
热门标签
当前位置: article > 正文
kafka基本使用及结合Java使用_java kafka
作者:小蓝xlanll | 2024-04-14 05:59:44
赞
踩
java kafka
一、Kafka介绍
Kafka是一个分布式、支持分区、多副本的消息系统,最大特点是实时处理大量数据以满足各种需求场景。它可以用于日志收集、消息系统、用户活动跟踪、运营指标等。Kafka是用Scala语言编写的,于2010年贡献给了Apache基金会并成为顶级开源项目。
1.Kafka的使用场景
- 实时数据流处理:Kafka可以接收和传递实时数据,使得数据可以在各种系统或应用之间进行实时通信。
- 日志收集:Kafka可以用于收集各种服务的日志,使得这些日志可以集中存储和分析。
- 事件驱动架构:通过将事件发布到Kafka主题,可以触发各种事件处理程序,构建事件驱动的系统。
- 缓存数据:Kafka可以作为缓存数据的存储,提供高吞吐量的读取服务。
- 数据管道:Kafka可以用于将数据从一个系统传输到另一个系统,实现数据同步和集成。
由于Kafka的高吞吐量、可扩展、可靠和分布式等特点,它在很多大型的互联网应用中得到广泛的应用。
2.Kafka基本概念
Kafka是一个分布式的、分区的消息服务,提供了消息系统应该具备的功能。它借鉴了JMS规范的思想,但是并没有完全遵循JMS规范。JMS是一种类似于JDBC对于数据库的,对于Java调用消息队列的接口规范。
Kafka主要用于处理实时数据流,提供高吞吐量、可扩展、可靠和分布式的数据处理能力。
首先,让我们来看一下基础的消息(Message)相关术语:
- 主题(Topic):Kafka将消息分为不同的主题。每个主题都是消息的分类,消息发布到特定的主题。
- 生产者(Producer):生产者负责将消息发送到Kafka。它可以将消息发送到任何可用的Kafka代理,并使用特定的主题。
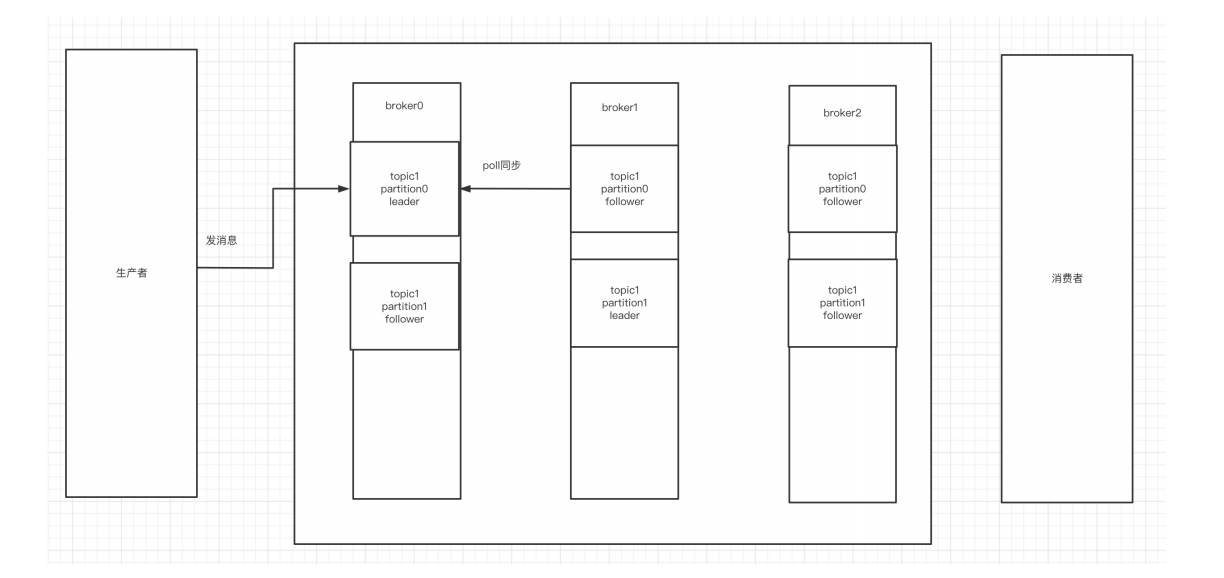
- 代理(Broker):消息中间件处理节点,⼀个Kafka节点就是⼀个broker。代理是Kafka服务的核心,它们提供对Kafka集群的接口。Kafka集群由一个或多个代理组成。
- 消费者(Consumer):消费者从Kafka中读取消息。它可以订阅一个或多个主题,并按照订阅的顺序处理消息。
- 分区(Partition):为了实现可扩展性和容错性,Kafka将每个主题分为多个分区。每个分区都是一个独立的消息队列,消息按照它们到达的时间顺序存储。
- 副本(Replica):Kafka提供副本机制来保证数据的安全性。每个分区都有一定数量的副本,分布在不同的代理上。
- 消费者组(ConsumerGroup):每个Consumer属于⼀个特定的Consumer Group,⼀条消息可以被多个不同的Consumer Group消费,但是⼀个Consumer Group中只能有⼀个Consumer能够消费该消息。
因此,从一个较高的层面上来看,producer通过网络发送消息到Kafka集群,然后consumer 来进行消费,如下图:
服务端(brokers)和客户端(producer、consumer)之间通信通过 TCP协议 来完成。
二、kafka基本使用
1.安装
- 安装jdk
- 安装zk
ZooKeeper主要服务于分布式系统,可以用ZooKeeper来做:统一配置管理、统一命名服务、分布式锁、集群管理。 使用分布式系统就无法避免对节点管理的问题(需要实时感知节点的状态、对节点进行统一管理等等),而由于这些问题处理起来可能相对麻烦和提高了系统的复杂性,ZooKeeper作为一个能够通用解决这些问题的中间件就应运而生了。
在云服务器上使用docker安装Kafka:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小蓝xlanll/article/detail/420511
推荐阅读

相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

