
- 1李宏毅机器学习2016 第十五讲 无监督学习 生成模型之 VAE_vae 李宏毅 ppt
- 2基于Java的剧本杀预约系统设计与实现(源码+lw+部署文档+讲解等)_剧本杀预约系统java
- 3鸿蒙系统app开发语言_华为高管宣布,开发鸿蒙App编程语言确认,或取代安卓系统?...
- 4人眼定位python代码_使用dlib,OpenCV和Python进行人脸识别—人眼眨眼检测
- 5山东移动CM311-5-ZG_国科GK6323V100C_安卓4.4.2_免拆U盘卡刷刷机固件包_cm311-5 刷机
- 6Pytorch简介和安装_pytorch preview
- 7关于docker-Engine使用的存储驱动devicemapper的常识
- 8网络七层模型之会话层:理解网络通信的架构(五)
- 9Python界面 可视化开发(python3+PyQt5+Qt Designer)_基于python和pyqt5的快速开发模板系统
- 10微信小程序的使用_上传成功后,需要联系管理员在小程序管理后台将本次上传设置为体验版本.
Disco Diffusion 快速入门
赞
踩
简介
Disco Diffusion(DD)是一个CLIP指导的AI图像生成技术,简单来说,Diffusion是一个对图像不断去噪的过程,而CLIP模型负责对图像的文本描述(CLIP是一个图文匹配模型)
DD liyongCLIP图像识别的能力,来不断指导diffusion算法迭代去噪的过程,来使图像不断接近我们的描述(prompt),CLIP在这个过程中,用于评估图像和文本之间的差距,并提供一个方向性的指导。
这里插播一段简要介绍一下CLIP模型的作用,我们知道,作为语义理解能力非常强的人类,我们可以轻松地根据图片来“看图写话”,亦可以轻松的根据文字描绘的场景在大脑中重建,然而对于计算机来说,理解人类说的“话”并非易事,要想把人类理解的“意思”转译为一个个二进制符号,实际上具有很大的挑战,好在深度学习技术和发展和硬件条件的飞速提升,计算机视觉和自然语音处理都实现了很多不可思议的功能,计算机视觉可以让计算机轻松的识别画面中的内容,但实际上计算机的输出只是一个个概率,而画面的“语义”仍然需要人们去赋予; 自然语言处理可以轻松的“理解”人们说了什么,甚至可以和你进行对话和聊天。可是,如果二者结合起来,让一堆风格内容各异,和对这些画面的描述语结合起来呢?于是CLIP应运而生,它可以做到在一堆乱七八糟的描述语中找到最适合当前这副化的,就像你给它一副放在框框中的苹果,它会找到最接近的描述如“苹果放在框中”而不会说这是一个香蕉在碗里。
