
热门标签
热门文章
- 1NSSCTF做题(6)_$aaa==114514 && $bbb==114514 && $aaa!=$bbb
- 2Github网络安全测试工具库_github漏洞扫描器项目
- 31.springboot压测调优_springboot项目压测了几个请求就padding
- 4关于CSDN博客阅读数显示的一些问题_csdn已阅读包括自己吗
- 5_string
- 6C语言I/O学习笔记(1)stdin,stdout和stderr以及重定向_c语言 重定义 stdin
- 7工业设备嵌入式通讯接口升级方案_设备通讯接口升级权限
- 8【错误记录】Android 编译报错 ( The project uses Gradle version which is incompatible with Android Studio )_unsupported gradle. the project uses gradle versio
- 9搭建自己的chatgpt-web(nextchat)_chatgptweb搭建
- 10uniapp通过custom-tab-bar 自定义tabbar导航栏(主要用于微信小程序)_uniapp custom-tab-bar
当前位置: article > 正文
单链表的一些练习【移除数组元素】【反转链表】【链表的中间节点】【合并两个有序链表】【约瑟夫问题】【分割链表】
作者:小蓝xlanll | 2024-04-19 06:38:11
赞
踩
单链表的一些练习【移除数组元素】【反转链表】【链表的中间节点】【合并两个有序链表】【约瑟夫问题】【分割链表】
一.移除数组元素
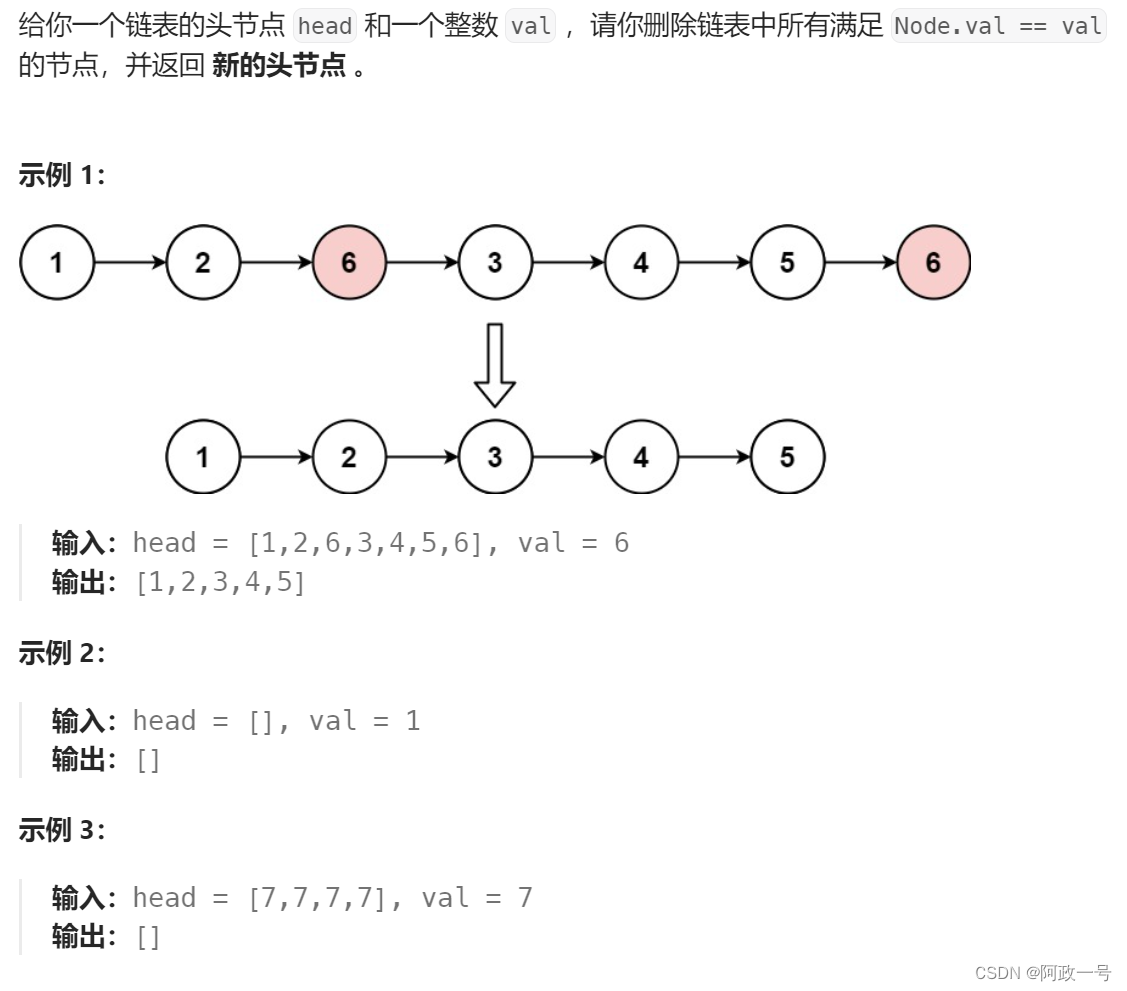
- /**
- * Definition for singly-linked list.
