
- 1angular学习之关于ng-class详解
- 2gradio高级技巧_gradio修改界面格式
- 3关于openai和chatgpt、gpt-4、PyTorch、TensorFlow 两者和Transformers的关系
- 4数仓建设教程_数仓搭建
- 5如何在Java开发中,更加安全的编码?这是一个问题,3个月学会Java开发
- 6IDEA的gitee使用_gitee在idea中的使用
- 7微信开发者工具-project.config.json配置详情 (转)_[ project.config.json 文件内容错误] project.config.json:
- 8Spring Boot入门(06):Spring Boot常用注解大全:让你不再为注解而困惑_史上最详细springboot
- 9用git bash调用md5sum进行批量MD5计算_bash md5
- 10MQ消息队列(五)——RabbitMQ进阶 MQ集群+集群的部署+集群的扩容_rabbitmq(五) | mq集群搭建、部署、仲裁队列、集群扩容
Apache Iceberg + Amoro 构建云原生湖仓实战
赞
踩
01 摘要
本文将系统的介绍云原生湖仓(cloud native lakehouse)的概念,阐述基于云平台构建云原生湖仓的优势和挑战。云原生湖仓可以更好地利用云平台本身的弹性扩缩容,低成本存储、以及运维成本低的特性。
Amoro 是构建在数据湖之上的开源湖仓管理系统,提供一系列可插拔组件的功能组件和自我管理的能力,提供开箱即用的湖仓体验,帮助数据平台或数据产品构建基础设施无关,流批融合的湖原生架构。
02 什么是湖仓一体
湖仓一体是一种结合了数据湖和数据仓库技术的新型的数据处理架构。数仓技术自诞生以来其主要处理的都是结构化数据,然而最近几年随着流计算,AI,机器学习等新兴业务的不断发展,催生了对与半结构化数据、非结构化数据以及具有高多样性的数据处理的需求,面对这些场景,传统数仓并不适用。在这种背景下,企业需要一种集中式的存储系统,用于保存、处理大量的结构化、半结构化和非结构化数据,这种集中式的存储系统以及相关的数据处理技术被称为数据湖(Data Lake)。
由于数据湖天然的开放性,以及低廉的存储价格,业界开始尝试基于数据湖构建面向结构化数据处理的方案,以实现在一个统一个存储系统上容纳不同分析产品和工作负载的数据,Hive 就是这种背景下的成果之一。然而数据湖对于一些关键特性的缺失,比如不支持事物,缺乏一致性/隔离性等导致其几乎无法同时处理读取和写入,批处理和流计算。为了满足不同业务的复杂的计算需求,一个解决方案是并行的使用多个系统,比如使用 Hive 处理批处理作业,使用 Kafka 和 Kudu 处理流作业等。过多的系统带来了不必要的复杂性、成本以及数据孤岛等问题。在这种背景下,业界急需新的技术方案以补齐数据湖缺失的特性,并构建面向流批统一的数仓。
在谈到湖仓一体时,往往会提到 Iceberg、Hudi、Dalta 等项目,这些数据湖表项目有着以下共同特性:
-
支持 ACID:对于 ACID 的支持使得不同的计算任务可以并发的处理数据,不同的计算任务可以自由的对数据进行读写而不用担心破坏数据的一致性。
-
支持结构演进:相比 Hive 中对于表定义的粗糙管理,新兴的湖表格可以安全的进行结构变更而不破坏数据的约束以及一致性。
-
高效的更新/删除能力:相比 Hive 只能支持追加写(Append)和分区覆盖(Overwrite),新兴的数据湖表可以高效的对部分数据进行修改,这极大的提高了业务对于数据处理的灵活性。
-
更好的支持流:相比 Hive 几乎只能应用了批场景下,数据湖表对流计算的支持更加完善,流计算目前在企业数据处理中占据着非常重要的地位,对流计算的支持消除了需要构建单独的系统以用于实时数据处理的需求,有助于数据孤岛的消除。
-
OLAP 查询的支持:对于 Hive 来说,数据的查询效率极大的依赖于数据是如何写入的,面对灵活且复杂的 OLAP 查询显得力不从心,因此在有 OLAP 或者 BI 需求的场景下,往往需要将 Hive 数据引入别的系统来提供给数据应用。数据湖表提供了 File Sikp 能力极大优化在复杂查询条件下的性能,对 OLAP 查询的支持同样有助于消除数据孤岛。
-
数据回溯:数据回溯功能提供了访问历史版本数据的能力,这对于数据回滚,AI 训练等场景十分重要.
