
- 1k8s中部署nginx-ingress实现外部访问k8s集群内部服务_ingress跨ns访问后端service
- 2在Android核的java核心库libcore中打印log,和单独编译_单独编译libcore
- 3uni-app:实现滚动条效果_uniapp滚动条
- 4理解梅尔频谱(mel spectrogram)_melspectrogram
- 5SEAndroid学习
- 680psi等于多少kpa_PSI和KPa如何转换
- 7vue.config.js 的完整配置(超详细)_vueconfig.js配置
- 8【深度学习】生成对抗网络(GANs)详解!
- 9全球智库动态 | 未来极具潜力的50项新兴技术
- 10如何在手机和电脑之间共享文件以及共享模拟器网络给电脑_open snapdrop on other devices to send files
CVPR2022 Oral | CosFace、ArcFace的大统一升级,AdaFace解决低质量图像人脸识
赞
踩
https://mp.weixin.qq.com/s/nS3dTHUFhTEmdR4I2htqnw

一直以来,低质量图像的人脸识别都具有挑战性,因为人脸属性是模糊和退化的。
margin-based loss functions的进步提高了嵌入空间中人脸的可辨别性。此外,以往的研究研究了适应性损失的影响,使错误分类(Head)的样本更加重要。在这项工作中,在损失函数中引入了另一个因素,即
图像质量。作者认为,强调错误分类样本的策略应根据其图像质量进行调整。具体来说,简单或困难样本的相对重要性应该基于样本的图像质量来给定。据此作者提出了一种新的损失函数来通过图像质量强调不同的困难样本的重要性。本文的方法通过用
feature norms来近似图像质量,这里是以自适应边缘函数的形式来实现这一点。大量的实验表明,
AdaFace在4个数据集(IJB-B、IJB-C、IJB-S和IJBTinyFace)上提高了现有的(SoTA)的人脸识别性能。
说在前面
对于人脸识别,大家可能觉得已经内卷的差不多了,没什么可以挖掘的了,但是实际上我们还是在有意无意的在回避一些实际落地的问题,AdaFace则是一个直面落地问题的经典工作,作为CVPR2022的Oral工作当之无愧。
其直面低质量人脸图像的识别问题,同时作者通过使用特征范数来近似图像质量提出一个概括性的损失函数,可以随意在ArcFace和CosFace之间随意游走,在提升低质量图像的识别精度的同时,也没有损失高质量图像的精度,可以说是一个很不错和经典的工作。
希望这里的解读可以帮助到大家!!!
这里文中给出最富有总结性的一个表格:

1简介
图像质量是一个属性的组合,表明一个图像如何如实地捕获原始场景。影响图像质量的因素包括亮度、对比度、锐度、噪声、色彩一致性、分辨率、色调再现等。
这里人脸图像是本文的重点,可以在各种灯光、姿势和面部表情的设置下捕捉到的图像,有时也可以在极端的视觉变化下捕捉,如对象的年龄或妆容。这些参数的设置使得学习过的人脸识别模型很难完成识别任务。尽管如此,这项任务还是可以完成的,因为人类或模型通常可以在这些困难的环境下识别人脸。

图1
然而,当人脸图像质量较低时,根据质量程度的不同,识别任务变得不可行。图1显示了高质量和低质量的人脸图像的例子。不可能识别出图1最后1列中的对象。
像图1最下面一行这样的低质量图像正越来越成为人脸识别数据集的重要组成部分,因为它们会在监控视频和无人机镜头中遇到。鉴于SoTA FR方法能够在相对较高质量的数据集,如LFW或CFP-FP中获得超过98%的验证精度,最近的FR挑战已经转向了较低质量的数据集,如IJB-B、IJB-C和IJB-S。虽然挑战是在低质量的数据集上获得较高的准确性,但大多数流行的训练数据集仍然由高质量的图像组成。由于只有一小部分训练数据质量较低,因此在训练期间适当地利用它是很重要的。
低质量的人脸图像的一个问题是,它们往往无法辨认。当图像退化过大时,相关的身份信息从图像中消失,导致图像无法识别。
这些无法识别的图像对训练过程有害的,因为模型将试图利用图像中的其他视觉特征,如服装颜色或图像分辨率,进而会影响训练损失。如果这些图像在低质量图像的分布中占主导地位,那么该模型在测试期间很可能在低质量的数据集上表现不佳。
由于无法识别的面部图像的存在,于是作者便想设计一个损失函数,根据图像质量对不同困难的样本赋予不同的重要性。作者的目标是强调高质量图像的困难样本和低质量图像的简单样本。通常,对样本的不同困难是通过观察训练进展(课程学习)来分配不同的重要性的。然而,作者实验表明,样本的重要性应该通过观察难度和图像质量来调整。
应该根据图像质量不同地设置重要性的原因是,直接强调困难样本总是强烈强调不可识别的图像。这是因为人们只能对无法识别的图像进行随机猜测,因此,它们总是在困难样本中。在将图像质量引入到目标中方面存在着一些挑战。这是因为图像质量是难以量化的,因为它的广泛定义和基于困难的缩放样本经常引入本质上是启发式。
在本工作中,作者提出了一个损失函数,以无缝的方式实现上述目标。作者还发现,
-
特征范数可以很好地代表图像质量;
-
不同的裕度函数对不同的样本困难具有不同的重要性。
这2个发现结合在一个统一的损失函数AdaFace中,该函数根据图像质量自适应地改变边缘函数,对不同的样本困难赋予不同的重要性。
主要贡献
-
提出了一个损失函数,
AdaFace,它根据样本的图像质量对不同的困难样本赋予不同的权重。通过结合图像质量,避免强调难以识别的图像,专注于困难但可识别的样本; -
通过实验表明,角边缘尺度的学习梯度与训练样本的难度相关。这一观察结果促使作者通过自适应地改变边缘函数来强调困难样本,如果图像质量较低,则忽略非常困难的样本(无法识别的图像)。
-
证明了
feature norms可以作为图像质量的代理。它绕过了需要一个额外的模块来估计图像质量。因此,自适应边际函数不需要额外的复杂度。 -
通过对9个不同质量的数据集(LFW、CFP-FP、CPLFW、AgeDB、CALFW、IJB-B、IJB-C、IJB-S和TinyFace)的广泛评估,验证了该方法的有效性。实验表明,
AdaFace在低质量数据集上的识别性能可以大大提高,同时保持在高质量数据集上的性能。
2相关工作
2.1 Margin Based Loss Function
基于Margin的softmax损失函数被广泛应用于人脸识别训练中(FR)。在Softmax损失中加入了Margin,是因为加入Margin后模型可以学习到更好的类间表征和类内表征,特征也就更具有可判别性。典型的形式有:SphereFace、CosFace和ArcFace引入了不同形式的Margin函数。具体来说,它可以t同意写成:
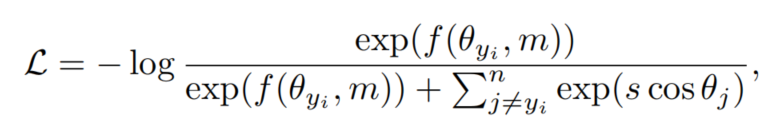
式中,θ为特征向量与第个分类器权值向量之间的夹角,为Ground Truth(GT)的索引,m为Margin是一个标量超参数。是一个边际函数,其中,SphereFace、CosFace和ArcFace可以用一下3中不同的Margin函数表达:

