
- 1拿到字节跳动奖学金,入职字节跳动做科研,他们经历了什么?
- 2Ubuntu darknet(yolov4)标记、训练自己的数据流程记录_darknet 视频mp4检测 显示视频
- 3MySQL学习的第一天,mysql的安装费了我好大力气。问题:initializing database(may take a long time)一直报错。以及datagrip的安装破解_initializing database may take
- 4SoulPermission-Android一句话权限适配的更优解决方案_soulpermission无法获取短信权限
- 5AndrewNg机器学习编程作业python实现及心得总结_人工智能大作业python
- 62024年华为OD机试真题-螺旋数字矩阵-Python-OD统一考试(C卷)_2024年华为od机考真题螺旋数字矩阵
- 7Vue图片点击放大预览_vue图片点击放大预览代码
- 8C/C++语言typedef的用法详解以及与define的区别
- 9天工开物 #7 Rust 与 Java 程序的异步接口互操作
- 10ArduinoHTTP请求 获取任意服务器的时间_asyncudp arduino
计算机网络——HTTP协议原理_http原理
赞
踩
摘要
在日常的开发中,很多开发的同学可能很少了解的HTTP协议的底层原理。HTTP协议的底层涉及到请求响应模型,HTTP的工作流程。cookie和session的原理等。本博文主要介绍计算机网络中HTTP的相关知识。帮助大家学习和理解HTTP协议的相关原理。

一、HTTP基础原理
HTTP是HyperTextTransfer Protocol(超文本传输协议)的缩写。HTTP是一个应用层协议,由请求和响应构成,是一个标准的客户端服务器模型。HTTP是一个无状态的协议。HTTP协议通常承载于TCP协议之上,HTTPS就是也承载于TLS或SSL协议层之上。HTTP由请求和响应构成,是一个标准的客户端服务器模型(B/S)。HTTP协议永远都是客户端发起请求,服务器回送响应。HTTP协议是一个双向协议:我们在上网冲浪时,浏览器是请求方A,百度网站就是应答方B。双方约定用HTTP协议来通信,于是浏览器把请求数据发送给网站,网站再把一些数据返回给浏览器,最后由浏览器渲染在屏幕,就可以看到图片、视频了。
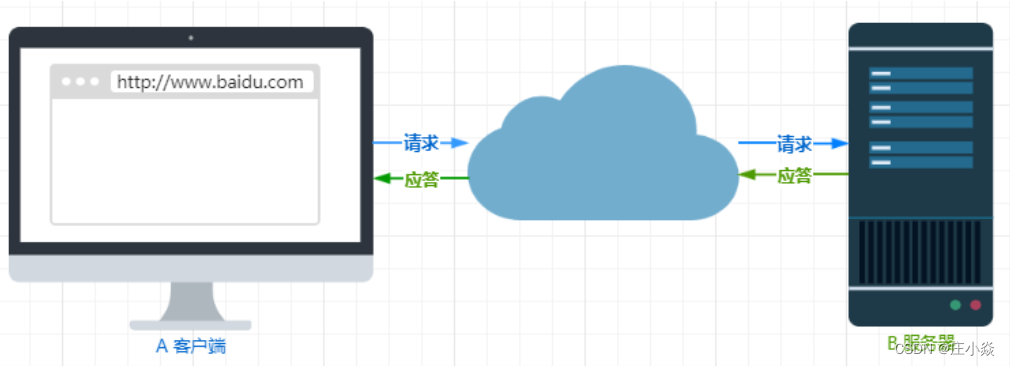
1.1 HTTP格式与报文信息

1.2 HTTP 请求报信息
1.3 HTTP包含的字段
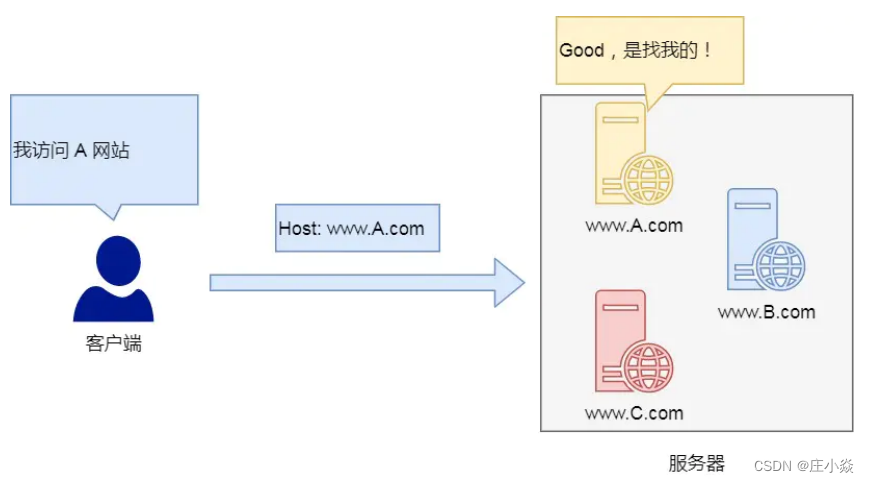
1.3.1 Host字段
客户端发送请求时,⽤来指定服务器的域名 。 有了 Host 字段,就可以将请求发往同⼀台服务器上的不同网站。
1.3.2 Content-Length 字段
服务器在返回数据时,会有 Content-Length 字段,表明本次回应的数据⻓度。 如下⾯则是告诉浏览器,本次服务器回应的数据⻓度是 1000 个字节,后⾯的字节就属于下⼀个回应了。

1.3.3 Connection 字段
Connection 字段最常⽤于客户端要求服务器使⽤ TCP 持久连接,以便其他请求复⽤ 。 HTTP/1.1 版本的默认连接都是持久连接,但为了兼容⽼版本的 HTTP,需要指定 Connection ⾸部字段的值为Keep-Alive 。⼀个可以复⽤的 TCP 连接就建⽴了,直到客户端或服务器主动关闭连接。但是,这不是标准字段。

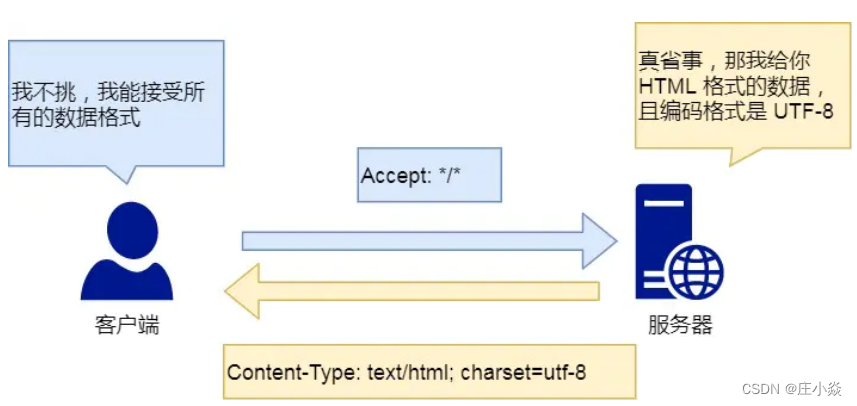
1.3.4 Content-Type 字段
Content-Type 字段⽤于服务器回应时,告诉客户端,本次数据是什么格式。
1.3.5 Content-Encoding 字段
Content-Encoding 字段说明数据的压缩⽅法。表示服务器返回的数据使⽤了什么压缩格式 。 下⾯表示服务器返回的数据采⽤了 gzip ⽅式压缩,告知客户端需要⽤此⽅式解压。 客户端在请求时,⽤ Accept-Encoding 字段说明⾃⼰可以接受哪些压缩⽅法。

二、HTTP八种请求方法
| 方法 | 作用 |
| OPTIONS(options) | 返回服务器针对特定资源所支持的HTTP请求方法,也可以利用向web服务器发送‘*’的请求来测试服务器的功能性。 |
| HEAD(head) | 向服务器索与GET请求相一致的响应,只不过响应体将不会被返回。这一方法可以再不必传输整个响应内容的情况下,就可以获取包含在响应小消息头中的元信息。 |
| GET(get) | 向特定的资源发出请求。注意:GET方法不应当被用于产生“副作用”的操作中,例如在Web Application中,其中一个原因是GET可能会被网络蜘蛛等随意访问。 |
| POST(post) | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。 Loadrunner中对应POST请求函数:web_submit_data,web_submit_form。 |
| PUT(put) | 向指定资源位置上传其最新内容。 |
| DELETE(delete) | 请求服务器删除Request-URL所标识的资源。 |
| TRACE(trace) | 回显服务器收到的请求,主要用于测试或诊断。 |
| CONNECT(connect) | HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。 |
三、HTTP的响应状态码
3.1 1xx类状态码
属于提示信息,是协议处理中的⼀种中间状态,实际⽤到的⽐较少。
3.2 2xx 类状态码