从计算层面来看,这些数据湖表似乎已经解决了在数据湖上高效的处理结构化数据的需求,并在一定程度上实现了流批融合,但是只依靠数据湖表,生产可用的流批统一的湖上数仓还有一定的距离。相比一个生产可以的湖上数仓,数据湖表还缺失一些特性:
-
元数据目录(Catalog):传统的数仓均提供了统一的表的元数据管理能力,通过一个中心化的服务,可以轻易的管理大量的表。而目前数据湖表技术缺乏这种能力,通常这些湖表需要依赖其他的元数据服务(比如 Hive)来进行统一的元数据管理。
-
表的持续优化能力:由于湖表提供了流批融合的能力,流计算任务持续写入的特性必然导致小文件和文件碎片问题,因此需要持续不断的对数据进行优化以满足最佳的查询性能。有些湖表格式(比如 Hudi)提供了在流式写入时优化的能力来解决这个问题,但是这种模式必然对写入性能产生影响。所以湖表基本都提供了通过触发批任务来对表进行优化的方案,然而由于湖表格式在设计上天然的去中心化,导致优化任务缺乏的统一管理。
-
统一的访问方式:不同格式的湖表在不同领域提供了不同的特性,在生产中可能需要联合不同格式的湖表以应对不同类型的问题,(比如 Iceberg 在批处理和 AI 学习的场景提供了丰富的支持,而 Hudi 则在 CDC 和有主键场景提供了比较好的支持)目前各种湖表均提供了独立的 connector 用于访问各自的表格式,如果想在一个任务中实现不同类型的湖表联邦,必须同时配置多个 Catalog,这对于数据的统一管理带来更多的挑战。
-
其他通用的功能:比如统一的权限管理,数据血缘等功能
因此,在构建湖仓一体时,除了要选择合适的数据湖表格式,还需要有合适的管理平台才能构建生产可用的湖仓一体。
03 湖仓一体与云
在构建湖仓一体的实践中,往往与云计算相结合,这是因为湖仓的很多关键特性与云计算的特性匹配。
-
Lakehouse 构建在廉价且高可靠的存储上,而对象存储作为云计算的基础服务之一,天然就是廉价且高可靠的。
-
Lakehouse 存算分离的架构使得业务可以根据需求扩展计算或存储资源,而弹性扩缩容是云计算的核心能力。
此外,云还极大的减少了运维部署成本,在云上,无论是机器采购、新服务部署、新机房部署,在时效性和运维成本上都是远远小于云下的。在构建湖仓一体的过程中,充分利用云的特性进行技术选型,面向云计算技术设计的湖仓一体架构被称为云原生湖仓(Cloude Native Lakehouse)。
虽然云原生湖仓在理论上十分美好,但是从传统的企业数仓转型到云原生湖仓却面临着很多挑战,这些挑战有些来自于构建湖仓一体本身,有些来自于云环境与非云环境的差异。
-
存储系统的不兼容:云上数据湖通常是基于对象存储服务构建的,而云下数据湖一般采用 HDFS,HDFS 的 API 模型是面向 POSIX 兼容的文件系统设计的,而对象存储的 API 更加类似一种 KV 存储,有些语义的 API(比如 Rename 或 list)对象存储服务并不提供或无法保证类似 HDFS 一致的语义。
-
云数据管理问题:在数据湖构建过程中,由于存量数据和业务的问题,往往使用 Hive 做元数据中心以兼容原来的 Hive 计算任务,如果重头构建新的湖仓一体,使用 Hive 做元数据中心显得有些多余,而且由于 Hive 是强依赖于 HDFS 的,导致的云上部署时必须提供 HDFS 的部署方案才可以部署 Hive。因此在上云的过程中,很多企业会选择云厂商提供的元数据服务以减少部署和运维的成本,不过选择云厂商的元数据服务固然省心,但是企业在上云过程中通常又不愿意和某一家云厂商绑定太深,谁也不能保证未来不会迁移到其他的云上。
-
多云、混合云的问题:在云上实践的过程中,多云或者混合云的场景是很多企业会遇到的情况。比如对于跨国业务,可能在不同的国家会选择不同的云厂商提供基础设施,或者在上云的过程中,需要云上云下的业务共存一段时间因而出现混合部署的情况。在这类场景下,原生 Hive 这种元数据中心的能力显得有些不足,导致往往需要部署多套 Hive 才能解决,这不仅带来额外的部署运维成本,也无法对元数据进行统一的管理。
04 Apache Iceberg 适合云原生湖仓的特性
在构建云原生湖仓时间,对于数据湖表格式的选择需要更关注其在面向云场景下的能力,综合对比下来,Iceberg 是非常适合构建云原生湖仓的表格式。
-
Iceberg 在实现上并不强依赖于 Hadoop API,其对存储层的抽象比较彻底,可以直接访问对象存储而不用经过 Hadoop API,在云上部署时可以减少不必要的依赖。Iceberg 已经适配了多个云厂商的对象存储,包括 AWS 的 S3,阿里云 OSS,Dell 的 ECS 等。
-
Iceberg Catalog 抽象的也比较彻底,天然容易适配各种不同的元数据服务,除了 Hive 还适配了 AWS 的 Glue Catalog。Iceberg 还定义了一套开放的 Catalog Open API,任何实现了该 OpenAPI 的服务均可以作为 Iceberg 的元数据中心,该特性使得构建与云厂商无关的元数据中心服务成为可能。
以上两点特性使得 Iceberg 成为了一个非常适合构建云原生湖仓的数据湖表格式,但如前文所说,只有数据湖表并不能构成湖仓,还需要有其他组件来解决缺失的湖表管理、优化等问题,而这部分功能则可以由 Amoro 补齐。
05 Amoro 云原生友好的特性
Amoro 是一个基于开源数据湖表格的湖仓管理系统。它与包括 Flink、Spark 和 Trino 在内的计算引擎一起工作,为 LakeHouse 提供可插拔的自管理功能,提供开箱即用的数据仓库体验,并帮助数据平台或产品轻松构建基于湖的架构,实现基础设施解耦、流批融合的目标。
