
- 1树莓派配置环境变量,解决No such file or directory的错误提示_树莓派vncunable to open i2c device: no such file or d
- 2洛谷p3817 小A的糖果
- 3C语言easyx飞机大战源码+素材(大屏版)_易语言 飞机大战
- 4基于SpringBoot的农产品销售小程序平台的设计与实现_基于springboot粮食加工订单
- 5Word Tokenization
- 6浅析自动编码器(自编码器 Autoencoder)_深度学习 coding decoding
- 7抖音商品详情数据接口python_python 获取抖音商户信息
- 8MATLAB非线性规划优化问题_带约束的非线性优化算法代码
- 9毕业设计:基于卷积神经网络的图像分类系统 python人工智能_基于卷积神经网络的图像分类系统研究研究或设计的目的和意义:
- 10Dual Contrastive Learning: Text Classification via Label-Aware Data Augmentation 阅读笔记_dual-pool contrastive learning
Fluid 携手 Vineyard,打造 Kubernetes 上的高效中间数据管理
赞
踩
作者:曹野 车漾
背景介绍和面临的挑战
随着 Kubernetes 在 AI/大数据领域的普及和业务场景变得越来越复杂,数据科学家在研发效率和运行效率上遇到了新的挑战。当下的应用,往往需要使用端到端的流水线来实现,以下图所示的一个风控作业数据操作流为例:首先,需要从数据库中导出订单相关数据;随后,图计算引擎会处理这些原始数据,构建“用户-商品”关系图,并通过图算法,初筛出其中隐藏的潜在作弊团伙;接下来,机器学习算法会对这些潜在团伙进行作弊归因,筛选出更准确的结果;最后这些结果会经过人工筛查,并最终做出业务处理。

在这样的场景下,我们常常会遇到如下问题:
1. 开发环境和生产环境的差异导致数据工作流的开发和调试变得复杂且低效: 数据科学家在自己的计算机上开发时通常使用 Python,但是又需要在生产环境中将代码转化为他们并不熟悉的 YAML 文件从而利用 Argo、Tekton 等基于 Kubernetes 的工作流引擎,这大大降低了开发和部署效率。
2. 需要引入分布式存储实现中间临时数据交换,带来额外的开发、费用、运维成本: 端到端任务的子任务之间的数据交换通常依赖分布式文件系统或对象存储系统(如 HDFS、S3 和 OSS),这使得整个工作流需要进行大量的数据格式转换和适配工作,导致冗余的 I/O 操作,并由于中间数据的短期性,使用分布式存储系统会导致额外的成本。
3. 在大规模 Kubernetes 集群环境中数据处理的效率问题: 在大规模的 Kubernetes 集群中,使用现有的分布式文件系统处理数据时,由于调度系统对数据的读写本地性缺乏足够的理解,并未有效地考虑到数据的位置问题,没有充分利用数据的局部性,导致在处理节点间的数据交换时,无法避免大量的数据重复拉取操作。这种操作既增加了 I/O 消耗,也降低了整体的运行效率。