表示服务器成功处理了客户端的请求,也是我们最愿意看到的状态。
- 200 OK是最常⻅的成功状态码,表示⼀切正常。如果是⾮ HEAD 请求,服务器返回的响应头都会有 body 数据。
- 204 No Content也是常⻅的成功状态码,与 200OK 基本相同,但响应头没有 body 数据。
- 206 Partial Content是应⽤于 HTTP 分块下载或断点续传,表示响应返回的 body 数据并不是资源的全部,⽽是其中的⼀部分,也是服务器处理成功的状态。
3.3 3xx 类状态码
表示客户端请求的资源发送了变动,需要客户端⽤新的 URL 新发送请求获取资源,也就是重定向。
- 301 Moved Permanently表示永久定向,说明请求的资源已经不存在了,需改⽤新的 URL 再次访问。
- 302 Found表示临时定向,说明请求的资源还在,但暂时需要⽤另⼀个 URL 来访问。
- 301 和 302 都会在响应头⾥使⽤字段 Location ,指明后续要跳转的 URL,浏览器会⾃动᯿定向新的 URL。
- 304 Not Modified不具有跳转的含义,表示资源未修改,定向已存在的缓冲⽂件,也称缓存定向,⽤于缓存控制。
3.4 4xx 类状态码
表示客户端发送的报⽂有误,服务器⽆法处理,也就是错误码的含义。
- 400 Bad Request表示客户端请求的报⽂有错误,但只是个笼统的错误。
- 403 Forbidden表示服务器禁⽌访问资源,并不是客户端的请求出错。
- 404 Not Found表示请求的资源在服务器上不存在或未找到,所以⽆法提供给客户端。
3.5 5xx 类状态码
表示客户端请求报⽂正确,但是服务器处理时内部发⽣了错误,属于服务器端的错误码。
- 500 Internal Server Error与 400 类型,是个笼统通⽤的错误码,服务器发⽣了什么错误,我们并不知道。
- 501 Not Implemented表示客户端请求的功能还不⽀持,类似“即将开业,敬请期待”的意思。
- 502 Bad Gateway通常是服务器作为⽹关或代理时返回的错误码,表示服务器⾃身⼯作正常,访问后端服务器 发⽣了错误。
- 503 Service Unavailable表示服务器当前很忙,暂时⽆法响应服务器,类似“⽹络服务正忙,请稍后在试”的意思
- 504 GetWay timeout 表示网关超时
- 505 HTTP version not support 表示的HTTP协议不支持。
四、HTTP的三次握手原理
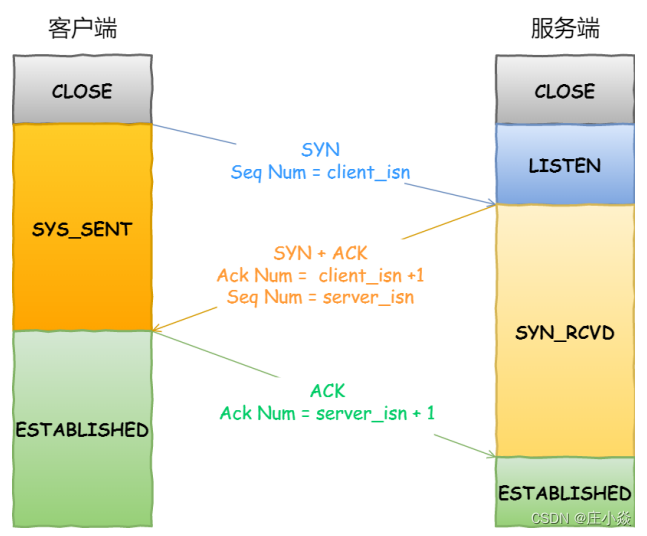
三次握手流程:
- 第一次握手:建立连接时,客户端发送syn包(syn=x)到服务器,并进入SYN_SENT状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)。
- 第二次握手:服务器收到syn包,必须确认客户的SYN(ack=x+1),同时自己也发送一个SYN包(syn=y),即SYN+ACK包,此时服务器进入SYN_RECV状态;
- 第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=y+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
为什么是三次握手?不是两次、四次?
三次握手才可以阻止重复历史连接的初始化(主要原因)
网路环境是错综复杂的,往往并不是如我们期望的⼀样,先发送的数据包,就先到达目标主机,可能会由于网路拥堵等乱七八糟的原因,会使得旧的数据包,先到达⽬标主机,那么这种情况下 TCP三次握手是如何避免的呢?
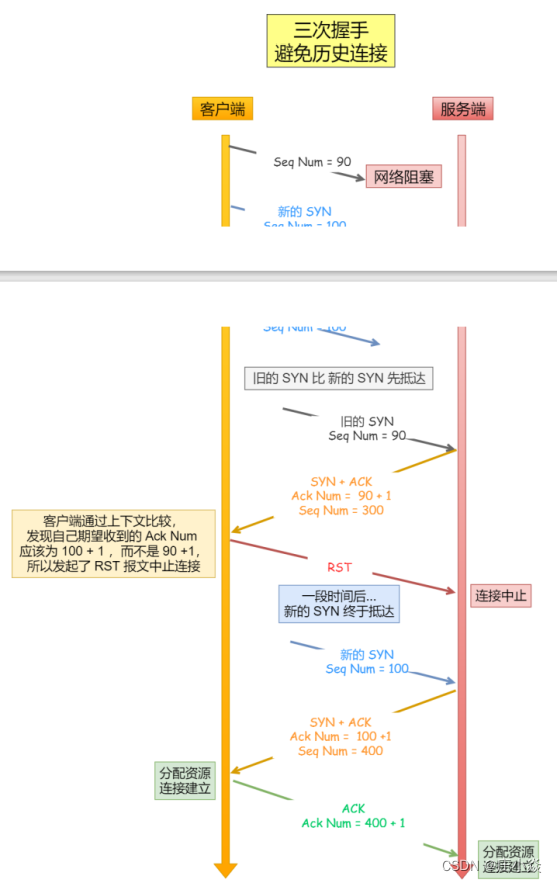
客户端连续发送多次 SYN 建⽴连接的报⽂,在网络拥堵情况下:
- ⼀个旧 SYN 报⽂⽐最新的 SYN 报⽂早到达了服务端;
- 那么此时服务端就会回⼀个 SYN + ACK 报⽂给客户端;
- 客户端收到后可以根据⾃身的上下⽂,判断这是⼀个历史连接(序列号过期或超时),那么客户端就会发送 RST 报⽂给服务端,表示中止这⼀次连接。
- 如果是两次握⼿连接,就不能判断当前连接是否是历史连接,三次握⼿则可以在客户端(发送⽅)准备发送第三次报⽂时,客户端因有⾜够的上下⽂来判断当前连接是否是历史连接:
- 如果是历史连接(序列号过期或超时),则第三次握⼿发送的报⽂是 RST 报⽂,以此中⽌历史连接;
- 如果不是历史连接,则第三次发送的报⽂是 ACK 报⽂,通信双⽅就会成功建⽴连接; 所以,TCP 使⽤三次握⼿建⽴连接的最主要原因是防⽌历史连接初始化了连接。
三次握手才可以同步双方的初始序列号
TCP 协议的通信双⽅, 都必须维护⼀个序列号, 序列号是可靠传输的⼀个关键因素,它的作⽤:
- 接收⽅可以去除重复的数据;
- 接收⽅可以根据数据包的序列号按序接收;
- 可以标识发送出去的数据包中, 哪些是已经被对方收到的。
序列号在 TCP 连接中占据着常重要的作⽤,所以当客户端发送携带初始序列号的 SYN 报⽂的时 候,需要服务端回⼀个 ACK 应答报⽂,表示客户端的 SYN 报⽂已被服务端成功接收,那当服务端发送初始序 列号给客户端的时候,依然也要得到客户端的应答回应,这样⼀来⼀回,才能确保双⽅的初始序列号能被可靠的同步。
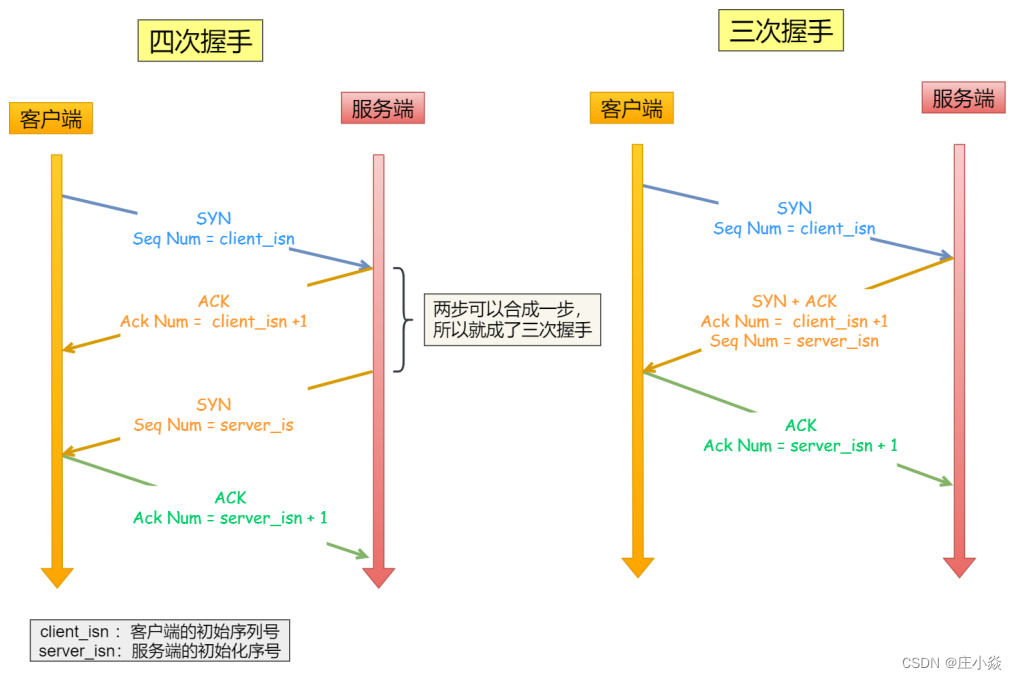
四次握⼿其实也能够可靠的同步双⽅的初始化序号,但由于第⼆步和第三步可以优化成⼀步,所以就成了三次握 ⼿。 ⽽两次握⼿只保证了⼀⽅的初始序列号能被对⽅成功接收,没办法保证双⽅的初始序列号都能被确认接收。
三次握手才可以避免资源浪费
