交互,及组件与容器之间的交互。但随着 Java EE的广泛应用,在 lava ee企业应用的构建过程中,一些架构层面上的共性问题,如页面导航、国际化、数据持久化、输入校验等渐渐浮出水面。这些问题是每个企业应用开发人员构建企业应用时几乎必然遇到的,但 Java EE规范并没有对此给出标准答案,因此,各种第三方架构如 Struts2、 Hibernate、 Spring、Seam等大行其道。这些众多的框架给开发人员带来很大压力,也给 Java EE服务器厂商带来更多的麻烦,限制了他们为 Java EE应用提供更高级的支持。因此,在Java EE 6规范中,吸收了目前流行的架构的优点,增加了架构方面的一些标准规范。
1.JSF
JSF( Java Server Faces)是一种用于构建 Java EE Web应用表现层的框架标准。它提供了一种以组件为中心的事件驱动的用户界面构建方法,从而大大简化了 Java EE Web应用的开发。通过引入了基于组件和事件驱动的开发模式,使开发人员可以使用类似于处理传统界面的方式来开发Web应用程序。JSF还通过将模型-视图-控制器(MVC)设计模式集成到它的体系结构中,提供了行为与表达的清晰分离,确保了应用程序具有更高的可维护性。 Java EE 6规范中包含的JSF的版本为2.1。
2.JPA
数据持久化对于大部分企业应用来说都是至关重要的,因为企业应用中的大部分信息都需要持久化存储到关系数据库等永久介质中。尽管有不少选择可以用来构建应用程序的持久化层,但是并没有一个统一的标准可以用在 Java EE环境中。作为 Java EE 5规范中的一部分,JPA( Java Persistence API)规范了Java平台下的持久化实现,大大提高了应用的可移植性。 Java EE 6规范中包含的JPA的版本为2.0。
Java EE优点
Java EE体系架构具有以下优点。
1.独立于硬件配置和操作系统。
Java EE应用运行在JVM( Java virtual machine,Java虚拟机)上,利用Java本身的跨平台特性,独立于硬件配置和操作系统。JRE几乎可以运行于所有的硬件/操作系统组合。因此 Java EE架构的企业应用使企业免于高昂的硬件设备和操作系统的再投资,保护已有的IT资源。
2.坚持面向对象的设计原则
作为一门完全面向对象的语言,Java几乎支持所有的面向对象的程序设计特征。面向对象和基于组件的设计原则构成了 Java EE应用编程模型的基础。 Java EE多层结构的每一层都有多种组件模型。因此开发人员所要做的就是为应用项目选择适当的组件模型组合,灵活地开发和装配组件,这样不仅有助于提高应用系统的可扩展性,还能有效地提高开发速度,缩短开发周期。
3.灵活性、可移植性和互操作性
利用Java的跨平台特性, Java EE组件可以很方便地移植到不同的应用服务器环境中。这意味着企业不必再拘泥于单一的开发平台。 Java EE的应用系统可以部署在不同的应用服务器上,在全异构环境下, Java EE组件仍可彼此协同工作。这一特征使得装配应用组件首次获得空前的互操作性。
4.轻松的企业信息系统集成
Java EE技术出台后不久,很快就将JDBC、JMS和JCA等一批标准归纳自身体系之下,这大大简化了企业信息系统整合的工作量,方便企业将诸如遗产系统、ERP和数据库等多个不同的信息系统进行无缝集成。
经典Java EE与轻量级Java EE
目前 Java EE应用的开发方式大致可分为两种:一种以 Spring、 Hibernate等开源框架为基础这就是通常所说的轻量级 Java EE应用;另一种则以EJB3+JPA为基础,也就是经典 Java EE应用。在EJB3出现以前,由于EJB学习曲线陡峭,使用时也有点困难,因此影响了EJB在实际项目中的使用。为此EJB3进行了大刀阔斧的改革,有人说EJB3中的 Session Bean就像 Spring容器中的Bean:只要一个接口和一个实现类即可一—其实这句话说反了,应该说Spring框架充分借鉴了早期的EJB规范,但对EJB规范进行了简化,比如它不要求Bean继承任何基类,而且 Spring对Bean的要求比较“温柔”:它只是建议面向接囗编程;而EJB规范则显得很“强硬”:EJB必须有一个接口和一个实现类。但最终殊途同归: Spring容器中的Bean通常由一个接口和一个实现类组成,EJB也由一个接口和一个实现类组成。到了EJB3时代,开发Session Bean不会比开发 Spring中的Bean更复杂,EJB3中的 Session Bean同样不需要继承任何基类,只要提供一个接口、一个实现类即可,也就是说,EJB3规范也吸收了 Spring框架简单、易用的特性。
Java EE 5的两个核心规范是EJB3和JPA,EJB3使 Java EE应用开发变得更加简单;而JPA规范则体现了Sun公司的良苦用心—Java开源领域中各种ORM框架层出不穷,而 Java EE开发者则疲于学习各种ORM框架: Hibernate是主流,但下一家公司可能选择其他ORM框架,于是开发者不得不重新学习……在这样的背景下,JPA规范诞生了,JPA本质上应属于一种ORM规范应用开发者只需要学习JPA规范、掌握 JPA API即可,不需要为使用 Hibernate学习一套API,为使用 Toplink又要重新学习一套API。开发者面向JPA规范编程,而底层则可以在不同ORM框架(可理解为JPA实现)之间自由切换。通常来说,应用服务器会负责为JPA规范提供ORM实现;如果开发者希望在 Java se应用程序中使用JPA,这也是允许的,只要开发者自行为JPA选择合适的ORM实现即可。事实证明,在应用程序中使用JPA作为持久化解决方案更方便,而且能在各种ORM框架之间自由切换,具有更好的可扩展性。
Java EE 5规范面世以来,大量开发者重新回归到EJB3+JPA旗下,采用EJB3+JPA开发的企业级应用也越来越多。除此之外,JSF作为一个前端MVC框架,能与EJB3+JPA完美整合,从而开发出具有高度可扩展性、高度可维护性的企业级应用。
在目前实际的 Java EE开发平台中,主要可分为两支:一支以 Spring、 Hibernate两个框架为核心来构建,这类应用无须应用服务器支持,只要在 Tomcat、 Jetty之类的Web服务器上即可运行良好。这类 Java EE应用被称为轻量级 Java EE应用;另一支则以EJB3为核心来构建,这类应用需要EJB容器支持,通常需要在 JBOSS、 Weblogic、 Websphere服务器中运行,这类 Java EE应用是Sun公司官方推荐的 Java EE平台,称为经典 Java EE应用。无论是轻量级 Java EE应用,还是经典 Java EE应用,一样具有稳定的性能和极高的可扩展性、可维护性。
Java虚拟机
Java在虚拟机层面隐藏了底层技术的复杂性以及机器与操作系统的差异性。运行程序的物理机器的情况千差万别,而Java虚拟机则在千差万别的物理机上建立了统一的运行平台,实现了在任意一台虚拟机上编译的程序都能在任何一台虚拟机上正常运行。这一极大优势使得Java应用的开发比传统C/C++应用的开发更高效和快捷,程序员可以把主要精力集中在具体业务逻辑上,而不是物理硬件的兼容性上。在一般情况下,一个程序员只要了解了必要的Java API、Java语法,以及学习适当的第三方开发框架,就已经基本能满足日常开发的需要了,虚拟机会在用户不知不觉中完成对硬件平台的兼容及对内存等资源的管理工作。因此,了解虚拟机的运作并不是一般开发人员必须掌握的知识。
其实,目前商用的高性能Java虚拟机都提供了相当多的优化特性和调节手段,用于满足应用程序在实际生产环境中对性能和稳定性的要求。如果只是为了入门学习,让程序在自己的机器上正常运行,那么这些特性可以说是可有可无的;如果用于生产开发,尤其是企业级生产开发,就迫切需要开发人员中至少有一部分人对虚拟机的特性及调节方法具有很清晰的认识,所以在Java开发体系中,对架构师、系统调优师、高级程序员等角色的需求一直都非常大。学习虚拟机中各种自动运作特性的原理也成为了Java程序员成长道路上必然会接触到的一课。
Java内存区域
Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同的数据区域。这些区域都有各自的用途,以及创建和销毁的时间,有的区域随着虚拟机进程的启动而存在,有些区域则依赖用户线程的启动和结束而建立和销毁。
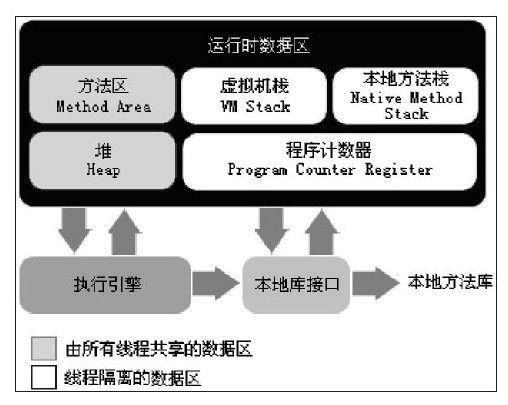
程序计数器
程序计数器(Program Counter Register)是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器。在虚拟机的概念模型里(仅是概念模型,各种虚拟机可能会通过一些更高效的方式去实现),字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支、循环、跳转、异常处理、线程恢复等基础功能都需要依赖这个计数器来完成。
由于Java虚拟机的多线程是通过线程轮流切换并分配处理器执行时间的方式来实现的,在任何一个确定的时刻,一个处理器(对于多核处理器来说是一个内核)都只会执行一条线程中的指令。因此,为了线程切换后能恢复到正确的执行位置,每条线程都需要有一个独立的程序计数器,各条线程之间计数器互不影响,独立存储,我们称这类内存区域为“线程私有”的内存。
如果线程正在执行的是一个Java方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的是Native方法,这个计数器值则为空(Undefined)。此内存区域是唯一一个在Java虚拟机规范中没有规定任何OutOfMemoryError情况的区域。
Java虚拟机栈
与程序计数器一样,Java虚拟机栈(Java Virtual Machine Stacks)也是线程私有的,它的生命周期与线程相同。虚拟机栈描述的是Java方法执行的内存模型:每个方法在执行的同时都会创建一个栈帧(Stack Frame )用于存储局部变量表、操作数栈、动态链接、方法出口等信息。每一个方法从调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。
经常有人把Java内存区分为堆内存(Heap)和栈内存(Stack),这种分法比较粗糙,Java内存区域的划分实际上远比这复杂。这种划分方式的流行只能说明大多数程序员最关注的、与对象内存分配关系最密切的内存区域是这两块。所指的“栈”就是现在讲的虚拟机栈,或者说是虚拟机栈中局部变量表部分。
局部变量表存放了编译期可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference类型,它不等同于对象本身,可能是一个指向对象起始地址的引用指针,也可能是指向一个代表对象的句柄或其他与此对象相关的位置)和returnAddress类型(指向了一条字节码指令的地址)。
