
- 1Android App开发的自动化测试框架UI Automator使用教程_uiautomator 教程
- 2MySQL Navicat 12安装及使用教程_官网下载navicat for mysql 12
- 3AI实践与学习1_NLP文本特征提取以及Milvus向量数据库实践_clip 多模态大模型 milvus
- 4Hive行转列[一行拆分成多行/一列拆分成多列]_hive 中将一行数据按分隔符拆分成多行
- 5使用BERT做中文文本相似度计算与文本分类_bert中文文本相似度计算与文本分类
- 6R语言 多组堆砌图_多样本堆砌图
- 7web3项目自动连接小狐狸以及小狐狸中的各种“地址”详解_web3js 验证小狐狸钱包是否已给地址
- 8Netlify前端自动化部署工具
- 9【小余送书第二期】《MLOps工程实践:工具、技术与企业级应用》参与活动,即有机会中奖哦!!!祝各位铁铁们双节快乐!_mlops工程实践:工具、技术与企业级应用pdf
- 10ruoyi-nbcio版本从RuoYi-Flowable-Plus迁移过程记录_core-js/modules/web.url-search-params.delete.js
人人都能看懂的DDPM加噪公式推导_ddpm公式介绍
赞
踩
本文是作者对DDPM的一些个人理解,可能有理解错误的地方,欢迎评论指正。在网上也搜索了很多人写的文章,都是相互抄袭,或者是通篇公式。符号一大堆,不理解作者为什么要这样设置参数,不理解内在动机。
本文尝试以笔者自己的观点去理解推导公式,隐含着笔者对作者动机的猜测,可能不够准确,但是对于理解来说非常有用。首先看下面这张图,相信大家对加噪和去噪过程容易理解。我简单描述一下:
加噪过程:分为T步,每步在上一次加完噪的基础上,从正态分布中随机采样噪声加入。
降噪过程:与加噪过程相反,不再赘述。
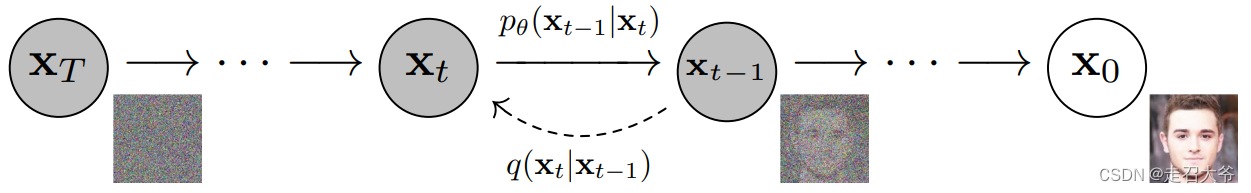
最近看到一个巨牛的人工智能教程,分享一下给大家。教程不仅是零基础,通俗易懂,而且非常风趣幽默,像看小说一样!觉得太牛了,所以分享给大家。平时碎片时间可以当小说看,【点这里可以去膜拜一下大神的“小说”】。
先给出DDPM最终公式:
- α t + β t = 1 \alpha_t +\beta_t=1 αt+βt=1,其中 β t \beta_t βt 是正态分布方差,即第 t t t 步产生的噪声从 N ( 0 , β t ) N(0,\beta_t) N(0,βt) 采样。
- X t = α ‾ t X 0 + 1 − α ‾ t z t X_t = \sqrt{\overline{\alpha}_t} X_0 + \sqrt{1- \overline{\alpha}_t}z_t Xt=αt X0+1−αt zt,其中 X t X_t Xt表示第t步加噪后的图像, X 0 X_0 X0表示初始图像。 α ‾ t = α t α t − 1 α t − 2 . . . α 1 \overline{\alpha}_t = \alpha_t\alpha_{t-1}\alpha_{t-2}...\alpha_1 αt=αtαt−1αt−2...α1, z t z_t zt ~ N ( 0 , 1 ) N(0, 1) N(0,1)
因此只需确定N步加噪中的每一步的噪点采样方差,就能一步实现叠加N随机噪声。
0 数学知识
对于DDPM加噪过程,其实只需一个公式:
如果 x x x ~ N ( 0 , 1 ) N(0, 1) N(0,1),那么, a x ax ax ~ N ( 0 , a 2 ) N(0, a^2) N(0,a2)
1 前向公式推导
1.1 噪点采样分布
噪点从正态分布中采样,那么,如何确定正态分布的均值和方差?