如果只有两次握⼿,当客户端的 SYN 请求连接在⽹络中阻塞,客户端没有接收到 ACK 报⽂,就会重新发送SYN ,由于没有第三次握⼿,服务器不清楚客户端是否收到了⾃⼰发送的建⽴连接的 ACK确认信号,所以每收到⼀个 SYN就只能先主动建⽴⼀个连接。
这会造成什么情况呢? 如果客户端的SYN阻塞了,重复发送多次SYN报⽂,那么服务器在收到请求后就会建⽴多个冗余的无效的连接,造成不必要的资源浪费。

五、HTTP的四次挥手原理
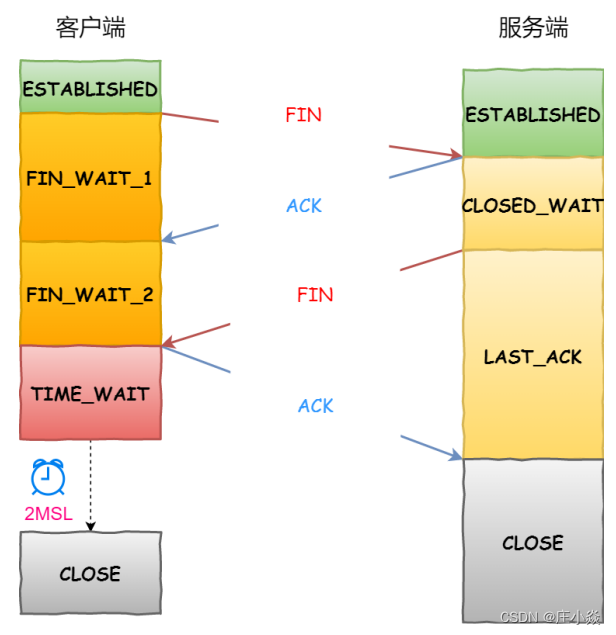
四次挥手的流程:
- 客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时,客户端进入FIN-WAIT-1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
- 服务器收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并且带上自己的序列号seq=v,此时,服务端就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
- 客户端收到服务器的确认请求后,此时,客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。
- 服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
- 客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,ack=w+1,而自己的序列号是seq=u+1,此时,客户端就进入了TIME-WAIT(时间等待)状态。注意此时TCP连接还没有释放,必须经过2∗∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。
- 服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。
为什么需要四次挥手?
- 关闭连接时,客户端向服务端发送 FIN 时,仅仅表示客户端不再发送数据了但是还能接收数据。
- 服务器收到客户端的 FIN 报⽂时,先回⼀个 ACK 应答报⽂,⽽服务端可能还有数据需要处理和发送,等服务端不再发送数据时,才发送 FIN 报⽂给客户端来表示同意现在关闭连接。 从上⾯过程可知,
- TCP 是全双工模式,并且支持半关闭特性,提供了连接的一端在结束发送后还能接收来自另一端数据的能力。任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了 TCP 连接。
- 两次握手就可以释放一端到另一端的 TCP 连接,完全释放连接一共需要四次握手。
为什么 TIME_WAIT 等待的时间是 2MSL?
- MSL是Maximum Segment Lifetime,报⽂最大生存时间,它是任何报⽂在网络上存在的最⻓时间,超过这个时间报⽂将被丢弃。因为 TCP 报⽂基于是 IP 协议的。
- TTL字段: 而IP头中有⼀个TTL字段,是IP 数据报可以经过的最大路由数,每经过⼀个处理他的路由器此值就减 1,当此值为0则数据报将被丢弃,同时发送 ICMP 报⽂通知源主机
MSL与TTL 的区别
- MSL 的单位是时间,而TTL 是经过路由跳数。所以MSL 应该要⼤于等于 TTL 消耗为 0 的 时间,以确保报文已被⾃然消亡。
- TIME_WAIT等待2倍的 MSL,比较合理的解释: 网络中可能存在来⾃发送⽅的数据包,当这些发送⽅的数据包 被接收⽅处理后⼜会向对⽅发送响应,所以⼀来⼀回需要等待2倍的时间。
- 如果被动关闭⽅没有收到断开连接的最后的 ACK 报⽂,就会触发超时重发 Fin 报⽂,另⼀⽅接收到 FIN 后, 会重发 ACK 给被动关闭⽅,⼀来⼀去正好2个MSL。
- 2MSL 的时间是从客户端接收到 FIN 后发送 ACK 开始计时的。如果在 TIME-WAIT 时间内,因为客户端的 ACK 没有传输到服务端,客户端⼜接收到了服务端重发的 FIN 报⽂,那么 2MSL 时间将重新计时。
- 在Linux 系统2MSL 默认 60秒,那么⼀个MSL也就是30 秒。Linux系统停留在,TIME_WAIT 的时 间为固定的 60 秒 。 其定义在 Linux 内核代码⾥的名称为 TCP_TIMEWAIT_LEN : define TCP_TIMEWAIT_LEN (60*HZ) ,如果要修改 TIME_WAIT 的时间⻓度,只能修改 Linux 内核代码⾥ TCP_TIMEWAIT_LEN 的值,并重新编译 Linux 内核 。
为什么需要TIME_WAIT 状态?
主动发起关闭连接的⼀⽅,才会有 TIME-WAIT 状态。 需要 TIME-WAIT 状态,主要是两个原因:
- 防⽌具有相同四元组的旧数据包被收到;
- 保证被动关闭连接的⼀⽅能被正确的关闭,即保证最后的 ACK 能让被动关闭⽅接收,从⽽帮助其正常关闭;
TIME-WAIT 没有等待时间或时间过短,被延迟的数据包抵达后会发生什么呢?
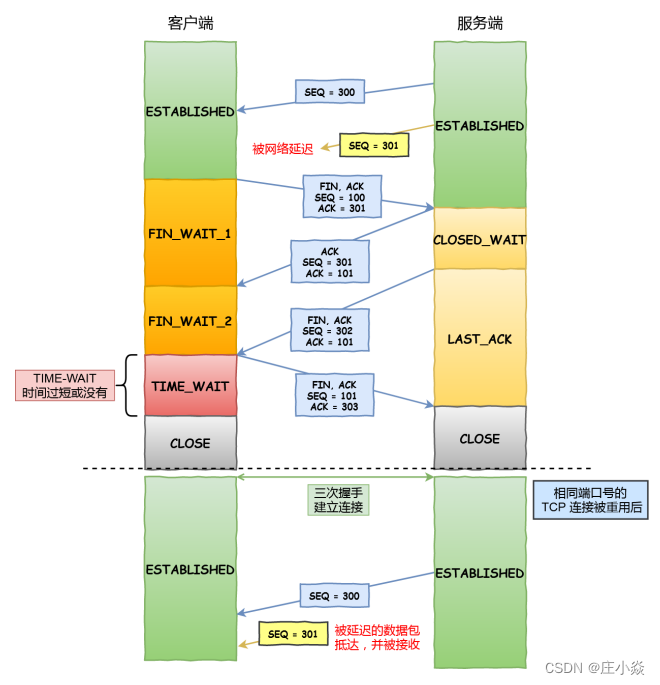
如上图黄色框框服务端在关闭连接之前发送的SEQ=301报⽂,被⽹络延迟了。 这时有相同端⼝的 TCP 连接被复⽤后,被延迟的 SEQ = 301 抵达了客户端,那么客户端是有可能正常接收 这个过期的报⽂,这就会产⽣数据错乱等严重的问题。 所以,TCP 就设计出了这么⼀个机制,经过 2MSL 这个时间,⾜以让两个⽅向上的数据包都被丢弃,使得原来 连接的数据包在⽹络中都⾃然消失,再出现的数据包⼀定都是新建⽴连接所产⽣的。
假设 TIME-WAIT 没有等待时间或时间过短,断开连接会造成什么问题呢?