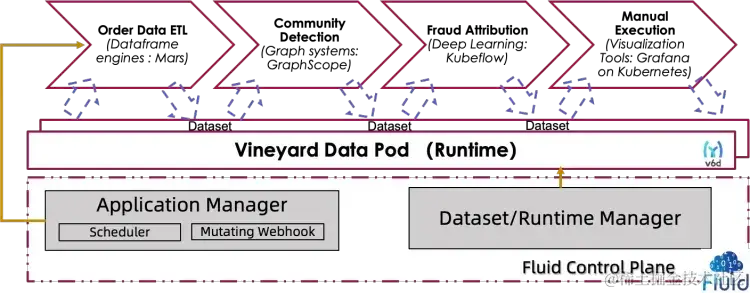
为了解决上述问题,我们提出了结合 Vineyard 数据共享能力和 Fluid 数据编排能力的解决方案:
- Fluid 的 Python SDK 能够方便地对数据流进行编排,为熟悉 Python 的数据科学家提供了一种简单的方式来构建和提交以数据集操作为中心的工作流。此外,Fluid 支持在开发环境和云上生产环境通过一套代码进行数据流管理。
- Vineyard 使端到端工作流中任务之间的数据共享更加高效, 通过内存映射的方式实现零拷贝数据共享,从而避免了额外的 I/O 开销。
- 通过利用 Fluid 的数据亲和性调度能力,在 Pod 调度策略考虑数据写入节点的信息,从而减小数据迁移引入的网络开销,提升端到端性能。
解决方案
什么是 Fluid
Fluid 是一个开源的 Kubernetes 原生的分布式数据集编排和加速引擎,主要服务于云原生场景下的数据密集型应用。通过 Kubernetes 服务提供的数据层抽象,可以让数据像流体一样在诸如 HDFS、OSS、Ceph 等存储源和 Kubernetes 上层云原生应用计算之间灵活高效地移动、复制、驱逐、转换和管理。
而具体数据操作对用户透明,用户不必再担心访问远端数据的效率、管理数据源的便捷性,以及如何帮助 Kuberntes 做出运维调度决策等问题。用户只需以最自然的 Kubernetes 原生数据卷方式直接访问抽象出来的数据,剩余任务和底层细节全部交给 Fluid 处理。
Fluid 项目架构如下图所示,当前主要关注数据集编排和应用编排这两个重要场景。数据集编排可以将指定数据集的数据缓存到指定特性的 Kubernetes 节点,而应用编排将指定该应用调度到可以或已经存储了指定数据集的节点上。这两者还可以组合形成协同编排场景,即协同考虑数据集和应用需求进行节点资源调度。
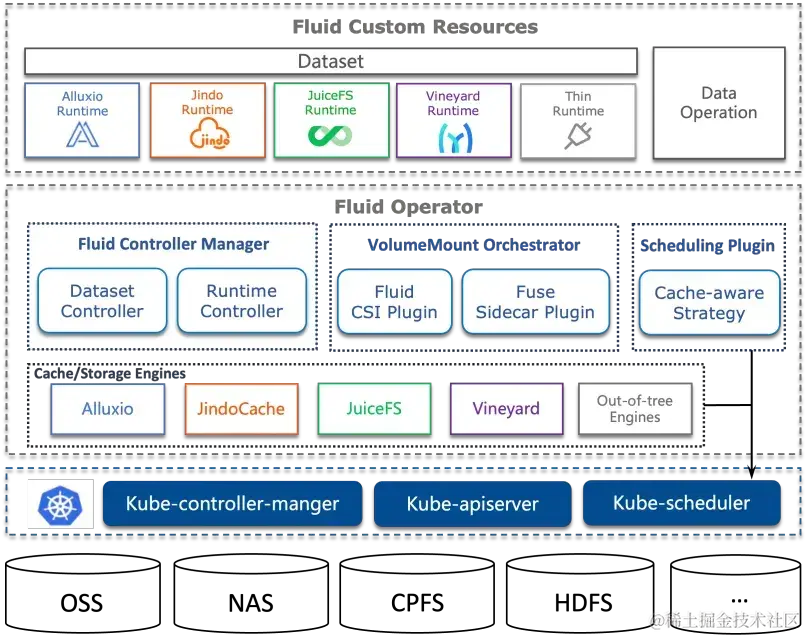
接着介绍 Fluid 中数据集 Dataset 的概念,数据集是逻辑上相关的一组数据的集合,会被运算引擎使用,比如大数据的 Spark、AI 场景的 TensorFlow。Dataset 的管理实际上也有多个维度,比如安全性、版本管理和数据加速。
Fluid 希望从数据加速出发,对数据集的管理提供支持。在 Dataset 上面, 通过定义 Runtime 这样一个执行引擎来实现数据集安全性、版本管理和数据加速等能力。Runtime 定义了一系列生命周期的接口,可以通过实现这些接口来支持数据集的管理和加速。Fluid 的目标是为 AI 与大数据云原生应用提供一层高效便捷的数据抽象,将数据从存储抽象出来从而达到如下功能:
- 通过数据亲和性调度和分布式缓存引擎加速,实现数据和计算之间的融合,从而加速计算对数据的访问。
- 将数据独立于存储进行管理,并且通过 Kubernetes 的命名空间进行资源隔离,实现数据的安全隔离。
- 将来自不同存储的数据联合起来进行运算,从而有机会打破不同存储的差异性带来的数据孤岛效应。