- 均值: u u u。理论上可以取任意值,但是考虑到让添加到图像上,希望噪点值有正有负,因此取 u = 0 u=0 u=0是最合适的,因为可以保证正负概率相同。
- 方差: σ 2 \sigma^2 σ2。理论上可以取任意值,这里我们不具体设置值。
第 t t t 次往图像上添加正态分布噪点 Z t Z_t Zt,则 Z t Z_t Zt ~ N ( 0 , σ t 2 ) N(0, \sigma_t^2) N(0,σt2)。令 Z t = σ t z t Z_t=\sigma_t z_t Zt=σtzt,通过正态分布性质可知: z t z_t zt~ N ( 0 , 1 ) N(0, 1) N(0,1)
因此,只需从标准正态分布采样 z t z_t zt,然后乘以 σ t \sigma_t σt 即可得到 Z t Z_t Zt
1.2如何添加噪声
第
t
t
t 步加噪后的图像
X
t
X_t
Xt是在第
t
−
1
t-1
t−1 步得到的图像
X
t
−
1
X_{t-1}
Xt−1基础上加噪点
Z
t
Z_t
Zt。即:
X
t
=
a
t
X
t
−
1
+
b
t
Z
t
X_t = a_tX_{t-1} + b_tZ_t
Xt=atXt−1+btZt
其中,
a
t
a_t
at 和
b
t
b_t
bt 为第
t
t
t 步的两个常数系数。
Z
t
Z_t
Zt替换成
σ
t
z
t
\sigma_tz_t
σtzt,得:
X
t
=
a
t
X
t
−
1
+
b
t
σ
t
z
t
X_t = a_t X_{t-1} + b_t\sigma_t z_t
Xt=atXt−1+btσtzt
其中
b
t
σ
t
z
t
b_t\sigma_t z_t
btσtzt ~
N
(
0
,
b
t
2
σ
t
2
)
N(0, b_t^2\sigma_t ^2)
N(0,bt2σt2),即,方差为
b
t
2
σ
t
2
b_t^2\sigma_t ^2
bt2σt2的正态分布。不妨令
β
t
=
b
t
2
σ
t
2
\beta_t = b_t^2\sigma_t ^2
βt=bt2σt2,那么:
X
t
=
a
t
X
t
−
1
+
β
t
z
t
X_t = a_t X_{t-1} + \sqrt{\beta_t}z_t
Xt=atXt−1+βt
zt
可以如下递推:
X
t
=
a
t
X
t
−
1
+
β
t
z
t
=
a
t
(
a
t
−
1
X
t
−
2
+
β
t
−
1
z
t
−
1
)
+
β
t
z
t
=
a
t
a
t
−
1
X
t
−
2
+
a
t
β
t
−
1
z
t
−
1
+
β
t
z
t
=
a
t
a
t
−
1
(
a
t
−
2
X
t
−
3
+
β
t
−
2
z
t
−
2
)
+
a
t
β
t
−
1
z
t
−
1
+
β
t
z
t
=
a
t
a
t
−
1
a
t
−
2
X
t
−
3
+
a
t
a
t
−
1
β
t
−
2
z
t
−
2
+
a
t
β
t
−
1
z
t
−
1
+
β
t
z
t
=
(
a
t
a
t
−
1
a
t
−
2
.
.
.
a
1
)
X
0
+
(
a
t
a
t
−
1
.
.
.
a
2
)
β
1
z
1
+
.