- 如上图红⾊框框客户端四次挥⼿的最后⼀个 ACK 报⽂如果在⽹络中被丢失了,此时如果客户端 TIME- WAIT 过短或没有,则就直接进⼊了 CLOSED 状态了,那么服务端则会⼀直处在 LASE_ACK 状态。
- 当客户端发起建⽴连接的 SYN 请求报⽂后,服务端会发送RST报⽂给客户端,连接建⽴的过程就会被 终⽌。
如果TIME-WAIT 等待⾜够⻓的情况就会遇到两种情况 ?
- 服务端正常收到四次挥⼿的最后⼀个 ACK 报⽂,则服务端正常关闭连接。
- 服务端没有收到四次挥⼿的最后⼀个 ACK 报⽂时,则会重发 FIN 关闭连接报⽂并等待新的 ACK 报⽂。
TIME_WAIT过多有什么危害?
如果服务器有处于 TIME-WAIT 状态的 TCP,则说明是由服务器⽅主动发起的断开请求。 过多的 TIME-WAIT 状态主要的危害有两种:
- 第⼀是内存资源占⽤;
- 第⼆是对端⼝资源的占⽤,⼀个 TCP 连接⾄少消耗⼀个本地端⼝
如何优化TIME_WAIT?
打开 net.ipv4.tcp_tw_reuse 和 net.ipv4.tcp_timestamps 选项
如下的 Linux 内核参数开启后,则可以复⽤处于 TIME_WAIT 的 socket 为新的连接所⽤。 有⼀点需要注意的是,tcp_tw_reuse 功能只能⽤客户端(连接发起⽅),因为开启了该功能,在调⽤ connect() 函数时,内核会随机找⼀个 time_wait 状态超过 1 秒的连接给新的连接复⽤。
net.ipv4.tcp_max_tw_buckets
这个值默认为 18000,当系统中处于 TIME_WAIT 的连接⼀旦超过这个值时,系统就会将后⾯的 TIME_WAIT 连接 状态重置 。 这个⽅法过于暴⼒,⽽且治标不治本,带来的问题远⽐解决的问题多,不推荐使⽤
程序中使用SO_LINGER ,应⽤强制使⽤ RST 关闭
我们可以通过设置 socket 选项,来设置调⽤ close 关闭连接⾏为,我们可以通过设置 socket 选项,来设置调⽤ close 关闭连接⾏为 。
如果已经建立了连接,但是客户端突然出现故障了怎么办?
TCP 有⼀个机制是保活机制。这个机制的原理是这样的: 定义⼀个时间段,在这个时间段内,如果没有任何连接相关的活动,TCP 保活机制会开始作⽤,每隔⼀个时间间 隔,发送⼀个探测报⽂,该探测报文包含的数据⾮常少,如果连续几个探测报⽂都没有得到响应,则认为当前的 TCP 连接已经死亡,系统内核将错误信息通知给上层应⽤程序 :
- 在 Linux 内核可以有对应的参数可以设置保活时间、保活探测的次数、保活探测的时间间隔,以下都为默认值:
- tcp_keepalive_time=7200:
- 表示保活时间是7200秒(2⼩时),也就2⼩时内如果没有任何连接相关的活动,则会启动保活机制
- tcp_keepalive_intvl=75:
- 表示每次检测间隔75秒;
- tcp_keepalive_probes=9:
- 表示检测9次⽆响应,认为对⽅是不可达的,从⽽中断本次的连接。
如果开启了 TCP 保活,需要考虑以下⼏种情况:
- 第⼀种,对端程序是正常⼯作的。当 TCP 保活的探测报⽂发送给对端, 对端会正常响应,这样 TCP 保活时间会被 重置,等待下⼀个 TCP 保活时间的到来。
- 第⼆种,对端程序崩溃重启。当 TCP 保活的探测报⽂发送给对端后,对端是可以响应的,但由于没有该连接的 有效信息,会产⽣⼀个 RST 报⽂,这样很快就会发现 TCP 连接已经被重置。
- 第三种,是对端程序崩溃,或对端由于其他原因导致报⽂不可达。当 TCP 保活的探测报⽂发送给对端后,⽯沉⼤ 海,没有响应,连续⼏次,达到保活探测次数后,TCP 会报告该 TCP 连接已经死亡。
六、HTTP1.0特性
6.1 HTTP1.0特性的优点
- 简单 HTTP 基本的报⽂格式就是 header + body ,头部信息也是 key-value 简单⽂本的形式,易于理解,降低了学习 和使⽤的⻔槛。
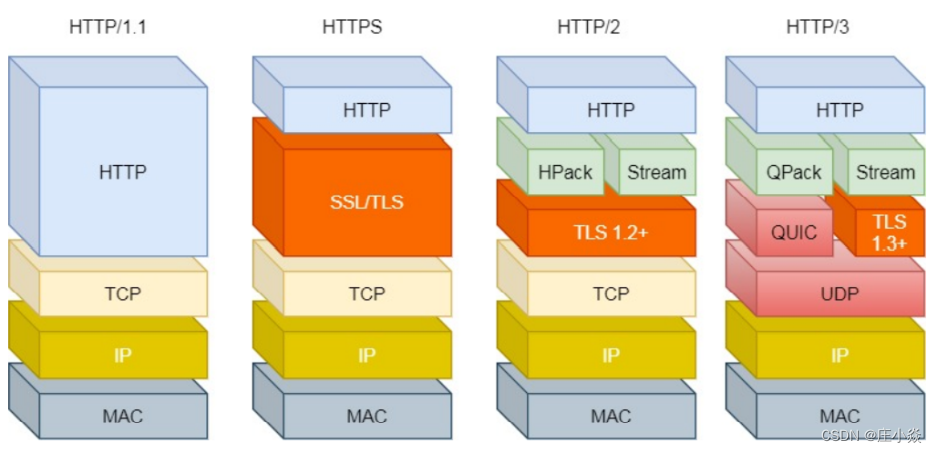
- 灵活和易于扩展 HTTP协议⾥的各类请求⽅法、URI/URL、状态码、头字段等每个组成要求都没有被固定死,都允许开发⼈员⾃定 义和扩充。 同时 HTTP 由于是⼯作在应⽤层( OSI 第七层),则它下层可以随意变化。 HTTPS 也就是在 HTTP 与 TCP 层之间增加了 SSL/TLS 安全传输层,HTTP/3 甚⾄把 TCP 层换成了基于 UDP 的 QUIC。