其中64位长度的long和double类型的数据会占用2个局部变量空间(Slot),其余的数据类型只占用1个。局部变量表所需的内存空间在编译期间完成分配,当进入一个方法时,这个方法需要在帧中分配多大的局部变量空间是完全确定的,在方法运行期间不会改变局部变量表的大小。
在Java虚拟机规范中,对这个区域规定了两种异常状况:如果线程请求的栈深度大于虚拟机所允许的深度,将抛出StackOverflowError异常;如果虚拟机栈可以动态扩展(当前大部分的Java虚拟机都可动态扩展,只不过Java虚拟机规范中也允许固定长度的虚拟机栈),如果扩展时无法申请到足够的内存,就会抛出OutOfMemoryError异常。
本地方法栈
本地方法栈(Native Method Stack)与虚拟机栈所发挥的作用是非常相似的,它们之间的区别不过是虚拟机栈为虚拟机执行Java方法(也就是字节码)服务,而本地方法栈则为虚拟机使用到的Native方法服务。在虚拟机规范中对本地方法栈中方法使用的语言、使用方式与数据结构并没有强制规定,因此具体的虚拟机可以自由实现它。甚至有的虚拟机(譬如Sun HotSpot虚拟机)直接就把本地方法栈和虚拟机栈合二为一。与虚拟机栈一样,本地方法栈区域也会抛出StackOverflowError和OutOfMemoryError异常。
Java堆
对于大多数应用来说,Java堆(Java Heap)是Java虚拟机所管理的内存中最大的一块。Java堆是被所有线程共享的一块内存区域,在虚拟机启动时创建。此内存区域的唯一目的就是存放对象实例,几乎所有的对象实例都在这里分配内存。这一点在Java虚拟机规范中的描述是:所有的对象实例以及数组都要在堆上分配,但是随着JIT编译器的发展与逃逸分析技术逐渐成熟,栈上分配、标量替换优化技术将会导致一些微妙的变化发生,所有的对象都分配在堆上也渐渐变得不是那么“绝对”了。
Java堆是垃圾收集器管理的主要区域,因此很多时候也被称做“GC堆”(Garbage Collected Heap,幸好国内没翻译成“垃圾堆”)。从内存回收的角度来看,由于现在收集器基本都采用分代收集算法,所以Java堆中还可以细分为:新生代和老年代;再细致一点的有Eden空间、From Survivor空间、To Survivor空间等。从内存分配的角度来看,线程共享的Java堆中可能划分出多个线程私有的分配缓冲区(Thread Local Allocation Buffer,TLAB)。不过无论如何划分,都与存放内容无关,无论哪个区域,存储的都仍然是对象实例,进一步划分的目的是为了更好地回收内存,或者更快地分配内存。
根据Java虚拟机规范的规定,Java堆可以处于物理上不连续的内存空间中,只要逻辑上是连续的即可,就像我们的磁盘空间一样。在实现时,既可以实现成固定大小的,也可以是可扩展的,不过当前主流的虚拟机都是按照可扩展来实现的(通过-Xmx和-Xms控制)。如果在堆中没有内存完成实例分配,并且堆也无法再扩展时,将会抛出OutOfMemoryError异常。
方法区
方法区(Method Area)与Java堆一样,是各个线程共享的内存区域,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做Non-Heap(非堆),目的应该是与Java堆区分开来。
对于习惯在HotSpot虚拟机上开发、部署程序的开发者来说,很多人都更愿意把方法区称为“永久代”(Permanent Generation),本质上两者并不等价,仅仅是因为HotSpot虚拟机的设计团队选择把GC分代收集扩展至方法区,或者说使用永久代来实现方法区而已,这样HotSpot的垃圾收集器可以像管理Java堆一样管理这部分内存,能够省去专门为方法区编写内存管理代码的工作。对于其他虚拟机(如BEA JRockit、IBM J9等)来说是不存在永久代的概念的。原则上,如何实现方法区属于虚拟机实现细节,不受虚拟机规范约束,但使用永久代来实现方法区,现在看来并不是一个好主意,因为这样更容易遇到内存溢出问题(永久代有-XX:MaxPermSize的上限,J9和JRockit只要没有触碰到进程可用内存的上限,例如32位系统中的4GB,就不会出现问题),而且有极少数方法(例如String.intern())会因这个原因导致不同虚拟机下有不同的表现。因此,对于HotSpot虚拟机,根据官方发布的路线图信息,现在也有放弃永久代并逐步改为采用Native Memory来实现方法区的规划了,在目前已经发布的JDK 1.7的HotSpot中,已经把原本放在永久代的字符串常量池移出。
Java虚拟机规范对方法区的限制非常宽松,除了和Java堆一样不需要连续的内存和可以选择固定大小或者可扩展外,还可以选择不实现垃圾收集。相对而言,垃圾收集行为在这个区域是比较少出现的,但并非数据进入了方法区就如永久代的名字一样“永久”存在了。这区域的内存回收目标主要是针对常量池的回收和对类型的卸载,一般来说,这个区域的回收“成绩”比较难以令人满意,尤其是类型的卸载,条件相当苛刻,但是这部分区域的回收确实是必要的。在Sun公司的BUG列表中,曾出现过的若干个严重的BUG就是由于低版本的HotSpot虚拟机对此区域未完全回收而导致内存泄漏。
根据Java虚拟机规范的规定,当方法区无法满足内存分配需求时,将抛出OutOfMemoryError异常。
运行时常量池
运行时常量池(Runtime Constant Pool)是方法区的一部分。Class文件中除了有类的版本、字段、方法、接口等描述信息外,还有一项信息是常量池(Constant Pool Table),用于存放编译期生成的各种字面量和符号引用,这部分内容将在类加载后进入方法区的运行时常量池中存放。
Java虚拟机对Class文件每一部分(自然也包括常量池)的格式都有严格规定,每一个字节用于存储哪种数据都必须符合规范上的要求才会被虚拟机认可、装载和执行,但对于运行时常量池,Java虚拟机规范没有做任何细节的要求,不同的提供商实现的虚拟机可以按照自己的需要来实现这个内存区域。不过,一般来说,除了保存Class文件中描述的符号引用外,还会把翻译出来的直接引用也存储在运行时常量池中。
运行时常量池相对于Class文件常量池的另外一个重要特征是具备动态性,Java语言并不要求常量一定只有编译期才能产生,也就是并非预置入Class文件中常量池的内容才能进入方法区运行时常量池,运行期间也可能将新的常量放入池中,这种特性被开发人员利用得比较多的便是String类的intern()方法。
既然运行时常量池是方法区的一部分,自然受到方法区内存的限制,当常量池无法再申请到内存时会抛出OutOfMemoryError异常。
直接内存
直接内存(Direct Memory)并不是虚拟机运行时数据区的一部分,也不是Java虚拟机规范中定义的内存区域。但是这部分内存也被频繁地使用,而且也可能导致OutOfMemoryError异常出现,所以我们放到这里一起讲解。
在JDK 1.4中新加入了NIO(New Input/Output)类,引入了一种基于通道(Channel)与缓
冲区(Buffer)的I/O方式,它可以使用Native函数库直接分配堆外内存,然后通过一个存储在Java堆中的DirectByteBuffer对象作为这块内存的引用进行操作。这样能在一些场景中显著提高性能,因为避免了在Java堆和Native堆中来回复制数据。
显然,本机直接内存的分配不会受到Java堆大小的限制,但是,既然是内存,肯定还是会受到本机总内存(包括RAM以及SWAP区或者分页文件)大小以及处理器寻址空间的限制。服务器管理员在配置虚拟机参数时,会根据实际内存设置-Xmx等参数信息,但经常忽略直接内存,使得各个内存区域总和大于物理内存限制(包括物理的和操作系统级的限制),从而导致动态扩展时出现OutOfMemoryError异常。
垃圾收集器与内存分配策略
Java内存运行时区域,其中程序计数器、虚拟机栈、本地方法栈3个区域随线程而生,随线程而灭;栈中的栈帧随着方法的进入和退出而有条不紊地执行着出栈和入栈操作。每一个栈帧中分配多少内存基本上是在类结构确定下来时就已知的,因此这几个区域的内存分配和回收都具备确定性,在这几个区域内就不需要过多考虑回收的问题,因为方法结束或者线程结束时,内存自然就跟随着回收了。而Java堆和方法区则不一样,一个接口中的多个实现类需要的内存可能不一样,一个方法中的多个分支需要的内存也可能不一样,我们只有在程序处于运行期间时才能知道会创建哪些对象,这部分内存的分配和回收都是动态的,垃圾收集器所关注的是这部分内存。
判断对象已死
在堆里面存放着Java世界中几乎所有的对象实例,垃圾收集器在对堆进行回收前,第一件事情就是要确定这些对象之中哪些还“存活”着,哪些已经“死去”(即不可能再被任何途径使用的对象)。
(1)引用计数算法
很多教科书判断对象是否存活的算法是这样的:给对象中添加一个引用计数器,每当有一个地方引用它时,计数器值就加1;当引用失效时,计数器值就减1;任何时刻计数器为0的对象就是不可能再被使用的。作者面试过很多的应届生和一些有多年工作经验的开发人员,他们对于这个问题给予的都是这个答案。
客观地说,引用计数算法(Reference Counting)的实现简单,判定效率也很高,在大部分情况下它都是一个不错的算法,也有一些比较著名的应用案例,例如微软公司的COM(Component Object Model)技术、使用ActionScript 3的FlashPlayer、Python语言和在游戏脚本领域被广泛应用的Squirrel中都使用了引用计数算法进行内存管理。但是,至少主流的Java虚拟机里面没有选用引用计数算法来管理内存,其中最主要的原因是它很难解决对象之间相互循环引用的问题。
(2)可达性分析算法
在主流的商用程序语言(Java、C#,甚至包括前面提到的古老的Lisp)的主流实现中,都是称通过可达性分析(Reachability Analysis)来判定对象是否存活的。这个算法的基本思路就是通过一系列的称为“GC Roots”的对象作为起始点,从这些节点开始向下搜索,搜索所走过的路径称为引用链(Reference Chain),当一个对象到GC Roots没有任何引用链相连(用图论的话来说,就是从GC Roots到这个对象不可达)时,则证明此对象是不可用的。如图3-1所示,对象object 5、object 6、object 7虽然互相有关联,但是它们到GC Roots是不可达的,所以它们将会被判定为是可回收的对象。
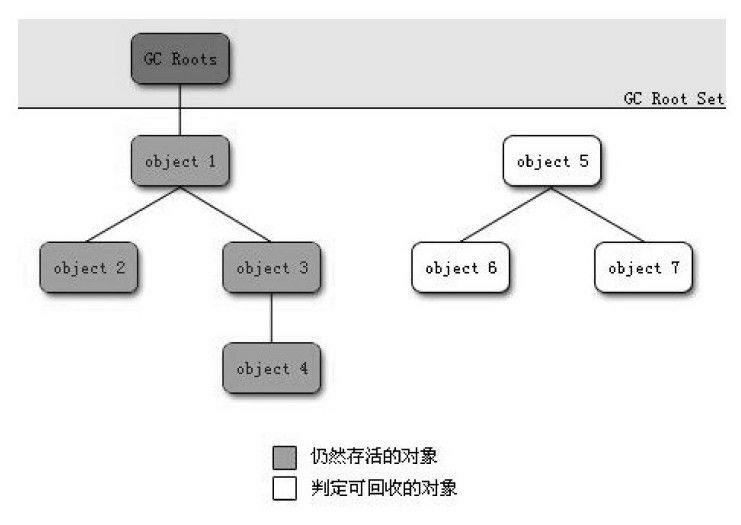
在Java语言中,可作为GC Roots的对象包括下面几种:
虚拟机栈(栈帧中的本地变量表)中引用的对象。
方法区中类静态属性引用的对象。
方法区中常量引用的对象。
本地方法栈中JNI(即一般说的Native方法)引用的对象。
生存还是死亡