那么,如果反过来呢,既然可以根据图片来匹配到文字描述,那么可以至给出文字描述来让AI画图么?这就是Disco Diffusion接下来要做的事情。
通俗地来说,Diffusion的起点,是一堆毫无意义的噪声,也就是你在使用模型训练时,一开始看到的是这样的:

好,现在你看到的是一副没有任何信息,杂乱无章的图像,但是我更愿意将他称为"在浓雾中的名画"。 几年前,计算机视觉的科学家就在想办法将被噪声污染的图像通过各种技术手段还原,包括去除成像设备固有缺陷带来的噪点、天气条件恶劣如大雾大雨造成的图像不清晰,而如今,图像去雾去雨技术已经让人眼难以分辨,那么,计算机能够凭借它的想象力将这幅画的“浓雾”褪去,解开它的真实面目么?
这就是Diffsion,它的任务其实就是去噪,换句话来说,我给了Diffusion一个最极端的任务,就是一副全部是噪声的图像,让他在一副全部是噪声的图像中“作画”,那既然这幅画我们自己都不知道是啥样子了,Diffusion怎么能给出来了,于是,Diffusion就不断的猜呀猜,就像一个作家在玩沙画一样,但一开始他也不知道该怎么画,所以沙子一开始是胡乱的摆放着的;
而CLIP它像个没学过画画的小孩,没有任何绘画技巧,但是这个小孩有着天马行空的脑袋,大人给他讲一个简单的故事,它脑海中就会有非常奇妙的画面,于是,我们吧故事(也就是prompt)将给CLIP听,CLIP看着Diffusion画画,告诉它要画哪些东西,画人还是画房子,房子是啥样的,天空是啥样子的,然后Duffusion用灵巧的双手不断的重排沙子的位置,渐渐的,它就把CLIP想要的画画出来了,于是,完成了AI创作。
快速开始
这里使用的平台是@矩池云
官方的平台放在了Google Colab,但是实际上考虑到科学上网的技术难度、网速、算力资源,一般用户使用起来还是比较困难的,但是矩池云已经搭建了完成的Disco镜像,可以直接使用,无需自己再搭建环境。
进入官网后租用GPU,找到Disco镜像,(一般在第2页就是,找不到也可快速搜索)