.
.
+
a
t
a
t
−
1
β
t
−
2
z
t
−
2
+
a
t
β
t
−
1
z
t
−
1
+
β
t
z
t
Xt=atXt−1+√βtzt=at(\textcolorredat−1Xt−2+√βt−1zt−1)+√βtzt=atat−1Xt−2+at√βt−1zt−1+√βtzt=atat−1(\textcolorredat−2Xt−3+√βt−2zt−2)+at√βt−1zt−1+√βtzt=atat−1at−2Xt−3+atat−1√βt−2zt−2+at√βt−1zt−1+√βtzt=(atat−1at−2...a1)X0+\textcolorgreen(atat−1...a2)√β1z1+...+atat−1√βt−2zt−2+at√βt−1zt−1+√βtzt
上式绿色部分,每一项都是独立的正态分布,且均值为0,方差为各自系数的平方。根据正态分布叠加公式,它们的和也服从正态分布,且均值为0,方差为各项方差之和。
因此上式绿色部分的方差为:
( a t a t − 1 . . . a 2 ) 2 β 1 + ( a t a t − 1 . . . a 3 ) 2 β 2 + . . . + a t 2 a t − 1 2 β t − 2 + a t 2 β t − 1 + β t (a_ta_{t-1}...a_2)^2\beta_1+(a_ta_{t-1}...a_3)^2\beta_2+... +a_t^2a_{t-1}^2\beta_{t-2} +a_t^2\beta_{t-1} + \beta_t (atat−1...a2)2β1+(atat−1...a3)2β2+...+at2at−12βt−2+at2βt−1+βt
前面有提到: a t a_t at 和 b t b_t bt 为第 t t t 步的两个常数系数, β t \beta_t βt与 b t b_t bt是一个概念, β t \beta_t βt也是个常数系数。
为了便于计算,令 a t = 1 − β t a_t = \sqrt{1-\beta_t} at=1−βt ,即, a t 2 + β t = 1 a_t^2 +\beta_t=1 at2+βt=1,上式为:
( a t a t − 1 . . . a 2 ) 2 β 1 + ( a t a t − 1 . . . a 3 ) 2 β 2 + . . . + a t 2 a t − 1 2 β t − 2 + a t 2 β t − 1 + β t = ( a t a t − 1 . . . a 2 ) 2 ( 1 − a 1 2 ) + ( a t a t − 1 . . . a 3 ) 2 ( 1 − a 2 2 ) + . . . + a t 2 a t − 1 2 ( 1 − a t − 2 2 ) + a t 2 ( 1 − a t − 1 2 ) + ( 1 − a t 2 ) = ( a t a t − 1 . . . a 2 ) 2 − ( a t a t − 1 . . . a 1 ) 2 + ( a t a t − 1 . . . a 3 ) 2 − ( a t a t − 1 . . . a 2 ) 2 + . . . + ( a t a t − 1 ) 2 − ( a t a t − 1 a t − 2 ) 2 + a t 2 − a t 2 a t − 1 2 + 1 − a t 2 = 1 − ( a t a t − 1 . . . a 1 ) 2 (atat−1...a2)2β1+(atat−1...a3)2β2+...+a2ta2t−1βt−2+a2tβt−1+βt=(atat−1...a2)2(\textcolorred1−a21)+(atat−1...a3)2(\textcolorgreen1−a22)+...+a2ta2t−1(\textcolorblue1−a2t−2)+a2t(\textcolorcyan1−a2t−1)+(\textcolormagenta1−a2t)=\textcolorred(atat−1...a2)2−(atat−1...a1)2+\textcolorgreen(atat−1...a3)2−(atat−1...a2)2+...+\textcolorblue(atat−1)2−(atat−1at−2)2+\textcolorcyana2t−a2ta2t−1+\textcolormagenta1−a2t=\textcolormagenta1\textcolorred−(atat−1...a1)2
(atat−1...a2)2β1+(atat−1...a3)2β2+...+at2at−12βt−2+at2βt−1+βt=(atat−1...a2)2(1−a12)+(atat−1...a3)2(1−a22)+...+at2at−12(1−at−22)+at2(1−at−12)+(1−at2)=(atat−1...a2)2−(atat−1...a1)2+(atat−1...a3)2−(atat−1...a2)2+...+(atat−1)2−(atat−1at−2)2+at2−at2at−12+1−at2=1−(atat−1...a1)2
即:
X
t
=
(
a
t
a
t
−
1
a
t
−
2
.
