
- 1GPT-2原理-Language Models are Unsupervised Multitask Learners
- 2垃圾分类算法训练及部署_垃圾4分类cnn模型构建代码
- 3chapter_linear-networks:线性回归的从零开始实现_如果样本个数不能被批量大小整除,data_iter函数的行为会有什么变化?
- 4动手学深度学习:代码笔记_动手学深度学习代码
- 5借助 AI 我为 Raycast 制作了一个可以 OCR 中文的插件_raycast怎么设置中文
- 6面试的时候,如何自我介绍?_面试自我介绍csdn
- 7【鸿蒙征程】二.真机模拟,签名证书获取✨保姆级教学,很详细✨_鸿蒙 hap 签名证书 申请
- 8计算机毕业设计选题推荐-画师约稿平台-Java项目实战_计算机毕设 约稿
- 9SpringBoot整合SpringMVC+MyBatis_springbootmvc +mybatis
- 10利用SPI协议读写SD卡_spi sd driver
史上最直白之Attention详解(原理+代码)_od_attention
赞
踩
为什么要了解Attention机制
在自然语言处理领域,近几年最火的是什么?是BERT!谷歌团队2018提出的用于生成词向量的BERT算法在NLP的11项任务中取得了非常出色的效果,堪称2018年深度学习领域最振奋人心的消息。而Transformer的Encoder部分是 BERT 模型的核心组成部分,Transformer中最为巧妙的结构又是attention机制,这次咱们从Attention机制的原理写这篇博客既是对我自己学习的一个总结,也希望或许能对你有所帮助!!!
Attention 的直观理解
Attention 机制直观理解很像人类看图片的逻辑,当我们看一张图片的时候,我们并没有看清图片的全部内容,而是将注意力集中在了图片的焦点上。大家看一下下面这张图:

我们一定会看清「锦江饭店」4个字,如下图:

但是我相信没人会第一时间去关注「路上的行人」也不会意识到路的尽头还有一个「優の良品」,所以,当我们看一张图片的时候,其实是这样的:

而我们上面所说的,通过引入我们的视觉系统这种关注图片中的突出信息的例子,就是我们深度学习中Attention机制的最直观的理解,在深度学习中Attention机制就是通过矩阵运算的方式将模型的注意力集中在输入信息重点特征上,从而节省资源,快速获得最有效的信息。
图解深度学习中的Attention机制
来拿seq2seq的模型来举例子,一般的基于seq2seq的翻译模型模型如下图:
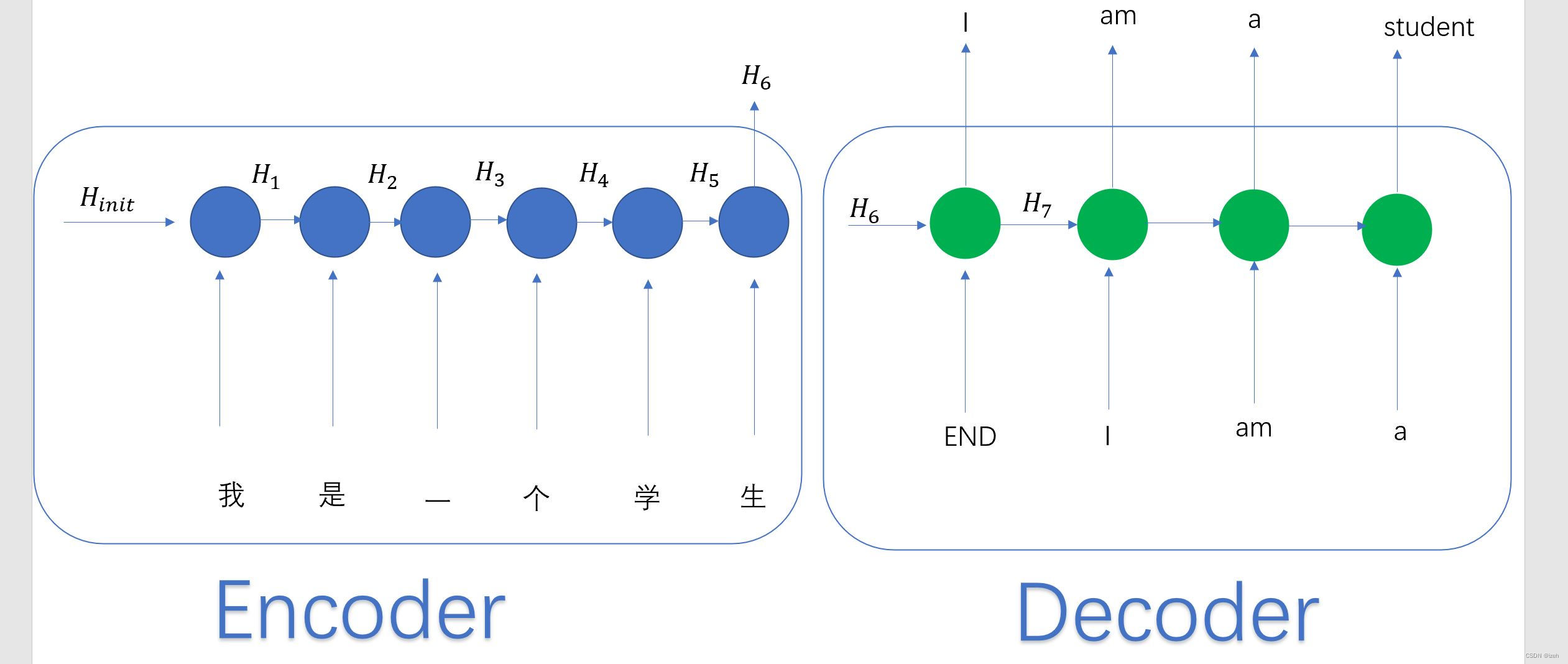 机器翻译场景中,输入的中文句子为:我是一个学生,Encoder-Decoder框架通过encoding得出了一个包含中文句子全部信息的H6向量,并通过H6逐步生成中文单词:”I“、”am“、”a“、”student“。在翻译”student“这个单词的时候,分心模型里面每个英文单词对于翻译目标单词”student“的贡献程度是相同的,这很显然是不合道理的。显然”学生“对于翻译成”student“更为重要。
机器翻译场景中,输入的中文句子为:我是一个学生,Encoder-Decoder框架通过encoding得出了一个包含中文句子全部信息的H6向量,并通过H6逐步生成中文单词:”I“、”am“、”a“、”student“。在翻译”student“这个单词的时候,分心模型里面每个英文单词对于翻译目标单词”student“的贡献程度是相同的,这很显然是不合道理的。显然”学生“对于翻译成”student“更为重要。
那么它会存在什么问题呢?类似RNN无法捕捉长序列的道理,没有引入Attention机制在输入句子较短时影响不大,但是如果输入句子比较长,此时所有语义通过一个中间语义向量表示,单词自身的信息避免不了会消失,也就是会丢失很多细节信息,这也是为何引入Attention机制的原因。例如上面的例子,如果引入Attention的话,在翻译”student“的时候,会体现出英文单词对于翻译当前中文单词的不同程度影响,比如给出类似下面的概率分布:
(我,0.2)
(是,0.1)
(一个,0.2)
(学生,0.5)
那么attention机制是通过什么方式来对于输入信息实现这种功能的能,答案是引入所谓的q、k、v三个矩阵并进行运算实现的,Attention有很多不同种类,本文具体以self-attention的来讲解Attention机制的实现过程(self-Attention中的Q是对自身(self)输入的变换,而在传统的Attention中,Q来自于外部):1、在self-attention中,会有三种矩阵向量,即Q(Query)查询向量、K(key)键值向量、V(value)值向量。它们是通过X乘以三个不同的权值矩阵
W
Q
W_Q
WQ、
W
k
W_k
Wk、
W
v
W_v
Wv具体操作步骤如下:
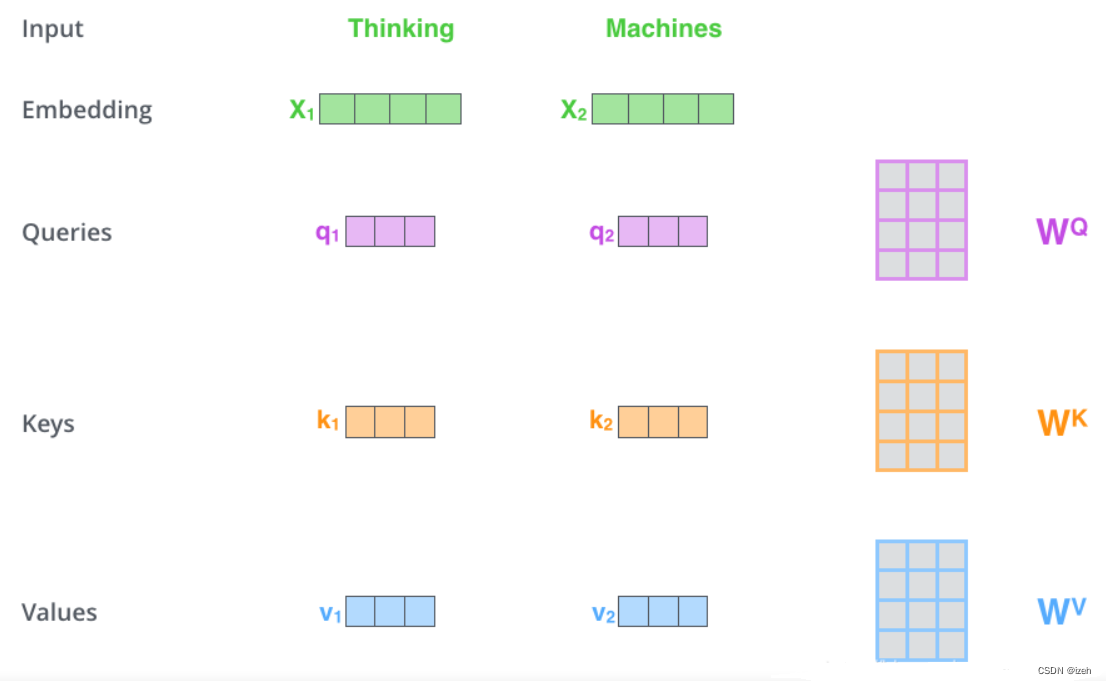 注意,这里的每个单词都会通过这三个向量产生这三种矩阵,而这三种向量是怎么把每个单词联系起来的呢?
注意,这里的每个单词都会通过这三个向量产生这三种矩阵,而这三种向量是怎么把每个单词联系起来的呢?
答案是在进行Attention运算时,首先会把当前单词产生的q(查询矩阵)和所有的k(键值矩阵进行相乘)得到一个中间结果,最后把自己的v(值矩阵)向量乘上这个中间结果矩阵,得到一个含有句子所有词语上下文信息的新向量。
q,k,v这三个向量在通过反向传播不断的学习,而逐步习得句子中那些信息是模型需要关注的重要特征。

self-Attention的实现代码:
# Muti-head Attention 机制的实现
from math import sqrt
import torch
import torch.nn
class Self_Attention(nn.Module):
# input : batch_size * seq_len * input_dim
# q : batch_size * input_dim * dim_k
# k : batch_size * input_dim * dim_k
# v : batch_size * input_dim * dim_v
def __init__(self,input_dim,dim_k,dim_v):
super(Self_Attention,self).__init__()
self.q = nn.Linear(input_dim,dim_k)
self.k = nn.Linear(input_dim,dim_k)
self.v = nn.Linear(input_dim,dim_v)
self._norm_fact = 1 / sqrt(dim_k)
def forward(self,x):
Q = self.q(x) # Q: batch_size * seq_len * dim_k
K = self.k(x) # K: batch_size * seq_len * dim_k
V = self.v(x) # V: batch_size * seq_len * dim_v
atten = nn.Softmax(dim=-1)(torch.bmm(Q,K.permute(0,2,1))) * self._norm_fact # Q * K.T() # batch_size * seq_len * seq_len
output = torch.bmm(atten,V) # Q * K.T() * V # batch_size * seq_len * dim_v
return output
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
Self-Attention可以通过qkv矩阵的计算过程中直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。除此外,Self-Attention对于增加计算的并行性也有直接帮助作用。正好弥补了RNN机制的两个缺点,这就是为何Self-Attention现在被广泛使用的主要原因。
总结
Attention机制笔者认为是Transformer模型中最出彩的设计,效果很好的同时可解释性也很强,在笔者后续的文章中会向大家再介绍大名鼎鼎的Transformer和BERT。希望看到这里,能帮助小伙伴你搞懂Attention机制,这样才能更好的理解后续的Transformer和BERT模型。