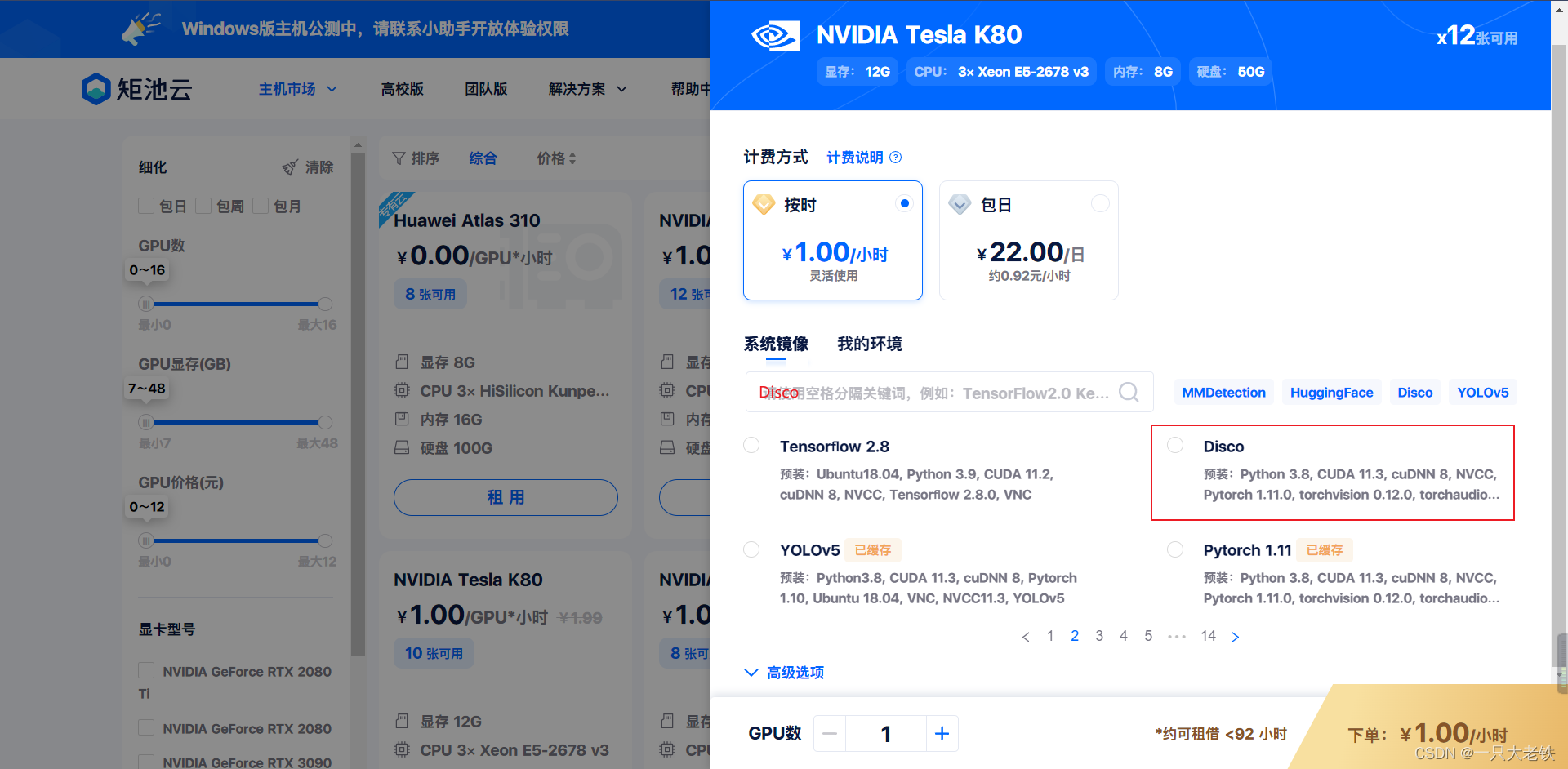
等待服务器启动完成后,点击连接进入Jupyter
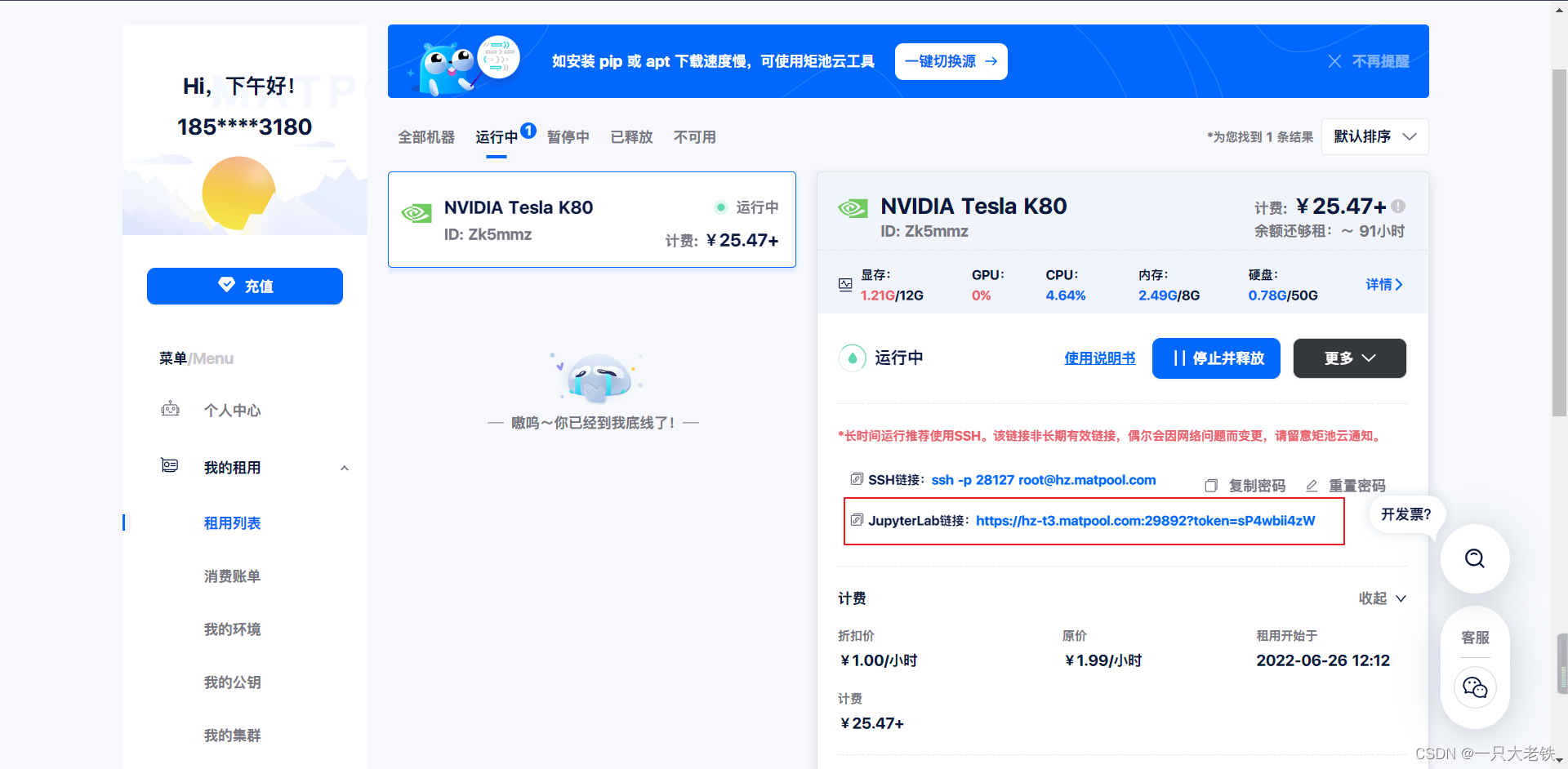
进入后找到 disco-diffusion文件夹
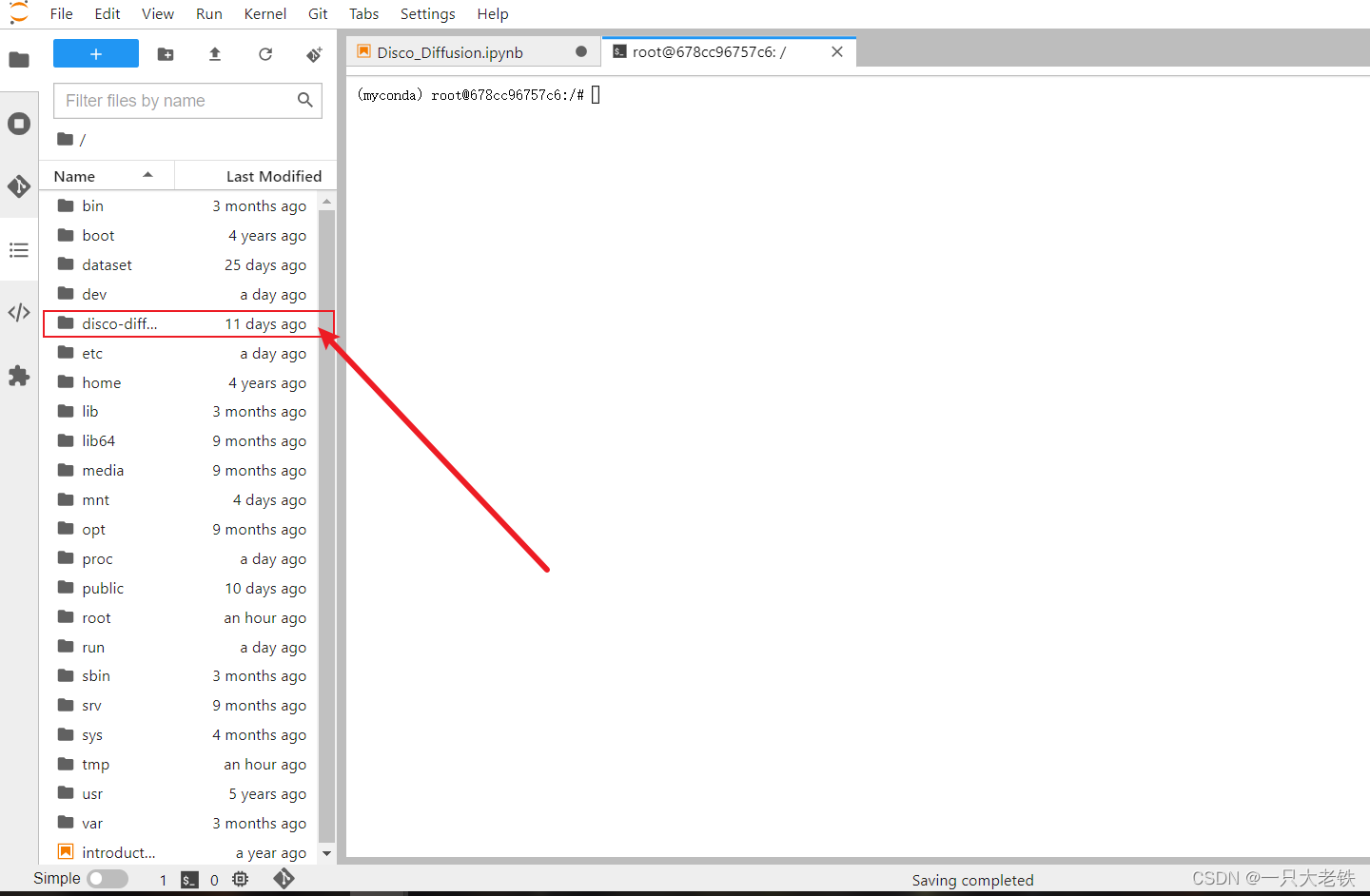
点开后打开Jupyter notebook
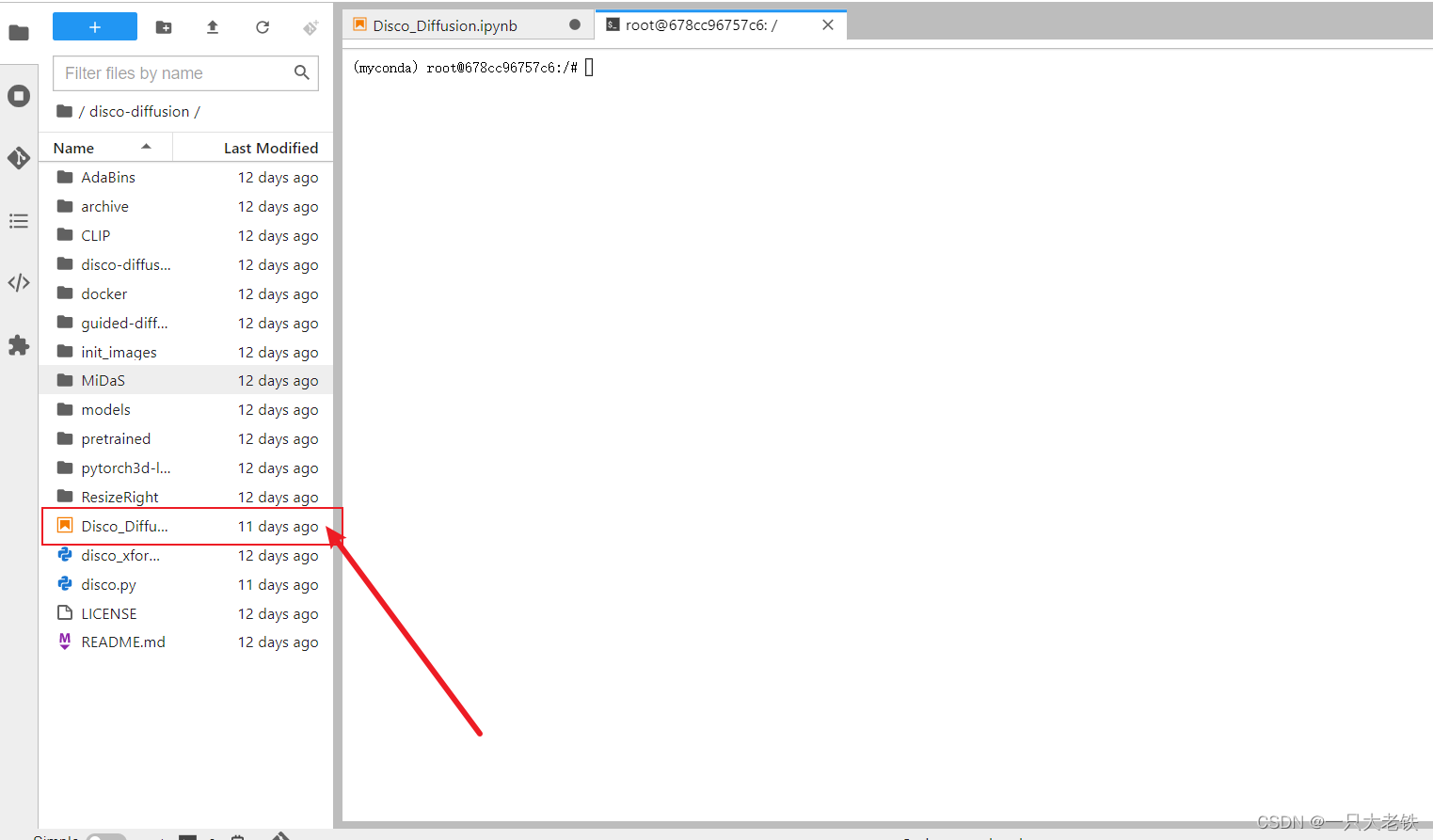
点击全部运行,等待依次等待模型加载完成,就可看到图像根据prompt的生成和迭代了:
进阶使用
修改prompt
在jupyter中找到下面这样的代码,或者Ctrl+F查找text_prompts关键词快速跳转
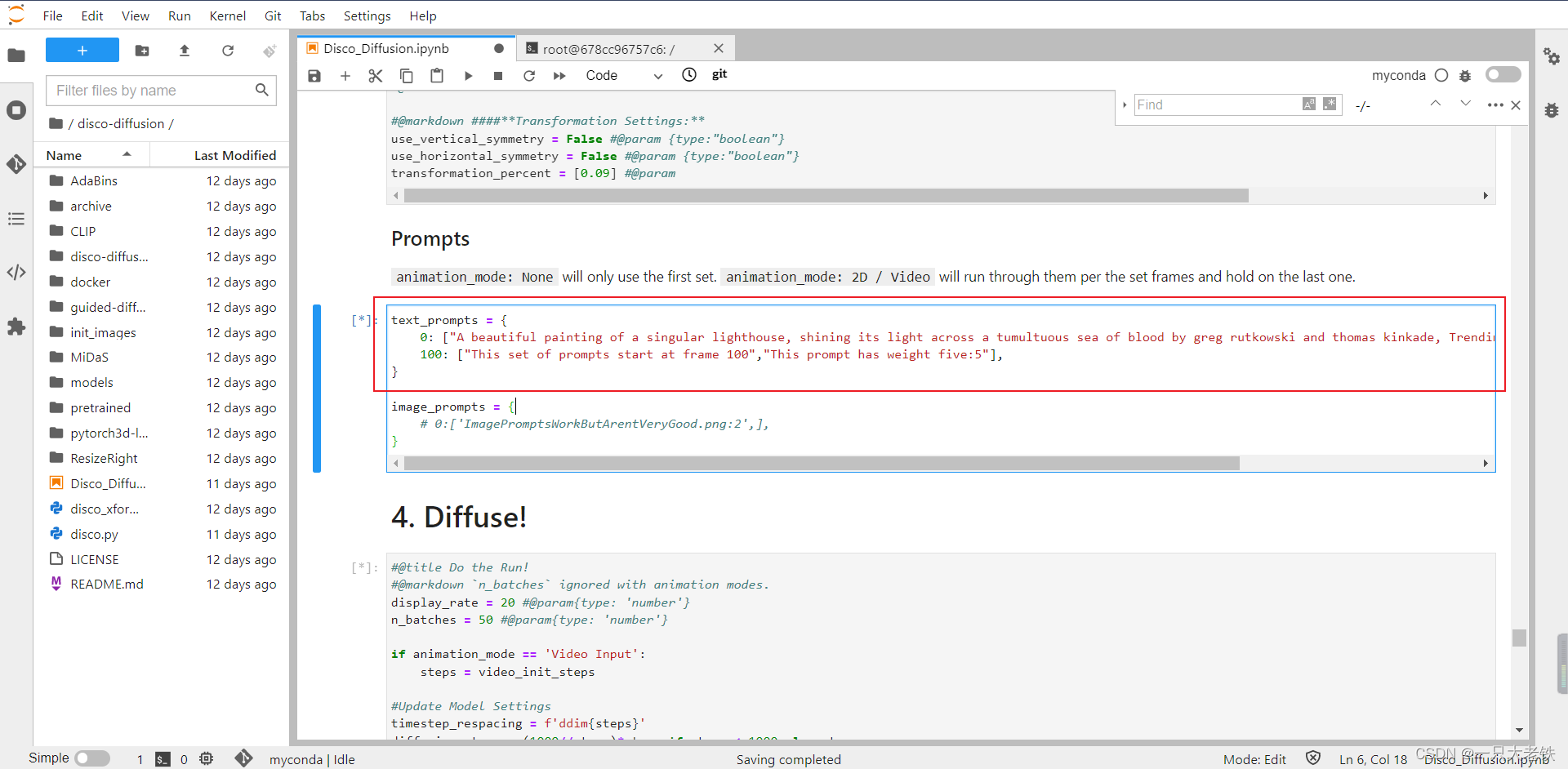
红框中的就是描述语了,我们只需呀该0后面的语句,不需要动100后面的语句。描述语句可以参考网站:bilibili
整个画作的描述词可拆解为五个维度理解:
- 画种描述:A beautiful painting of;
- 内容描述:a singular lighthouse, shining its light across a tumultuous sea of blood;
- 画家描述:by greg rutkowski and thomas kinkade;
参考渲染方式:Trending on artstation(全球最专业的CG艺术家社区,又称A站); - 颜色描述:yellow color scheme。
给定指导图像
事实上Disco Diffusion不仅仅可以根据文本描述,还可以添加参考图像来创作,Disco Diffusion在你给定的参考图像基础上,结合文本描述进一步“艺术化”
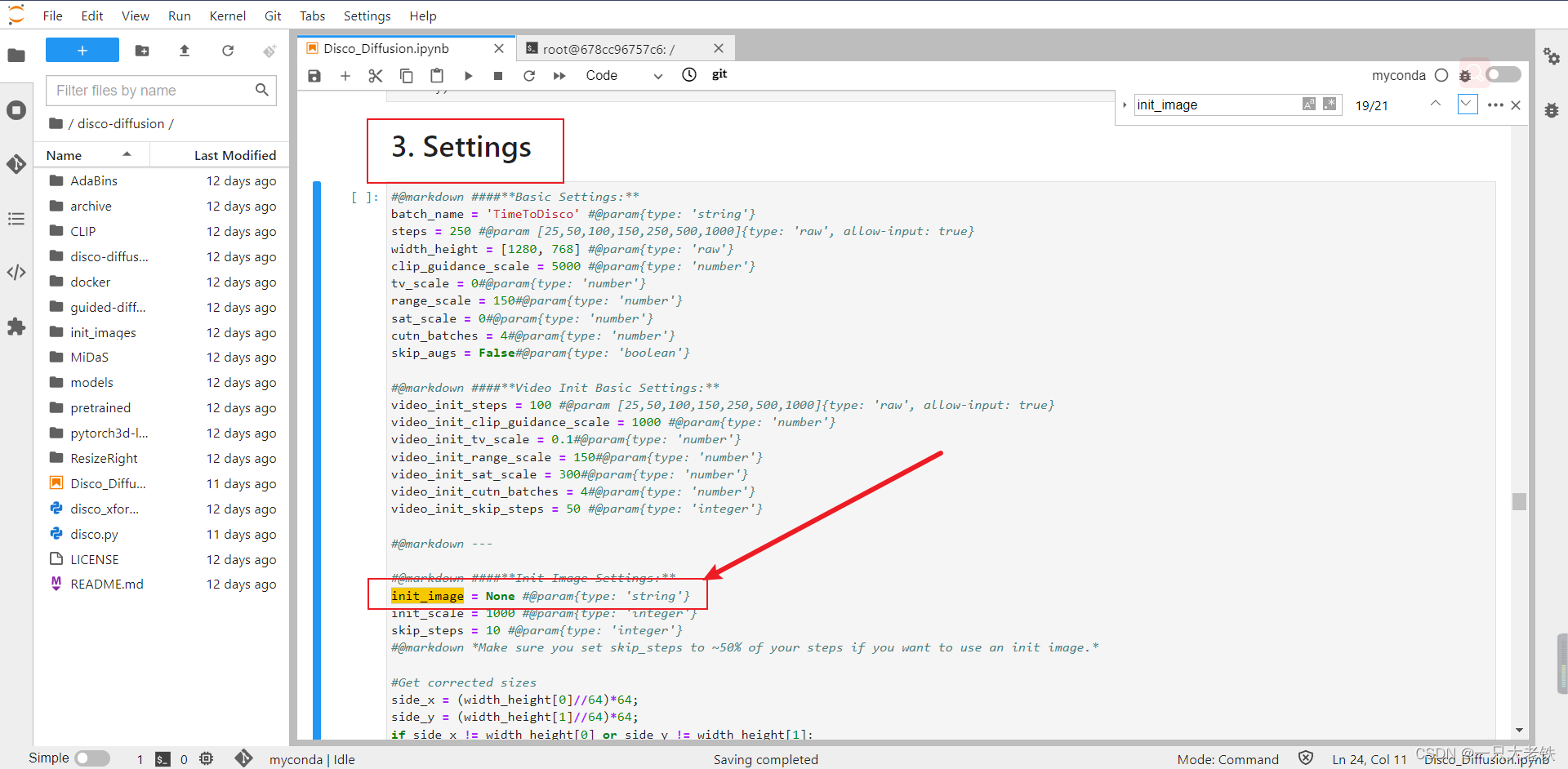
在Jupyter中找到init_image ,填写参考图像的路径即可。
修改基础参数
