
- 1SpringBoot集成自然语言处理hanlp工具包_springboot 集成hanlp
- 2【GlobalMapper精品教程】022:根据一个字段属性值批量计算另一个字段属性值(地类名称求地类编码)_arcgis 计算 不同编码
- 3【AcWing】蓝桥杯集训每日一题Day14|Flood Fill|洪水灌溉算法|DFS|并查集|687.扫雷(C++)
- 4【Hadoop】Hadoop车辆数据存储_基于hadoop的公共自行车数据分布式存储和计算
- 5Django高级扩展之中间件
- 6头歌 实验六 java输入输出_本关任务:从文件读取一篇英语文章,然后统计26个英文字母出现的次数。
- 7【无标题】嘻嘻嘻嘻嘻嘻嘻_max_energy_0 = torch.max(energy, -1, keepdim=true)
- 8机器翻译评测----BLEU算法_bleu机器翻译
- 9【python】flask模板渲染引擎Jinja2,流程控制语句与过滤器的用法剖析与实战应用
- 10测试人员前期参与设计方案时需要注意什么?
进行数据离散化的原因_数据处理 | pandas入门专题——离散化与one-hot
赞
踩
今天是pandas数据处理专题第7篇文章,可以点击上方专辑查看往期文章。
在上一篇文章当中我们介绍了对dataframe进行排序以及计算排名的一些方法,在今天的文章当中我们来了解一下dataframe两个非常重要的功能——离散化和one-hot。
离散化
离散对应的反面是连续,离散化也就是将连续性的数值映射到一个离散的值。举个很简单的例子,比如说现在有一个特征是用户的收入,我们都知道贫富差距是非常巨大的,一个马云的收入顶的上成千上万人收入之和。而最穷的人收入非常少,甚至每天不到一美元。
我们来设想一下,假设我们将收入这个值作为特征放入模型,会发生什么。如果是线性模型,很显然模型会被这个特征值给带跑偏。我们来看下线性回归的公式:,这里的W表示的样本矩阵X的系数向量。假设某一维是收入,那么它对应的系数显然必须非常非常小,因为样本当中有马云这种顶级大佬的收入存在,也就是说为了拟合这样的极端数据,模型被带跑偏了。
这种情况非常多,因为现实生活当中很多数据的分布是非常不均匀的。往往不是正态分布而是二八分布,甚至更加两极分化。那针对这种情况该怎么处理呢?
比较简单也比较常用的一种方法就是将它离散化,将原本连续的值映射成离散的变量。比如说收入,我们不再直接用收入这个值来作为特征,而是将它分成几个桶,比如分为低收入群体,中等收入群体,高收入群体。这样对模型训练来说,就不会被带偏了,但是缺点是损失了部分信息。比如说马云和东哥都是高收入群体,但是两人的挣钱能力其实还是相差蛮远的。如果采用这种方式就体现不出来了,所以离散化的设计也不是拍脑门的,也要根据实际情况具体分析。
那么假设我们希望在dataframe当中做这样离散化的操作,应该怎么办呢?