即使在可达性分析算法中不可达的对象,也并非是“非死不可”的,这时候它们暂时处于“缓刑”阶段,要真正宣告一个对象死亡,至少要经历两次标记过程:如果对象在进行可达性分析后发现没有与GC Roots相连接的引用链,那它将会被第一次标记并且进行一次筛选,筛选的条件是此对象是否有必要执行finalize()方法。当对象没有覆盖finalize()方法,或者finalize()方法已经被虚拟机调用过,虚拟机将这两种情况都视为“没有必要执行”。
如果这个对象被判定为有必要执行finalize()方法,那么这个对象将会放置在一个叫做F-Queue的队列之中,并在稍后由一个由虚拟机自动建立的、低优先级的Finalizer线程去执行它。这里所谓的“执行”是指虚拟机会触发这个方法,但并不承诺会等待它运行结束,这样做的原因是,如果一个对象在finalize()方法中执行缓慢,或者发生了死循环(更极端的情),将很可能会导致F-Queue队列中其他对象永久处于等待,甚至导致整个内存回收系统崩溃。inalize()方法是对象逃脱死亡命运的最后一次机会,稍后GC将对F-Queue中的对象进行第次小规模的标记,如果对象要在finalize()中成功拯救自己——只要重新与引用链上的任何一个对象建立关联即可,譬如把自己(this关键字)赋值给某个类变量或者对象的成员变量,那在第二次标记时它将被移除出“即将回收”的集合;如果对象这时候还没有逃脱,那基本上它就真的被回收了。
需要特别说明的是,上面关于对象死亡时finalize()方法的描述可能带有悲情的艺术色彩,笔者并不鼓励大家使用这种方法来拯救对象。相反,笔者建议大家尽量避免使用它,因为它不是C/C++中的析构函数,而是Java刚诞生时为了使C/C++程序员更容易接受它所做出的一个妥协。它的运行代价高昂,不确定性大,无法保证各个对象的调用顺序。有些教材中描述它适合做“关闭外部资源”之类的工作,这完全是对这个方法用途的一种自我安慰。finalize()能做的所有工作,使用try-finally或者其他方式都可以做得更好、更及时,所以笔者建议大家完全可以忘掉Java语言中有这个方法的存在。
垃圾收集算法
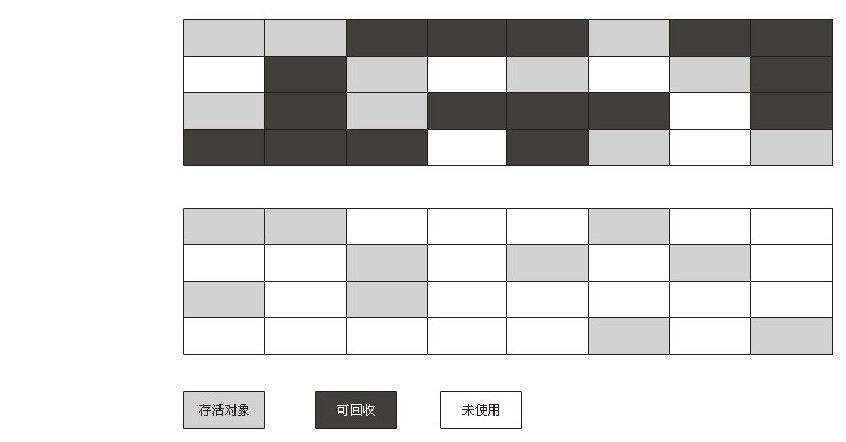
(1)标记-清除算法
最基础的收集算法是“标记-清除”(Mark-Sweep)算法,如同它的名字一样,算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所被标记的对象,它的标记过程其实在前一节讲述对象标记判定时已经介绍过了。之所以说它是最基础的收集算法,是因为后续的收集算法都是基于这种思路并对其不足进行改进而得到的。它的主要不足有两个:一个是效率问题,标记和清除两个过程的效率都不高;另一个是空间问题,标记清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致以后在程序运行过程中需要分配较大对象时,无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。标记—清除算法的执行过程如下图所示。
(2)复制算法
为了解决效率问题,一种称为“复制”(Copying)的收集算法出现了,它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。这样使得每次都是对整个半区进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况,只要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。只是这种算法的代价是将内存缩小为了原来的一半,未免太高了一点。复制算法的执行过程如下图所示。
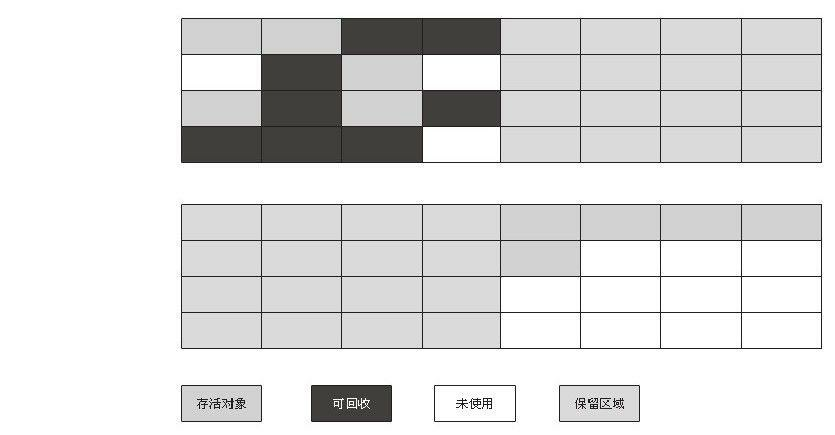
现在的商业虚拟机都采用这种收集算法来回收新生代,IBM公司的专门研究表明,新生代中的对象98%是“朝生夕死”的,所以并不需要按照1:1的比例来划分内存空间,而是将内存分为一块较大的Eden空间和两块较小的Survivor空间,每次使用Eden和其中一块Survivor 。当回收时,将Eden和Survivor中还存活着的对象一次性地复制到另外一块Survivor空间上,最后清理掉Eden和刚才用过的Survivor空间。HotSpot虚拟机默认Eden和Survivor的大小比例是8:1,也就是每次新生代中可用内存空间为整个新生代容量的90%(80%+10%),只有10%的内存会被“浪费”。当然,98%的对象可回收只是一般场景下的数据,我们没有办法保证每次回收都只有不多于10%的对象存活,当Survivor空间不够用时,需要依赖其他内存(这里指老年代)进行分配担保(Handle Promotion)。
内存的分配担保就好比我们去银行借款,如果我们信誉很好,在98%的情况下都能按时偿还,于是银行可能会默认我们下一次也能按时按量地偿还贷款,只需要有一个担保人能保证如果我不能还款时,可以从他的账户扣钱,那银行就认为没有风险了。内存的分配担保也一样,如果另外一块Survivor空间没有足够空间存放上一次新生代收集下来的存活对象时,这些对象将直接通过分配担保机制进入老年代。
(3)标记-整理算法
复制收集算法在对象存活率较高时就要进行较多的复制操作,效率将会变低。更关键的是,如果不想浪费50%的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以在老年代一般不能直接选用这种算法。
根据老年代的特点,有人提出了另外一种“标记-整理”(Mark-Compact)算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存,“标记-整理”算法的示意图如下图所示。
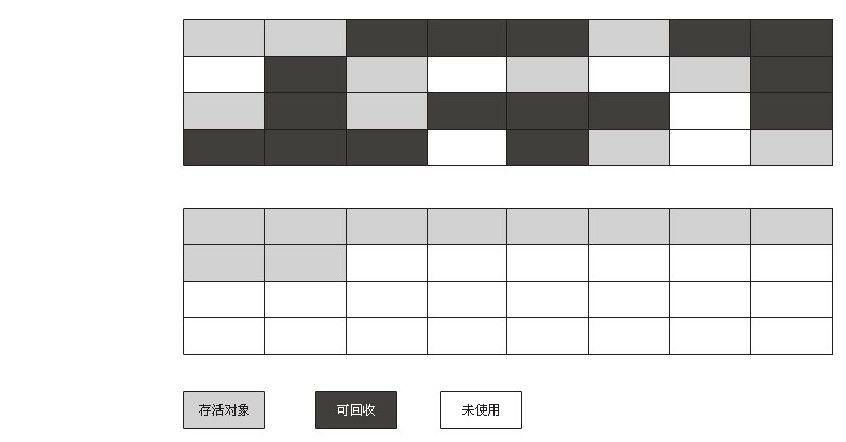
(4)分代收集算法
当前商业虚拟机的垃圾收集都采用“分代收集”(Generational Collection)算法,这种算法并没有什么新的思想,只是根据对象存活周期的不同将内存划分为几块。一般是把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记—清理”或者“标记—整理”算法来进行回收。
垃圾收集器
如果说收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。Java虚拟机规范中对垃圾收集器应该如何实现并没有任何规定,因此不同的厂商、不同版本的虚拟机所提供的垃圾收集器都可能会有很大差别,并且一般都会提供参数供用户根据自己的应用特点和要求组合出各个年代所使用的收集器。这里讨论的收集器基于JDK 1.7 Update 14之后的HotSpot虚拟机(在这个版本中正式提供了商用的G1收集器,之前G1仍处于实验状态),这个虚拟机包含的所有收集器如下图所示。
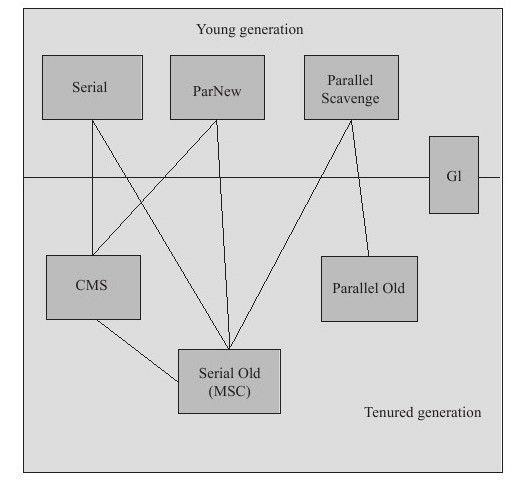
上图展示了7种作用于不同分代的收集器,如果两个收集器之间存在连线,就说明它们可以搭配使用。虚拟机所处的区域,则表示它是属于新生代收集器还是老年代收集器。
虽然我们是在对各个收集器进行比较,但并非为了挑选出一个最好的收集器。因为直到现在为止还没有最好的收集器出现,更加没有万能的收集器,所以我们选择的只是对具体应用最合适的收集器。这点不需要多加解释就能证明:如果有一种放之四海皆准、任何场景下都适用的完美收集器存在,那HotSpot虚拟机就没必要实现那么多不同的收集器了。
内存分配与回收策略
Java技术体系中所提倡的自动内存管理最终可以归结为自动化地解决了两个问题:给对象分配内存以及回收分配给对象的内存。
对象的内存分配,往大方向讲,就是在堆上分配(但也可能经过JIT编译后被拆散为标量类型并间接地栈上分配 ),对象主要分配在新生代的Eden区上,如果启动了本地线程分配缓冲,将按线程优先在TLAB上分配。少数情况下也可能会直接分配在老年代中,分配的规则并不是百分之百固定的,其细节取决于当前使用的是哪一种垃圾收集器组合,还有虚拟机中与内存相关的参数的设置。
(1)对象优先在Eden分配
大多数情况下,对象在新生代Eden区中分配。当Eden区没有足够空间进行分配时,虚拟机将发起一次Minor GC。
(2)大对象直接进入老年代
所谓的大对象是指,需要大量连续内存空间的Java对象,最典型的大对象就是那种很长的字符串以及数组。大对象对虚拟机的内存分配来说就是一个坏消息(替Java虚拟机抱怨一句,比遇到一个大对象更加坏的消息就是遇到一群“朝生夕灭”的“短命大对象”,写程序的时候应当避免),经常出现大对象容易导致内存还有不少空间时就提前触发垃圾收集以获取足够的连续空间来“安置”它们。
(3)长期存活的对象将进入老年代
既然虚拟机采用了分代收集的思想来管理内存,那么内存回收时就必须能识别哪些对象应放在新生代,哪些对象应放在老年代中。为了做到这点,虚拟机给每个对象定义了一个对象年龄(Age)计数器。如果对象在Eden出生并经过第一次Minor GC后仍然存活,并且能被Survivor容纳的话,将被移动到Survivor空间中,并且对象年龄设为1。对象在Survivor区中每“熬过”一次Minor GC,年龄就增加1岁,当它的年龄增加到一定程度(默认为15岁),就将会被晋升到老年代中。对象晋升老年代的年龄阈值,可以通过参数-XX:MaxTenuringThreshold设置。
(4)动态对象年龄判定
为了能更好地适应不同程序的内存状况,虚拟机并不是永远地要求对象的年龄必须达到了MaxTenuringThreshold才能晋升老年代,如果在Survivor空间中相同年龄所有对象大小的总和大于Survivor空间的一半,年龄大于或等于该年龄的对象就可以直接进入老年代,无须等到MaxTenuringThreshold中要求的年龄。
(5)空间分配担保
在发生Minor GC之前,虚拟机会先检查老年代最大可用的连续空间是否大于新生代所有对象总空间,如果这个条件成立,那么Minor GC可以确保是安全的。如果不成立,则虚拟机会查看HandlePromotionFailure设置值是否允许担保失败。如果允许,那么会继续检查老年代最大可用的连续空间是否大于历次晋升到老年代对象的平均大小,如果大于,将尝试着进行一次Minor GC,尽管这次Minor GC是有风险的;如果小于,或者HandlePromotionFailure设置不允许冒险,那这时也要改为进行一次Full GC。
类文件结构
代码编译的结果从本地机器码转变为字节码,是存储格式发展的一小步,却是编程语言发展的一大步。
时至今日,商业机构和开源机构已经在Java语言之外发展出一大批在Java虚拟机之上运行的语言,如Clojure、Groovy、JRuby、Jython、Scala等。使用过这些语言的开发者可能还不是非常多,但是听说过的人肯定已经不少,随着时间的推移,谁能保证日后Java虚拟机在语言无关性上的优势不会赶上甚至超越它在平台无关性上的优势呢?
