
- 1LeetCode 27题 移除元素 -- JavaScript_leecode移除元素
- 2Simulink 快速入门(二)--创建简单模型_simulink模型
- 32、SQL学习:排序查询and分组查询_分组排序查询
- 4AI大模型低成本快速定制秘诀:RAG和向量数据库_rag和向量库的关系
- 5python-使用scikit-learn工具计算文本TF-IDF值_python sklearn tf-idf
- 6mysql 将date字段默认值设置为CURRENT_DATE_mysql date 默认设置成当前时间
- 7Atlas 200I DK A2(小藤) 开箱_atlas200
- 8MySQL的指令大全和注意事项(强烈推荐收藏)_mysql命令语句大全
- 9视频码率
- 10postgresql 语句_postgresql 循环
ViT再升级!9个视觉transformer最新改进方案让性能飞跃_vision transformer 改进
赞
踩
通过优化ViT结构和训练策略,我们可以提高模型的性能和计算效率,增强模型对局部信息的捕捉能力。同时解决一些原有模型存在的问题。
比如原始的ViT模型在处理高分辨率图像时,由于自注意力机制的计算复杂度与序列长度相关,会导致较高的计算成本。通过对ViT进行改进,我们就可以减少参数量和计算量。
这类改进不仅能够更高效地处理图像数据,同时还能增强ViT在各种视觉任务中的适用性。因此,为了让模型更加高效和适用于实际应用,研究者们已经提出不少值得学习的ViT改进方案。比如基于全新残差注意力机制的ReViT。
本文介绍9种最新的ViT改进方案,配套模型与开源代码都整理了,希望可以为同学们提供新的思路和方法。
论文和代码需要的同学看文末
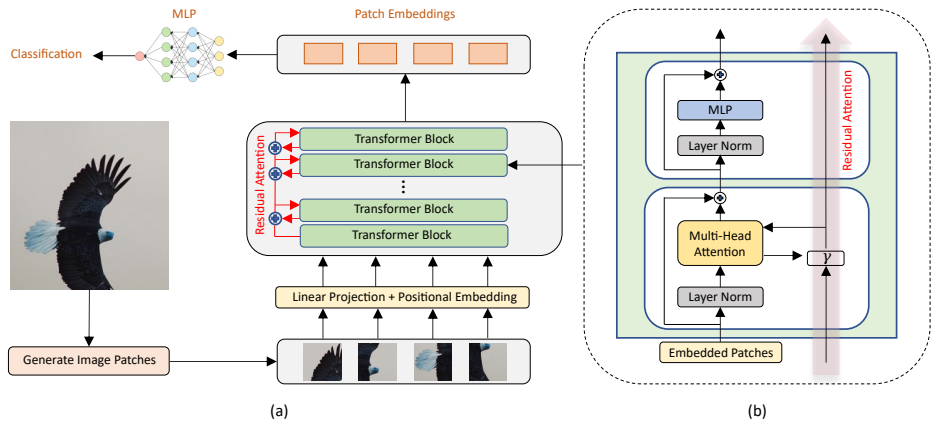
ReViT
ReViT: Enhancing Vision Transformers with Attention Residual Connections for Visual Recognition
方法:论文引入了一种创新的残余注意力视觉变换器(ReViT)网络,通过将残余注意力学习整合到视觉变换器(ViT)架构中,来增强对视觉特征的提取。该方法有效地传输和累积来自查询和键的注意力信息,跨越连续的多头自注意力(MHSA)层。这种残余连接防止了低级视觉特征的减少。此外,它通过减缓注意力机制的全球化,在学习新特征时赋予模型利用先前提取的特征的能力。
创新点:
-
基于残差注意力模块的ViT架构:引入了一种新颖的ViT架构,利用残差注意力模块将重要的低层视觉特征融入到学习表示中,同时保持提取全局上下文的能力,从而增强了网络深层中的特征多样性。
-
残差注意力对ViT的鲁棒性增强:通过对Oxford Flowers-102和Oxford-IIIT Pet数据集上的图像分类任务进行综合评估,以实验证明残差注意力提高了ViT对平移不变性的鲁棒性。
ExMobileViT
ExMobileViT: Lightweight Classifier Extension for Mobile Vision Transformer
方法:论文提出了一种通过多尺度特征聚合(MSFA)或特征金字塔网络(FPN)来提取各种数据特征的大型模型。作者使用轻量级模型对MobileViT进行扩展,以直接通过快捷方式为分类器进行通道扩展。然而,由于ViT需要大量的计算资源和存储需求,因此提出了MobileViT来兼具ViT的优势和MobileNet的卷积结构的优点。
创新点:
-
使用早期注意力阶段的信息来增强MobileViT的性能:作者提出了一种结构来存储和重复使用早期注意力阶段的信息,以提高最终分类器的性能。通过使用来自早期注意力阶段的不同尺度特征的平均池化结果来扩展最终分类器中的通道,从而引入归纳偏差,以增强最终性能。
-
引入ExShortcut来补充注意力型ViT的归纳偏差不足:为了补充注意力型ViT的归纳偏差不足,作者将CNN引入到模型中,以编码局部信息。通过将各个尺度的特征图的输出存储和重复使用,可以从各个尺度的特征图中提取数据。在这种模型中,直接传入分类器的快捷方式被称为ExShortcut。使用ExShortcut可以直接传入模型的局部特征和全局特征一起进行训练。

MPTQ-ViT
MPTQ-ViT: Mixed-Precision Post-Training Quantization for Vision Transformer
方法:论文介绍了一种新颖的混合精度后训练量化方案MPTQ-ViT。MPTQ-ViT结合了SQ-b用于对称分布、OPT-m用于数据相关的SFs和Greedy MP用于逐层分配BW。实验结果表明,所提出的方法在SP和MP下达到了SOTA性能。
创新点:
-
提出了MPTQ-ViT,这是一种新颖的混合精度后训练量化方案,用于ViTs。MPTQ-ViT结合了SQ-b对称分布、OPT-m数据相关SF和Greedy MP逐层BW分配。
-
SQ-b和OPT-m方法相较于现有方法在4位SP情境下提高了0.90%至23.35%的准确率,验证了通过SQ-b增强数据对称性和通过OPT-m部署数据相关SF的有效性。

ViTAEv2
ViTAEv2: Vision Transformer Advanced by Exploring Inductive Bias for Image Recognition and Beyond
方法:本文提出了ViTAE和ViTAEv2模型,并对其进行了多种变体的比较实验。通过引入局部窗口注意力和多阶段设计,这些模型在图像分类任务以及目标检测、语义分割和姿态估计等下游视觉任务上表现出色。研究结果表明,引入固有的归纳偏置可以提高大规模视觉变换器模型的性能和数据效率。进一步的实验分析也证明了这些模型的模块设计、推理速度、内存占用和与最新研究的比较等方面的优势。
创新点:
-
作者提出了ViTAE模型,它是一种将Transformer应用于图像任务的方法。相较于之前的ViT模型,ViTAE在建模局部视觉结构方面引入了归纳偏差,提高了分类性能。
-
作者进一步将ViTAE模型扩展为多阶段设计的ViTAEv2模型。通过在不同阶段使用不同类型的注意力机制,ViTAEv2在分类性能和计算成本之间取得了良好的平衡。
-
作者通过实验证明,使用局部窗口注意力机制的ViTAEv2模型在不同图像分辨率下具有优异的分类性能和较低的内存占用,比其他设计更具优势。
关注下方《学姐带你玩AI》
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

