
- 1SpringBoot3.0 集成 Redis2.6_springboot3.0 redis
- 2决胜B端(二)设计篇-从业务诊断到形成方案-调研_决胜b端2
- 3github上如何添加Demo动画_github.io在个人主页添加视频
- 4JAVA安全之Log4j-Jndi注入原理以及利用方式
- 5DataGridView取消默认选中行_datagridview取消选中状态
- 6MySQL的安装与环境变量配置_mysql中如何设置环境变量
- 7学校作业5_3字符串_统计英文文件中的单词数(头哥作业[Python])_统计英文文件中的单词数python头歌
- 8微信小程序picker多列选择器:四级联动
- 9ant design pro v5 - 03 动态菜单 动态路由(配置路由 动态登录路由 登录菜单)_ant design pro 动态菜单
- 10垃圾分类数据集-8w张图片245个类附赠tensorflow代码_垃圾分类数据集(垃圾图片数据集)
知识抽取与知识挖掘
赞
踩
前言
知识抽取是构建大规模知识图谱的重要环节,而知识挖掘是在已有知识图谱的基础上发现隐藏的知识。
1.非结构化数据的知识抽取
大量的数据以非结构化数据的形式存在,如新闻报道、文学,读书等。我们将从实体抽取、关系抽取和事件抽取进行介绍。
1.2 实体抽取
实体抽取又称命名实体识别,其目的是从文本中抽取实体信息元素,包括人名、时间、地点、数值等。实体抽取是解决很多自然语言处理问题的基础。想要从文本中进行实体抽取,首先需要从文本中识别和定位实体,然后再将识别的实体分类到预定义的类别中去。实体抽取问题的研究开展得比较早,该领域积累了大量的方法。总体上,可以将已有的方法分为基于规则的方法、基于统计模型的方法和基于深度学习的方法。
1.2.1 基于规则的方法
早期的命名实体识别方法主要采用人工编制规则的方法进行实体的抽取。这类方法首先需要构建大量的实体抽取规则。一般由相关领域的知识专家进行手工构建,然后将这些规则与文本字符串进行匹配,识别命名实体。
这种实体抽取方法在小数据集上可以达到很高的准确率和召回率*(召回率(Recall) = 系统检索到的相关文件 / 系统所有相关的文件总数)* 但是随着数据集的增大,规则集的构建周期边长,并且移植性较差。
1.2.2 基于统计模型的方法
基于统计模型的方法利用完全标注或标注的语料进行模型训练,主要采用的模型包括隐马尔可夫模型、条件马尔可夫模型、最大熵模型以及条件随机场模型。
这类方法将命名识别作为序列标注问题处理。与普通的分类问题相比,序列标注问题中当前标签的预测不仅与当前的输入特征相关,还与之前的预测标签相关,即预测序列是有强相互依赖关系的。
基于统计模型构建命名识别方法主要涉及训练语料标注、特征定义和模型训练三个方面 :
-
训练语料标注:为了构建统计模型的训练语料。一般采用Inside-Outside-Beginning(IOB)或Inside-Outside(IO)标注体系对文本进行人工标注。在IOB标注体系中,文本中的每个词被标记为实体名的启始词(B)、实体名称的后续词(I)或实体名称的外部词(D)。而在IO标注体系中,文本的词被标记为实体名称内部词(I)或实体名称外部词(D)。
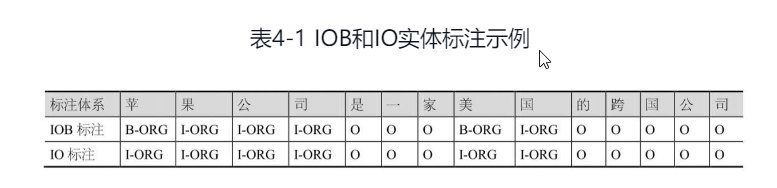
-
特征定义。在训练模型之前,统计模型需要计算每个词的一组特征作为模型的输入,这些特征具体包含单词级别体征、词典特征和文档级特征等。单词级别特征包含是否首字母大写、是否以句点结尾、是否包含数字、词性等。词典级别特征依赖外部词典定义,例如预定义的词表、地点列表等。文档级特征基于整个语料文档集计算,如文档集中的词频、同现词等。
-
模型训练:隐马尔可夫(HMM)和条件随机场(CRF)是两个常用于标注问题的统计学习模型,也被广泛应用于实体抽取问题。
1.2.3 基于深度学习的方法
随着深度学习在自然语言处理的广泛应用,深度神经网络也被广泛的成功用于命名实体识别问题,并取得很好地效果。与传统统计模型相比,基于深度学习的方法直接以文本中词的向量为输入,通过神经网络实现端到端的命名实体识别,不再依赖人工定义的特征。目前,用于命名实体识别的神经网络主要有卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent NeuralNetwork,RNN)以及引入注意力机制(Attention Mechanism)的神经网络。
1.3 关系抽取
关系抽取是从文本中抽取两个或者多个实体之间的语义关系。关系抽取与实体抽取密切相关,一般在识别出文本中的实体后,在抽取实体之间可能存在的关系。目前,关系抽取得方法可以分为基于模板的关系抽取方法,基于监督学习的关系抽取方法和基于弱监督学习的抽取方法。