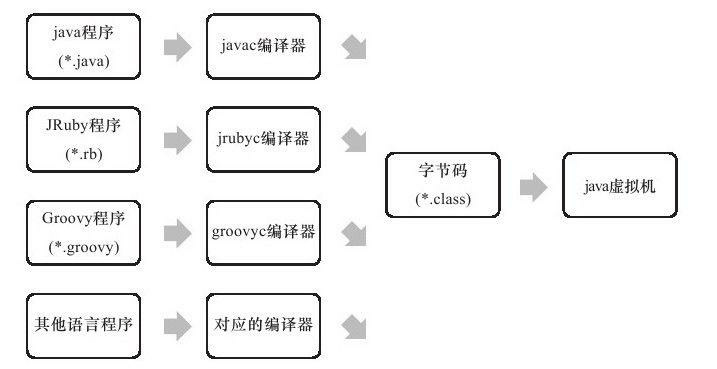
实现语言无关性的基础仍然是虚拟机和字节码存储格式。Java虚拟机不和包括Java在内的任何语言绑定,它只与“Class文件”这种特定的二进制文件格式所关联,Class文件中包含了Java虚拟机指令集和符号表以及若干其他辅助信息。基于安全方面的考虑,Java虚拟机规范要求在Class文件中使用许多强制性的语法和结构化约束,但任一门功能性语言都可以表示为一个能被Java虚拟机所接受的有效的Class文件。作为一个通用的、机器无关的执行平台,任何其他语言的实现者都可以将Java虚拟机作为语言的产品交付媒介。例如,使用Java编译器可以把Java代码编译为存储字节码的Class文件,使用JRuby等其他语言的编译器一样可以把程序代码编译成Class文件,虚拟机并不关心Class的来源是何种语言,如下图所示。
Java语言中的各种变量、关键字和运算符号的语义最终都是由多条字节码命令组合而成的,因此字节码命令所能提供的语义描述能力肯定会比Java语言本身更加强大。因此,有一些Java语言本身无法有效支持的语言特性不代表字节码本身无法有效支持,这也为其他语言实现一些有别于Java的语言特性提供了基础。
Class文件是一组以8位字节为基础单位的二进制流,各个数据项目严格按照顺序紧凑地排列在Class文件之中,中间没有添加任何分隔符,这使得整个Class文件中存储的内容几乎全部是程序运行的必要数据,没有空隙存在。当遇到需要占用8位字节以上空间的数据项时,则会按照高位在前的方式分割成若干个8位字节进行存储。
根据Java虚拟机规范的规定,Class文件格式采用一种类似于C语言结构体的伪结构来存储数据,这种伪结构中只有两种数据类型:无符号数和表,后面的解析都要以这两种数据类型为基础,所以这里要先介绍这两个概念。
无符号数属于基本的数据类型,以u1、u2、u4、u8来分别代表1个字节、2个字节、4个字节和8个字节的无符号数,无符号数可以用来描述数字、索引引用、数量值或者按照UTF-8编码构成字符串值。
表是由多个无符号数或者其他表作为数据项构成的复合数据类型,所有表都习惯性地以“_info”结尾。表用于描述有层次关系的复合结构的数据,整个Class文件本质上就是一张表,它由下图所示的数据项构成。

虚拟机类加载机制
虚拟机把描述类的数据从Class文件加载到内存,并对数据进行校验、转换解析和初始化,最终形成可以被虚拟机直接使用的Java类型,这就是虚拟机的类加载机制。
与那些在编译时需要进行连接工作的语言不同,在Java语言里面,类型的加载、连接和初始化过程都是在程序运行期间完成的,这种策略虽然会令类加载时稍微增加一些性能开销,但是会为Java应用程序提供高度的灵活性,Java里天生可以动态扩展的语言特性就是依赖运行期动态加载和动态连接这个特点实现的。例如,如果编写一个面向接口的应用程序,可以等到运行时再指定其实际的实现类;用户可以通过Java预定义的和自定义类加载器,让一个本地的应用程序可以在运行时从网络或其他地方加载一个二进制流作为程序代码的一部分,这种组装应用程序的方式目前已广泛应用于Java程序之中。从最基础的Applet、JSP到相对复杂的OSGi技术,都使用了Java语言运行期类加载的特性。
类从被加载到虚拟机内存中开始,到卸载出内存为止,它的整个生命周期包括:加载(Loading)、验证(Verification)、准备(Preparation)、解析(Resolution)、初始化(Initialization)、使用(Using)和卸载(Unloading)7个阶段。其中验证、准备、解析3
部分统称为连接(Linking),这7个阶段的发生顺序如下图所示。
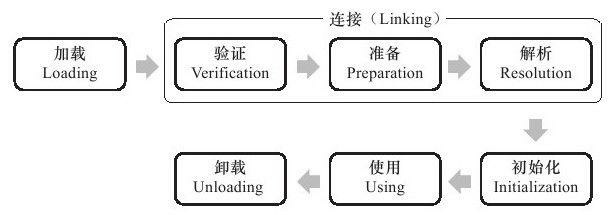
加载、验证、准备、初始化和卸载这5个阶段的顺序是确定的,类的加载过程必须按照这种顺序按部就班地开始,而解析阶段则不一定:它在某些情况下可以在初始化阶段之后再开始,这是为了支持Java语言的运行时绑定(也称为动态绑定或晚期绑定)。注意,这里写的是按部就班地“开始”,而不是按部就班地“进行”或“完成”,强调这点是因为这些阶段通常都是互相交叉地混合式进行的,通常会在一个阶段执行的过程中调用、激活另外一个阶段。
虚拟机设计团队把类加载阶段中的“通过一个类的全限定名来获取描述此类的二进制字节流”这个动作放到Java虚拟机外部去实现,以便让应用程序自己决定如何去获取所需要的类。实现这个动作的代码模块称为“类加载器”。
类加载器可以说是Java语言的一项创新,也是Java语言流行的重要原因之一,它最初是为了满足Java Applet的需求而开发出来的。虽然目前Java Applet技术基本上已经“死掉”,但类加载器却在类层次划分、OSGi、热部署、代码加密等领域大放异彩,成为了Java技术体系中一块重要的基石,可谓是失之桑榆,收之东隅。
类加载器虽然只用于实现类的加载动作,但它在Java程序中起到的作用却远远不限于类加载阶段。对于任意一个类,都需要由加载它的类加载器和这个类本身一同确立其在Java虚拟机中的唯一性,每一个类加载器,都拥有一个独立的类名称空间。这句话可以表达得更通俗一些:比较两个类是否“相等”,只有在这两个类是由同一个类加载器加载的前提下才有意义,否则,即使这两个类来源于同一个Class文件,被同一个虚拟机加载,只要加载它们的类加载器不同,那这两个类就必定不相等。
这里所指的“相等”,包括代表类的Class对象的equals()方法、isAssignableFrom()方法、isInstance()方法的返回结果,也包括使用instanceof关键字做对象所属关系判定等情况。如果没有注意到类加载器的影响,在某些情况下可能会产生具有迷惑性的结果。
从Java虚拟机的角度来讲,只存在两种不同的类加载器:一种是启动类加载器(Bootstrap ClassLoader),这个类加载器使用C++语言实现,是虚拟机自身的一部分;另一种就是所有其他的类加载器,这些类加载器都由Java语言实现,独立于虚拟机外部,并且全都继承自抽象类java.lang.ClassLoader。
从Java开发人员的角度来看,类加载器还可以划分得更细致一些,绝大部分Java程序都会使用到以下3种系统提供的类加载器。
启动类加载器(Bootstrap ClassLoader):这个类将器负责将存放在<JAVA_HOME>\lib目录中的,或者被-Xbootclasspath参数所指定的路径中的,并且是虚拟机识别的(仅按照文件名识别,如rt.jar,名字不符合的类库即使放在lib目录中也不会被加载)类库加载到虚拟机内存中。启动类加载器无法被Java程序直接引用,用户在编写自定义类加载器时,如果需要把加载请求委派给引导类加载器,那直接使用null代替即可。
扩展类加载器(Extension ClassLoader):这个加载器由sun.misc.Launcher$ExtClassLoader实现,它负责加载<JAVA_HOME>\lib\ext目录中的,或者被java.ext.dirs系统变量所指定的路径中的所有类库,开发者可以直接使用扩展类加载器。
应用程序类加载器(Application ClassLoader):这个类加载器由sun.misc.Launcher $App-ClassLoader实现。由于这个类加载器是ClassLoader中的getSystemClassLoader()方法的返回值,所以一般也称它为系统类加载器。它负责加载用户类路径(ClassPath)上所指定的类库,开发者可以直接使用这个类加载器,如果应用程序中没有自定义过自己的类加载器,一般情况下这个就是程序中默认的类加载器。
我们的应用程序都是由这3种类加载器互相配合进行加载的,如果有必要,还可以加入自己定义的类加载器。这些类加载器之间的关系一般如下图所示。
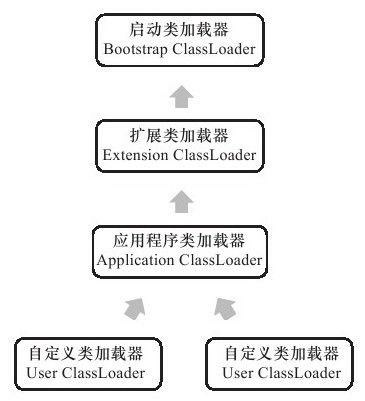
上图展示的类加载器之间的这种层次关系,称为类加载器的双亲委派模型(ParentsDelegation Model)。双亲委派模型要求除了顶层的启动类加载器外,其余的类加载器都应当有自己的父类加载器。这里类加载器之间的父子关系一般不会以继承(Inheritance)的关系来实现,而是都使用组合(Composition)关系来复用父加载器的代码。
双亲委派模型的工作过程是:如果一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载。
Java SE API所有包的作用
java.applet
提供了需要创建一个小程序和用来跟其他小程序交流上下文的类。
java.awt
包含了所有用于创建用户界面和绘制图形和图像的类。
java.awt.color
提供了颜色空间的类。
java.awt.datatransfer
提供了应用程序内部和应用程序之间进行数据交换的接口和类。
java.awt.dnd
拖放功能是分布在许多提供一个与GUI中的显示元素逻辑相关的两个实体之间交换数据机制的用户界面系统中的直接操作动作。
java.awt.event
提供了处理由AWT组件激活的不同类型的事件的接口和类。
java.awt.font
提供了与字体相关的类和接口。
java.awt.geom
提供了定义和执行二维几何相关对象的Java 2D类。
java.awt.im
提供了输入法框架的类和接口。
java.awt.im.spi
提供了能开发可用于在任何Java运行环境的输入法的接口。
java.awt.image
提供了创建和修改图片的类。
java.awt.image.renderable
提供了生产呈现无关的图像类和接口。
java.awt.print
提供了通用的打印API的类和接口。
java.beans
包含了beans(基于JavaBean架构组件)开发相关的类。
java.beans.beancontext
提供了bean上下文相关的类和接口。
java.io
提供了通过数据流、序列化和文件系统进行的系统系统输入和输出。
java.lang
提供了Java编程语言基础设计的类。
java.lang.annotation
提供了支持Java编程语言的注释设备库
java.lang.instrument
提供了允许Java编程语言代理运行在JVM上的程序的服务。
java.lang.invoke
java.lang.invoke包包含了直接提供Java核心类库和虚拟机的动态语言支持。
java.lang.management
提供了Java运行时监控和管理Java虚拟机和其他组件的管理接口。
java.lang.ref
提供了与垃圾回收器有限程度交互作用的引用对象类。
java.lang.reflect
提供了获取关于类和对象反射信息的类和接口。
java.math
提供了执行任意精度整数算法(BigInteger)和任意精度小数算法的类。
java.net
提供了实现网络应用程序的类。
java.nio
定义了缓冲器,它是数据容器,并且提供其他NIO包的概述。
java.nio.channels
定义了描述连接能够执行I/O操作的实体,例如文件和sockets。定义了多路复用且非阻塞I/O操作的选择器。
java.nio.channels.spi
java.nio.channels包的服务提供者类。
java.nio.charset
定义了用于字节和统一编码字符之间转换的字符集、解码器和编码器。
java.nio.charset.spi
java.nio.charset包的服务提供者类。
java.nio.file
定义了Java虚拟机访问文件、文件属性和文件系统的接口和类。
java.nio.file.attribute
提供访问文件和文件系统属性的接口和类。
java.nio.file.spi
java.nio.file.spi包的服务提供者类。
java.rmi
提供了RMI包。
java.rmi.activation
为RMI对象激活提供支持。
java.rmi.dgc
提供了RMI分布式垃圾收集(DGC)的类和接口。
java.rmi.registry
提供了RMI注册表的一个类和两个接口。
java.rmi.server
提供了支持RMI的服务器端的类和接口。
java.security
提供了安全框架的类和接口。
java.security.acl
这个包里的类和接口已经取代了 in the java.security包的类。
java.security.cert
提供了解析和管理证书、证书废除列表(CRLs)和证书路径的类和接口。
java.security.interfaces
提供了生成在RSA实验室技术说明PKS#1中定义的RSA(Rivest,Shamir和Adleman AsymmetricCipher算法)密匙和在NIST’s FIPS-186中定义的DSA(数字信号算法)密匙的接口。
java.security.spec
提供了密匙规范和算法参数规范的类和接口。
java.sql
提供了使用Java编程语言访问和处理存储在一个数据源(通常是一个关系数据库)的API。
java.text
提供了语言无关的方式处理文本、日期、数字和信息的类和接口。
java.text.spi
java.text包的服务提供者类。
java.time
日期、时间、时刻和时间段的主要API。
java.time.chrono
不同于默认ISO的日历系统的通用API。
java.time.format
提供了打印和解析日期和时间的类。
java.time.temporal
使用字段和单元和日期时间调整来访问日期和时间,
java.time.zone
时区及其规则的支持。
java.util
包含了集合框架、遗留的集合类、事件模型、日期和时间工具、国际化和各种各样的工具类(一个字符编译器、一个随机数生成器和一个位数组)。
java.util.concurrent
用于并发编程的的公共工具类。
java.util.concurrent.atomic
支持单一变量无锁和线程安全的小工具类。
java.util.concurrent.locks
为锁定和等待不同的内置同步和监视器提供一个框架的类和接口。
java.util.function
为微积分表达式和方法引用提供目标类型的功能接口。
java.util.jar
提供了读写JAR(Java归档)文件格式,它是基于标准的的ZIP文件格式和一个可选清单文件的。
java.util.logging
为JavaTM2平台核心日志工具提供了类和接口。
java.util.prefs
此包允许应用程序存储并检索用户和系统首选项和配置数据。
java.util.regex
用于匹配违反了正则表达式指定模式的字符序列的类。
java.util.spi
java.util包的服务提供者类。
java.util.stream
支持在如集合多核处理转换这样的元素流上的功能样式操作的类。
java.util.zip
提供了读写标准的ZIP和GZIP文件格式的类。
javax.accessibility
定义了用户界面组件和提供了访问其他组件的辅助技术之间的协议。
javax.activation
javax.activity
包含了解组期间通过ORB机制抛出异常的相关活动服务。
javax.annotation
javax.annotation.processing
声明注释处理器和允许注释处理器与注释处理工具环境通信的工具。
javax.crypto
提供了加密操作的类和接口。
javax.crypto.interfaces
提供了RSA实验室的PKCS#3中定义的Diffie-Hellman密钥接口。
javax.crypto.spec
提供了密匙规范和算法参数规范的类和接口。
javax.imageio
Java 图像 I/O API 的主包。
javax.imageio.event
一个在读写图像期间Java 图像 I/O API处理同步通知的事件的包。
javax.imageio.metadata
Java 图像 I/O API处理读写元数据的一个包。
javax.imageio.plugins.bmp
包含了用于内置BMP插件公共类的包。
javax.imageio.plugins.jpeg
支持内置JPEG插件的类。
javax.imageio.spi
Java图像I/O API的包含阅读器、写入器、转码器和流,和一个运行时注册表的插件接口的包。
javax.imageio.stream
Java图像I/O API处理低级文件和流的包。
javax.jws
javax.jws.soap
javax.lang.model
用于模拟Java编程语言的类和包层次结构。
javax.lang.model.element
用于模拟Java编程语言的元素接口。
javax.lang.model.type
用于模拟Java编程语言的类型的接口。
javax.lang.model.util
帮助在编程元素和类型过程中处理的实用程序。
javax.management
提供了Java管理拓展的核心类。
javax.management.loading
提供了实现高级动态加载的类。
javax.management.modelmbean
提供了ModelMBean类的定义。
javax.management.monitor
提供了监视器类的定义。
javax.management.openmbean
提供了开放数据类型和开放MNBeam描述符类。
javax.management.relation
提供了关系服务的定义。
javax.management.remote
远程访问JMX MBean服务器的接口。
javax.management.remote.rmi
RMI连接器是一个使用RMI来传输客户端请求道一个远程MBean服务器的 JMX Remote API 连接器。
javax.management.timer
提供了MBean定时器的定义。
javax.naming
提供了访问命名服务的类和接口。
javax.naming.directory
扩展了he javax.naming包提供访问目录服务的功能。
javax.naming.event
提供了当访问命名和目录服务时支持事件通知。
javax.naming.ldap
提供了支持LDAPv3 扩展操作和控制。
javax.naming.spi
javax.net
提供了网络应用的类。
javax.net.ssl
提供了安全套接字包。
javax.print
提供了Java打印服务API 的主要类和接口。
javax.print.attribute
提供了描述Java打印服务属性和如何将它们收集到属性集中的类和接口。
javax.print.attribute.standard
javax.print.attribute.standard 包包含了特定打印属性的类。
javax.print.event
javax.print.event包包含了事件类和监听接口。
javax.rmi
包含了RMI-IIOP的用户APIs。
javax.rmi.CORBA
包含了 RMI-IIOP的便携性APIs。
javax.rmi.ssl
提供了安全套接字层(SSL)或传输层安全(TLS)协议之上的RMIClientSocketFactory和RMIServerSocketFactory的实现。
javax.script
组成API脚本的和接口定义了Java TM脚本引擎并提供了它们在Java应用程序中使用的一个。框架
javax.security.auth
此包提供了验证和授权的框架。
javax.security.auth.callback
此包提供了为了检索信息(验证包含例如用户名或密码的数据)或者呈现信息(例如错误和警告信息)相作用的所需要的服务类。
javax.security.auth.kerberos
此包包含了Kerberos 网络验证协议相关的实用工具类。
javax.security.auth.login
此包提供了一个可插拔的认证框架。
javax.security.auth.spi
此包提供了用于实现可插入验证模块的接口。
javax.security.auth.x500
此包包含了可用于存储X500 Principal 和 X500私有证书的主题类。
javax.security.cert
提供了用于公钥证书的类。
javax.security.sasl
包含了支持SASL的类和接口。
javax.sound.midi
提供了I/O、 系列化和合成MIDI(音乐乐器数字接口)数据的接口和类。
avax.sound.midi.spi
提供接口当提供新的MIDI设备、MIDI文件读写器或音库读取器时服务提供者去实现。
javax.sound.sampled
提供了捕获、处理和音频数据取样回放的接口和类。
javax.sound.sampled.spi
当提供音频设备、声音文件读写器或音频格式转换器时提供抽象类给服务提供者作为子类。
javax.sql
javax.sql.rowset
JDBC RowSet实现的标准接口和基类。
avax.sql.rowset.serial
在Java编程语言中提供了允许SQL类型和数据类型之间序列化映射的实用工具类。
javax.sql.rowset.spi
给同步提供者的实现中使用的第三方供应商的标准类和接口。
javax.swing
提供了一组“轻量级”(纯Java语言)组件,最大程度的可能,在所有平台上进行同样的工作。
javax.swing.border
提供了围绕一个Swing组件绘制特殊边框的类和接口。
javax.swing.colorchooser
包含了供JColorChooser组件使用的类和接口。
javax.swing.event
提供了由Swing组件触发的事件。
javax.swing.filechooser
包含用于JFileChooser组件的类和接口。
javax.swing.plaf
提供一个接口和许多抽象类,Swing用它们来提供自己的可插入的外观和感觉功能。
javax.swing.plaf.basic
提供了根据基本外观构建的用户界面对象。
javax.swing.plaf.metal
提供根据Java外观(曾经代称为Metal)构建的用户界面对象,这是默认的外观和感觉。
javax.swing.plaf.multi
提供了组合两个或多个外观的用户界面对象。
javax.swing.plaf.nimbus
提供了根据跨平台的Nimbus外观构建的用户界面对象。
javax.swing.plaf.synth
Synth是一个可更换皮肤的外观,其中所有绘制都是可委托的。
javax.swing.table
提供了处理 javax.swing.JTable.的类和接口。
javax.swing.text
提供了处理可编辑和不可编辑的文本组件的类和接口。
javax.swing.text.html
提供了用于创建HTML文本编辑器的HTMLEditorKit和支持类。
javax.swing.text.html.parser
提供了默认的HTML解析器以及支持类。
javax.swing.text.rtf
提供一个类(RTFEditorKit),用于创建富文本格式的文本编辑器。
javax.swing.tree
提供了处理 javax.swing.JTree的类和接口。
javax.swing.undo
允许开发者提供支持撤消/重做的应用,如文本编辑器。
javax.tools
提供le 可以从一个程序被调用的接口,例如编译器工具。
javax.transaction
包含解组期间ORB机制抛出的三个异常。
javax.transaction.xa
提供了事务管理和资源管理之间的协议的定义,这样允许事务管理在JTA事务中去获取和去除资源对象(由资源管理驱动程序提供)。
javax.xml
javax.xml.bind
提供了一个运运行时绑定框架给客户端应用程序,包括解组、编组和验证功能。
javax.xml.bind.annotation
定义为XML模式映射定义Java变成元素的注释
javax.xml.bind.annotation.adapters
XmlAdapter及其规范定义的子类允许任意Java类与JAXB一起使用。
javax.xml.bind.attachment
javax.xml.bind.helpers
JAXB提供者专用:提供部分默认实现一些 the javax.xml.bind接口。
