
- 1题解 | #查找入职员工时间排名倒数第三的员工所有信息#_小红书 用人部门筛选(进行中)
- 2Django系统权限和组的使用_django中的group和权限怎么使用
- 3STM32F7xx基于HAL库的USB_CDC接收数据的函数调用_otg_hs_irqhandler
- 4java dfs算法_Java数据结构与算法之DFS
- 5A very simple framework for state-of-the-art Natural Language Processing (NLP) ------ note-1_transformerdocumentembeddings
- 6【C++ OpenCV】阈值二值化、阈值反二值化、截断、阈值取零、阈值反取零、自适应阈值使用方法以及时机_阈值二值化算法
- 7C语言常见知识点之变量的作用域和生命周期是什么?_c语言变量生命周期是什么意思
- 8java中List集合的几种遍历方式_java遍历list集合
- 9「 科研经验 」思考“工程解决方案”的思维_布尔森法则
- 10git使用笔记—如何下载tag下的版本代码_git下载某个tag 的源码
DCGAN解读
赞
踩
DCGAN
引言
DCGAN( Generative Adversarial Nets),又称生成对抗网络。原创论文由Martin Arjovsky等人于2017年发表。它是对标准的GAN模型的扩展,通过使用卷积层和反卷积层来处理图像数据,从而实现更稳定和高质量的图像生成。
对于DCGAN的理论模型和原理,原文的链接
标题和摘要
标题:
UNSUPERVISED REPRESENTATION LEARNING WITH DEEP
CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
unsupervised representation learning,即无监督表示学习,deep表示网络较深,
convolutional,即使用卷积神经网络,generative即生成式模型,adversarial即对抗网络,nets是networks的缩写。
摘要:
近年,在有监督的CV领域,cnn成就斐然。在无监督领域,我们尝试选用DCGAN处理无监督的任务,实验证明G和D能学习到多层次的物体表示,在多个数据集上表现良好。
结论和未来
-
成果展示:
作者在多个数据集上取得了较好的效果,并且对一些中间过程和结果做了数据可视化。
- Faces:
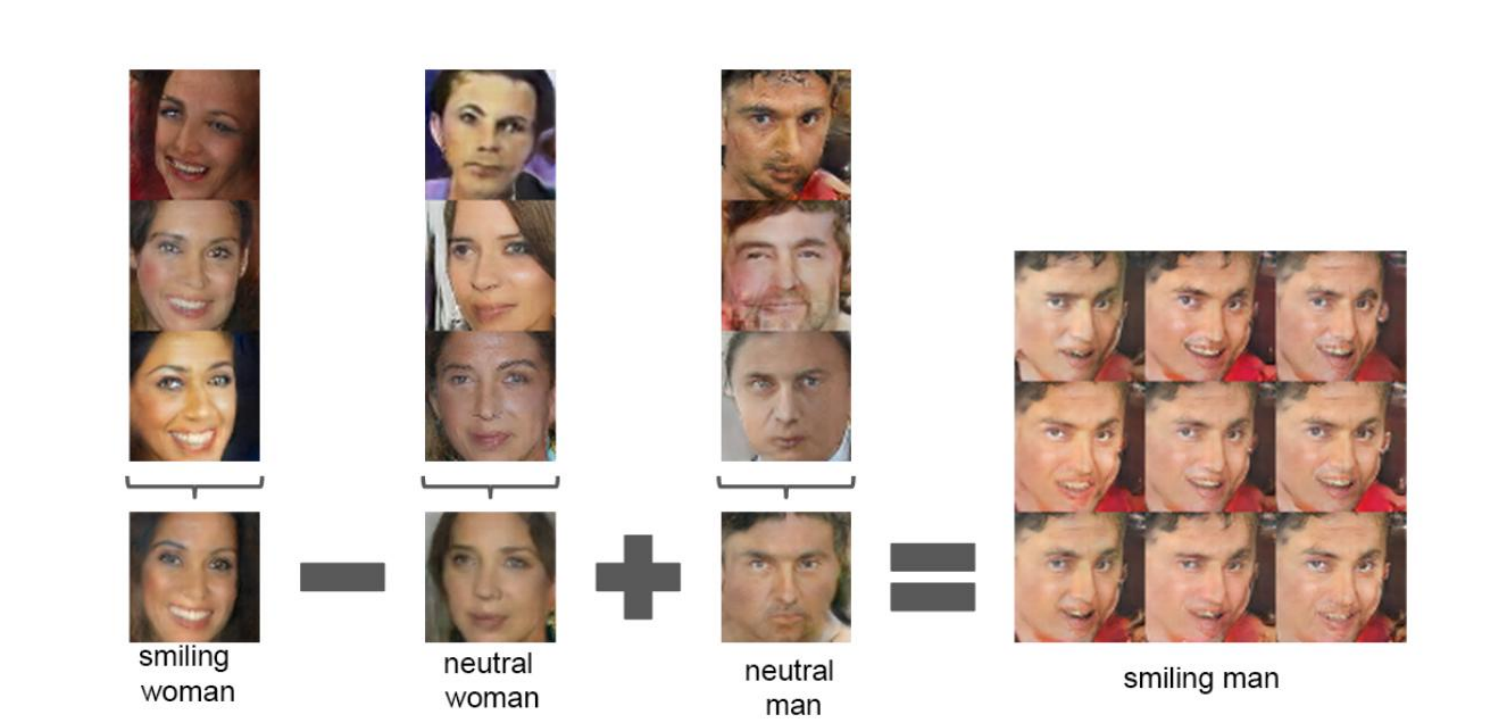
这里可以很直观地看到,上述实验得到以下等式:
微笑女人的人脸特征-普通女人人脸特征+普通男人人脸特征 = 微笑男人的人脸特征

同上,可以发现:戴眼镜男-不戴眼镜男+不戴眼镜女 = 戴眼镜女
 这个是对人脸的转向进行的调整,从左往右表示人脸的朝向变化。
这个是对人脸的转向进行的调整,从左往右表示人脸的朝向变化。
-
未来研究:
需要进一步的工作来解决这个不稳定问题。作者认为可以考虑扩展这个框架到其他领域,例如视频(用于帧预测)和音频(用于语音合成的预训练特征)。对学习到的潜在空间的属性的进一步研究也很有趣。