- 应⽤⼴泛和跨平台 互联⽹发展⾄今,HTTP 的应⽤范围⾮常的⼴泛,从台式机的浏览器到⼿机上的各种 APP,从看新闻、刷贴吧到购 物、理财、吃鸡,HTTP 的应⽤⽚地开花,同时天然具有跨平台的优越性。
6.2 HTTP1.0特性的缺点
HTTP协议⾥有优缺点⼀体的双刃剑,分别是⽆状态、明⽂传输,同时还有⼀⼤缺点不安全。
- ⽆状态双刃剑⽆状态的好处,因为服务器不会去记忆 HTTP 的状态,所以不需要额外的资源来记录状态信息,这能减轻服务器的 负担,能够把更多的 CPU 和内存⽤来对外提供服务。 ⽆状态的坏处,既然服务器没有记忆能⼒,它在完成有关联性的操作时会⾮常麻烦。
- 例如登录->添加购物⻋->下单->结算->⽀付,这系列操作都要知道⽤户的身份才⾏。但服务器不知道这些请求是有 关联的,每次都要问⼀遍身份信息。 这样每操作⼀次,都要验证信息,这样的购物体验还能愉快吗?别问,问就是酸爽! 对于⽆状态的问题,解法⽅案有很多种,其中⽐较简单的⽅式⽤ Cookie 技术。 Cookie 通过在请求和响应报⽂中写⼊ Cookie 信息来控制客户端的状态。 相当于,在客户端第⼀次请求后,服务器会下发⼀个装有客户信息的⼩贴纸,后续客户端请求服务器的时候, 带上⼩贴纸,服务器就能认得了了 。
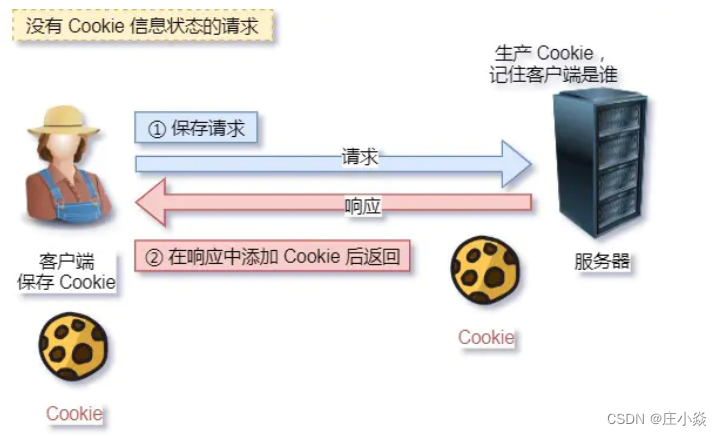
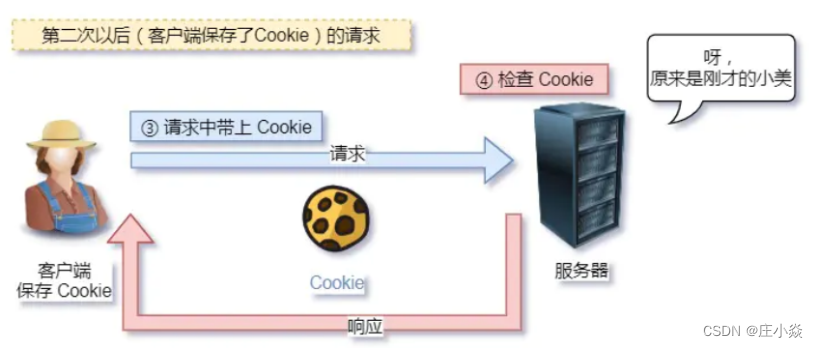
- 明文意味着在传输过程中的信息,是可⽅便阅读的,通过浏览器的 F12 控制台或 Wireshark 抓包都可以直接⾁眼查 看,为我们调试⼯作带了极⼤的便利性。 但是这正是这样,HTTP 的所有信息都暴露在了光天化⽇下,相当于信息裸奔。在传输的漫⻓的过程中,信息的内 容都毫⽆隐私可⾔,很容易就能被窃取,如果⾥⾯有你的账号密码信息,那你号没了。
- 不安全 HTTP 比较严重的缺点就是不安全: 通信使用明文(不加密),内容可能会被窃听。比如,账号信息容易泄漏,那你号没了。 不验证通信⽅的身份,因此有可能遭遇伪装。比如,访问假的淘宝、拼多多,那你钱没了。 ⽆法证明报⽂的完整性,所以有可能已遭篡改。⽐如,⽹⻚上植⼊垃圾⼴告,视觉污染,眼没了。 HTTP 的安全问题,可以⽤ HTTPS 的⽅式解决,也就是通过引⼊ SSL/TLS 层,使得在安全上达到了极致。
七、HTPP1.1特性
HTTP 协议是基于 TCP/IP,并且使⽤了请求 - 应答的通信模式,所以性能的关键就在这两点⾥。
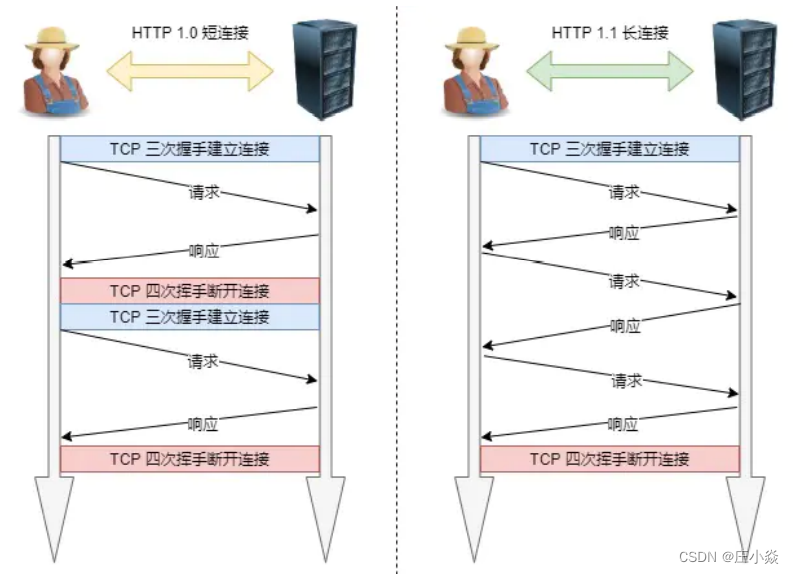
7.1 长连接
早期 HTTP/1.0 性能上的⼀个很⼤的问题,那就是每发起⼀个请求,都要新建⼀次 TCP 连接(三次握⼿),⽽且是 串⾏请求,做了⽆谓的 TCP 连接建⽴和断开,增加了通信开销。 为了解决上述 TCP 连接问题,HTTP/1.1 提出了长连接的通信⽅式,也叫持久连接。这种⽅式的好处在于减少了 TCP 连接的᯿复建⽴和断开所造成的额外开销,减轻了服务器端的负载。 持久连接的特点是,只要任意⼀端没有明确提出断开连接,则保持 TCP 连接状态。
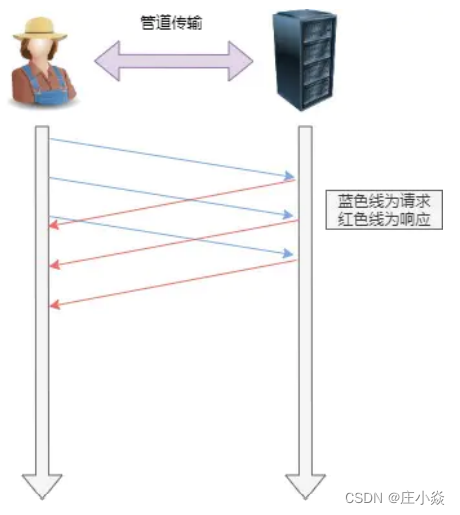
7.2 管道网络传输
HTTP/1.1 采⽤了⻓连接的⽅式,这使得管道(pipeline)⽹络传输成为了可能。 即可在同⼀个 TCP 连接⾥⾯,客户端可以发起多个请求,只要第⼀个请求发出去了,不必等其回来,就可以发第 ⼆个请求出去,可以减少整体的响应时间。 举例来说,客户端需要请求两个资源。以前的做法是,在同⼀个TCP连接⾥⾯,先发送 A 请求,然后等待服务器做 出回应,收到后再发出 B 请求。管道机制则是允许浏览器同时发出 A 请求和 B 请求。 但是服务器还是按照顺序,先回应 A 请求,完成后再回应 B 请求。要是前⾯的回应特别慢,后⾯就会有许多请求 排队等着。这称为队头堵塞。
八、HTTP2.0特性
HTTP/2 协议是基于 HTTPS 的,所以 HTTP/2 的安全性也是有保障的。 那 HTTP/2 相⽐ HTTP/1.1 性能上的改进
8.1 头部压缩
HTTP/2 会压缩头(Header)如果你同时发出多个请求,他们的头是⼀样的或是相似的,那么,协议会帮你消除重 复的部分。 这就是所谓的HPACK算法:在客户端和服务器同时维护⼀张头信息表,所有字段都会存⼊这个表,⽣成⼀个索引号,以后就不发送同样字段了,只发送索引号,这样就提⾼速度了。
8.2 二进制格式
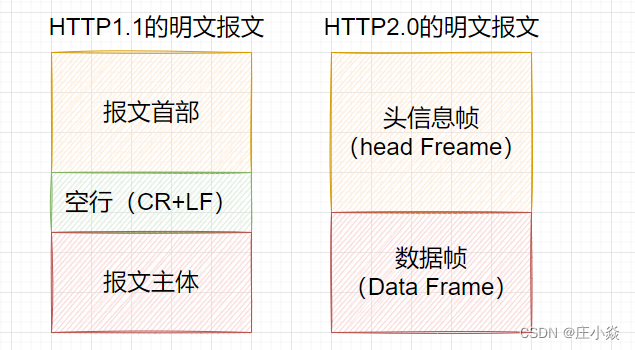