- * struct ListNode {
- * int val;
- * struct ListNode *next;
- * };
- */
- typedef struct ListNode ListNode;
- struct ListNode* removeElements(struct ListNode* head, int val)
- {
- ListNode* pcur=head;
- //创建一个新链表
- ListNode* newTail=NULL;//指向头的指针
- ListNode* newHead=NULL;//指向尾的指针
- while(pcur)//当pcur不为NULL的时候,进入循环
- {
- if(val!=pcur->val)//val在链表里没有此数据,进入if语句
- {
- if(newTail==NULL)//刚开始新链表为NULL时
- {
- newHead=newTail=pcur;//头指针和尾指针都指向刚开始的头结点
- }
- else //新链表已经有数据了,执行尾插操作
- {
- newTail->next=pcur;//newTail的next指针指向pcur节点
- newTail=newTail->next;//将newTail往后移动一个节点
- }
- }
- pcur=pcur->next;//每经过一次的循环,pcur就往后移动一个节点
- }
- if(newTail)//这里有一个if语句主要是为了避免传参过来的head为NULL的情况
- //如果head为NULL,那么上面的while循环就不会进入,newTail还是为NULL
- newTail->next=NULL;//把新链表的尾节点的next指针置为NULL
- //如果这里不置为NULL的话,假设我的head链表是1,2,6,4,5,6.要去除6的话。那么这里的newTail->next就还是指向的是6所在的这个节点
- return newHead;//返回我的新链表
- }

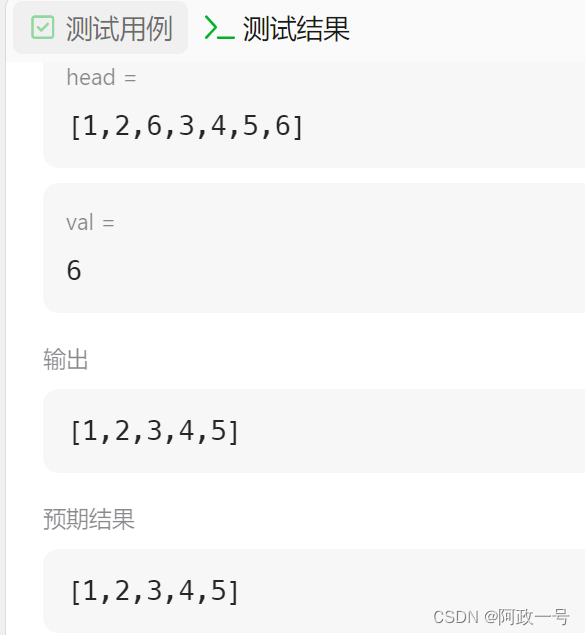
下面是三种测试结果,分别对应三种情况:


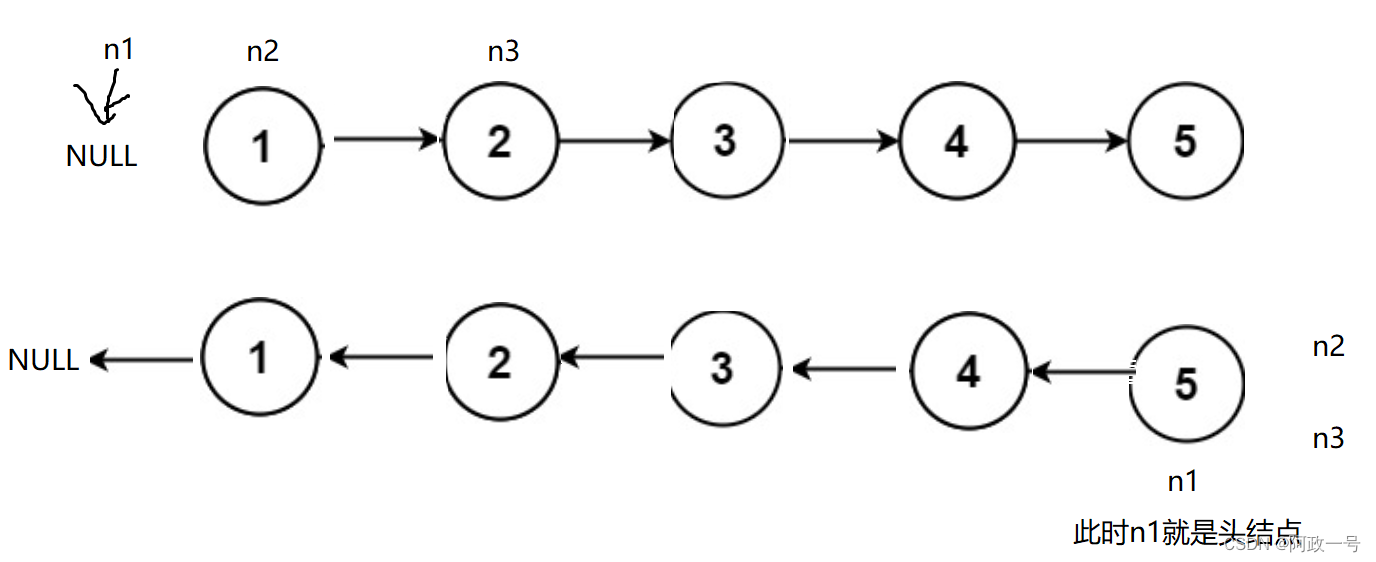
二. 反转链表

- /**
- * Definition for singly-linked list.
- * struct ListNode {
- * int val;
- * struct ListNode *next;
- * };
- */
- typedef struct ListNode ListNode;
- struct ListNode* reverseList(struct ListNode* head) {
- //判断head是否为NULL
- if(head==NULL)
- {
- return head;//如果为NULL,则返回NULL,程序不再往下执行
- }
- //我们创建三个指针,一直指向NULL,一个指向头结点,一个指向第二个节点
- ListNode* n1=NULL;
- ListNode* n2=head;
- ListNode* n3=n2->next;
- while(n2)//当n2为NULL时跳出循环
- {
- n2->next=n1;//n2->next原本指向的是第二个节点,这里直接给它指向n1
- n1=n2;//把n1指向的位置移动到n2的位置
- n2=n3;//把n2移动到n3的位置,等到n3走到NULL的时候,赋值给n2,此时也就跳出循环
- if(n3)