其实非常简单,pandas的开发人员早就想到了这个需求,有现成且成熟的api可以使用。我们来看个例子,首先我们创建一批数据,表示一批用户的年收入:
income = [2000, 10000, 150000, 8000, 20000, 30000, 50000, 1000000, 20000000, 300000000]然后我们再人为的设置分桶用来对收入进行划分:
bins = [0, 30000, 100000, 10000000, 1000000000]之后我们只需要调用pandas当中的cut方法,将income和bins数组都传入就可以了:
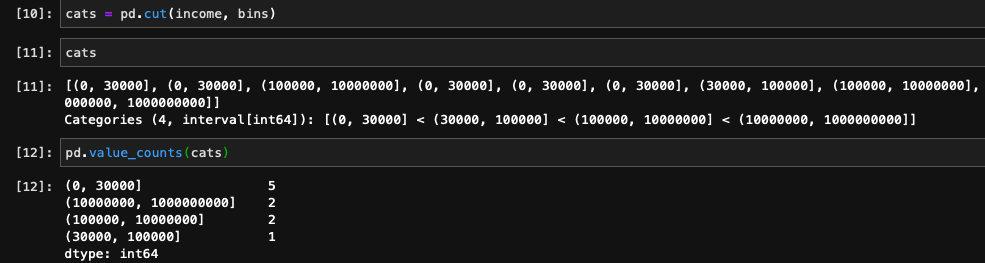
pandas返回的结果是Categorical的对象,表示一种类别。像是(0, 30000]既是这个分桶的值的范围,也表示这个分桶的名字。我们也可以自己传入我们定义的分桶名称来替换这个范围:
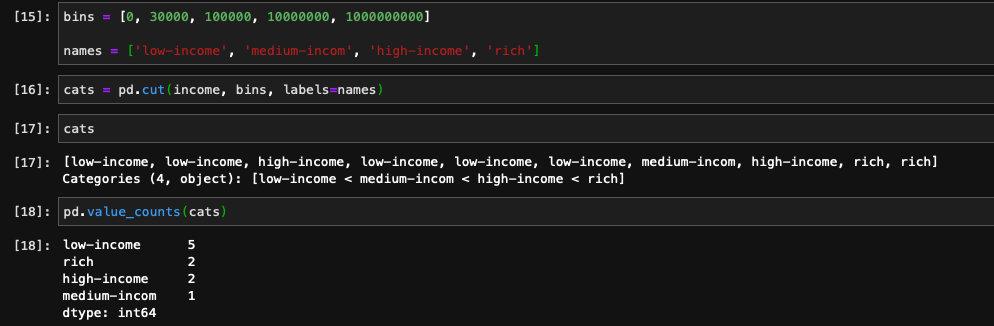
这里要注意我们传入的labels的数量要比bins也就是划分范围少一个,因为划分的区间是半闭半开的,区间的数量是bins-1,所以我们指定的labels数量也应该是bins-1。在默认的划分方法当中,采用的是左开右闭区间,和我们常用的左闭右开区间不同,我们可以通过right=False这个参数将它设置成左闭右开区间。
在使用cut的过程当中,如果我们希望按照值的范围来进行均等划分的话,我们也可以传入我们希望划分的分桶数量代替bins,这样pandas会根据这一列值的范围按照指定的数量进行均分进行划分:
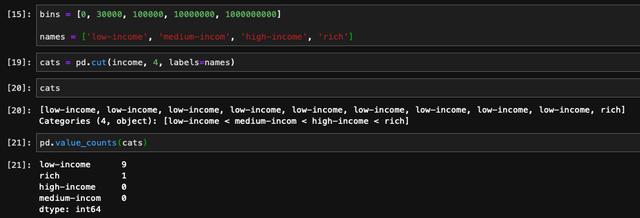
如果是采用均等划分,想要对划分的精度进行限定,可以通过precision参数进行限定。比如说我们希望精度保留两位小数,那么传入precision=2即可。
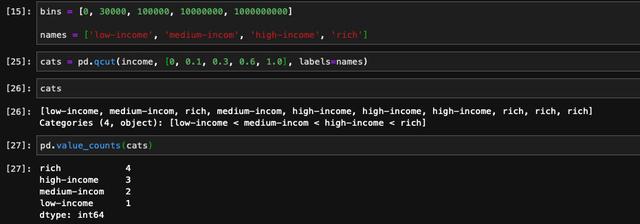
离散化的方法除了cut之外,还有一个叫做qcut,和cut不同之处在于qcut是根据分位数进行划分的。比如我们希望忽视具体的数值,按照数据的数量进行等分,就需要用到qcut了。
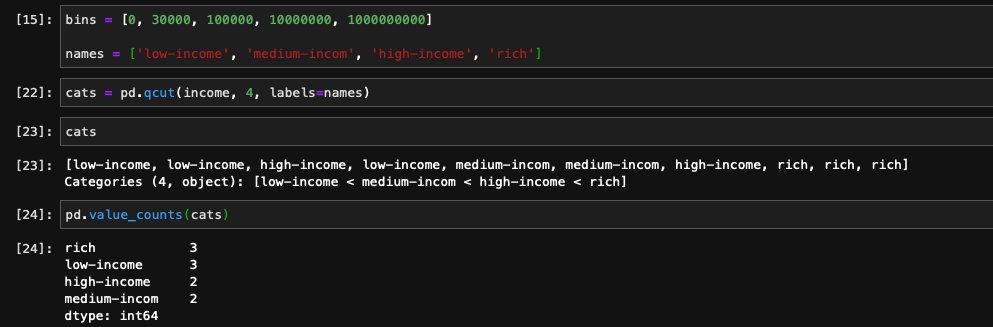
除了传入想要得到的划分数量之外,我们也可以指定想要划分的分位数,是0到1之间的小数,包含端点:
one-hot
one-hot也是机器学习当中非常非常常用的一种数据处理方式,one-hot这个词乍看不是很明白,也有地方翻译成独热码,也很费解。其实它的含义很简单,就是将一系列非数值型的值进行类别分桶。
我们举个很简单的例子,假设我们把男生分为三种:高富帅、矮矬穷和理工男,我们现在有4个男生:[高富帅、矮矬穷、理工男、高富帅],这显然是一个特征,但问题是大部分模型是不接受字符串类型的特征的,我们必须将它转化成数值才行。问题就在转化这里,我们很难做这个映射。
有人会说我们可以让高富帅、矮矬穷这些标签对应不同的数值,做一个映射不就可以了吗?比如说矮矬穷等于1,高富帅等于2,这样一映射不就变成数值了吗?很可惜不行,原因也很简单,因为我们单纯地把它们映射成数值之后,它们就从一个抽象的概念变成数了。抽象的概念之间是没有大小关系也没有倍数关系的,但是数值有。比如说高富帅等于2,矮矬穷等于1,那在模型当中是否一个高富帅等于两个矮矬穷?是否高富帅大于矮矬穷?
这些额外的信息对模型是非常致命的,我们不希望模型得到这些信息。最好的方法是我们生成一个列表,列表当中有三列分别是高富帅、矮矬穷和理工男。你是高富帅就高富帅那一列为1,其他列都为0,同理你是矮矬穷就矮矬穷那一列为1,其他列为0。在这个列表当中每一行只有一列为1,其他都为0,相当于只有一列热,其他列都是冷的,one-hot就是这么来的。
我们噼里啪啦说了很多,但实际上one-hot的实现非常简单,只有一行:
pd.get_dummies(dataframe)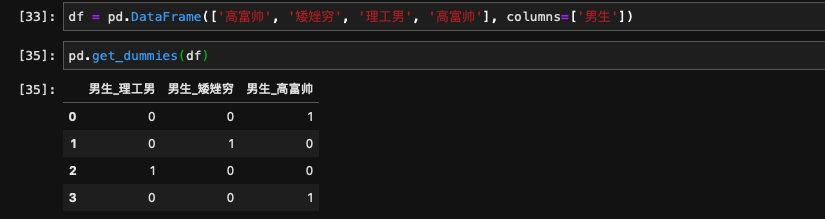
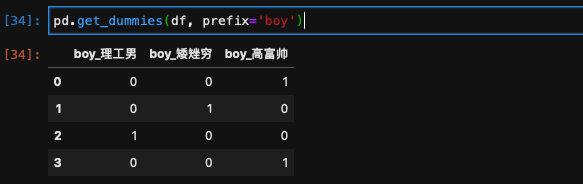
默认得到的列表的名称会加上这一列的列名作为前缀,我们也可以自己通过prefix传入我们想要的前缀:
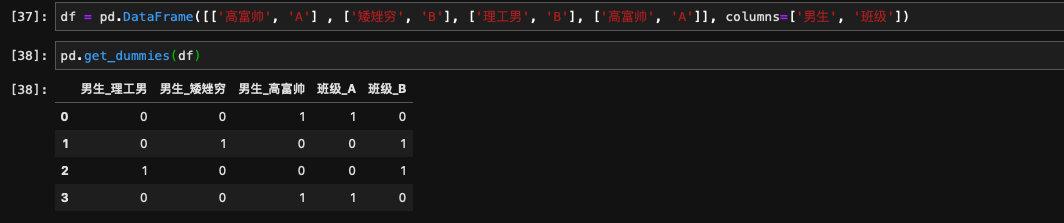
多列一起进行one-hot也没有关系:
总结
离散化和one-hot都是非常常用的功能, 一般来说这两个功能通常会连在一起使用,先将某一个值进行离散化,然后再将离散化的结果进行one-hot,从而适应模型。因此本文的内容非常实用,不要错过哦。
今天的文章到这里就结束了,如果喜欢本文的话,请来一波素质三连,给我一点支持吧(关注、转发、点赞)。
- END -
本文始发于公众号: TechFlow