batch_name: batch保存的文件夹名,最终的图像/视频输出将会保存在.\Disco_Diffusion\images_out\ batch_namewidth_height: 希望的最终图像尺寸,单位是像素,默认1280×768,尺寸越大占用显存越多。你可以有一个正方形、宽或高的图像,但每个边缘的长度应设置为64的倍数,在默认情况下,最小为512 px。官方建议[512x768]是你开始使用的时候很好的设置, [1024x768]其实有点过大了,也有可能会导致显存不够的现象。steps: 迭代次数,默认250,可选值范围是50-10000,在创建一个图像时,去噪过程被细分为处理的步骤。 每个步骤(或迭代)都涉及到AI查看被称为 "切割 "的图像子集并计算出 “方向"来引导图像朝着prompt的方向生成。然后,它在diffusion去噪的过程对图像进行调整并进入下一个步骤。 增加steps将为AI提供更多的机会来调整图像,而且每次调整都会比较小,因此会产生更多的精细的图像。增加steps的代价就是延长渲染时间。另外,虽然增加步数通常会提高画面质量,但一般来说超过250-500步的时候,实际上的改善就不是特别明显了。然而,一些复杂的图像可能需要1000、2000、甚至更多的步骤,这都取决于你。- skip_steps: 必须可以整除steps,默认值10,。由于一开始图像变化会非常快,AI需要从完全的噪声图像快速的形成画面的大致轮廓,但随着diffusion步骤的进行,AI开始对画面的调整也愈来愈精细。因此去噪的前几个步骤往往是非常戏剧性的,有些步骤 (可能占总数的10-15%) 可以被跳过而不而不影响最终的图像。因此,可以通过跳过这些步骤来缩短渲染时间。但与此同时,这项值过大意味着跳过了太多的步骤,剩下的噪声可能不够产生新的内容,因此可能没有 "剩余时间 "来完成一幅满意的图像。实际上,设置一定的skip_steps是必要的,因为它也可以方式CLIP模型过拟合的可能,比如颜色饱和度过高、出现纯白或者纯黑的区域,最后,如果有
init_image,则需要跳过大约50%的steps来保证和init_image的相似。 clip_guidance_scale: 默认5000,可选范围1500-100000,用于指示最终图像和描述文本(prompt)的相似度,是非常重要的参数之一。一般来说越高越好,但如果太大的话,它也会过度接近目标并扭曲图像,所以该参数的选择也需要结合自己的经验吧。 