
- 1蓝桥杯必刷题_在一座长度为l的独木桥,独木桥上有l个坐标,分别为1,2,...,l。现在桥上有n个人,每
- 2【postgresql 基础入门】事物transaction的开启,提交,回滚命令,自动提交设置_pg数据库自动提交
- 3微信小程序实战:无痛集成腾讯地图服务
- 4活动报名|大模型的推理能力究竟由什么决定
- 5python文本数据分析作业分享案例_python文本分析案例
- 6Suggestion: add 'tools:replace="android:name"' to element at AndroidManifest.xml
- 7ubuntu 下 opencv的安装以及配置(亲测有效)_ubuntu安装opencv
- 89、技巧之二:Firefox文件上传和自动下载 【Selenium+Python3网页自动化总结】_selenium 火狐
- 9GPT的发展历程_gpt的历史
- 10【AIGC调研系列】通过流量收集工具和AIGC生成自动化测试脚本_aigc 自动化测试
0基础小白十分钟入门人工智能强化学习(附有实战源码)_强化学习 小白
赞
踩
强化学习概述
1.1 强化学习的学习任务目标
强化学习(Reinforcement Learning, RL),用官话讲,是机器学习的范式和方法论之一,用于描述和解决智能体(agent)在与环境的交互过程中通过学习策略以达成回报最大化或实现特定目标的问题。
在我个人的理解,就是我们使用特定的训练方法去训练一个‘智慧生物’,让它能去实现一系列的功能。通过奖励(有好有坏)反馈给这个‘智慧生物’,让他向着奖励越来越高的方向去靠拢,从而达到我们所期望赋予他的能力。比如拿到高分的超级玛丽亚,让他不踩到怪物又能吃到蘑菇。比如飞机大战游戏中躲避敌人子弹又消灭敌人的飞机,甚至自动驾驶(可以在虚拟环境中训练)也有强化学习的应用。
1.2 强化学习的不同分类依据和具体分类方法
强化学习有许多纬度的分类标准,下面按照比较常见的分类方式进行分类。
1.2.1
根据agent是否理解其所处的环境,即是否知道所依赖的马尔科夫决策过程的状态转移概率及对应回报,可以将强化学习方法分为:无模型的强化学习(Model-Free RL)和基于模型的强化学习(Model-Based RL)。
简单来说,Model-Free RL的agent 没有跟环境进行交互,环境的所有信息都有了,经典的Sarsa、Q-Learning算法就是Model-Free的。Model-Based RL的agent没有环境的信息,需要跟环境进行交互,采集到很多的轨迹数据,agent 从轨迹中获取信息来改进策略,从而获得更多的奖励。Dyna-Q算法就是Model-Based RL的算法。
1.2.2
根据agent选取动作的策略不同,可以将强化学习方法分为:基于概率的强化学习(Policy-Based RL)和基于价值的强化学习(Value-Based RL)。
举个例子,在经典的AC算法模型中,由Actor神经网络和Critic网络组成,Actor用于选择一个动作,而Critic通过对Actor选择的动作进行‘评分’,用于评价Actor这个网络的好坏。在这里Actor是Policy-Based RL的,因为他是基于动作的概率去选择接下来下一个动作。而Critic是Value-Based RL的。
1.2.3
根据策略或价值函数的更新频率,可以将强化学习方法分为:回合更新强化学习(Monte-Carlo Update RL, MC)和单步更新强化学习(Temporal-Difference Update RL, TD)。
简单点说,就是TD可以在最终结果出来之前进行更新,这种更新又叫做在线学习,而MC必须等最终状态到达才行,叫做离线学习。
1.2.4
根据agent是否直接与环境互动进行学习(更新策略或价值函数),可以将强化学习方法分为:在线学习(On-Policy RL)和离线学习(Off-Policy RL)。
他们的分类标准就是目前agent所学习的样本是不是用当前的策略采集到的。举个例子,如果是Off-Policy RL,当前的Actor网络能使用老的Actor网络所产生的动作和奖励序列进行更新,文章的主角PPO算法中便使用到了重要性采样的概念,能用其他策略产生样本去更新当前的策略,提高非常多的效率。
1.3 强化学习代表性开源实验环境
OpenAI Gym and Universe
最出名的莫过于Gym和Universe了。OpenAI Gym用于评估和比较强化学习算法的好坏。它的接口支持在任何框架下的算法,像TensorFlow, Theano, Keras这些都可以。
入门实战项目
项目介绍:使用的是PPO算法和小车上山的环境进行试验.