HTTP/2 不再像 HTTP/1.1 ⾥的纯⽂本形式的报⽂,⽽是全⾯采⽤了⼆进制格式,头信息和数据体都是⼆进制,并 且统称为帧(frame):头信息帧和数据帧。这样虽然对⼈不友好,但对计算机f非常友好,因为计算机只懂⼆进制,那么收到报⽂后,⽆需再将明⽂的报⽂转 成⼆进制,直接解析⼆进制报⽂,这增加了数据传输的效率 。
8.3 数据流
HTTP/2 的数据包不是按顺序发送的,同⼀个连接里面连续的数据包,可能属于不同的回应。因此,必须要对数据包做标记,指出它属于哪个回应。 每个请求或回应的所有数据包,称为⼀个数据流(Stream )。每个数据流都标记着⼀个独⼀⽆⼆的编号,其中规定客户端发出的数据流编号为奇数, 服务器发出的数据流编号为偶数客户端还可以指定数据流的优先级。优先级⾼的请求,服务器就先响应该请求。
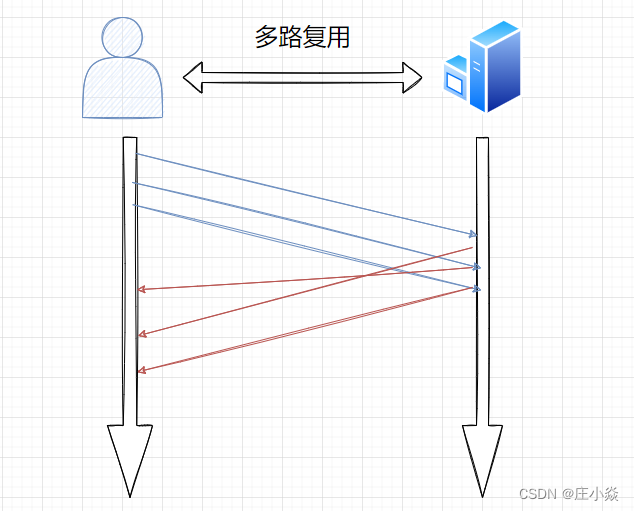
8.4 多路复用技术
HTTP/2 是可以在⼀个连接中并发多个请求或回应,⽽不⽤按照顺序⼀⼀对应。 移除了 HTTP/1.1 中的串⾏请求,不需要排队等待,也就不会再出现队头阻塞问题,降低了延迟,⼤幅度提⾼ 了连接的利⽤率。 举例来说,在⼀个 TCP 连接⾥,服务器收到了客户端 A 和 B 的两个请求,如果发现 A 处理过程⾮常耗时,于是就 回应 A 请求已经处理好的部分,接着回应 B 请求,完成后,再回应 A 请求剩下的部分。
8.5 服务器推送
HTTP/2 还在⼀定程度上改善了传统的请求--应答⼯作模式,服务不再是被动地响应,也可以主动向客户端发 送消息。 举例来说,在浏览器刚请求 HTML 的时候,就提前把可能会⽤到的 JS、CSS ⽂件等静态资源主动发给客户端,减少延时的等待,也就是服务器推送(Server Push,也叫 Cache Push)。
8.6 HTTP的总结
HTTP/2 协议其实还有很多内容,⽐如流控制、流状态、依赖关系等等 。HTTP/2 是如何提示性能的几个⽅向,它相比HTTP/1大大的提高了传输效率、吞吐能力。
- 第⼀点,对于常⻅的 HTTP 头部通过静态表和 Huffman 编码的⽅式,将体积压缩了近⼀半,⽽且针对后续的请求 头部,还可以建⽴动态表,将体积压缩近 90%,⼤⼤提⾼了编码效率,同时节约了带宽资源。不过,动态表并⾮可以⽆限增⼤, 因为动态表是会占⽤内存的,动态表越⼤,内存也越⼤,容易影响服务器总体的 并发能⼒,因此服务器需要限制 HTTP/2 连接时⻓或者请求次数 。
- 第⼆点,HTTP/2 实现了 Stream 并发,多个 Stream 只需复⽤ 1 个 TCP 连接,节约了 TCP 和 TLS 握⼿时间,以 及减少了 TCP 慢启动阶段对流ᰁ的影响。不同的 Stream ID 才可以并发,即时乱序发送帧也没问题,但是同⼀个 Stream ⾥的帧必须严格有序。 另外,可以根据资源的渲染顺序来设置 Stream 的优先级,从⽽提⾼⽤户体验
- 第三点,服务器⽀持主动推送资源,⼤⼤提升了消息的传输性能,服务器推送资源时,会先发送 PUSH_PROMISE 帧,告诉客户端接下来在哪个 Stream 发送资源,然后⽤偶数号 Stream 发送资源给客户端。HTTP/2 通过 Stream 的并发能⼒,解决了 HTTP/1 队头阻塞的问题,看似很完美了,但是 HTTP/2 还是存在“队头 阻塞”的问题,只不过问题不是在 HTTP 这⼀层⾯,⽽是在TCP 这⼀层。
HTTP/2 是基于 TCP 协议来传输数据的,TCP 是字节流协议,TCP 层必须保证收到的字节数据是完整且连续的, 这样内核才会将缓冲区⾥的数据返回给 HTTP 应⽤,那么当前 1 个字节数据没有到达时,后收到的字节数据只 能存放在内核缓冲区⾥,只有等到这 1 个字节数据到达时,HTTP/2 应用层才能从内核中拿到数据,这就是 HTTP/2 队头阻塞问题。 有没有什么解决⽅案呢?既然是TCP 协议⾃身的问题,那干脆放弃 TCP 协议,HTTP/3 协议使用UDP 协议作为传输层协议!
九、HTTP/3 的特性
9.1 HTTP/2 主要的问题在于
- 队头阻塞
- TCP 与 TLS 的握⼿时延迟
- ⽹络迁移需要重新连接
9.1.1 队列阻塞
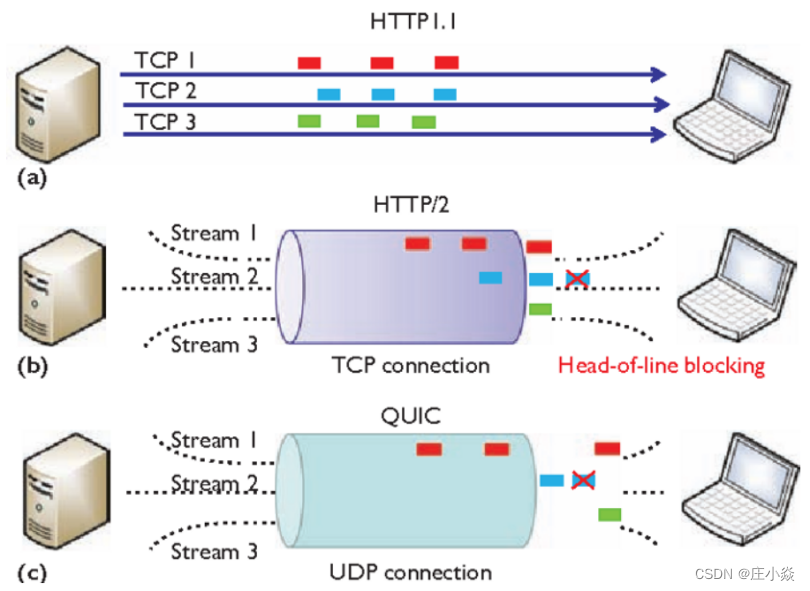
HTTP/2 多个请求是跑在⼀个TCP 连接中的,那么当TCP丢包时,整个TCP 都要等待重传,那么就会阻塞该 TCP 连接中的所有请求。因为 TCP 是字节流协议,TCP 层必须保证收到的字节数据是完整且有序的,如果序列号较低的 TCP 段在⽹络传输 中丢失了,即使序列号较⾼的 TCP 段已经被接收了,应⽤层也⽆法从内核中读取到这部分数据,从HTTP 视⻆看,就是请求被阻塞了。
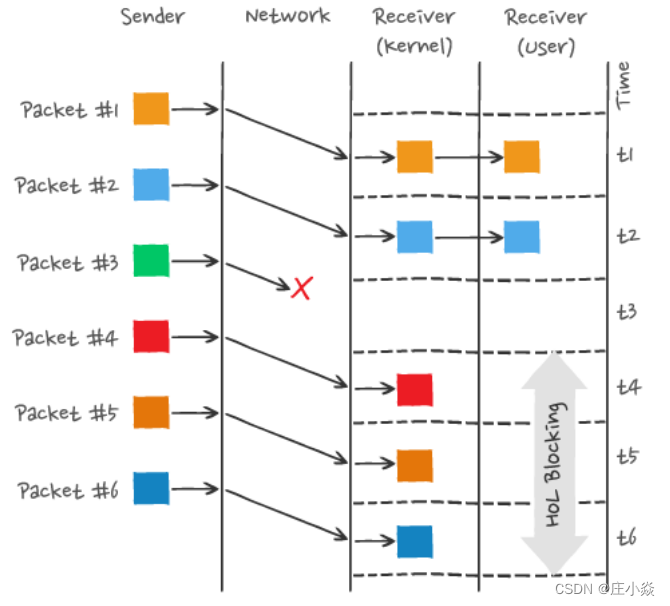