Amoro 提供了两个核心组件 AMS 和 Optimizer,AMS(Amoro Management Service)提供了面向湖仓的管理服务,是 Amoro 的核心,而 Optimizer 是可插拔的分布式湖表优化执行器。二者一起提供了如下核心能力。
Catalog 服务
Amoro 提供了面向数据湖表的元数据管理服务,主要包括:
-
Iceberg Rest Catalog 服务:AMS 提供了面向 Iceberg Rest Catalog OpenAPI 的实现,Iceberg 使用者在引擎端通过简单的配置就可以直接连接到 AMS,并将湖表的信息注册到 AMS。AMS 提供了一种与云厂商无关的面向湖表的元数据服务,用户不用担心未来在不同云厂商见迁移时元数据迁移的问题。
-
多 Catalog 管理:不同于 Hive 只有 Database 和 table 的二元结构,AMS 提供了多 Catalog 管理的能力,用户可以根据具体的业务需要,灵活的创建不同的 Catalog,每个 Catalog 均拥有独立的命名空间。在混合云或者多云的场景下,可以使用一套 AMS 服务通过不同的 Catalog 管理不同湖上的表。
-
对接外部 metastore:AMS 可以对接各种类型的外部 Catalog,以实现元数据的统一管理。任何 Iceberg 支持的 Catalog 类型(比如:Hive,Glue,DynamicDB 等)都可以通过简单配置即可注册到 AMS 中,并映射为一个 Catalog。在有些场景下,比如因为需要和云厂商的其他 SAAS 服务进行集成的需求,必须选择某种其他类型的 Metastore,仍然可以通过一套 AMS 服务实现不同 Region 数据湖表的管理。
湖表持续优化
在流批融合的场景下,持续不断的流式写入会带来大量的小文件,CDC 入湖以及流式的更新会生成大量的逻辑删除文件,这些问题可能会显著影响数据分析的性能和成本。因此,Amoro 引入了自我优化机制,创建了一个开箱即用的流式 LakeHouse 管理服务,其用户友好程度与传统数据库或数据仓库相当。自我优化涉及各种过程,如文件压缩、去重和排序等。
-
Self-Optimizing 由 AMS 统一管理:AMS 会持续监控数据湖表的写入,并根据文件碎片的大小,写入数据的分布,以及 Delete 文件的数量决定是否触发数据湖表的 Optimizing,用户不必关心任务的触发时机,AMS 会根据用户配置的优化目标持续的调度优化任务,因此用户可以将更多的精力关注在业务本身。
-
弹性 Optimizer:Amoro 提供了可插拔的 Optimizer 实现,并支持 on yarn,或 on k8s 等多种方式。Optimizer 可以根据需要弹性扩缩容,业务无需为了流量尖峰预留大量资源,可以充分利用云上弹性扩缩容的特性,按需对 Optimizer 进行扩缩容。
-
资源隔离:Amoro 通过 Optimizing group 实现资源的共享和隔离,通过在数据湖表上的 Properties 指定所属的 Optimizing group 即可实现计算资源在数据湖表之间的共享和隔离。
-
灵活的调度策略:Amoro 实现了两种调度策略,在每个 Optimizing Group 下,Balanced 的策略倾向于使得所有表尽可能平等的使用资源。Quota 策略则可以根据需要,为每个表配置不同的权重,使得权重更高的表占据更多的优化资源。通过调度策略的配置,用户可以在分析性能,资源使用之间达到平衡。
统一湖表管理
通过 Catalog 服务和外部 Metastore 适配,AMS 实现了湖表信息的打通以及统一管理。
-
平台管理者可以通过 AMS 提供的 Web 管理页面查询不同湖上的湖表,查看表的分区信息,Snapshot 信息,存储资源使用情况以及 DDL 变更历史等信息。
-
湖表的持续优化也可以通过 Web 页面查看,包括表的优化历史,每次优化输入数据文件数量,数据量,正在执行的优化进度等信息。
06 Apache Iceberg + Amoro 云原生部署实战
在接下来的部分,本文将演示如何在云上基于 Apache Iceberg + Amoro 构建与基础设施无关构的云原生湖仓系统。
接下来的演示基于 AWS,在接下来的演示中将使用 AWS S3 服务作为数据湖,以 Iceberg 构建数据湖表,通过 Amoro Rest Catalog 来管理湖上的 Iceberg 表,并演示通过 Flink 任务模拟数据入湖,然后通过 Spark 查询,并演示湖表上的自动持续自优化能力。
在演示中除了使用到 S3 存储服务以外,还需要一台 EC2 云主机用于部署 Amoro 服务,一个 EKS(K8S)集群用于演示弹性扩缩容的持续优化能力,并运行 Flink 和 Spark 任务。
1. 环境准备
为了完成本文后续的演练部分,请提前完成以下环境准备。
→ Step 1:创建 S3 Bucket
进入 S3 服务控制台,创建 S3 Bucket 用于构建数据湖。
→ Step 2:创建 VPC
进入 VPC 服务控制台,创建一个 VPC,VPC 要求至少 2 个可用区域,每个区域包括一个 public subnet。由于后续需要访问 DockerHub 和 GitHub 服务,
→ Step 3:创建一台 EC2 云主机