javax.xml.bind.util
有用的客户端实用工具类。
javax.xml.crypto
XML加密通用类。
javax.xml.crypto.dom
javax.xml.crypto包的DOM特定类。
javax.xml.crypto.dsig
用于生成和验证XML数字签名的类。
javax.xml.crypto.dsig.dom
javax.xml.crypto.dsig包的DOM特定类。
javax.xml.crypto.dsig.keyinfo
解析和处理KeyInfo元素和结构的类。
javax.xml.crypto.dsig.spec
XML数字签名的参数类。
javax.xml.datatype
XML/Java类型映射。
javax.xml.namespace
XML命名空间的处理。
javax.xml.parsers
提供允许处理XML文档的处理的类。
javax.xml.soap
提供用于创建和构建SOAP消息的API。
javax.xml.stream
javax.xml.stream.events
javax.xml.stream.util
javax.xml.transform
此包定义了用于处理转换指令,以及执行从源到结果的转换的一般API。
javax.xml.transform.dom
此包实现特定DOM的转换API。
javax.xml.transform.sax
此包实现了特定SAX2的转换API。
javax.xml.transform.stax
提供了特定的StAX的转换API。
javax.xml.transform.stream
此包实现了流和特定URI转换API。
javax.xml.validation
此包提供了用于XML文档验证的API。
javax.xml.ws
此包包含核心JAX-WS的API。
javax.xml.ws.handler
此包定义了消息处理程序的API。
javax.xml.ws.handler.soap
此包定义了SOAP消息处理程序的API。
javax.xml.ws.http
此包定义了特定于HTTP绑定的API。
javax.xml.ws.soap
此包定义了特定于SOAP绑定的API。
javax.xml.ws.spi
此包定义了JAX-WS的SPI。
javax.xml.ws.spi.http
提供了一个用于便携式容器部署JAX-WS Web服务(如用于HTTP SPI 提供了一个HTTP SPI用于在容器中JAX-WS服务的便携式部署(例如..)。
javax.xml.ws.wsaddressing
此包定义了WS-Addressing相关的API。
javax.xml.xpath
此件包为XPath表达式的访问评估和访问评估环境提供了对象模型中立的API。
org.ietf.jgss
此包提供了一个框架,允许应用程序开发人员使用安全服务,如身份验证,数据完整性和数据保密性的各种如Kerberos基础安全机制,采用了统一的API。
org.omg.CORBA
提供OMG CORBA API到JavaTM的编程语言的映射,包括ORB类,它已经实现,因此程序员可以使用它作为一个全功能对象请求代理(ORB)。
org.omg.CORBA_2_3
CORBA23包定义添加到Java(TM)标准版6现有的CORBA接口。这些改变发生在最近的由OMG定义的CORBA API版本。这些新的方法被添加到从在CORBA包中的相应接口派生的接口。这提供向后兼容性和避免断JCK测试。
org.omg.CORBA_2_3.portable
提供输入和输出值类型的方法,并包含其他更新的org/omg/CORBA便携包。
org.omg.CORBA.DynAnyPackage
提供了用DynAny接口((InvalidValue, Invalid, InvalidSeq, and TypeMismatch)方式使用的异常。
org.omg.CORBA.ORBPackage
提供了InvalidName异常,这是由ORB方法抛出的,保留最初参数和InconsistentTypeCode异常,这是由ORB类中的动态Any创建的方法抛出的。
org.omg.CORBA.portable
提供可移植性层,即一组ORB API,这些API可以使一个供应商生成到另一个供应商的ORB运行代码。
org.omg.CORBA.TypeCodePackage
提供用户定义的异常BadKind和Bounds,它们通过方法TypeCode类中抛出。
org.omg.CosNaming
为Java IDL提供命名服务。
org.omg.CosNaming.NamingContextExtPackage
此包包含以下类,它们用于org.omg.CosNaming.NamingContextExt。
org.omg.CosNaming.NamingContextPackage
此包包含了 org.omg.CosNaming 包的异常类。
org.omg.Dynamic
此包包含了OMG移植拦截规范中的特定动态模块。
org.omg.DynamicAny
提供了能够遍历与任何运行时关联的数据值,并能提取出数值的原始成分的类和接口。
org.omg.DynamicAny.DynAnyFactoryPackage
此包包含了 DynAnyFactory接口中来自OMG的公共对象请求代理的定的DynamicAny模块的类和异常:结构和规范。
org.omg.DynamicAny.DynAnyPackage
此包包含了 DynAny接口中来自OMG的公共对象请求代理的定的DynamicAny模块的类和异常:结构和规范。
org.omg.IOP
此包包含了这个软件包包含了OMG文档中的通用对象请求代理指定的IOP模块:结构和规范。
org.omg.IOP.CodecFactoryPackage
此包包含了IOP :: CodeFactory接口中指定的异常(作为Portable Interceptor规范的一部分)。
org.omg.IOP.CodecPackage
这个包是从IOP ::编解码器IDL接口定义生成。
org.omg.Messaging
此包包含了CORBA消息规范中的特定消息模块。
org.omg.PortableInterceptor
提供了一个注册ORB钩子通过ORB服务可以截取执行ORB的正常流动的机制。
org.omg.PortableInterceptor.ORBInitInfoPackage
此包包含了来自OMG移植拦截规范中的HTTP指定的PortableInterceptor模块的ORBInitInfo本地接口的异常和类型定义。
org.omg.PortableServer
提供使您的应用程序移植的服务器端跨多个供应商ORB的类和接口。
org.omg.PortableServer.CurrentPackage
供方法实现能够访问被调用的方法的对象的身份。
org.omg.PortableServer.POAManagerPackage
封装POA关联的处理状态
org.omg.PortableServer.POAPackage
允许程序员构造便携不同ORB产品间对象实现。
org.omg.PortableServer.portable
提供使您的应用程序移植跨多个供应商ORB的服务器端的类和接口。
org.omg.PortableServer.ServantLocatorPackage
提供定位servant的类和接口。
org.omg.SendingContext
为值类型的编组提供支持。
org.omg.stub.java.rmi
包含RMI-IIOP Stubs给发生在 java.rmi包的远程类型。
org.w3c.dom
为文档对象模型(DOM)提供接口。
org.w3c.dom.Bootstrap
org.w3c.dom.events
org.w3c.dom.ls
org.w3c.dom.views
org.xml.sax
此包提供了核心SAX API。
org.xml.sax.ext
此包包含SAX2设施的接口,一致性的SAX驱动程序不一定支持。
org.xml.sax.helpers
此包包含“帮助器”类,其中包括对引导基于SAX的应用程序的支持。
Java历代版本新特性
Java 5的新特性
泛型
所谓类型擦除指的就是Java源码中的范型信息只允许停留在编译前期,而编译后的字节码文件中将不再保留任何的范型信息。也就是说,范型信息在编译时将会被全部删除,其中范型类型的类型参数则会被替换为Object类型,并在实际使用时强制转换为指定的目标数据类型。而C++中的模板则会在编译时将模板类型中的类型参数根据所传递的指定数据类型生成相对应的目标代码。
Map<Integer, Integer> squares = new HashMap<Integer, Integer>();- 1
枚举
JDK1.5加入了一个全新类型的“类”—枚举类型。为此JDK1.5引入了一个新关键字enum。
【并不能说成是一个类,它的真正类型叫枚举,但是它和类又很像。】
我们可以这样来定义一个枚举类型
Public enum Color{
Red;
White;
Blue;
} - 1
- 2
- 3
- 4
- 5
然后这样来使用Color myColor = Color.Red;
自动装箱和拆箱
将基本类型转换成对应的封装类型:Boolean、Byte、Short、Character、Integer、Long、Float、Double。
可变长度的参数列表
private String print(Object... values) {
StringBuilder sb = new StringBuilder();
for (Object o : values) {
sb.append(o.toString())
.append(" ");
}
return sb.toString();
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
注解
注解(Annotation)就是在程序中加上一些说明,容器在调用这些类,方法的时候就知道怎么处理了。
for/in
for/in循环办不到的事情:
(1)遍历同时获取index
(2)集合逗号拼接时去掉最后一个
(3)遍历的同时删除元素
静态import
import static java.lang.System.err;
import static java.lang.System.out;
import java.io.IOException;
import java.io.PrintStream;
public class StaticImporter {
public static void writeError(PrintStream err, String msg)
throws IOException {
// Note that err in the parameter list overshadows the imported err
err.println(msg);
}
public static void main(String[] args) {
if (args.length < 2) {
err.println(
"Incorrect usage: java com.oreilly.tiger.ch08 [arg1] [arg2]");
return;
}
out.println("Good morning, " + args[0]);
out.println("Have a " + args[1] + " day!");
try {
writeError(System.out, "Error occurred.");
} catch (IOException e) {
e.printStackTrace();
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
格式化
public static void stringFormat()
{
// Format a string containing a date.