- n3=n3->next;//n3一直走到尾节点的后面:NULL
- }
- return n1;//n1的位置此时就在我们新的头结点的位置
- }
这个就是需要单独判断一下传参过去的链表为NULL的情况。然后通过三个指针的移动来实现链表的反转。
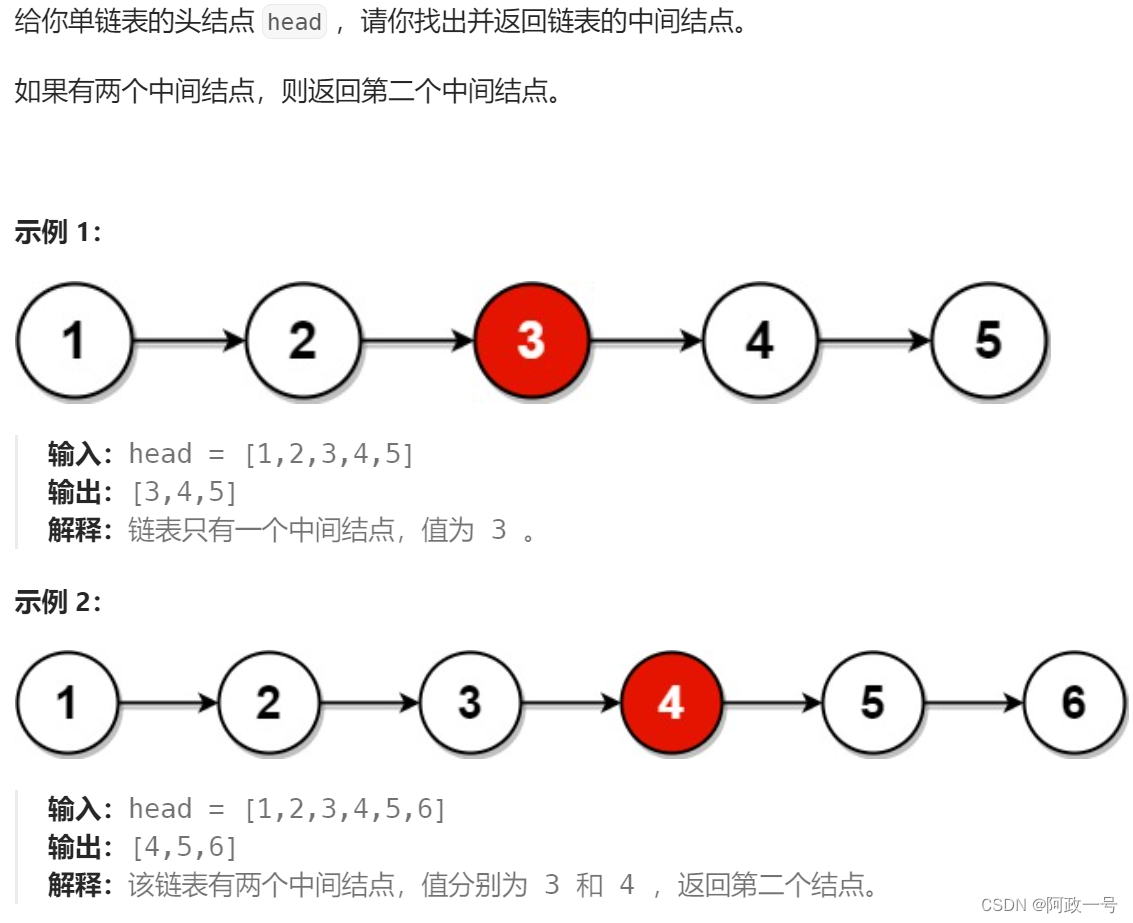
三.链表的中间节点
- /**
- * Definition for singly-linked list.
- * struct ListNode {
- * int val;
- * struct ListNode *next;
- * };
- */
- typedef struct ListNode ListNode;
- struct ListNode* middleNode(struct ListNode* head) {
- ListNode* slow=head;//慢指针
- ListNode* fast=head;//快指针
- while(fast&&fast->next)//这两个条件不能反过来,因为fast是有可能为NULL的,如果反过来了,此时就会出现空指针解引用的情况。
- {
- slow=slow->next;//一次往后走一个节点
- fast=fast->next->next;//一次往后走两个节点
- }
- return slow;//此时的slow就是中间节点,直接返回就行了
- }
这个题目用快慢指针来解决的话就非常好解。当然肯定不止这么一种思路,我们还可以做一个循环,先遍历整个链表,每一次经过一个节点就用一个count计数,最后把count/2就是中间节点的位置。
四.合并两个有序链表

- /**
- * Definition for singly-linked list.