什么是Vineyard Runtime
首先我们来介绍 Vineyard,一个专为云原生环境大数据分析工作流中不同任务之间高效共享中间结果而设计的数据管理引擎。通过共享内存实现不同计算引擎之间中间数据共享的零拷贝,避免数据存入外部存储(本地磁盘、S3 及 OSS 等)的开销,从而提高了数据处理的效率和速度。
Vineyard Runtime 是 Fluid 中 Vineyard 相关组件的抽象,整体架构如下图所示。
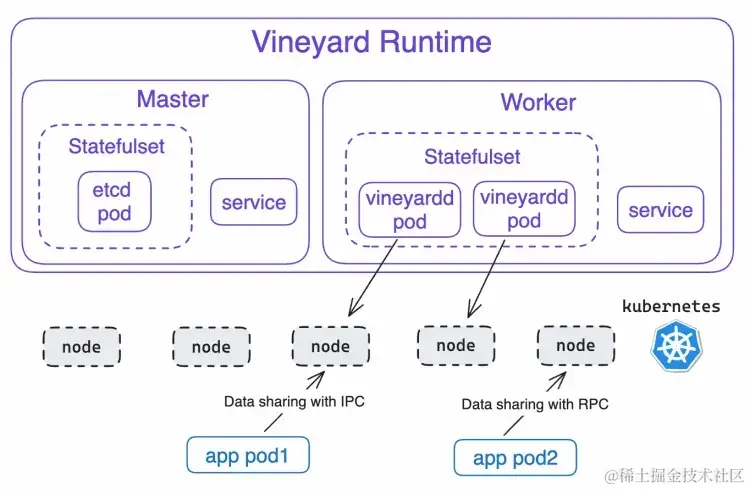
从图中可以看到,Vineyard Runtime 由两个核心组件 Master 和 Worker 构成,它们共同管理 Vineyard 中构成每个对象的 metadata 和 payload:
- Master:使用 etcd 作为元数据管理系统,承担 metadata 的存储功能。
- Worker:使用 vineyardd(Vineyard 的守护进程) 管理共享内存,负责存储 payload 数据。
在性能方面,当应用任务与 vineyardd 位于同一节点上,它们通过内部进程通信(IPC)进行高速数据传输;而在不同节点之间,应用任务与 vineyardd 通过远程过程调用(RPC)传输数据,速率相对较慢。
Vineyard Runtime 的优势
- 性能卓越: 避免不必要的内存拷贝、序列化/反序列化、文件 I/O 和网络传输等。同节点内应用与数据交互实现瞬时读取(大约 0.1 秒),写入仅需秒级时间;跨节点操作时,数据传输速度可接近网络带宽上限。
- 简单易用: 通过对分布式对象进行数据抽象,用户只需要使用简单的 put 和 get 操作就能在 Vineyard 中进行数据存取。同时支持包括 C++、Python、Java、Rust 和 Golang 在内的多语言 SDK 。
- 集成 Python 生态: 集成了常用的 Python 对象,例如 numpy.ndarray 、pandas.DataFrame、pyarrow.{Array,RecordBatch,Table}、pytorch.Dataset 和 pytorch.Module 等。
Vineyard Runtime 性能怎么样
在数据量大小为 22GB 的情况下,使用 Vineyard Runtime 的同节点和跨节点性能分别如下图所示。
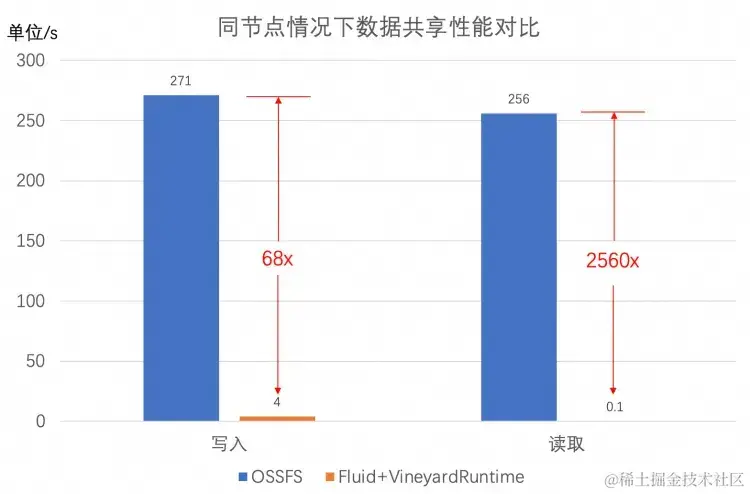
当用户任务被调度到 vineyardd 所在节点上时,此时达到 Vineyard 的最佳性能,即通过 IPC 实现数据传输。由于 Vineyard 会预先分配内存,数据写入到 Vineyard 比对象存储作为中间介质快 68 倍左右;由于和 Vineyard 共享同一块内存,用户任务在读取 Vineyard 数据时,数据将通过零拷贝的形式被传递到用户任务中,实现瞬时读取。

当用户任务被调度非 vineyardd 所在节点时,此时达到 Vineyard 的最差性能,即通过 RPC 进行数据传输。相比于 OSS,由于 Vineyard 进行 RPC 传输时基本能打满带宽,数据写入到 Vineyard 比 OSS 快 2.3 倍左右,从 Vineyard 读取数据比 OSS 快 2.2 倍左右。