值得注意的一点,这个参数,它会随着图像的尺寸变化而变化,如果一开始你选择了一个合适的参数比如总尺寸增加了50%,那么这个参数值也应该增加50%tv_scale: 总噪声方差,默认为0,可选参数,范围为0-1000,设置为0即可关闭。控制最终输出的 “平滑度”。如果使用,tv_scale将尝试平滑你的最终图像,以减少整体噪声。range_scale: 默认150,可选参数,范围0-1000,0即关闭。用于调整颜色的对比度。较低的range_scale会增加对比度。非常低的值会产生更多鲜艳的或类似海报的图像。较高的range_scale会降低对比度,使图像更加柔和。sat_scale: 过饱和调整,可选参数,设置为零即可关闭。如果使用,sat_scale将有助于减轻过饱和度,如果你的图像过于饱和,可以增加sat_scale来降低饱和度。init_image: 可选参数,作为AI生成图像的参考图像,也是起点图像,如果保持默认值(None),那么生成的结果就是一开始我们看到的噪声图像。init_scale: 默认值1000,可选范围10-20000, 这控制了CLIP在多大程度上会试图匹配提供的init_image。这与上面的 clip_guidance_scale相互平衡。较大的值时,图像就不会在扩散过程中变化很大。而太多的clip_guidance_scale,初始图像可能会被丢失。cutn_batches: 切割批次,默认值4,取值范围1-8,每一次迭代,AI都会将图像切割成更小的片段,称为"切割",并将每个切割与提示进行比较以决定如何指导下一个diffusion步骤。更多的切割通常会有更好的图像,因为DD有更多的机会在每个step中微调图像的精度。然而,当切割数目过多的时候也需要大量的内存,如果DD试图一次评估太多的切割,它可能会耗尽内存。你可以使用cutn_batches 来增加切割的次数,而不增加内存的使用。在默认设置下,DD被安排在每个时间段做16次切割。如果 cutn_batches被设置为1,则每个时间段确实只有16次切割。如果设置,则总共切割64次,并分成4批切割 。在同一时间,计算机只会处理1批的切割,因此 切割总次数/16 = cutn_batches (切割批次)skip_augs: 算法中使用 "torchvision"进行了图像增强,即在图像创建过程中引入了随机的图像缩放、透视和其他选择性的 在图像创建过程中进行随机调整。这些增强的目的是为了帮助提高图像质量,但可能会对边缘产生 不被希望的"平滑 "效果。通过设置skip_augs为True就可以跳过这些增强步骤,并略微加快渲染速度。可以尝试对比打开前后的差异,来获取你想要的结果。