图中发送⽅发送了很多个packet,每个 packet 都有⾃⼰的序号,你可以认为是 TCP 的序列号,其中 packet 3 在 ⽹络中丢失了,即使 packet 4-6 被接收⽅收到后,由于内核中的 TCP 数据不是连续的,于是接收⽅的应⽤层就⽆ 法从内核中读取到,只有等到 packet 3 重传后,接收⽅的应⽤层才可以从内核中读取到数据,这就是 HTTP/2 的 队头阻塞问题,是在 TCP 层⾯发⽣的 。
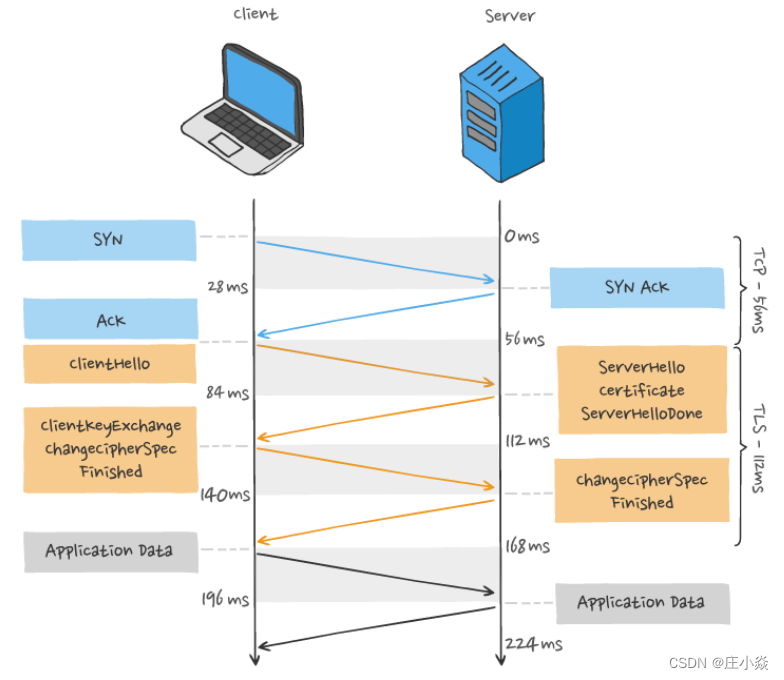
9.1.2 TCP与TLS 的握手时延迟
发起HTTP 请求时,需要经过 TCP三次握⼿和TLS四次握⼿(TLS 1.2)的过程,因此共需要 3 个 RTT 的时延才 能发出请求数据 。另外, TCP 由于具有拥塞控制的特性,所以刚建⽴连接的 TCP 会有个慢启动的过程,它会对 TCP 连接 产⽣"减速"效果。
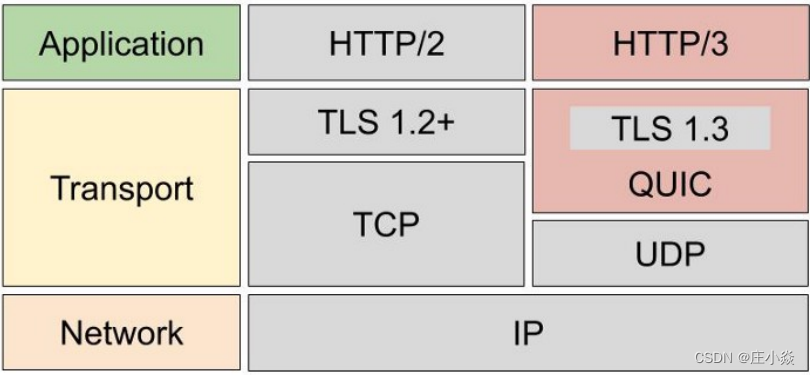
9.1.3 网络迁移需要重新连接
⼀个TCP 连接是由四元组(源 IP 地址,源端⼝,⽬标 IP 地址,⽬标端⼝)确定的,这意味着如果 IP 地址或者端⼝变动了,就会导致需要 TCP与TLS重新握⼿,这不利于移动设备切换⽹络的场景,比如4G网络环境切换成 WIFI。 这些问题都是 TCP 协议固有的问题,⽆论应⽤层的 HTTP/2 在怎么设计都⽆法逃脱。要解决这个问题,就必须把传输层协议替换成 UDP!
9.2 HTTP/3的QUIC协议
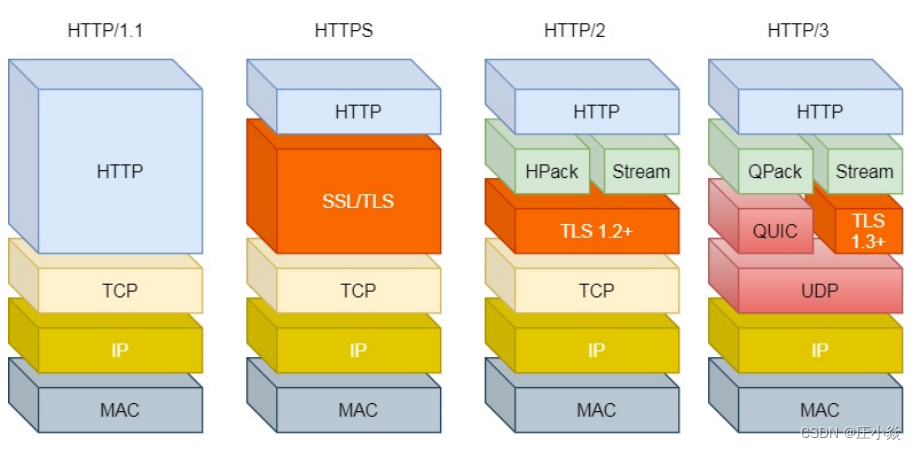
HTTP/2主要的问题在于多个 HTTP 请求在复⽤⼀个 TCP 连接,下层的 TCP 协议是不知道有多少个 HTTP 请求 的。所以⼀旦发⽣了丢包现象,就会触发 TCP 的᯿传机制,这样在⼀个 TCP 连接中的所有的 HTTP 请求都必须等 待这个丢了的包被重传回来。
- HTTP/1.1 中的管道( pipeline)传输中如果有⼀个请求阻塞了,那么队列后请求也统统被阻塞住了。
- HTTP/2 多个请求复⽤⼀个TCP连接,⼀旦发⽣丢包,就会阻塞住所有的 HTTP 请求。
这都是基于 TCP 传输层的问题,所以 HTTP/3 把 HTTP 下层的 TCP 协议改成了 UDP
UDP发⽣是不管顺序,也不管丢包的,所以不会出现 HTTP/1.1 的队头阻塞 和 HTTP/2 的⼀个丢包全部传问题。 ⼤家都知道UDP 是不可靠传输的,但基于 UDP 的 QUIC 协议可以实现类似 TCP 的可靠性传输。 QUIC 有⾃⼰的⼀套机制可以保证传输的可靠性的。当某个流发⽣丢包时,只会阻塞这个流,其他流不会受到 影响。 TLS3 升级成了最新的 1.3 版本,头部压缩算法也升级成了 QPack 。 HTTPS 要建⽴⼀个连接,要花费 6 次交互,先是建⽴三次握⼿,然后是 TLS/1.3 的三次握⼿。QUIC 直接 把以往的 TCP 和 TLS/1.3 的 6 次交互合并成了 3 次,减少了交互次数。
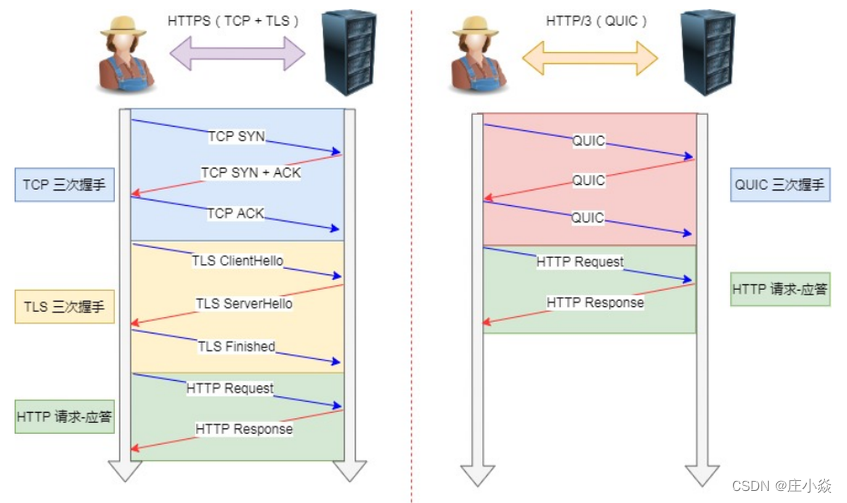
我们深知,UDP是⼀个简单、不可靠的传输协议,⽽且是 UDP 包之间是⽆序的,也没有依赖关系。 UDP 是不需要连接的,也就不需要握⼿和挥⼿的过程,所以天然的就⽐TCP 快。 当然,HTTP/3 不仅仅只是简单将传输协议替换成了 UDP,还基于 UDP 协议在应⽤层实现了 QUIC 协议,它 具有类似 TCP 的连接管理、拥塞窗⼝、流量控制的⽹络特性,相当于将不可靠传输的 UDP 协议变成“可靠”的了, 所以不⽤担⼼数据包丢失的问题。 QUIC 协议的优点有很多,比如 :
- ⽆队头阻塞;
- 更快的连接建⽴;
- 连接迁移;
9.2.1 无队头阻塞
QUIC协议也有类似 HTTP/2 Stream 与多路复⽤的概念,也是可以在同⼀条连接上并发传输多个Stream,Stream 可以认为就是⼀条 HTTP 请求。 由于 QUIC 使⽤的传输协议是 UDP,UDP 不关⼼数据包的顺序,如果数据包丢失,UDP 也不关⼼。 不过 QUIC 协议会保证数据包的可靠性,每个数据包都有⼀个序号唯⼀标识。当某个流中的⼀个数据包丢失了,即使该流的其他数据包到达了,数据也⽆法被 HTTP/3 读取,直到 QUIC重传丢失的报⽂,数据才会交给 HTTP/3。⽽其他流的数据报⽂只要被完整接收,HTTP/3 就可以读取到数据。这与 HTTP/2 不同,HTTP/2 只要某个流中的 数据包丢失了,其他流也会因此受影响。 所以,QUIC 连接上的多个 Stream 之间并没有依赖,都是独⽴的,某个流发⽣丢包了,只会影响该流,其他流不 受影响。