Fluid+Vineyard 实战
在本教程中,我们将演示如何使用 Vineyard Runtime 在 ACK(Alibaba Cloud Kubernetes)上训练一个线性回归模型,请按照以下步骤进行操作。
步骤一:在 ACK 集群中安装 Fluid
选择 1:安装 ack-fluid,安装步骤可参考云原生 AI 套件文档 [ 1] 。
选择 2:使用开源版,我们使用 Kubectl [ 2] 创建一个名字为 fluid-system 的 namespace,然后使用 Helm [ 3] 来安装 Fluid,仅需通过以下几个命令来完成这个过程。
# 创建 fluid-system namespace
$ kubectl create ns fluid-system
# 将 Fluid 存储库添加到 Helm 存储库
$ helm repo add fluid https://fluid-cloudnative.github.io/charts
# 获取最新的 Fluid 存储库
$ helm repo update
# 找到 Fluid 存储库中的开发版本
$ helm search repo fluid --devel
# 在 ACK 上部署相应版本的 Fluid chart
$ helm install fluid fluid/fluid --devel
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
当我们在 ACK 上部署好 Fluid 平台后,接下来需要执行以下命令来安装 Fluid Python SDK。
$ pip install git+https://github.com/fluid-cloudnative/fluid-client-python.git
- 1
步骤二:开启数据与任务的协同调度(可选)
在云环境中,端到端数据操作流水线经常包含多个子任务。当这些任务被 Kubernetes 调度时,系统仅考虑了所需的资源约束,而无法保证连续执行的两个任务能在同一个节点运行。这导致二者在使用 Vineyard 共享中间结果时,会因为数据迁移引入额外的网络开销。如果希望将任务和 Vineyard 调度到同一节点达到最佳性能,可以按照修改如下 configmap 配置开启 FUSE 亲和性调度,这样系统调度将优先让相关联的任务在同一个节点进行内存访问,以减少数据迁移产生的网络开销。
# 按照以下命令修改 webhook-plugins 的配置,并开启 fuse 亲和性调度,
$ kubectl edit configmap webhook-plugins -n fluid-system
data:
pluginsProfile: |
pluginConfig:
- args: |
preferred:
# 开启 fuse 亲和性调度
- name: fluid.io/fuse
weight: 100
...