简介和相关
简介中作者提到了自己的贡献:
-
提出并评估了一组关于卷积 GAN 架构拓扑的约束,使它们能够在大多数设置下稳定地进行训练,将此类架构命名为DCGAN;
-
使用训练有素的鉴别器进行图像分类任务,与其他无监督算法的性能相比有竞争力;
-
将 GAN 学习到的过滤器可视化,并根据经验表明特定的过滤器已经学会了如何绘制特定的物体;
-
证明生成器具有向量算术属性,可以轻松实现操纵生成样本的许多语义质量。
相关工作这里,作者总结了一些前人的经验和相关研究,不做过多阐述
原理介绍
一个简单的DCGAN在图像生成领域的算法流程如下:
(1) 在随机正态分布上找一个点z(即找一个数)
(2) 通过生成器将点z映射为一个图片,选择的网络有点像CNN的逆过程
(3) 然后将这张伪造的图片和一些真实的图片喂给判别器(真实的图片的标签为“真”,伪造的图片的标签为“假”),让判别器区分哪些图片是真实的,哪些图片上是假的,选择的网络可以是常见的二分类CNN
(4) 训练判别器就是简单的二分类问题;在训练生成器时,修改伪造图片的标签(使其为“真”),并固定判别器的参数,按照损失函数梯度方向只更新生成器的参数。这只会更新生成器的权重(只更新生成器的权重,因为判别器在GAN中被冻结),其更新方向是使得判别器能够将生成图像预测为“真实图像”。这个过程是训练生成器去欺骗判别器。
《Python深度学习》中DCGAN的部分核心代码,如下(虚假图像标签为1,真实为0)

最核心的是在训练生成器的时候,将虚假的图像标签设定为0(0表示真实图片),然后和真实的图片放在一起作为判别器的输入,更新参数时候不去更新判别器,只更新生成器的。
实验
数据集:
- LSUN
Large-scale Scene Understanding,该数据集是指在计算机视觉领域中,对大规模、复杂场景中的物体、结构、关系和语义进行理解和分析的任务。这涉及从图像或视频数据中提取高层次的语义信息,以实现对场景的深入理解。
- Faces
作者从随机查询人名的网络图像中提取包含人脸的图像。这些人的名字是从百科全书中获得的,选取标准是他们必须出生在现代。
这个数据集有来自10K个人的3M张图像。我们在这些图像上运行了一个OpenCV人脸检测器,保持了足够高的分辨率,这给了我们大约35万个人脸盒。我们用这些脸盒来训练。未对图像进行数据增强。
- Imagenet-1k
ImageNet-1K" 是指 ImageNet 数据集中的一个子集,其中包含了大约 1000 个不同的类别,每个类别都有一些图像样本。ImageNet 数据集是一个广泛用于计算机视觉任务的大规模图像数据集,它包含了来自各种类别的图像,用于训练和评估深度学习模型。
实证验证:
- CIFAR-10
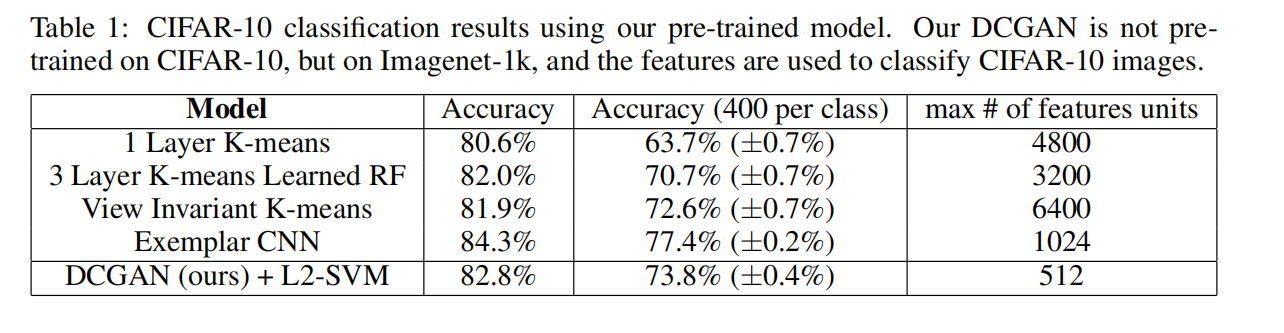
CIFAR-10(Canadian Institute for Advanced Research 10)是一个经常用于计算机视觉研究的图像数据集,由10个不同的类别组成,每个类别有6000张尺寸为 32x32 像素的彩色图像。这个数据集旨在为图像分类和目标识别任务提供一个基准测试平台。