在这个环境中,小车的目的是登上右侧的山坡,训练的目的就是让小车能尽可能在少的时间通过左右移动发力登上右侧山顶.
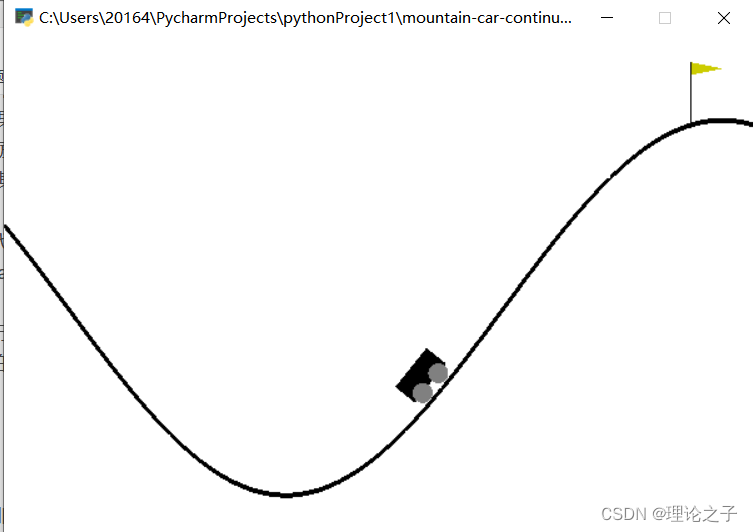
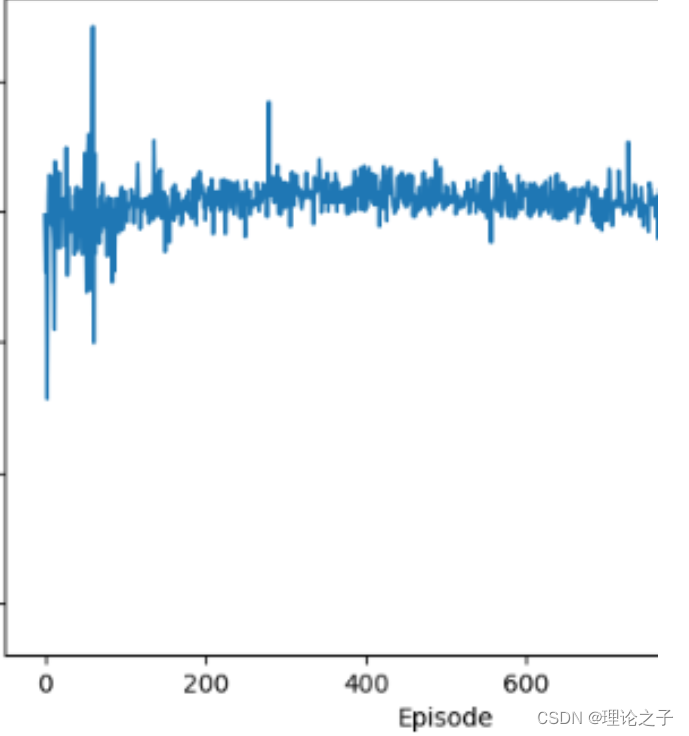
在该环境下训练效果如下,在接近600轮次时已经收敛了.
源码及环境搭配,使用方法为付费内容:https://mbd.pub/o/bread/Y56Ym5xp