运行参数设置
n_batches: 默认值50,可选范围0-100,这个变量设置你希望DD创建的静止图像的数量。如果你使用的是动画模式,DD将忽略n_batches,并根据动画设置创建一套单一的动画帧,并根据动画设置创建一组动画。display_rate: 默认值50,可选范围5-500, 控制预览刷新频率。默认的50表示每50步刷新一次预览效果,把它设置为一个较低的值,如5或10,是一个很好的方法来获得一个早期的监视你的图像的走向的方法。resume_run: 如果你的批处理运行被打断了(无论是因为你停止了或因为断线,)你可以用这个复选框在你离开的地方恢复你的批处理运行,但前提是必须不改变之前的参数设置,不然可能就不能恢复。因此,如果你已经中断了一次运行并调整了设置,就不应该使用这个参数 ,而应该重新运行。
运行建议
一个常见的DD工作流程是,改变描述(prompt)或参数设置,做一个短的运行。评估图像,然后调整设置,再做一次。在DD的表现上有很多的变化,而且图像需要时间来渲染,所以反馈也需要时间。因此,最好是有条不紊地去做并记下你所做的改变和它们的影响。当你在尝试使用文字的描述时,最好是把总的步骤数调低。这样你就能很快看到描述后的效果。一旦你确定了你喜欢的文字描述,那么你就可以调高步数和调整设置,以使你的最后的图像效果和图像质量更好。
模型设置
这些设置涉及对渲染模型的更改,属于更“高级”的设置,初学玩家可以先不考虑。
diffusion_model: 所选择的diffusion模型use_secondary_model: 默认值为True, 可以选择使用一个辅助的diffusion模型来清理临时diffusion图像,用于CLIP 评估。如果这个选项被关闭,DD将使用常规的 (大)扩散模型。使用辅助模型更快,渲染速度几乎可以提高50%。但可能会降低图像质量和细节。.sampling_mode: 两种去噪算法,默认值ddim,可选值(ddim or plms) 两种。