.
.
a
1
)
X
0
+
1
−
(
a
t
a
t
−
1
.
.
.
a
1
)
2
z
t
X_t = (a_ta_{t-1}a_{t-2}...a_1)X_0 + \sqrt{1-(a_ta_{t-1}...a_1)^2}z_t
Xt=(atat−1at−2...a1)X0+1−(atat−1...a1)2
zt
其中,
z
t
z_t
zt ~
N
(
0
,
1
)
N(0, 1)
N(0,1),令
a
t
‾
=
a
t
a
t
−
1
a
t
−
2
.
.
.
a
1
\overline{ a_t}=a_t a_{t-1} a_{t-2}...a_1
at=atat−1at−2...a1,那么:
X
t
=
a
t
‾
X
0
+
1
−
a
t
‾
2
z
t
X_t = \overline{ a_t}X_0 + \sqrt{1-\overline{ a_t}^2}z_t
Xt=atX0+1−at2
zt
1.3 对齐论文
注意,在DDPM 论文中,给出的由
X
0
X_0
X0生成
X
t
X_t
Xt公式如下:
q
(
x
t
∣
x
0
)
=
N
(
x
t
;
α
t
‾
x
0
,
(
1
−
α
t
‾
)
I
)
q(x_t|x_0) = N (x_t;\sqrt{\overline{\alpha_t}}x_0, (1-\overline{\alpha_t})I )
q(xt∣x0)=N(xt;αt
x0,(1−αt)I)
翻译一下就是
X
t
X_t
Xt服从均值为
α
t
‾
x
0
\sqrt{\overline{\alpha_t}}x_0
αt
x0,方差为
(
1
−
α
t
‾
)
(1-\overline{\alpha_t})
(1−αt)的正态分布。进一步标准化即:
x
t
=
α
t
‾
x
0
+
1
−
α
t
‾
z
t
x_t = \sqrt{\overline{ \alpha_t}}x_0 + \sqrt{1-\overline{ \alpha_t}}z_t
xt=αt
x0+1−αt
zt
其中,
z
t
z_t
zt ~
N
(
0
,
1
)
N(0, 1)
N(0,1)
注意到,本文推导出来的公式与论文稍微有些区别,但是本质是一样的。前面1.2小节我们得到两个公式:
- a t 2 + β t = 1 a_t^2 +\beta_t=1 at2+βt=1,其中 β t \beta_t βt 是正态分布方差,即第 t t t 步噪声从 N ( 0 , β t ) N(0,\beta_t) N(0,βt) 采样。
- X t = ( a t a t − 1 a t − 2 . . . a 1 ) X 0 + 1 − ( a t a t − 1 . . . a 1 ) 2 z t X_t = (a_ta_{t-1}a_{t-2}...a_1)X_0 + \sqrt{1-(a_ta_{t-1}...a_1)^2}z_t Xt=(atat−1at−2...a1)X0+1−(atat−1...a1)2 zt
为了对齐论文,我们把符号稍微调整。令 α t = a t 2 \alpha_t=a_t^2 αt=at2,则有:
- α t + β t = 1 \alpha_t +\beta_t=1 αt+βt=1,其中 β t \beta_t βt 是第 t t t 步噪声从 N ( 0 , β t ) N(0,\beta_t) N(0,βt) 采样。
- X t = α t α t − 1 α t − 2 . . . α 1 X 0 + 1 − α t α t − 1 . . . α 1 z t X_t = \sqrt{\alpha_t\alpha_{t-1}\alpha_{t-2}...\alpha_1} X_0 + \sqrt{1- \alpha_t\alpha_{t-1}...\alpha_1}z_t Xt=αtαt−1αt−2...α1 X0+1−αtαt−1...α1 zt
令
α
‾
t
=
α
t
α
t
−
1
α
t
−
2
.
.
.
α
1
\overline{\alpha}_t = \alpha_t\alpha_{t-1}\alpha_{t-2}...\alpha_1
αt=αtαt−1αt−2...α1,则有
X
t
=
α
‾
t
X
0
+
1
−
α
‾
t
z
t
X_t = \sqrt{\overline{\alpha}_t} X_0 + \sqrt{1- \overline{\alpha}_t}z_t
Xt=αt
X0+1−αt
zt
1.3 小结
目前为止,得到如下两个公式:
- α t + β t = 1 \alpha_t +\beta_t=1 αt+βt=1,其中 β t \beta_t βt 是正态分布方差,即第 t t t 步产生的噪声从 N ( 0 , β t ) N(0,\beta_t) N(0,βt) 采样。
- X t = α ‾ t X 0 + 1 − α ‾ t z t X_t = \sqrt{\overline{\alpha}_t} X_0 + \sqrt{1- \overline{\alpha}_t}z_t Xt=αt X0+1−αt zt,其中 α ‾ t = α t α t − 1 α t − 2 . . . α 1 \overline{\alpha}_t = \alpha_t\alpha_{t-1}\alpha_{t-2}...\alpha_1 αt=αtαt−1αt−2...α1, z t z_t zt ~ N ( 0 , 1 ) N(0, 1) N(0,1)
2 代码实现
代码实现这里我们首先分析diffusers库里实现的scheduling_ddpm源码,下一篇文章手撕代码实现,敬请关注。从上面公式推理分析过程大概可以总结实现步骤如下:
- 确定总的步数
num_train_timesteps - 按照某种策略,确定第t步的噪音采样的方差 β t \beta_t βt
- 计算 α t ‾ = α t α t − 1 α t − 2 . . . α 1 \overline{\alpha_t}=\alpha_t\alpha_{t-1}\alpha_{t-2}...\alpha_1 αt=αtαt−1αt−2...α1,即 α t ‾ = ( 1 − β t ) ( 1 − β t − 1 ( 1 − β t − 2 ) . . . ( 1 − β 1 ) \overline{\alpha_t}=(1-\beta_t)(1-\beta_{t-1}(1-\beta_{t-2})...(1-\beta_1) αt=(1−βt)(1−βt−1(1−βt−2)...(1−β1)
- 计算第 t t t 步加噪后的图像 X t = α t ‾ X 0 + 1 − α t ‾ z t X_t = \sqrt{\overline{\alpha_t}}X_0 + \sqrt{1-\overline{\alpha_t}}z_t Xt=αt X0+1−αt zt
分析diffusers库实现的scheduling_ddpm源码,源码地址https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddpm.py
对应上述的4步,我们从源码中找到对应的实现。首先在__init__函数中实现如下几步:
1. 确定总步数num_train_timesteps,作为参数传入到函数__init__中(下面代码第3行):
def __init__(
self,
num_train_timesteps: int = 1000, # 总步数
beta_start: float = 0.0001, # 方差beta的最小值
beta_end: float = 0.02, # 方差beta的最大值
beta_schedule: str = "linear",
...其他参数略
):
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2. 按照某种策略,确定第t步的噪音采样的方差
β
t
\beta_t
βt ,这一步依然在函数__init__中实现:
if trained_betas is not None: # 如果直接传递方差beta,那就直接用 self.betas = torch.tensor(trained_betas, dtype=torch.float32) elif beta_schedule == "linear": # 线性生成策略,从最小到最大值,等间距采样作为每一步的方差。 self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32) elif beta_schedule == "scaled_linear": # this schedule is very specific to the latent diffusion model. self.betas = ( torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2 ) elif beta_schedule == "squaredcos_cap_v2": # Glide cosine schedule self.betas = betas_for_alpha_bar(num_train_timesteps) elif beta_schedule == "sigmoid": # GeoDiff sigmoid schedule betas = torch.linspace(-6, 6, num_train_timesteps) self.betas = torch.sigmoid(betas) * (beta_end - beta_start) + beta_start else: raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
此时可以得到每一步的采样方差,存放在self.betas属性中。
3. 计算
α
t
‾
=
(
1
−
β
t
)
(
1
−
β
t
−
1
(
1
−
β
t
−
2
)
.