Calendar c = new GregorianCalendar(1995, MAY, 23);
String s = String.format("Duke's Birthday: %1$tm %1$te,%1$tY", c);
// -> s == "Duke's Birthday: May 23, 1995"
System.out.println(s);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Java 6的新特性
脚本引擎
public class BasicScripting {
public void greet() throws ScriptException {
ScriptEngineManager manager = new ScriptEngineManager();
//支持通过名称、文件扩展名、MIMEtype查找
ScriptEngine engine = manager.getEngineByName("JavaScript");
// engine = manager.getEngineByExtension("js");
// engine = manager.getEngineByMimeType("text/javascript");
if (engine == null) {
throw new RuntimeException("找不到JavaScript语言执行引擎。");
}
engine.eval("println('Hello!');");
}
public static void main(String[] args) {
try {
new BasicScripting().greet();
} catch (ScriptException ex) {
Logger.getLogger(BasicScripting.class.getName()).log(Level.SEVERE, null, ex);
}
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
Java Compiler API
现在我们可以用JDK6 的Compiler API(JSR 199)去动态编译Java源文件,Compiler API结合反射功能就可以实现动态的产生Java代码并编译执行这些代码,有点动态语言的特征。这个特性对于某些需要用到动态编译的应用程序相当有用,比如JSP Web Server,当我们手动修改JSP后,是不希望需要重启Web Server才可以看到效果的,这时候我们就可以用Compiler API来实现动态编译JSP文件,当然,现在的JSP Web Server也是支持JSP热部署的,现在的JSP Web Server通过在运行期间通过Runtime.exec或ProcessBuilder来调用javac来编译代码,这种方式需要我们产生另一个进程去做编译工作,不够优雅而且容易使代码依赖与特定的操作系统;Compiler API通过一套易用的标准的API提供了更加丰富的方式去做动态编译,而且是跨平台的。
Pluggable Annotation Processing API
Java tool和framework 提供商可以定义自己的 annotations ,并且内核支持自定义annotation的插件和执行处理器。
JDBC 4.0
JDBC 4.0 增加了许多特性例如支持XML作为SQL数据类型,更好的集成Binary Large OBjects (BLOBs) 和 Character Large OBjects (CLOBs) 。
Web Services
优先支持编写 XML web service 客户端程序。你可以用过简单的annotaion将你的API发布成.NET交互的web services. Mustang 添加了新的解析和 XML 在 Java object-mapping APIs中, 之前只在Java EE平台实现或者Java Web Services Pack中提供。
轻量级HttpServer
JDK6提供了一个简单的Http Server API,据此我们可以构建自己的嵌入式Http Server,它支持Http和Https协议,提供了HTTP1.1的部分实现,没有被实现的那部分可以通过扩展已有的Http Server API来实现。
Java 7的新特性
switch中可以使用字符串了
String s = "test";
switch (s)
{
case "test" :
System.out.println("test");
case "test1" :
System.out.println("test1");
break ;
default :
System.out.println("break");
break ;
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
泛型实例化类型自动推断
List tempList = new ArrayList<>();- 1
异常catch可以一次处理完而不像以前一层层的捕获
public void newMultiCatch()
{
try {
methodThatThrowsThreeExceptions();
} catch (ExceptionOne | ExceptionTwo | ExceptionThree e) {
// log and deal with all Exceptions
}
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
文件读写 会自动关闭流而不像以前那样需要在finally中显式close
public void newTry()
{
try (FileOutputStream fos = new FileOutputStream("movies.txt");
DataOutputStream dos = new DataOutputStream(fos))
{
dos.writeUTF("Java 7 Block Buster");
} catch (IOException e) {
// log the exception
}
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
数值可以使用下划线分隔
int million = 1_000_000 ;- 1
文件读写功能增强,有更简单的api调用
public void pathInfo()
{
Path path = Paths.get("c:\\Temp\\temp");
System.out.println("Number of Nodes:" + path.getNameCount());
System.out.println("File Name:" + path.getFileName());
System.out.println("File Root:" + path.getRoot());
System.out.println("File Parent:" + path.getParent());
//文件不存在不会抛异常
Files.deleteIfExists(path);
} - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
文件改变的事件通知功能
多核 并行计算的支持加强 fork join 框架
ForkJoinPool pool = new ForkJoinPool(numberOfProcessors);
public class MyBigProblemTask extends RecursiveAction
{
@Override
protected void compute() {
. . . // your problem invocation goes here
}
}
pool.invoke(task); - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
详细情况了解这里。
https://www.oreilly.com/learning/java7-features
Java 8的新特性
一、接口的默认方法和静态方法
Java 8使用两个新概念扩展了接口的含义:默认方法和静态方法。默认方法使得开发者可以在不破坏二进制兼容性的前提下,往现存接口中添加新的方法,即不强制那些实现了该接口的类也同时实现这个新加的方法。默认方法和抽象方法之间的区别在于抽象方法需要实现,而默认方法不需要。接口提供的默认方法会被接口的实现类继承或者覆写。只需要使用 default关键字即可定义默认方法。
interface Formula {
double calculate(int a);
default double sqrt(int a) {
return Math.sqrt(a);
}
}- 1
- 2
- 3
- 4
- 5
- 6
/**
* 定义接口,并包含默认实现方法
*/
public interface CollectionDemoInter {
//增加默认实现
default void addOneObj(Object object){
System.out.println("default add");
}
//删除默认实现
default void delOneObj(Object object){
System.out.println("default del");
}
//更新默认实现
default void updateOneObj(Object object){
System.out.println("default del");
}
//接口定义需要实现方法
String showMsg();
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
Java 8允许接口中定义静态方法。
private interface DefaulableFactory {
// Interfaces now allow static methods
static Defaulable create( Supplier< Defaulable > supplier ) {
return supplier.get();
}
}- 1
- 2
- 3
- 4
- 5
- 6
二、Lambda 表达式
首先看看在老版本的Java中是如何排列字符串的:
List<String> names = Arrays.asList("peter", "anna", "mike", "xenia");
Collections.sort(names, new Comparator<String>() {
@Override
public int compare(String a, String b) {
return b.compareTo(a);
}
});- 1
- 2
- 3
- 4
- 5
- 6
- 7
只需要给静态方法 Collections.sort 传入一个List对象以及一个比较器来按指定顺序排列。通常做法都是创建一个匿名的比较器对象然后将其传递给sort方法。
在Java 8 中你就没必要使用这种传统的匿名对象的方式了,Java 8提供了更简洁的语法,Lambda表达式:
Collections.sort(names, (String a, String b) -> {
return b.compareTo(a);
});- 1
- 2
- 3
看到了吧,代码变得更段且更具有可读性,但是实际上还可以写得更短:
Collections.sort(names, (String a, String b) -> b.compareTo(a));- 1
对于函数体只有一行代码的,你可以去掉大括号{}以及return关键字,但是你还可以写得更短点:
Collections.sort(names, (a, b) -> b.compareTo(a));- 1
函数式接口
Lambda表达式是如何在Java的类型系统中表示的呢?每一个Lambda表达式都对应一个类型,通常是接口类型。而“函数式接口”是指仅仅只包含一个抽象方法的接口,每一个该类型的Lambda表达式都会被匹配到这个抽象方法。因为 默认方法 不算抽象方法,所以你也可以给你的函数式接口添加默认方法。
我们可以将Lambda表达式当作任意只包含一个抽象方法的接口类型,确保你的接口一定达到这个要求,你只需要给你的接口添加 @FunctionalInterface 注解,编译器如果发现你标注了这个注解的接口有多于一个抽象方法的时候会报错的。
@FunctionalInterface
interface Converter<F, T> {
T convert(F from);
}
Converter<String, Integer> converter = (from) -> Integer.valueOf(from);
Integer converted = converter.convert("123");
System.out.println(converted); // 123- 1
- 2
- 3
- 4
- 5
- 6
- 7
方法与构造函数引用
前一节中的代码还可以通过静态方法引用来表示:
Converter<String, Integer> converter = Integer::valueOf;
Integer converted = converter.convert("123");
System.out.println(converted); // 123- 1
- 2
- 3
Java 8 允许你使用 :: 关键字来传递方法或者构造函数引用,上面的代码展示了如何引用一个静态方法,我们也可以引用一个对象的方法:
Converter<String, String> converter = something::startsWith;
String converted = converter.convert("Java");
System.out.println(converted); // "J"- 1
- 2
- 3
接下来看看构造函数是如何使用::关键字来引用的,首先我们定义一个包含多个构造函数的简单类:
class Person {
String firstName;
String lastName;
Person() {}
Person(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
接下来我们指定一个用来创建Person对象的对象工厂接口:
interface PersonFactory<P extends Person> {
P create(String firstName, String lastName);
}- 1
- 2
- 3
这里我们使用构造函数引用来将他们关联起来,而不是实现一个完整的工厂:
PersonFactory<Person> personFactory = Person::new;
Person person = personFactory.create("Peter", "Parker");- 1
- 2
我们只需要使用 Person::new 来获取Person类构造函数的引用,Java编译器会自动根据PersonFactory.create方法的签名来选择合适的构造函数。
Lambda 作用域
在Lambda表达式中访问外层作用域和老版本的匿名对象中的方式很相似。你可以直接访问标记了final的外层局部变量,或者实例的字段以及静态变量。
访问局部变量
我们可以直接在lambda表达式中访问外层的局部变量:
final int num = 1;
Converter<Integer, String> stringConverter =
(from) -> String.valueOf(from + num);
stringConverter.convert(2); // 3- 1
- 2
- 3
- 4
但是和匿名对象不同的是,这里的变量num可以不用声明为final,该代码同样正确:
int num = 1;
Converter<Integer, String> stringConverter =
(from) -> String.valueOf(from + num);
stringConverter.convert(2); // 3- 1
- 2
- 3
- 4
不过这里的num必须不可被后面的代码修改(即隐性的具有final的语义),例如下面的就无法编译:
int num = 1;
Converter<Integer, String> stringConverter =
(from) -> String.valueOf(from + num);
num = 3;- 1
- 2
- 3
- 4
在lambda表达式中试图修改num同样是不允许的。
访问对象字段与静态变量
和本地变量不同的是,lambda内部对于实例的字段以及静态变量是即可读又可写。该行为和匿名对象是一致的:
class Lambda4 {
static int outerStaticNum;
int outerNum;
void testScopes() {
Converter<Integer, String> stringConverter1 = (from) -> {
outerNum = 23;
return String.valueOf(from);
};
Converter<Integer, String> stringConverter2 = (from) -> {
outerStaticNum = 72;
return String.valueOf(from);
};
}
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Lambda表达式不能访问接口的默认方法
还记得第一节中的formula例子么,接口Formula定义了一个默认方法sqrt可以直接被formula的实例包括匿名对象访问到,但是在lambda表达式中这个是不行的。
Lambda表达式中是无法访问到默认方法的,以下代码将无法编译:
Formula formula = (a) -> sqrt( a * 100);
Built-in Functional Interfaces- 1
- 2
三、内建函数式接口
JDK 1.8 API包含了很多内建的函数式接口,在老Java中常用到的比如Comparator或者Runnable接口,这些接口都增加了@FunctionalInterface注解以便能用在lambda上。
Java 8 API同样还提供了很多全新的函数式接口来让工作更加方便,有一些接口是来自Google Guava库里的,即便你对这些很熟悉了,还是有必要看看这些是如何扩展到lambda上使用的。
这些已经默认提供的内建函数式接口主要是:
Predicate接口
Predicate 接口只有一个参数,返回boolean类型。该接口包含多种默认方法来将Predicate组合成其他复杂的逻辑(比如:与,或,非):
@FunctionalInterface
public interface Predicate<T>
{
//Returns a composed predicate that represents a short-circuiting logical AND of this predicate and another.
default Predicate<T> and(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) && other.test(t);
}
//Returns a predicate that tests if two arguments are equal according to Objects.equals(Object, Object).
static <T> Predicate<T> isEqual(Object targetRef) {
return (null == targetRef)
? Objects::isNull
: object -> targetRef.equals(object);
}
//Returns a predicate that represents the logical negation of this predicate.
default Predicate<T> negate() {
return (t) -> !test(t);
}
//Returns a composed predicate that represents a short-circuiting logical OR of this predicate and another.
default Predicate<T> or(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) || other.test(t);
}
//Evaluates this predicate on the given argument.