9.2.2 更快的连接建立
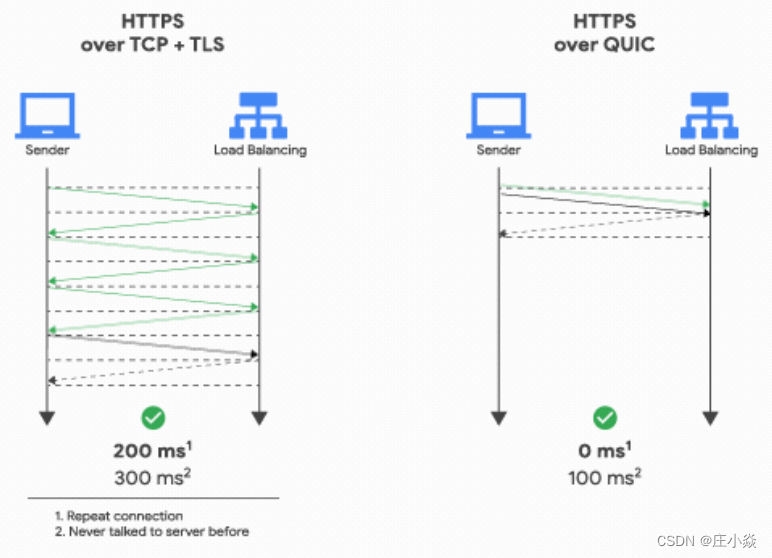
对于 HTTP/1 和 HTTP/2 协议,TCP 和 TLS 是分层的,分别属于内核实现的传输层、openssl 库实现的表示层,因此它们难以合并在⼀起,需要分批次来握⼿,先 TCP 握⼿,再 TLS 握⼿。 HTTP/3 在传输数据前虽然需要 QUIC 协议握⼿,这个握⼿过程只需要1RTT,握⼿的⽬的是为确认双⽅的连接 ID,连接迁移是基于连接 ID 实现。
但是 HTTP/3 的 QUIC 协议并不是与 TLS 分层,⽽是QUIC 内部包含了 TLS,它在⾃⼰的帧会携带 TLS ⾥的“记 录”,再加上 QUIC 使⽤的是 TLS1.3,因此仅需 1 个 RTT 就可以同时完成建⽴连接与密钥协商,甚⾄在第⼆ 次连接的时候,应⽤数据包可以和 QUIC 握⼿信息(连接信息 + TLS 信息)⼀起发送,达到 0-RTT 的效果。
如下图右边部分,HTTP/3 当会话恢复时,有效负载数据与第⼀个数据包⼀起发送,可以做到 0-RTT:
9.2.3 连接迁移
在前⾯我们提到,基于 TCP 传输协议的 HTTP 协议,由于是通过四元组(源 IP、源端⼝、⽬的 IP、⽬的端⼝)确 定⼀条 TCP 连接,那么当移动设备的⽹络从 4G 切换到 WIFI 时,意味着 IP 地址变化了,那么就必须要断开连 接,然后重新建⽴连接,⽽建⽴连接的过程包含 TCP 三次握⼿和 TLS 四次握⼿的时延,以及 TCP 慢启动的减速 过程,给⽤户的感觉就是⽹络突然卡顿了⼀下,因此连接的迁移成本是很⾼的。 ⽽ QUIC 协议没有⽤四元组的⽅式来“绑定”连接,⽽是通过连接 ID来标记通信的两个端点,客户端和服务器可以各⾃选择⼀组 ID 来标记⾃⼰,因此即使移动设备的⽹络变化后,导致 IP 地址变化了,只要仍保有上下⽂信息(⽐如 连接 ID、TLS 密钥等),就可以“⽆缝”地复⽤原连接,消除重连的成本,没有丝毫卡顿感,达到了连接迁移的功能。
9.2.4 HTTP/3 协议
了解完 QUIC 协议的特点后,我们再来看看 HTTP/3 协议在 HTTP 这⼀层做了什么变化。 HTTP/3 同 HTTP/2 ⼀样采⽤⼆进制帧的结构,不同的地⽅在于HTTP/2 的⼆进制帧⾥需要定义Stream,⽽ HTTP/3 ⾃身不需要再定义 Stream,直接使⽤ QUIC ⾥的 Stream,于是 HTTP/3 的帧的结构也变简单了。
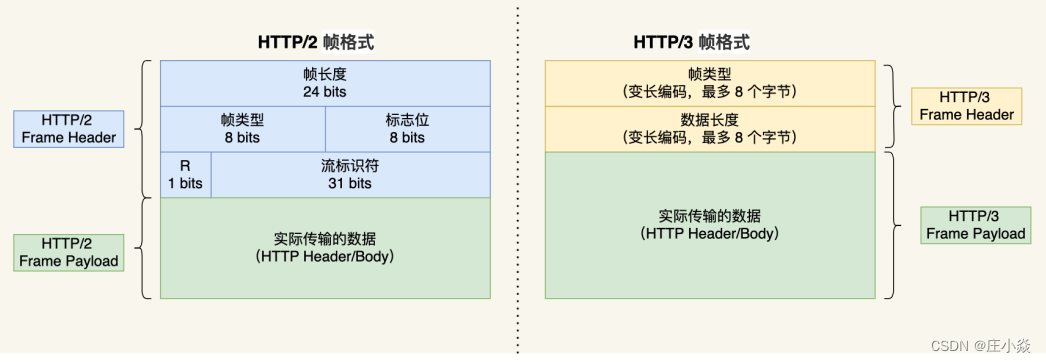
从上图可以看到,HTTP/3 帧头只有两个字段:类型和⻓度。 根据帧类型的不同,⼤体上分为数据帧和控制帧两⼤类,HEADERS 帧(HTTP 头部)和 DATA 帧(HTTP 包体) 属于数据帧
HTTP/3 在头部压缩算法这⼀⽅便也做了升级,升级成了 QPACK。与 HTTP/2 中的 HPACK 编码⽅式相似, HTTP/3 中的 QPACK 也采⽤了静态表、动态表及 Huffman 编码。 对于静态表的变化,HTTP/2 中的 HPACK 的静态表只有 61 项,⽽ HTTP/3 中的 QPACK 的静态表扩⼤到 91项
HTTP/2 和 HTTP/3 的 Huffman 编码并没有多⼤不同,但是动态表编解码⽅式不同。 所谓的动态表,在⾸次请求-响应后,双⽅会将未包含在静态表中的 Header 项更新各⾃的动态表,接着后续传输时 仅⽤ 1 个数字表示,然后对⽅可以根据这 1 个数字从动态表查到对应的数据,就不必每次都传输⻓⻓的数据,⼤⼤提升了编码效率 。
可以看到,动态表是具有时序性的,如果⾸次出现的请求发⽣了丢包,后续的收到请求,对⽅就⽆法解码出 HPACK 头部,因为对⽅还没建⽴好动态表,因此后续的请求解码会阻塞到⾸次请求中丢失的数据包重传过来。
HTTP/3 的 QPACK 解决了这⼀问题,那它是如何解决的呢?
QUIC 会有两个特殊的单向流,所谓的单项流只有⼀端可以发送消息,双向则指两端都可以发送消息,传输 HTTP 消息时⽤的是双向流,这两个单向流的⽤法: ⼀个叫 QPACK Encoder Stream, ⽤于将⼀个字典(key-value)传递给对⽅,⽐如⾯对不属于静态表的 HTTP 请求头部,客户端可以通过这个 Stream 发送字典;⼀个叫 QPACK Decoder Stream,⽤于响应对⽅,告诉它刚发的字典已经更新到⾃⼰的本地动态表了,后续 就可以使⽤这个字典来编码了。 这两个特殊的单向流是⽤来同步双⽅的动态表,编码⽅收到解码⽅更新确认的通知后,才使⽤动态表编码 HTTP 头部。
参考博文
《小林图解网络》