进入 EC2 服务控制台,在刚创建的 VPC 内创建一台 EC2 云主机,名称为 amoro-ams ,用于部署 AMS,规格至少为 m5.large 且拥有 100G 的 EBS,AMI 镜像选择 Ubuntu 并部署于 public subnet 内。在完成 EC2 创建后,请修改安全组配置,允许其访问互联网。在本文的后面部分,将以 `amoro-ams-host` 指代可以访问该云主机的 IP 地址。
→ Step 4:创建 EKS 集群,并添加计算节点
进入 EKS 服务管理页面,添加 EKS 集群,名称为 amoro-k8s。
注意需要选择刚创建的 VPC,并且选择 public subnet。
集群创建成功后,进入集群详情页,选择计算 Tab 页面,创建节点组。节点组规格选择 m5.large,节点数量最少选择 2 个。节点组创建成功后,切回 EC2 管理平台,可以看到自动创建了 2 台 EC2 云主机,这两天云主机将会作为 K8S 集群的 node 节点。
→ Step 5:申请密钥对
进入账户-安全凭证页面,创建访问密钥对,记录下 access_key 和 sercet_key。
注意这里密钥只会出现一次,需要保存好,在后面的步骤中会使用到。并且将其设置到环境变量中,以便本文后续脚本中使用。
- export AWS_ACCESS_KEY_ID=<your-access-key>
- export AWS_SECRET_ACCESS_KEY=<your-secret-key>
→ Step 6:安装必须软件
登录到 amoro-ams 云主机中,切换到 root 用户,执行以下脚本以安装必须软件
- #!/bin/bash
- # install docker
- for pkg in docker.io docker-doc docker-compose podman-docker containerd runc; do sudo apt-get remove $pkg; done
- apt-get update
- apt-get install -y ca-certificates curl gnupg
- install -m 0755 -d /etc/apt/keyrings
- curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
- chmod a+r /etc/apt/keyrings/docker.gpg
- echo \
- "deb [arch="$(dpkg --print-architecture)" signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
- "$(. /etc/os-release && echo "$VERSION_CODENAME")" stable" | \
- sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
-
- apt-get update
- apt-get install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
- docker run hello-world
-
- # install java
- apt-get install -y openjdk-8-jdk
-
- # install maven
- cd /usr/local/share
- wget https://dlcdn.apache.org/maven/maven-3/3.8.8/binaries/apache-maven-3.8.8-bin.tar.gz
- tar -zxvf apache-maven-3.8.8-bin.tar.gz
- cd /usr/local/bin
- ln -s /usr/local/share/apache-maven-3.8.8/bin/mvn mvn
-
- # install flink
- cd ~
- wget https://dlcdn.apache.org/flink/flink-1.16.2/flink-1.16.2-bin-scala_2.12.tgz
- tar zxvf flink-1.16.2-bin-scala_2.12.tgz
-
- # install aws
- apt-get install -y unzip
- curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
- unzip awscliv2.zip
- ./aws/install
- aws --version
-
- # install kubectl
- curl -O https://s3.us-west-2.amazonaws.com/amazon-eks/1.27.1/2023-04-19/bin/linux/amd64/kubectl
- chmod +x ./kubectl
- mv ./kubectl /usr/local/bin/kubectl
- kubectl version

执行完成后,再继续执行以下命令初始化配置文件
- #!/bin/bash
-
- # aws configure
- aws configure
-
- EKS_CLUSTER_NAME=amoro-k8s
- aws eks update-kubeconfig --name ${EKS_CLUSTER_NAME}