1.3.1 基于模板的关系抽取方法
在早期的实体关系方法大多数基于模板匹配实现。该类方法基于语言学知识,结构语料的特点,由领域专家手工编写模板,从文本中匹配具有特定关系的实体。
在小规模、限定领域的实体关系抽取问题上,基于模板的方法能够取得较好的效果。优点是模板构建简单,可以比较快地在小规模数据集上实现关系的抽取系统。但是,当数据规模较大是,手工构建某班需要消耗专家大量的时间,此外,系统的可移植性差。
1.3.2 基于监督学习的抽取方法
基于监督学习的抽取方法将关系抽取转化为分类问题。在大量标注数据的基础上,训练有监督学习模型进行关系抽取。一般的步骤包括:
- 预定义关系的类型
- 人工标注数据
- 设计关系识别所需的特征,一般根据实体所在句子的上下文计算获得
- 选择分类模型,基于标注数据训练模型
- 对训练的模型进行评估
传统的基于监督学习的关系抽取是一种依赖特征工程的方法,近年来有多个基于深度学习的关系抽取模型被研究者们提出。目前,已有的基于深度学习的关系抽取方法主要包括流水线方法和联合抽取方法两大类。流水线方法将识别实体和关系抽取作为两个分离的过程进行处理,两者不会相互影响;关系抽取在实体抽取结果的基础上进行,因此关系抽取的结果也依赖于实体抽取的结果。联合抽取方法将实体抽取和关系抽取相结合,在统一的模型中共同优化;联合抽取方法可以避免流水线方法存在的错误积累问题。
1.3.3 基于弱监督学习的关系抽取方法
基于监督学习的关系抽取方法需要大量的训练语料,特别是基于深度学习的方法,模型的优化更依赖大量的训练数据。当训练语料不足时,弱监督学习方法可以只利用少量的标注数据进行模型学习。基于弱监督学习的关系抽取方法主要包括远程监督方法和Bootstrapping方法。
(1)远程监督方法。远程监督方法通过将知识图谱与非结构化文本对齐的方式自动构建大量的训练数据,减少模型对人工标注数据的依赖,增强模型的跨领域适应能力。远程监督方法的基本假设是如果两个实体在知识图谱中存在某种关系,则包含两个实体的句子均表达了这种关系。
因此,远程监督关系抽取方法的一般步骤为:
●从知识图谱中抽取存在目标关系的实体对;
●从非结构化文本中抽取含有实体对的句子作为训练样例;
●训练监督学习模型进行关系抽取。
远程监督关系抽取方法可以利用丰富的知识图谱信息获取训练数据,有效地减少了人工标注的工作量。但是,基于远程监督的假设,大量噪声会被引入到训练数据中,从而引发语义漂移的现象。
(2)Bootstrapping方法。Bootstrapping方法利用少量的实例作为初始种子集合,然后在种子集合上学习获得关系抽取的模板,再利用模板抽取更多的实例,加入种子集合中。通过不断地迭代,Bootstrapping方法可以从文本中抽取关系的大量实例。
Bootstrapping方法的优点是关系抽取系统构建成本低,适合大规模的关系抽取任务,并且具备发现新关系的能力。但是,Bootstrapping方法也存在不足之处,包括对初始种子较为敏感、存在语义漂移问题、结果准确率较低等。
1.4 事件抽取
事件是指发生的事情,通常具有时间、地点、参与者等属性。事件的发生可能是因为一个动作的产生或者系统状态的改变。事件抽取是指从自然语言文本中抽取出用户感兴趣的事件信息,并以结构化的形式呈现出来,例如事件发生的时间、地点、发生原因、参与者等
一般地,事件抽取任务包含的子任务有:
●识别事件触发词及事件类型;
●抽取事件元素的同时判断其角色;
●抽出描述事件的词组或句子;
●事件属性标注;
●事件共指消解。
已有的事件抽取方法可以分为流水线方法和联合抽取方法两大类。
1).事件抽取的流水线方法流水线方法将事件抽取任务分解为一系列基于分类的子任务,包括事件识别、元素抽取、属性分类和可报告性判别;每一个子任务由一个机器学习分类器负责实施。一个基本的事件抽取流水线需要的分类器包括:
(1)事件触发词分类器。判断词汇是否为事件触发词,并基于触发词信息对事件类别进行分类。
(2)元素分类器。判断词组是否为事件的元素。
(3)元素角色分类器。判定事件元素的角色类别。
(4)属性分类器。判定事件的属性。
(5)可报告性分类器。判定是否存在值得报告的事件实例。
2).事件的联合抽取方法事件抽取的流水线方法在每个子任务阶段都有可能存在误差,这种误差会从前面的环节逐步传播到后面的环节,从而导致误差不断累积,使得事件抽取的性能急剧衰减。为了解决这一问题,一些研究工作提出了事件的联合抽取方法。在联合抽取方法中,事件的所有相关信息会通过一个模型同时抽取出来。一般地,联合事件抽取方法可以采用联合推断或联合建模的方法