通过表一,我们可以看到DCGAN的准确率打败了使用K-means聚类的相关算法,略逊于CNN,不过作者的DCGAN是基于IMAGENET-1K做的预训练,然后在CIFAR-10上训练得到的结果,从另一个角度可见泛化能力。
- SVHN
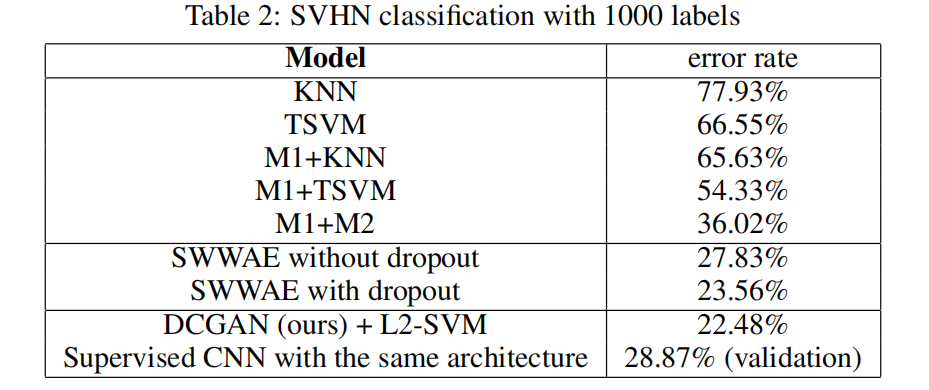
SVHN(Street View House Numbers)是一个用于数字识别任务的图像数据集,其主要用途是识别街道上的房屋号码。这个数据集包含了来自Google街景图像的房屋号码图像,可以用于训练和评估数字识别模型。
很明显,表二显示的错误率最低的是DCGAN+L2-SVM,这里的DCGAN相当于是一个特征提取器,然后将学到的特征处理后给L2-SVM,让L2-SVM进行分类。
SWWAE(stacked what-where auto-encoders),更准确的说是一种 convolutional auto-encoder,因为在CNN中的pooling处才有 “what-where”,而what-where是注意力机制的体现,有助于增强模型对图像中物体的感知能力,并在物体检测、图像分割等任务中取得更好的结果。相关信息参考原论文
总结
DCGAN 在图像生成任务中取得了显著的成功,其关键思想包括:
- 卷积层和反卷积层: DCGAN使用卷积层作为生成器和判别器的主要构建块。生成器使用反卷积层(也称为转置卷积层)来将低维的随机噪声转化为高分辨率图像。
- 无池化(Unpooling): DCGAN避免了池化操作,转而使用反卷积层来实现上采样。这有助于避免图像中的信息丢失。
- 批量归一化(Batch Normalization): DCGAN引入了批量归一化来加速训练过程并提高稳定性。它有助于控制梯度消失问题,使网络更易于训练。
- 去除全连接层: 与传统的GAN不同,DCGAN将全连接层从生成器和判别器中移除,这有助于避免模型过拟合和提高生成图像的质量。
- 激活函数和损失函数: 生成器使用ReLU激活函数,输出层使用tanh激活函数以获得适当的像素范围。判别器使用LeakyReLU激活函数。损失函数通常使用二进制交叉熵,帮助优化生成器和判别器之间的对抗性训练。
对原始的GAN做了一些优化,但是并不彻底,在文章结论部分,作者提到“我们提出了一套更稳定的架构来训练生成对抗网络,并提供证据表明对抗网络可以学习良好的图像表示,以进行监督学习和生成建模。仍然存在某些形式的模型不稳定 ——随着模型训练时间的延长,它们有时会将滤波器的子集折叠为单一振荡模式。”
化,但是并不彻底,在文章结论部分,作者提到“我们提出了一套更稳定的架构来训练生成对抗网络,并提供证据表明对抗网络可以学习良好的图像表示,以进行监督学习和生成建模。仍然存在某些形式的模型不稳定 ——随着模型训练时间的延长,它们有时会将滤波器的子集折叠为单一振荡模式。”
后续,有学者提出Wasserstein 距离,对GAN的训练不稳定提出了更好的解决方案。
- 深度学习展示 ...
赞
踩