在执行过程中,需要输入上面步骤中申请的 access_key 和 sercet_key。然后创建一个 ServiceAccount 用于提交 Flink 任务。
-
- # create service account
- kubectl create serviceaccount flink
- kubectl create clusterrolebinding flink-role-bind --clusterrole=edit --serviceaccount=default:flink
最后,开启 kubectl 的 proxy 服务。
kubectl proxy --port=8081 --address=0.0.0.0 --disable-filter=true &这可以让我们在 amoro-ams 这台云主机的 8081 端口上访问 K8S 集群内的容器端口。
2. 部署 Amoro AMS
Amoro 一些面向云原生的特性在 0.5.0 版本中引入,您通过以下命令从源码构建。
- git clone https://github.com/NetEase/amoro.git
- cd amoro
- git checkout v0.5.0
- mvn clean install -DskipTests -am -e -pl dist -Paws -Poptimizer.flink1.166
构建完成后,可以在 ./dist/target 目录下找到以 .zip 后缀的二进制包。
无论是通过下载还是通过源码构建,将二进制包复制到 EC2 云主机中并解压。将解压后的目录设置为环境变量。
- unzip amoro-0.5.0-bin.zip
- export AMORO_HOME=/root/amoro-0.5.0
在本文后续步骤中,将以 AMORO_HOME 指代 amoro 二进制包根目录。然后修改 amoro 配置文件
- cd ${AMORO_HOME}
- vim conf/config.yml
Amoro 的配置请参考官网:https://amoro.netease.com/docs/latest/deployment/#configuration
注意:本次演示中,由于需要在 K8S 集群中访问 AMS,必须修改 ams.server-expose-host 对应的值为本云主机从外部可以访问的 IP。
完成配置修改后,启动 AMS
./bin/ams.sh start 然后通过浏览器 http://{amoro-ams-host}:1630 访问 AMS 页面,默认登录账号 admin 默认登录密码 admin。
3. 接入 Apache Iceberg
在使用 Iceberg 前,需要先配置一个 Catalog,按以下步骤创建一个 Catalog。
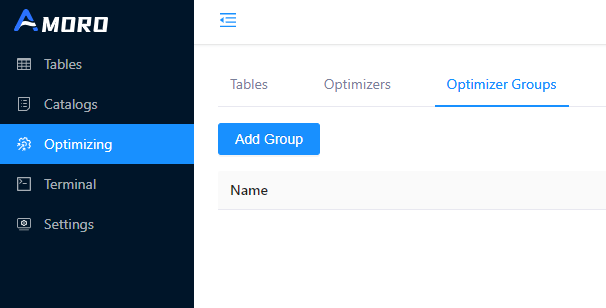
→ Step 1:为 Catalog 创建 Optimizer Group
进入到 Optimizing -> Optimizer Groups 页面,点击 Add Group
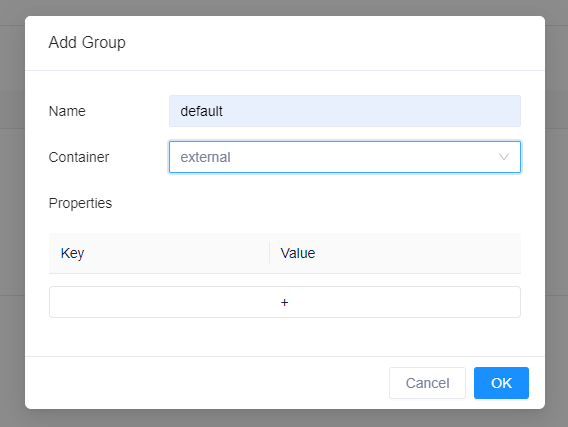
在弹出的对话框中,输入 Group Name 为 default,Container 类型为 external。点击 OK 按钮保存
→ Step 2:创建 Catalog
进入 Catalogs 页面,按以下方式创建 Catalog
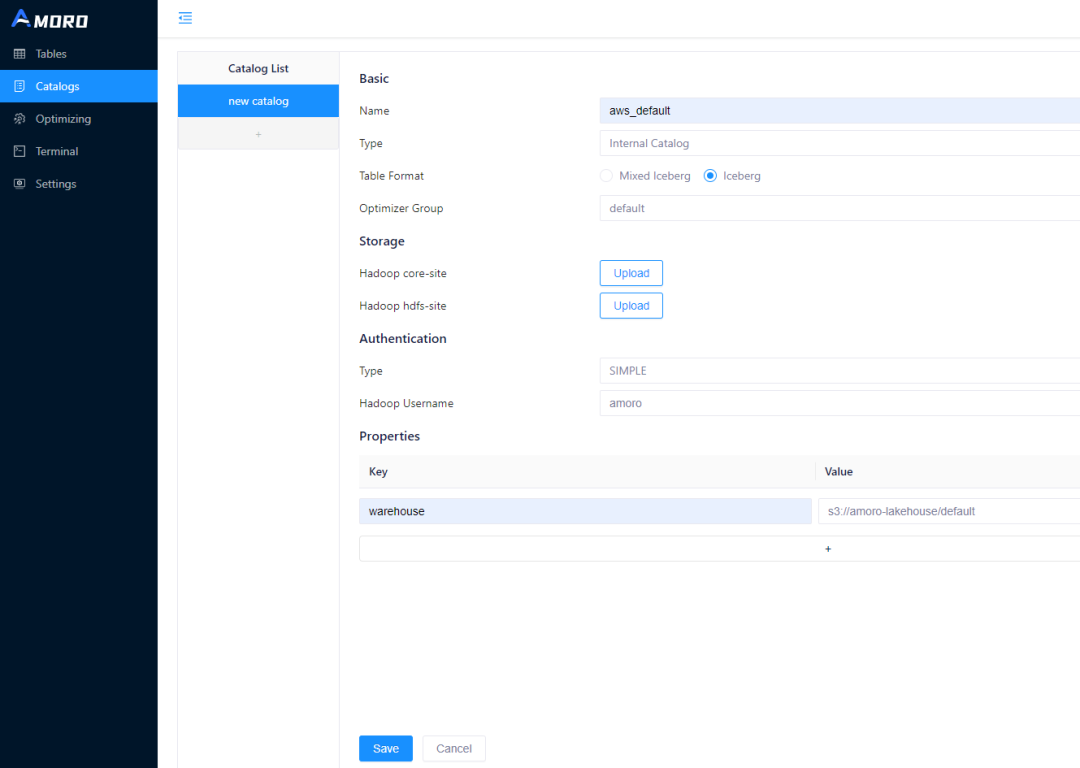
注意:
-
Catalog Type 需要选择 Internal Catalog,TableFormat 选择 Iceberg
-
由于是直接基于 S3 服务构建数据湖,所以 Storage 部分可以不用上传 Hadoop Site 文件
-
同样的,云上也不采用 Hadoop 的认证体系,在认证这里可以选择 SIMPLE,填入任意值即可
-
在属性这部分,必须配置 warehouse,这是数据存储的目录,在这里我们配置了一个 S3 的 bucket,并带上 /defaut 前缀。在实践中,一个 bucket 可以通过前缀给多个 catalog 使用。
点击保存,一个 Iceberg Catalog 即创建好了。
这里注意创建时填写的 Catalog Name,在后续的计算任务中将使用该 Catalog Name 作为 Warehouse 名称。这里使用的名称是 aws_default 在后续的演示中,会直接使用该名称。
4. 启动 Optimizer
Optimizer 是一个 Flink Job,可以通过 flink run 命令提交到 Yarn 或者 K8S 集群上,当需要进行弹性扩容时,可以提交多个 Flink Job 以获取更多的计算资源。
本步骤中所需的 Optimizer Docket Image 已经上传到 Dockerhub,可以直接拉取 docker pull arctic163/optimizer-flink1.16:0.5.0-aws 也可以通过以下 Dockerfile 构建。
- FROM apache/flink:1.16-java8
- ARG REPO_URL=https://repo.maven.apache.org/maven2
- ARG OPTIMIZRE_JOB=OptimizeJob.jar
- RUN mkdir -p $FLINK_HOME/usrlib
- COPY $OPTIMIZRE_JOB $FLINK_HOME/usrlib/OptimizeJob.jar