ddim出现的时间较长,而且更加成熟和经过测试。plms是一种新增加的方法,承诺以较少的步骤获得良好的扩散结果,但没有经过充分的测试,可能有不稳定的情况。这种新的plms模式也正在积极被研究中。timestep_respacing: 保持默认,内部变量,可以不用管他diffusion_steps: 保持默认,内部变量,可以不用管他use_checkpoint: 默认值为True, 这个选项有助于在生成图像时节省显存生成图像。如果你使用的是一台非常强大的机器(如A100),你可以会把这个选项关掉,以加快速度,然而你也可能立即遇到CUDA OOM错误,所以要谨慎使用。
参数详情
基本可调的参数都如下表:
| 变量名称 | 描述 | 默认值 |
|---|---|---|
| text_prompts | 对你希望机器生成的内容进行描述。 | N/A |
| image_prompts | 可以设置一些参考图片,以对其内容的更多描述(可选) | N/A |
| clip_guidance_scale | 控制图像与描述语的相似程度。 | 1000 |
| tv_scale | 控制最终输出的平滑度 | 150 |
| range_scale | 控制RGB值允许超出的范围有多大 | 150 |
| sat_scale | 画面饱和度控制 | 0 |
| cutn | 控制要从图像中提取多少个裁剪 | 16 |
| cutn_batches | 积累batch裁切的CLIP梯度 | 2 |
| init_image | 初始化的图片,机器在一张图片的基础上做渲染,可以是照片、涂鸦等,也可以保持缺失让机器自己发挥 | None |
| init_scale | 初始图像对最终结果影响的程度,建议值是1000 | 0 |
| skip_steps | 控制控制diffusion时间段的起始点 | 0 |
| perlin_init | 是否选择以随机的perlin噪声开始 | FALSE |
| perlin_mode | perlin噪声模式—(‘gray’, ‘color’) | mixed’ |
| skip_augs | 是否跳过torchvision的图像增强功能 | FALSE |
| randomize_class | imagenet类是否在每次迭代中随机改变 | Ture |