- * struct ListNode {
- * int val;
- * struct ListNode *next;
- * };
- */
- typedef struct ListNode ListNode;
- struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2)
- {
- //如果两个链表有一个为NULL,则直接返回另一个链表
- if(list1==NULL)
- {
- return list2;
- }
- if(list2==NULL)
- {
- return list1;
- }
- ListNode* l1=list1;
- ListNode* l2=list2;
- //定义一个新的链表,有新头和新尾
- ListNode* newHead,*newTail;
- //直接开辟一块动态内存的空间,当做我们的头结点,也叫做哨兵位
- newHead=newTail=(ListNode*)malloc(sizeof(ListNode));
- while(l1&&l2)//当两个链表为其中一个完全遍历完,为NULL的时候出循环
- {
- if(l1->val < l2->val)
- {
- //l1的val比l2的小,把l1拿下来尾插
- newTail->next=l1;
- newTail=l1;
- l1=l1->next;
- }
- else
- {
- //把l2拿下来尾插
- newTail->next=l2;
- newTail=l2;
- l2=l2->next;
- }
- }
- //出了循环,不一定全部的节点都接在了新链表的后面
- if(l1==NULL)
- {
- newTail->next=l2;//把l2后面的节点也都给接过来
- }
- if(l2==NULL)
- {
- newTail->next=l1;//把l1后面的节点也都给接过来
- }
- ListNode* ret=newHead->next;//先把头结点的下一个节点给存起来,避免后面释放空间导致丢失
- free(newHead);
- newHead=NULL;
- return ret;//直接返回我们有效的节点
- }
注意,如果我们没有这个叫做哨兵位的头结点的话,写代码是比我们现在写的这个要麻烦一些的。比如我们在进入循环的时候,我们还要多判断一步新链表为不为NULL的情况。
五.环形链表的约瑟夫问题
故事背景:
据说著名犹太 Josephus有过以下的故事:在罗马人占领乔塔帕特后,39 个犹太人与Josephus及他的朋友躲到⼀个洞中,39个犹太人决定宁愿死也不要被人抓到,于是决定了一个自杀方式,41个人排成一个圆圈,由第1个人开始报数,每报数到第3人该人就必须自杀,然后再由下一个重新报数,直到所有人都自杀死亡为止。 然而Josephus 和他的朋友并不想遵从,Josephus要他的朋友先假装遵从,他将朋友与自己安排在第16个与第31个位置,于是逃过了这场死亡游戏。