其中 OptimizeJob.jar 在 ${AMORO_HOME}/plugin/optimize/OptimizeJob.jar 需要提前复制到 Dockerfile 同级目录。
在 amoro-ams 云主机上执行以下命令,向 K8S 集群提交 Flink Optimizer 任务。
- AMORO_THRIFT_ENDPOINT=thrift://<arcitc-ams-host>:1261
- OPTIMIZER_CLUSTER_ID=amoro-default-optimizer
-
- ./bin/flink run-application \
- --target kubernetes-application \
- -Dkubernetes.cluster-id=${OPTIMIZER_CLUSTER_ID} \
- -Dkubernetes.jobmanager.service-account=flink \
- -Dcontainerized.master.env.AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID} \
- -Dcontainerized.master.env.AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY} \
- -Dcontainerized.taskmanager.env.AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID} \
- -Dcontainerized.taskmanager.env.AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY} \
- -Dkubernetes.container.image=arctic163/optimizer-flink1.16:0.5.0-aws \
- -Dkubernetes.container.image.pull-policy=Always \
- -Dkubernetes.jobmanager.cpu=0.5 \
- -Dkubernetes.taskmanager.cpu=0.5 \
- -c com.netease.arctic.optimizer.flink.FlinkOptimizer \
- local:///opt/flink/usrlib/OptimizeJob.jar \
- -a ${AMORO_THRIFT_ENDPOINT} -g default -m 1024 -p 2
提交成功后,Flink 会在 K8S 上创建 3 个 Pod,其中一个 JM 两个 TM ,通过以下命令可以查询。
- root@ip-10-0-12-143:~/flink-1.16.2# kubectl get pods
- NAME READY STATUS RESTARTS AGE
- amoro-default-optimizer-5cfd74f7bb-6vkcq 1/1 Running 0 6m13s
- amoro-default-optimizer-taskmanager-1-1 1/1 Running 0 5m39s
- amoro-default-optimizer-taskmanager-1-2 1/1 Running 0 5m39s
也通过kubectl proxy 访问Pod内端口,通过链接 http://{amoro-ams-host}:8081/api/v1/namespaces/default/services/amoro-default-optimizer-rest:rest/proxy/#/job/running 可以看到刚提交的任务的 Flink Dashbord。
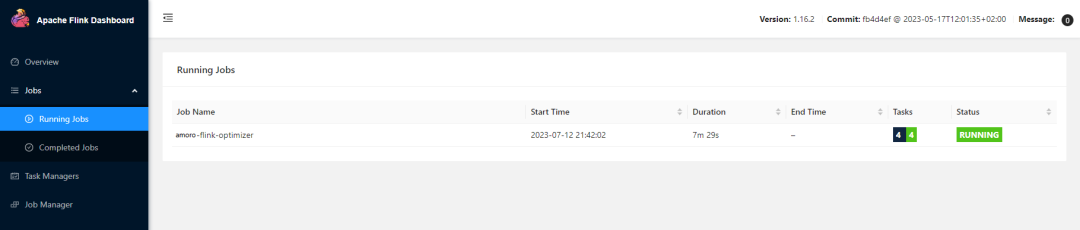
Optimizer 启动成功后,会向 AMS 进行注册。在 AMS 的 Optimizing -> Optimizers 页面可以看到刚才提交的 Flink Optimizer 任务。
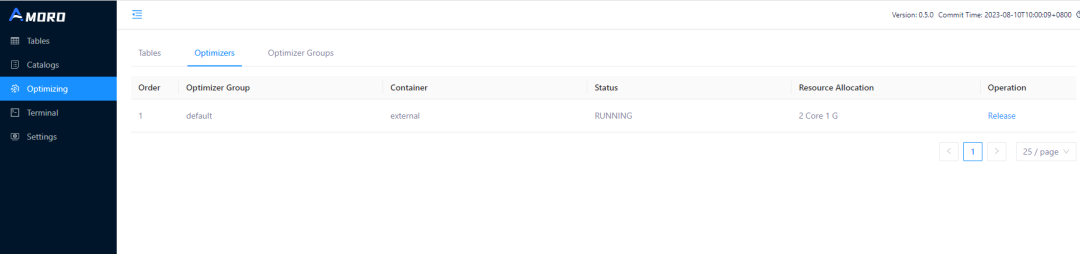
5. 开启入湖任务
在本部分我们提交一个 Flink SQL 任务模拟数据入湖。在接下来需要在 K8S 集群上创建一个 Flink Session ,然后通过 FlinkSQL Client 提交一个 Iceberg upsert 入湖任务。
这部分需要的 Docker image 已经上传至 Dockerhub ,可以通过命令 arctic163/flink1.16-iceberg-aws:latest 直接获取,也可以通过以下 Dockerfile 重头构建。
- FROM apache/flink:1.16-java8
- ARG REPO_URL=https://repo.maven.apache.org/maven2
- RUN cd ${FLINK_HOME}/lib \
- && wget ${REPO_URL}/org/apache/iceberg/iceberg-flink-runtime-1.16/1.1.0/iceberg-flink-runtime-1.16-1.1.0.jar \
- && wget ${REPO_URL}/software/amazon/awssdk/bundle/2.20.5/bundle-2.20.5.jar \