boolean test(T t)
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
使用方法如下。
Predicate<String> predicate = (s) -> s.length() > 0;
Predicate<String> predicate2 = (s) -> s.length() < 0;
predicate.test("foo"); // true
predicate.negate().test("foo"); // false
predicate.and(predicate2).test("foo"); //false
predicate.or(predicate2).test("foo"); //true
Predicate.isEqual("abc").test("abc"); //true- 1
- 2
- 3
- 4
- 5
- 6
- 7
Function 接口
Function 接口有一个参数并且返回一个结果,并附带了一些可以和其他函数组合的默认方法(compose, andThen):
Function<String, Integer> toInteger = Integer::valueOf;
Function<String, String> backToString = toInteger.andThen(String::valueOf);
backToString.apply("123"); // "123" - 1
- 2
- 3
Supplier 接口
Supplier 接口返回一个任意范型的值,和Function接口不同的是该接口没有任何参数。
Supplier<Person> personSupplier = Person::new;
personSupplier.get(); // new Person - 1
- 2
Consumer 接口
Consumer 接口表示执行在单个参数上的操作。
Consumer<Person> greeter = (p) -> System.out.println("Hello, " + p.firstName);
greeter.accept(new Person("Luke", "Skywalker")); - 1
- 2
Comparator 接口
Comparator 是老Java中的经典接口, Java 8在此之上添加了多种默认方法:
Comparator<Person> comparator = (p1, p2) -> p1.firstName.compareTo(p2.firstName);
Person p1 = new Person("John", "Doe");
Person p2 = new Person("Alice", "Wonderland");
comparator.compare(p1, p2); // > 0
comparator.reversed().compare(p1, p2); // < 0 - 1
- 2
- 3
- 4
- 5
Optional 接口
Optional 不是函数是接口,这是个用来防止NullPointerException异常的辅助类型,这是下一节中将要用到的重要概念,现在先简单的看看这个接口能干什么:
Optional 被定义为一个简单的容器,其值可能是null或者不是null。在Java 8之前一般某个函数应该返回非空对象但是偶尔却可能返回了null,而在Java 8中,不推荐你返回null而是返回Optional。
Optional<String> optional = Optional.of("bam");
optional.isPresent(); // true
optional.get(); // "bam"
optional.orElse("fallback"); // "bam"
optional.ifPresent((s) -> System.out.println(s.charAt(0))); // "b" - 1
- 2
- 3
- 4
- 5
Stream 接口
java.util.Stream 表示能应用在一组元素上一次执行的操作序列。Stream 操作分为中间操作或者最终操作两种,最终操作返回一特定类型的计算结果,而中间操作返回Stream本身,这样你就可以将多个操作依次串起来。Stream 的创建需要指定一个数据源,比如 java.util.Collection的子类,List或者Set, Map不支持。Stream的操作可以串行执行或者并行执行。
首先看看Stream是怎么用,首先创建实例代码的用到的数据List:
List<String> stringCollection = new ArrayList<>();
stringCollection.add("ddd2");
stringCollection.add("aaa2");
stringCollection.add("bbb1");
stringCollection.add("aaa1");
stringCollection.add("bbb3");
stringCollection.add("ccc");
stringCollection.add("bbb2");
stringCollection.add("ddd1"); - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
Java 8扩展了集合类,可以通过 Collection.stream() 或者 Collection.parallelStream() 来创建一个Stream。下面几节将详细解释常用的Stream操作:
Filter过滤
过滤通过一个predicate接口来过滤并只保留符合条件的元素,该操作属于中间操作,所以我们可以在过滤后的结果来应用其他Stream操作(比如forEach)。forEach需要一个函数来对过滤后的元素依次执行。forEach是一个最终操作,所以我们不能在forEach之后来执行其他Stream操作。
stringCollection
.stream()
.filter((s) -> s.startsWith("a"))
.forEach(System.out::println);
// "aaa2", "aaa1" - 1
- 2
- 3
- 4
- 5
Sort 排序
排序是一个中间操作,返回的是排序好后的Stream。如果你不指定一个自定义的Comparator则会使用默认排序。
stringCollection
.stream()
.sorted()
.filter((s) -> s.startsWith("a"))
.forEach(System.out::println);
// "aaa1", "aaa2" - 1
- 2
- 3
- 4
- 5
- 6
需要注意的是,排序只创建了一个排列好后的Stream,而不会影响原有的数据源,排序之后原数据stringCollection是不会被修改的。
Map 映射
中间操作map会将元素根据指定的Function接口来依次将元素转成另外的对象,下面的示例展示了将字符串转换为大写字符串。你也可以通过map来将对象转换成其他类型,map返回的Stream类型是根据你map传递进去的函数的返回值决定的。
stringCollection
.stream()
.map(String::toUpperCase)
.sorted((a, b) -> b.compareTo(a))
.forEach(System.out::println);
// "DDD2", "DDD1", "CCC", "BBB3", "BBB2", "AAA2", "AAA1" - 1
- 2
- 3
- 4
- 5
- 6
Match 匹配
Stream提供了多种匹配操作,允许检测指定的Predicate是否匹配整个Stream。所有的匹配操作都是最终操作,并返回一个boolean类型的值。
boolean anyStartsWithA =
stringCollection
.stream()
.anyMatch((s) -> s.startsWith("a"));
System.out.println(anyStartsWithA); // true
boolean allStartsWithA =
stringCollection
.stream()
.allMatch((s) -> s.startsWith("a"));
System.out.println(allStartsWithA); // false
boolean noneStartsWithZ =
stringCollection
.stream()
.noneMatch((s) -> s.startsWith("z"));
System.out.println(noneStartsWithZ); // true - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
Count 计数
计数是一个最终操作,返回Stream中元素的个数,返回值类型是long。
long startsWithB =
stringCollection
.stream()
.filter((s) -> s.startsWith("b"))
.count();
System.out.println(startsWithB); // 3 - 1
- 2
- 3
- 4
- 5
- 6
Reduce 规约
这是一个最终操作,允许通过指定的函数来讲stream中的多个元素规约为一个元素,规越后的结果是通过Optional接口表示的:
Optional<String> reduced =
stringCollection
.stream()
.sorted()
.reduce((s1, s2) -> s1 + "#" + s2);
reduced.ifPresent(System.out::println);
// "aaa1#aaa2#bbb1#bbb2#bbb3#ccc#ddd1#ddd2" - 1
- 2
- 3
- 4
- 5
- 6
- 7
并行Streams
前面提到过Stream有串行和并行两种,串行Stream上的操作是在一个线程中依次完成,而并行Stream则是在多个线程上同时执行。
下面的例子展示了是如何通过并行Stream来提升性能:
首先我们创建一个没有重复元素的大表:
int max = 1000000;
List<String> values = new ArrayList<>(max);
for (int i = 0; i < max; i++) {
UUID uuid = UUID.randomUUID();
values.add(uuid.toString());
}- 1
- 2
- 3
- 4
- 5
- 6
然后我们计算一下排序这个Stream要耗时多久,
串行排序:
long t0 = System.nanoTime();
long count = values.stream().sorted().count();
System.out.println(count);
long t1 = System.nanoTime();
long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);
System.out.println(String.format("sequential sort took: %d ms", millis));
// 串行耗时: 899 ms- 1
- 2
- 3
- 4
- 5
- 6
- 7
并行排序:
long t0 = System.nanoTime();
long count = values.parallelStream().sorted().count();
System.out.println(count);
long t1 = System.nanoTime();
long millis = TimeUnit.NANOSECONDS.toMillis(t1 - t0);
System.out.println(String.format("parallel sort took: %d ms", millis));
// 并行排序耗时: 472 ms- 1
- 2
- 3
- 4
- 5
- 6
- 7
上面两个代码几乎是一样的,但是并行版的快了50%之多,唯一需要做的改动就是将stream()改为parallelStream()。
四、Map
前面提到过,Map类型不支持stream,不过Map提供了一些新的有用的方法来处理一些日常任务。
Map<Integer, String> map = new HashMap<>();
for (int i = 0; i < 10; i++) {
map.putIfAbsent(i, "val" + i);
}
map.forEach((id, val) -> System.out.println(val));- 1
- 2
- 3
- 4
- 5
以上代码很容易理解, putIfAbsent 不需要我们做额外的存在性检查,而forEach则接收一个Consumer接口来对map里的每一个键值对进行操作。
五、Date API
Java 8 在包java.time下包含了一组全新的时间日期API。新的日期API和开源的Joda-Time库差不多,但又不完全一样,下面的例子展示了这组新API里最重要的一些部分:
Clock 时钟
Clock类提供了访问当前日期和时间的方法,Clock是时区敏感的,可以用来取代 System.currentTimeMillis() 来获取当前的微秒数。某一个特定的时间点也可以使用Instant类来表示,Instant类也可以用来创建老的java.util.Date对象。
Timezones 时区
在新API中时区使用ZoneId来表示。时区可以很方便的使用静态方法of来获取到。 时区定义了到UTS时间的时间差,在Instant时间点对象到本地日期对象之间转换的时候是极其重要的。
LocalTime 本地时间
LocalTime 定义了一个没有时区信息的时间,例如 晚上10点,或者 17:30:15。
LocalDate 本地日期
LocalDate 表示了一个确切的日期,比如 2014-03-11。该对象值是不可变的,用起来和LocalTime基本一致。
LocalDateTime 本地日期时间
LocalDateTime 同时表示了时间和日期,相当于前两节内容合并到一个对象上了。LocalDateTime和LocalTime还有LocalDate一样,都是不可变的。LocalDateTime提供了一些能访问具体字段的方法。
六、Annotation 注解
在Java 8中支持多重注解了。Java 8 引入了重复注解机制,这样相同的注解可以在同一地方使用多次。重复注解机制本身必须用 @Repeatable 注解。
七、HotSpot虚拟机移除永久代
其实,移除永久代的工作从JDK1.7就开始了。JDK1.7中,存储在永久代的部分数据就已经转移到了Java Heap或者是 Native Heap。但永久代仍存在于JDK1.7中,并没完全移除,譬如符号引用(Symbols)转移到了native heap;字面量(interned strings)转移到了java heap;类的静态变量(class statics)转移到了java heap。
JDK8 HotSpot JVM 使用本地内存来存储类元数据信息并称之为:元空间(Metaspace)。
元空间的本质和永久代类似,都是对JVM规范中方法区的实现。不过元空间与永久代之间最大的区别在于:元空间并不在虚拟机中,而是使用本地内存。因此,默认情况下,元空间的大小仅受本地内存限制,但可以通过以下参数来指定元空间的大小:
-XX:MetaspaceSize,初始空间大小,达到该值就会触发垃圾收集进行类型卸载,同时GC会对该值进行调整:如果释放了大量的空间,就适当降低该值;如果释放了很少的空间,那么在不超过MaxMetaspaceSize时,适当提高该值。
-XX:MaxMetaspaceSize,最大空间,默认是没有限制的。
除了上面两个指定大小的选项以外,还有两个与 GC 相关的属性:
-XX:MinMetaspaceFreeRatio,在GC之后,最小的Metaspace剩余空间容量的百分比,减少为分配空间所导致的垃圾收集
-XX:MaxMetaspaceFreeRatio,在GC之后,最大的Metaspace剩余空间容量的百分比,减少为释放空间所导致的垃圾收集
关于Java 8新特性还可以参考这里。
http://www.cnblogs.com/seaspring/p/6187767.html
后记
本篇博客主要介绍了Java的历史,Java SE,Java Card,Java ME,Java EE,Java虚拟机。希望能对Java有一个系统的认识,避免出现概念上的认知偏差,方便以后进一步深入学习。
参考文献
BruceEckel. Java编程思想:第4版[M]. 机械工业出版社, 2007.
周志明. 深入理解Java虚拟机:JVM高级特性与最佳实践(第2版)[M]. 机械工业出版社, 2013.
《JavaCard 应用程序开发三部曲》
詹建飞. Java ME核心技术与最佳实践[M]. 电子工业出版社, 2007.
郝玉龙, 周旋. Java EE核心技术与应用[M]. 电子工业出版社, 2013.
李刚. 经典Java EE企业应用实战:基于WebLogi/JBoss的JSF+EJB+JPA整合开发[M]. 电子工业出版社, 2010.