- /**
- * 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
- *
- *
- * @param n int整型
- * @param m int整型
- * @return int整型
- */
- typedef struct ListNode ListNode;
- //创建节点
- ListNode* buyNode(int x)
- {
- ListNode* node=(ListNode*)malloc(sizeof(ListNode));
- if(node==NULL)
- {
- exit(1);
- }
- node->val=x;
- node->next=NULL;
- return node;
- }
- //创建循环链表
- ListNode* nodeCircle(int n)
- {
- ListNode* phead=buyNode(1);//先创建第一个节点
- ListNode* ptail=phead;
- for(int i=2;i<=n;i++)
- {
- ptail->next=buyNode(i);//一个一个的创建节点
- ptail=ptail->next;//指针依次往后走,直到尾节点
- }
- ptail->next=phead;//把最后一个节点的next指针指向头结点,就构成了循环链表
- return ptail;//返回的是头结点的前一个节点
- }
- int ysf(int n, int m )
- {
- ListNode* prev=nodeCircle(n);//这个指针指向的就是头结点的前一个节点
- ListNode* pcur=prev->next;//pcur指向的是头结点
- int count=1;//用来计数
- while(pcur->next!=pcur)//链表只有一个节点了,就跳出循环了
- {
- if(count==m)
- {
- prev->next=pcur->next;//直接跳过要删除的链表,指向下下一个链表
- free(pcur);
- pcur=prev->next;//pcur再往后移动
- count=1;//这里重新计数
- }
- else
- {
- //此时不需要删除节点
- prev=pcur;
- pcur=pcur->next;
- count++;
- }
- }
- return pcur->val;//剩下的这个节点里的值就是我们需要的值
- }
六.分割链表
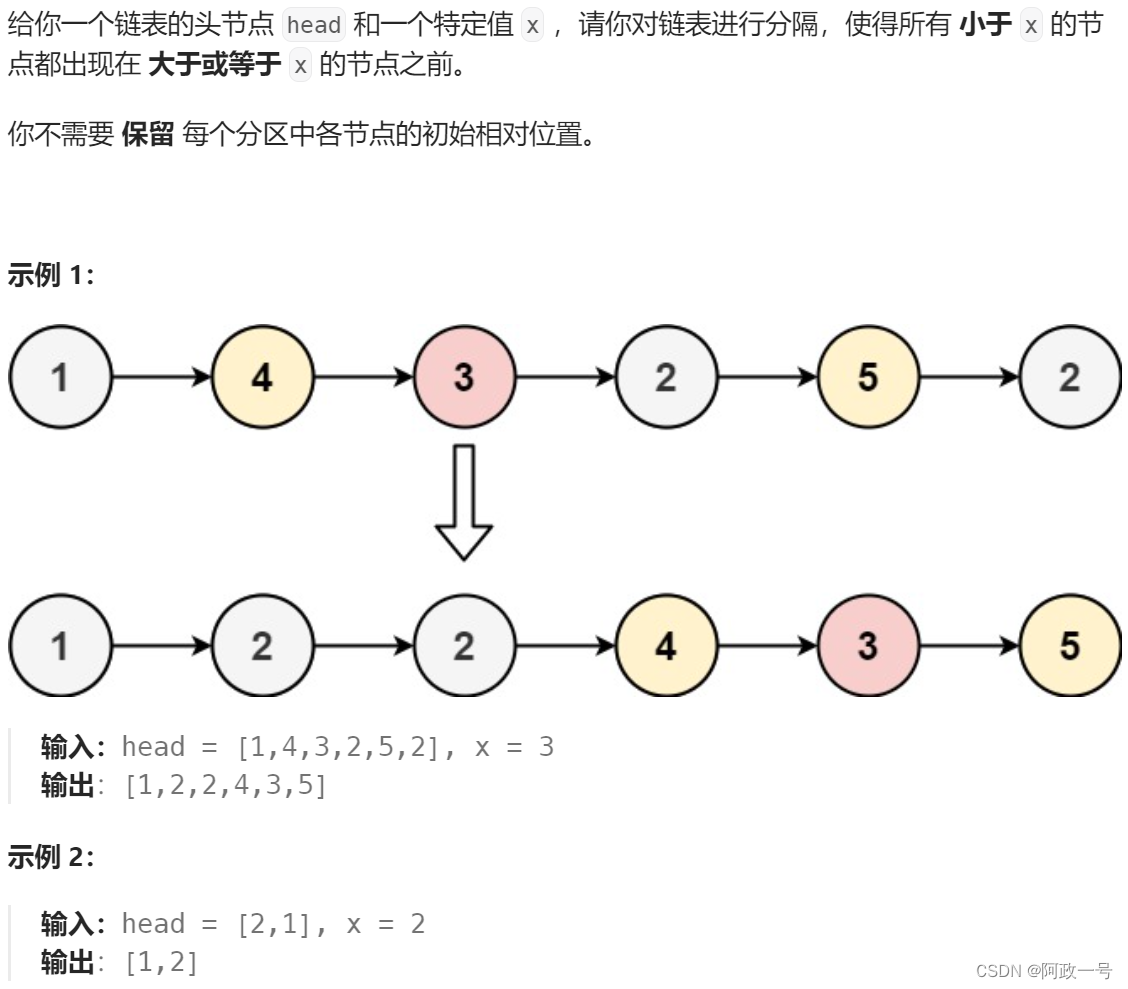
这个题的思路还挺多的,我们可以在原链表的基础上来思考:
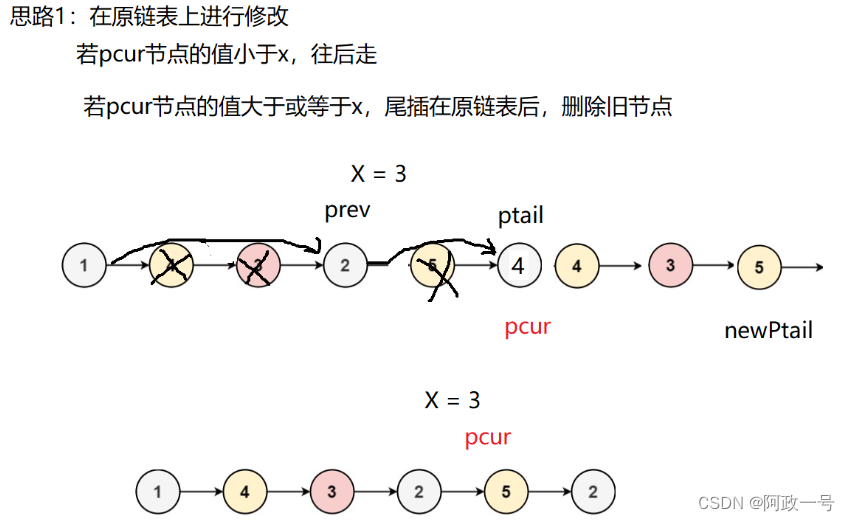
我们也可以创建一个新链表,利用尾插和头插来操作
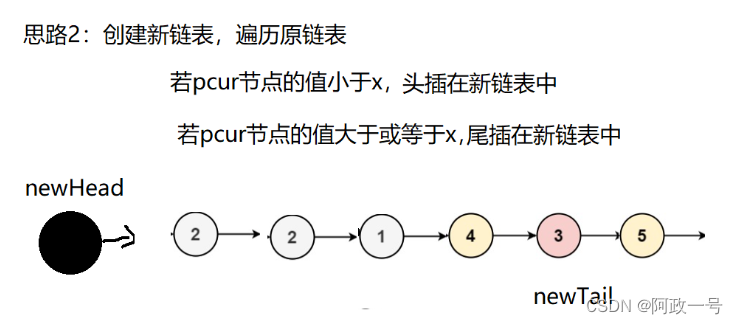
还有就是我们还可以创建两个链表:大链表和小链表
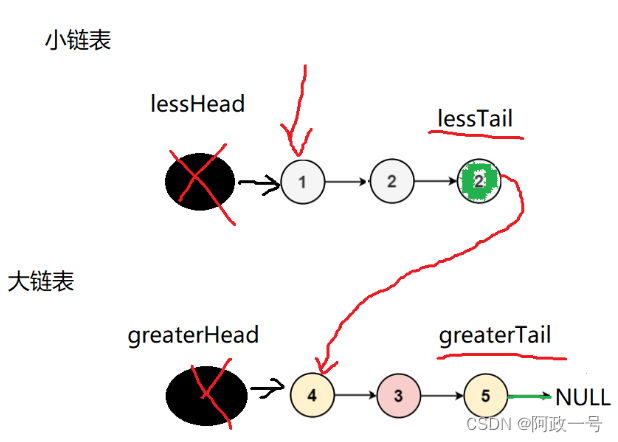
这个代码来实现一下:
- /**
- * Definition for singly-linked list.
- * struct ListNode {
- * int val;
- * struct ListNode *next;
- * };
- */
-
- typedef struct ListNode ListNode;
- struct ListNode* partition(struct ListNode* head, int x)
- {
- if(head==NULL)
- {
- return head;
- }
- //创建两个带头链表:大链表和小链表
- ListNode* lessHead,*lessTail;
- ListNode* greatHead,*greatTail;
- lessHead=lessTail=(ListNode*)malloc(sizeof(ListNode));
- greatHead=greatTail=(ListNode*)malloc(sizeof(ListNode));
-
- ListNode* pcur=head;
- while(pcur)//原链表走到NULL时跳出循环
- {
- if(pcur->val<x)//小于x就把节点尾插到小链表中
- {
- lessTail->next=pcur;
- lessTail=lessTail->next;//尾插完就把链表的尾节点,跳到下一个节点
- }
- else//反之,尾插到大链表中
- {
- greatTail->next=pcur;
- greatTail=greatTail->next;
- }
- pcur=pcur->next;//进行一次循环,pcur也要往后走
- }
- greatTail->next=NULL;//如果不把大链表的尾节点的next指针置为NULL,这就是个死循环
- lessTail->next=greatHead->next;//把小链表的尾节点插入到大链表的第一个有效节点
- return lessHead->next;//返回的也必须是有效节点
- }
做完这些题关于链表的知识我们基本上也有了一定的认识。感谢大家的观看,如有错误,请大家多多指出。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/小蓝xlanll/article/detail/450408
推荐阅读

相关标签