.
.
(
1
−
β
1
)
\overline{\alpha_t}=(1-\beta_t)(1-\beta_{t-1}(1-\beta_{t-2})...(1-\beta_1)
αt=(1−βt)(1−βt−1(1−βt−2)...(1−β1),这一步依然在函数__init__中实现:
self.alphas =1.0 - self.betas
self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
self.one = torch.tensor(1.0)
- 1
- 2
- 3
注意,上面代码属性self.alphas相当于本文中的
α
t
2
\alpha_t^2
αt2,因为他这里计算的是
1
−
β
t
1-\beta_t
1−βt,还没开根号。另外,这里是一次性计算了所有步的
α
t
2
\alpha_t^2
αt2。
这里调用了torch.cumprod函数,此函数是计算当前位置前面所有元素相乘。说的抽象,以一个具体例子说明:
>>> a = torch.randn(10)
>>> a
tensor([ 0.6001, 0.2069, -0.1919, 0.9792, 0.6727, 1.0062, 0.4126,
-0.2129, -0.4206, 0.1968])
>>> torch.cumprod(a, dim=0)
tensor([ 0.6001, 0.1241, -0.0238, -0.0233, -0.0157, -0.0158, -0.0065,
0.0014, -0.0006, -0.0001])
>>> a[5] = 0.0
>>> torch.cumprod(a, dim=0)
tensor([ 0.6001, 0.1241, -0.0238, -0.0233, -0.0157, -0.0000, -0.0000,
0.0000, -0.0000, -0.0000])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
因此,这里self.alphas_cumprod属性相当于是本文中的
α
t
‾
\overline{\alpha_t}
αt
4. 计算第 t t t 步加噪后的图像 X t X_t Xt
公式:
X
t
=
α
t
‾
X
0
+
1
−
α
t
‾
z
t
X_t = \sqrt{\overline{\alpha_t}}X_0 + \sqrt{1-\overline{\alpha_t}}z_t
Xt=αt
X0+1−αt
zt
这里封装到函数add_noise中:
def add_noise(
self,
original_samples: torch.FloatTensor,
noise: torch.FloatTensor,
timesteps: torch.IntTensor,
) -> torch.FloatTensor:
...略
sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5
...略
sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5
...略
noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
return noisy_samples
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
add_noise函数中,original_samples参数表示初始图片
X
0
X_0
X0。 noise参数表示从标准正态分布采样得到的噪声即
z
t
z_t
zt ;timesteps表示采样加噪step次数,注意与num_train_timesteps区分,为了提升泛化能力,在训练时,会动态设置加噪次数。接下来我们只看函数内部实现的关键代码,其他代码忽略。
重点代码解析:
sqrt_alpha_prod:相当于
α
t
‾
\sqrt{\overline{\alpha_t}}
αt
sqrt_one_minus_alpha_prod:即
1
−
α
t
‾
\sqrt{1-\overline{\alpha_t}}
1−αt
noisy_samples =
α
t
‾
∗
\sqrt{\overline{\alpha_t}}*
αt
∗ original_samples +
1
−
α
t
‾
∗
\sqrt{1-\overline{\alpha_t}}*
1−αt
∗ noise
与第1节推导公式完全一致。