| clip_denoised | CLIP是否能分辨出有噪音的或去噪的图像 | FALSE |
| clamp_grad | 实验性的:在cond_fn中是否使用自适应clip梯度 | Ture |
| seed | 选择一个随机的种子,并在运行结束时打印出来供复制。 | random_seed |
| fuzzy_prompt | 是否向描述损失添加多个随机的干扰描述 | FALSE |
| rand_mag | 控制随机的干扰描述的大小 | 0.1 |
| eta | DDIM超参数 | 0.5 |
| use_vertical_symmetry | 是否是水平对称的 | FALSE |
| use_horizontal_symmetry | 是否是垂直对称的 | FALSE |
| transformation_steps | 控制对称性强度(以百分比的形式) | 0.01 |
| video_init_flow_warp | 是否启动Flow_warp | Ture |
| video_init_flow_blend | 0–你得到的是原始输入,1–你得到的是被warp的前一帧 | 0.999 |
| video_init_check_consistency | TBD检查前向-后向flow的一致性(除非有太多的扭曲假象,否则不检查) | FALSE |
| timestep_respacing | 修改这个值可以减少迭代次数 | ddim100 |
| diffusion_steps | 迭代次数 | 1000 |
| clip_models | 要加载的CLIP的模型。通常情况下,越多越好,但它们都有很高的显存成本。 | ViT-B/32, ViT-B/16, RN50x4 |
| display_rate | 控制预览刷新频率。默认的50表示每50步刷新一次预览效果 | 50 |
| n_batches | 同一词组关键词,生成多少张图。默认的50表示AI绘制完成50张图后停止绘画 | 50 |
| steps | 越大画面越精细,渲染也越慢,但超过500其实提升不显著 | 240 |
| width_height | 生成的图像大小(分辨率),必须是64的倍数, | [1270,768] |