- && wget ${REPO_URL}/software/amazon/awssdk/url-connection-client/2.20.5/url-connection-client-2.20.5.jar \
- && wget ${REPO_URL}/org/apache/flink/flink-shaded-hadoop-2-uber/2.8.3-10.0/flink-shaded-hadoop-2-uber-2.8.3-10.0.jar \
- && chown flink:flink *.jar
通过以下命令向 K8S 创建一个 Flink Session 。
- CLUSTER_ID=flink-iceberg-session
- BUCKET=<your s3 bucket name>
-
- ./bin/kubernetes-session.sh \
- -Dkubernetes.cluster-id=${CLUSTER_ID} \
- -Dkubernetes.jobmanager.service-account=flink \
- -Dcontainerized.master.env.AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID} \
- -Dcontainerized.master.env.AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY} \
- -Dcontainerized.master.env.ENABLE_BUILT_IN_PLUGINS="flink-s3-fs-hadoop-1.16.2.jar" \
- -Dcontainerized.taskmanager.env.AWS_ACCESS_KEY_ID=${AWS_ACCESS_KEY_ID} \
- -Dcontainerized.taskmanager.env.AWS_SECRET_ACCESS_KEY=${AWS_SECRET_ACCESS_KEY} \
- -Dcontainerized.taskmanager.env.ENABLE_BUILT_IN_PLUGINS="flink-s3-fs-hadoop-1.16.2.jar" \
- -Dkubernetes.jobmanager.cpu=0.5 \
- -Dkubernetes.taskmanager.cpu=0.5 \
- -Dexecution.checkpointing.interval=15s \
- -Ds3.access-key=${AWS_ACCESS_KEY_ID} \
- -Ds3.secret-key=${AWS_SECRET_ACCESS_KEY} \
- -Dstate.checkpoints.dir="s3://${BUCKET}/checkpoints/" \
- -Dstate.backend=filesystem \
- -Dkubernetes.container.image=arctic163/flink1.16-iceberg-aws:latest
提交成功后可以通过 kubectl 查询 pod 状态
- root@ip-10-0-12-143:~/flink-1.16.2# kubectl get pods
- NAME READY STATUS RESTARTS AGE
- amoro-default-optimizer-5cfd74f7bb-6vkcq 1/1 Running 0 6m13s
- amoro-default-optimizer-taskmanager-1-1 1/1 Running 0 5m39s
- amoro-default-optimizer-taskmanager-1-2 1/1 Running 0 5m39s
- flink-iceberg-session-5f6cc679b7-smbnn 1/1 Running 0 28s
其中前三个是上一步中提交的 Flink Optimizer Job 。最好一个是刚才创建的 Flink Session,由于 Session 中还没有创建 Flink 任务,目前只有一个 JobManager 的 Pod。
通过以下命令登录到 JM 容器内启动 flink sql client。
- kubectl exec -it flink-iceberg-session-5f6cc679b7-smbnn -- /bin/bash
- root@flink-iceberg-session-5f6cc679b7-smbnn:/opt/flink# ./bin/sql-client.sh
然后提交以下 SQL ,在这段 SQL 中,我们创建了一个 Iceberg catalog 并使其指向我们在 AMS 中的 catalog,然后创建了一个 datagen 的原表用于生成随机数据,并且限制了会生成重复的 id 的记录。然后通过 upsert 模式写入 Iceberg 表中。
- SET 'execution.runtime-mode' = 'streaming';
- SET 'table.dynamic-table-options.enabled' = 'true';
-
- CREATE TABLE `source` (
- id INT,
- price DECIMAL(32,2),
- buyer STRING,
- order_time TIMESTAMP