# 重启 fluid-webhook pod
$ kubectl delete pod -lcontrol-plane=fluid-webhook -n fluid-system
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
步骤三:构建和部署线性回归数据操作流水线
该步骤包括数据预处理、模型训练和模型测试阶段,完整代码可参考示例代码 [ 4] 。该步骤主要步骤如下:
- 创建 Fluid 客户端:代码使用默认的 kubeconfig 文件连接到 Fluid 控制平台,并创建 Fluid 客户端实例。
import fluid
# 使用默认 kubeconfig 文件连接到 Fluid 控制平台,并创建 Fluid 客户端实例
fluid_client = fluid.FluidClient(fluid.ClientConfig())
- 1
- 2
- 3
- 4
- 创建和配置 Vineyard 数据集与运行时环境:脚本创建名为 vineyard 的数据集并初始化相关配置,包括副本数和内存大小,使数据集绑定到运行时环境。
# 在 default namespace 下创建名为 vineyard 的数据集
fluid_client.create_dataset(dataset_name="vineyard")
# 获取 vineyard 数据集实例
dataset = fluid_client.get_dataset(dataset_name="vineyard")
# 初始化 vineyard runtime 的配置,并将 vineyard 数据集实例绑定到该 runtime。
# 副本数为 2,内存分别为 30Gi
dataset.bind_runtime(
runtime_type=constants.VINEYARD_RUNTIME_KIND,
replicas=2,
cache_capacity_GiB=30,
cache_medium="MEM",
wait=True
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 定义数据预处理、模型训练和模型评估函数:分别实现了用于执行数据清洗和划分数据集的预处理函数,训练线性回归模型的训练函数,以及用于评估模型性能的测试函数。
# 定义数据预处理函数 def preprocess(): ... # 将训练数据和测试数据存入 vineyard import vineyard vineyard.put(X_train, name="x_train", persist=True) vineyard.put(X_test, name="x_test", persist=True) vineyard.put(y_train, name="y_train", persist=True) vineyard.put(y_test, name="y_test", persist=True) ... # 定义模型训练函数 def train(): ... # 从 vineyard 中读取训练数据 import vineyard x_test_data = vineyard.get(name="x_test", fetch=True) y_test_data = vineyard.get(name="y_test", fetch=True) ... # 定义模型测试函数 def test(): ... # 从 vineyard 中读取测试数据 import vineyard x_train_data = vineyard.get(name="x_train", fetch=True) y_train_data = vineyard.get(name="y_train", fetch=True) ...

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 创建任务模版并定义任务工作流:利用先前定义的函数,创建了数据预处理、模型训练和模型测试的任务模板。这些任务按顺序执行以形成完整的工作流。
preprocess_processor = create_processor(preprocess)
train_processor = create_processor(train)
test_processor = create_processor(test)
# 创建线性回归模型的任务工作流:数据预处理 -> 模型训练 -> 模型测试
# 下列的挂载路径 "/var/run/vineyard" 是 vineyard 配置文件的默认路径
flow = dataset.process(processor=preprocess_processor, dataset_mountpath="/var/run/vineyard") \
.process(processor=train_processor, dataset_mountpath="/var/run/vineyard") \
.process(processor=test_processor, dataset_mountpath="/var/run/vineyard")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 提交并执行任务工作流:将工作流提交到 Fluid 平台进行执行,并等待任务完成。
# 将线性回归模型的任务工作流提交到 fluid 平台,并开始执行
run = flow.run(run_id="linear-regression-with-vineyard")
run.wait()
- 1
- 2
- 3
- 资源清理:执行完毕后,清理在 Fluid 平台上创建的所有资源。
# 清理所有资源
dataset.clean_up(wait=True)
- 1
- 2
通过以上一套 Python 代码可以帮助数据科学家在本地开发通过 kind 环境 [ 5] 进行调试,把阿里云 ACK 作为生产环境进行使用,在提升了开发效率的同时得到非常好的运行性能。
总结与展望
通过结合 Fluid 的数据编排和 Vineyard 的高效数据共享机制,可以解决 Kubernetes 中数据工作流中的开发效率低下、中间数据存储成本高昂和运行效率不足的问题。点击此处即可获得实战源代码。
未来,我们计划支持两个主要场景,一个是 AIGC 的模型加速,通过避免 FUSE 开销和存储对象格式转换将模型加载性能进一步提升;另一个是支持 Serverless 场景,为 Serverless 容器提供高效的原生数据管理。
参考资料:
[1] 云原生 AI 套件文档
https://help.aliyun.com/zh/ack/cloud-native-ai-suite/user-guide/deploy-the-cloud-native-ai-suite?spm=a2c4g.11186623.0.i14#task-2038811
[2] Kubectl
https://github.com/kubernetes/kubectl
[3] Helm
https://github.com/helm/helm
[4] 示例代码
https://v6d.io/tutorials/kubernetes/vineyard-on-fluid.html
[5] kind 环境
https://kind.sigs.k8s.io/