- ) WITH (
- 'connector' = 'datagen',
- 'rows-per-second' = '10',
- 'fields.id.min' = '1',
- 'fields.id.max' = '200'
- );
-
- CREATE CATALOG `amoro_iceberg` WITH (
- 'type'='iceberg',
- 'catalog-impl'='org.apache.iceberg.rest.RESTCatalog',
- 'uri'='http://{amoro-ams-host}:1630/api/iceberg/rest',
- 'warehouse'='aws_default'
- );
-
- USE CATALOG `amoro_iceberg`;
- CREATE DATABASE IF NOT EXISTS `sales`;
- CREATE TABLE IF NOT EXISTS `sales`.`orders` (
- id INT,
- price DECIMAL(32,2),
- buyer STRING,
- order_time TIMESTAMP,
- PRIMARY KEY (id) NOT ENFORCED
- ) WITH (
- 'format-version'='2',
- 'write.upsert.enabled'='true',
- 'write.metadata.metrics.default'='full'
- );
-
- insert into `sales`.`orders` select * from `default_catalog`.`default_database`.`source`;
注意:由于 flink sql client 不支持一次性输入多条数据,以上 SQL 需要逐行输入。
任务提交后可以通过 kubectl proxy 查看 Flink WebUI
http://{amoro-ams-host}:8081/api/v1/namespaces/default/services/flink-iceberg-session-rest:rest/proxy/#/overview
在任务详情页可以看到
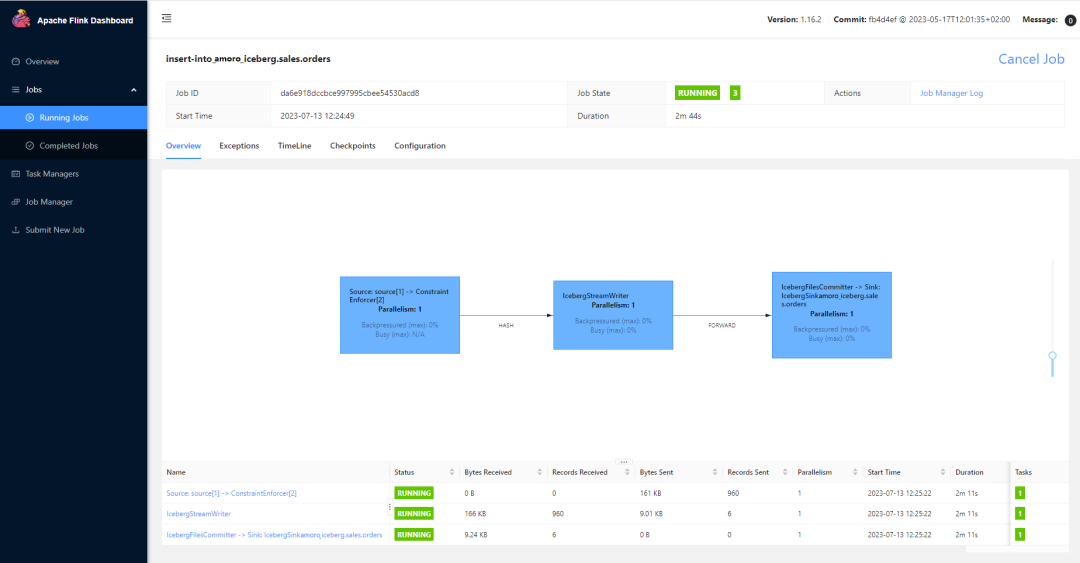
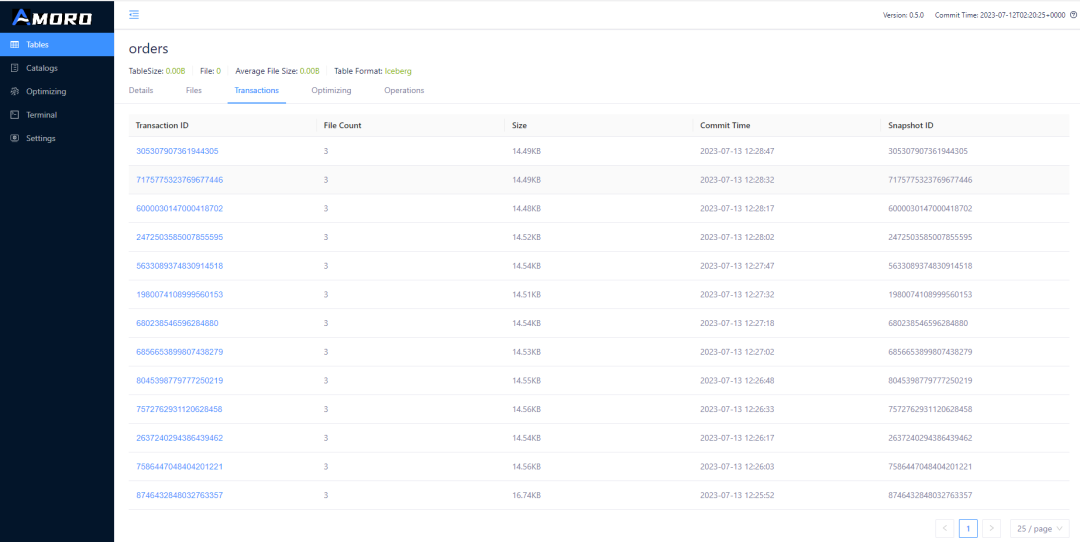
说明任务正常启动成功。打开AMS的 表详情页面,可以看到 Flink 提交事物
http://{amoro-ams-host}:1630/tables?catalog=aws_default&db=sales&table=orders&type=ICEBERG&tab=Transactions
6. 查询入湖数据
在 Flink 任务持续入湖的过程中,再通过 Spark 查询湖上的数据。AMS 集成了一个 embedded Spark 环境,切换到 AMS 的 Terminal 页面,选择 aws_default Catalog ,执行以下 SQL
- set `spark.sql.iceberg.handle-timestamp-without-timezone`=`true` ;
- select * from sales.orders order by id limit 10 ;
即可在页面查询刚才通过 Flink 写入的数据。
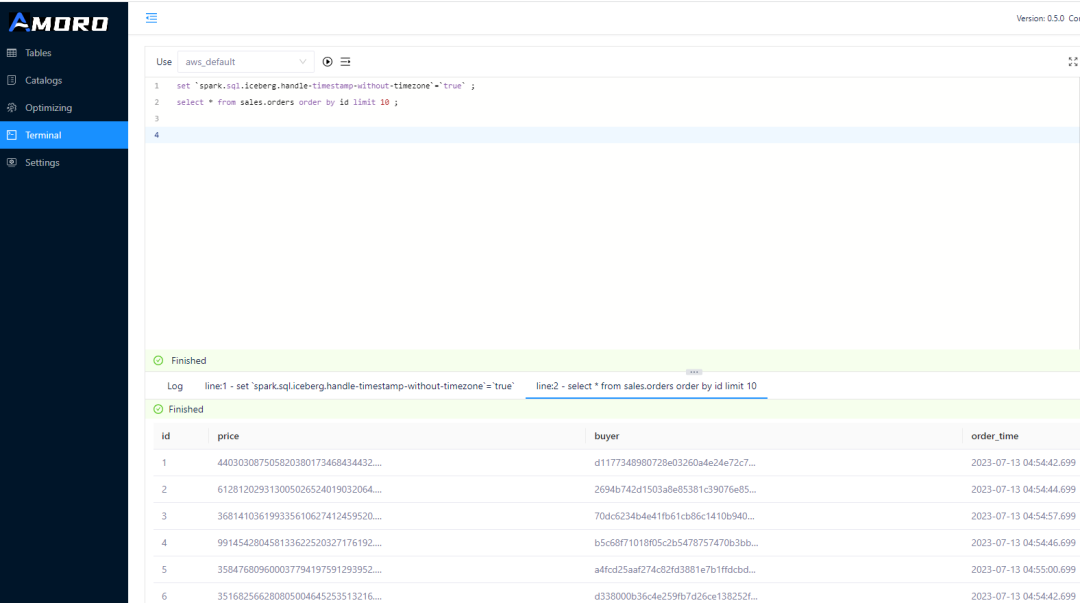
可以每隔一段时间查询一次,由于 Iceberg 表开启了 upsert 模式,因此可以看到虽然表的数据量一直维持在 200 条记录,但是数据会随机更新。
您也可以在 AWS S3 控制页面查看入湖的数据文件。
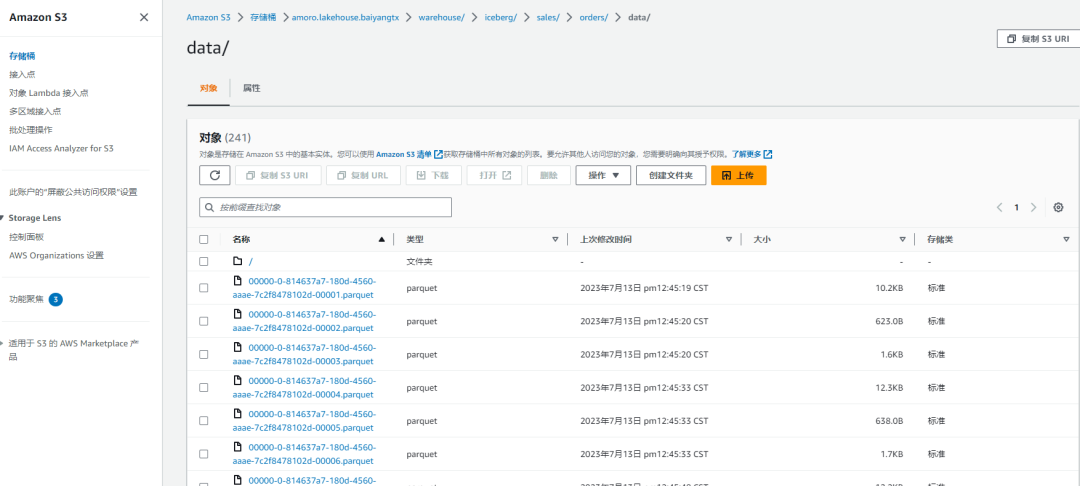
7. 查看优化效果
在 AMS 表详情页面,切换到 Optimizing 子页面,可以查询到表上执行 Optimizing 的历史以及状态
http://{amoro-ams-host}:1630/tables?catalog=aws_default&db=sales&table=orders&type=ICEBERG&tab=Optimized
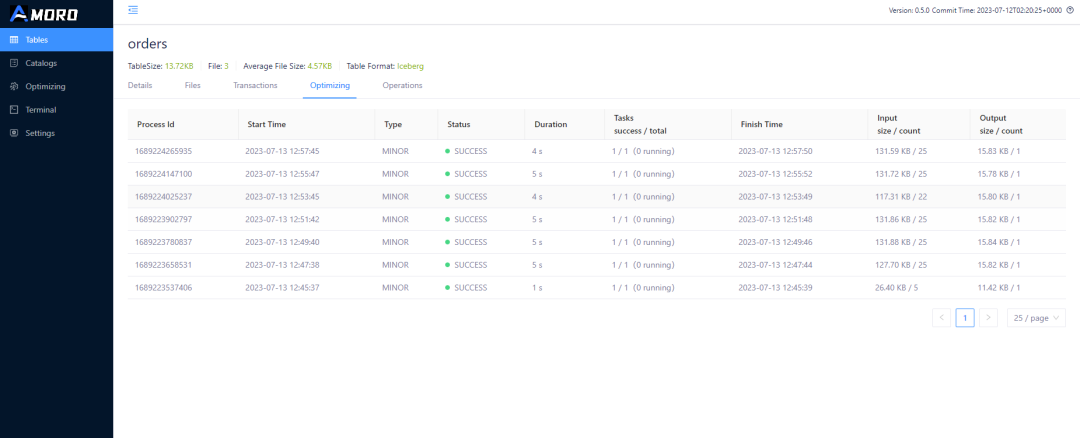
页面上展示了表上执行 Optimizing 的历史,每次 Optimizing 的输入数据量和输出数据量。可以看到基本每 3-5min 就会触发一次 Optimizing, 每次执行大约都会将 25 个小文件合并成一个文件,对比输入输出数据规模,可以看出每次合并都消除了大量的无效 delete 数据。
06 总结
本文系统的介绍 cloud native lakehouse 的概念,阐述基于云平台构建云原生湖仓的优势和挑战,介绍了 Apache Iceberg + Amoro 在构建云原生湖仓方面的优势,并以实际案例演示了基于 AWS S3 构建数据湖,通过 Iceberg Upsert 功能完成数据入湖,并通过 Amoro AMS 对湖表进行管理,Optimizing 自动优化等功能。未来我们会为您带来更多在云上的业务实践案例的分享。
关于 Amoro 的更多资讯可查看:
官网:https://amoro.netease.com/
源码:https://github.com/NetEase/amoro
作者:张永翔
编辑:Viridian

